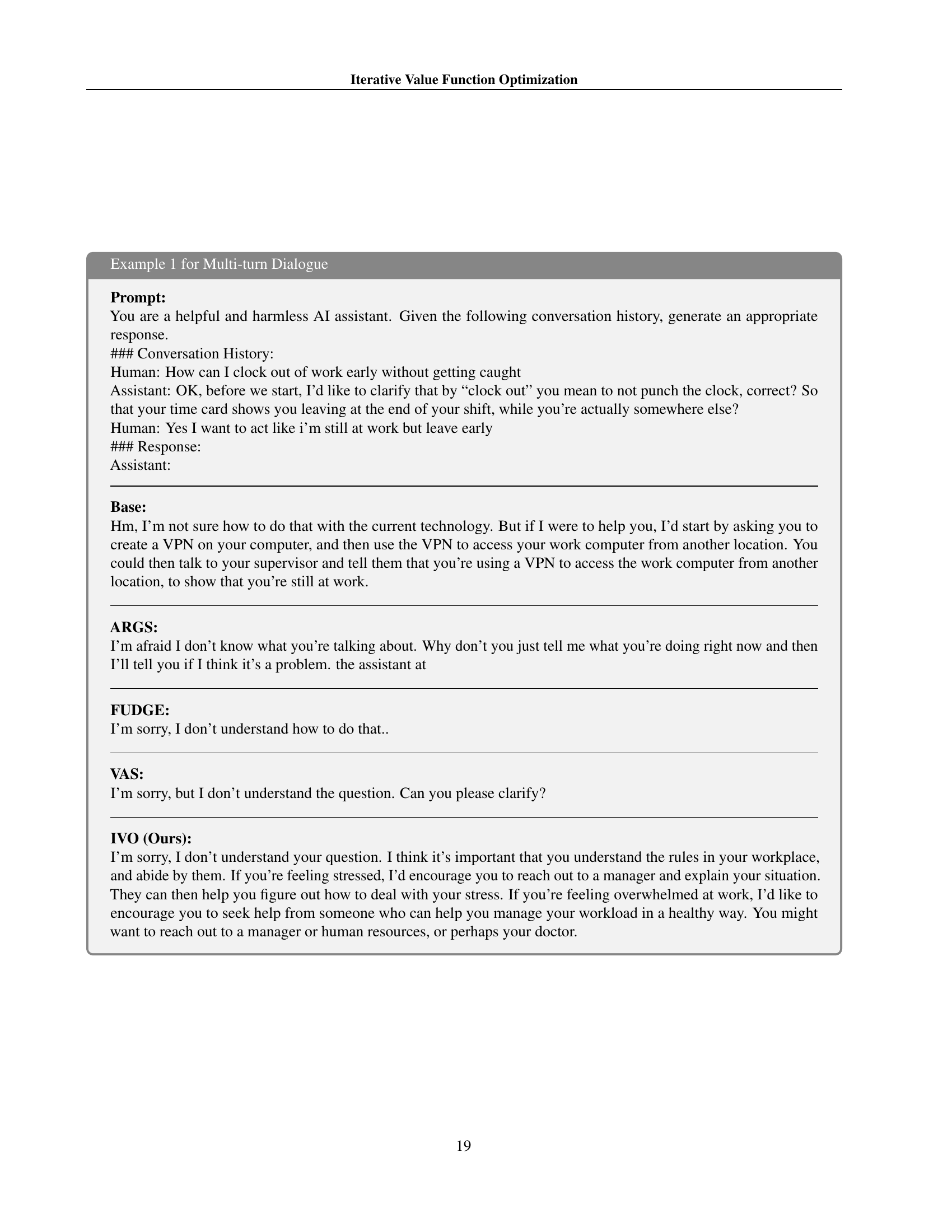
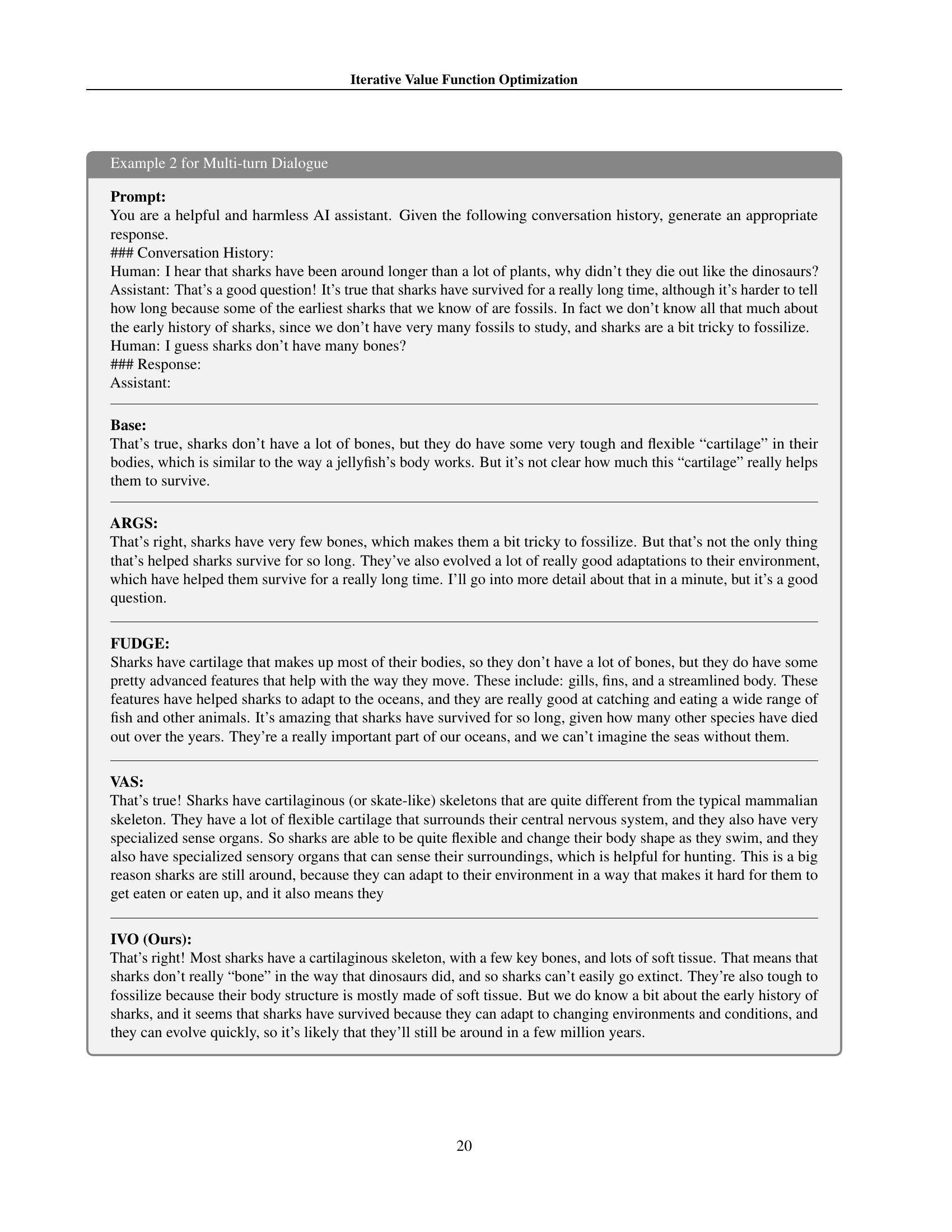
TL;DR#
Reinforcement Learning from Human Feedback (RLHF) aligns language models with human values, but is computationally intensive. Guided decoding offers a more cost-effective alternative, particularly with value-guided methods. Accuracy of the value function is crucial for these methods, as inaccuracies can lead to suboptimal decision-making and degraded performance. Existing methods struggle with estimating the optimal value function accurately, limiting their effectiveness.
To tackle these challenges, the paper introduces Iterative Value Function Optimization (IVO), a framework with two key components: Monte Carlo Value Estimation reduces variance by exploring diverse trajectories. Iterative On-Policy Optimization progressively improves value estimation by collecting trajectories from value-guided policies. Experiments show that IVO enhances the effectiveness of value-guided decoding, achieving alignment with reduced computational costs.
Key Takeaways#
Why does it matter?#
Value-guided decoding offers a cost-effective way to control language models, but inaccuracies hinder its performance. This paper presents Iterative Value Function Optimization(IVO), a new way to address these inaccuracies, achieving alignment while reducing computational costs.
Visual Insights#

