TL;DR#
Existing LLM-based recommender systems often rely solely on purchase histories. This approach overlooks valuable user-generated textual data such as reviews and product descriptions, which could significantly enhance recommendation accuracy and personalization. Handling and processing the increasing amount of textual data from users to longer recommendation sessions and LLM memory constraints are key challenges.
To address these issues, PURE systematically extracts user preferences, dislikes, and key features from user reviews, integrating them into structured user profiles. PURE optimizes LLM memory management, and experimental results on Amazon datasets demonstrate that PURE outperforms existing methods.
Key Takeaways#
Why does it matter?#
This paper introduces an innovative LLM-based recommendation system. It addresses the critical need for effectively managing and leveraging user-generated textual data to enhance recommendation accuracy and personalization. The method will have a substantial impact on how recommender systems are designed and implemented in real-world applications. Also, it provides a valuable benchmark and reference point for future research in LLM-enhanced recommendation systems. It advances the field by offering a practical solution that balances performance and scalability.
Visual Insights#

🔼 PURE (Profile Update for REcommender) is a novel LLM-based recommendation framework. Unlike traditional LLM recommenders that only use purchase history, PURE incorporates user reviews and ratings to build more comprehensive user profiles. The figure illustrates PURE’s three key components: a Review Extractor that processes reviews to extract user preferences, dislikes, and key product features; a Profile Updater that refines and updates the user profile, resolving redundancies and conflicts; and a Recommender that generates personalized recommendations based on the enriched user profile. This approach mitigates the scalability challenges (large input token sizes) associated with processing extensive user data by systematically extracting and summarizing key information.
read the caption
Figure 1: Overall system of PURE. PURE incorporates reviews, ratings, and item interactions, whereas LLM Recommender handles only item interactions. By using the 'Review Extractor' to identify key information and the 'Profile Updater' to refine the user profile, PURE addresses scalability issue (i.e., growth of input token size).
| Games | Movies | ||||||||
| Data | Method | N@1 | N@5 | N@10 | N@20 | N@1 | N@5 | N@10 | N@20 |
| items | Sequential | 10.75 | 18.25 | 23.13 | 28.97 | 9.99 | 15.92 | 20.17 | 26.94 |
| Recency | 15.34 | 24.31 | 28.82 | 34.24 | 12.17 | 17.75 | 22.18 | 28.19 | |
| ICL | 14.28 | 26.57 | 30.51 | 35.72 | 12.03 | 19.56 | 23.36 | 29.91 | |
| items + reviews | Sequential† | 11.14 | 19.95 | 24.97 | 32.00 | 8.05 | 13.11 | 17.72 | 25.57 |
| Recency† | 12.19 | 23.64 | 28.37 | 35.35 | 8.54 | 15.78 | 21.31 | 29.21 | |
| ICL† | 15.11 | 26.34 | 31.25 | 37.39 | 12.24 | 22.10 | 27.31 | 34.52 | |
| PURE (Sequential) | 15.06 | 25.71 | 31.08 | 38.28 | 12.59 | 21.33 | 25.96 | 32.21 | |
| PURE (Recency) | 18.18 | 28.90 | 33.91 | 40.69 | 13.85 | 21.99 | 26.53 | 33.37 | |
| PURE (ICL) | 16.62 | 29.81 | 35.60 | 42.00 | 15.80 | 26.32 | 32.03 | 38.93 | |
🔼 This table compares the performance of the proposed PURE model against several baseline models on two Amazon datasets (Video Games and Movies & TV). The comparison is made under two conditions: using only purchase history (item interactions) and using both purchase history and user reviews. The baseline models are adapted to utilize reviews in a naive way (indicated by †), allowing for a direct comparison of how effectively PURE integrates review data. The metrics used to evaluate performance are NDCG@k (k=1, 5, 10, 20), indicating the ranking accuracy of recommendations.
read the caption
Table 1: Comparison PURE with Baselines. We evaluate performance under two data settings: using only item interactions and using item interactions augmented with reviews. ††\dagger† indicates customized baselines where review data is naively incorporated into the original prompt templates designed for item interactions only (see Sec. C.2).
