TL;DR#
Large Language Models (LLMs) rely on pre-training knowledge, but Low-Rank Adaptation (LoRA) is used for updates. Integrating new facts can compromise previously learned knowledge. Existing techniques like Retrieval-Augmented Generation (RAG) and few-shot learning have limitations, motivating a revisit to fine-tuning for knowledge integration. Fine-tuning LLMs is computationally expensive, leading to Parameter-Efficient Fine-Tuning (PEFT) techniques like LoRA. However, modified LLMs can suffer from catastrophic forgetting or loss of associations. Increased new data can degrade pre-existing knowledge, prompting investigation into how much knowledge can be added without harm.
This study investigates additional knowledge integration into LLMs via LoRA while preserving capabilities. Experiments fine-tuned Llama-3.1-8B-instruct with varying new knowledge amounts, tracking degradation using metrics and benchmarks(MMLU, TruthfulQA). The best results came from mixing known and new facts, but performance on external question-answering declined. Training data bias led to over-represented answers, while models became more confident and refused answers less often. The findings underscore LoRA-based LLM updates’ pitfalls and the importance of balanced training data.
Key Takeaways#
Why does it matter?#
This paper is important for researchers as it highlights the trade-offs involved in updating LLMs with new knowledge using LoRA. Understanding these dynamics is crucial for developing effective and safe fine-tuning strategies. The research also uncovers the risk of reasoning disruption and suggests directions for mitigating these issues, paving the way for further research.
Visual Insights#

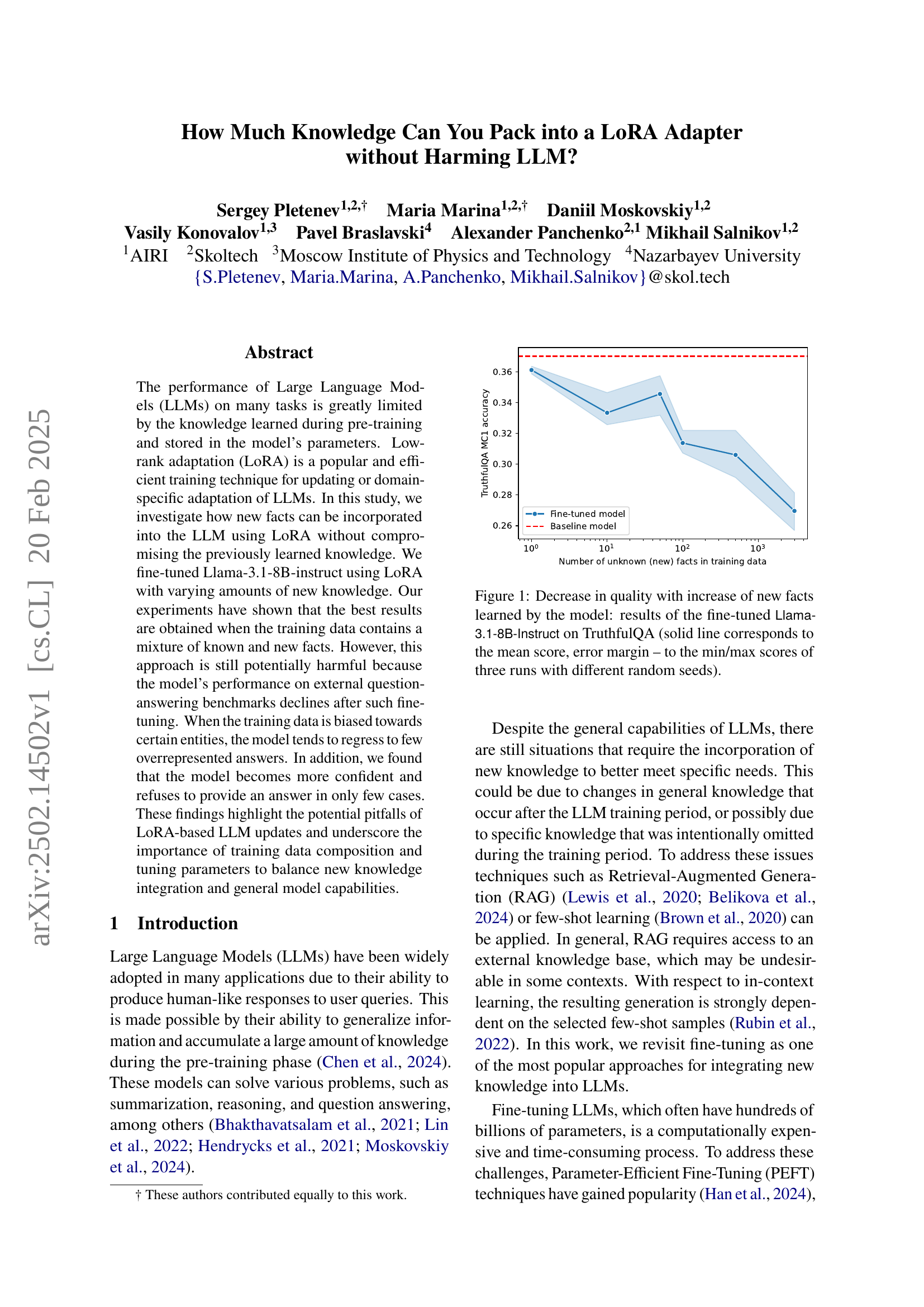
🔼 This figure displays the performance of a fine-tuned Llama-3.1-8B-Instruct language model on the TruthfulQA benchmark as the amount of new knowledge incorporated during training increases. The solid line represents the average accuracy across three independent trials (with different random seeds), and the shaded area shows the range (minimum to maximum) of those accuracy scores. The x-axis indicates the number of ‘unknown’ facts (facts not present in the model’s pre-training data) added to the training set. The y-axis shows the accuracy on the TruthfulQA benchmark. The results illustrate a negative correlation: As more new facts are added, the model’s accuracy on TruthfulQA tends to decrease.
read the caption
Figure 1: Decrease in quality with increase of new facts learned by the model: results of the fine-tuned Llama-3.1-8B-Instruct on TruthfulQA (solid line corresponds to the mean score, error margin – to the min/max scores of three runs with different random seeds).
| Category | Definition | Explanation | # Facts |
|---|---|---|---|
| Unknown (UK) | LLM never returns the correct answer | 14,373 | |
| MaybeKnown (MK) | LLM returns the correct answer occasionally | 3,931 | |