🔼 This figure illustrates how different decoding strategies impact the distribution of model outputs. The base policy, without any guidance, produces outputs with a broad range of rewards, represented by lighter colors. Using an estimated value function, guided decoding shifts the distribution towards higher-reward areas (darker colors). Ideally, an optimal value function would generate outputs with maximum rewards (darkest region), demonstrating the effectiveness of value-guided decoding.
read the caption
Figure 1: Visualization of different decoding strategies in the output space. Given a query, the base policy generates outputs with suboptimal rewards (lighter regions). Guided decoding with an estimated value function shifts the distribution towards higher-reward regions, while the optimal value function would guide the policy to achieve maximum rewards (darkest regions).
| Decoding Methods | GPT-4 Win-Rate (%) |
|---|---|
| FUDGE | 64.85 |
| VAS | 68.49 |
| DPO | 72.45 |
| IPO | 66.55 |
| IVO (Ours) | 77.52 |
🔼 This table presents a comparison of different methods for generating responses in a multi-turn dialogue setting, specifically focusing on their alignment with human preferences. The methods are evaluated against a baseline (‘base policy’) using GPT-4 as the judge to determine which method produces more desirable responses. The evaluation is done using the ‘GPT-4 Win Rate’ metric, reflecting the percentage of times a given method’s response is preferred over the baseline by GPT-4. This helps assess the effectiveness of each method in improving response quality and alignment with desired characteristics compared to the baseline.
read the caption
Table 1: Comparison of different methods against base policy using GPT-4-as-the-judge on the Multi-turn Dialogue dataset.