In-depth insights#
LLM User Profile#
LLM-based user profiling is an interesting area, especially with the recent trends. User profiles managed by LLMs can adapt and incorporate diverse data sources, such as user reviews and purchase histories, to provide a richer representation compared to traditional methods. The capability of LLMs to extract and summarize information from textual data can allow the creation of dynamic and evolving user profiles, reflecting changing preferences. Managing token limits and preventing redundancy are key challenges. Efficient summarization and information extraction are important for long-term user modeling. By capturing the nuances of user preferences, the recommender system can become more reliable. Furthermore, the risk of hallucination is a significant problem to address.
Review Extraction#
Review extraction is a vital module as it identifies user preferences & key product features from reviews using LLMs. The review data often contains noise that can be removed to improve data quality, which in turn enhance recommender performance. By analyzing the review text for sentiments & keywords, a deeper understanding of the user’s inclinations can be obtained. Key to this process is prompt engineering, which greatly affects performance and should be chosen wisely. Effective review extraction requires careful consideration of what aspects the LLM should focus on.
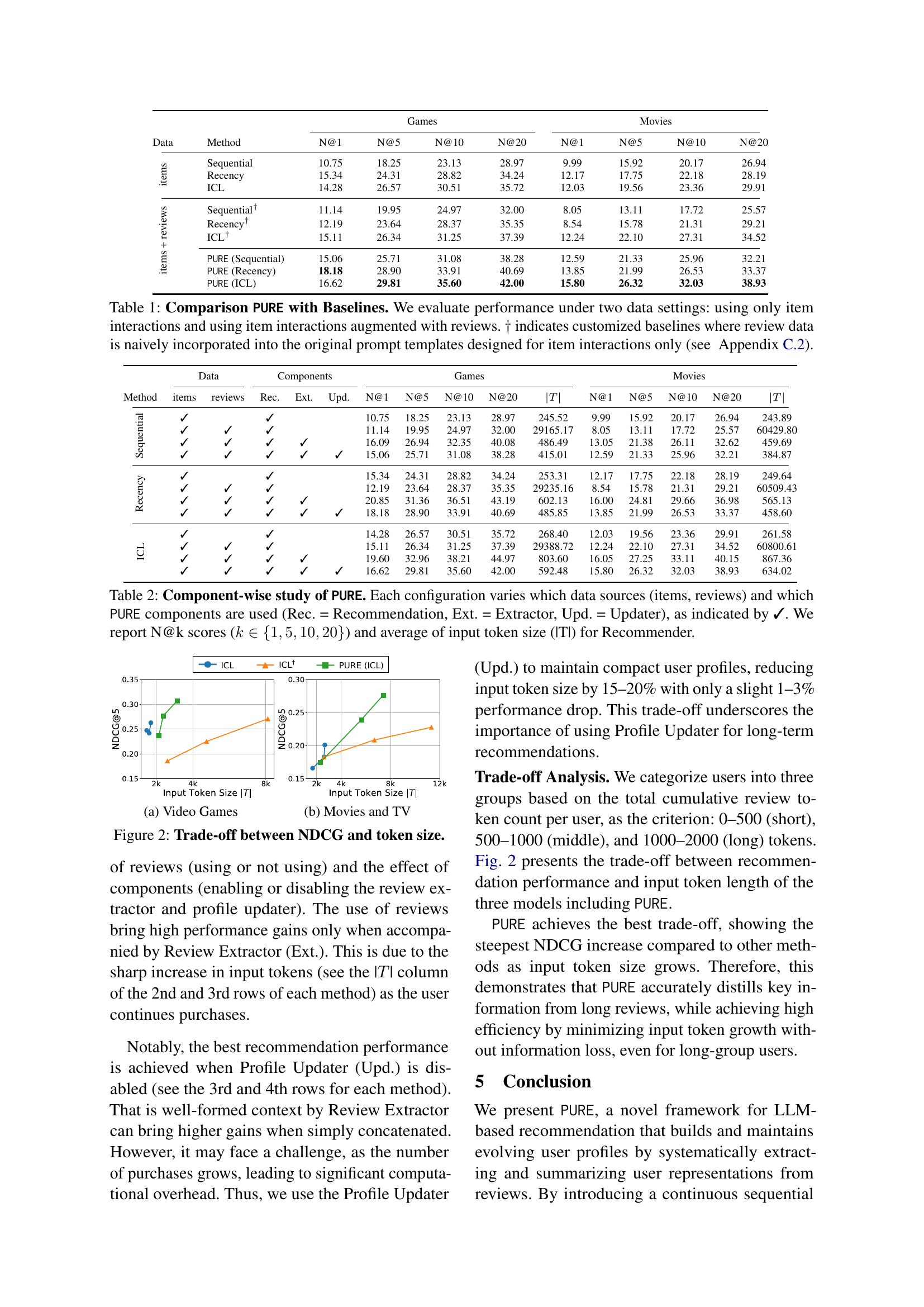
Profile Updating#
Profile updating is a critical aspect of building robust LLM-driven recommendation systems. Efficiently refining user profiles with new data while managing token limits presents challenges. A key component of profile updating involves removing redundant or conflicting information to maintain a compact and coherent representation. Efficiently managing profile updating