TL;DR#
Collecting task completion data or human demonstrations for complex reasoning is expensive, especially in interactive domains. This creates a need for self-supervised methods for policy or value LLMs to avoid ground truth. Prior methods are constrained by the capabilities of base models or require ground truth rewards to guide node selection during search.
This paper introduces Self-Taught Lookahead (STL), a self-supervised method that uses state-transition dynamics to train a value model for language model-controlled search. STL matches the performance of frontier LLMs, improves performance by 20%, and reduces costs by 37x compared to previous LLM-based tree search.
Key Takeaways#
Why does it matter?#
This work is important because it offers a self-supervised learning method to improve value estimation in LLM-based search, reducing reliance on costly ground truth data. It presents a cost-effective alternative that maintains performance and opens new avenues for efficient agent training and deployment.
Visual Insights#
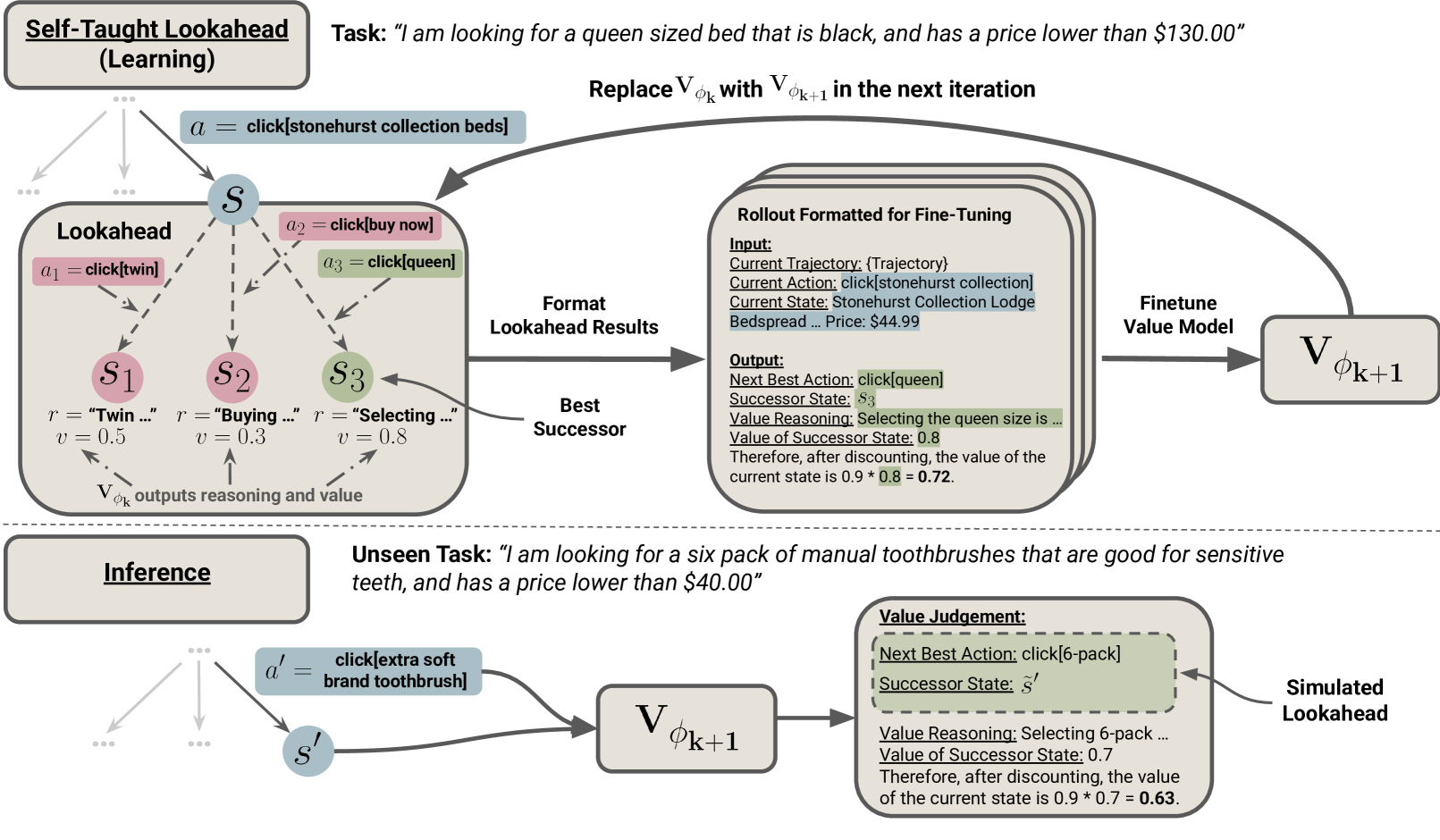
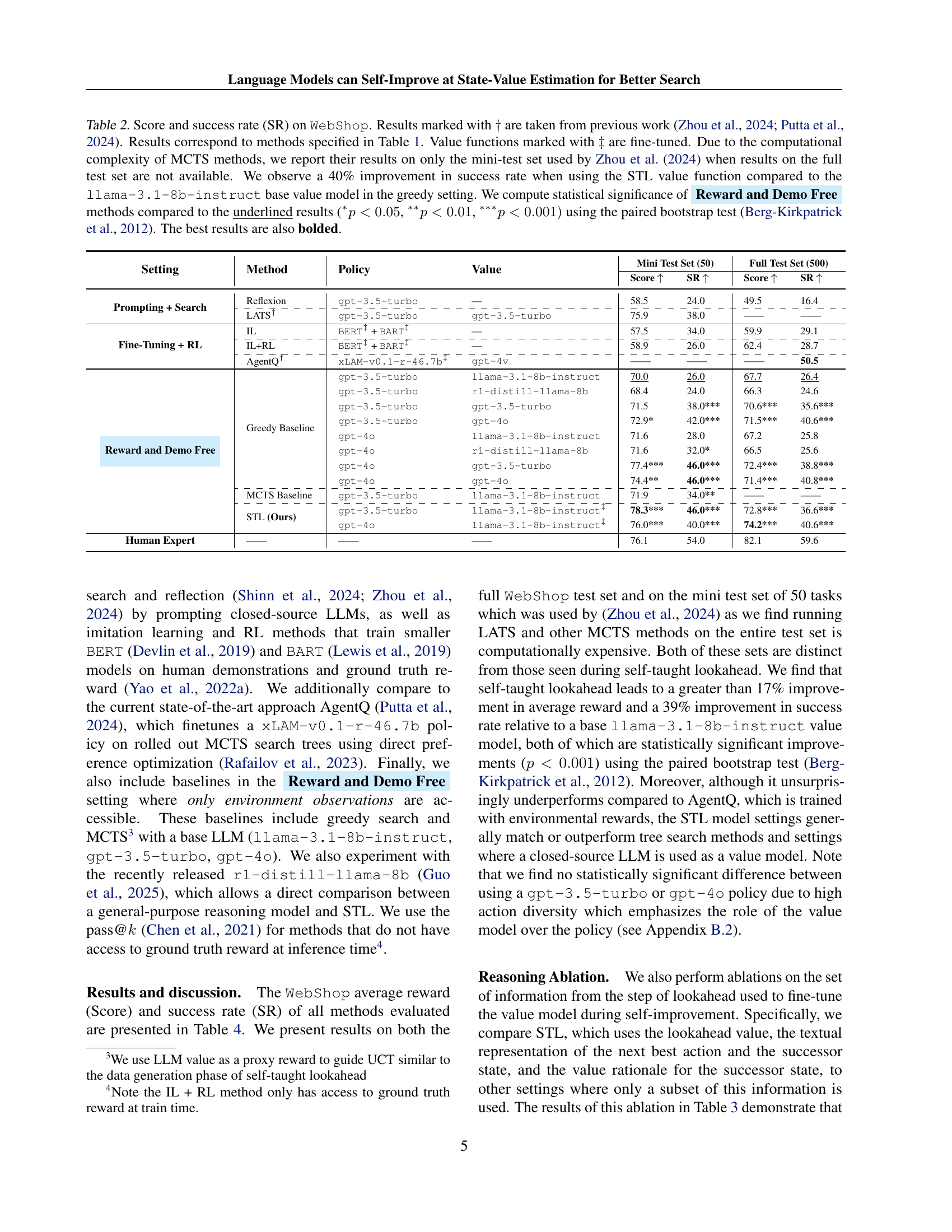
🔼 Figure 1 illustrates the self-taught lookahead (STL) process. The top-left panel shows the data generation phase, where a tree search explores various states. For each state encountered, possible successor states are generated using a base policy and the current value model. The top-middle panel shows how verbal representations of the best action and successor state, along with the value model’s reasoning and numerical value, are used to create formatted training examples. These examples are used to fine-tune an improved value model (top-right panel), which is then used in the next iteration of the algorithm. Finally, the bottom panel demonstrates how the learned value model can evaluate unseen states during search by simulating a single lookahead step, considering the best next action and resulting state.