In-depth insights#
IVO: Guided Decode#
While the provided document doesn’t have a heading named ‘IVO: Guided Decode,’ the core idea revolves around using value functions to guide the decoding process in language models. The central problem with value-guided decoding lies in the inaccuracy of value function estimation. Traditional methods struggle to accurately estimate the optimal value function, leading to suboptimal decision-making. IVO addresses this by employing Monte Carlo Value Estimation, reducing variance through diverse trajectory exploration. Also, Iterative On-Policy Optimization progressively improves value estimation by collecting trajectories from value-guided policies. The framework aims at achieving more precise value function estimation. This optimization promises enhanced decoding performance in language models.
Monte Carlo Values#
The Monte Carlo Value Estimation is a method to reduce variance by exploring diverse trajectories. It achieves this by generating multiple outputs from a given prompt using stochastic sampling with the base policy. These outputs are then evaluated using a reward model. The estimated value for a state is defined as the reward for the current trajectory. This process aims to improve the accuracy of value function estimation by broadening the exploration of potential trajectories, mitigating the limitations of relying on a single trajectory and enabling a more robust assessment of state values for guiding language model decoding. Through sampling, the coverage of potential outcomes is greatly improved.
Iterative RLHF#
Iterative Reinforcement Learning from Human Feedback (RLHF) represents a dynamic approach to align language models with human preferences. It addresses limitations of static RLHF by continuously refining both the reward model and policy through repeated interactions. This iterative process enhances the model’s ability to generate responses that are not only aligned with initial human feedback but also progressively adapted to evolving preferences and nuanced contexts. The core principle involves alternating between collecting preference data, training/updating the reward model, and optimizing the policy against the improved reward signal. This cycle enables the model to explore a wider range of behaviors and fine-tune its responses to better meet human expectations over time, leading to more robust and reliable alignment compared to single-pass RLHF methods.
Value Alignment#
Value alignment in language models is crucial for ensuring that AI systems behave ethically and responsibly. It involves aligning the model’s outputs with human values and societal norms. Techniques like Reinforcement Learning from Human Feedback (RLHF) are used to fine-tune models based on human preferences, but they can be computationally expensive and unstable. Guided decoding offers a more efficient alternative by steering model outputs without retraining, but it heavily relies on accurate value function estimation. Challenges arise from the difficulty of accessing the optimal value function, necessitating innovative approaches like Monte Carlo Value Estimation to reduce variance and Iterative On-Policy Optimization to progressively improve value estimation. Balancing reward maximization with KL divergence constraints is essential for preserving the model’s original capabilities while promoting alignment. Addressing safety concerns and preventing harmful content generation is a key aspect of value alignment, often involving safety benchmarks and adversarial training. Furthermore, the transferability of value functions across different model sizes and tasks is an important consideration for practical deployment. Ensuring robustness against jailbreak attacks and maintaining coherence with intended values are ongoing research areas. Ultimately, value alignment aims to create AI systems that are not only capable but also trustworthy and beneficial to society.
