TL;DR#
Personalizing video models to capture dynamic concepts has been a challenge because videos introduce a temporal dimension and concepts encompass both appearance and motion. Current methods fail to generalize across contexts or support meaningful composition. The paper introduces Set-and-Sequence, a framework for personalizing video models with dynamic concepts. It imposes a spatio-temporal weight space within Diffusion Transformers.
Set-and-Sequence fine-tunes Low-Rank Adaptation layers using an unordered set of frames to learn an appearance identity, free from temporal interference. Then, it augments these coefficients with Motion Residuals, fine-tuning them on the full video sequence to capture motion dynamics. This enables unprecedented editability and compositionality, setting a new benchmark for personalizing dynamic concepts.
Key Takeaways#
Why does it matter?#
This paper is important for researchers because it presents a novel approach to personalizing video generation models, addressing limitations of current methods in capturing dynamic concepts. The Set-and-Sequence framework and the concept of spatiotemporal weight space pave the way for more realistic and controllable video editing and composition, opening new research directions in generative video modeling and content creation.
Visual Insights#

🔼 Figure 1 demonstrates the personalization of a video generation model to capture dynamic concepts. The left panel shows examples of dynamic concepts, such as ocean waves and a bonfire, which are defined by both their visual appearance and characteristic motion patterns. The right panel illustrates the high-fidelity generation, editing, and composition capabilities enabled by this personalization. It shows how these dynamic elements can be seamlessly integrated into a single video, interacting naturally with each other.
read the caption
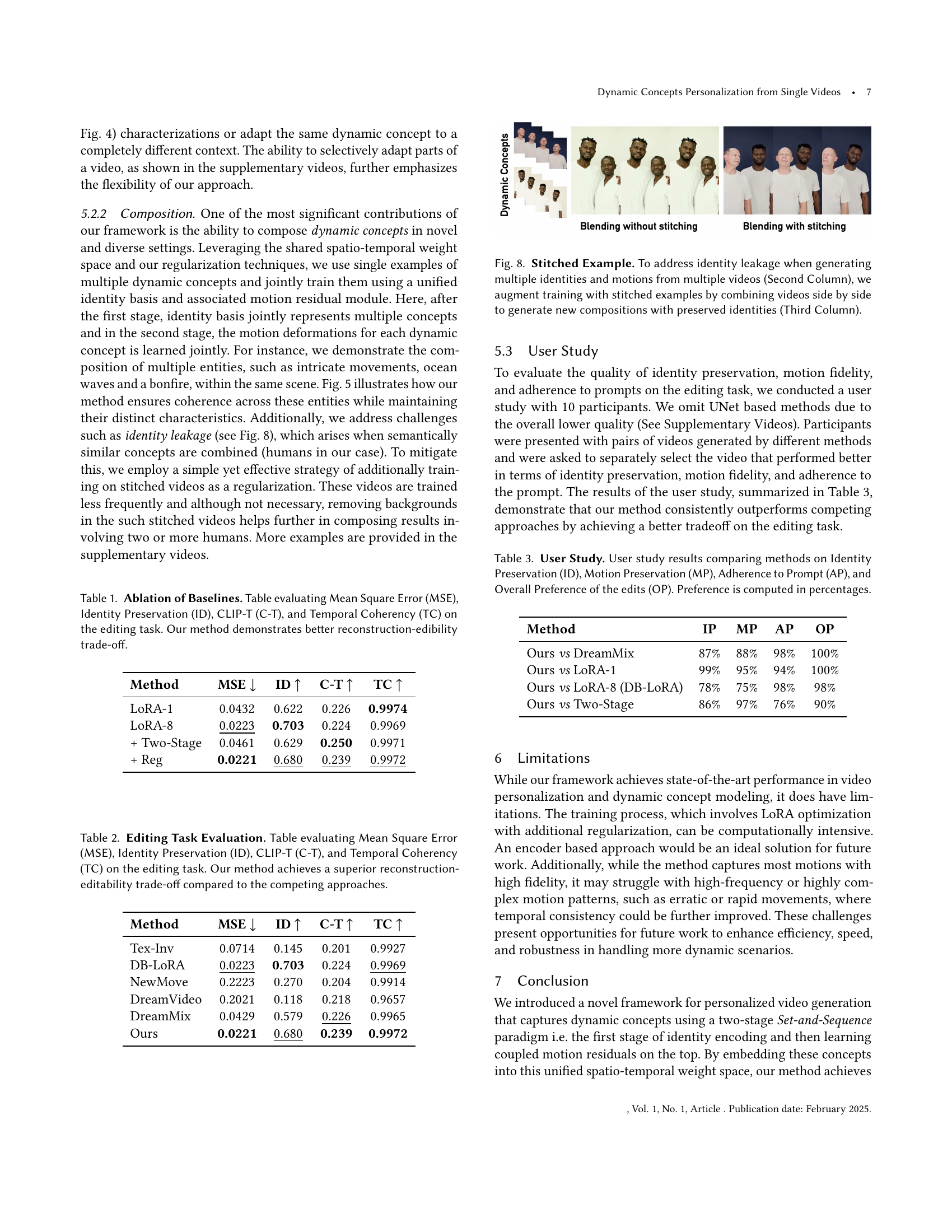
Figure 1. We personalize a video model to capture dynamic concepts – entities defined not only by their appearance but also by their unique motion patterns, such as the fluid motion of ocean waves or the flickering dynamics of a bonfire (left). This enables high-fidelity generation, editing, and the composition of these dynamic elements into a single video, where they interact naturally (right).
| Method | MSE | ID | C-T | TC |
|---|---|---|---|---|
| LoRA-1 | 0.0432 | 0.622 | 0.226 | 0.9974 |
| LoRA-8 | 0.0223 | 0.703 | 0.224 | 0.9969 |
| + Two-Stage | 0.0461 | 0.629 | 0.250 | 0.9971 |
| + Reg | 0.0221 | 0.680 | 0.239 | 0.9972 |
