TL;DR#
Large Language Models(LLMs) raise concerns about Wikipedia’s future. While Wikipedia hasn’t remained unaffected, the impact of LLMs requires comprehensive investigation. Current research has started examining the influence of LLMs on Wikipedia, this paper analyzes the direct impact of LLMs on Wikipedia, focusing on changes in page views, word frequency, and linguistic style, exploring indirect effects on NLP, particularly in machine translation and RAG.
This paper quantifies the impact of LLMs on Wikipedia pages across categories and analyzes this impact from the perspective of word usage, providing estimates. It examines how LLM-generated content affects machine translation and the efficiency of RAG. Results show a slight decline in page views, and some Wikipedia articles have been influenced by LLMs, with an overall limited impact. Machine translation scores may be inflated. RAG may be less effective with LLM content.
Key Takeaways#
Why does it matter?#
This study is crucial for understanding and mitigating the impact of LLMs on information ecosystems. It underscores the need for careful monitoring of content quality and reliability in the face of AI-driven content generation, offering insights for future research and policy.
Visual Insights#

🔼 This figure illustrates the research design. The researchers directly analyzed the impact of LLMs on Wikipedia by examining changes in page views, word frequency, and linguistic style. They also explored the indirect impact on the broader NLP community by assessing how LLMs might affect machine translation benchmarks and RAG (Retrieval-Augmented Generation) systems, which rely heavily on Wikipedia data. The core question is whether LLMs have already altered Wikipedia and what future risks and consequences might arise.
read the caption
Figure 1: Our work analyze the direct impact of LLMs on Wikipedia, and exploring the indirect impact of LLMs generated content on Wikipedia: Have LLMs already impacted Wikipedia, and if so, how might they influence the broader NLP community?
| Criteria | LLM | Data | Figures |
| Auxiliary verb % | 5(a), 5(d) | ||