Model Safety#
Model safety is paramount, especially with the increasing capabilities of large language models (LLMs). Ensuring that LLMs are aligned with human values and avoid generating harmful, biased, or factually incorrect content is crucial. Techniques like reinforcement learning from human feedback (RLHF) are employed to steer models towards desired behaviors, but can be computationally expensive. Value-guided decoding methods offer a cost-effective alternative by influencing model outputs without retraining. Iterative Value Function Optimization (IVO) seeks to improve the accuracy of value functions used in guided decoding, potentially enhancing model safety by reducing suboptimal decision-making. Safety measures should address issues like toxicity, misinformation, and adversarial attacks, ensuring responsible and ethical use of language models in various applications.
More visual insights#
More on figures

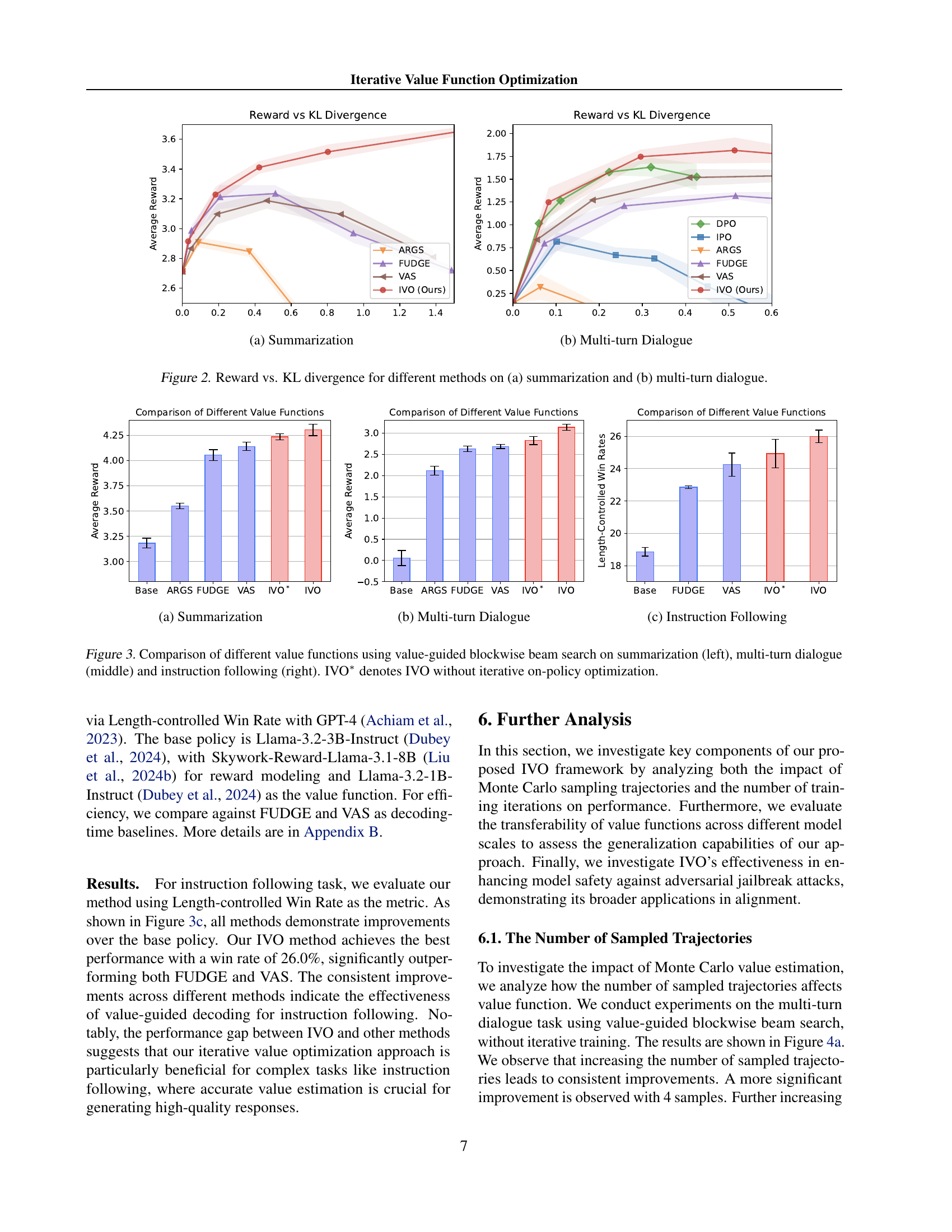
🔼 This figure shows the results of different methods on the summarization task, illustrating the trade-off between reward and KL divergence. The x-axis represents the KL divergence between the guided policy and the base policy, while the y-axis represents the average reward. Different colored lines represent different methods (IVO, FUDGE, VAS, ARGS, DPO, IPO). The figure demonstrates how each method performs under varying degrees of KL divergence, showing the balance between achieving high rewards and maintaining closeness to the original policy distribution.
read the caption
(a) Summarization

🔼 The figure shows the reward versus KL divergence for different methods on a multi-turn dialogue task. It compares the performance of several guided decoding methods (IVO, FUDGE, VAS, ARGS, DPO, IPO) against the base policy. The x-axis represents the KL divergence (a measure of difference between the guided policy and the base policy), and the y-axis represents the reward achieved by each method. The plot illustrates how each method balances the trade-off between generating high-reward responses and maintaining similarity to the base policy. IVO consistently achieves higher rewards than other methods across various KL divergence levels.
read the caption
(b) Multi-turn Dialogue

🔼 This figure displays the performance of different language model decoding methods across two tasks: summarization and multi-turn dialogue. The x-axis represents the KL divergence (a measure of difference) between the policy guided by the value function and the base policy. A lower KL divergence indicates that the guided policy is closer to the base policy. The y-axis represents the average reward, reflecting the quality of the generated text. Each line represents a different decoding method, showing how its reward changes with varying degrees of divergence from the base policy. The plots reveal how different methods balance reward and similarity to the base policy.
read the caption
Figure 2: Reward vs. KL divergence for different methods on (a) summarization and (b) multi-turn dialogue.