| HighlyKnown (HK) | LLM always returns the correct answer | 2,732 |
🔼 This table categorizes knowledge facts based on a language model’s ability to generate correct answers. The probability of the model giving the correct answer is assessed using various few-shot prompts. Three categories are defined: HighlyKnown (always predicts correctly), MaybeKnown (sometimes predicts correctly), and Unknown (never predicts correctly). The table also provides the count of facts within each category.
read the caption
Table 1: Fact categories based on the probability of providing the correct answer to a corresponding question and number of fact (q,a)𝑞𝑎(q,a)( italic_q , italic_a ) from each category.
In-depth insights#
LoRA’s Limits#
LoRA’s limits stem from its design. While efficient, it only adjusts a fraction of the parameters, potentially capping the model’s capacity to absorb new knowledge without disrupting existing capabilities. The trade-off between accuracy, recall and hallucination must be considered in designing LoRA for knowledge integration. Integrating new information requires a careful balance to maintain the model’s reasoning abilities. As shown in the study TruthfulQA, and MMLU, these methods do not provide any help to LoRA to perform well. Therefore, the composition of training data is necessary when using LoRA.
Known Fact Bias#
Known fact bias in language models arises when models disproportionately favor information they already possess during pre-training, hindering the integration of new knowledge. This bias manifests as a resistance to learning novel facts or a tendency to distort new information to align with existing beliefs. Fine-tuning on imbalanced datasets exacerbates this, leading to models that excel at recalling known facts but struggle with generalization and adaptation. Mitigating this bias requires careful data curation, favoring datasets with diverse and novel information, and employing techniques like contrastive learning to encourage the model to distinguish between known and unknown facts. Further research on knowledge attribution within models could reveal the mechanisms underlying this bias and inform more effective mitigation strategies, promoting more robust and adaptive language models.
Paraphrase Impact#
Paraphrasing enhances knowledge integration: Augmenting training data with paraphrased versions of unknown facts improves the LLM’s ability to learn and retain new information. Convergence and reliability: Models trained with paraphrased data converge faster during fine-tuning and achieve higher reliability scores, indicating better learning of new knowledge. Structural understanding: Paraphrasing helps the model grasp the ‘inner structure’ of knowledge rather than just memorizing simple sentences, leading to more robust knowledge representation. Mitigation of forgetting: By exposing the model to different phrasings of the same information, paraphrasing reduces the risk of catastrophic forgetting of previously known facts.
