TL;DR#
Existing models lack the breadth of improvements into a single model. Therefore, the paper introduces SigLIP 2, a family of new multilingual vision-language encoders that builds on the success of the original SigLIP. It extends the original image-text training objective with captioning-based pretraining, self-supervised losses, and online data curation. SigLIP 2 models outperform their SigLIP counterparts and the new training recipe leads to significant improvements on localization and dense prediction tasks.
SigLIP 2 models are backward compatible with SigLIP by relying on the same architecture. SigLIP 2 also includes a NaFlex variant, which supports multiple resolutions and preserves the native image aspect ratio. SigLIP 2 further optimizes performance of smaller models by using techniques in distillation via active data curation. The paper also shows the multilingual retrieval performance on Crossmodal-3600. Furthermore, SigLIP 2 achieves better performance than SigLIP on COCO and LVIS.
Key Takeaways#
Why does it matter?#
This paper is important for researchers because it introduces a new family of multilingual vision-language encoders with improved capabilities and broader cultural awareness. It provides a solid foundation for future VLMs, enhances cross-lingual applications, and offers insights into reducing biases, paving the way for more inclusive and accurate AI systems.
Visual Insights#

🔼 This figure illustrates the SigLIP 2 training recipe, which enhances the original SigLIP model by incorporating several techniques. It combines the original SigLIP’s sigmoid loss with additional methods: caption-based pretraining (LocCa), self-distillation and masked prediction (SILC and TIPS). The self-distillation and masked prediction are applied during the final 20% of training. Some SigLIP 2 variants also include fine-tuning with data curation or adaptation for handling images with native aspect ratios and variable sequence lengths.
read the caption
Figure 1: SigLIP 2 adds the captioning-based pretraining from LocCa [62] as well as self-distillation and masked prediction from SILC [45] and TIPS [38] (during the last 20% of training) to the sigmoid loss from SigLIP [71]. For some variants, the recipe additionally involves fine-tuning with data curation [61] or adaptation to native aspect ratio and variable sequence length [6, 12].
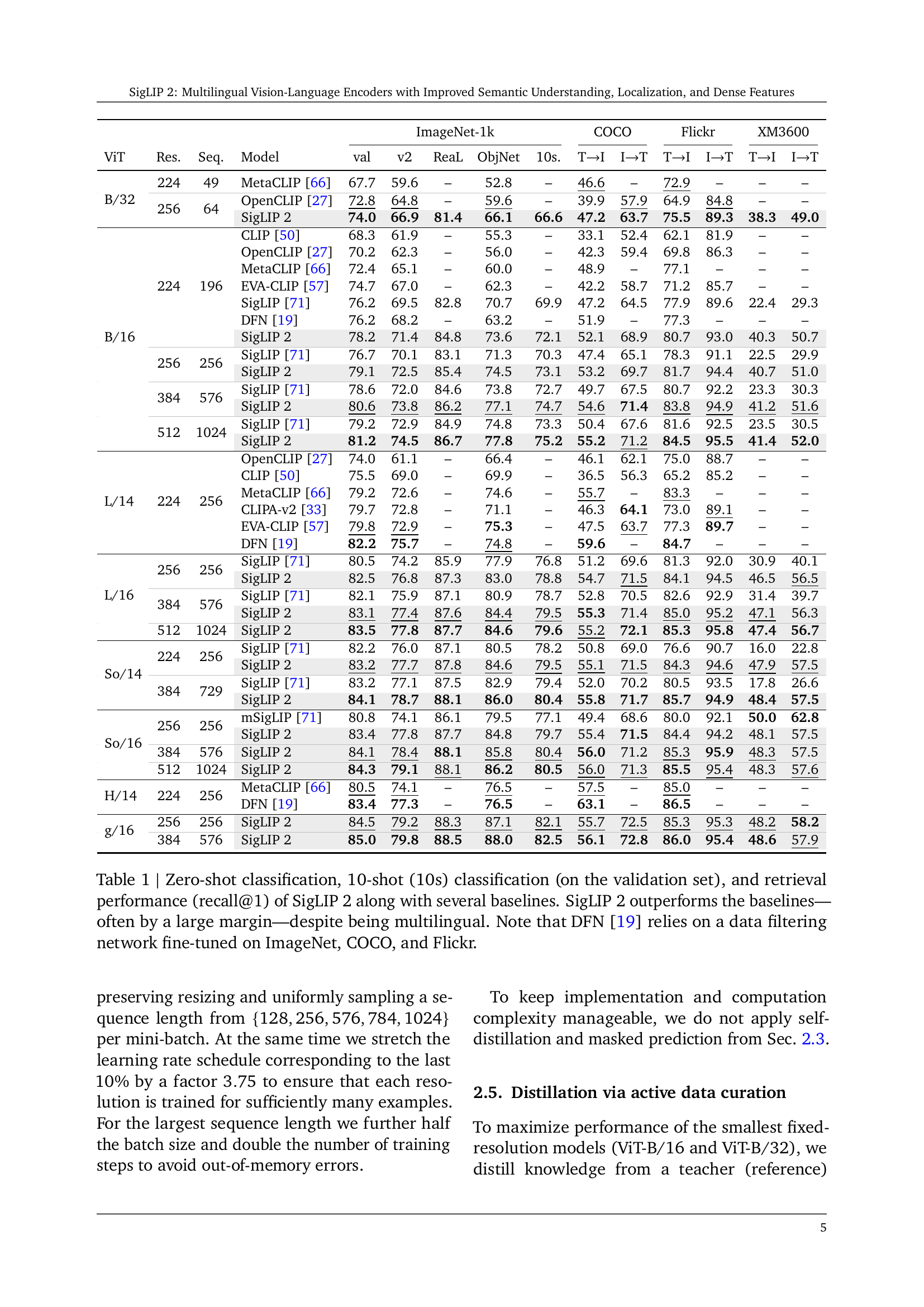
| ImageNet-1k | COCO | Flickr | XM3600 | |||||||||||
| ViT | Res. | Seq. | Model | val | v2 | ReaL | ObjNet | 10s. | TI | IT | TI | IT | TI | IT |
| B/32 | 224 | 49 | MetaCLIP [66] | 67.7 | 59.6 | – | 52.8 | – | 46.6 | – | 72.9 | – | – | – |
| 256 | 64 | OpenCLIP [27] | 72.8 | 64.8 | – | 59.6 | – | 39.9 | 57.9 | 64.9 | 84.8 | – | – | |
| SigLIP 2 | 74.0 | 66.9 | 81.4 | 66.1 | 66.6 | 47.2 | 63.7 | 75.5 | 89.3 | 38.3 | 49.0 | |||
| B/16 | 224 | 196 | CLIP [50] | 68.3 | 61.9 | – | 55.3 | – | 33.1 | 52.4 | 62.1 | 81.9 | – | – |
| OpenCLIP [27] | 70.2 | 62.3 | – | 56.0 | – | 42.3 | 59.4 | 69.8 | 86.3 | – | – | |||
| MetaCLIP [66] | 72.4 | 65.1 | – | 60.0 | – | 48.9 | – | 77.1 | – | – | – | |||
| EVA-CLIP [57] | 74.7 | 67.0 | – | 62.3 | – | 42.2 | 58.7 | 71.2 | 85.7 | – | – | |||
| SigLIP [71] | 76.2 | 69.5 | 82.8 | 70.7 | 69.9 | 47.2 | 64.5 | 77.9 | 89.6 | 22.4 | 29.3 | |||
| DFN [19] | 76.2 | 68.2 | – | 63.2 | – | 51.9 | – | 77.3 | – | – | – | |||
| SigLIP 2 | 78.2 | 71.4 | 84.8 | 73.6 | 72.1 | 52.1 | 68.9 | 80.7 | 93.0 | 40.3 | 50.7 | |||
| 256 | 256 | SigLIP [71] | 76.7 | 70.1 | 83.1 | 71.3 | 70.3 | 47.4 | 65.1 | 78.3 | 91.1 | 22.5 | 29.9 | |
| SigLIP 2 | 79.1 | 72.5 | 85.4 | 74.5 | 73.1 | 53.2 | 69.7 | 81.7 | 94.4 | 40.7 | 51.0 | |||
| 384 | 576 | SigLIP [71] | 78.6 | 72.0 | 84.6 | 73.8 | 72.7 | 49.7 | 67.5 | 80.7 | 92.2 | 23.3 | 30.3 | |
| SigLIP 2 | 80.6 | 73.8 | 86.2 | 77.1 | 74.7 | 54.6 | 71.4 | 83.8 | 94.9 | 41.2 | 51.6 | |||
| 512 | 1024 | SigLIP [71] | 79.2 | 72.9 | 84.9 | 74.8 | 73.3 | 50.4 | 67.6 | 81.6 | 92.5 | 23.5 | 30.5 | |
| SigLIP 2 | 81.2 | 74.5 | 86.7 | 77.8 | 75.2 | 55.2 | 71.2 | 84.5 | 95.5 | 41.4 | 52.0 | |||
| L/14 | 224 | 256 | OpenCLIP [27] | 74.0 | 61.1 | – | 66.4 | – | 46.1 | 62.1 | 75.0 | 88.7 | – | – |
| CLIP [50] | 75.5 | 69.0 | – | 69.9 | – | 36.5 | 56.3 | 65.2 | 85.2 | – | – | |||
| MetaCLIP [66] | 79.2 | 72.6 | – | 74.6 | – | 55.7 | – | 83.3 | – | – | – | |||
| CLIPA-v2 [33] | 79.7 | 72.8 | – | 71.1 | – | 46.3 | 64.1 | 73.0 | 89.1 | – | – | |||
| EVA-CLIP [57] | 79.8 | 72.9 | – | 75.3 | – | 47.5 | 63.7 | 77.3 | 89.7 | – | – | |||
| DFN [19] | 82.2 | 75.7 | – | 74.8 | – | 59.6 | – | 84.7 | – | – | – | |||
| L/16 | 256 | 256 | SigLIP [71] | 80.5 | 74.2 | 85.9 | 77.9 | 76.8 | 51.2 | 69.6 | 81.3 | 92.0 | 30.9 | 40.1 |
| SigLIP 2 | 82.5 | 76.8 | 87.3 | 83.0 | 78.8 | 54.7 | 71.5 | 84.1 | 94.5 | 46.5 | 56.5 | |||
| 384 | 576 | SigLIP [71] | 82.1 | 75.9 | 87.1 | 80.9 | 78.7 | 52.8 | 70.5 | 82.6 | 92.9 | 31.4 | 39.7 | |
| SigLIP 2 | 83.1 | 77.4 | 87.6 | 84.4 | 79.5 | 55.3 | 71.4 | 85.0 | 95.2 | 47.1 | 56.3 | |||
| 512 | 1024 | SigLIP 2 | 83.5 | 77.8 | 87.7 | 84.6 | 79.6 | 55.2 | 72.1 | 85.3 | 95.8 | 47.4 | 56.7 | |
| So/14 | 224 | 256 | SigLIP [71] | 82.2 | 76.0 | 87.1 | 80.5 | 78.2 | 50.8 | 69.0 | 76.6 | 90.7 | 16.0 | 22.8 |
| SigLIP 2 | 83.2 | 77.7 | 87.8 | 84.6 | 79.5 | 55.1 | 71.5 | 84.3 | 94.6 | 47.9 | 57.5 | |||
| 384 | 729 | SigLIP [71] | 83.2 | 77.1 | 87.5 | 82.9 | 79.4 | 52.0 | 70.2 | 80.5 | 93.5 | 17.8 | 26.6 | |
| SigLIP 2 | 84.1 | 78.7 | 88.1 | 86.0 | 80.4 | 55.8 | 71.7 | 85.7 | 94.9 | 48.4 | 57.5 | |||
| So/16 | 256 | 256 | mSigLIP [71] | 80.8 | 74.1 | 86.1 | 79.5 | 77.1 | 49.4 | 68.6 | 80.0 | 92.1 | 50.0 | 62.8 |
| SigLIP 2 | 83.4 | 77.8 | 87.7 | 84.8 | 79.7 | 55.4 | 71.5 | 84.4 | 94.2 | 48.1 | 57.5 | |||
| 384 | 576 | SigLIP 2 | 84.1 | 78.4 | 88.1 | 85.8 | 80.4 | 56.0 | 71.2 | 85.3 | 95.9 | 48.3 | 57.5 | |
| 512 | 1024 | SigLIP 2 | 84.3 | 79.1 | 88.1 | 86.2 | 80.5 | 56.0 | 71.3 | 85.5 | 95.4 | 48.3 | 57.6 | |
| H/14 | 224 | 256 | MetaCLIP [66] | 80.5 | 74.1 | – | 76.5 | – | 57.5 | – | 85.0 | – | – | – |
| DFN [19] | 83.4 | 77.3 | – | 76.5 | – | 63.1 | – | 86.5 | – | – | – | |||
| g/16 | 256 | 256 | SigLIP 2 | 84.5 | 79.2 | 88.3 | 87.1 | 82.1 | 55.7 | 72.5 | 85.3 | 95.3 | 48.2 | 58.2 |
| 384 | 576 | SigLIP 2 | 85.0 | 79.8 | 88.5 | 88.0 | 82.5 | 56.1 | 72.8 | 86.0 | 95.4 | 48.6 | 57.9 | |
🔼 This table presents a comprehensive comparison of SigLIP 2’s performance against several other vision-language models across three key tasks: zero-shot classification (the ability to classify images into categories without explicit training on those categories), 10-shot classification (a form of few-shot learning where the model receives 10 examples per category for training before classification), and image-text retrieval (measuring the accuracy of matching images to their corresponding text descriptions and vice-versa). The results are shown for various model sizes and resolutions, offering a detailed analysis of SigLIP 2’s capabilities and efficiency. The table highlights SigLIP 2’s superior performance across all tasks and model scales, emphasizing its multilingual capabilities despite often outperforming even monolingual baselines which have been specifically tuned to individual datasets like ImageNet, COCO, and Flickr. The exceptional performance of SigLIP 2 underscores its robustness and generalizability.