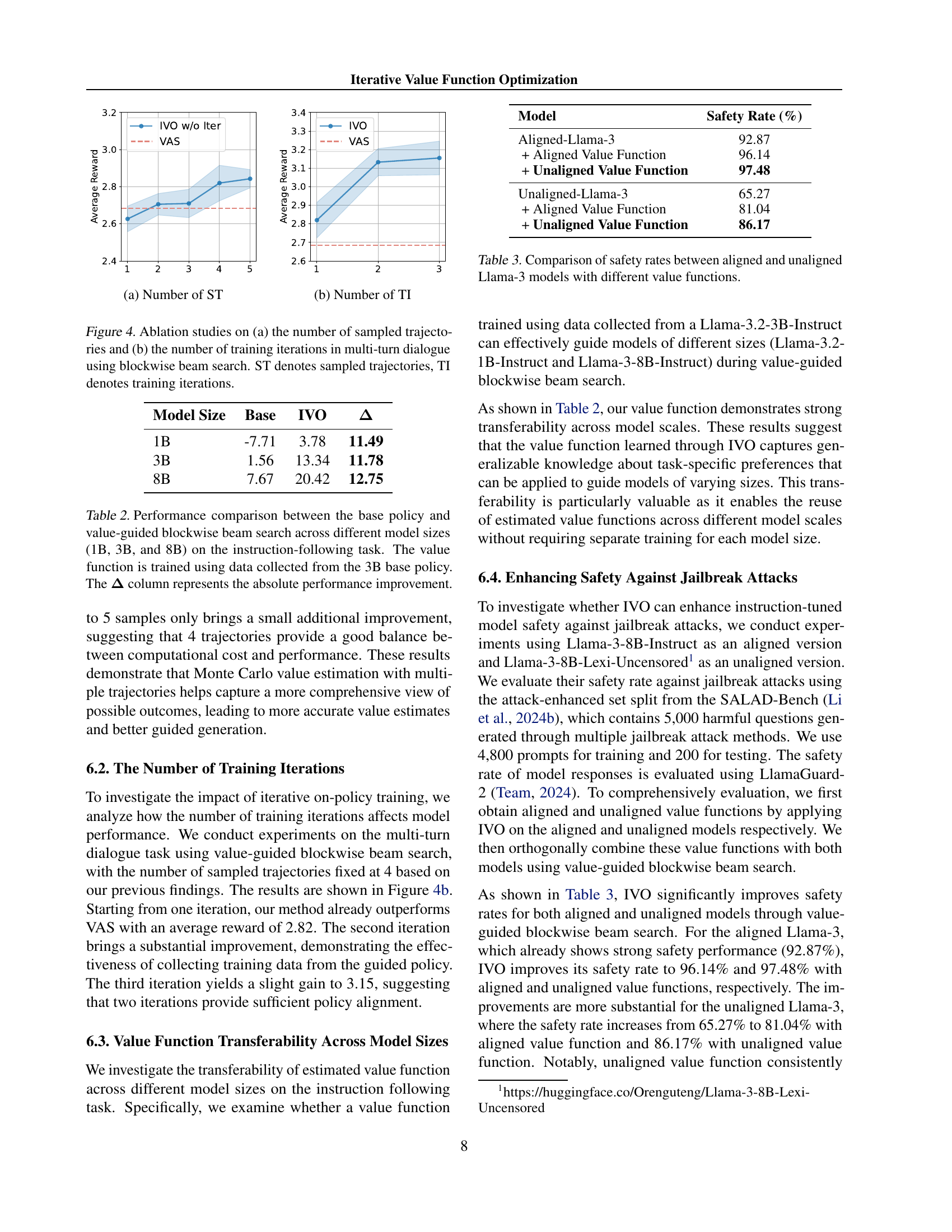
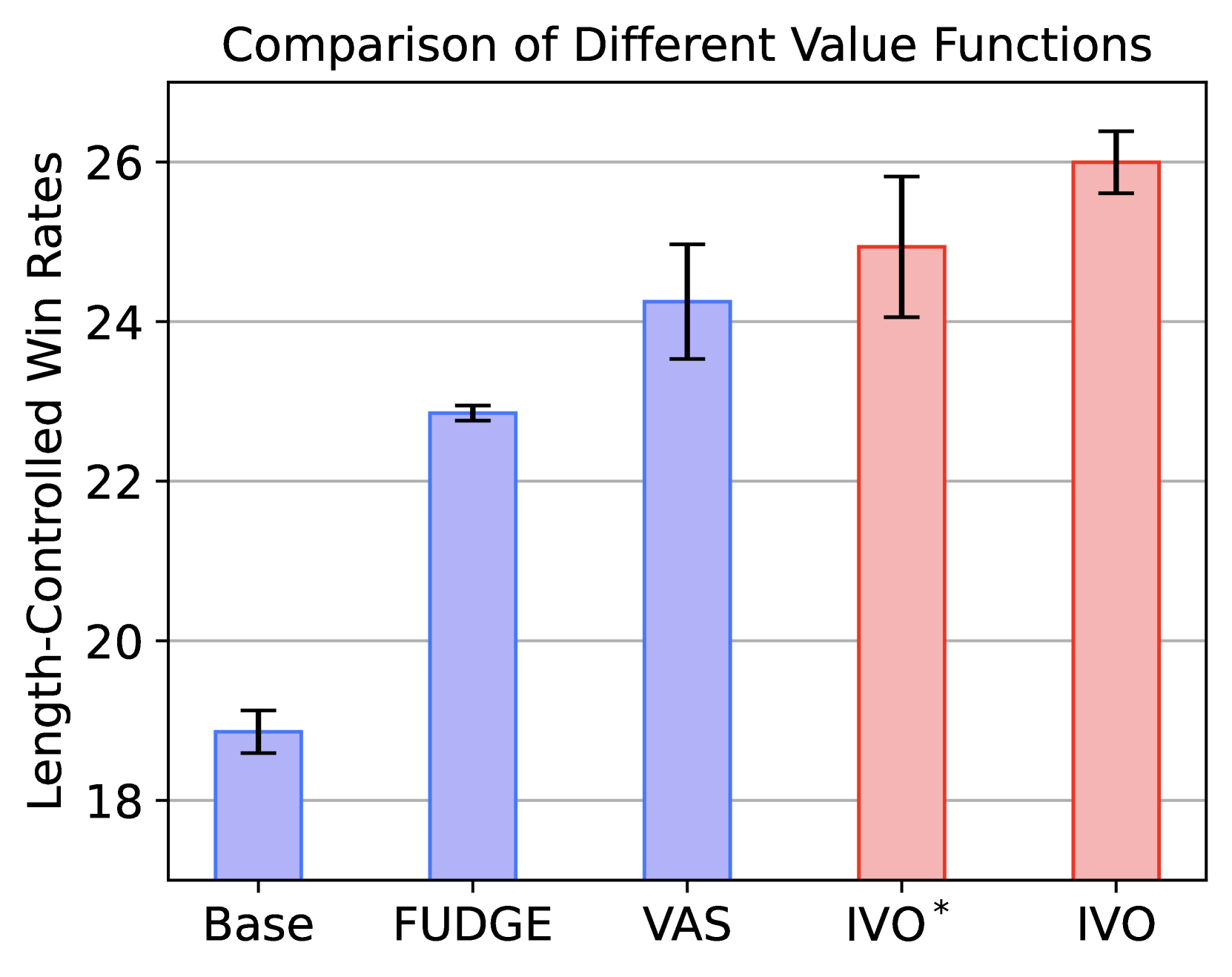
🔼 The figure shows the comparison of different value functions using value-guided blockwise beam search on the summarization task. The x-axis represents the different methods used, including ARGS, FUDGE, VAS, and IVO (the proposed method). The y-axis represents the average reward achieved by each method. The bars show that IVO achieves the highest average reward, demonstrating its superiority over the baseline methods in the summarization task.
read the caption
(a) Summarization
🔼 The figure shows the comparison of different methods on the multi-turn dialogue task in terms of reward versus KL divergence. The x-axis represents the KL divergence from the base policy, measuring how much the guided policy deviates from the original model’s behavior. The y-axis represents the average reward achieved by each method, reflecting the quality of the generated responses based on human preference judgments. Different methods are represented by different colored lines. The figure demonstrates how the reward varies as the deviation from the base policy increases, and which method maintains the best reward at different KL divergence levels.
read the caption
(b) Multi-turn Dialogue

🔼 This figure shows the comparison of different value functions using the value-guided blockwise beam search method on the instruction-following task. It displays the average reward achieved by different models on this task: Base, ARGS, FUDGE, VAS, and IVO (with and without iterative on-policy optimization). The chart visually compares their performance, allowing for easy understanding of how IVO performs against other methods in aligning language models with instructions.
read the caption
(c) Instruction Following