will contribute to a scalable system, where user profiles can evolve over time without exceeding token limits. The profile updating also ensures that the recommendation engine has access to the most relevant and up-to-date information. Therefore, an effective profile updating strategy is vital for generating accurate recommendations.
Continuous Rec#
Continuous recommendation embodies a multi-step prediction task, iteratively predicting items at each step, unlike one-shot approaches. This captures temporal dependencies and user preference evolution more realistically. By updating interaction history at each step, models can adapt to changing user needs and provide more relevant suggestions. This approach more closely mirrors real-world scenarios. This enables continuous updates, making recs more aligned. Models predict next items from a candidate set, effectively capturing the user’s evolving tastes, desires and ensuring the recommendations reflect their current needs.
Token Efficiency#
Token efficiency is vital in LLM-based systems. With limited context windows, managing token usage optimizes performance. The paper likely explores methods to reduce tokens without losing crucial data. Summarization techniques, like abstractive or extractive methods on user reviews, could be employed. Another approach is feature selection, focusing on the most relevant aspects of reviews. Efficient prompt engineering is also key, crafting concise prompts that elicit desired responses with fewer tokens. The paper’s exploration of these strategies reveals how long-term user information can be retained while staying within token limits, enhancing the scalability and practicality of LLM-driven recommendation systems. PURE’s architecture seems designed to maintain a compact user profile, essential for token-efficient personalization.
