TL;DR#
Large Language Models (LLMs) often generate hallucinations, mixing truthful and incorrect information. Existing methods, using response-level feedback, inadvertently introduce noise during training. To solve the issue, the paper introduces Mask-DPO, a fine-grained approach that uses sentence-level factuality as a mask signal, only training on factually correct sentences and preventing penalties on truthful content when models make mistakes.
Experimental results show that Mask-DPO significantly improves factuality on both in-domain and out-of-domain tasks, surpassing existing models. The method also improves generalization by scaling training data effectively, emphasizing the importance of topic diversity. Furthermore, the paper hypothesizes that factuality alignment adjusts LLMs’ internal knowledge structures, improving the model’s responses.
Key Takeaways#
Why does it matter?#
This paper is important to researchers since it addresses a critical issue in LLMs: hallucinations. By introducing a novel and effective method (Mask-DPO) for factuality alignment, the study paves the way for more reliable and trustworthy LLMs. Furthermore, the investigation of data scaling strategies and their impact on generalization is valuable for future research in this area, opening avenues for improving LLMs.
Visual Insights#

🔼 This figure illustrates the core difference between the vanilla Direct Preference Optimization (DPO) method and the proposed Mask-DPO method for factuality alignment in LLMs. Vanilla DPO uses response-level factuality, leading to the model inadvertently encouraging incorrect information in preferred samples and penalizing correct information in non-preferred samples. Mask-DPO addresses this issue by incorporating sentence-level factuality as a mask signal during training. This allows Mask-DPO to learn only from factually correct sentences in the preferred samples, thus resolving ambiguity and enhancing the effectiveness of factuality alignment.
read the caption
Figure 1: Comparison between DPO and Mask-DPO. Vanilla DPO (a) inadvertently encourages and penalizes all the content in the preferred and non-preferred samples, respectively, regardless of their correctness. Instead, Mask-DPO (b) incorporates sentence-level facticity into the mask signal, preventing incorrect reward signal, which resolves ambiguity in preference learning.
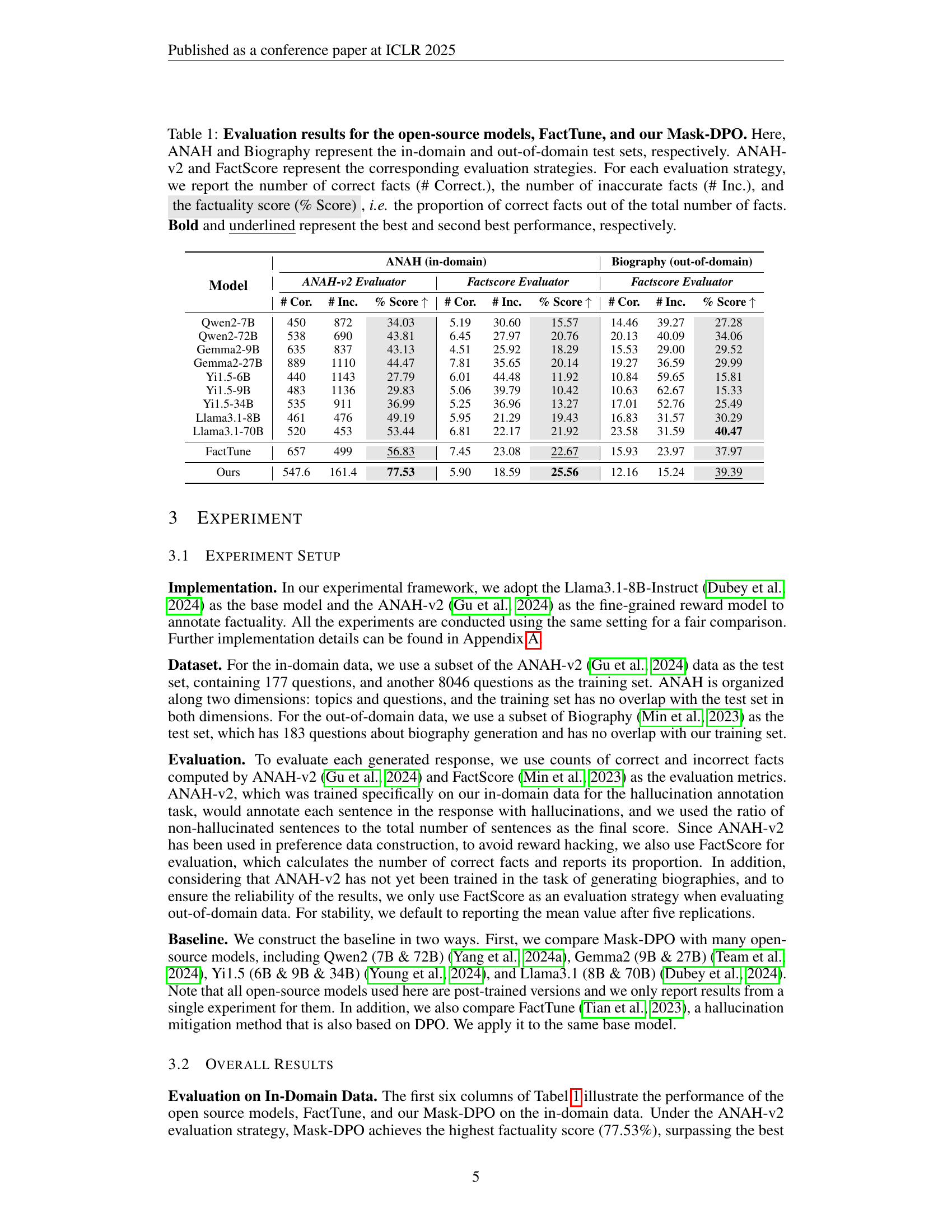
| Model | ANAH (in-domain) | Biography (out-of-domain) | |||||||
| ANAH-v2 Evaluator | Factscore Evaluator | Factscore Evaluator | |||||||
| # Cor. | # Inc. | % Score | # Cor. | # Inc. | % Score | # Cor. | # Inc. | % Score | |
| Qwen2-7B | 450 | 872 | 34.03 | 5.19 | 30.60 | 15.57 | 14.46 | 39.27 | 27.28 |
| Qwen2-72B | 538 | 690 | 43.81 | 6.45 | 27.97 | 20.76 | 20.13 | 40.09 | 34.06 |
| Gemma2-9B | 635 | 837 | 43.13 | 4.51 | 25.92 | 18.29 | 15.53 | 29.00 | 29.52 |
| Gemma2-27B | 889 | 1110 | 44.47 | 7.81 | 35.65 | 20.14 | 19.27 | 36.59 | 29.99 |
| Yi1.5-6B | 440 | 1143 | 27.79 | 6.01 | 44.48 | 11.92 | 10.84 | 59.65 | 15.81 |
| Yi1.5-9B | 483 | 1136 | 29.83 | 5.06 | 39.79 | 10.42 | 10.63 | 62.67 | 15.33 |
| Yi1.5-34B | 535 | 911 | 36.99 | 5.25 | 36.96 | 13.27 | 17.01 | 52.76 | 25.49 |