Knowledge Tradeoff#
The “knowledge tradeoff” in LLMs adapted with LoRA highlights a critical balance: integrating new facts without impairing existing knowledge. Fine-tuning can degrade pre-existing knowledge if not carefully managed. Experiments reveal that combining known and new facts during training yields optimal results, but carries the risk of diminished performance on general knowledge benchmarks. The model may regress to overrepresented answers when training data is biased, and interestingly, confidence increases, leading to more refusals to answer. It indicates a complex interplay between new information assimilation and maintaining prior knowledge and abilities. The trade-off underscores the need for careful training data design and parameter adjustment to ensure new knowledge integration enhances, rather than harms, the overall model capabilities. In short, the efficient packing of knowledge is not only about adding new information but also about preserving the utility and reliability of existing knowledge.
Over-Confidence#
The paper touches upon the important issue of model overconfidence, noting that LLMs fine-tuned with LoRA adapters demonstrate a reduction in their ability to express uncertainty. Specifically, the research highlights that LoRA-adapted LLMs become less likely to admit when they don’t know an answer. This has serious implications, as the model may start giving statistically overrepresented answers. Essentially, the fine-tuning process, while aiming to improve knowledge integration, can inadvertently lead to decreased reliability in the LLM’s self-assessment of its knowledge boundaries. Thus, it’s not simply about adding new facts, but ensuring that the model maintains its capacity to appropriately express doubt when faced with questions outside its knowledge base. The observed overconfidence emphasizes the need for careful calibration techniques during or after fine-tuning to ensure the model remains both knowledgeable and realistically self-aware.
More visual insights#
More on figures

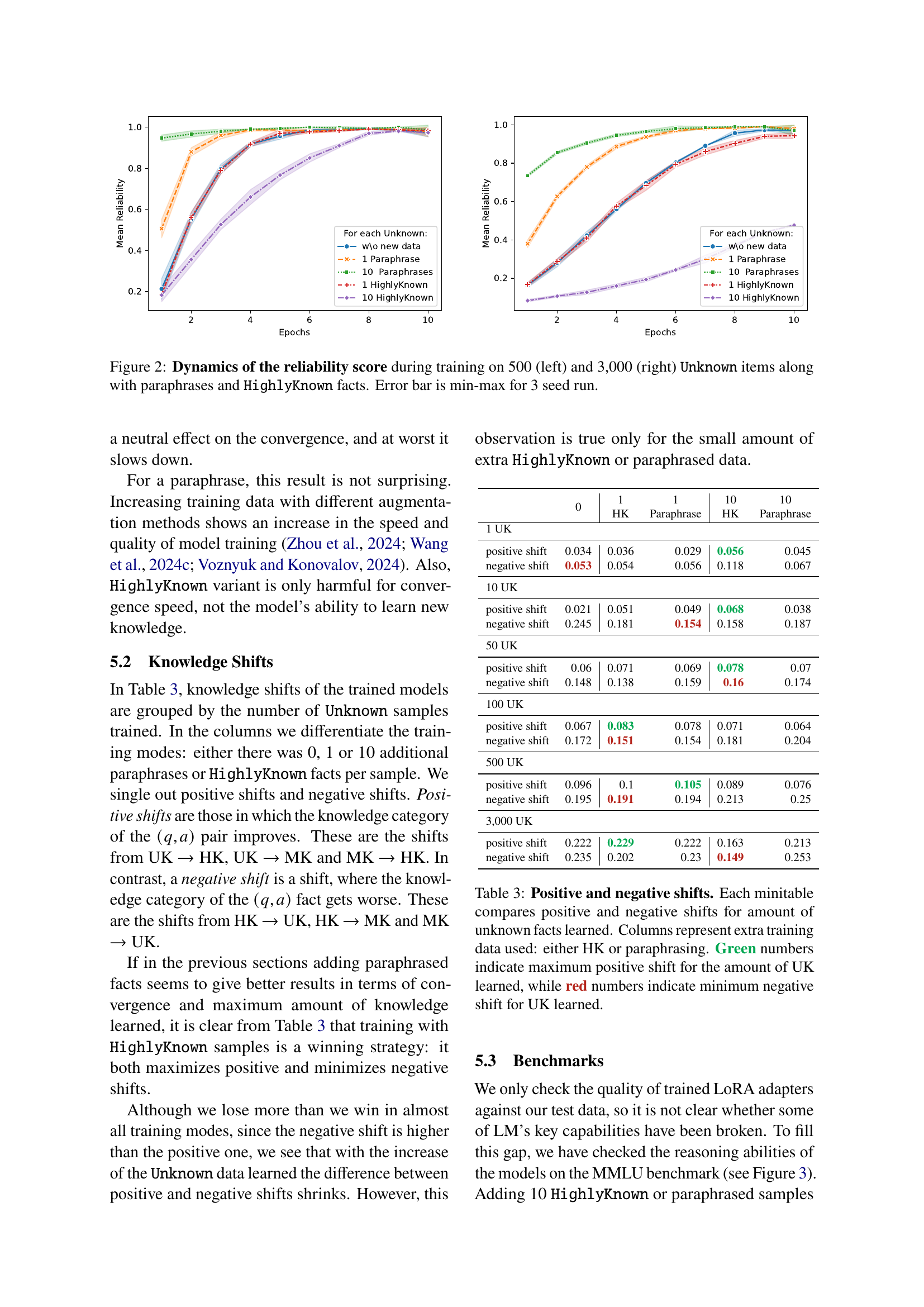
🔼 This figure displays the reliability scores across multiple training epochs for two different datasets (500 and 3000 Unknown items) while incorporating paraphrased and HighlyKnown facts. The reliability metric reflects the model’s ability to consistently generate correct answers, illustrating the impact of additional training data on model performance. Separate lines represent different training approaches (using 0, 1, or 10 paraphrases or HighlyKnown facts per unknown item). The min-max error bars shown for each data point reflect variability across three independent training runs, suggesting the consistency of results.