More visual insights#
More on tables
| Data | Components | Games | Movies | ||||||||||||
| Method | items | reviews | Rec. | Ext. | Upd. | N@1 | N@5 | N@10 | N@20 | N@1 | N@5 | N@10 | N@20 | ||
| Sequential | ✓ | ✓ | 10.75 | 18.25 | 23.13 | 28.97 | 245.52 | 9.99 | 15.92 | 20.17 | 26.94 | 243.89 | |||
| ✓ | ✓ | ✓ | 11.14 | 19.95 | 24.97 | 32.00 | 29165.17 | 8.05 | 13.11 | 17.72 | 25.57 | 60429.80 | |||
| ✓ | ✓ | ✓ | ✓ | 16.09 | 26.94 | 32.35 | 40.08 | 486.49 | 13.05 | 21.38 | 26.11 | 32.62 | 459.69 | ||
| ✓ | ✓ | ✓ | ✓ | ✓ | 15.06 | 25.71 | 31.08 | 38.28 | 415.01 | 12.59 | 21.33 | 25.96 | 32.21 | 384.87 | |
| Recency | ✓ | ✓ | 15.34 | 24.31 | 28.82 | 34.24 | 253.31 | 12.17 | 17.75 | 22.18 | 28.19 | 249.64 | |||
| ✓ | ✓ | ✓ | 12.19 | 23.64 | 28.37 | 35.35 | 29235.16 | 8.54 | 15.78 | 21.31 | 29.21 | 60509.43 | |||
| ✓ | ✓ | ✓ | ✓ | 20.85 | 31.36 | 36.51 | 43.19 | 602.13 | 16.00 | 24.81 | 29.66 | 36.98 | 565.13 | ||
| ✓ | ✓ | ✓ | ✓ | ✓ | 18.18 | 28.90 | 33.91 | 40.69 | 485.85 | 13.85 | 21.99 | 26.53 | 33.37 | 458.60 | |
| ICL | ✓ | ✓ | 14.28 | 26.57 | 30.51 | 35.72 | 268.40 | 12.03 | 19.56 | 23.36 | 29.91 | 261.58 | |||
| ✓ | ✓ | ✓ | 15.11 | 26.34 | 31.25 | 37.39 | 29388.72 | 12.24 | 22.10 | 27.31 | 34.52 | 60800.61 | |||
| ✓ | ✓ | ✓ | ✓ | 19.60 | 32.96 | 38.21 | 44.97 | 803.60 | 16.05 | 27.25 | 33.11 | 40.15 | 867.36 | ||
| ✓ | ✓ | ✓ | ✓ | ✓ | 16.62 | 29.81 | 35.60 | 42.00 | 592.48 | 15.80 | 26.32 | 32.03 | 38.93 | 634.02 | |
🔼 This table presents a component-wise analysis of the PURE model’s performance. It shows the impact of using different combinations of data sources (items only, items and reviews) and PURE components (Recommendation, Extractor, Updater) on the model’s recommendation accuracy, measured by N@k scores (where k represents the top-k recommended items and N@k represents the percentage of times the correct item is among the top k). The table also shows the average input token size used by the recommender for each configuration. A checkmark (✓) indicates which components and data sources were used in a particular configuration.
read the caption
Table 2: Component-wise study of PURE. Each configuration varies which data sources (items, reviews) and which PURE components are used (Rec. = Recommendation, Ext. = Extractor, Upd. = Updater), as indicated by ✓. We report N@k scores (k∈{1,5,10,20}𝑘151020k\in\{1,5,10,20\}italic_k ∈ { 1 , 5 , 10 , 20 }) and average of input token size (|T|) for Recommender.
| Method | Type | Contents |
| Baselines | Recommender Input | I’ve purchased the following products in chronological order: {user-item interactions & reviews} Then if I ask you to recommend a new product to me according to the given purchasing history, you should recommend {recent item} and now that I’ve just purchased {recent item}. There are 20 candidate products that I can consider to purchase next: {20 candidate items} Please rank these 20 products by measuring the possibilities that I would like to purchase next most, according to the given purchasing records. Please think step by step. Please show me your ranking results with order numbers. Split your output with line break. You MUST rank the given candidate product. You cannot generate products that are not in the given candidate list. No other description is needed. |
| Recommender Output | [20 ordered items] | |
| PURE (Ours) | Review Extractor Input | I purchased the following products in chronological order: {user-item interactions & reviews} Then if I ask you to recommend a new product to me according to the given purchasing history, you should recommend {recent item} and now I’ve just purchased {recent item}. And I left review: {recent item review} Your task is to analyze user’s purchasing behavior and extract user’s likes, dislikes and key features from the input review. Response only likes/dislikes/key features in descriptive form. Please prioritize the most recent item {recent item} when analyzing likes/dislikes/key features. Split likes, dislikes, and key features and response in same format. |