| Llama3.1-8B | 461 | 476 | 49.19 | 5.95 | 21.29 | 19.43 | 16.83 | 31.57 | 30.29 |
| Llama3.1-70B | 520 | 453 | 53.44 | 6.81 | 22.17 | 21.92 | 23.58 | 31.59 | 40.47 |
| FactTune | 657 | 499 | 56.83 | 7.45 | 23.08 | 22.67 | 15.93 | 23.97 | 37.97 |
| Ours | 547.6 | 161.4 | 77.53 | 5.90 | 18.59 | 25.56 | 12.16 | 15.24 | 39.39 |
🔼 This table presents a comparison of factuality scores achieved by various large language models (LLMs) on two datasets: ANAH (in-domain) and Biography (out-of-domain). The models compared include several open-source LLMs, FactTune (a factuality enhancement method), and the proposed Mask-DPO method. Two different evaluation metrics are used: ANAH-v2 and FactScore. For each model and metric, the number of correct and incorrect factual statements are reported, along with the overall factuality score (percentage of correct statements). The best and second-best performing models for each metric are highlighted.
read the caption
Table 1: Evaluation results for the open-source models, FactTune, and our Mask-DPO. Here, ANAH and Biography represent the in-domain and out-of-domain test sets, respectively. ANAH-v2 and FactScore represent the corresponding evaluation strategies. For each evaluation strategy, we report the number of correct facts (# Correct.), the number of inaccurate facts (# Inc.), and the factuality score (% Score), i.e. the proportion of correct facts out of the total number of facts. Bold and underlined represent the best and second best performance, respectively.
In-depth insights#
Factuality F-tuning#
Factuality Fine-tuning is crucial for reliable LLMs. Aligning models with factual knowledge requires addressing inherent hallucinations. Existing methods using response-level preferences introduce noise, penalizing correct content alongside errors. A fine-grained approach is needed, masking sentence-level factuality. Mask-DPO leverages sentence-level factuality to guide training, avoiding penalization of truthful content. This resolves preference learning ambiguity, improving in-domain and out-of-domain generalization. Scaling by increasing the number of topics during alignment is more effective for knowledge adaptation. The underlying knowledge graph adjusts, influencing generalization. This addresses the need for targeted adjustments, rather than broad distributional changes. This refines LLM knowledge, boosting real-world applications.
Mask-DPO Insight#
Mask-DPO refines LLM factuality by masking sentence-level inaccuracies during DPO, addressing the issue where truthful content is penalized alongside hallucinations. This fine-grained approach enables more precise knowledge alignment, leading to improved performance on both in-domain and out-of-domain datasets. The method’s success hinges on sentence-level factuality, as this allows for accurate reward signals during preference learning. It prevents inadvertently encouraging inaccuracies or penalizing truths, a problem inherent in response-level methods like vanilla DPO. By integrating sentence-level factuality, Mask-DPO effectively improves the factuality of LLMs, showcasing its potential in enhancing the reliability of these models across various domains. This is particularly important since mitigating hallucinations improves LLM trustworthiness.
