TL;DR#
The paper addresses the growing issue of misinformation, particularly in low-resource languages like Vietnamese, where existing fact-checking methods struggle with semantic nuances and complex linguistic structures. Current systems often trade accuracy for efficiency. To solve the problems, the authors introduces SemViQA, a novel Vietnamese fact-checking framework designed to improve both accuracy and speed. SemViQA addresses semantic ambiguity, homonyms, and complex linguistic structures, achieving state-of-the-art results on standard datasets.
SemViQA integrates Semantic-based Evidence Retrieval (SER) and Two-step Verdict Classification (TVC). SER combines TF-IDF for speed with a Question Answering Token Classifier (QATC) for semantic understanding. TVC uses a hierarchical approach with Focal Loss and Cross-Entropy Loss for robust classification. Two versions are presented: SemViQA Standard prioritizes accuracy, while SemViQA Faster emphasizes speed. Experiments on ISE-DSC01 and ViWikiFC datasets show SemViQA outperforms existing methods, with SemViQA Faster achieving a 7x speedup.
Key Takeaways#
Why does it matter?#
SemViQA sets a new benchmark in Vietnamese fact verification, offering a strong baseline for future research. Its component SER and TVC, offer insights for improving fact-checking systems, especially for low-resource languages. This work can inspire development of more accurate and efficient misinformation detection tools.
Visual Insights#

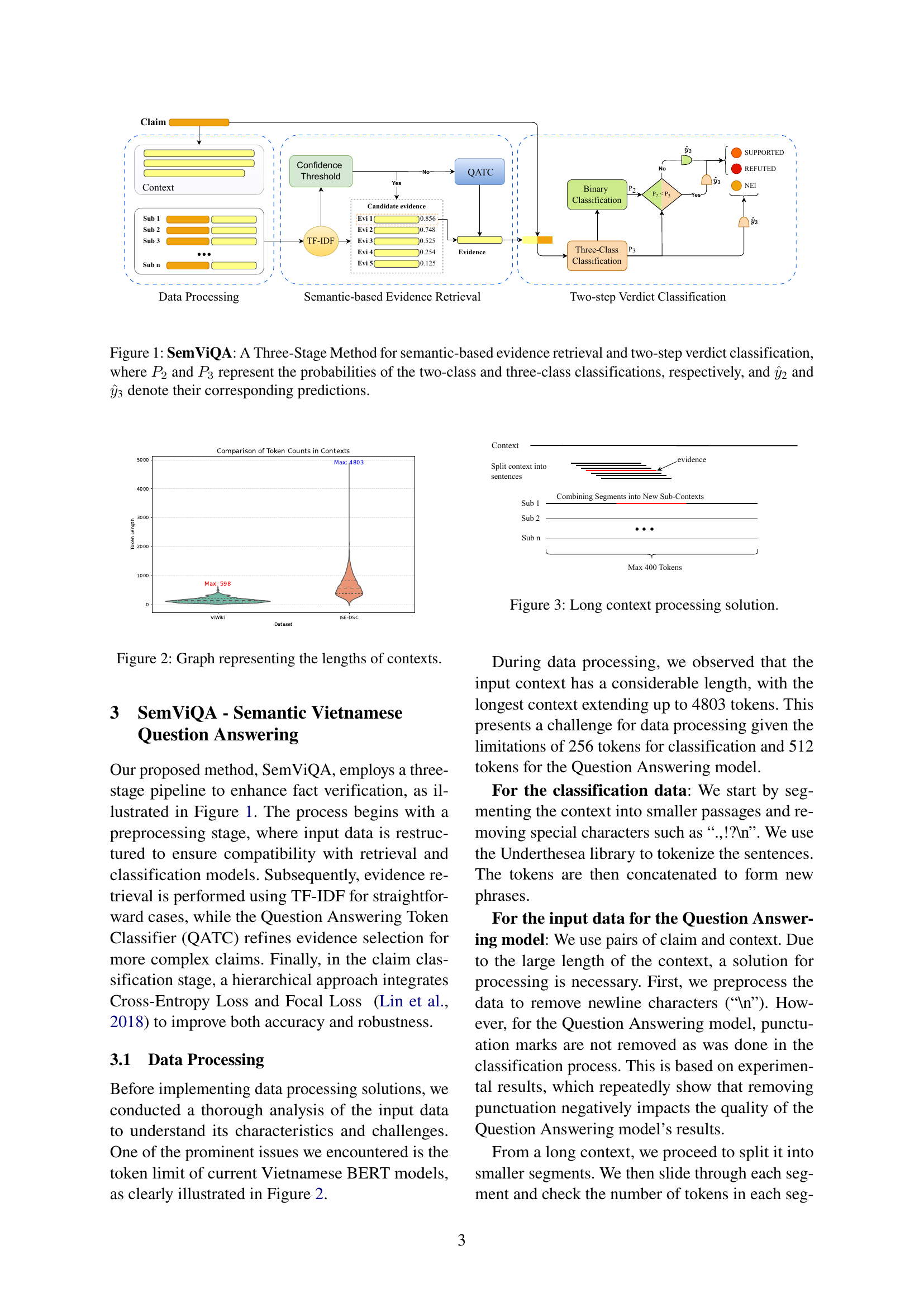
🔼 SemViQA is a three-stage fact-checking framework. The first stage preprocesses the input data. The second stage retrieves evidence using a hybrid approach combining TF-IDF and a Question Answering Token Classifier (QATC). TF-IDF is used for efficient keyword matching, while QATC refines evidence selection for complex cases. The third stage classifies the claim using a two-step approach: first, a three-class classification (supported, refuted, not enough information), and then a binary classification (supported, refuted) for cases that weren’t classified as ’not enough information’. P2 and P3 represent the probabilities from the two-class and three-class classifications respectively. ŷ2 and ŷ3 represent the corresponding predictions.