read the caption
Table 1: Zero-shot classification, 10-shot (10s) classification (on the validation set), and retrieval performance (recall@1) of SigLIP 2 along with several baselines. SigLIP 2 outperforms the baselines—often by a large margin—despite being multilingual. Note that DFN [19] relies on a data filtering network fine-tuned on ImageNet, COCO, and Flickr.
In-depth insights#
Beyond CLIP#
Beyond CLIP signifies advancements that improve upon the original CLIP model’s limitations. These enhancements often involve refining training techniques, augmenting datasets with more diverse or high-quality data, and incorporating auxiliary tasks to enrich the learned representations. For example, one direction is to add more spatial perception ability. The spatial perception may include improving object detection accuracy, image segmentation precision, or referring comprehension. Furthermore, the original CLIP model can not process multiple image resolution so that the new method should consider the multiple scales. Another direction is to adapt existing architectures to different scales. These include training small or big model effectively. The goal is to train a set of models and adapting each model separately to different resolutions. This can also boost dense features and representation bias. Besides, it can improve fairness for different gender and region.
Multilingualism#
The document underscores the significance of multilingualism in vision-language models. SigLIP 2’s proficiency in multiple languages allows for use across diverse linguistic and cultural contexts. The model’s design focuses on reducing biases and enhancing fairness across different languages, ensuring equitable performance and representation. This is achieved through a data mixture that incorporates de-biasing techniques. Multilingual training ensures the model’s applicability and effectiveness are not limited to English-centric benchmarks. In evaluations, SigLIP 2 shows strong results on multilingual benchmarks while maintaining or improving performance on English-focused tasks. It improves generalization and robustness in varied linguistic scenarios.
Native Aspect#
The preservation of the native aspect ratio and support for variable resolutions in SigLIP 2’s NaFlex variant are key enhancements. This allows processing images at their original proportions, minimizing distortion and improving performance on tasks sensitive to aspect ratio, such as document understanding and OCR. This flexibility, combined with the model’s ability to handle different sequence lengths, makes it more adaptable to various image types and resolutions. The goal is to balance accurate representation with computational efficiency by appropriately resizing images while keeping the aspect ratio mostly intact. Maintaining aspect ratio reduces distortion, ultimately improving performance.
SigLIP Distill#
While the provided document doesn’t explicitly mention a section titled “SigLIP Distill,” the concept of distillation is central to improving smaller models. Distillation involves transferring knowledge from a larger, pre-trained “teacher” model to a smaller “student” model. This is achieved by having the student model mimic the teacher’s outputs, thereby learning more effectively than training from scratch. In SigLIP 2, active data curation using the ACID method further enhances distillation. This method selects the most “learnable” examples for the student, leading to improved performance for smaller B-sized models. This efficient knowledge transfer from larger teacher architectures contributes to enhancing accuracy while also promoting faster training times.
VLM Vision#
Vision-Language Models (VLMs) represent a critical area where visual and textual data are integrated for advanced AI applications. At the core, VLMs seek to bridge the gap between how machines ‘see’ and how they ‘understand’ language. VLMs are pivotal in tasks where understanding the context of an image is critical, such as in image captioning, visual question answering, or generating text-based descriptions from visual inputs. Effective VLMs rely on robust feature extraction from both modalities, necessitating high-quality vision encoders and language models. The development of VLMs also addresses challenges around data bias, fairness, and cultural representation. Advancements in this field promise more versatile and human-like AI systems.
More visual insights#
More on figures

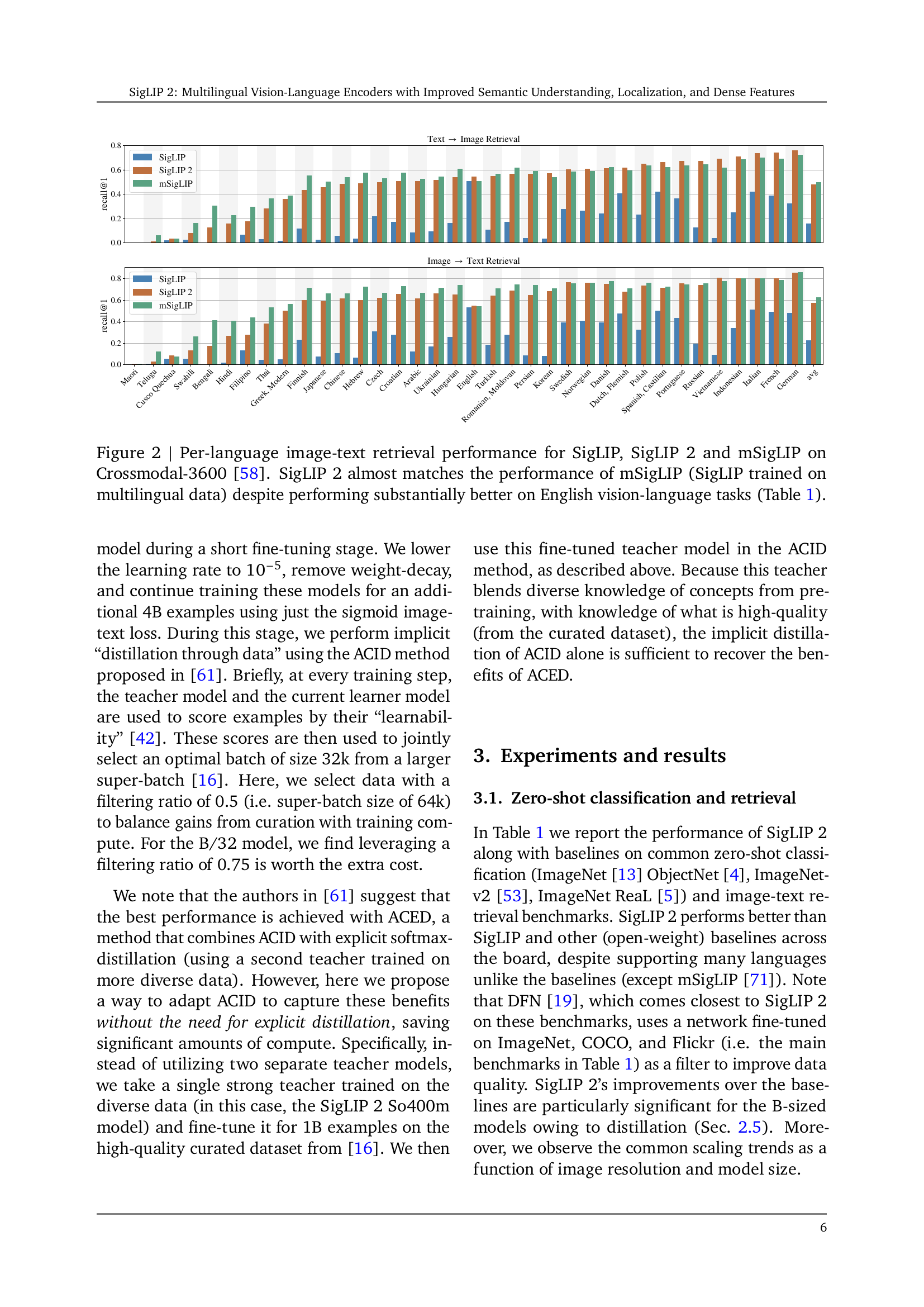
🔼 This figure displays a comparison of image-text retrieval performance across three vision-language models: SigLIP, SigLIP 2, and mSigLIP, evaluated on the Crossmodal-3600 benchmark dataset. The benchmark encompasses 36 different languages, and the chart shows the recall@1 score (a measure of retrieval accuracy) for each language. Notably, SigLIP 2, despite exhibiting superior performance on English-centric tasks, achieves a recall@1 nearly identical to mSigLIP (a multilingual variant of SigLIP), highlighting its strong multilingual capabilities. This demonstrates SigLIP 2’s effectiveness across a broad range of languages.
read the caption
Figure 2: Per-language image-text retrieval performance for SigLIP, SigLIP 2 and mSigLIP on Crossmodal-3600 [58]. SigLIP 2 almost matches the performance of mSigLIP (SigLIP trained on multilingual data) despite performing substantially better on English vision-language tasks (Table 1).