Topic Scaling#
Topic scaling appears to be a critical factor in improving the factuality and generalization capabilities of LLMs. The research suggests that diversifying the topics within the training data leads to better performance than simply increasing the number of questions within the same topics. This highlights the importance of exposing the model to a broader range of knowledge domains to improve its ability to answer questions accurately and generalize to new, unseen topics. The success of topic scaling likely stems from the LLM’s ability to develop a more robust and well-rounded understanding of the world when trained on a diverse set of subjects. Furthermore, the research implies that focusing on topics helps the model grasp broader concepts, while question variety under a single topic might lead to overfitting to specific question structures, hindering generalization.
Knowledge Graph#
Knowledge graphs (KGs) offer a structured way to represent information, connecting entities through relationships. They can enhance LLMs by providing factual knowledge. LLMs often struggle with hallucination, KGs can serve as external knowledge sources, grounding responses in verifiable facts. By integrating KGs, LLMs can access and reason over structured data, reducing reliance on parametric memory and improving accuracy. Factuality alignment methods are essential to minimize errors and provide trustable information. The effectiveness hinges on KG quality and integration strategy; a poorly constructed KG or ineffective integration can yield limited benefits.
RLHF Extension#
Reinforcement Learning from Human Feedback (RLHF) has become a pivotal technique for aligning LLMs with human preferences, extending beyond mere task completion to encompass aspects like robustness, factuality, and safety. This extension involves a complex pipeline: initially training a reward model to mimic human judgment and iteratively optimizing the language model using the reward signal. RLHF’s adaptability allows it to integrate diverse feedback sources, offering granular control over model behavior. Recent advancements explore more efficient methods like Direct Preference Optimization (DPO) to sidestep explicit reward modeling, directly optimizing the policy model using preference data. These methods also seek to refine data creation utilizing AI feedback.
More visual insights#
More on tables
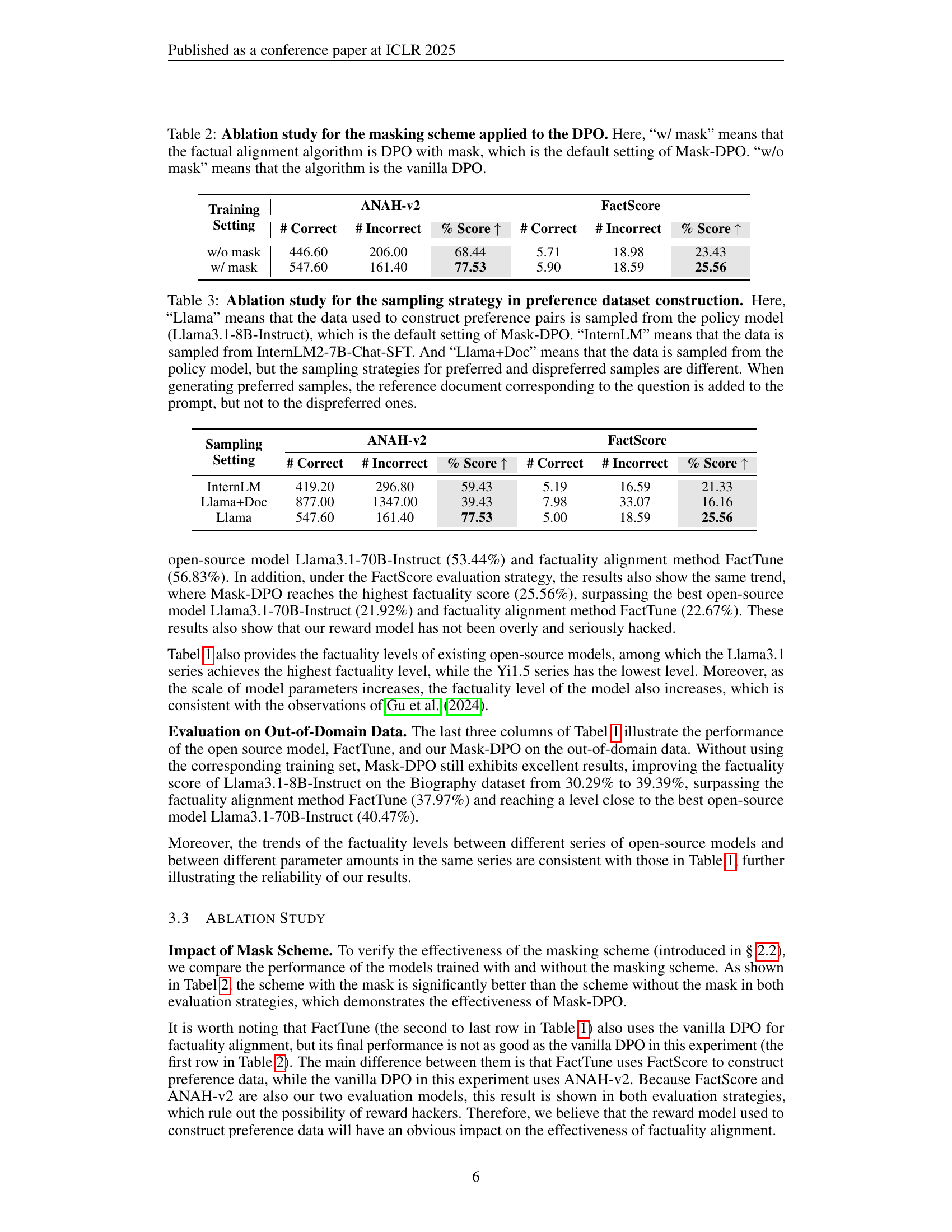
| Training Setting | ANAH-v2 | FactScore | ||||