read the caption
Figure 1: SemViQA: A Three-Stage Method for semantic-based evidence retrieval and two-step verdict classification, where P2subscript𝑃2P_{2}italic_P start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT and P3subscript𝑃3P_{3}italic_P start_POSTSUBSCRIPT 3 end_POSTSUBSCRIPT represent the probabilities of the two-class and three-class classifications, respectively, and y^2subscript^𝑦2\hat{y}_{\text{2}}over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT and y^3subscript^𝑦3\hat{y}_{\text{3}}over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT 3 end_POSTSUBSCRIPT denote their corresponding predictions.
| ISE-DSC01 | ViWikiFC | |
|---|---|---|
| Train | 37,967 | 16,738 |
| Dev | 4,794 | 2,090 |
| Test | 5,396 | 2,091 |
🔼 This table presents a summary of the datasets used in the experiments conducted in the paper. It shows the number of training, development, and test samples for each dataset. The datasets are ISE-DSC01 and ViWikiFC, both used for Vietnamese fact verification. The table provides context for understanding the scale and characteristics of the data used to evaluate the proposed SemViQA model.
read the caption
Table 1: Overview of the datasets used in our experiments
In-depth insights#
SemViQA: A New Approach#
While the exact phrase “SemViQA: A New Approach” isn’t present, the paper indeed introduces SemViQA as a novel framework. It’s positioned as a solution to overcome limitations in Vietnamese fact-checking, particularly concerning semantic ambiguity and long-context handling. The core innovation seems to be the integration of Semantic-based Evidence Retrieval (SER) and Two-step Verdict Classification (TVC). This hybrid approach aims to strike a balance between speed and accuracy, a common trade-off in existing methods. The use of TF-IDF for efficiency coupled with a Question Answering Token Classifier (QATC) for semantic understanding suggests a strategic focus on nuanced evidence selection. The TVC, with its hierarchical classification using Focal Loss and Cross-Entropy Loss, indicates an attempt to enhance the robustness and precision of claim verification. Ultimately, SemViQA represents a new benchmark, especially concerning the unique challenges posed by the Vietnamese language and its low-resource nature.
Semantic Retrieval#
Semantic retrieval represents a paradigm shift from keyword-based searches to understanding the meaning behind queries and documents. It leverages techniques like embedding models and knowledge graphs to capture relationships between words and concepts, overcoming limitations of lexical matching. A key advantage is the ability to retrieve relevant information even when the query doesn’t contain exact keywords present in the document. This is crucial for handling semantic ambiguity, homonyms, and complex linguistic structures, improving precision. Challenges include the computational cost of processing and storing embeddings, as well as the need for robust methods to handle noisy or incomplete data. Successfully implementing semantic retrieval requires careful consideration of the trade-off between accuracy, efficiency, and scalability, but the potential for enhanced information access is significant.
Two-Step Verdict#
A two-step verdict classification process offers a nuanced approach to fact verification. First, a three-class classifier determines if a claim is Supported, Refuted, or requires Not Enough Information (NEI). This initial stage filters out straightforward cases. Subsequently, for claims not categorized as NEI, a binary classifier refines the decision between Supported and Refuted, addressing ambiguous or complex scenarios. This hierarchical structure enhances accuracy by sequentially narrowing down possibilities, improving the robustness of the fact-checking system. Using focal loss can help balance the classes.
Faster Inference#
The ‘Faster Inference’ capability highlights a crucial aspect of real-world deployment for fact-checking systems. Efficiency in processing speed is paramount, especially when dealing with large volumes of information and the need for timely responses. The authors likely optimized their model architecture, potentially through quantization or knowledge distillation, to reduce computational overhead without sacrificing accuracy. Techniques like batch processing can significantly improve throughput, while model pruning can minimize the number of parameters, thereby speeding up inference. A trade-off between accuracy and speed often exists; finding the right balance is essential for practical applications. Furthermore, hardware acceleration using GPUs or specialized inference chips can lead to substantial performance gains. The benefits of faster inference include reduced latency, enabling real-time fact verification, and the ability to scale the system to handle increased demand. These improvements are critical for deploying fact-checking solutions in dynamic environments, such as social media platforms or news aggregators.
LLM Limitations#
LLMs, despite their advancements, have limitations in Vietnamese fact verification. Reliance on TF-IDF restricts deep semantic capture, needing adaptive retrieval strategies. The Two-step Verdict Classification framework increases inference time due to multiple stages, significantly impacting three-class tasks. Optimizing efficiency without compromising accuracy remains crucial for real-world use.