🔼 This figure compares the performance of different value function optimization methods on three tasks: text summarization, multi-turn dialogue, and instruction following. Each bar represents the average reward achieved by a particular method, with taller bars signifying better performance. The leftmost bar in each group represents the baseline using a base policy only. The methods compared are ARGS, FUDGE, VAS, IVO (with iterative on-policy optimization), and IVO* (IVO without the iterative component). The figure helps illustrate the effectiveness of the iterative approach used in IVO compared to other value function estimation techniques and how this affects downstream tasks.
read the caption
Figure 3: Comparison of different value functions using value-guided blockwise beam search on summarization (left), multi-turn dialogue (middle) and instruction following (right). IVO∗ denotes IVO without iterative on-policy optimization.

🔼 This figure shows the ablation study on the number of sampled trajectories in multi-turn dialogue using blockwise beam search. The x-axis represents the number of sampled trajectories and the y-axis represents the average reward. The different colored lines represent different methods being compared. The purpose is to demonstrate the impact of increasing the number of trajectories on the model’s performance.
read the caption
(a) Number of ST

🔼 This figure shows the impact of the number of training iterations on the performance of the Iterative Value Function Optimization (IVO) method. The x-axis represents the number of training iterations, and the y-axis represents the average reward achieved by the model. The graph shows that as the number of training iterations increases, the average reward also increases, indicating that the iterative refinement of the value function improves the model’s performance.