| # Correct | # Incorrect | % Score | # Correct | # Incorrect | % Score | |
| w/o mask | 446.60 | 206.00 | 68.44 | 5.71 | 18.98 | 23.43 |
| w/ mask | 547.60 | 161.40 | 77.53 | 5.90 | 18.59 | 25.56 |
🔼 This table presents an ablation study comparing the performance of the proposed Mask-DPO method against a baseline DPO method without the masking scheme. The study evaluates the impact of the masking scheme on the factuality of the model’s responses. The ‘w/ mask’ column shows results using the Mask-DPO method (DPO with masking), while ‘w/o mask’ shows results using standard DPO without masking. The table reports the number of correct and incorrect facts identified by two different metrics, ANAH-v2 and FactScore, and the corresponding factuality score for each condition. This allows for a quantitative assessment of how the proposed masking scheme contributes to improved factuality.
read the caption
Table 2: Ablation study for the masking scheme applied to the DPO. Here, “w/ mask” means that the factual alignment algorithm is DPO with mask, which is the default setting of Mask-DPO. “w/o mask” means that the algorithm is the vanilla DPO.
| Sampling Setting | ANAH-v2 | FactScore | ||||
| # Correct | # Incorrect | % Score | # Correct | # Incorrect | % Score | |
| InternLM | 419.20 | 296.80 | 59.43 | 5.19 | 16.59 | 21.33 |
| Llama+Doc | 877.00 | 1347.00 | 39.43 | 7.98 | 33.07 | 16.16 |
| Llama | 547.60 | 161.40 | 77.53 | 5.00 | 18.59 | 25.56 |
🔼 This table presents an ablation study comparing different sampling strategies for creating preference data used in Mask-DPO. The default strategy samples data from the Llama3.1-8B-Instruct policy model. The comparison includes using data from InternLM2-7B-Chat-SFT, and a strategy where the policy model is used, but preferred samples include the reference document in the prompt, while dispreferred samples do not.
read the caption
Table 3: Ablation study for the sampling strategy in preference dataset construction. Here, “Llama” means that the data used to construct preference pairs is sampled from the policy model (Llama3.1-8B-Instruct), which is the default setting of Mask-DPO. “InternLM” means that the data is sampled from InternLM2-7B-Chat-SFT. And “Llama+Doc” means that the data is sampled from the policy model, but the sampling strategies for preferred and dispreferred samples are different. When generating preferred samples, the reference document corresponding to the question is added to the prompt, but not to the dispreferred ones.