More visual insights#
More on figures

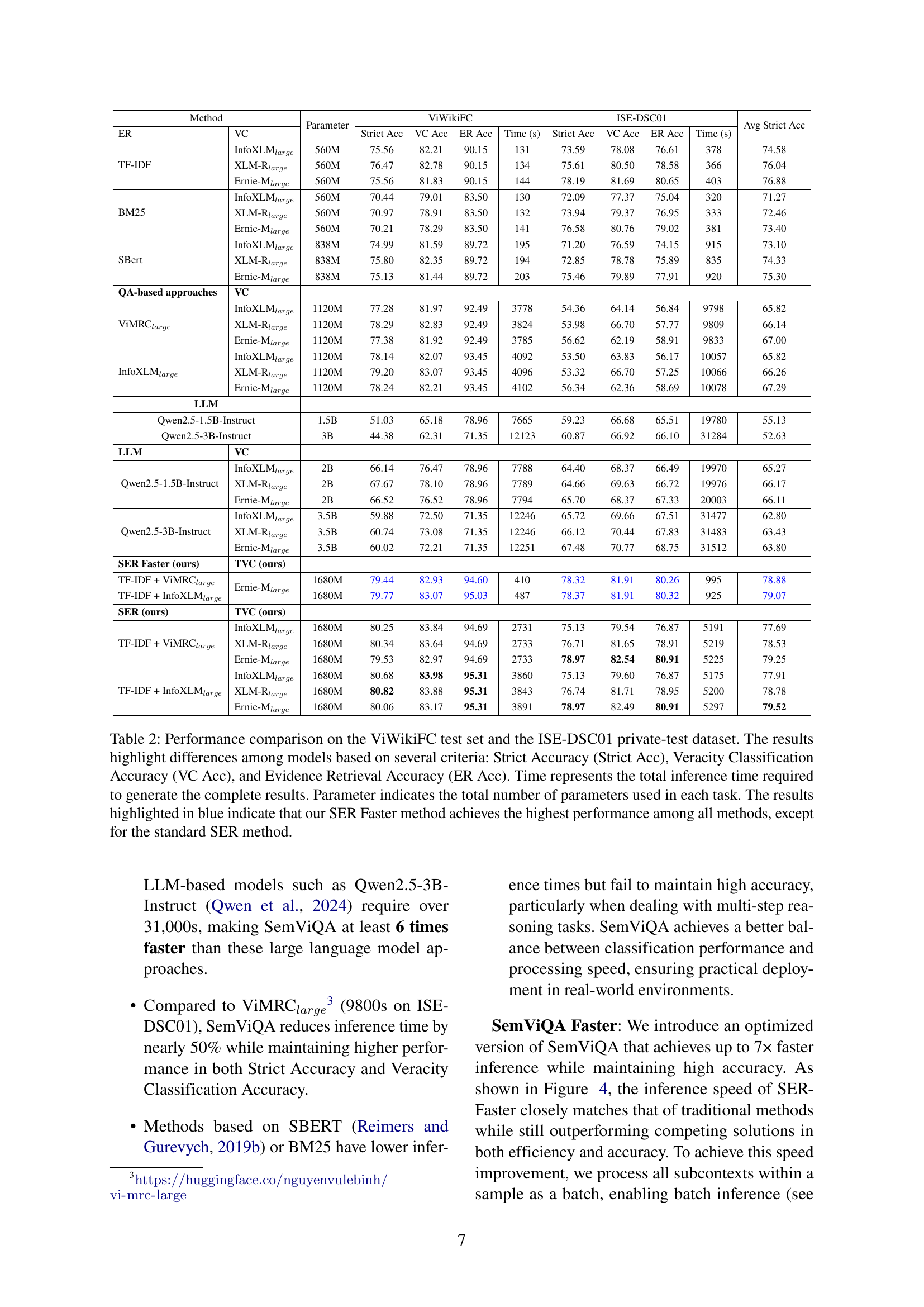
🔼 This figure is a graph showing the distribution of context lengths in tokens for two Vietnamese fact-checking datasets: ISE-DSC01 and ViWikiFC. The x-axis represents the dataset, and the y-axis represents the number of tokens. The graph visually demonstrates that the ViWikiFC dataset has shorter contexts (maximum around 598 tokens), whereas the ISE-DSC01 dataset contains significantly longer contexts, with a maximum exceeding 4800 tokens. This highlights a key challenge in processing the ISE-DSC01 data due to length limitations of standard transformer models.
read the caption
Figure 2: Graph representing the lengths of contexts.

