TL;DR#
Large language models (LLMs) with expanded vocabularies face efficiency challenges in speculative sampling, a technique used to accelerate the generation process. Existing methods struggle with the computational overhead of large vocabulary sizes, particularly in the Language Modeling (LM) Head, which becomes a bottleneck. Current solutions are also hindered by suboptimal implementation frameworks, obscuring the true impact of vocabulary size on performance.
To tackle these challenges, this paper introduces a novel approach called FR-Spec. FR-Spec optimizes the selection of draft candidates by compressing the vocabulary space, focusing on high-frequency tokens. This reduces the computational burden on the LM Head while ensuring the final output distribution remains consistent. The method involves detailed profiling to identify bottlenecks and an optimized implementation framework to ensure accurate evaluation. The results demonstrate that FR-Spec achieves significant speedups over existing methods.
Key Takeaways#
Why does it matter?#
This paper introduces FR-Spec, a novel method to accelerate LLMs, particularly in large-vocabulary scenarios. It offers a practical solution to a growing challenge and shows a way for future research in optimizing language model efficiency without compromising performance. The insights from the detailed profiling analysis are valuable for system-level optimizations in LLM deployment.
Visual Insights#

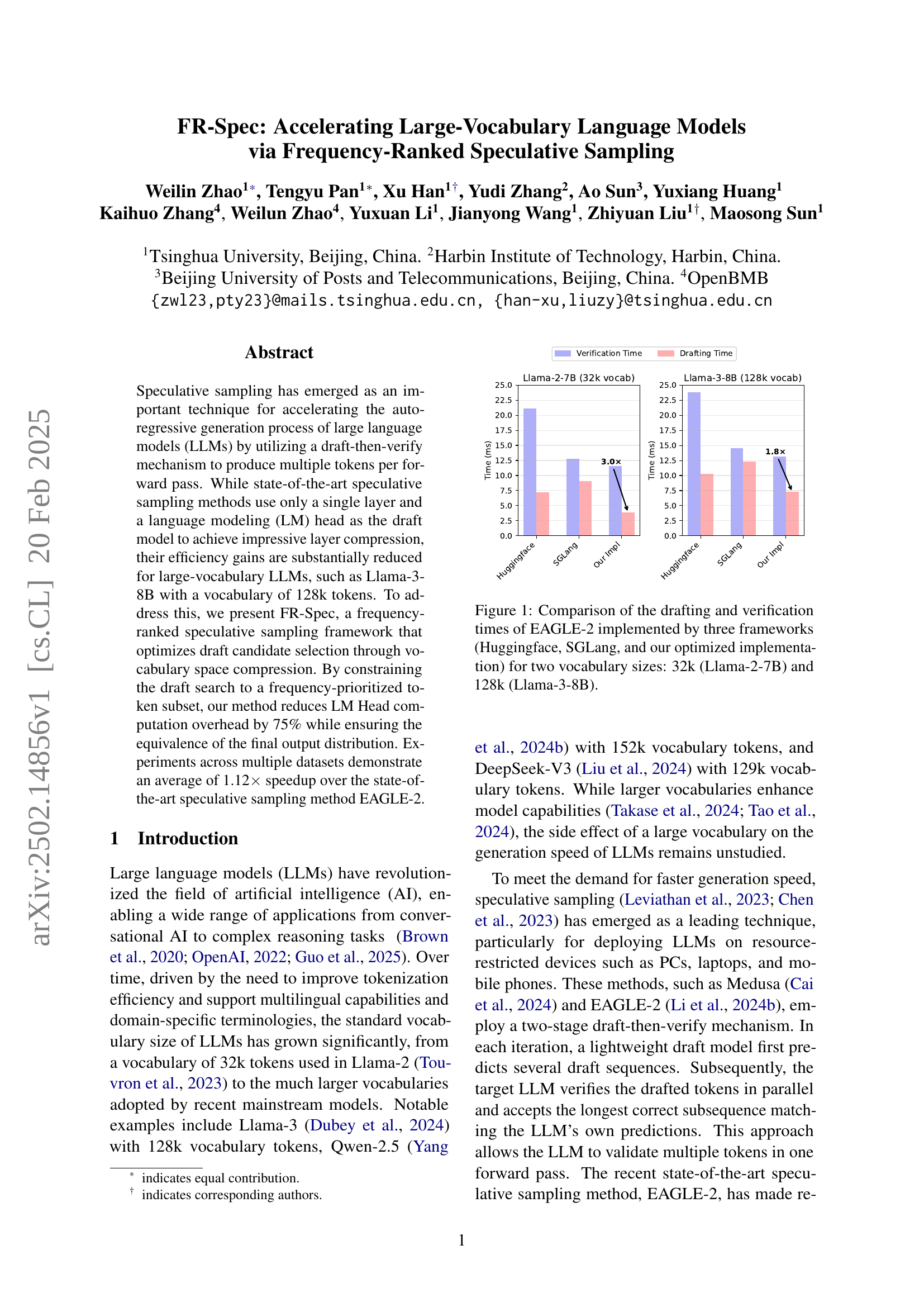
🔼 This figure compares the time spent on drafting and verification stages of the EAGLE-2 speculative sampling algorithm across three different implementations (Huggingface, SGLang, and an optimized implementation developed by the authors). The comparison is shown for two different vocabulary sizes: 32k (representing the Llama-2-7B model) and 128k (representing the Llama-3-8B model). The figure visually illustrates how the drafting and verification times change depending on the implementation and the vocabulary size of the language model. This helps to understand the computational bottlenecks and the effectiveness of the authors’ optimized implementation.