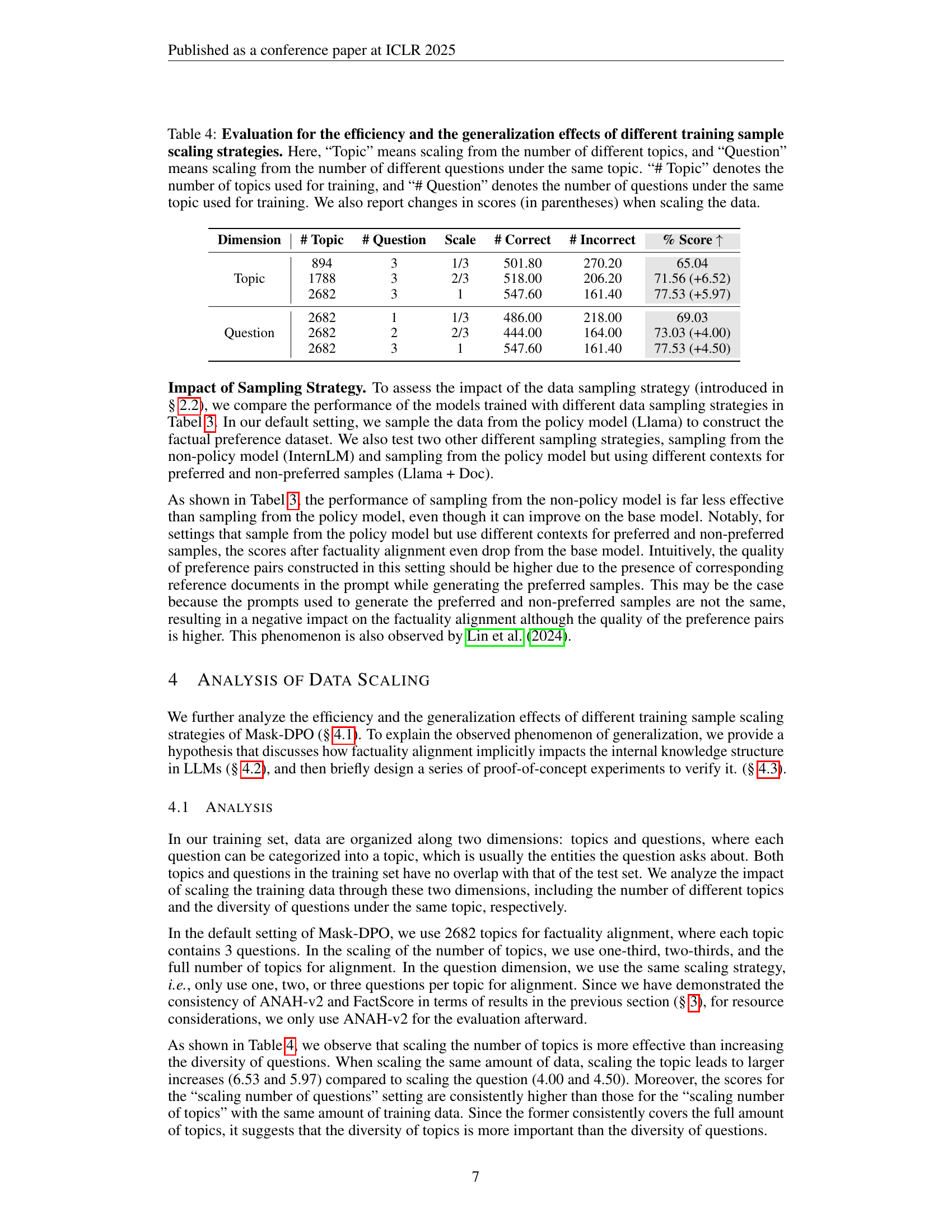
| Dimension | # Topic | # Question | Scale | # Correct | # Incorrect | % Score |
| Topic | 894 | 3 | 1/3 | 501.80 | 270.20 | 65.04 |
| 1788 | 3 | 2/3 | 518.00 | 206.20 | 71.56 (+6.52) | |
| 2682 | 3 | 1 | 547.60 | 161.40 | 77.53 (+5.97) | |
| Question | 2682 | 1 | 1/3 | 486.00 | 218.00 | 69.03 |
| 2682 | 2 | 2/3 | 444.00 | 164.00 | 73.03 (+4.00) | |
| 2682 | 3 | 1 | 547.60 | 161.40 | 77.53 (+4.50) |
🔼 This table presents a study on the impact of scaling training data on the efficiency and generalization of Mask-DPO, a fine-grained factuality alignment method. Two scaling strategies were used: scaling the number of different topics and scaling the number of questions within each topic. The table shows the number of topics and questions used for training at different scales (1/3, 2/3, and 1x the original data), along with the corresponding number of correct and incorrect facts, factuality score, and the change in score compared to the baseline. This allows for analysis of how different scaling approaches affect the performance of the model, specifically its ability to generalize to unseen data.
read the caption
Table 4: Evaluation for the efficiency and the generalization effects of different training sample scaling strategies. Here, “Topic” means scaling from the number of different topics, and “Question” means scaling from the number of different questions under the same topic. “# Topic” denotes the number of topics used for training, and “# Question” denotes the number of questions under the same topic used for training. We also report changes in scores (in parentheses) when scaling the data.