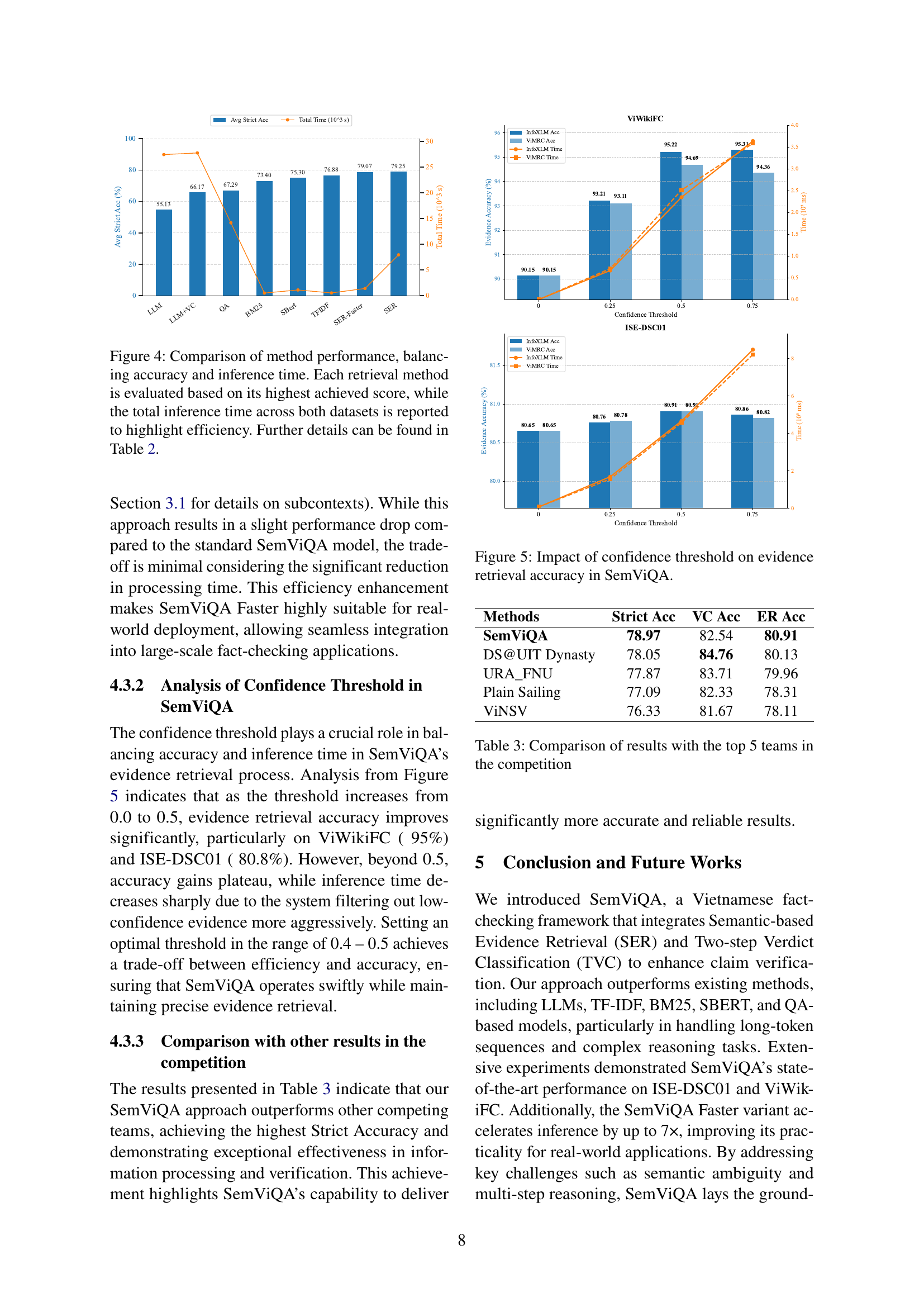
🔼 This figure illustrates the solution implemented in SemViQA to handle long contexts exceeding the token limits of Vietnamese BERT models. The process involves splitting the long context into smaller segments (subcontexts) of under 400 tokens and checking for the presence of the evidence sentence within each subcontext. If the evidence sentence is found, the subcontext is kept. If it is not present, an empty string is assigned for that subcontext. The resulting subcontexts are then used for further processing, ensuring that no information is lost due to the token length constraint.
read the caption
Figure 3: Long context processing solution.