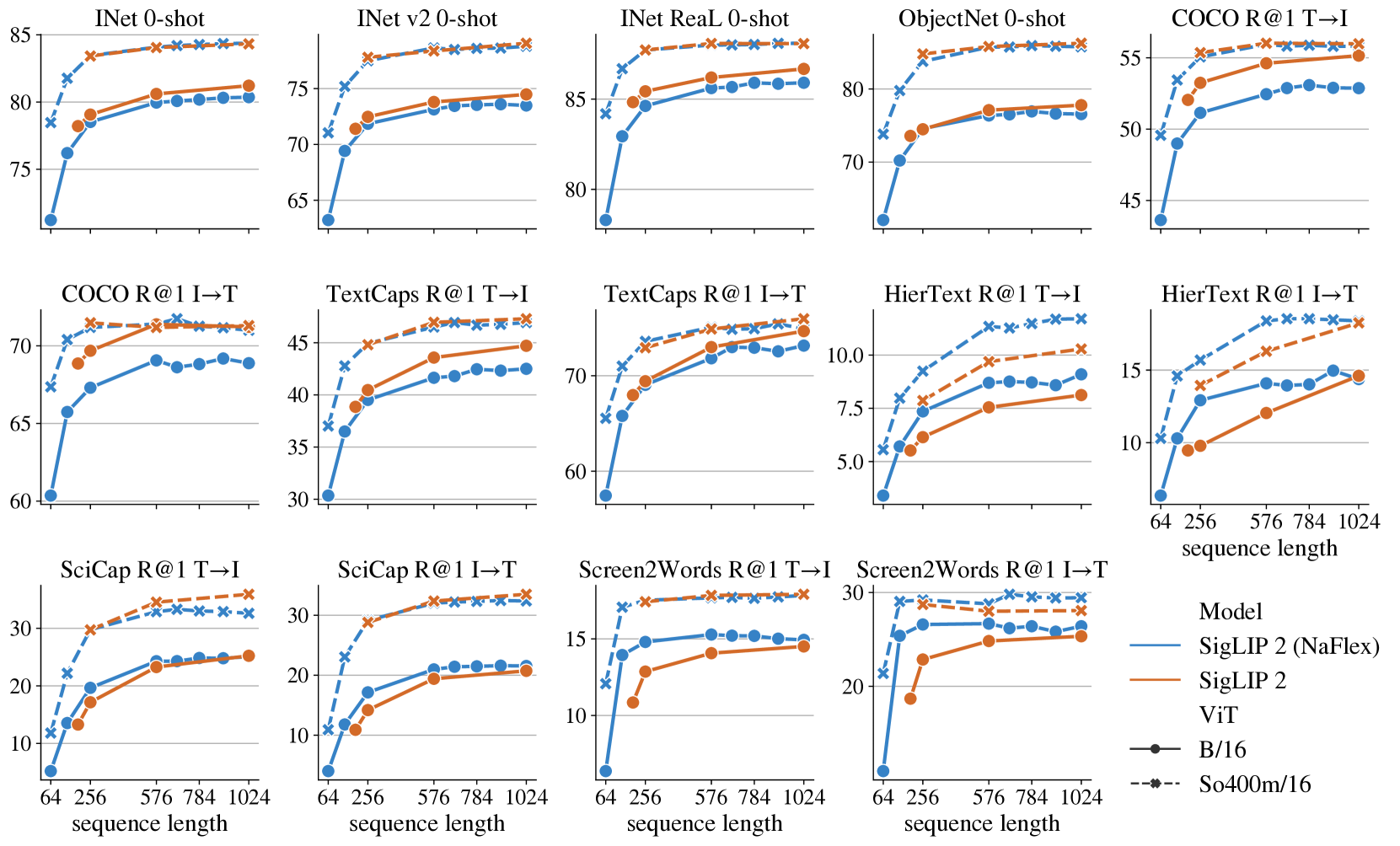
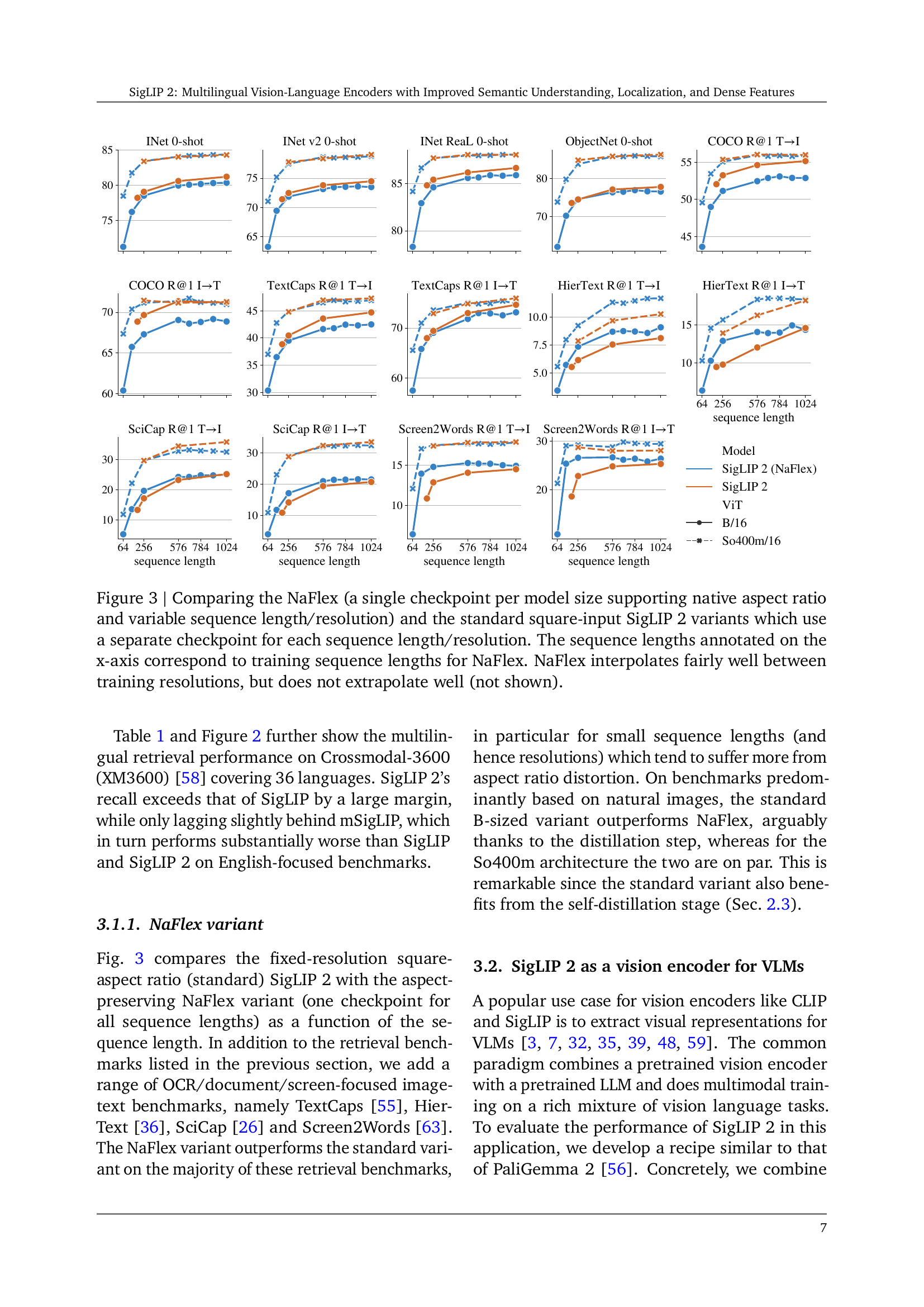
🔼 Figure 3 compares the performance of two SigLIP 2 model variants: NaFlex and the standard square-input model. NaFlex uses a single checkpoint for all sequence lengths and resolutions, while maintaining the native aspect ratio of the input image. In contrast, the standard model requires a separate checkpoint for each sequence length and resolution. The x-axis shows training sequence lengths for NaFlex, illustrating its ability to handle variable input sizes. The figure demonstrates that NaFlex performs well across different input sizes by interpolating between training resolutions, although extrapolation to sizes outside the training range is not shown to be successful.
read the caption
Figure 3: Comparing the NaFlex (a single checkpoint per model size supporting native aspect ratio and variable sequence length/resolution) and the standard square-input SigLIP 2 variants which use a separate checkpoint for each sequence length/resolution. The sequence lengths annotated on the x-axis correspond to training sequence lengths for NaFlex. NaFlex interpolates fairly well between training resolutions, but does not extrapolate well (not shown).

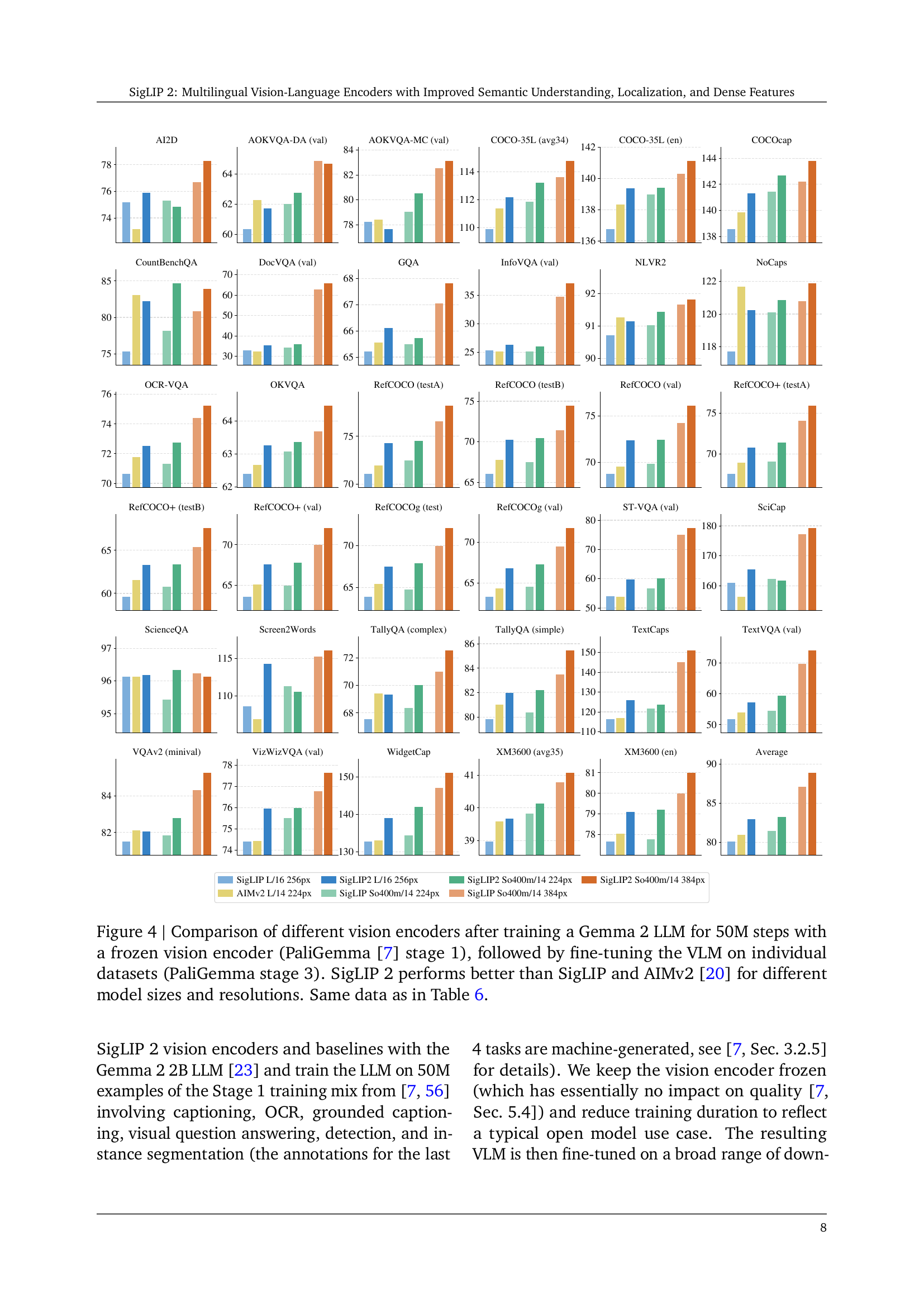
🔼 This figure compares the performance of SigLIP 2, SigLIP, and AIMv2 vision encoders when used as part of a Vision-Language Model (VLM). The VLMs were created by training a Gemma 2 Large Language Model (LLM) for 50 million steps with a frozen vision encoder (following the PaliGemma stage 1 training procedure), and then fine-tuning the resulting VLM on various individual datasets (PaliGemma stage 3). The figure shows the performance of each vision encoder across multiple datasets, model sizes (ViT-B/16, ViT-L/16, ViT-So400m/14), and image resolutions. SigLIP 2 consistently outperforms both SigLIP and AIMv2, demonstrating its effectiveness as a vision encoder in VLMs.