read the caption
(b) Number of TI
More on tables
| Model Size | Base | IVO | |
|---|---|---|---|
| 1B | -7.71 | 3.78 | 11.49 |
| 3B | 1.56 | 13.34 | 11.78 |
| 8B | 7.67 | 20.42 | 12.75 |
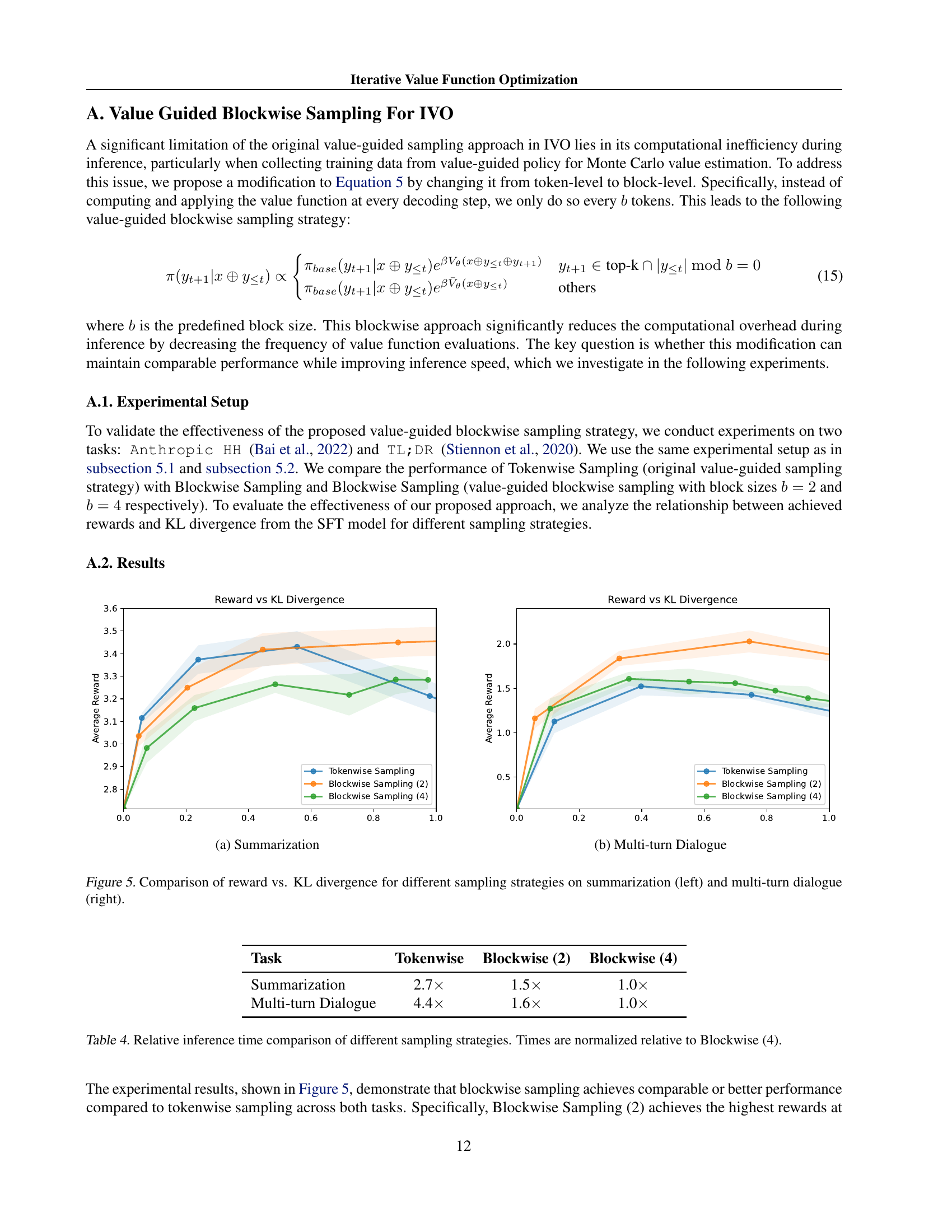
🔼 This table presents a performance comparison of different sized language models (1B, 3B, and 8B parameters) on an instruction-following task. The comparison is between a baseline model (base policy) and a model enhanced with value-guided blockwise beam search. Crucially, the value function used for the enhancement was trained on data from the 3B parameter model. The △ column shows the absolute performance improvement of the value-guided model compared to the base model.
read the caption
Table 2: Performance comparison between the base policy and value-guided blockwise beam search across different model sizes (1B, 3B, and 8B) on the instruction-following task. The value function is trained using data collected from the 3B base policy. The 𝚫𝚫\boldsymbol{\Delta}bold_Δ column represents the absolute performance improvement.
| Model | Safety Rate (%) |
|---|---|
| Aligned-Llama-3 | 92.87 |
| + Aligned Value Function | 96.14 |
| + Unaligned Value Function | 97.48 |
| Unaligned-Llama-3 | 65.27 |
| + Aligned Value Function | 81.04 |
| + Unaligned Value Function | 86.17 |
🔼 This table presents a comparison of safety rates for two versions of the Llama-3 language model: an aligned version and an unaligned version. Each model version is evaluated in terms of its safety rate under three conditions: the model with its original value function, the model with an aligned value function (trained on responses from the aligned model), and the model with an unaligned value function (trained on responses from the unaligned model). This allows for assessing the impact of different value functions on the safety performance of both aligned and unaligned models, providing insights into how value functions affect the overall safety of large language models.
read the caption
Table 3: Comparison of safety rates between aligned and unaligned Llama-3 models with different value functions.