read the caption
Figure 1: Self-taught lookahead self-improves the value model by learning from state-transition dynamics. During the data generation phase (top left), tree search is used to discover diverse states. For every observed state s𝑠sitalic_s encountered during the search, successor states are expanded using base policy πθsubscript𝜋𝜃\pi_{\theta}italic_π start_POSTSUBSCRIPT italic_θ end_POSTSUBSCRIPT and the current value model Vϕksubscript𝑉subscriptitalic-ϕ𝑘V_{\phi_{k}}italic_V start_POSTSUBSCRIPT italic_ϕ start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT end_POSTSUBSCRIPT, and a formatted textual training example is formed using verbal representations of the next best action and successor state, as well as Vϕksubscript𝑉subscriptitalic-ϕ𝑘V_{\phi_{k}}italic_V start_POSTSUBSCRIPT italic_ϕ start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT end_POSTSUBSCRIPT’s outputted value reasoning (r𝑟ritalic_r) and numerical value (v𝑣vitalic_v) (top middle). These examples are used to fine-tune Vϕk+1subscript𝑉subscriptitalic-ϕ𝑘1V_{\phi_{k+1}}italic_V start_POSTSUBSCRIPT italic_ϕ start_POSTSUBSCRIPT italic_k + 1 end_POSTSUBSCRIPT end_POSTSUBSCRIPT, which will be used in the next iteration of the algorithm (top right). Value models learned during self-taught lookahead can be used to evaluate unseen states encountered during search on unseen tasks by simulating a step of lookahead including the next best action and the best successor state s~′superscript~𝑠′\tilde{s}^{\prime}over~ start_ARG italic_s end_ARG start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT (bottom).
| Method | Inference Config | Human Demo. | GT Reward | Env. Obs. | FT |
|---|---|---|---|---|---|
| Reflexion (Shinn et al., 2024) | — | ✗ | ✓ | ✓ | ✗ |
| LATS (Zhou et al., 2024) | MCTS | ✗ | ✓ | ✓ | ✗ |
| IL (Yao et al., 2022a) | pass@ | ✓ | ✗ | ✓ | ✓ |
| IL+RL (Yao et al., 2022a) | pass@ | ✓ | ✓ | ✓ | ✓ |
| MCTS + DPO (Putta et al., 2024) | MCTS | ✗ | ✓ | ✓ | ✓ |
| Greedy Baseline | Greedy (pass@) | ✗ | ✗ | ✓ | ✗ |
| MCTS Baseline | MCTS (pass@) | ✗ | ✗ | ✓ | ✗ |
| STL (Ours) | Greedy (pass@) | ✗ | ✗ | ✓ | ✓ |
| Expert (Yao et al., 2022a) | — | ✓ | ✗ | ✓ | — |
🔼 Table 1 provides a detailed comparison of various methods used for the WebShop task, a benchmark for evaluating agents’ performance in interactive web environments. Each method is analyzed across several key aspects. These include the specific language models employed (both for policy and value), the inference configuration used during the search process, and the reliance on various types of training data. Specifically, the table indicates whether each method utilizes human demonstrations, ground truth rewards, and environmental observations in its training or inference. It also notes whether fine-tuning is involved. Notably, a separate section highlights methods that operate in a ‘Reward and Demo Free’ setting, where only environmental observations are available. This distinction allows for a clear comparison of methods’ capabilities under different data availability constraints.
read the caption
Table 1: Comparison of methods for the WebShop task. For each method, the models and inference configuration are listed along with the usage of human demonstrations, ground truth rewards, environmental observations, and fine-tuning marked with ✓ (used) and ✗ (unused). In the Reward and Demo Free setting, only environment observations are accessible.
In-depth insights#
Self-Taught STL#
Self-Taught Lookahead (STL) presents a novel approach to improve LLM value models without ground truth task completion rewards or human intervention, particularly crucial in complex multi-step reasoning tasks. It is unique as it enables self-improvement by bootstrapping from an initial value function and leveraging state-transition dynamics. The algorithm generates self-improvement data through single-step lookahead in a tree search, refining state values akin to the Bellman update but without explicit environment rewards. It captures the mechanics of traditional RL by training a value model to predict the next best action, resulting state, and the rationale for the state’s value. This is better than prior methods that utilize ground truth. Self-taught lookahead effectively transfers computation from expensive large closed-source models to cheaper open-source alternatives.
LM Value Models#
While the paper doesn’t have a specific section titled “LM Value Models,” it extensively explores how Large Language Models (LLMs) can be leveraged to estimate state values in the context of tree search for complex reasoning tasks. The core idea revolves around using an LLM as a value function, guiding the search process by predicting the utility of different states. The authors introduce “Self-Taught Lookahead” (STL), a self-supervised method where the LLM bootstraps its value estimation by learning from state-transition dynamics without relying on ground truth rewards. This approach involves fine-tuning the LLM to reason about the utility of a state, predict the next best action, and generate a rationale for its value assessment. By explicitly incorporating rationales, the LLM can capture domain-specific state transitions more effectively, improving its ability to assign accurate values to states. Furthermore, the paper demonstrates that LLMs can replace computationally expensive components by generating proxy rewards, and the value models can be made with low cost and smaller models.
