TL;DR#
Large Language Models (LLMs) struggle with tasks needing genuine visual spatial reasoning despite being good at language tasks. Current Vision-Language Models (VLMs) are good at recognizing patterns and objects, but have problems with deeper spatial thinking and planning. It’s a big step toward more flexible AI to close this gap and give LLMs strong visual thinking skills.
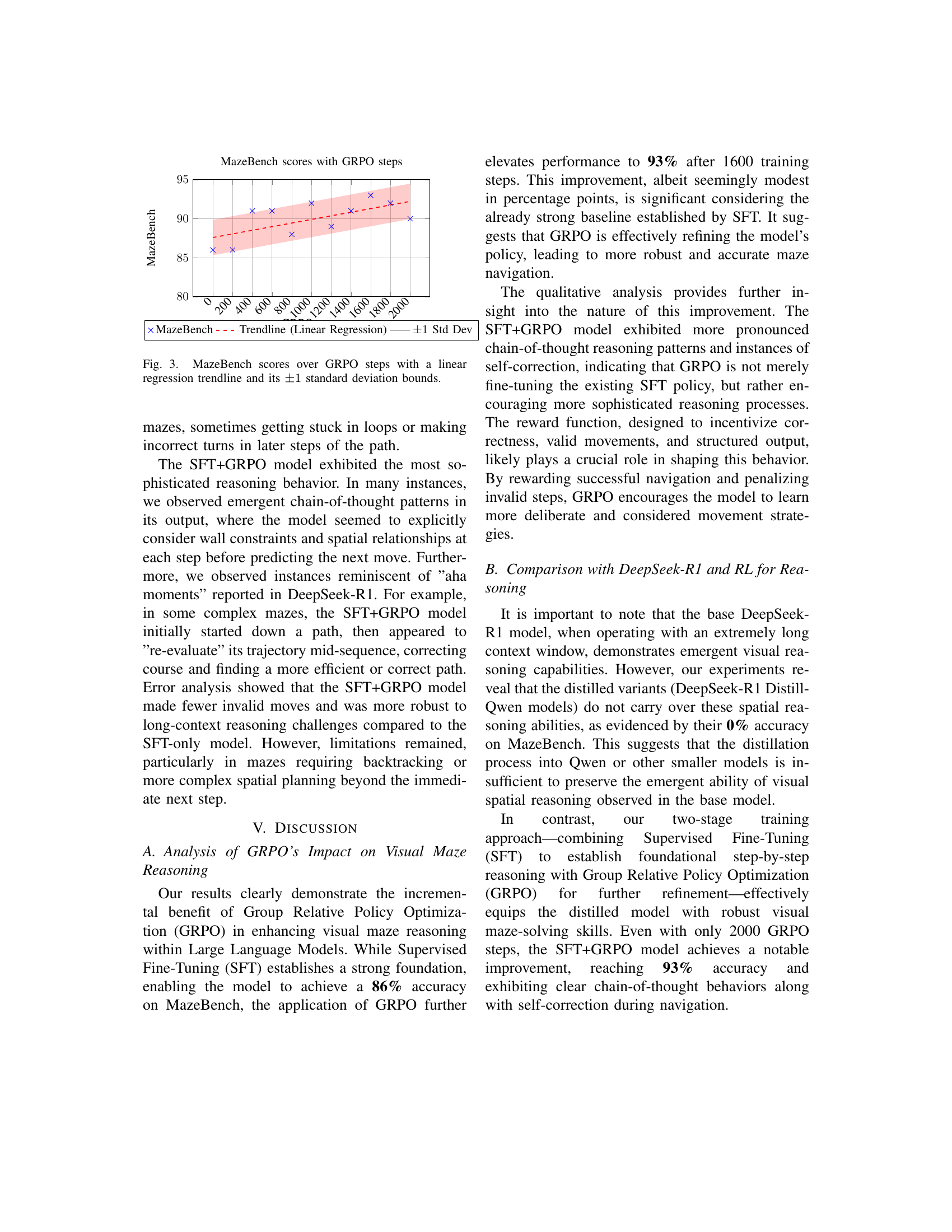
To address this, the paper introduces AlphaMaze, a new two-stage training method to give standard LLMs visual reasoning skills for maze navigation. The method uses Supervised Fine-Tuning (SFT) on tokenized mazes to teach movement commands, followed by Group Relative Policy Optimization (GRPO) with a special reward function to improve decision-making. The new MazeBench is introduced to evaluate maze-solving ability, while the experiments show big accuracy gains through GRPO.
Key Takeaways#
Why does it matter?#
This paper introduces a novel method of enhancing LLMs’ spatial reasoning, opening new avenues for AI applications in robotics and navigation. The work’s focus on combining SFT and GRPO could inspire more effective training strategies and promote further research.
Visual Insights#

🔼 This figure shows a simple example of a maze used in the AlphaMaze research. It is a small grid-based maze with a clear start (origin) and end (target) point. The walls of the maze are visually depicted, and the maze is designed to illustrate the tokenized representation used by the model to understand the maze’s structure.
read the caption
Figure 1: Visual of the Example Maze
| Model | SFT | GRPO | Score (%) |
|---|---|---|---|
| Baseline-1.5B | ✗ | ✗ | 0.0 |
| Baseline-7B | ✗ | ✗ | 0.0 |
| Baseline-1.5B (SFT) | ✓ | ✗ | 0.0 |
| AlphaMaze-SFT | ✓ | ✗ | 86.0 |
| AlphaMaze | ✓ | ✓ | 93.0 |
🔼 This table presents the quantitative results of the maze-solving performance of different models on the MazeBench benchmark. It shows the accuracy (in percentage) achieved by three baseline models and the proposed AlphaMaze model. The baseline models include a direct prediction model and two DeepSeek-R1-Distill-Qwen models with different parameter sizes (1.5B and 7B). AlphaMaze represents the performance of the model after applying Supervised Fine-Tuning (SFT) and Group Relative Policy Optimization (GRPO). The table highlights the impact of SFT and GRPO on improving maze-solving accuracy.
read the caption
TABLE I: Maze Solving Accuracy on MazeBench
Full paper#