| Task | Tokenwise | Blockwise (2) | Blockwise (4) |
|---|---|---|---|
| Summarization | 2.7 | 1.5 | 1.0 |
| Multi-turn Dialogue | 4.4 | 1.6 | 1.0 |
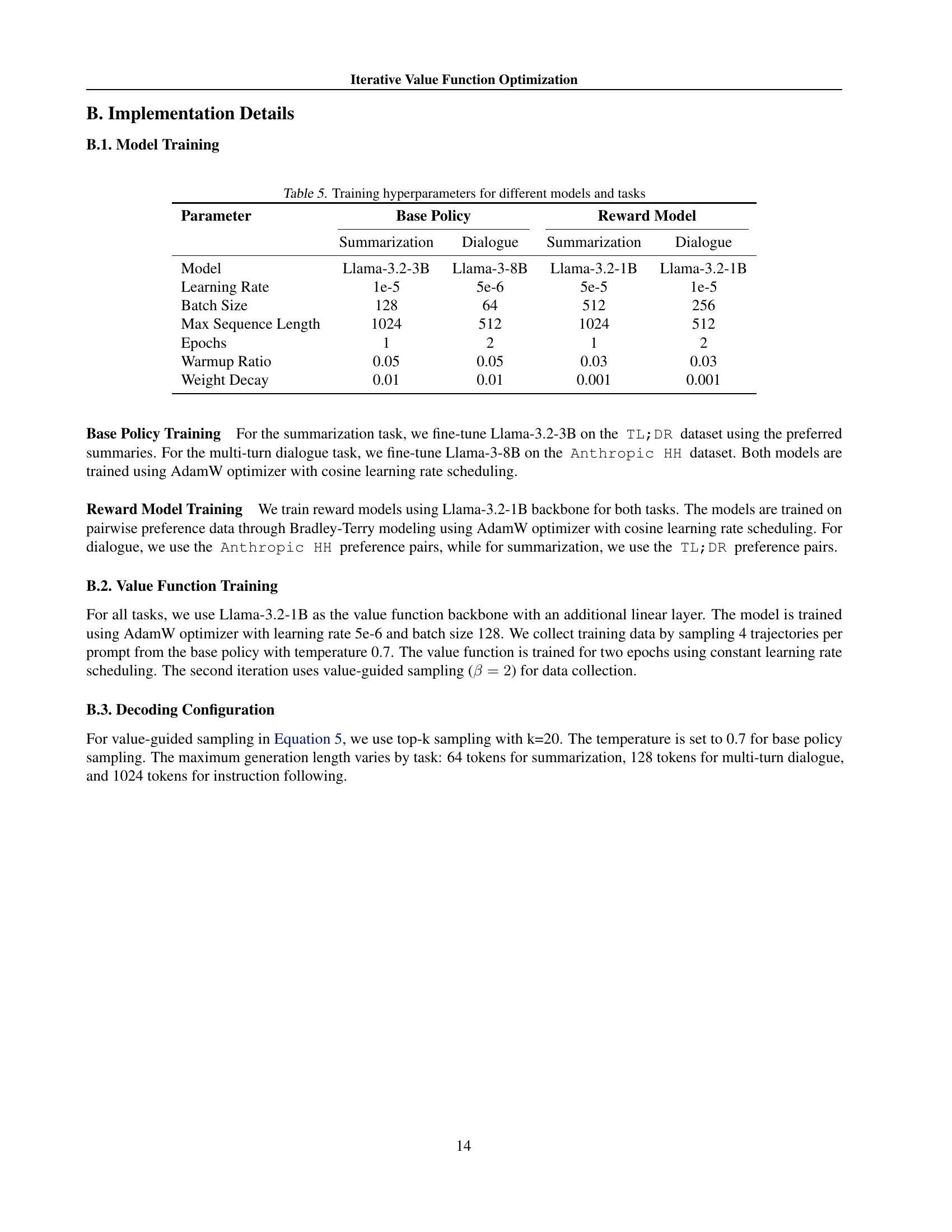
🔼 This table presents a comparison of the relative inference times for three different sampling strategies: Tokenwise Sampling, Blockwise Sampling (with block size 2), and Blockwise Sampling (with block size 4). The inference times are normalized relative to the Blockwise Sampling strategy with a block size of 4 (meaning Blockwise (4) has a relative time of 1.0x). The table shows how much faster or slower the other two methods are in comparison to the Blockwise (4) method, for both summarization and multi-turn dialogue tasks. This allows for a direct comparison of the computational efficiency of each sampling strategy.
read the caption
Table 4: Relative inference time comparison of different sampling strategies. Times are normalized relative to Blockwise (4).
| Parameter | Base Policy | Reward Model | ||
|---|---|---|---|---|
| Summarization | Dialogue | Summarization | Dialogue | |
| Model | Llama-3.2-3B | Llama-3-8B | Llama-3.2-1B | Llama-3.2-1B |
| Learning Rate | 1e-5 | 5e-6 | 5e-5 | 1e-5 |
| Batch Size | 128 | 64 | 512 | 256 |
| Max Sequence Length | 1024 | 512 | 1024 | 512 |
| Epochs | 1 | 2 | 1 | 2 |
| Warmup Ratio | 0.05 | 0.05 | 0.03 | 0.03 |
| Weight Decay | 0.01 | 0.01 | 0.001 | 0.001 |
🔼 This table details the hyperparameters used during the training phase for different language models and tasks. It includes information on the specific model architecture (e.g., Llama-3.2-3B), learning rate, batch size, maximum sequence length, number of training epochs, warmup ratio, and weight decay. The information is broken down by model type (base policy and reward model) and specific task (summarization and multi-turn dialogue).
read the caption
Table 5: Training hyperparameters for different models and tasks
Full paper#