Action Rationale#
In the realm of language model-driven search and self-improvement, the concept of “action rationale” emerges as a critical component. Instead of merely focusing on the numerical value or score assigned to a state during tree search, explicitly capturing and learning from the reasoning behind state transitions enhances the model’s understanding of the environment’s dynamics. This involves generating rationales that explain the outcome of taking a specific action, detailing the resulting successor state and the rationale for its assigned value. This approach diverges from traditional methods that solely rely on numerical rewards, enabling the model to leverage the rich information encoded in natural language. By fine-tuning the value model on these action-outcome rationales, the model gains the ability to predict the consequences of actions and integrate this prediction into its value estimates. This not only improves accuracy but also fosters greater interpretability, as the model can articulate the reasoning behind its decisions. The action-outcome rationales capture which action yielded the best successor state and why the successor state was assigned a high value by V.
WebShop Pareto#
Analyzing a hypothetical “WebShop Pareto” section of a research paper, one would expect it to delve into the Pareto optimality of different approaches within the WebShop environment. This likely involves examining the trade-offs between various performance metrics such as task completion rate, cost, environmental impact (number of states visited), and computational efficiency. The section might present a Pareto frontier, visually demonstrating the methods that offer the best balance between these competing objectives, where no improvement can be made in one metric without sacrificing another. A key focus would be on identifying approaches that achieve high task success with minimal computational resources and environmental interaction, reflecting a shift towards more sustainable and efficient agent designs. The section might also analyze why certain methods fall short of the Pareto frontier, identifying bottlenecks or inefficiencies that hinder their overall performance. Furthermore, expect a discussion on the limitations of the chosen metrics and potential avenues for future research to explore alternative performance measures that better capture the complexities of the WebShop environment.
Smaller Models#