read the caption
Figure 1: Comparison of the drafting and verification times of EAGLE-2 implemented by three frameworks (Huggingface, SGLang, and our optimized implementation) for two vocabulary sizes: 32k (Llama-2-7B) and 128k (Llama-3-8B).
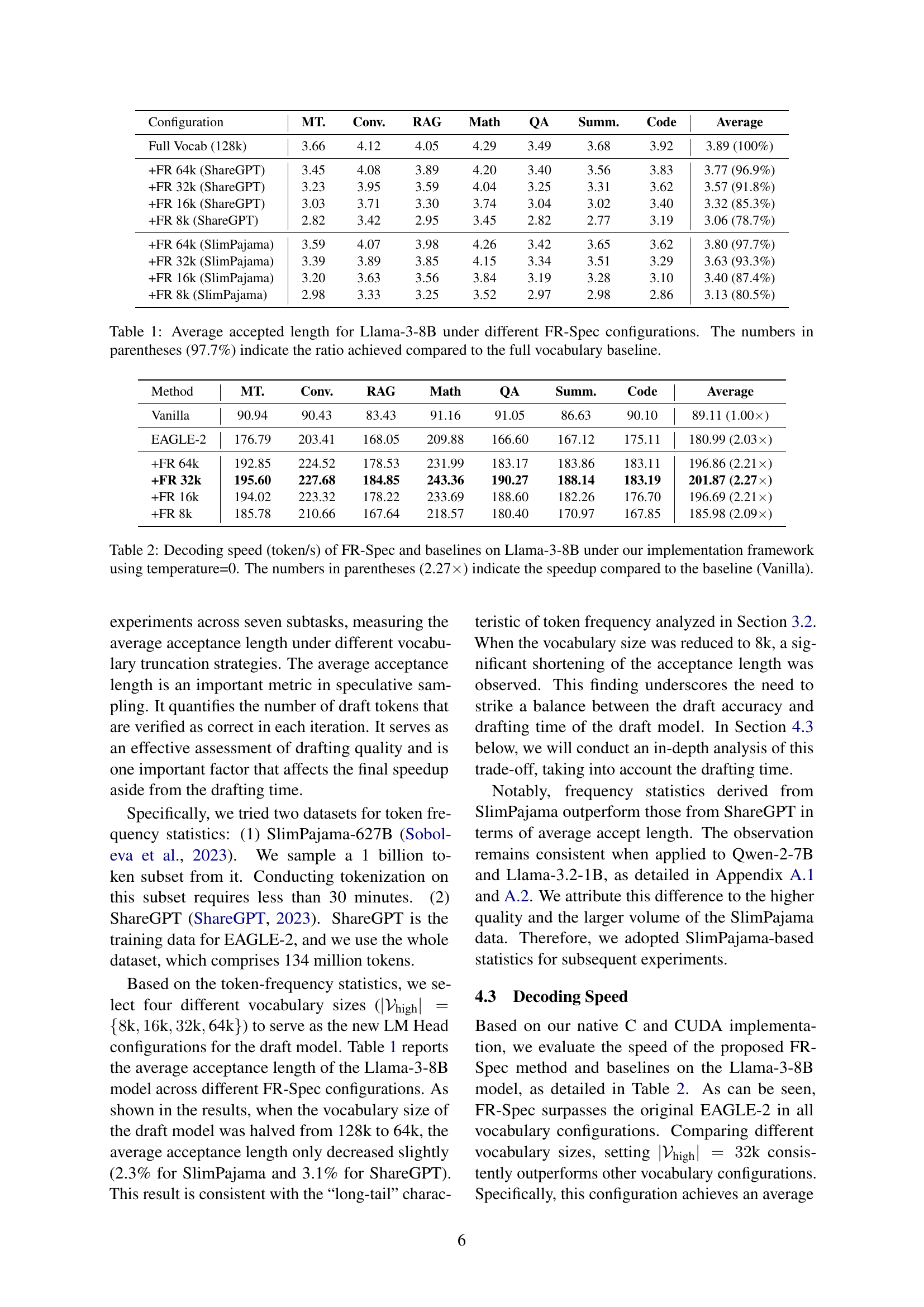
| Configuration | MT. | Conv. | RAG | Math | QA | Summ. | Code | Average |
| Full Vocab (128k) | 3.66 | 4.12 | 4.05 | 4.29 | 3.49 | 3.68 | 3.92 | 3.89 (100%) |
| +FR 64k (ShareGPT) | 3.45 | 4.08 | 3.89 | 4.20 | 3.40 | 3.56 | 3.83 | 3.77 (96.9%) |
| +FR 32k (ShareGPT) | 3.23 | 3.95 | 3.59 | 4.04 | 3.25 | 3.31 | 3.62 | 3.57 (91.8%) |
| +FR 16k (ShareGPT) | 3.03 | 3.71 | 3.30 | 3.74 | 3.04 | 3.02 | 3.40 | 3.32 (85.3%) |
| +FR 8k (ShareGPT) | 2.82 | 3.42 | 2.95 | 3.45 | 2.82 | 2.77 | 3.19 | 3.06 (78.7%) |
| +FR 64k (SlimPajama) | 3.59 | 4.07 | 3.98 | 4.26 | 3.42 | 3.65 | 3.62 | 3.80 (97.7%) |
| +FR 32k (SlimPajama) | 3.39 | 3.89 | 3.85 | 4.15 | 3.34 | 3.51 | 3.29 | 3.63 (93.3%) |
| +FR 16k (SlimPajama) | 3.20 | 3.63 | 3.56 | 3.84 | 3.19 | 3.28 | 3.10 | 3.40 (87.4%) |
| +FR 8k (SlimPajama) | 2.98 | 3.33 | 3.25 | 3.52 | 2.97 | 2.98 | 2.86 | 3.13 (80.5%) |
🔼 This table presents the average accepted length achieved by the FR-Spec model across various configurations with different vocabulary sizes. The results are shown for the Llama-3-8B language model and are broken down across seven tasks: Machine Translation (MT.), multi-turn conversation (Conv.), retrieval-augmented generation (RAG), arithmetic reasoning (Math), question answering (QA), document summarization (Summ.), and code generation (Code). Each row represents a different experiment with a varying number of high-frequency tokens used in the drafting process (indicated by +FR and the size of the vocabulary). The numbers in parentheses show the percentage of the average accepted length relative to the baseline using the full vocabulary. This allows for direct comparison across different vocabulary sizes and evaluation of the trade-off between reduced vocabulary size and maintained model performance.
read the caption