🔼 This table presents an ablation study comparing the performance of different baselines and the proposed method on a video editing task. The metrics used to evaluate the models are Mean Squared Error (MSE) to measure reconstruction quality, Identity Preservation (ID) to assess how well the model maintains the identity of the subject, CLIP-Text similarity (C-T) to gauge the semantic alignment between the generated video and the input text prompt, and Temporal Coherency (TC) to evaluate the smoothness of motion in the video. The table shows that the proposed method achieves a better balance between the quality of the reconstruction and the ability to edit and adapt the video content, which is represented by the Identity and Temporal Coherency metrics.
read the caption
Table 1. Ablation of Baselines. Table evaluating Mean Square Error (MSE), Identity Preservation (ID), CLIP-T (C-T), and Temporal Coherency (TC) on the editing task. Our method demonstrates better reconstruction-edibility trade-off.
In-depth insights#
Dynamic Motion LoRA#
Dynamic Motion LoRA could refer to a Low-Rank Adaptation (LoRA) technique specifically designed to capture and manipulate the dynamic aspects of motion within videos. This may involve training separate LoRA modules to disentangle and control different motion styles or patterns. One could envision a framework where a base LoRA captures the static appearance, and then a series of motion-specific LoRAs additively layer on top, enabling fine-grained control over movement. Careful regularization and conditioning would be required to prevent motion artifacts and ensure temporal coherence. The effectiveness would likely hinge on the choice of architecture, loss functions, and the composition strategy of combining static and dynamic LoRAs.
Set-and-Sequence#
The ‘Set-and-Sequence’ framework seems to tackle the challenge of personalizing video generation models to capture dynamic concepts, going beyond static image personalization. It likely involves a two-stage process. The ‘Set’ stage probably deals with learning the appearance of the concept from a collection of unordered frames, stripping out temporal information to get a clean representation. The ‘Sequence’ stage likely focuses on embedding motion dynamics by analyzing the full video sequence and refining the initial appearance representation, thus enabling edits and compositions while preserving the unique motion characteristics. This approach appears to address limitations in existing methods that struggle to disentangle appearance and motion, resulting in more robust and adaptable video personalization.