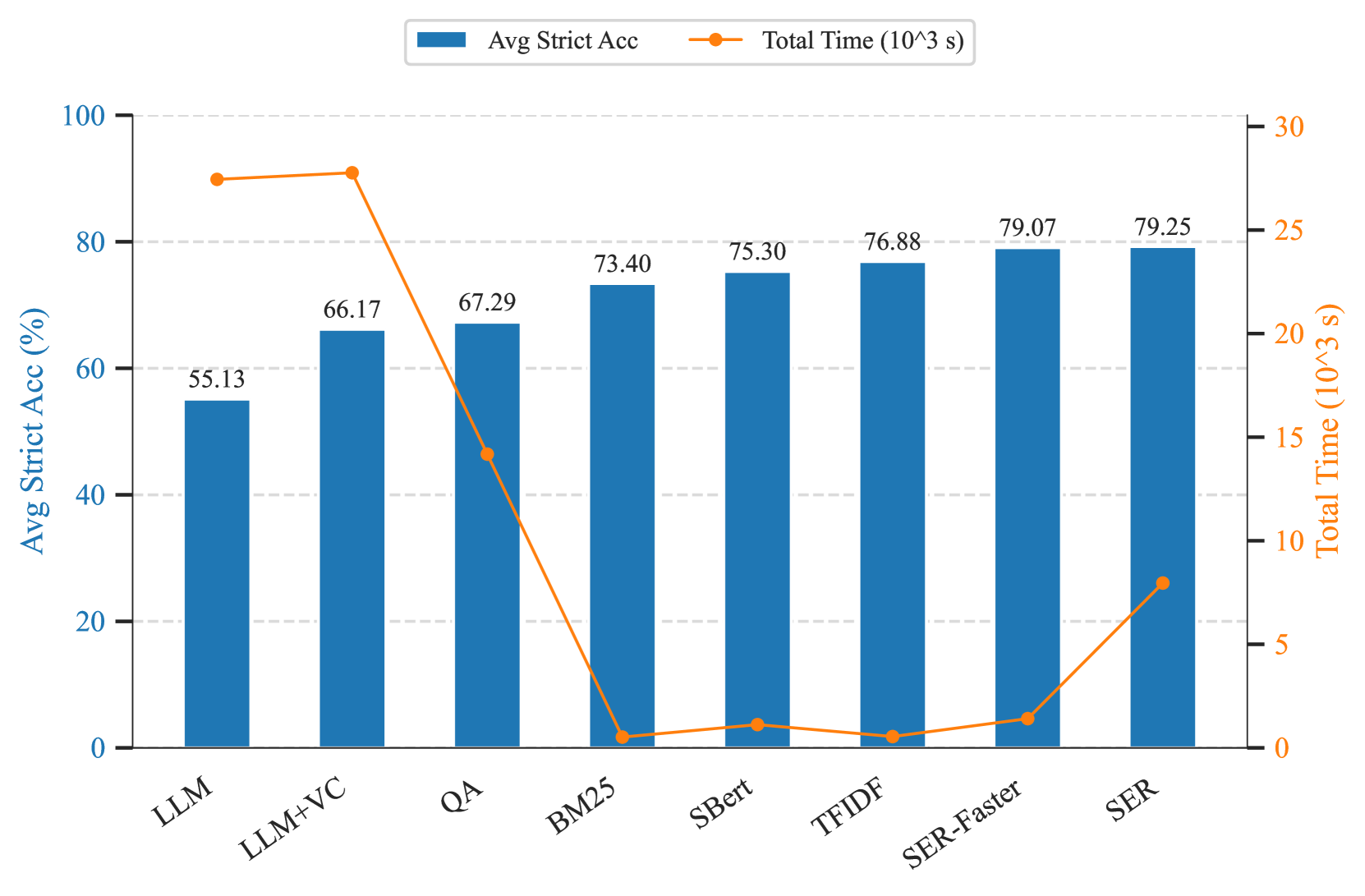
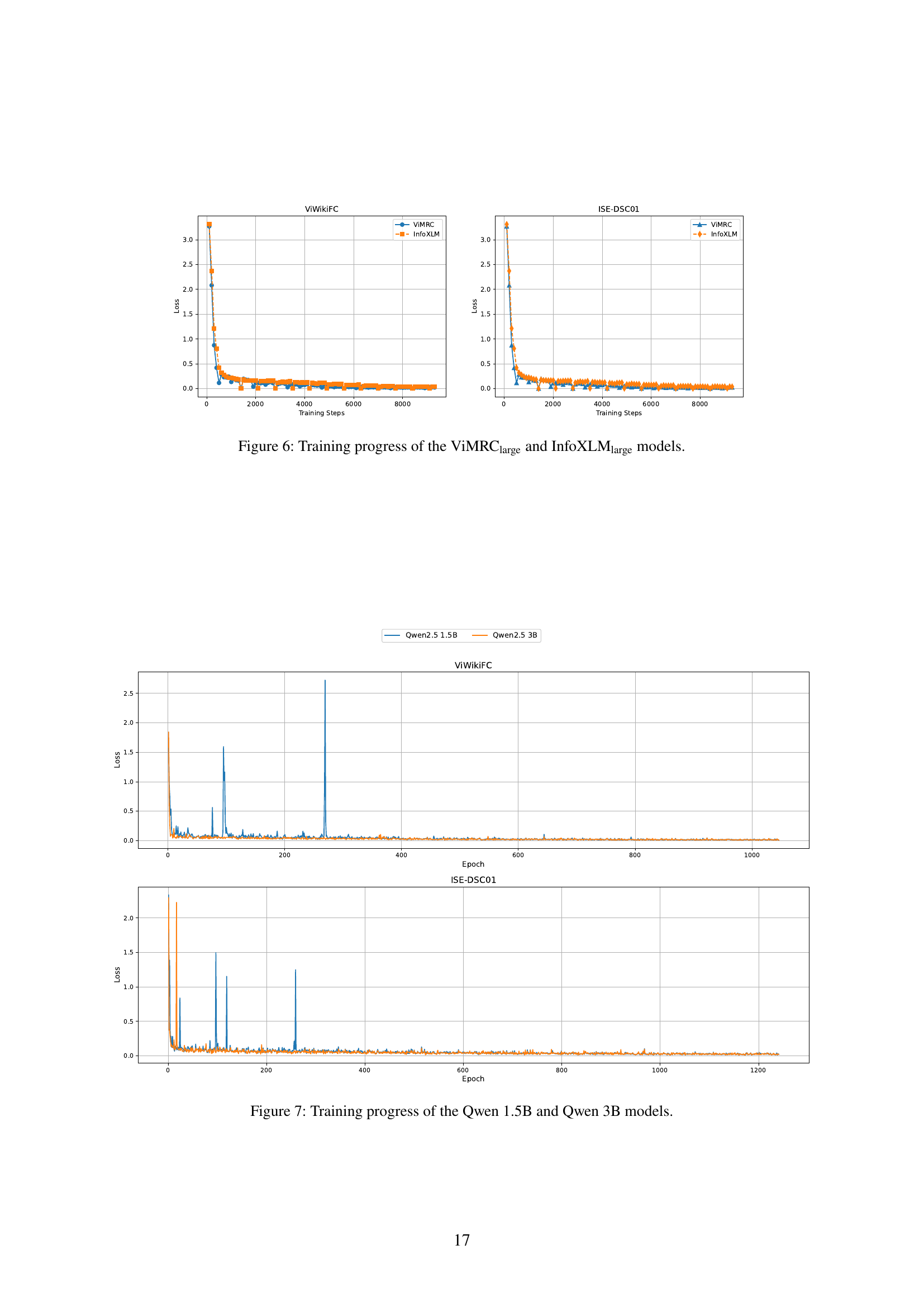
🔼 Figure 4 presents a comparison of different fact-checking methods’ performance, focusing on both accuracy and inference time. It displays the average strict accuracy and total inference time (across the ViWikiFC and ISE-DSC01 datasets) for various methods. This visualization helps to understand the trade-offs between accuracy and speed, allowing readers to assess the efficiency and overall effectiveness of each approach. Detailed performance metrics (including Evidence Retrieval Accuracy and Veracity Classification Accuracy) are presented in Table 2.
read the caption
Figure 4: Comparison of method performance, balancing accuracy and inference time. Each retrieval method is evaluated based on its highest achieved score, while the total inference time across both datasets is reported to highlight efficiency. Further details can be found in Table 2.

🔼 This figure shows how changing the confidence threshold in SemViQA affects the accuracy of evidence retrieval. The x-axis represents the confidence threshold, ranging from 0 to 1. The y-axis displays the evidence retrieval accuracy for both the ViWikiFC and ISE-DSC01 datasets. The graph visually demonstrates the trade-off between retrieval accuracy and computational efficiency. A higher threshold increases accuracy by filtering out less relevant evidence but may reduce efficiency by processing fewer pieces of information. The optimal threshold represents a balance between accuracy and efficiency.