Table 1: Average accepted length for Llama-3-8B under different FR-Spec configurations. The numbers in parentheses (97.7%) indicate the ratio achieved compared to the full vocabulary baseline.
In-depth insights#
LM Head Bottleneck#
The LM Head bottleneck refers to the computational burden imposed by the Language Modeling (LM) Head in neural networks, especially within the context of speculative sampling. This bottleneck arises primarily due to the large vocabulary size of modern LLMs, where the LM Head projects the model’s hidden states into the vocabulary space. The computational cost of this projection, coupled with the subsequent softmax operation to obtain token probabilities, scales linearly with the vocabulary size. This can become a significant bottleneck, overshadowing the computational cost of the transformer layers themselves. The bottleneck is exacerbated in speculative sampling where the draft model, which is designed to be lightweight, often has a 1:1 ratio of transformer layers to LM Heads and is now the larger part of computational load. Optimizations for alleviating this bottleneck include vocabulary space compression techniques, such as frequency-ranked sampling, which reduce the vocabulary subset.
FR-Spec Design#
While the paper does not explicitly use the heading ‘FR-Spec Design,’ we can infer the design principles from the proposed ‘frequency-ranked speculative sampling’ framework (FR-Spec). The core idea revolves around optimizing draft candidate selection by compressing the vocabulary space. This is achieved by focusing the draft model on a frequency-prioritized subset of tokens, effectively reducing the computational overhead associated with the LM Head, especially crucial for large-vocabulary LLMs. The design ensures mathematical equivalence in the verification process, guaranteeing the final output distribution remains unaltered compared to standard speculative sampling. The design also includes a plug-and-play nature to ensure that it can be easily used with existing speculative sampling frameworks. In short, it uses frequency distribution for selecting the sub-vocabulary and preserving distribution.