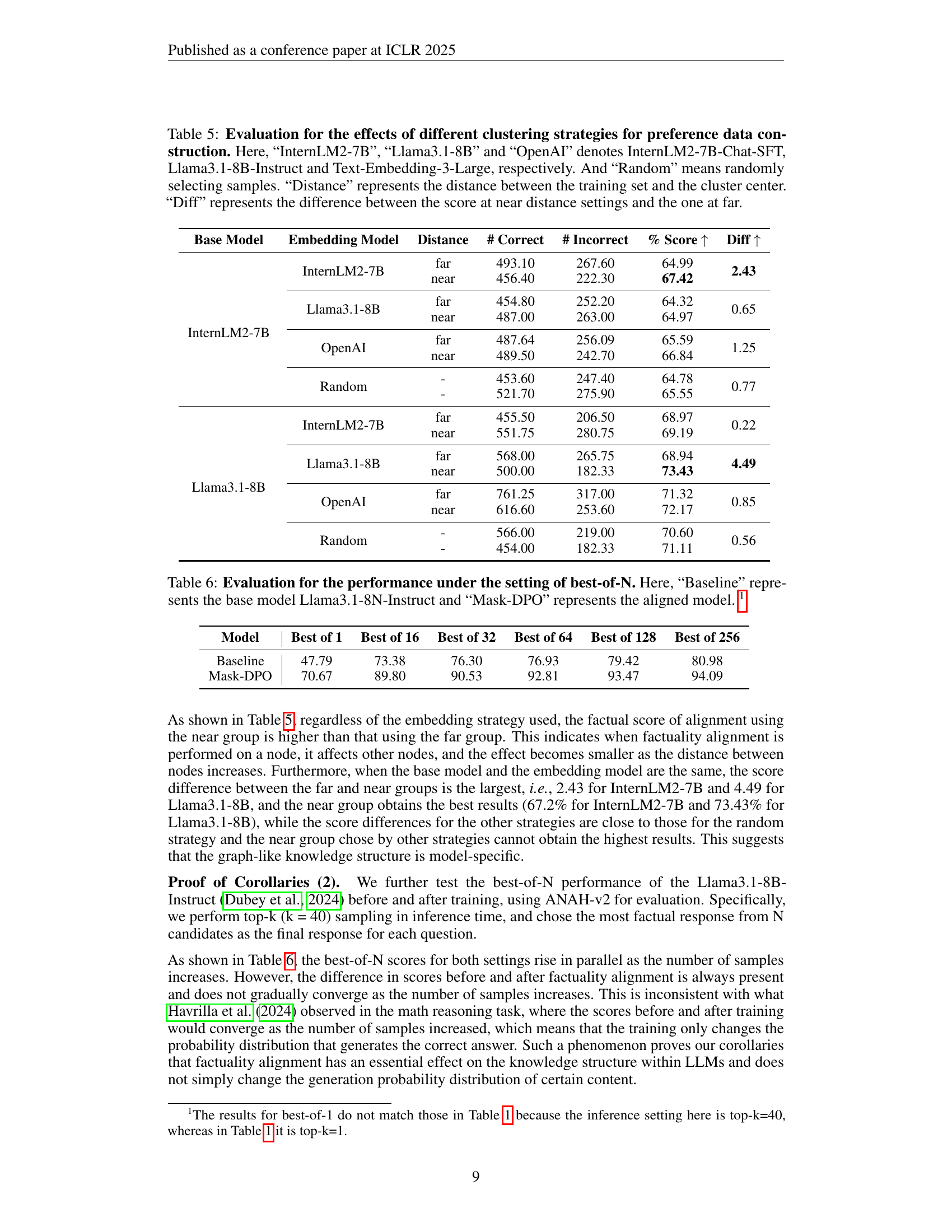
| Base Model | Embedding Model | Distance | # Correct | # Incorrect | % Score | Diff |
| InternLM2-7B | InternLM2-7B | far | 493.10 | 267.60 | 64.99 | 2.43 |
| near | 456.40 | 222.30 | 67.42 | |||
| Llama3.1-8B | far | 454.80 | 252.20 | 64.32 | 0.65 | |
| near | 487.00 | 263.00 | 64.97 | |||
| OpenAI | far | 487.64 | 256.09 | 65.59 | 1.25 | |
| near | 489.50 | 242.70 | 66.84 | |||
| Random | - | 453.60 | 247.40 | 64.78 | 0.77 | |
| - | 521.70 | 275.90 | 65.55 | |||
| Llama3.1-8B | InternLM2-7B | far | 455.50 | 206.50 | 68.97 | 0.22 |
| near | 551.75 | 280.75 | 69.19 | |||
| Llama3.1-8B | far | 568.00 | 265.75 | 68.94 | 4.49 | |
| near | 500.00 | 182.33 | 73.43 | |||
| OpenAI | far | 761.25 | 317.00 | 71.32 | 0.85 | |
| near | 616.60 | 253.60 | 72.17 | |||
| Random | - | 566.00 | 219.00 | 70.60 | 0.56 | |
| - | 454.00 | 182.33 | 71.11 |
🔼 This table presents a quantitative analysis of the impact of different topic clustering strategies on the effectiveness of Mask-DPO’s factuality alignment. Four different methods for generating topic embeddings are compared: InternLM2-7B-Chat-SFT, Llama3.1-8B-Instruct, Text-Embedding-3-Large, and a random baseline. For each embedding method, the training data is divided into ’near’ and ‘far’ groups based on the distance of each topic’s embedding to the cluster center. The table shows the number of correct and incorrect facts, the overall factuality score, and the difference in score between the ’near’ and ‘far’ groups for each embedding method. The results demonstrate the relationship between topic proximity and factuality improvement after alignment.