read the caption
Figure 4: Comparison of different vision encoders after training a Gemma 2 LLM for 50M steps with a frozen vision encoder (PaliGemma [7] stage 1), followed by fine-tuning the VLM on individual datasets (PaliGemma stage 3). SigLIP 2 performs better than SigLIP and AIMv2 [20] for different model sizes and resolutions. Same data as in Table 6.

🔼 Figure 5 presents a comparative analysis of SigLIP and SigLIP 2 models on geographically diverse object classification tasks using three benchmark datasets: Dollar Street, GeoDE (country/region), and GLDv2. The performance is evaluated under both 10-shot and 0-shot learning scenarios. The figure visually demonstrates that SigLIP 2 consistently achieves higher accuracy than SigLIP across all datasets and learning settings. Table 8 in the paper provides a more detailed numerical breakdown of the results shown in this figure.
read the caption
Figure 5: 10-shot and 0-shot accuracy for geographically diverse object classification tasks (Dollar Street, GeoDE), as well as geolocalization (GeoDE country/region) and landmark localization (GLDv2) tasks. SigLIP 2 consistently performs better than SigLIP (see Table 8 for additional results).
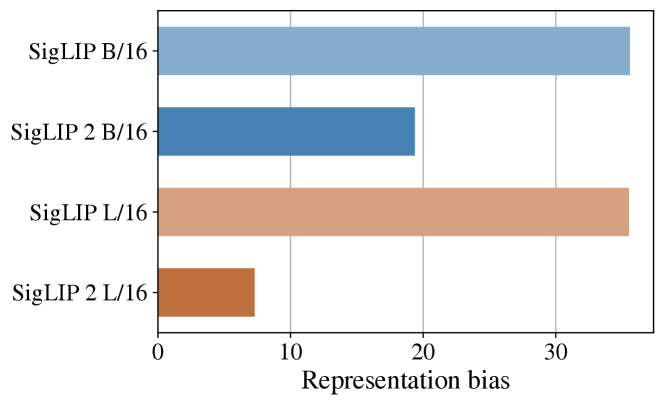
🔼 Figure 6 illustrates the representation bias present in different vision-language models. Representation bias refers to the tendency of a model to associate certain objects with specific genders disproportionately. Lower scores on the y-axis indicate less bias, signifying a more equitable association of objects with genders. The figure compares the SigLIP and SigLIP 2 models across various sizes, showcasing the improvement in reducing gender bias achieved by SigLIP 2.
read the caption
Figure 6: Representation bias (association of random objects with gender; lower is better) for different models.
More on tables
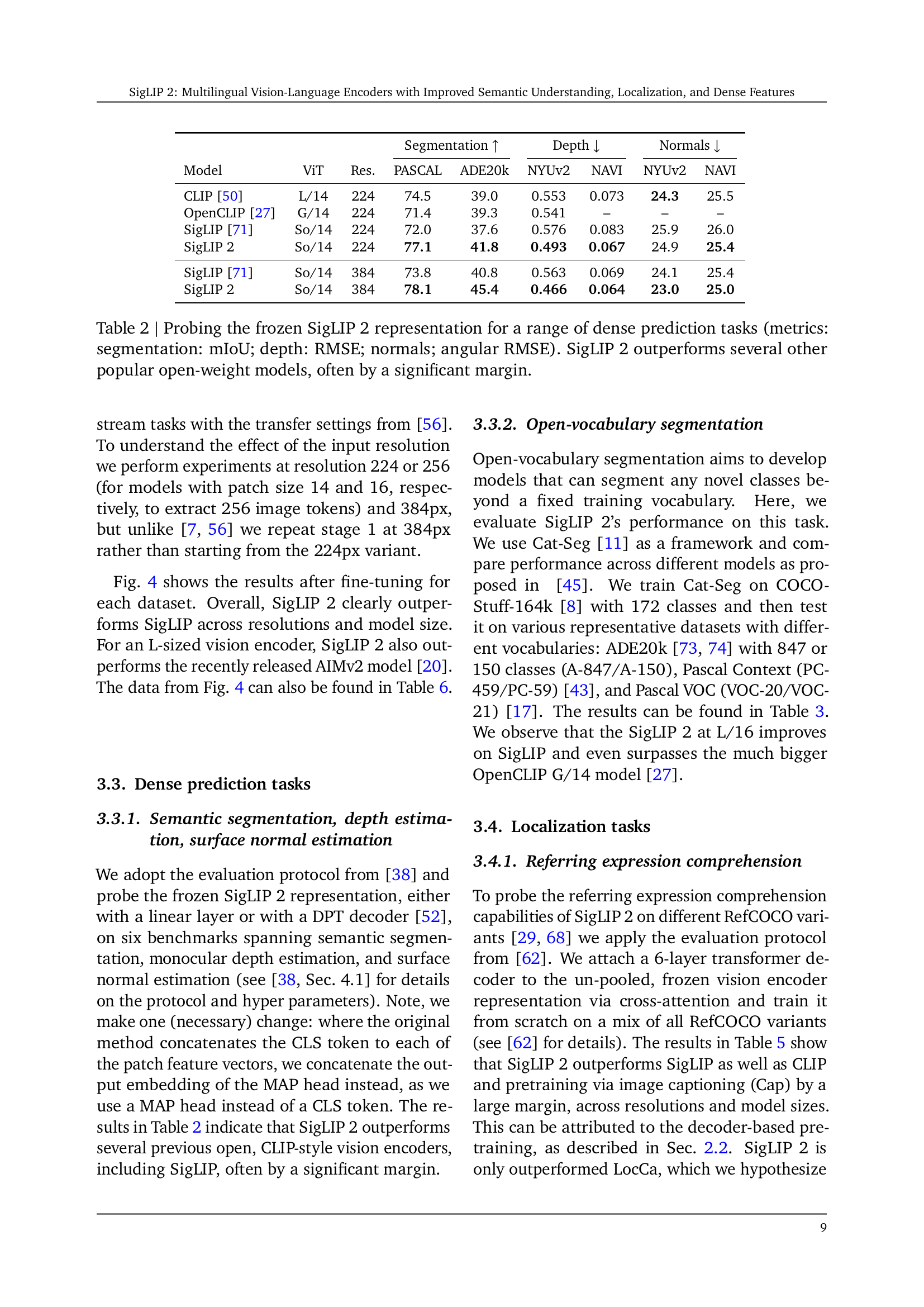
| Segmentation | Depth | Normals | ||||||
| Model | ViT | Res. | PASCAL | ADE20k | NYUv2 | NAVI | NYUv2 | NAVI |
| CLIP [50] | L/14 | 224 | 74.5 | 39.0 | 0.553 | 0.073 | 24.3 | 25.5 |
| OpenCLIP [27] | G/14 | 224 | 71.4 | 39.3 | 0.541 | – | – | – |
| SigLIP [71] | So/14 | 224 | 72.0 | 37.6 | 0.576 | 0.083 | 25.9 | 26.0 |
| SigLIP 2 | So/14 | 224 | 77.1 | 41.8 | 0.493 | 0.067 | 24.9 | 25.4 |
| SigLIP [71] | So/14 | 384 | 73.8 | 40.8 | 0.563 | 0.069 | 24.1 | 25.4 |
| SigLIP 2 | So/14 | 384 | 78.1 | 45.4 | 0.466 | 0.064 | 23.0 | 25.0 |
🔼 Table 2 presents a comprehensive evaluation of SigLIP 2’s performance on various dense prediction tasks, including semantic segmentation, depth estimation, and surface normal estimation. The results demonstrate SigLIP 2’s superior performance compared to other popular open-source vision models, showcasing significant improvements across all three tasks, often by a substantial margin. Metrics used to quantify performance are mIoU for segmentation, RMSE for depth estimation, and angular RMSE for surface normal estimation, allowing for a direct comparison of the models’ accuracy and effectiveness in these complex tasks.
read the caption
Table 2: Probing the frozen SigLIP 2 representation for a range of dense prediction tasks (metrics: segmentation: mIoU; depth: RMSE; normals; angular RMSE). SigLIP 2 outperforms several other popular open-weight models, often by a significant margin.