C/CUDA EAGLE-2#
While the paper doesn’t explicitly have a section titled ‘C/CUDA EAGLE-2’, it details a significant reimplementation of the EAGLE-2 speculative sampling method in C and CUDA. The original EAGLE-2 relied on Python’s PyTorch, introducing overhead due to dynamic typing and interpretation. Switching to C/CUDA allowed for direct memory management, preallocation, and optimized operator implementations, notably modified FlashAttention for tree attention masks. This shift significantly reduced latency, streamlining execution, and facilitated a more accurate profiling of bottlenecks. The transition to C/CUDA exposed the LM Head as the primary bottleneck, a finding obscured by Python overhead in the original implementation, highlighting the importance of low-level optimization in analyzing and improving LLM inference.
SlimPajama > GPT#
While “SlimPajama > GPT” isn’t a direct heading from the paper, it sparks interesting thoughts. It suggests comparing the SlimPajama dataset, used for token frequency analysis, with the datasets used to train OpenAI’s GPT models. SlimPajama, being a cleaned and deduplicated version of RedPajama, likely offers a more controlled and potentially higher-quality dataset for pre-training or fine-tuning language models, as seen in the paper. The implication is that models trained on SlimPajama or similar datasets might exhibit improved characteristics compared to those trained on GPT datasets, particularly in terms of reducing biases or improving generalization. The paper leverages SlimPajama to guide vocabulary selection, impacting efficiency; this highlights the significance of dataset composition. The comparison also prompts questions about the trade-offs between data size and data quality. While GPT datasets are vast, SlimPajama demonstrates the power of carefully curated data in achieving effective results within specific constraints. It underscores the importance of dataset engineering in the LLM landscape.
No Adaptability#
Lack of adaptability in language models can significantly hinder their performance across diverse tasks and evolving environments. Models trained on specific datasets or tasks often struggle to generalize to new scenarios, requiring extensive fine-tuning or retraining. This inflexibility can be attributed to the static nature of their learned representations, which fail to capture the dynamic nuances of language and context. Moreover, the absence of efficient mechanisms for incorporating new knowledge or adapting to shifting user preferences limits their real-world applicability. Overcoming this limitation necessitates the development of more flexible and adaptive architectures that can seamlessly integrate new information and adjust their behavior based on evolving contexts.
More visual insights#
More on figures

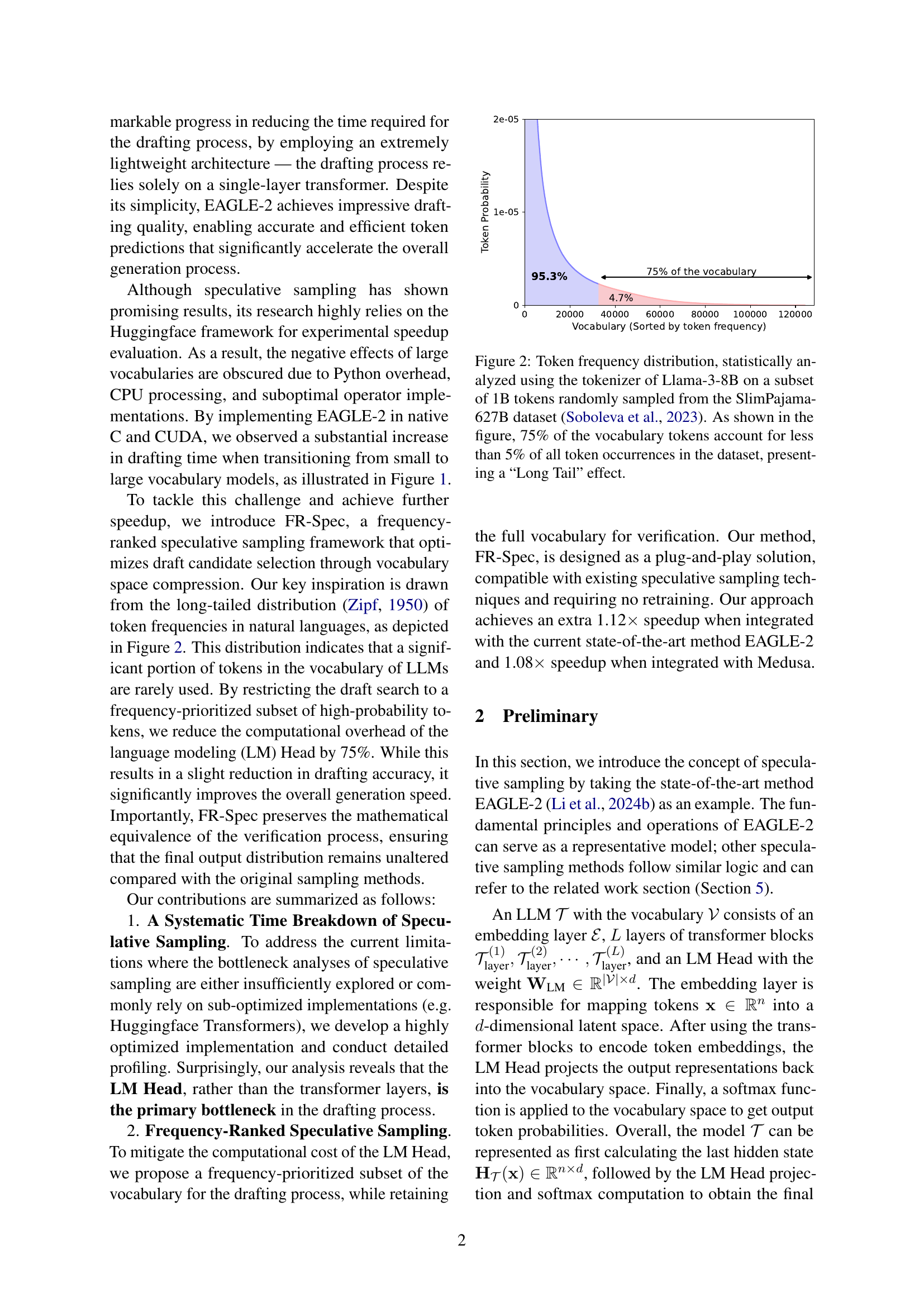
🔼 This figure shows the distribution of token frequencies in the Llama-3-8B vocabulary. The data was obtained by analyzing one billion tokens randomly selected from the SlimPajama-627B dataset. The distribution exhibits a long-tail effect, meaning that a small percentage of tokens (25%) account for most (95%) of the token occurrences in the dataset, while the vast majority of tokens (75%) are very rarely used. This uneven distribution highlights the sparsity in the vocabulary.