read the caption
Table 5: Evaluation for the effects of different clustering strategies for preference data construction. Here, “InternLM2-7B”, “Llama3.1-8B” and “OpenAI” denotes InternLM2-7B-Chat-SFT, Llama3.1-8B-Instruct and Text-Embedding-3-Large, respectively. And “Random” means randomly selecting samples. “Distance” represents the distance between the training set and the cluster center. “Diff” represents the difference between the score at near distance settings and the one at far.
| Model | Best of 1 | Best of 16 | Best of 32 | Best of 64 | Best of 128 | Best of 256 |
| Baseline | 47.79 | 73.38 | 76.30 | 76.93 | 79.42 | 80.98 |
| Mask-DPO | 70.67 | 89.80 | 90.53 | 92.81 | 93.47 | 94.09 |
🔼 This table presents the performance comparison between the baseline model (Llama-3.1-8B-Instruct) and the Mask-DPO model under different best-of-N settings. Best-of-N refers to selecting the top-performing response from N generated responses. The table shows the number of correct and incorrect facts and the resulting factuality score for each model and each N value (1, 16, 32, 64, 128, 256). The discrepancy between the best-of-1 results here and those reported in Table 1 is because the inference setting used here is top-k=40, while the setting for Table 1 was top-k=1. This highlights the impact of different inference parameters on model performance.
read the caption
Table 6: Evaluation for the performance under the setting of best-of-N. Here, “Baseline” represents the base model Llama3.1-8N-Instruct and “Mask-DPO” represents the aligned model. 222The results for best-of-1 do not match those in Table 1 because the inference setting here is top-k=40, whereas in Table 1 it is top-k=1.
| # Correct | # Incorrect | % Score | |
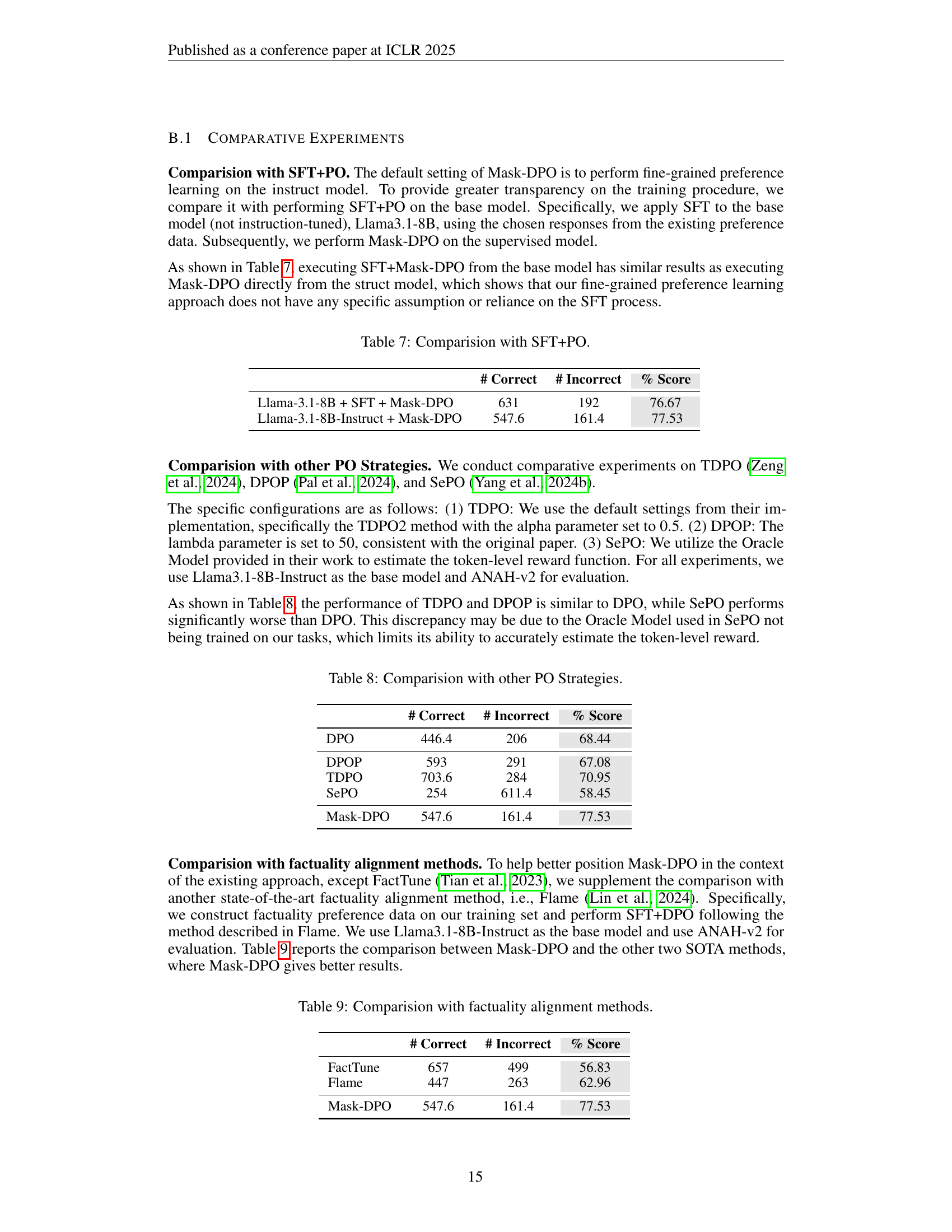
| Llama-3.1-8B + SFT + Mask-DPO | 631 | 192 | 76.67 |
| Llama-3.1-8B-Instruct + Mask-DPO | 547.6 | 161.4 | 77.53 |
🔼 This table compares the performance of two approaches to factuality alignment: 1) directly applying Mask-DPO to an instruction-tuned LLM and 2) first applying supervised fine-tuning (SFT) to a base LLM and then applying Mask-DPO. It shows the number of correct and incorrect facts, as well as the factuality score achieved by each method. This comparison helps demonstrate that the effectiveness of Mask-DPO is not dependent on a prior SFT step.