read the caption
Figure 2: Dynamics of the reliability score during training on 500 (left) and 3,000 (right) Unknown items along with paraphrases and HighlyKnown facts. Error bar is min-max for 3 seed run.

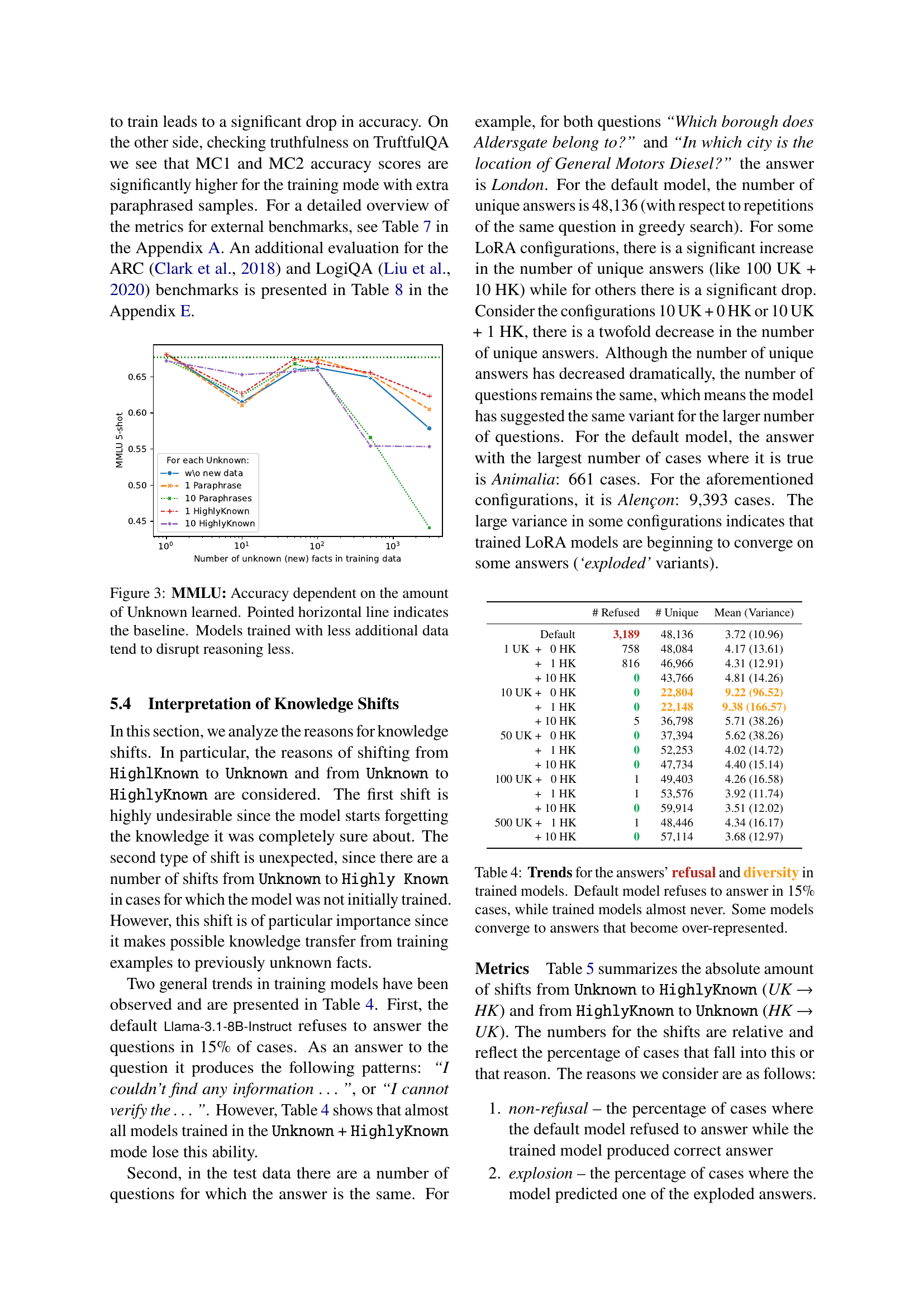
🔼 This figure displays the performance of the fine-tuned Llama-3.1-8B-Instruct model on the MMLU (Massive Multitask Language Understanding) benchmark as a function of the amount of new, previously unknown knowledge introduced during the fine-tuning process using LoRA (Low-Rank Adaptation). The x-axis represents the number of ‘Unknown’ facts added to the training dataset. The y-axis shows the accuracy achieved on the MMLU benchmark. A horizontal line represents the baseline accuracy of the original, untrained model. The graph illustrates that increasing the amount of new knowledge initially improves the model’s performance on MMLU; however, beyond a certain point, adding more new facts leads to a decrease in accuracy, indicating that integrating too much novel information into the model via LoRA can negatively affect its overall reasoning abilities. The results suggest a trade-off between incorporating new knowledge and maintaining the model’s general capabilities. Less additional data during training leads to less disruption in reasoning.
read the caption
Figure 3: MMLU: Accuracy dependent on the amount of Unknown learned. Pointed horizontal line indicates the baseline. Models trained with less additional data tend to disrupt reasoning less.
More on tables
| Highly Known | Paraphrase | |||||
|---|---|---|---|---|---|---|
| UK | 0 | 1 | 10 | 0 | 1 | 10 |
| 1 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 10 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 50 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 100 | 0.98 | 1.0 | 1.0 | 0.98 | 0.99 | 1.0 |
| 500 | 1.0 | 0.99 | 0.97 | 1.0 | 0.99 | 1.0 |
| 3,000 | 0.98 | 0.92 | 0.48 | 0.98 | 0.97 | 0.99 |