read the caption
Figure 2: Token frequency distribution, statistically analyzed using the tokenizer of Llama-3-8B on a subset of 1B tokens randomly sampled from the SlimPajama-627B dataset Soboleva et al. (2023). As shown in the figure, 75% of the vocabulary tokens account for less than 5% of all token occurrences in the dataset, presenting a “Long Tail” effect.

🔼 Figure 3 illustrates the drafting processes of both EAGLE-2 and FR-Spec. The left panel shows EAGLE-2’s drafting process with a prompt of ‘It’, a beam width of 2, and a search depth of 3. The model generates a draft tree by selecting the top 8 most probable tokens (shown in purple). The right panel displays FR-Spec’s modification to this process. FR-Spec optimizes the drafting process by removing the LM Head (Language Model Head), thereby reducing computational cost while maintaining the beam search methodology unchanged from EAGLE-2. The verification process remains identical between both methods.
read the caption
Figure 3: (Left) The drafting process of EAGLE-2 when promptP=𝑃absent~{}P=italic_P =“It”, beam width=2𝑤𝑖𝑑𝑡ℎ2width=2italic_w italic_i italic_d italic_t italic_h = 2 and search depth=3𝑑𝑒𝑝𝑡ℎ3depth=3italic_d italic_e italic_p italic_t italic_h = 3. It picks out the top K=8𝐾8K=8italic_K = 8 probability tokens (purple) as the draft tree. (Right) The drafting process of FR-Spec, where the LM Head is cropped during the drafting process while the beam search procedure remains the same.

🔼 This figure illustrates the verification process used in both EAGLE-2 and FR-Spec. It shows how the target LLM (the full model) verifies the candidate token sequences generated by the draft model (a smaller, faster model) during speculative sampling. The key difference is that FR-Spec uses a reduced vocabulary in its draft model, impacting the drafting process’s speed and efficiency without changing the verification process. The figure visually demonstrates how an attention mask is used to selectively attend to the valid draft tokens. This mask helps direct the LLM’s attention, ensuring the mathematical equivalence of the output distribution to the original method and enabling the verification process to be consistent across methods.
read the caption
Figure 4: The illustration of the verification process for EAGLE-2 and FR-Spec, given the draft in Figure 3. FR-Spec solely modifies the drafting process while the verification process remains consistent with EAGLE-2.

🔼 This figure compares the performance of Python-based and C-based implementations for three short-duration computational tasks (labeled X, Y, and Z) within the speculative sampling framework. It highlights the performance overhead introduced by Python’s interpreted nature, showcasing the significant speed improvements achieved through native C and CUDA implementations. This is done to isolate the core algorithmic performance from the implementation-related overhead in order to get accurate performance analysis of speculative sampling.
read the caption
Figure 5: Comparison of Python-based implementation and C-based implementation. X, Y, and Z represent three different short-duration computational tasks.