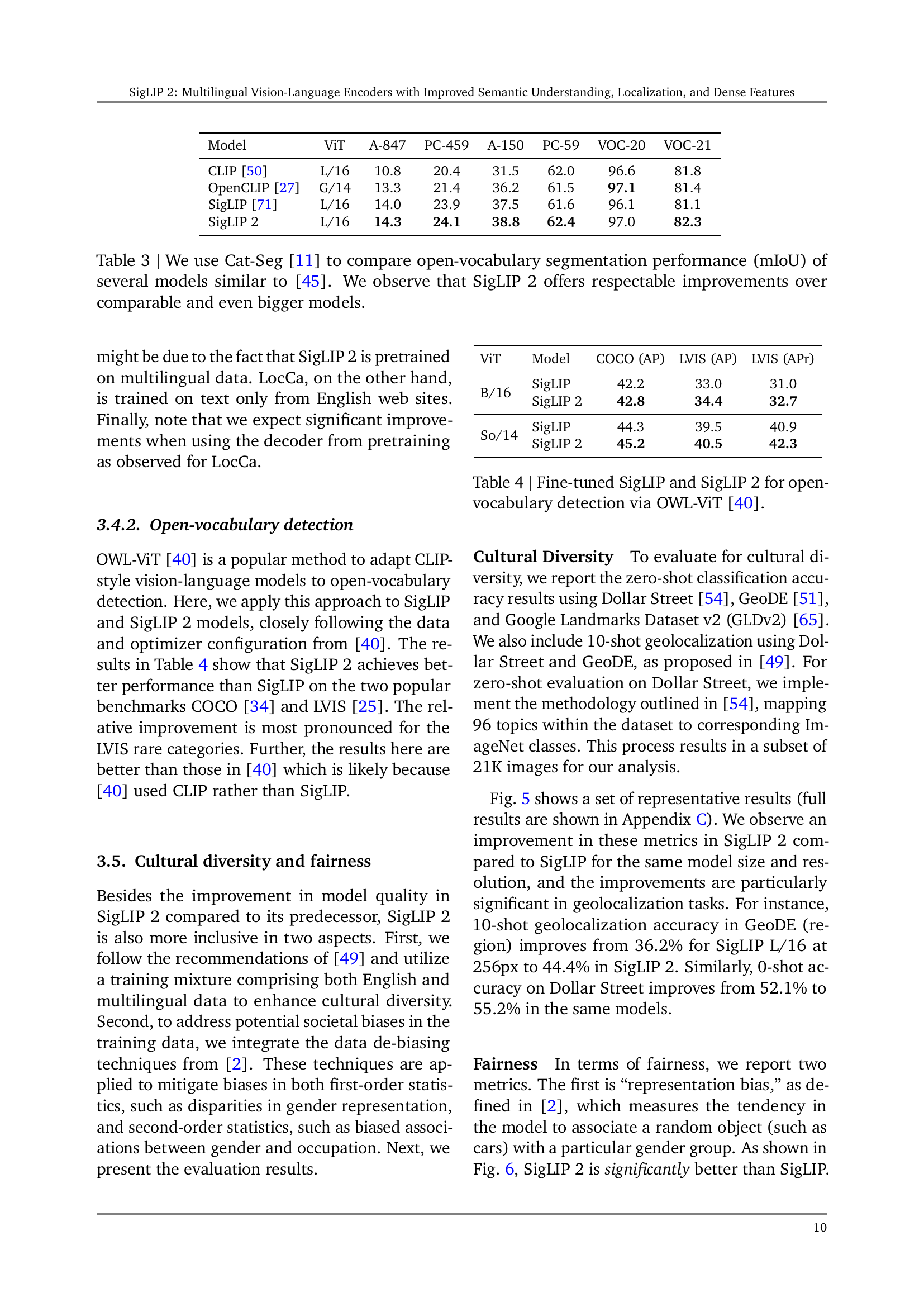
| Model | ViT | A-847 | PC-459 | A-150 | PC-59 | VOC-20 | VOC-21 |
|---|---|---|---|---|---|---|---|
| CLIP [50] | L/16 | 10.8 | 20.4 | 31.5 | 62.0 | 96.6 | 81.8 |
| OpenCLIP [27] | G/14 | 13.3 | 21.4 | 36.2 | 61.5 | 97.1 | 81.4 |
| SigLIP [71] | L/16 | 14.0 | 23.9 | 37.5 | 61.6 | 96.1 | 81.1 |
| SigLIP 2 | L/16 | 14.3 | 24.1 | 38.8 | 62.4 | 97.0 | 82.3 |
🔼 Table 3 presents a comparison of open-vocabulary semantic segmentation performance, measured by mean Intersection over Union (mIoU), across various vision models. The results are obtained using the Cat-Seg framework [11], and the models are evaluated on multiple datasets including ADE20k [73, 74] with different numbers of classes (847 or 150), Pascal Context (PC-459/PC-59) [43], and Pascal VOC (VOC-20/VOC-21) [17]. The table highlights that SigLIP 2 demonstrates notable improvements in mIoU over comparable models, even those significantly larger in size, showcasing the effectiveness of its training methodology.
read the caption
Table 3: We use Cat-Seg [11] to compare open-vocabulary segmentation performance (mIoU) of several models similar to [45]. We observe that SigLIP 2 offers respectable improvements over comparable and even bigger models.
| ViT | Model | COCO (AP) | LVIS (AP) | LVIS (APr) |
|---|---|---|---|---|
| B/16 | SigLIP | 42.2 | 33.0 | 31.0 |
| SigLIP 2 | 42.8 | 34.4 | 32.7 | |
| So/14 | SigLIP | 44.3 | 39.5 | 40.9 |
| SigLIP 2 | 45.2 | 40.5 | 42.3 |
🔼 This table presents the results of fine-tuning SigLIP and SigLIP 2 models for open-vocabulary object detection using the OWL-ViT framework [40]. It compares the performance of SigLIP and SigLIP 2 on the COCO and LVIS datasets, showcasing the Average Precision (AP) and Average Precision for Rare classes (APr) for each model. The results highlight the improvement achieved by SigLIP 2 over the original SigLIP model in open-vocabulary detection.
read the caption
Table 4: Fine-tuned SigLIP and SigLIP 2 for open-vocabulary detection via OWL-ViT [40].
| RefCOCO | RefCOCO+ | RefCOCOg | ||||||||
| ViT | Seq. | Model | val | testA | testB | val | testA | testB | val-u | test-u |
| B | 256 | SigLIP [71] | 64.05 | 70.10 | 57.89 | 55.77 | 63.57 | 47.51 | 59.06 | 60.33 |
| SigLIP 2 | 83.76 | 86.21 | 79.57 | 74.26 | 79.85 | 65.83 | 77.25 | 77.83 | ||
| 576 | SigLIP [71] | 67.17 | 72.94 | 60.94 | 59.09 | 67.26 | 50.22 | 61.98 | 62.64 | |
| SigLIP 2 | 85.18 | 87.92 | 80.53 | 76.08 | 82.17 | 67.10 | 79.08 | 79.60 | ||
| L | 256 | Cap [60] | 60.64 | 65.47 | 56.17 | 52.56 | 58.32 | 45.99 | 56.75 | 57.99 |
| CapPa [60] | 64.17 | 69.90 | 58.25 | 56.14 | 63.68 | 48.18 | 58.90 | 59.91 | ||
| CLIP [50] | 65.21 | 71.28 | 58.17 | 57.53 | 66.44 | 47.77 | 59.32 | 60.24 | ||
| SigLIP [71] | 67.33 | 72.40 | 61.21 | 59.57 | 67.09 | 51.08 | 61.89 | 62.90 | ||
| SigLIP 2 | 86.04 | 89.02 | 81.85 | 77.29 | 83.28 | 70.16 | 80.11 | 80.78 | ||
| LocCa [62] | 88.34 | 91.20 | 85.10 | 79.39 | 85.13 | 72.61 | 81.69 | 82.64 | ||
| 576 | SigLIP [71] | 70.76 | 76.32 | 63.79 | 63.38 | 71.48 | 54.65 | 64.73 | 65.74 | |
| SigLIP 2 | 87.28 | 90.29 | 82.85 | 79.00 | 85.00 | 70.92 | 81.84 | 82.15 | ||
| So | 256 | SigLIP [71] | 64.68 | 71.23 | 58.40 | 57.43 | 66.06 | 49.38 | 59.66 | 60.88 |
| SigLIP 2 | 86.42 | 89.41 | 82.48 | 77.81 | 84.36 | 70.67 | 80.83 | 81.27 | ||
| 729 | SigLIP [71] | 67.66 | 74.12 | 62.36 | 60.74 | 69.73 | 52.12 | 62.61 | 63.24 | |
| SigLIP 2 | 87.88 | 91.13 | 83.59 | 80.06 | 86.30 | 72.66 | 82.68 | 83.63 | ||
| g | 256 | SigLIP 2 | 87.31 | 90.24 | 83.25 | 79.25 | 85.23 | 71.60 | 81.48 | 82.14 |
| 576 | SigLIP 2 | 88.45 | 91.53 | 84.95 | 80.44 | 87.09 | 73.53 | 83.12 | 84.14 | |
🔼 Table 5 presents a detailed comparison of SigLIP 2’s performance on referring expression comprehension against SigLIP and other related models. The accuracy (Acc@0.5) is reported for various model sizes and sequence lengths. The results demonstrate SigLIP 2’s significant improvement over SigLIP across different configurations. It highlights that SigLIP 2’s superior performance stems from its architecture and training data. Only LocCa, which shares the decoder-based loss with SigLIP 2 but is trained exclusively on English captions, surpasses SigLIP 2.
read the caption
Table 5: Comparing SigLIP 2 models with SigLIP and other baselines from the literature on referring expression comprehension (Acc@0.5). For matching model size and sequence length (seq.) SigLIP 2 models outperform SigLIP models substantially. SigLIP 2 is only outperformed by LocCa, which uses the same decoder-based loss, but is trained on captions from English language websites only.