🔼 This table presents the reliability scores achieved by LoRA models trained on different combinations of HighlyKnown and paraphrased facts. The reliability score represents the model’s ability to consistently predict correct answers for unknown facts (UK) after fine-tuning. The results show that the model learns almost all UK facts effectively when trained using paraphrased data. However, when incorporating HighlyKnown (HK) facts, alongside the 3,000 UK facts, the reliability significantly decreases, indicating a negative impact of this training approach on the model’s ability to learn and retain new knowledge.
read the caption
Table 2: Reliability on test for models trained on HighlyKnown and Paraphrase. Almost all UK facts are learned except for 3,000 UK trained with HK.
| 0 |
|
|
|
| |||||||||
| 1 UK | |||||||||||||
| positive shift | 0.034 | 0.036 | 0.029 | 0.056 | 0.045 | ||||||||
| negative shift | 0.053 | 0.054 | 0.056 | 0.118 | 0.067 | ||||||||
| 10 UK | |||||||||||||
| positive shift | 0.021 | 0.051 | 0.049 | 0.068 | 0.038 | ||||||||
| negative shift | 0.245 | 0.181 | 0.154 | 0.158 | 0.187 | ||||||||
| 50 UK | |||||||||||||
| positive shift | 0.06 | 0.071 | 0.069 | 0.078 | 0.07 | ||||||||
| negative shift | 0.148 | 0.138 | 0.159 | 0.16 | 0.174 | ||||||||
| 100 UK | |||||||||||||
| positive shift | 0.067 | 0.083 | 0.078 | 0.071 | 0.064 | ||||||||
| negative shift | 0.172 | 0.151 | 0.154 | 0.181 | 0.204 | ||||||||
| 500 UK | |||||||||||||
| positive shift | 0.096 | 0.1 | 0.105 | 0.089 | 0.076 | ||||||||
| negative shift | 0.195 | 0.191 | 0.194 | 0.213 | 0.25 | ||||||||
| 3,000 UK | |||||||||||||
| positive shift | 0.222 | 0.229 | 0.222 | 0.163 | 0.213 | ||||||||
| negative shift | 0.235 | 0.202 | 0.23 | 0.149 | 0.253 | ||||||||
🔼 This table presents the results of experiments evaluating the impact of adding new knowledge to a language model using Low-Rank Adaptation (LoRA). It shows the number of positive and negative knowledge shifts observed for different amounts of unknown facts included in the training data, categorized by training methods (with and without additional paraphrased or HighlyKnown facts). Positive shifts represent cases where the model improves its knowledge (e.g., correctly answering a question it previously couldn’t), while negative shifts indicate knowledge degradation (e.g., starting to answer questions incorrectly). The table helps to analyze the effectiveness of different LoRA fine-tuning strategies in balancing new knowledge integration with retention of existing knowledge.