Motion Residuals#
Motion Residuals are a crucial element in video personalization, enabling the capture of dynamic concepts. Unlike static images, videos contain motion, requiring models to understand how objects move and change over time. By learning motion residuals, models can effectively disentangle appearance and motion, allowing for independent manipulation and composition. This is achieved by freezing the identity LoRAs and then augmenting their coefficients with motion residuals, which are fine-tuned on the full video sequence. This approach allows the model to capture the nuances of motion dynamics, leading to more realistic and controllable video generation. Incorporating motion residuals is essential for advanced video editing and synthesis tasks.
DiT Spatio-Temp#
DiT (Diffusion Transformer) for Spatio-Temporal Data: DiT’s architecture handles video generation with high-quality. Unlike UNet, DiT processes spatial and temporal data, achieving high-fidelity video synthesis. It’s absence of innate inductive biases presents challenges for dynamic concept embedding. The architecture’s ability to effectively capture complex motions and interactions in videos remains a key area of research. Novel training frameworks are needed to capture both appearance and motion within a unified representation.
Video Personalization#
Video personalization is a burgeoning field aimed at tailoring video content to individual user preferences. Unlike static images, videos introduce the temporal dimension, posing unique challenges for personalization. Existing methods often leverage UNet-based architectures, which may suffer from limitations in capturing complex motion dynamics. Current approaches can be broadly categorized into stylization, motion transfer, and local editing. While stylization focuses on altering the visual appearance, motion transfer emphasizes extracting and applying motion patterns from different videos. Local editing, on the other hand, targets specific parts of a single video for modification. The central challenge involves disentangling appearance and motion while ensuring temporal coherence and contextual realism. Future research could explore novel architectures and learning techniques to overcome these limitations and unlock new possibilities for personalized video experiences, especially in applications such as content creation, education, and entertainment. Also, it is important to note that identity leakage is one of the many challanges of personalizing the video content.
More visual insights#
More on figures

🔼 The Set-and-Sequence framework is a two-stage process for personalizing video generation models with dynamic concepts. Stage 1, Identity Basis, focuses on appearance. It uses an unordered set of frames from the input video to train LoRA (Low-Rank Adaptation) layers. This training learns an ‘identity LoRA basis’ representing the appearance of the concept without temporal information. In Stage 2, Motion Residuals, the identity LoRAs are frozen. The coefficients are augmented using additional LoRAs trained on the full temporal sequence of the video. This captures the motion dynamics. The final result is a spatio-temporal weight space that effectively integrates both appearance and motion into the model, allowing for high-fidelity generation and editing.
read the caption
Figure 2. Set-and-Sequence framework operates in two stages: (i) Identity Basis: We train LoRA Set Encoding on a unordered set of frames extracted from the video, focusing only on the appearance of the dynamic concept to achieve high fidelity without temporal distractions. (ii) Motion Residuals: The Basis of the Identity LoRAs is frozen and the coefficient part is augmented with coefficients of LoRA Sequence Encoding trained on the temporal sequence of full video clip, allowing the model to capture the motion dynamics of the concept.

🔼 This figure demonstrates the capabilities of the Set-and-Sequence framework for editing personalized videos. The framework allows for both global edits (affecting the entire scene, such as changing the background or lighting) and local edits (focused changes, such as altering clothing or replacing an object). Importantly, these edits are performed while maintaining the original appearance and motion characteristics of the dynamic concept, ensuring high-fidelity results. The images show several examples of these edits being applied, highlighting the flexibility and precision of the method.
read the caption
Figure 3. Local and Global Editing. Our Set-and-Sequence framework enables text-driven edits of dynamic concepts while preserving both their appearance and motion. Edits can be global (e.g., background and lighting) or local (e.g., clothing and object replacement), ensuring high fidelity to the original dynamic concepts.