read the caption
Table 7: Comparision with SFT+PO.
| # Correct | # Incorrect | % Score | |
| DPO | 446.4 | 206 | 68.44 |
| DPOP | 593 | 291 | 67.08 |
| TDPO | 703.6 | 284 | 70.95 |
| SePO | 254 | 611.4 | 58.45 |
| Mask-DPO | 547.6 | 161.4 | 77.53 |
🔼 This table compares the performance of Mask-DPO against other Preference Optimization (PO) strategies, namely TDPO, DPOP, and SePO, in enhancing the factuality of LLMs. It uses Llama3.1-8B-Instruct as the base model and ANAH-v2 for evaluation. The table shows the number of correct and incorrect facts, as well as the factuality score for each method, illustrating Mask-DPO’s superior performance compared to others.
read the caption
Table 8: Comparision with other PO Strategies.
| # Correct | # Incorrect | % Score | |
| FactTune | 657 | 499 | 56.83 |
| Flame | 447 | 263 | 62.96 |
| Mask-DPO | 547.6 | 161.4 | 77.53 |
🔼 This table presents a comparison of the factuality scores achieved by three different factuality alignment methods: Mask-DPO (the proposed method), FactTune, and Flame. The scores are based on the ANAH-v2 evaluation metric, indicating the proportion of correctly stated facts in the model’s responses. The table highlights Mask-DPO’s superior performance in terms of factuality compared to the other state-of-the-art methods.
read the caption
Table 9: Comparision with factuality alignment methods.
| GSM8K | MATH | GPQA | Human Eval | MBPP | |
| Baseline | 84.91 | 52.72 | 26.77 | 70.73 | 71.21 |
| Mask-DPO | 86.20 | 47.68 | 31.82 | 68.29 | 70.04 |
🔼 This table presents the performance of the Llama3.1-8B-Instruct model on several standard benchmarks before and after applying the Mask-DPO factuality alignment technique. The benchmarks cover diverse tasks, including mathematical reasoning (GSM8K, MATH, GPQA) and code generation (HumanEval, MBPP). The table shows the scores achieved by the model in each benchmark, allowing comparison of performance before and after the alignment process. This comparison helps determine if the improvement in factuality provided by Mask-DPO impacts the model’s overall capabilities across different tasks.
read the caption
Table 10: Evaluation on Standard Benchmarks.
| Temperature | # Correct | # Incorrect | % Score |
| 0.25 | 485 | 259.2 | 65.30 |
| 0.5 | 539 | 244.8 | 67.96 |
| 0.75 | 733 | 219 | 76.02 |
| 1.0 | 732 | 240.6 | 74.24 |
| 0.8 (default) | 547.6 | 161.4 | 77.53 |
🔼 This table presents the results of an ablation study on the impact of different inference temperatures on the performance of the Mask-DPO model. The study evaluates the model’s performance using four different temperatures: 0.25, 0.5, 0.75, and 1.0, with the default temperature of 0.8 included for comparison. The results show the number of correct and incorrect facts, along with the factuality score for each temperature setting. This analysis helps to determine the optimal temperature setting for the Mask-DPO model, balancing the trade-off between diversity and accuracy in the model’s outputs.
read the caption
Table 11: Evaluation on different inference setup.
| Distance | # Correct | # Incorrect | % Score | Diff |
| far | 541.4 | 214 | 71.69 | 0.23 |
| near | 518 | 195 | 71.92 |
🔼 This table presents an ablation study evaluating different strategies for constructing preference data in the Mask-DPO model. Specifically, it compares the performance of clustering topics based on questions versus topics to determine which is more effective in improving the model’s factuality. The table shows the number of correct and incorrect facts, along with the resulting factuality score, for each sampling strategy. The purpose is to assess if the model’s internal knowledge representation is organized primarily around topics or questions, helping to understand the impact of data scaling strategies for factuality alignment.
read the caption
Table 12: Evaluation on question-based clustering strategies for preference data construction.
Full paper#