🔼 This figure shows a breakdown of the time spent during the drafting process in the EAGLE-2 speculative sampling method. It compares the time spent on different components of the model for two different LLMs: Llama-2-7B (with a 32k vocabulary) and Llama-3-8B (with a 128k vocabulary). The breakdown shows the proportion of time spent on embedding, the transformer layers, and the LM head (including softmax). It highlights how the computational bottleneck shifts from the transformer layers in Llama-2-7B to the LM Head in Llama-3-8B as the vocabulary size increases, emphasizing the impact of vocabulary size on the drafting process efficiency.
read the caption
Figure 6: Time breakdown of the drafting process of EAGLE-2. We profile the EAGLE-2 trained on Llama-2-7B (32k vocabulary) and the EAGLE-2 trained on Llama-3-8B (128k vocabulary).

🔼 This figure compares the decoding speed, measured in tokens per second, of the FR-Spec method and the EAGLE-2 baseline when used with Llama-3-8B, a large language model. The comparison is done across different implementation frameworks: Hugging Face, SGLang, and a custom-optimized implementation. The results show the significant speed improvements achieved by FR-Spec in all three frameworks, demonstrating the effectiveness of the proposed method.
read the caption
Figure 7: Decoding speed (token/s) of FR-Spec and EAGLE-2 for Llama-3-8B under different frameworks.

🔼 This figure compares the decoding speed, measured in tokens per second, of the FR-Spec model and the baseline EAGLE-2 model for the Llama-3.2-1B language model. The comparison is made across three different implementation frameworks: Huggingface, SGLang, and a custom optimized implementation developed by the authors. The chart visually represents the performance gains achieved by FR-Spec over EAGLE-2 within each framework, illustrating the impact of different implementation choices on speed improvements. It showcases FR-Spec’s significant speedup, especially when compared to the Huggingface and SGLang implementations of EAGLE-2.
read the caption
Figure 8: Decoding speed (token/s) of FR-Spec and EAGLE-2 for Llama-3.2-1B under different implementation framework.
More on tables
| Method | MT. | Conv. | RAG | Math | QA | Summ. | Code | Average |
| Vanilla | 90.94 | 90.43 | 83.43 | 91.16 | 91.05 | 86.63 | 90.10 | 89.11 (1.00) |
| EAGLE-2 | 176.79 | 203.41 | 168.05 | 209.88 | 166.60 | 167.12 | 175.11 | 180.99 (2.03) |
| +FR 64k | 192.85 | 224.52 | 178.53 | 231.99 | 183.17 | 183.86 | 183.11 | 196.86 (2.21) |
| +FR 32k | 195.60 | 227.68 | 184.85 | 243.36 | 190.27 | 188.14 | 183.19 | 201.87 (2.27) |
| +FR 16k | 194.02 | 223.32 | 178.22 | 233.69 | 188.60 | 182.26 | 176.70 | 196.69 (2.21) |
| +FR 8k | 185.78 | 210.66 | 167.64 | 218.57 | 180.40 | 170.97 | 167.85 | 185.98 (2.09) |
🔼 This table presents the decoding speed, measured in tokens per second, for different methods on the Llama-3-8B language model. The methods compared include a vanilla autoregressive decoding approach, EAGLE-2 (a state-of-the-art speculative sampling method), and EAGLE-2 enhanced with FR-Spec (the proposed frequency-ranked speculative sampling method) at various vocabulary sizes. The speed is evaluated using temperature=0. The table shows the speedup factor achieved by each method compared to the vanilla autoregressive decoding. The speedup factors indicate how much faster the methods are compared to the standard vanilla approach.
read the caption
Table 2: Decoding speed (token/s) of FR-Spec and baselines on Llama-3-8B under our implementation framework using temperature=0. The numbers in parentheses (2.27×\times×) indicate the speedup compared to the baseline (Vanilla).
| Benchmark | Vanilla | EAGLE-2 | EAGLE-2(+FR 32k) | ||
| token/s | token/s | Speedup | token/s | Speedup | |
| MT. | 90.32 | 171.03 | 1.89 | 188.69 | 2.09 |
| Conv. | 89.85 | 187.95 | 2.09 | 212.08 | 2.36 |
| RAG | 83.18 | 159.37 | 1.92 | 178.64 | 2.15 |
| Math | 89.75 | 196.34 | 2.19 | 237.96 | 2.65 |
| QA | 90.58 | 155.10 | 1.71 | 182.59 | 2.02 |
| Summ. | 87.41 | 158.72 | 1.82 | 182.70 | 2.09 |
| Code | 89.77 | 180.67 | 2.01 | 183.54 | 2.04 |
| Average | 88.69 | 172.74 | 1.95 | 195.17 | 2.20 |
🔼 This table presents the decoding speed, measured in tokens per second, for the Llama-3-8B language model under different conditions. It compares the vanilla autoregressive decoding method against EAGLE-2 and FR-Spec (integrated with EAGLE-2), using both our optimized implementation and the Huggingface and SGLang frameworks. The results are shown for several tasks and using a temperature of 1 during generation, highlighting the speed improvements achieved by the speculative sampling methods, particularly FR-Spec, across different implementations.