read the caption
Table 3: Positive and negative shifts. Each minitable compares positive and negative shifts for amount of unknown facts learned. Columns represent extra training data used: either HK or paraphrasing. Green numbers indicate maximum positive shift for the amount of UK learned, while red numbers indicate minimum negative shift for UK learned.
| 1 |
| HK |
🔼 Table 4 analyzes the impact of fine-tuning LLMs using LoRA on two key aspects of model behavior: the tendency to refuse answering questions and the diversity of responses provided. The default, untuned Llama-3.1-8B-Instruct model is observed to refuse to answer approximately 15% of questions. The table reveals that fine-tuning with LoRA significantly reduces this refusal rate across various training configurations (different numbers of Unknown facts and added HighlyKnown or paraphrased facts). However, some fine-tuned models exhibit a phenomenon of convergence toward a limited set of responses, resulting in less response diversity. The table provides a detailed breakdown of the number of unique answers and the number of times the model refused to answer for each configuration.
read the caption
Table 4: Trends for the answers’ refusal and diversity in trained models. Default model refuses to answer in 15% cases, while trained models almost never. Some models converge to answers that become over-represented.
| 1 |
| Paraphrase |
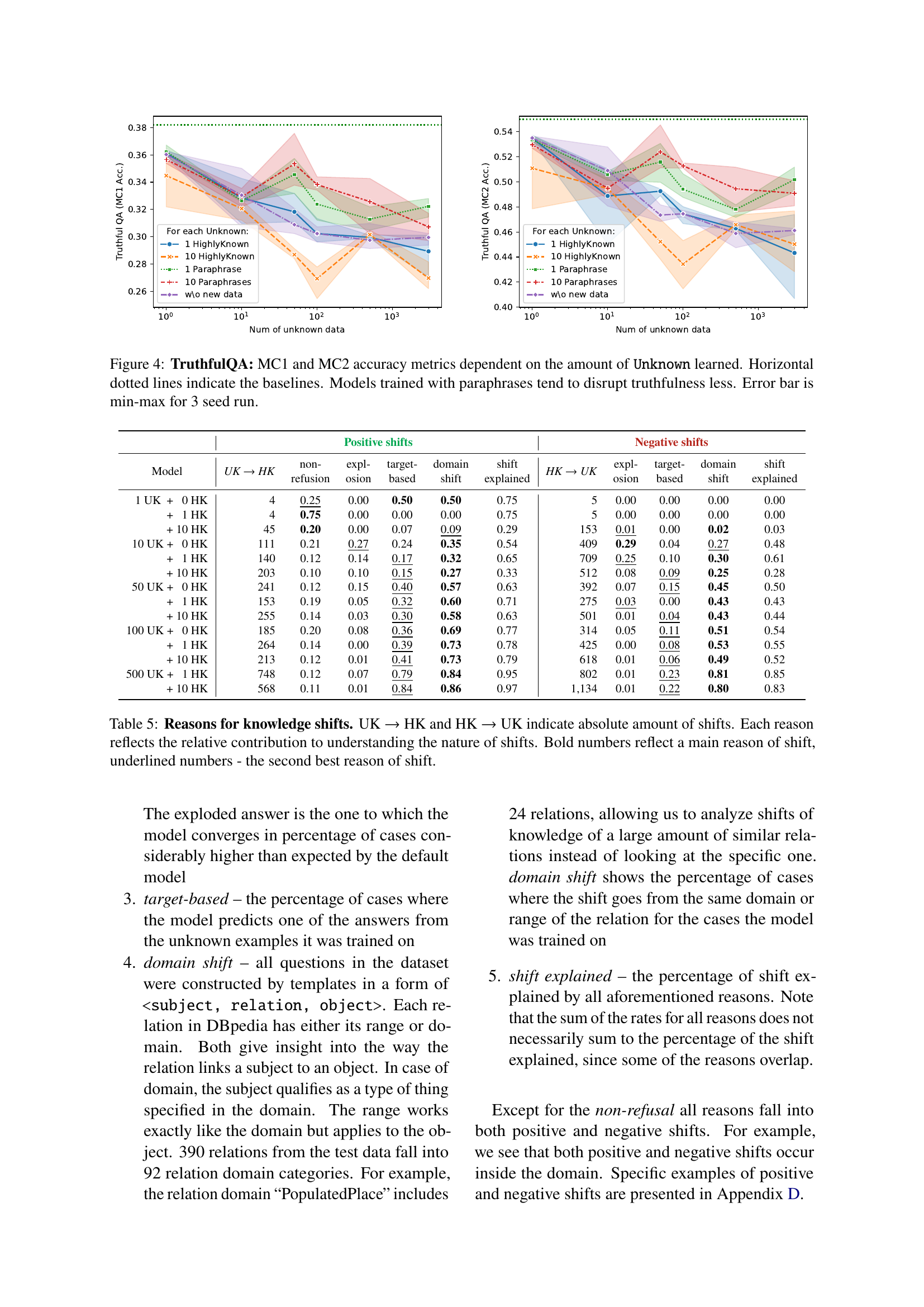
🔼 This table analyzes the reasons behind knowledge shifts observed during the fine-tuning of a language model. It shows the absolute counts of shifts from Unknown to HighlyKnown (new knowledge learned) and from HighlyKnown to Unknown (existing knowledge lost), breaking down each shift