It’s intriguing to consider the role of smaller language models in self-improvement techniques like self-taught lookahead (STL). While larger models like gpt-40 may offer strong initial capabilities, the practical benefits of smaller models, even those below 3 billion parameters, are noteworthy. These smaller models, when boosted with STL, demonstrate the capacity to match the performance of significantly larger models, pointing towards enhanced efficiency and reduced computational costs. This is especially relevant in real-world applications where resource constraints are a major concern. The key lies in STL’s ability to transfer knowledge from larger, potentially closed-source models to these smaller, open-source alternatives. This not only lowers the barrier to entry but also fosters greater accessibility and wider adoption. The finding that even the smaller models can be improved by STL opens up further possibilities, especially around improving the edge-computing capabilities of LLMs.
More visual insights#
More on figures

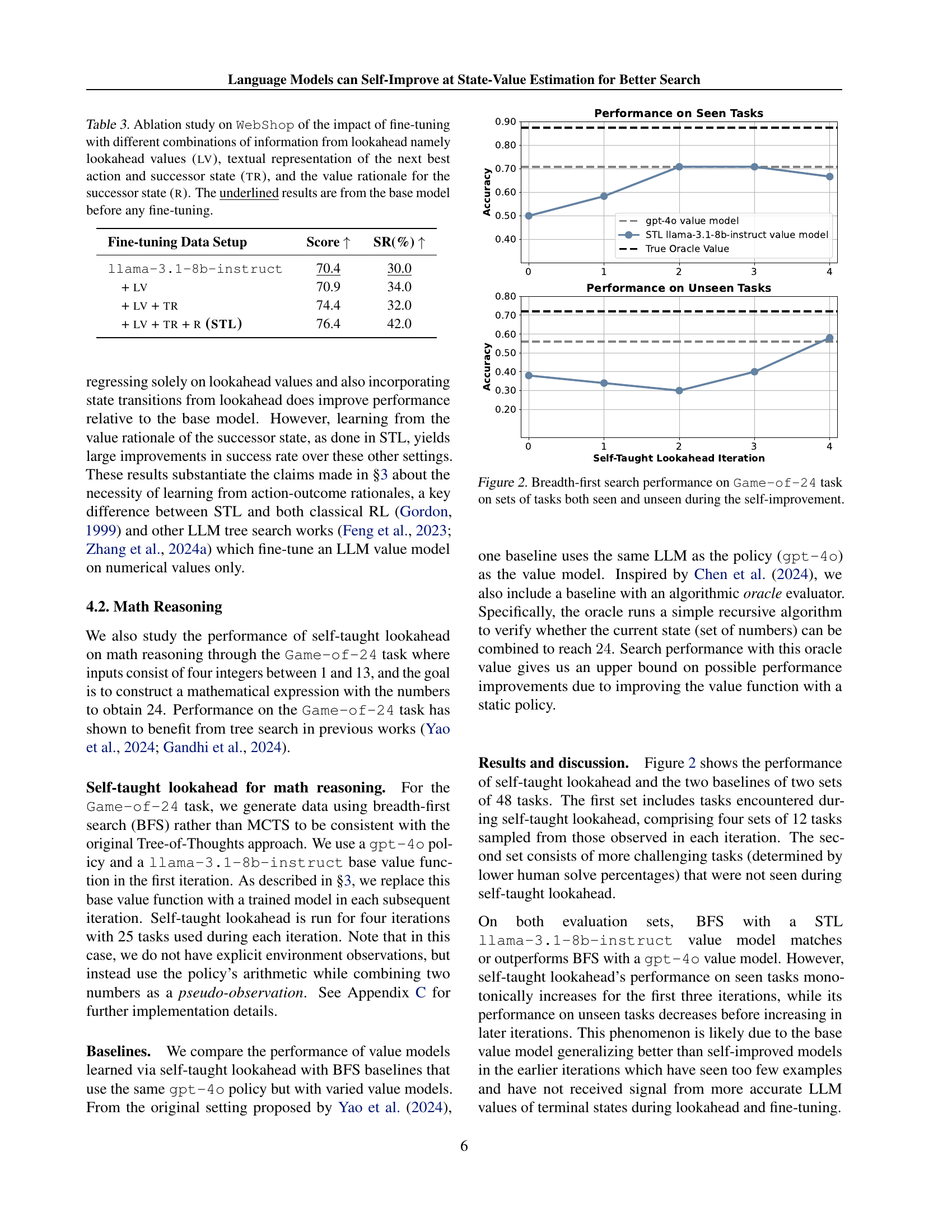
🔼 Figure 2 presents the results of applying self-taught lookahead to the Game-of-24 math reasoning task. The figure displays the performance of breadth-first search using different value models. One uses a GPT-40 LLM directly as a value model (baseline), the other employs a llama-3.1-8b-instruct model fine-tuned using the self-taught lookahead method. The performance is assessed on two sets of tasks: one set consists of tasks encountered during the self-improvement process, and the other comprises unseen tasks. The x-axis indicates the number of iterations of self-taught lookahead, and the y-axis represents the accuracy achieved by the search algorithm.
read the caption
Figure 2: Breadth-first search performance on Game-of-24 task on sets of tasks both seen and unseen during the self-improvement.

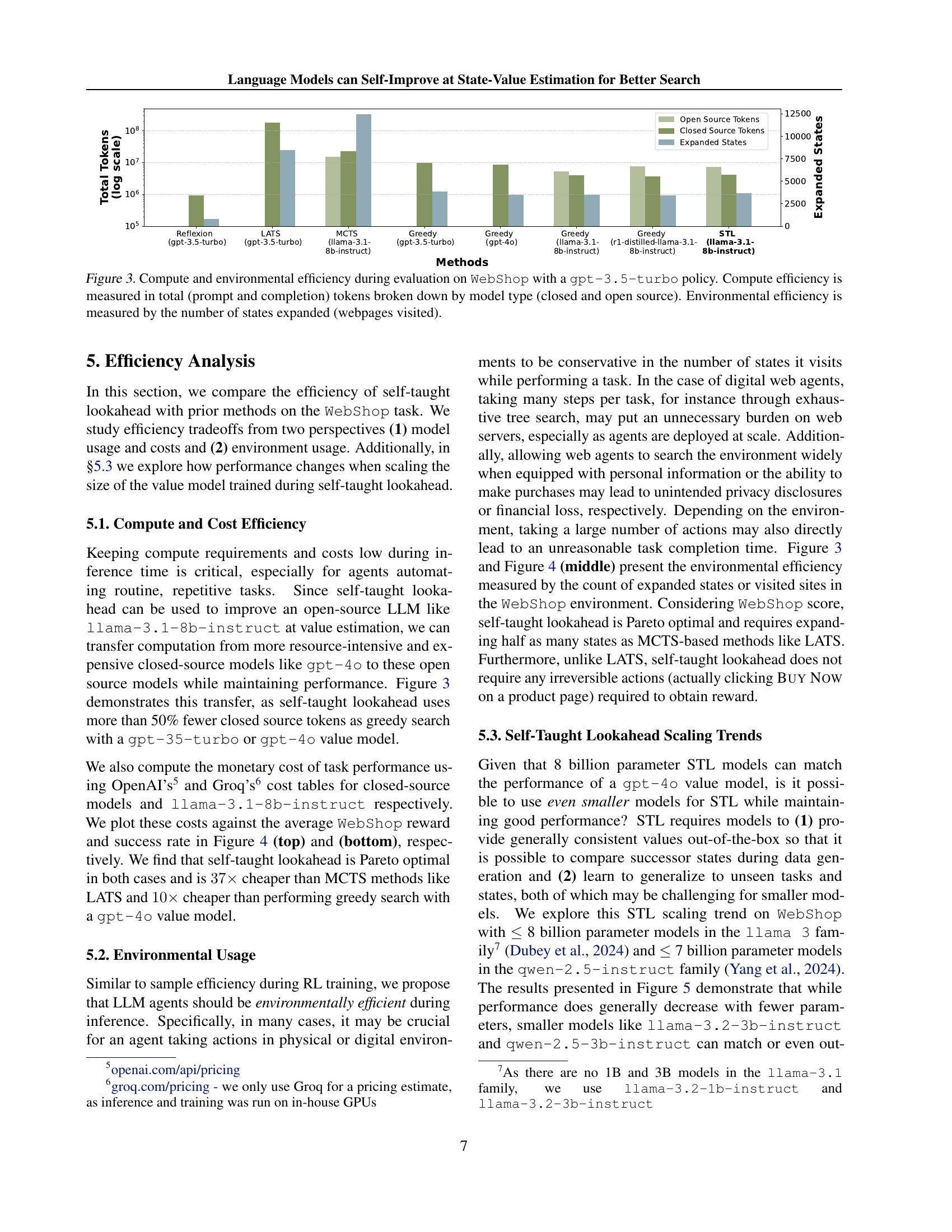
🔼 Figure 3 compares the computational and environmental efficiency of different methods for the WebShop task, using a gpt-3.5-turbo policy. Computational efficiency is presented as the total number of tokens used (prompt and completion tokens combined), categorized by whether the model was open or closed source. This highlights the cost difference between using open-source LLMs and large, closed-source models. Environmental efficiency is depicted as the number of states or ‘webpages visited’ during the search process. This illustrates the impact of different search methods on resource consumption and the number of interactions required with the website.