read the caption
Table 3: Decoding speed (token/s) of Llama-3-8B using temperature=1 under our implementation.
| Huggingface | Our Implementation | ||||
| Benchmark | Temp | Vanilla | EAGLE-2 | Vanilla | FR-Spec |
| HumanEval | 0 | 54.9 | 54.9 | 57.3 | 58.5 |
| 1 | 51.01.4 | 50.63.1 | 51.11.2 | 51.21.2 | |
| GSM8K | 0 | 76.8 | 77.0 | 76.3 | 76.1 |
| 1 | 70.82.0 | 66.52.9 | 65.61.8 | 67.10.8 | |
🔼 This table presents the performance comparison of Llama-3-8B model across two different implementations (Huggingface and the authors’ optimized implementation) on two tasks: math reasoning (GSM8K) and code generation (HumanEval). The results are shown for both greedy decoding (temperature=0) and random sampling (temperature=1). Due to the inherent randomness of random sampling, the average score and variance (across 5 different runs with different random seeds) are reported for temperature=1, while the single deterministic result is presented for temperature=0.
read the caption
Table 4: Performance of the Llama-3-8B model on math reasoning and code generation tasks across two implementation frameworks. Due to variability in results with temperature=1, we report the average scores and variance across five different random seeds.
| Benchmark | Vanilla | Medusa | Medusa (+FR 32k) | ||
| token/s | token/s | Speedup | token/s | Speedup | |
| MT. | 90.94 | 146.42 | 1.61 | 157.54 | 1.73 |
| Conv. | 90.43 | 157.99 | 1.75 | 169.26 | 1.87 |
| RAG | 83.43 | 130.56 | 1.56 | 139.62 | 1.67 |
| Math | 91.16 | 160.95 | 1.77 | 174.56 | 1.91 |
| QA | 91.05 | 138.92 | 1.53 | 151.07 | 1.66 |
| Summ. | 86.63 | 130.08 | 1.50 | 141.39 | 1.63 |
| Code | 90.10 | 152.57 | 1.69 | 161.28 | 1.79 |
| Average | 89.11 | 145.36 | 1.63 | 156.39 | 1.76 |
🔼 This table presents the decoding speed, measured in tokens per second, for the Llama-3-8B language model using the Medusa speculative sampling method with temperature set to 0. The results show the decoding speed under different configurations, demonstrating the performance improvement achieved by integrating the FR-Spec optimization into the Medusa framework. The benchmarks include various tasks such as machine translation (MT), conversation (Conv), retrieval-augmented generation (RAG), mathematical reasoning (Math), question answering (QA), summarization (Summ.), and code generation (Code).
read the caption
Table 5: Decoding speed (token/s) of Llama-3-8B using temperature=0 under our implemented Medusa.
| Configuration | MT. | Conv. | RAG | Math | QA | Summ. | Code | Average |
| Full Vocab (152k) | 2.90 | 4.06 | 3.65 | 4.31 | 3.27 | 3.74 | 4.22 | 3.74 (100%) |
| +FR 64k (ShareGPT) | 2.86 | 3.98 | 3.65 | 4.22 | 3.23 | 3.67 | 4.17 | 3.68 (98.6%) |
| +FR 32k (ShareGPT) | 2.76 | 3.90 | 3.42 | 4.10 | 3.24 | 3.39 | 3.98 | 3.54 (94.8%) |
| +FR 16k (ShareGPT) | 2.62 | 3.64 | 3.20 | 3.85 | 2.99 | 3.08 | 3.71 | 3.30 (88.3%) |
| +FR 8k (ShareGPT) | 2.45 | 3.39 | 3.01 | 3.60 | 2.48 | 2.81 | 3.41 | 3.02 (80.9%) |
| +FR 64k (SlimPajama) | 2.90 | 3.97 | 3.64 | 4.29 | 3.28 | 3.73 | 3.98 | 3.69 (98.6%) |
| +FR 32k (SlimPajama) | 2.83 | 3.73 | 3.53 | 4.20 | 3.39 | 3.58 | 3.71 | 3.57 (95.4%) |
| +FR 16k (SlimPajama) | 2.67 | 3.50 | 3.33 | 3.95 | 3.25 | 3.35 | 3.40 | 3.35 (89.7%) |
| +FR 8k (SlimPajama) | 2.60 | 3.28 | 3.12 | 3.65 | 2.91 | 3.04 | 3.10 | 3.10 (83.0%) |
🔼 This table presents the average accepted lengths achieved using different FR-Spec configurations on the Qwen-2-7B language model. The accepted length represents the average number of draft tokens that are ultimately accepted as correct during the speculative sampling process. Different configurations utilize varying sizes of high-frequency vocabulary subsets (8k, 16k, 32k, and 64k tokens), obtained from both the ShareGPT and SlimPajama datasets, to assess the impact on the generation process’s accuracy and efficiency. Comparing these results against the full vocabulary (152k tokens) provides insights into the trade-off between vocabulary size reduction and maintaining accurate generations.