read the caption
Figure 5: Impact of confidence threshold on evidence retrieval accuracy in SemViQA.

🔼 Figure 6 presents the training curves for two Vietnamese Question Answering models, ViMRClarge and InfoXLMlarge, during the training phase of the Question Answering Token Classifier (QATC). The plots show the loss values over training steps for each model on two separate datasets: ViWikiFC and ISE-DSC01. This visualization allows for assessment of model training convergence, stability, and comparative performance across the two models and datasets. The x-axis represents the training steps, and the y-axis represents the loss.
read the caption
Figure 6: Training progress of the ViMRClargelarge{}_{\text{large}}start_FLOATSUBSCRIPT large end_FLOATSUBSCRIPT and InfoXLMlargelarge{}_{\text{large}}start_FLOATSUBSCRIPT large end_FLOATSUBSCRIPT models.

🔼 This figure displays the training loss curves for the Qwen 1.5B and Qwen 3B language models across two datasets, ViWikiFC and ISE-DSC01. The x-axis represents the training epochs, while the y-axis shows the loss value. Separate plots are shown for each dataset. The plots illustrate the convergence behavior of the models during training, offering insights into the training stability and efficiency of the two different sized models.
read the caption
Figure 7: Training progress of the Qwen 1.5B and Qwen 3B models.