read the caption
Figure 3: Compute and environmental efficiency during evaluation on WebShop with a gpt-3.5-turbo policy. Compute efficiency is measured in total (prompt and completion) tokens broken down by model type (closed and open source). Environmental efficiency is measured by the number of states expanded (webpages visited).

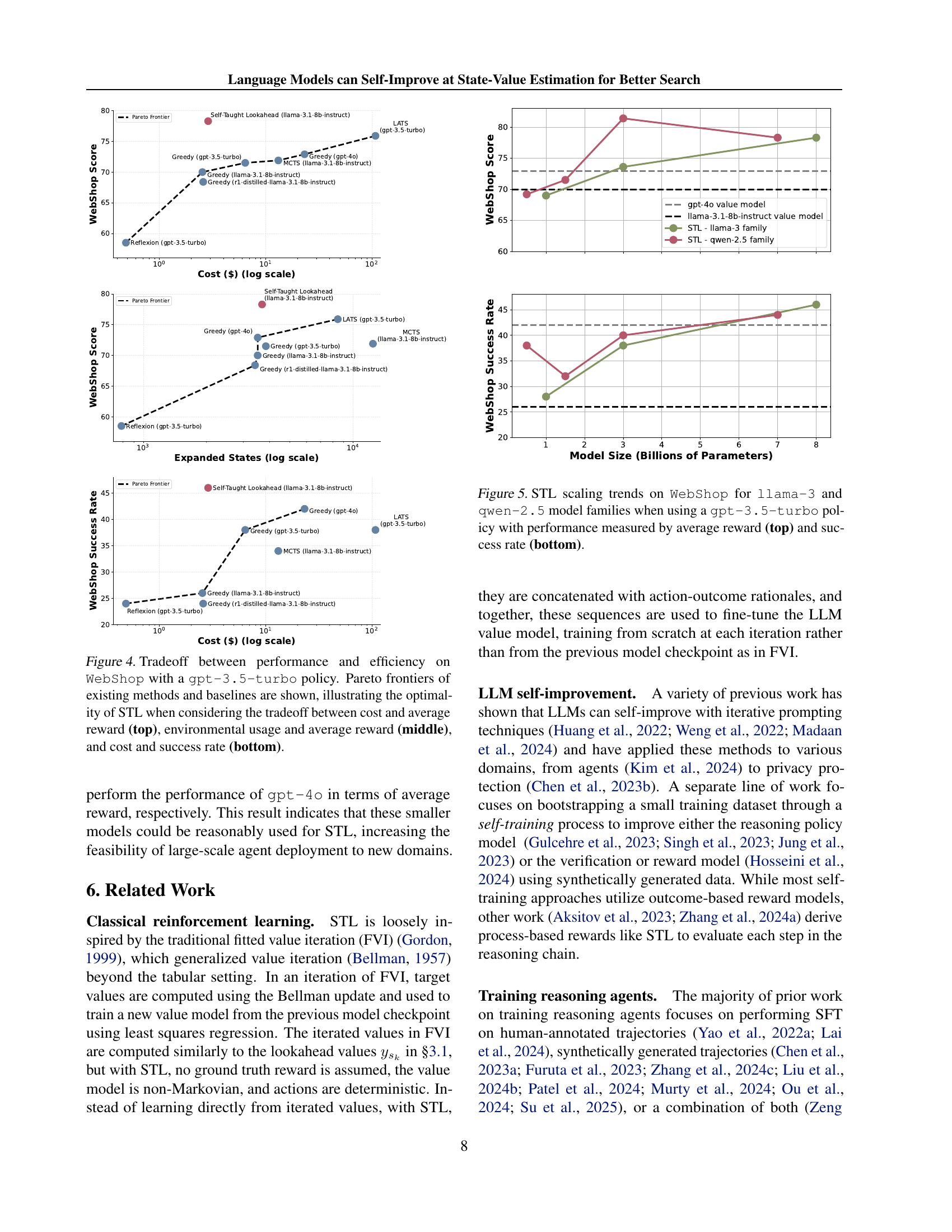
🔼 Figure 4 illustrates the tradeoffs between performance and efficiency for different search methods on the WebShop task, using a gpt-3.5-turbo policy. The Pareto frontiers in the three subplots show the optimal balance between cost and average reward (top), environmental impact (measured by expanded states) and average reward (middle), and cost and success rate (bottom). Self-taught lookahead (STL) consistently demonstrates Pareto optimality, outperforming other methods across all three tradeoff scenarios.
read the caption
Figure 4: Tradeoff between performance and efficiency on WebShop with a gpt-3.5-turbo policy. Pareto frontiers of existing methods and baselines are shown, illustrating the optimality of STL when considering the tradeoff between cost and average reward (top), environmental usage and average reward (middle), and cost and success rate (bottom).

🔼 This figure displays the scaling trends of Self-Taught Lookahead (STL) on the WebShop dataset using various llama-3 and qwen-2.5 model sizes. The experiments were conducted with a gpt-3.5-turbo policy model. The top panel shows the average reward achieved by each model size, while the bottom panel shows the success rate. The results illustrate how STL performs with different-sized models, indicating the potential for using smaller, more computationally efficient LLMs while maintaining reasonable performance.
read the caption
Figure 5: STL scaling trends on WebShop for llama-3 and qwen-2.5 model families when using a gpt-3.5-turbo policy with performance measured by average reward (top) and success rate (bottom).
More on tables
| Setting | Method | Policy | Value | Mini Test Set (50) | Full Test Set (500) | ||
| Score | SR | Score | SR | ||||
| Prompting + Search | Reflexion | gpt-3.5-turbo | — | 58.5 | 24.0 | 49.5 | 16.4 |
|---|---|---|---|---|---|---|---|
| \cdashline2-8 | LATS† | gpt-3.5-turbo | gpt-3.5-turbo | 75.9 | 38.0 | —— | —— |
| Fine-Tuning + RL | IL | BERT + BART | — | 57.5 | 34.0 | 59.9 | 29.1 |