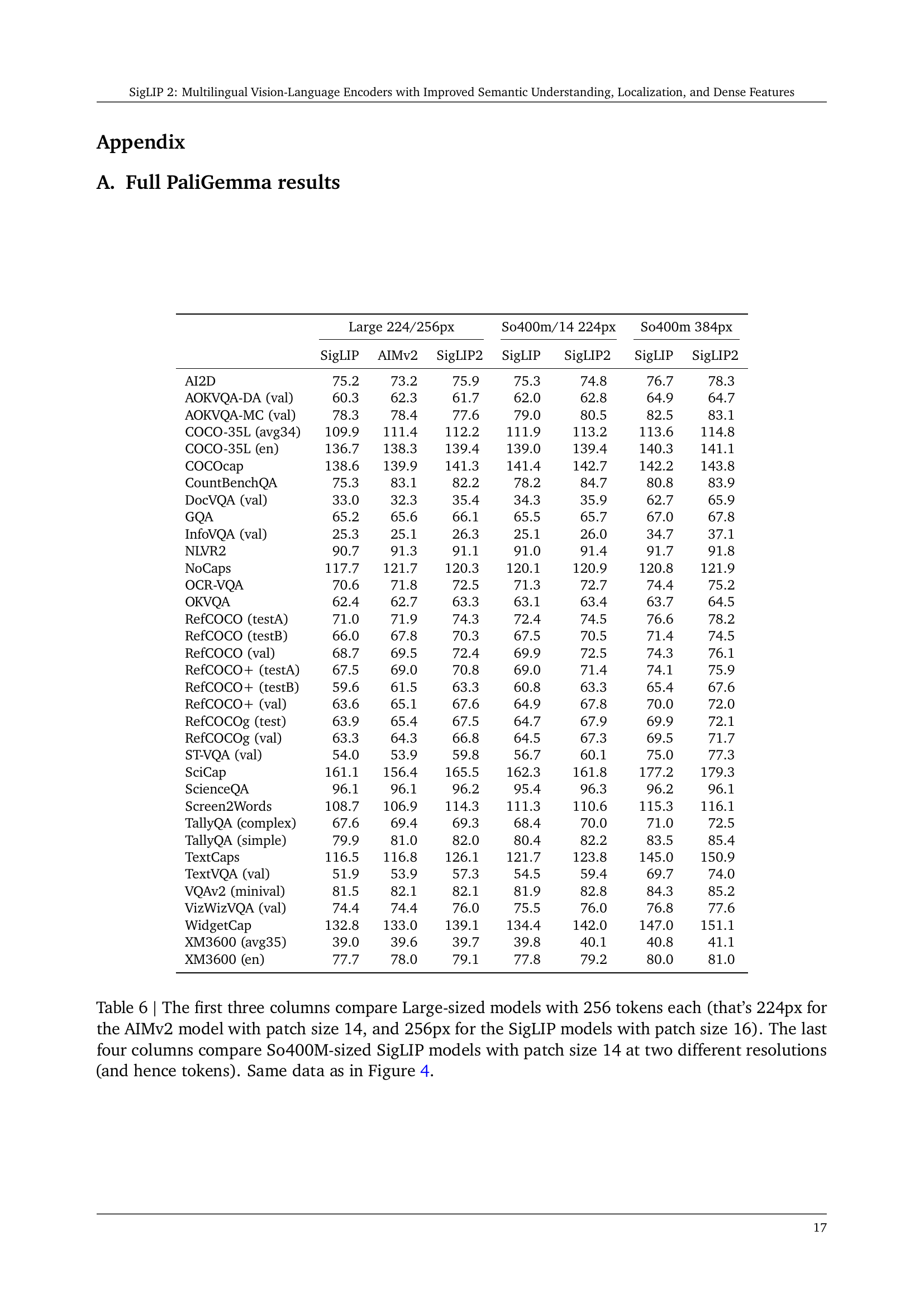
| Large 224/256px | So400m/14 224px | So400m 384px | |||||
|---|---|---|---|---|---|---|---|
| SigLIP | AIMv2 | SigLIP2 | SigLIP | SigLIP2 | SigLIP | SigLIP2 | |
| AI2D | 75.2 | 73.2 | 75.9 | 75.3 | 74.8 | 76.7 | 78.3 |
| AOKVQA-DA (val) | 60.3 | 62.3 | 61.7 | 62.0 | 62.8 | 64.9 | 64.7 |
| AOKVQA-MC (val) | 78.3 | 78.4 | 77.6 | 79.0 | 80.5 | 82.5 | 83.1 |
| COCO-35L (avg34) | 109.9 | 111.4 | 112.2 | 111.9 | 113.2 | 113.6 | 114.8 |
| COCO-35L (en) | 136.7 | 138.3 | 139.4 | 139.0 | 139.4 | 140.3 | 141.1 |
| COCOcap | 138.6 | 139.9 | 141.3 | 141.4 | 142.7 | 142.2 | 143.8 |
| CountBenchQA | 75.3 | 83.1 | 82.2 | 78.2 | 84.7 | 80.8 | 83.9 |
| DocVQA (val) | 33.0 | 32.3 | 35.4 | 34.3 | 35.9 | 62.7 | 65.9 |
| GQA | 65.2 | 65.6 | 66.1 | 65.5 | 65.7 | 67.0 | 67.8 |
| InfoVQA (val) | 25.3 | 25.1 | 26.3 | 25.1 | 26.0 | 34.7 | 37.1 |
| NLVR2 | 90.7 | 91.3 | 91.1 | 91.0 | 91.4 | 91.7 | 91.8 |
| NoCaps | 117.7 | 121.7 | 120.3 | 120.1 | 120.9 | 120.8 | 121.9 |
| OCR-VQA | 70.6 | 71.8 | 72.5 | 71.3 | 72.7 | 74.4 | 75.2 |
| OKVQA | 62.4 | 62.7 | 63.3 | 63.1 | 63.4 | 63.7 | 64.5 |
| RefCOCO (testA) | 71.0 | 71.9 | 74.3 | 72.4 | 74.5 | 76.6 | 78.2 |
| RefCOCO (testB) | 66.0 | 67.8 | 70.3 | 67.5 | 70.5 | 71.4 | 74.5 |
| RefCOCO (val) | 68.7 | 69.5 | 72.4 | 69.9 | 72.5 | 74.3 | 76.1 |
| RefCOCO+ (testA) | 67.5 | 69.0 | 70.8 | 69.0 | 71.4 | 74.1 | 75.9 |
| RefCOCO+ (testB) | 59.6 | 61.5 | 63.3 | 60.8 | 63.3 | 65.4 | 67.6 |
| RefCOCO+ (val) | 63.6 | 65.1 | 67.6 | 64.9 | 67.8 | 70.0 | 72.0 |
| RefCOCOg (test) | 63.9 | 65.4 | 67.5 | 64.7 | 67.9 | 69.9 | 72.1 |
| RefCOCOg (val) | 63.3 | 64.3 | 66.8 | 64.5 | 67.3 | 69.5 | 71.7 |
| ST-VQA (val) | 54.0 | 53.9 | 59.8 | 56.7 | 60.1 | 75.0 | 77.3 |
| SciCap | 161.1 | 156.4 | 165.5 | 162.3 | 161.8 | 177.2 | 179.3 |
| ScienceQA | 96.1 | 96.1 | 96.2 | 95.4 | 96.3 | 96.2 | 96.1 |
| Screen2Words | 108.7 | 106.9 | 114.3 | 111.3 | 110.6 | 115.3 | 116.1 |
| TallyQA (complex) | 67.6 | 69.4 | 69.3 | 68.4 | 70.0 | 71.0 | 72.5 |
| TallyQA (simple) | 79.9 | 81.0 | 82.0 | 80.4 | 82.2 | 83.5 | 85.4 |
| TextCaps | 116.5 | 116.8 | 126.1 | 121.7 | 123.8 | 145.0 | 150.9 |
| TextVQA (val) | 51.9 | 53.9 | 57.3 | 54.5 | 59.4 | 69.7 | 74.0 |
| VQAv2 (minival) | 81.5 | 82.1 | 82.1 | 81.9 | 82.8 | 84.3 | 85.2 |
| VizWizVQA (val) | 74.4 | 74.4 | 76.0 | 75.5 | 76.0 | 76.8 | 77.6 |
| WidgetCap | 132.8 | 133.0 | 139.1 | 134.4 | 142.0 | 147.0 | 151.1 |
| XM3600 (avg35) | 39.0 | 39.6 | 39.7 | 39.8 | 40.1 | 40.8 | 41.1 |
| XM3600 (en) | 77.7 | 78.0 | 79.1 | 77.8 | 79.2 | 80.0 | 81.0 |
🔼 Table 6 presents a comparison of the performance of large-sized (L) and So400M-sized SigLIP models on various downstream tasks. The first three columns show results for large models using 256 tokens (224px resolution for AIMv2 with a patch size of 14 and 256px resolution for SigLIP models with a patch size of 16). The remaining four columns display results for So400M SigLIP models with a patch size of 14 at two different resolutions, resulting in a varying number of tokens. This allows for evaluating how model size and resolution impact performance across a variety of tasks. The data in this table is the same as shown in Figure 4.
read the caption
Table 6: The first three columns compare Large-sized models with 256 tokens each (that’s 224px for the AIMv2 model with patch size 14, and 256px for the SigLIP models with patch size 16). The last four columns compare So400M-sized SigLIP models with patch size 14 at two different resolutions (and hence tokens). Same data as in Figure 4.
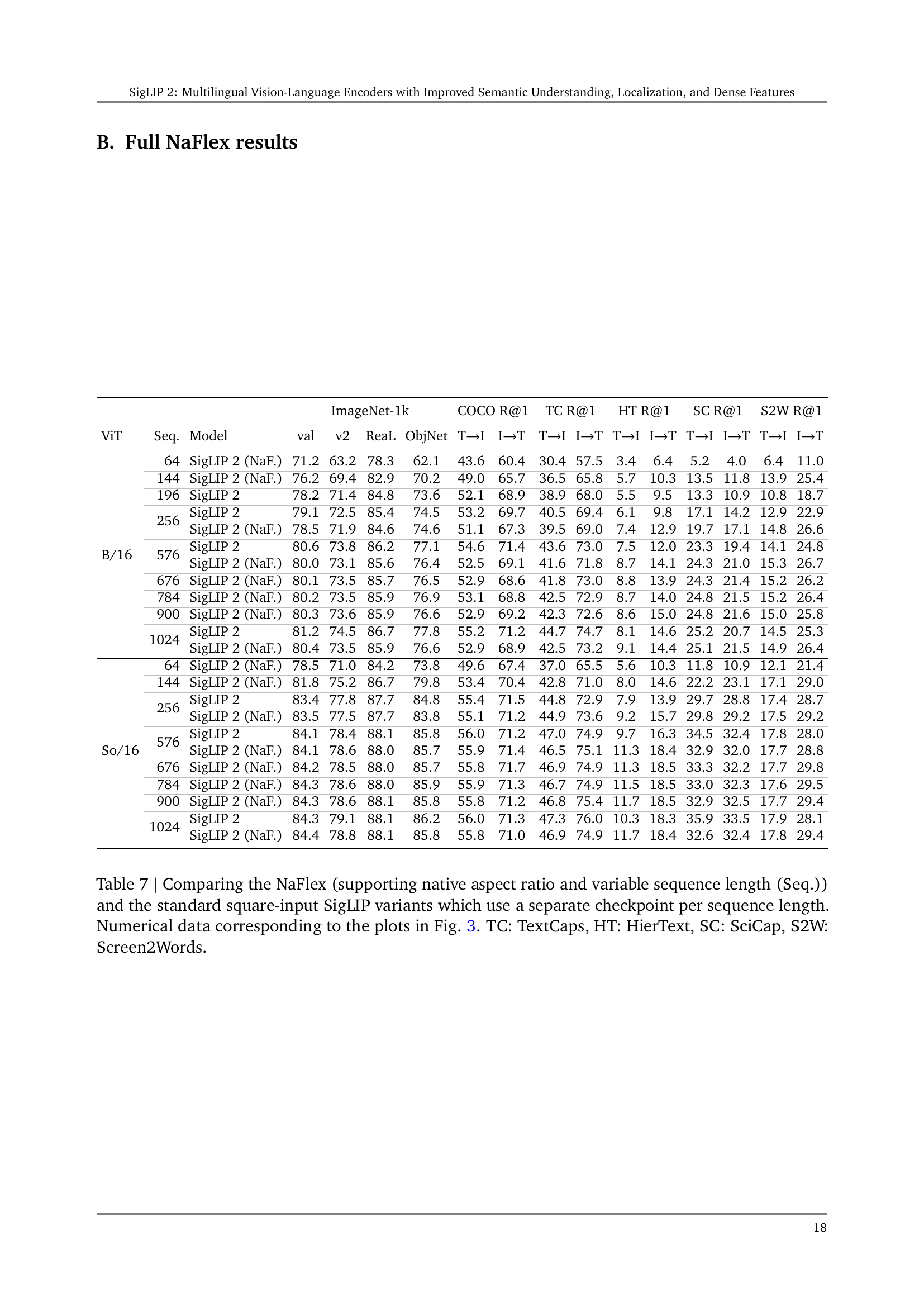
| ImageNet-1k | COCO R@1 | TC R@1 | HT R@1 | SC R@1 | S2W R@1 | |||||||||||
| ViT | Seq. | Model | val | v2 | ReaL | ObjNet | TI | IT | TI | IT | TI | IT | TI | IT | TI | IT |
| B/16 | 64 | SigLIP 2 (NaF.) | 71.2 | 63.2 | 78.3 | 62.1 | 43.6 | 60.4 | 30.4 | 57.5 | 3.4 | 6.4 | 5.2 | 4.0 | 6.4 | 11.0 |
| 144 | SigLIP 2 (NaF.) | 76.2 | 69.4 | 82.9 | 70.2 | 49.0 | 65.7 | 36.5 | 65.8 | 5.7 | 10.3 | 13.5 | 11.8 | 13.9 | 25.4 | |
| 196 | SigLIP 2 | 78.2 | 71.4 | 84.8 | 73.6 | 52.1 | 68.9 | 38.9 | 68.0 | 5.5 | 9.5 | 13.3 | 10.9 | 10.8 | 18.7 | |