read the caption
Table 6: Average accepted length for Qwen-2-7B on under different FR-Spec configurations.
| Configuration | MT. | Conv. | RAG | Math | QA | Summ. | Code | Average |
| Full Vocab (128k) | 2.49 | 2.96 | 2.80 | 3.08 | 2.69 | 2.62 | 3.04 | 2.81 (100%) |
| +FR 64k (ShareGPT) | 2.43 | 2.93 | 2.75 | 3.05 | 2.67 | 2.58 | 2.98 | 2.77 (98.6%) |
| +FR 32k (ShareGPT) | 2.39 | 2.90 | 2.65 | 2.98 | 2.54 | 2.51 | 2.85 | 2.69 (95.7%) |
| +FR 16k (ShareGPT) | 2.34 | 2.78 | 2.56 | 2.88 | 2.42 | 2.42 | 2.75 | 2.59 (92.3%) |
| +FR 8k (ShareGPT) | 2.25 | 2.66 | 2.44 | 2.76 | 2.35 | 2.31 | 2.65 | 2.49 (88.6%) |
| +FR 64k (SlimPajama) | 2.47 | 2.92 | 2.78 | 3.07 | 2.68 | 2.61 | 2.88 | 2.77 (98.7%) |
| +FR 32k (SlimPajama) | 2.43 | 2.82 | 2.69 | 3.04 | 2.58 | 2.57 | 2.70 | 2.69 (95.8%) |
| +FR 16k (SlimPajama) | 2.38 | 2.72 | 2.62 | 2.91 | 2.51 | 2.50 | 2.58 | 2.60 (92.6%) |
| +FR 8k (SlimPajama) | 2.30 | 2.58 | 2.50 | 2.80 | 2.40 | 2.39 | 2.43 | 2.49 (88.5%) |
🔼 This table presents the average accepted length achieved by the Llama-3.2-1B language model under various FR-Spec configurations. The accepted length represents the average number of draft tokens that are verified as correct during each iteration of the speculative sampling process. Different configurations use varying sizes of high-frequency vocabulary subsets (8k, 16k, 32k, and 64k tokens) during drafting, while maintaining the full vocabulary for verification. The table compares these results to a baseline using the full 128k vocabulary. The results show the effect of reducing the vocabulary size for drafting on the average number of accepted tokens.
read the caption
Table 7: Average accepted length for Llama-3.2-1B on under different FR-Spec configurations.
| Method | MT. | Conv. | RAG | Math | QA | Summ. | Code | Average |
| Vanilla | 259.83 | 255.89 | 220.25 | 263.34 | 260.13 | 248.15 | 256.64 | 252.03 (1.00) |
| EAGLE-2 | 306.04 | 358.37 | 266.84 | 372.37 | 305.52 | 294.82 | 360.60 | 323.51 (1.28) |
| +FR 64k | 349.12 | 406.14 | 297.62 | 427.14 | 350.08 | 338.81 | 390.78 | 365.67 (1.45) |
| +FR 32k | 378.90 | 428.75 | 317.68 | 467.53 | 378.39 | 363.70 | 395.95 | 390.13 (1.55) |
| +FR 16k | 394.81 | 443.00 | 326.75 | 476.47 | 394.47 | 375.70 | 402.07 | 401.90 (1.59) |
| +FR 8k | 386.97 | 428.94 | 319.83 | 462.98 | 382.75 | 363.50 | 392.13 | 391.01 (1.55) |
🔼 Table 8 presents the decoding speed, measured in tokens per second, achieved by various methods on the Llama-3.2-1B language model. The methods compared include a vanilla autoregressive decoding approach, the EAGLE-2 speculative sampling method, and EAGLE-2 enhanced with FR-Spec (Frequency-Ranked Speculative Sampling) using different vocabulary subset sizes. The experiment employed a temperature of 0 and used token frequency statistics from the SlimPajama dataset. The speedup factors shown in parentheses represent the improvement relative to the vanilla autoregressive decoding baseline.
read the caption
Table 8: Decoding speed (token/s) of FR-Spec and other baselines on Llama-3.2-1B under our implementation using temperature=0 and SlimPajama token-frequency statistics. The numbers in parentheses (1.59×\times×) indicate the speedup compared to the baseline (Vanilla).
Full paper#