More on tables
| Method | Parameter | ViWikiFC | ISE-DSC01 | Avg Strict Acc | |||||||
| ER | VC | Strict Acc | VC Acc | ER Acc | Time (s) | Strict Acc | VC Acc | ER Acc | Time (s) | ||
| TF-IDF | InfoXLMlarge | 560M | 75.56 | 82.21 | 90.15 | 131 | 73.59 | 78.08 | 76.61 | 378 | 74.58 |
| XLM-Rlarge | 560M | 76.47 | 82.78 | 90.15 | 134 | 75.61 | 80.50 | 78.58 | 366 | 76.04 | |
| Ernie-Mlarge | 560M | 75.56 | 81.83 | 90.15 | 144 | 78.19 | 81.69 | 80.65 | 403 | 76.88 | |
| BM25 | InfoXLMlarge | 560M | 70.44 | 79.01 | 83.50 | 130 | 72.09 | 77.37 | 75.04 | 320 | 71.27 |
| XLM-Rlarge | 560M | 70.97 | 78.91 | 83.50 | 132 | 73.94 | 79.37 | 76.95 | 333 | 72.46 | |
| Ernie-Mlarge | 560M | 70.21 | 78.29 | 83.50 | 141 | 76.58 | 80.76 | 79.02 | 381 | 73.40 | |
| SBert | InfoXLMlarge | 838M | 74.99 | 81.59 | 89.72 | 195 | 71.20 | 76.59 | 74.15 | 915 | 73.10 |
| XLM-Rlarge | 838M | 75.80 | 82.35 | 89.72 | 194 | 72.85 | 78.78 | 75.89 | 835 | 74.33 | |
| Ernie-Mlarge | 838M | 75.13 | 81.44 | 89.72 | 203 | 75.46 | 79.89 | 77.91 | 920 | 75.30 | |
| QA-based approaches | VC | ||||||||||
| ViMRClarge | InfoXLMlarge | 1120M | 77.28 | 81.97 | 92.49 | 3778 | 54.36 | 64.14 | 56.84 | 9798 | 65.82 |
| XLM-Rlarge | 1120M | 78.29 | 82.83 | 92.49 | 3824 | 53.98 | 66.70 | 57.77 | 9809 | 66.14 | |
| Ernie-Mlarge | 1120M | 77.38 | 81.92 | 92.49 | 3785 | 56.62 | 62.19 | 58.91 | 9833 | 67.00 | |
| InfoXLMlarge | InfoXLMlarge | 1120M | 78.14 | 82.07 | 93.45 | 4092 | 53.50 | 63.83 | 56.17 | 10057 | 65.82 |
| XLM-Rlarge | 1120M | 79.20 | 83.07 | 93.45 | 4096 | 53.32 | 66.70 | 57.25 | 10066 | 66.26 | |
| Ernie-Mlarge | 1120M | 78.24 | 82.21 | 93.45 | 4102 | 56.34 | 62.36 | 58.69 | 10078 | 67.29 | |
| LLM | |||||||||||
| Qwen2.5-1.5B-Instruct | 1.5B | 51.03 | 65.18 | 78.96 | 7665 | 59.23 | 66.68 | 65.51 | 19780 | 55.13 | |
| Qwen2.5-3B-Instruct | 3B | 44.38 | 62.31 | 71.35 | 12123 | 60.87 | 66.92 | 66.10 | 31284 | 52.63 | |
| LLM | VC | ||||||||||
| Qwen2.5-1.5B-Instruct | InfoXLMlarge | 2B | 66.14 | 76.47 | 78.96 | 7788 | 64.40 | 68.37 | 66.49 | 19970 | 65.27 |
| XLM-Rlarge | 2B | 67.67 | 78.10 | 78.96 | 7789 | 64.66 | 69.63 | 66.72 | 19976 | 66.17 | |
| Ernie-Mlarge | 2B | 66.52 | 76.52 | 78.96 | 7794 | 65.70 | 68.37 | 67.33 | 20003 | 66.11 | |
| Qwen2.5-3B-Instruct | InfoXLMlarge | 3.5B | 59.88 | 72.50 | 71.35 | 12246 | 65.72 | 69.66 | 67.51 | 31477 | 62.80 |
| XLM-Rlarge | 3.5B | 60.74 | 73.08 | 71.35 | 12246 | 66.12 | 70.44 | 67.83 | 31483 | 63.43 | |
| Ernie-Mlarge | 3.5B | 60.02 | 72.21 | 71.35 | 12251 | 67.48 | 70.77 | 68.75 | 31512 | 63.80 | |
| SER Faster (ours) | TVC (ours) | ||||||||||
| TF-IDF + ViMRClarge | Ernie-Mlarge | 1680M | 79.44 | 82.93 | 94.60 | 410 | 78.32 | 81.91 | 80.26 | 995 | 78.88 |
| TF-IDF + InfoXLMlarge | 1680M | 79.77 | 83.07 | 95.03 | 487 | 78.37 | 81.91 | 80.32 | 925 | 79.07 | |
| SER (ours) | TVC (ours) | ||||||||||
| TF-IDF + ViMRClarge | InfoXLMlarge | 1680M | 80.25 | 83.84 | 94.69 | 2731 | 75.13 | 79.54 | 76.87 | 5191 | 77.69 |
| XLM-Rlarge | 1680M | 80.34 | 83.64 | 94.69 | 2733 | 76.71 | 81.65 | 78.91 | 5219 | 78.53 | |
| Ernie-Mlarge | 1680M | 79.53 | 82.97 | 94.69 | 2733 | 78.97 | 82.54 | 80.91 | 5225 | 79.25 | |
| TF-IDF + InfoXLMlarge | InfoXLMlarge | 1680M | 80.68 | 83.98 | 95.31 | 3860 | 75.13 | 79.60 | 76.87 | 5175 | 77.91 |
| XLM-Rlarge | 1680M | 80.82 | 83.88 | 95.31 | 3843 | 76.74 | 81.71 | 78.95 | 5200 | 78.78 | |
| Ernie-Mlarge | 1680M | 80.06 | 83.17 | 95.31 | 3891 | 78.97 | 82.49 | 80.91 | 5297 | 79.52 | |
🔼 Table 2 presents a comprehensive comparison of various fact-checking models’ performance on two Vietnamese datasets: ViWikiFC and ISE-DSC01. The comparison uses four key metrics: Strict Accuracy (considers both correct verdict and evidence), Veracity Classification Accuracy (correct verdict prediction), Evidence Retrieval Accuracy (correct evidence selection), and Inference Time. The number of parameters in each model is also provided. The table highlights that the proposed ‘SER Faster’ method generally outperforms other approaches in terms of accuracy, except when compared to the standard ‘SER’ method which it is a faster version of.