| 256 | SigLIP 2 | 79.1 | 72.5 | 85.4 | 74.5 | 53.2 | 69.7 | 40.5 | 69.4 | 6.1 | 9.8 | 17.1 | 14.2 | 12.9 | 22.9 | |
| SigLIP 2 (NaF.) | 78.5 | 71.9 | 84.6 | 74.6 | 51.1 | 67.3 | 39.5 | 69.0 | 7.4 | 12.9 | 19.7 | 17.1 | 14.8 | 26.6 | ||
| 576 | SigLIP 2 | 80.6 | 73.8 | 86.2 | 77.1 | 54.6 | 71.4 | 43.6 | 73.0 | 7.5 | 12.0 | 23.3 | 19.4 | 14.1 | 24.8 | |
| SigLIP 2 (NaF.) | 80.0 | 73.1 | 85.6 | 76.4 | 52.5 | 69.1 | 41.6 | 71.8 | 8.7 | 14.1 | 24.3 | 21.0 | 15.3 | 26.7 | ||
| 676 | SigLIP 2 (NaF.) | 80.1 | 73.5 | 85.7 | 76.5 | 52.9 | 68.6 | 41.8 | 73.0 | 8.8 | 13.9 | 24.3 | 21.4 | 15.2 | 26.2 | |
| 784 | SigLIP 2 (NaF.) | 80.2 | 73.5 | 85.9 | 76.9 | 53.1 | 68.8 | 42.5 | 72.9 | 8.7 | 14.0 | 24.8 | 21.5 | 15.2 | 26.4 | |
| 900 | SigLIP 2 (NaF.) | 80.3 | 73.6 | 85.9 | 76.6 | 52.9 | 69.2 | 42.3 | 72.6 | 8.6 | 15.0 | 24.8 | 21.6 | 15.0 | 25.8 | |
| 1024 | SigLIP 2 | 81.2 | 74.5 | 86.7 | 77.8 | 55.2 | 71.2 | 44.7 | 74.7 | 8.1 | 14.6 | 25.2 | 20.7 | 14.5 | 25.3 | |
| SigLIP 2 (NaF.) | 80.4 | 73.5 | 85.9 | 76.6 | 52.9 | 68.9 | 42.5 | 73.2 | 9.1 | 14.4 | 25.1 | 21.5 | 14.9 | 26.4 | ||
| So/16 | 64 | SigLIP 2 (NaF.) | 78.5 | 71.0 | 84.2 | 73.8 | 49.6 | 67.4 | 37.0 | 65.5 | 5.6 | 10.3 | 11.8 | 10.9 | 12.1 | 21.4 |
| 144 | SigLIP 2 (NaF.) | 81.8 | 75.2 | 86.7 | 79.8 | 53.4 | 70.4 | 42.8 | 71.0 | 8.0 | 14.6 | 22.2 | 23.1 | 17.1 | 29.0 | |
| 256 | SigLIP 2 | 83.4 | 77.8 | 87.7 | 84.8 | 55.4 | 71.5 | 44.8 | 72.9 | 7.9 | 13.9 | 29.7 | 28.8 | 17.4 | 28.7 | |
| SigLIP 2 (NaF.) | 83.5 | 77.5 | 87.7 | 83.8 | 55.1 | 71.2 | 44.9 | 73.6 | 9.2 | 15.7 | 29.8 | 29.2 | 17.5 | 29.2 | ||
| 576 | SigLIP 2 | 84.1 | 78.4 | 88.1 | 85.8 | 56.0 | 71.2 | 47.0 | 74.9 | 9.7 | 16.3 | 34.5 | 32.4 | 17.8 | 28.0 | |
| SigLIP 2 (NaF.) | 84.1 | 78.6 | 88.0 | 85.7 | 55.9 | 71.4 | 46.5 | 75.1 | 11.3 | 18.4 | 32.9 | 32.0 | 17.7 | 28.8 | ||
| 676 | SigLIP 2 (NaF.) | 84.2 | 78.5 | 88.0 | 85.7 | 55.8 | 71.7 | 46.9 | 74.9 | 11.3 | 18.5 | 33.3 | 32.2 | 17.7 | 29.8 | |
| 784 | SigLIP 2 (NaF.) | 84.3 | 78.6 | 88.0 | 85.9 | 55.9 | 71.3 | 46.7 | 74.9 | 11.5 | 18.5 | 33.0 | 32.3 | 17.6 | 29.5 | |
| 900 | SigLIP 2 (NaF.) | 84.3 | 78.6 | 88.1 | 85.8 | 55.8 | 71.2 | 46.8 | 75.4 | 11.7 | 18.5 | 32.9 | 32.5 | 17.7 | 29.4 | |
| 1024 | SigLIP 2 | 84.3 | 79.1 | 88.1 | 86.2 | 56.0 | 71.3 | 47.3 | 76.0 | 10.3 | 18.3 | 35.9 | 33.5 | 17.9 | 28.1 | |
| SigLIP 2 (NaF.) | 84.4 | 78.8 | 88.1 | 85.8 | 55.8 | 71.0 | 46.9 | 74.9 | 11.7 | 18.4 | 32.6 | 32.4 | 17.8 | 29.4 | ||
🔼 Table 7 compares the performance of two SigLIP 2 variants: NaFlex and the standard square-input version. NaFlex supports native aspect ratios and variable sequence lengths, using a single checkpoint for all sequence lengths, while the standard version uses separate checkpoints for each sequence length. The table shows the performance of both variants on various image-text retrieval benchmarks (ImageNet-1k, COCO, TextCaps, HierText, SciCap, Screen2Words) across different model sizes and image resolutions. The numerical data in this table directly corresponds to the data visualized in Figure 3 of the paper.
read the caption
Table 7: Comparing the NaFlex (supporting native aspect ratio and variable sequence length (Seq.)) and the standard square-input SigLIP variants which use a separate checkpoint per sequence length. Numerical data corresponding to the plots in Fig. 3. TC: TextCaps, HT: HierText, SC: SciCap, S2W: Screen2Words.
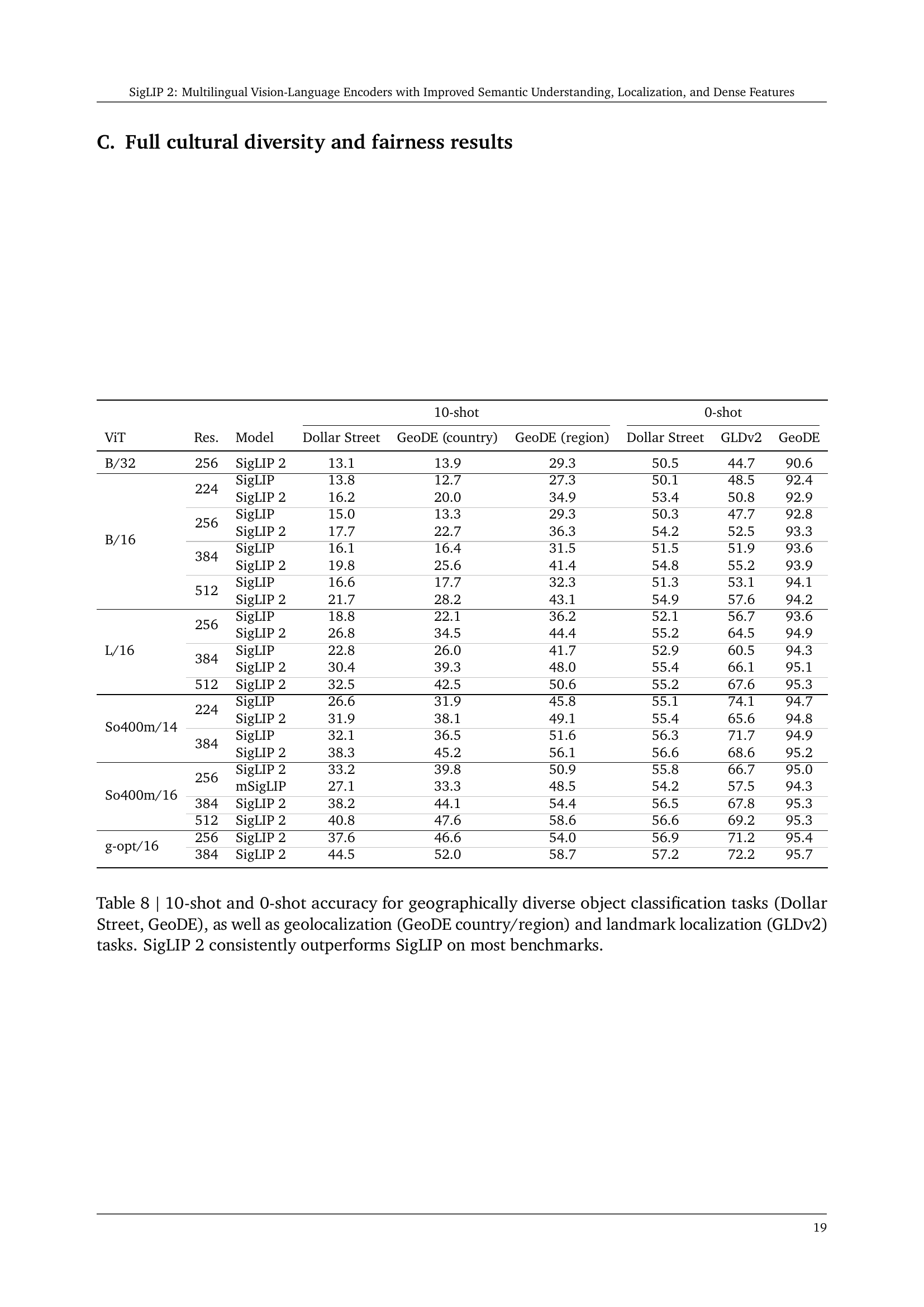
| 10-shot | 0-shot | |||||||
| ViT | Res. | Model | Dollar Street | GeoDE (country) | GeoDE (region) | Dollar Street | GLDv2 | GeoDE |
| B/32 | 256 | SigLIP 2 | 13.1 | 13.9 | 29.3 | 50.5 | 44.7 | 90.6 |
| B/16 | 224 | SigLIP | 13.8 | 12.7 | 27.3 | 50.1 | 48.5 | 92.4 |
| SigLIP 2 | 16.2 | 20.0 | 34.9 | 53.4 | 50.8 | 92.9 | ||
| 256 | SigLIP | 15.0 | 13.3 | 29.3 | 50.3 | 47.7 | 92.8 | |
| SigLIP 2 | 17.7 | 22.7 | 36.3 | 54.2 | 52.5 | 93.3 | ||
| 384 | SigLIP | 16.1 | 16.4 | 31.5 | 51.5 | 51.9 | 93.6 | |
| SigLIP 2 | 19.8 | 25.6 | 41.4 | 54.8 | 55.2 | 93.9 | ||
| 512 | SigLIP | 16.6 | 17.7 | 32.3 | 51.3 | 53.1 | 94.1 | |
| SigLIP 2 | 21.7 | 28.2 | 43.1 | 54.9 | 57.6 | 94.2 | ||
| L/16 | 256 | SigLIP | 18.8 | 22.1 | 36.2 | 52.1 | 56.7 | 93.6 |