type into contributing factors. The factors include: the model refusing to answer (non-refusal); the model producing over-represented answers (explosion); the model transferring knowledge from the same domain or entity range (domain-based shifts); and the portion of a shift that is unexplained by these three factors. Bold numbers indicate the most significant contributing factor for each shift type, while underlined numbers represent the second most significant factor.
read the caption
Table 5: Reasons for knowledge shifts. UK →→\to→ HK and HK →→\to→ UK indicate absolute amount of shifts. Each reason reflects the relative contribution to understanding the nature of shifts. Bold numbers reflect a main reason of shift, underlined numbers - the second best reason of shift.
| 10 |
| HK |
🔼 This table presents the accuracy shift results for the Mistral-7B-Instruct-v0.3 model. It shows the positive and negative accuracy shifts observed when incorporating different amounts of new knowledge into the model using various configurations of paraphrased and HighlyKnown data. The configurations involve adding 1 or 10 paraphrased examples or 1 or 10 HighlyKnown examples along with 1 Unknown example to the training data. The values represent the change in accuracy after the fine-tuning process.
read the caption
Table 6: Accuracy shift for Mistral-7B-Instruct-v0.3.
| 10 |
| Paraphrase |
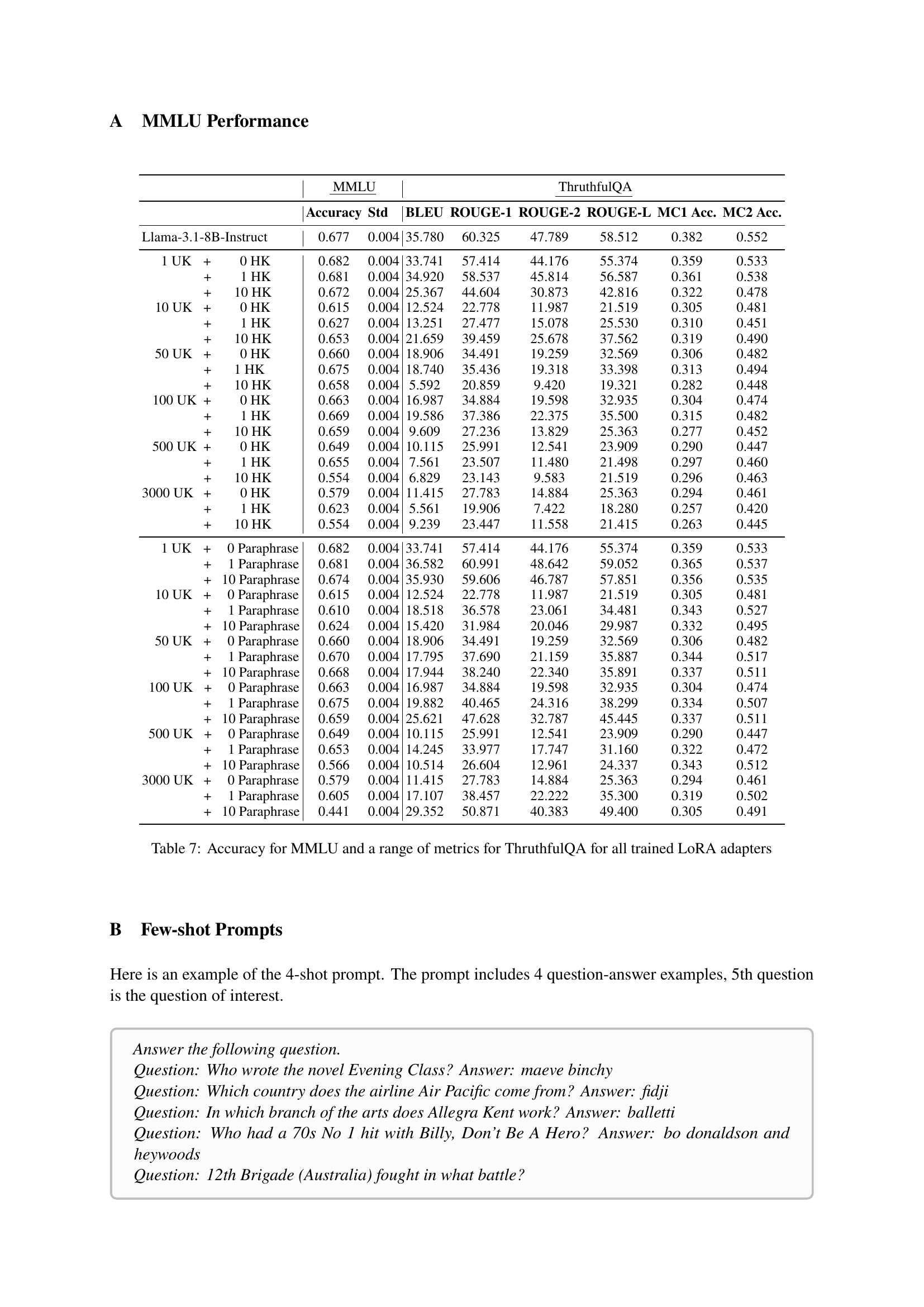
🔼 This table presents the performance of various LoRA-adapted LLMs on two benchmark datasets: MMLU (Massive Multitask Language Understanding) and TruthfulQA. For MMLU, the accuracy is reported. For TruthfulQA, multiple metrics are provided, including accuracy scores for both multiple choice question types (MC1 