| Review Extractor Output | Likes: {[‘*Long gameplay experience(50-60 hours), *Responsive controls, *Fantastic storyline, *Challenging puzzles, Emotional resonance (e.g.remorse), *Ability to gain new posers by killing enemies’, ‘*Humor and fun in games, *References to the simpsons franchise, *Variety of playable characters (Marge, Lisa, Apu, Bart, and Homer), Ability to drive or walk depending on preference, *Great voice acting from the cast members, *Presence of key locations from the Simpsons universe (Kwik-E-Mart, Power Plant, Church, etc.), Cool vehicle designs and stats, *Fantastic game overall’]} Dislikes: {[‘*No pause time when selecting a weapon, making the player vulnerable, *Inventory management can be inconvenient, requiring the player to switch to the inventory screen to user gadgets’, ‘*Boring story, *Not funny, *Awful weapons, *Unresponsive controls, *Terrible graphics, *Worse gameplay’]} Key Features: {[‘*No in-game loading, *Fighting mechanics, *Soul-hunger gameplay mechanic, *Ability to cover up face to hide disfigured jaw’, ‘*New camera system (Devil May Cry position), *Redone fighting mechanics, Playable as both Raziel and Kain, *Puzzles with a challenging but fun diffculty level’]} | |
| Profile Updater Input | You are given a list: {list of likes/dislikes/key features} You have to update this list by removing redundant or overlapping information. Note that crucial information should be preserved. Please response only a list. No other description is needed. | |
| Profile Updater Output | Likes: {[‘*Long Gameplay experience (50-60 hours), *Challenging puzzles, *Emotional resonance (e.g.remorse), Ability to gain new powers by killing enemies’, ‘*Variety of playable characters, Ability to drive or walk depending on preference, *Presence of key locations from the Simpsons universe, *Great voice acting, *Cool vehicle designs and stats’]} Dislikes: {[‘*No pause time when selecting a weapon, making the player vulnerable, *Inventory management can be inconvenient’, ‘*Unresponsive controls, *Terrible graphics, *Worse gameplay’]} Key Features: {[‘*Fighting mechanics, *Soul-hunger gameplay mechanic, *Ability to cover up face’, ‘*New camera system, *Redone fighting mechanics, *Playable as both Raziel and Kain, *Puzzles’]} | |
| Recommender Input | This is positive aspects from purchase history: {[‘*Long Gameplay experience (50-60 hours), *Challenging puzzles, *Emotional resonance (e.g.remorse), Ability to gain new powers by killing enemies’, ‘*Variety of playable characters, Ability to drive or walk depending on preference, *Presence of key locations from the Simpsons universe, Great voice acting, *Cool vehicle designs and stats’]} This is negative aspects from purchase history: {[‘*No pause time when selecting a weapon, making the player vulnerable, Inventory management can be inconvenient’, ‘*Unresponsive controls, *Terrible graphics, *Worse gameplay’]} This is key features of products: {[‘*Fighting mechanics, *Soul-hunger gameplay mechanic, *Ability to cover up face’, ‘*New camera system, *Redone fighting mechanics, *Playable as both Raziel and Kain, *Puzzles’]} Based on these inputs, your task is to rank 20 candidate products by evaluating their likelihood of being purchased. Now there are 20 candidate products that I consider to purchase next. Note that there is no specific order for these candidate items. Please rank the {20 candidate items} from 1 to 20. Your task is to rank these products based on the likelihood of purchase. You cannot generate products that are not in the given candidate list. No other description is needed. | |
| Recommender Output | {[20 ordered items]} |
🔼 Table 3 presents a qualitative comparison of the input and output processes for baseline methods and the proposed PURE model in a sequential recommendation task. It highlights how PURE’s components (Review Extractor and Profile Updater) refine user input by removing redundant or irrelevant information. This leads to more concise and efficient input for the recommender, improving performance while managing token limitations. Green highlights show removed redundant information, and yellow highlights show summarized content for conciseness.
read the caption
Table 3: Qualitative Results: Baselines vs PURE. Note that green-highlighted boxes indicate portions removed due to redundancy or overlapping information, while yellow-highlighted boxes represent summarized content where unnecessary modifiers or examples were omitted for conciseness.
Full paper#