| SigLIP 2 | 26.8 | 34.5 | 44.4 | 55.2 | 64.5 | 94.9 | ||
| 384 | SigLIP | 22.8 | 26.0 | 41.7 | 52.9 | 60.5 | 94.3 | |
| SigLIP 2 | 30.4 | 39.3 | 48.0 | 55.4 | 66.1 | 95.1 | ||
| 512 | SigLIP 2 | 32.5 | 42.5 | 50.6 | 55.2 | 67.6 | 95.3 | |
| So400m/14 | 224 | SigLIP | 26.6 | 31.9 | 45.8 | 55.1 | 74.1 | 94.7 |
| SigLIP 2 | 31.9 | 38.1 | 49.1 | 55.4 | 65.6 | 94.8 | ||
| 384 | SigLIP | 32.1 | 36.5 | 51.6 | 56.3 | 71.7 | 94.9 | |
| SigLIP 2 | 38.3 | 45.2 | 56.1 | 56.6 | 68.6 | 95.2 | ||
| So400m/16 | 256 | SigLIP 2 | 33.2 | 39.8 | 50.9 | 55.8 | 66.7 | 95.0 |
| mSigLIP | 27.1 | 33.3 | 48.5 | 54.2 | 57.5 | 94.3 | ||
| 384 | SigLIP 2 | 38.2 | 44.1 | 54.4 | 56.5 | 67.8 | 95.3 | |
| 512 | SigLIP 2 | 40.8 | 47.6 | 58.6 | 56.6 | 69.2 | 95.3 | |
| g-opt/16 | 256 | SigLIP 2 | 37.6 | 46.6 | 54.0 | 56.9 | 71.2 | 95.4 |
| 384 | SigLIP 2 | 44.5 | 52.0 | 58.7 | 57.2 | 72.2 | 95.7 | |
🔼 Table 8 presents a comprehensive evaluation of SigLIP 2 and SigLIP’s performance on geographically diverse object classification and localization tasks. It shows the 10-shot and 0-shot accuracy across three datasets: Dollar Street (measuring overall accuracy), GeoDE (assessing accuracy by country and region), and GLDv2 (evaluating landmark localization accuracy). The results demonstrate SigLIP 2’s consistent superior performance compared to SigLIP across various benchmarks, showcasing its improved capabilities in handling diverse geographic and cultural contexts.
read the caption
Table 8: 10-shot and 0-shot accuracy for geographically diverse object classification tasks (Dollar Street, GeoDE), as well as geolocalization (GeoDE country/region) and landmark localization (GLDv2) tasks. SigLIP 2 consistently outperforms SigLIP on most benchmarks.
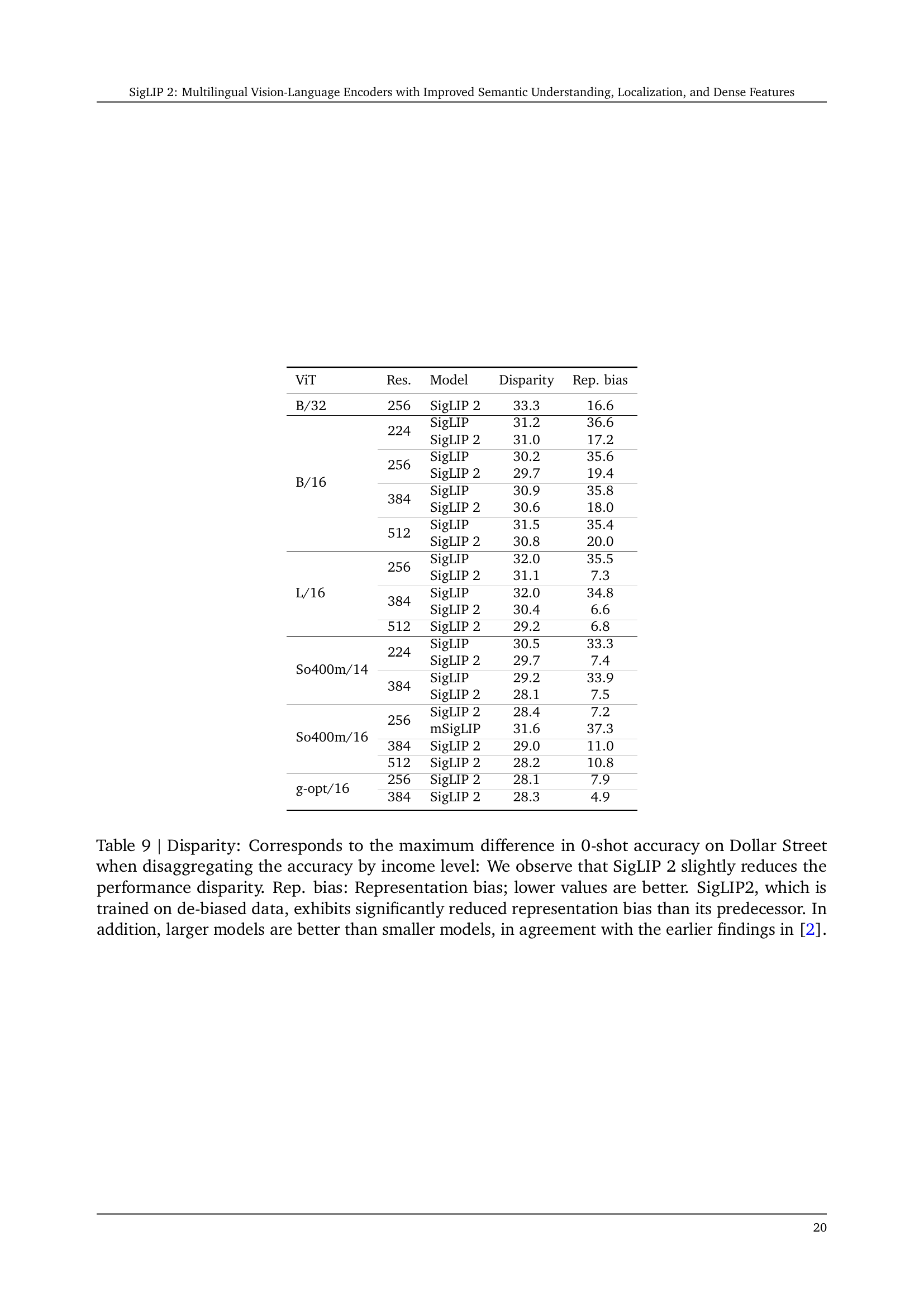
| ViT | Res. | Model | Disparity | Rep. bias |
| B/32 | 256 | SigLIP 2 | 33.3 | 16.6 |
| B/16 | 224 | SigLIP | 31.2 | 36.6 |
| SigLIP 2 | 31.0 | 17.2 | ||
| 256 | SigLIP | 30.2 | 35.6 | |
| SigLIP 2 | 29.7 | 19.4 | ||
| 384 | SigLIP | 30.9 | 35.8 | |
| SigLIP 2 | 30.6 | 18.0 | ||
| 512 | SigLIP | 31.5 | 35.4 | |
| SigLIP 2 | 30.8 | 20.0 | ||
| L/16 | 256 | SigLIP | 32.0 | 35.5 |
| SigLIP 2 | 31.1 | 7.3 | ||
| 384 | SigLIP | 32.0 | 34.8 | |
| SigLIP 2 | 30.4 | 6.6 | ||
| 512 | SigLIP 2 | 29.2 | 6.8 | |
| So400m/14 | 224 | SigLIP | 30.5 | 33.3 |
| SigLIP 2 | 29.7 | 7.4 | ||
| 384 | SigLIP | 29.2 | 33.9 | |
| SigLIP 2 | 28.1 | 7.5 | ||
| So400m/16 | 256 | SigLIP 2 | 28.4 | 7.2 |
| mSigLIP | 31.6 | 37.3 | ||
| 384 | SigLIP 2 | 29.0 | 11.0 | |
| 512 | SigLIP 2 | 28.2 | 10.8 | |
| g-opt/16 | 256 | SigLIP 2 | 28.1 | 7.9 |
| 384 | SigLIP 2 | 28.3 | 4.9 |
🔼 Table 9 presents a detailed analysis of the impact of SigLIP 2 on cultural diversity and fairness. It focuses on two key metrics: disparity and representation bias. Disparity measures the difference in 0-shot accuracy on the Dollar Street dataset when comparing different income levels. Lower disparity indicates better fairness, as the model’s performance is less dependent on income. Representation bias assesses the tendency of the model to associate an object (e.g., cars) with a particular gender. Lower representation bias reflects a more equitable and unbiased model. The table shows these metrics for various SigLIP 2 models of different sizes (ViT-B/32, B/16, L/16, So400m/14, So400m/16, g-opt/16) and resolutions. It also includes results for the original SigLIP model for comparison. The results demonstrate that SigLIP 2, particularly larger models trained on de-biased data, significantly reduces representation bias and shows slightly improved disparity, aligning with the findings presented earlier in the paper.
read the caption
Table 9: Disparity: Corresponds to the maximum difference in 0-shot accuracy on Dollar Street when disaggregating the accuracy by income level: We observe that SigLIP 2 slightly reduces the performance disparity. Rep. bias: Representation bias; lower values are better. SigLIP2, which is trained on de-biased data, exhibits significantly reduced representation bias than its predecessor. In addition, larger models are better than smaller models, in agreement with the earlier findings in [2].
Full paper#