🔼 This figure demonstrates the stylization capabilities of the Set-and-Sequence framework. The top row showcases how merely adjusting the identity basis weights allows for stylizing the appearance of the dynamic concept (a person) without altering its motion. The bottom row shows the result of applying both stylization and motion editing to the same concept; this time, edits are text-driven, demonstrating how the framework facilitates precise control over both the appearance and motion of dynamic elements.
read the caption
Figure 4. Stylization. Top: Stylization of dynamic concepts achieved by reweighting the identity basis. Bottom: Stylization and motion editing performed using prompt derived from the video in the top row.

🔼 This figure demonstrates the ability of the Set-and-Sequence framework to seamlessly integrate multiple dynamic concepts into a single video. Each concept is color-coded for easy identification. The results showcase high-fidelity generation and editing capabilities, where different dynamic elements interact naturally. For a more complete view of these capabilities, please refer to the supplementary videos.
read the caption
Figure 5. Dynamic Concepts Composition. Composition results achieved by our framework showcasing seamless integration of dynamic concepts. with each concept color-coded for clarity. For a more comprehensive demonstration, refer to the supplementary videos.

🔼 This figure compares the performance of the proposed ‘Set-and-Sequence’ method against several baseline approaches on two video editing tasks. The tasks involve modifying a video to (1) change the subject’s background and shirt, and (2) add a glass to the scene. The baselines include NewMove, DreamVideo, DB-LoRA, and DreamMix. The comparison highlights the superior performance of the proposed method in adhering to the specified edits described in text prompts while maintaining the subject’s identity and producing higher quality results than other methods.
read the caption
Figure 6. Comparison with baselines. Comparison of our method with baseline approaches (NewMove (Materzyńska et al., 2024), DreamVideo (Wei et al., 2024), DB-LoRA (Ryu, 2023; Ruiz et al., 2023a), and DreamMix (Molad et al., 2023)) on two editing scenarios: changing the background and shirt, and adding a glass. Our method demonstrates superior adherence to the prompt while preserving the subject identity, outperforming the baselines.

🔼 This ablation study analyzes the impact of different LoRA ranks and the two-stage training approach on video editing. Using the task of changing a shirt and background, it demonstrates that low-rank LoRAs (LoRA-1) cause underfitting, missing crucial details, while high-rank LoRAs (LoRA-8) lead to overfitting, reducing adaptability. The results highlight that the proposed two-stage approach with regularization provides the best balance, maintaining both high fidelity and the capacity for edits.
read the caption
Figure 7. Ablation. Ablation of design choices on the editing task of adding a different shirt and background. Low-rank LoRA (LoRA-1) results in underfitting, failing to capture sufficient detail, while high-rank LoRA (LoRA-8) overfits, compromising adaptability. Our two-stage approach with added regularization achieves a balanced trade-off, preserving both fidelity and editability.
More on tables
| Method | MSE | ID | C-T | TC |
|---|---|---|---|---|
| Tex-Inv | 0.0714 | 0.145 | 0.201 | 0.9927 |
| DB-LoRA | 0.0223 | 0.703 | 0.224 | 0.9969 |
| NewMove | 0.2223 | 0.270 | 0.204 | 0.9914 |
| DreamVideo | 0.2021 | 0.118 | 0.218 | 0.9657 |
| DreamMix | 0.0429 | 0.579 | 0.226 | 0.9965 |
| Ours | 0.0221 | 0.680 | 0.239 | 0.9972 |
🔼 This table presents a quantitative comparison of different methods for video editing, focusing on the trade-off between reconstruction quality and the ability to edit videos successfully. It evaluates four metrics: Mean Square Error (MSE) to assess reconstruction quality, Identity Preservation (ID) to measure how well the identity of subjects is maintained after editing, CLIP-T (C-T) to evaluate the semantic alignment between the generated video and the input text prompt, and Temporal Coherency (TC) to assess the smoothness of motion and transitions. The results show that the proposed ‘Our method’ outperforms other methods by achieving a better balance between high reconstruction quality and effective editing capabilities.