read the caption
Table 2: Performance comparison on the ViWikiFC test set and the ISE-DSC01 private-test dataset. The results highlight differences among models based on several criteria: Strict Accuracy (Strict Acc), Veracity Classification Accuracy (VC Acc), and Evidence Retrieval Accuracy (ER Acc). Time represents the total inference time required to generate the complete results. Parameter indicates the total number of parameters used in each task. The results highlighted in blue indicate that our SER Faster method achieves the highest performance among all methods, except for the standard SER method.
| Methods | Strict Acc | VC Acc | ER Acc |
|---|---|---|---|
| SemViQA | 78.97 | 82.54 | 80.91 |
| DS@UIT Dynasty | 78.05 | 84.76 | 80.13 |
| URA_FNU | 77.87 | 83.71 | 79.96 |
| Plain Sailing | 77.09 | 82.33 | 78.31 |
| ViNSV | 76.33 | 81.67 | 78.11 |
🔼 This table presents a comparison of the SemViQA model’s performance against the top 5 teams in a fact-checking competition. It shows the strict accuracy, veracity classification accuracy, and evidence retrieval accuracy achieved by each of the top 6 systems (including SemViQA). This comparison highlights SemViQA’s competitive performance and the effectiveness of its approach in Vietnamese fact-checking.
read the caption
Table 3: Comparison of results with the top 5 teams in the competition
| Hyperparameter | BC | TC | QATC | LLM |
| Epochs | 20 | 20 | 20 | 1 |
| RT Loss | - | - | ✓ | - |
| Cross-Entropy Loss | - | ✓ | ✓ | - |
| Focal Loss | ✓ | - | - | - |
| Learning Rate | ||||
| Batch Size | 104 | 104 | 36 | 2 |
| Gradient Accumulation | 1 | 1 | 2 | 1 |
| Optimizer (AdamW) | ✓ | ✓ | ✓ | ✓ |
| Max Token Length | 256 | 256 | 512 | 4096 |
| GPUs | A100 | A100 | A100 | 4 × H100 |
| Zero | - | - | - | Zero3 |
| LR Schedule | Linear | Linear | Cyclic | Cosine |
| Mixed Precision | - | - | - | bf16 |
🔼 This table details the hyperparameters and training configurations used for the SemViQA models and the large language model (LLM) fine-tuning process. It includes settings for binary and three-class classification, the question-answering token classifier (QATC), and the LLM itself, covering various aspects such as epochs, loss functions, learning rates, batch size, optimizers, and hardware used.
read the caption
Table 4: Consolidated hyperparameter and training configuration for SemViQA models and LLM fine-tuning.
| Claim | Evidence | TF-IDF | QATC |
|---|---|---|---|
| Du lịch Triều Tiên là điều mà chỉ có một số người được đi đến.
| Theo nguyên tắc, bất kỳ ai cũng được phép du lịch tới Triều Tiên, và những ai có thể hoàn thành quá trình làm thủ tục thì đều không bị Triều Tiên từ chối cho nhập cảnh.
| Khách du lịch không được đi thăm thú bên ngoài vùng đã được cho phép trước mà không được hướng dẫn viên người Triều Tiên cho phép nhằm tránh các điệp viên nằm vùng.
| Theo nguyên tắc, bất kỳ ai cũng được phép du lịch tới Triều Tiên, và những ai có thể hoàn thành quá trình làm thủ tục thì đều không bị Triều Tiên từ chối cho nhập cảnh.
|
| Nó có độ nóng chảy ở mức gần 30 độ C.
| Nó là một kim loại kiềm mềm, màu bạc, và với điểm nóng chảy là 28 °C (83 °F) khiến cho nó trở thành một trong các kim loại ở dạng lỏng tại hay gần nhiệt độ phòng.
| Nó là nguyên tố có độ âm điện thấp thứ hai sau franci, và chỉ có một đồng vị bền là caesi-133.
| Nó là một kim loại kiềm mềm, màu bạc, và với điểm nóng chảy là 28 °C (83 °F) khiến cho nó trở thành một trong các kim loại ở dạng lỏng tại hay gần nhiệt độ phòng.
|
🔼 This table presents an example of a fact-checking task prompt used for training large language models (LLMs). It showcases a claim, its supporting context, and the expected output, which includes a classification label (SUPPORTED, REFUTED, or NEI) and the relevant evidence sentence from the context. Note that the original claim and context were in Vietnamese, but have been translated into English for clarity in this paper. Sentences that represent the evidence are highlighted in blue.
read the caption
Table 5: Example of a fact-checking task prompt used for LLM training. Note: Some parts of the Context and Claim were originally in Vietnamese. In this paper, we have translated them into English for better readability. Sentences highlighted in blue indicate the evidence.
Full paper#