| \cdashline2-8 | IL+RL | BERT + BART | — | 58.9 | 26.0 | 62.4 | 28.7 |
| \cdashline2-8 | AgentQ† | xLAM-v0.1-r-46.7b | gpt-4v | —— | —— | —— | 50.5 |
| Reward and Demo Free | Greedy Baseline | gpt-3.5-turbo | llama-3.1-8b-instruct | 70.0 | 26.0 | 67.7 | 26.4 |
| gpt-3.5-turbo | r1-distill-llama-8b | 68.4 | 24.0 | 66.3 | 24.6 | ||
| gpt-3.5-turbo | gpt-3.5-turbo | 71.5 | 38.0*** | 70.6*** | 35.6*** | ||
| gpt-3.5-turbo | gpt-4o | 72.9* | 42.0*** | 71.5*** | 40.6*** | ||
| gpt-4o | llama-3.1-8b-instruct | 71.6 | 28.0 | 67.2 | 25.8 | ||
| gpt-4o | r1-distill-llama-8b | 71.6 | 32.0* | 66.5 | 25.6 | ||
| gpt-4o | gpt-3.5-turbo | 77.4*** | 46.0*** | 72.4*** | 38.8*** | ||
| gpt-4o | gpt-4o | 74.4** | 46.0*** | 71.4*** | 40.8*** | ||
| \cdashline2-8 | MCTS Baseline | gpt-3.5-turbo | llama-3.1-8b-instruct | 71.9 | 34.0** | —— | —— |
| \cdashline2-8 | STL (Ours) | gpt-3.5-turbo | llama-3.1-8b-instruct | 78.3*** | 46.0*** | 72.8*** | 36.6*** |
| gpt-4o | llama-3.1-8b-instruct | 76.0*** | 40.0*** | 74.2*** | 40.6*** | ||
| Human Expert | —— | —— | —— | 76.1 | 54.0 | 82.1 | 59.6 |
🔼 Table 2 presents a detailed comparison of different methods’ performance on the WebShop task, a benchmark for evaluating interactive web-based reasoning capabilities. The table includes various approaches, some using human demonstrations or ground truth rewards, and others that are reward-free. Performance is measured by both score (average reward) and success rate. Methods using Monte Carlo Tree Search (MCTS) are compared to others that employ simpler greedy search, and the self-taught lookahead (STL) method is highlighted, showcasing its improvement over existing techniques. Statistical significance is assessed using a paired bootstrap test for Reward and Demo Free methods against the baseline models. The table also indicates whether value functions were fine-tuned and notes the limitations of comparing MCTS methods due to computational constraints.
read the caption
Table 2: Score and success rate (SR) on WebShop. Results marked with ††{{\dagger}}† are taken from previous work (Zhou et al., 2024; Putta et al., 2024). Results correspond to methods specified in Table 1. Value functions marked with ‡‡{\ddagger}‡ are fine-tuned. Due to the computational complexity of MCTS methods, we report their results on only the mini-test set used by Zhou et al. (2024) when results on the full test set are not available. We observe a 40% improvement in success rate when