read the caption
Table 2. Editing Task Evaluation. Table evaluating Mean Square Error (MSE), Identity Preservation (ID), CLIP-T (C-T), and Temporal Coherency (TC) on the editing task. Our method achieves a superior reconstruction-editability trade-off compared to the competing approaches.
| Method | IP | MP | AP | OP |
|---|---|---|---|---|
| Ours vs DreamMix | 87% | 88% | 98% | 100% |
| Ours vs LoRA-1 | 99% | 95% | 94% | 100% |
| Ours vs LoRA-8 (DB-LoRA) | 78% | 75% | 98% | 98% |
| Ours vs Two-Stage | 86% | 97% | 76% | 90% |
🔼 This table presents the results of a user study comparing different video editing methods. Ten participants evaluated each method based on four criteria: Identity Preservation (how well the method maintained the original identity of the subject in the video), Motion Preservation (how well the method maintained the original motion of the subject), Adherence to Prompt (how well the generated video matched the user’s specified edits), and Overall Preference (participants’ overall ranking of each method). The results are shown as percentages, indicating the proportion of participants who preferred a given method for each criterion.
read the caption
Table 3. User Study. User study results comparing methods on Identity Preservation (ID), Motion Preservation (MP), Adherence to Prompt (AP), and Overall Preference of the edits (OP). Preference is computed in percentages.
| Autoencoder | MAGVIT |
|---|---|
| Base channels | 16 |
| Channel multiplier | [1, 4, 16, 32, 64] |
| Encoder blocks count | [1, 1, 2, 8, 8] |
| Decoder blocks count | [4, 4, 4, 4, 4] |
| Stride of frame | [1, 2, 2, 2, 1] |
| Stride of h and w | [2, 2, 2, 2, 1] |
| Padding mode | replicate |
| Compression rate | |
| Bottleneck channels | 32 |
| Use KL divergence | ✓ |
| Use adaptive norm | ✓(decoder only) |
🔼 This table details the architecture and hyperparameters of the autoencoder and MAGVIT model used in the paper. It specifies parameters such as base channels, channel multiplier, the number of encoder and decoder blocks, stride of frames and spatial dimensions, padding mode, compression rate, bottleneck channels, and whether KL divergence or adaptive normalization were used. This information is crucial for understanding the model’s ability to compress video data into a lower-dimensional latent space, which is important for efficient processing by the diffusion model.
read the caption
Table 4. Autoencoder and MAGVIT specifications.
| Backbone | DiT |
|---|---|
| Input channels | 32 |
| Patch size | |
| Latent token channels | 4096 |
| Positional embeddings | 3D-RoPE |
| DiT blocks count | 32 |
| Attention heads count | 32 |
| Window size | 6144 (center) |
| Normalization | Layer normalization |
| Use flash attention | ✓ |
| Use QK-normalization | ✓ |
| Use self conditioning | ✓ |
| Self conditioning prob. | 0.9 |
| Context channels | 1024 |
🔼 This table details the architecture of the DiT (Diffusion Transformer) model used as the backbone for video generation in the paper. It lists specifications for various components including input channels, patch size, latent token channels, positional embeddings, the number of DiT blocks, attention heads, window size, normalization techniques used, flash attention, QK-normalization, self-conditioning probability, and the number of context channels.
read the caption
Table 5. Backbone and DiT specifications.
| Optimizer | AdamW |
|---|---|
| Learning rate | |
| LR scheduler | constant |
| Beta | [0.9, 0.99] |
| Weight decay | 0.01 |
| Gradient clipping | 0.05 |
| Dropout (Stage I) | 0.8 |
| Dropout (Stage II) | 0.5 |
🔼 Table 6 details the hyperparameters and settings used during the training process of the Set-and-Sequence model. It provides a comprehensive overview of the optimization strategy employed for both stages of training, including the optimizer used, learning rate schedule, beta parameters, weight decay, gradient clipping, and dropout rates. This information is crucial for understanding the model’s training process and the choices made to achieve optimal performance.
read the caption
Table 6. Training stages and optimization settings.
Full paper#