and MC2). The table allows for a comparison of different LoRA training configurations (varying numbers of unknown facts and the addition of paraphrases or highly-known facts during training). It demonstrates the impact of different training methods and data augmentation strategies on the models’ performance across multiple dimensions of reasoning ability and factual accuracy.
read the caption
Table 7: Accuracy for MMLU and a range of metrics for ThruthfulQA for all trained LoRA adapters
| # Refused | # Unique | Mean (Variance) | |
|---|---|---|---|
| Default | 3,189 | 48,136 | 3.72 (10.96) |
| 1 UK + 0 HK | 758 | 48,084 | 4.17 (13.61) |
| + 1 HK | 816 | 46,966 | 4.31 (12.91) |
| + 10 HK | 0 | 43,766 | 4.81 (14.26) |
| 10 UK + 0 HK | 0 | 22,804 | 9.22 (96.52) |
| + 1 HK | 0 | 22,148 | 9.38 (166.57) |
| + 10 HK | 5 | 36,798 | 5.71 (38.26) |
| 50 UK + 0 HK | 0 | 37,394 | 5.62 (38.26) |
| + 1 HK | 0 | 52,253 | 4.02 (14.72) |
| + 10 HK | 0 | 47,734 | 4.40 (15.14) |
| 100 UK + 0 HK | 1 | 49,403 | 4.26 (16.58) |
| + 1 HK | 1 | 53,576 | 3.92 (11.74) |
| + 10 HK | 0 | 59,914 | 3.51 (12.02) |
| 500 UK + 1 HK | 1 | 48,446 | 4.34 (16.17) |
| + 10 HK | 0 | 57,114 | 3.68 (12.97) |
🔼 This table presents the performance metrics of several LoRA adapters on two question answering benchmarks: ARC and LogiQA. The adapters were fine-tuned using different configurations, varying the number of unknown facts and the type of additional training data (paraphrases or highly known facts). The results show the accuracy scores across different subsets of ARC and LogiQA datasets, providing a comprehensive evaluation of the adapters’ performance.
read the caption
Table 8: Metrics for ARC and LogiQA benchmarks for trained LoRA adapters
Full paper#