using the STL value function compared to the llama-3.1-8b-instruct base value model in the greedy setting. We compute statistical significance of Reward and Demo Free methods compared to the underlined results (p∗<0.05superscript𝑝0.05{}^{*}p<0.05start_FLOATSUPERSCRIPT ∗ end_FLOATSUPERSCRIPT italic_p < 0.05, p∗∗<0.01superscript𝑝absent0.01{}^{**}p<0.01start_FLOATSUPERSCRIPT ∗ ∗ end_FLOATSUPERSCRIPT italic_p < 0.01, p∗∗∗<0.001){}^{***}p<0.001)start_FLOATSUPERSCRIPT ∗ ∗ ∗ end_FLOATSUPERSCRIPT italic_p < 0.001 ) using the paired bootstrap test (Berg-Kirkpatrick et al., 2012). The best results are also bolded.
| Fine-tuning Data Setup | Score | SR(%) |
| llama-3.1-8b-instruct | 70.4 | 30.0 |
| + lv | 70.9 | 34.0 |
| + lv + tr | 74.4 | 32.0 |
| + lv + tr + r (stl) | 76.4 | 42.0 |
🔼 This ablation study investigates the impact of different combinations of information from the lookahead process on the performance of the WebShop task. Specifically, it examines the effects of including lookahead values (LV), textual representations of the next best action and successor state (TR), and the value rationale for the successor state (R), in the fine-tuning process. The table compares the performance (score and success rate) resulting from various combinations of these information sources, with the performance of the base model (before fine-tuning) serving as a baseline. The results indicate how much each element of the lookahead contributes to the overall improvement achieved by self-taught lookahead.
read the caption
Table 3: Ablation study on WebShop of the impact of fine-tuning with different combinations of information from lookahead namely lookahead values (lv), textual representation of the next best action and successor state (tr), and the value rationale for the successor state (r). The underlined results are from the base model before any fine-tuning.
| warmup-steps | learning-rate | weight-decay | per-device-batch size | lora-r | lora-alpha | |
| STL |
🔼 This table lists the hyperparameters used during the training phase of the Self-Taught Lookahead (STL) algorithm. It shows values for parameters such as warmup steps, learning rate, weight decay, per-device batch size, lora-r (the rank for LoRA adaptation), and lora-alpha (the scaling factor for LoRA adaptation). These hyperparameters were tuned for optimal performance of the STL method in training value models.
read the caption
Table 4: Hyperparameters during STL training.
Full paper#