| "To Be" verb % | 14 | ||
| CTTR | 15 | ||
| Long word % | 16 | ||
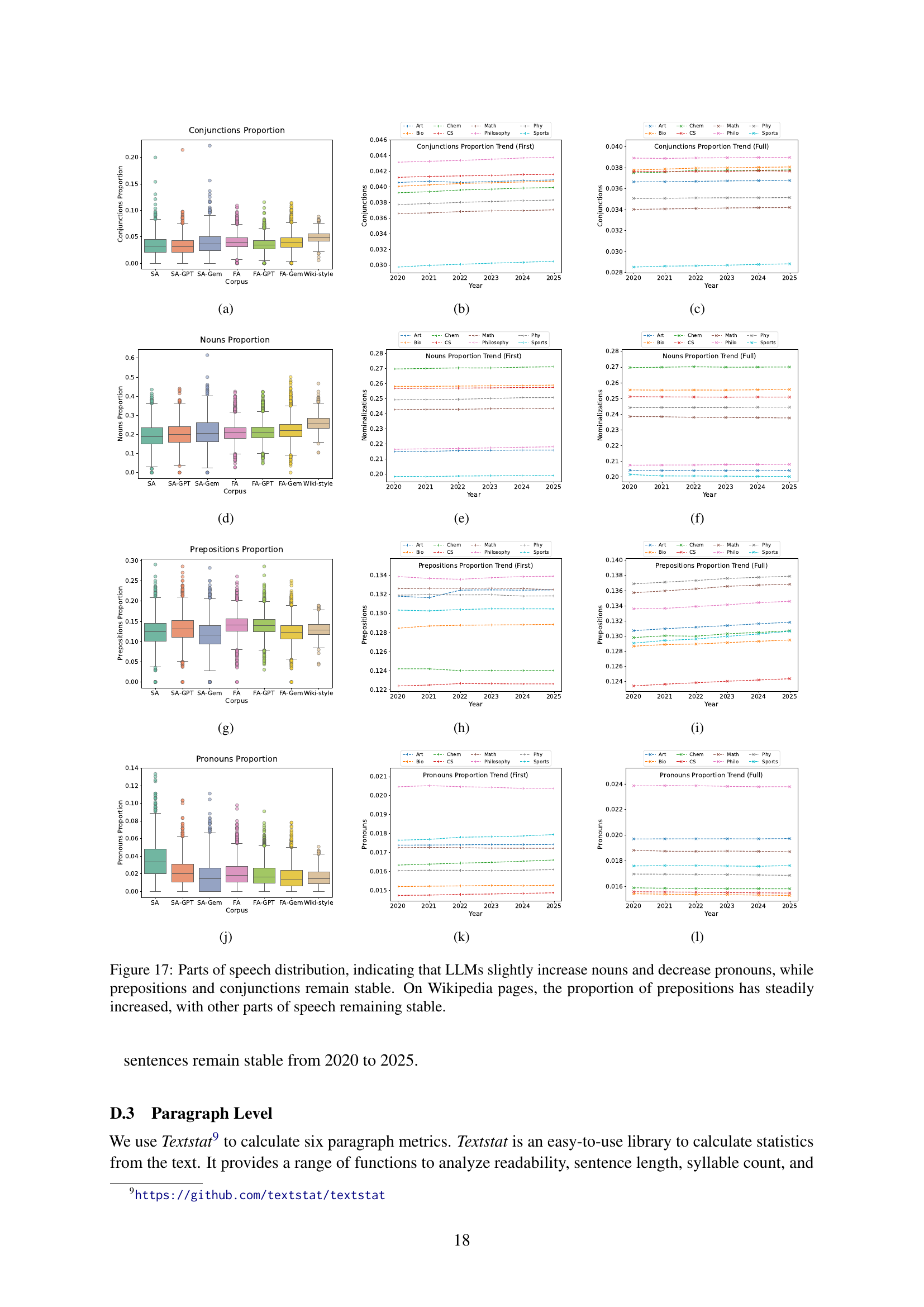
| Conjunction % | 17(a), 17(b), 17(c) | ||
| Noun % | 17(d), 17(e), 17(f) | ||
| Preposition % | 17(g), 17(h), 17(i) | ||
| Pronouns % | 17(j), 17(k), 17(l) | ||
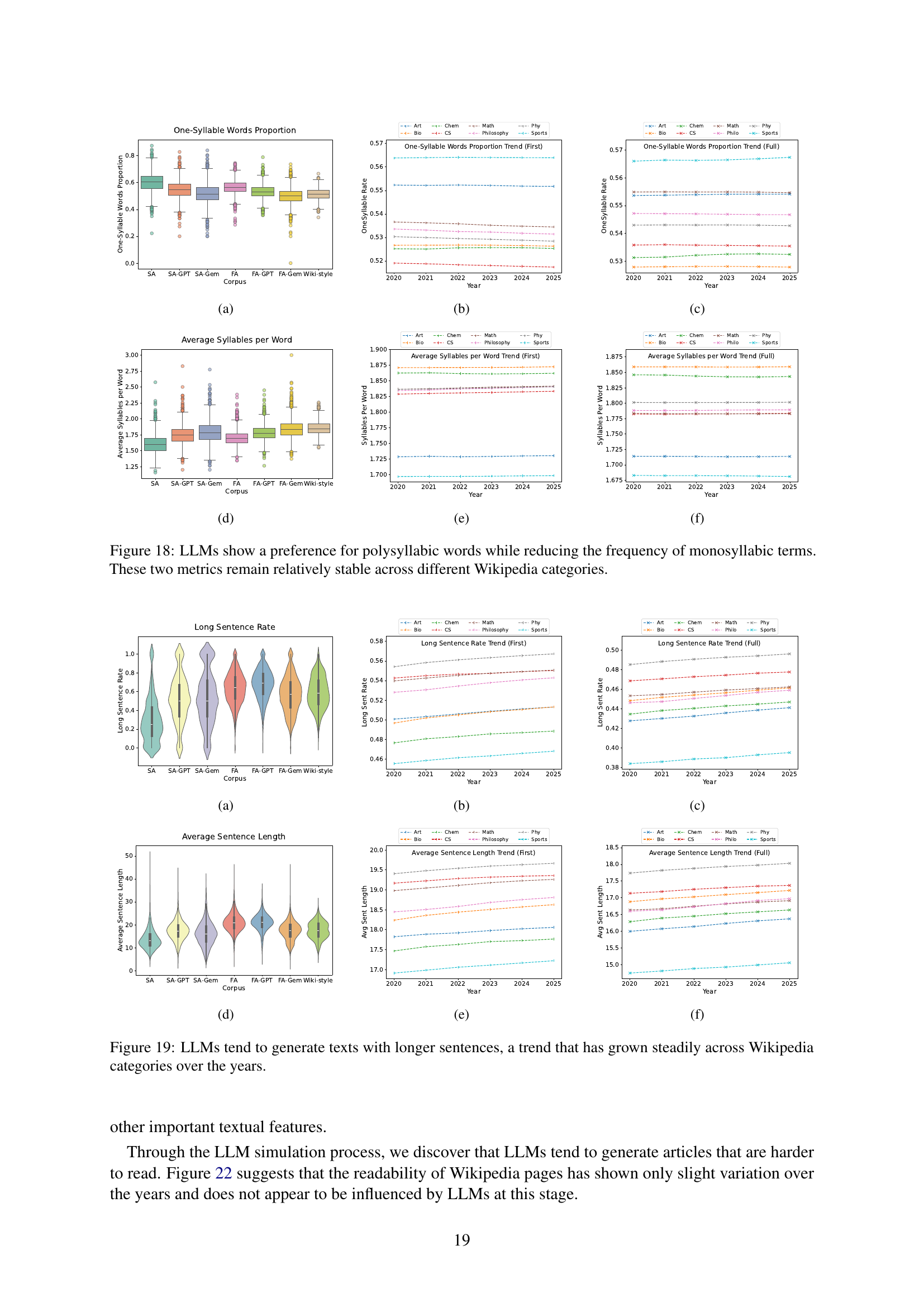
| One-syllable word % | 18(a), 18(b), 18(c) | ||
| Average syllables per word | 18(d), 18(e), 18(f) | ||
| Passive voice % | 5(b), 5(e) | ||
| Long sentence % | 19(a), 19(b), 19(c) | ||
| Average sentence length | 19(d), 19(e), 19(f) | ||
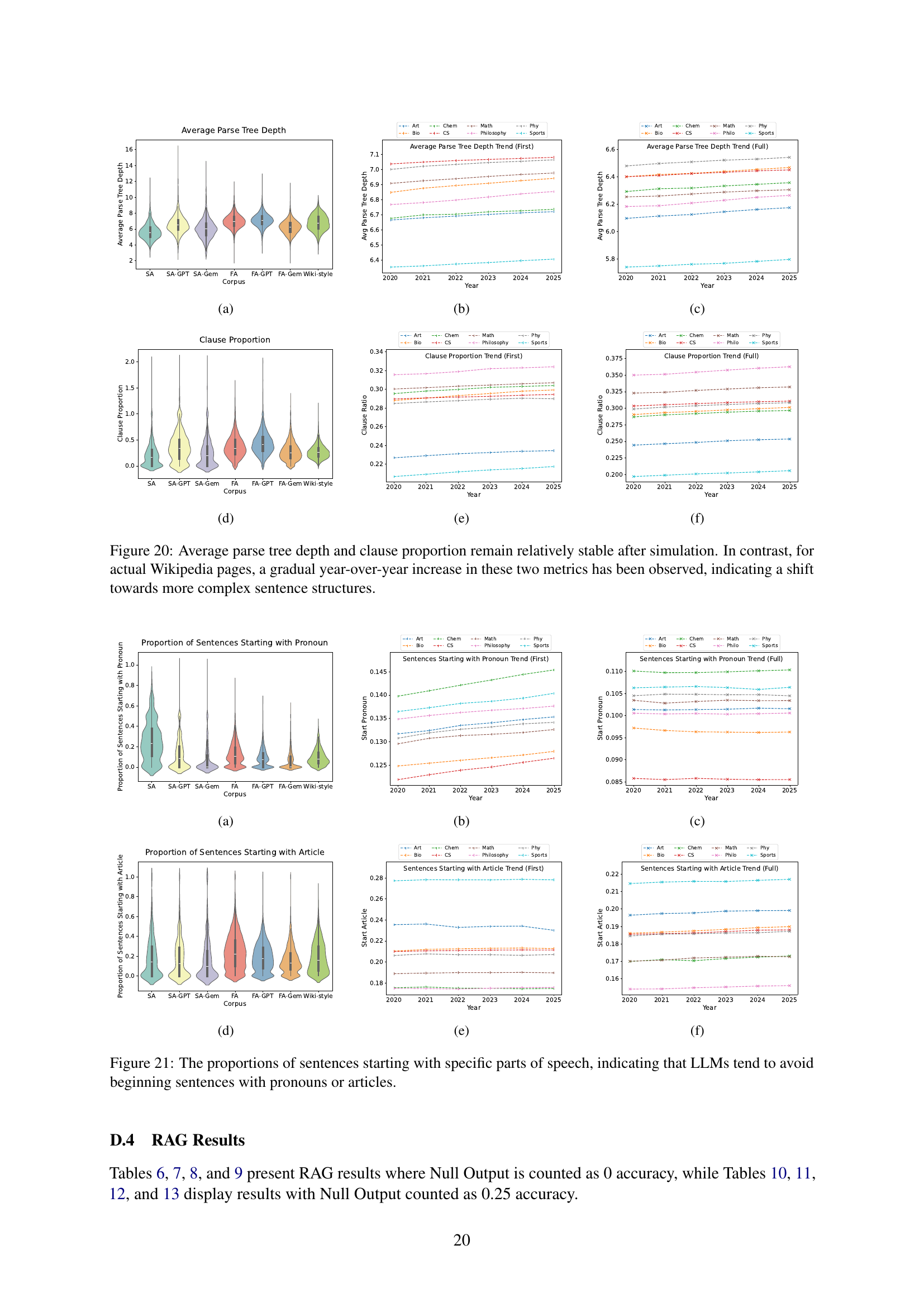
| Average parse tree depth | 20(a), 20(b), 20(c) | ||
| Clause % | 20(d), 20(e), 20(f) | ||
| Pronoun-initial sentence % | 21(a), 21(b), 21(c) | ||
| Article-initial sentence % | 21(d), 21(e), 21(f) | ||
| Dale-Chall readability | 5(c), 22(a) | ||
| Automated readability index | 5(c), 22(b) | ||
| Flesch-Kincaid grade level | 5(c), 5(f) | ||
| Flesch reading ease | 5(c), 22(c) | ||
| Coleman-Liau index | 5(c), 22(d) | ||
| Gunning Fox index | 5(c), 22(e) |
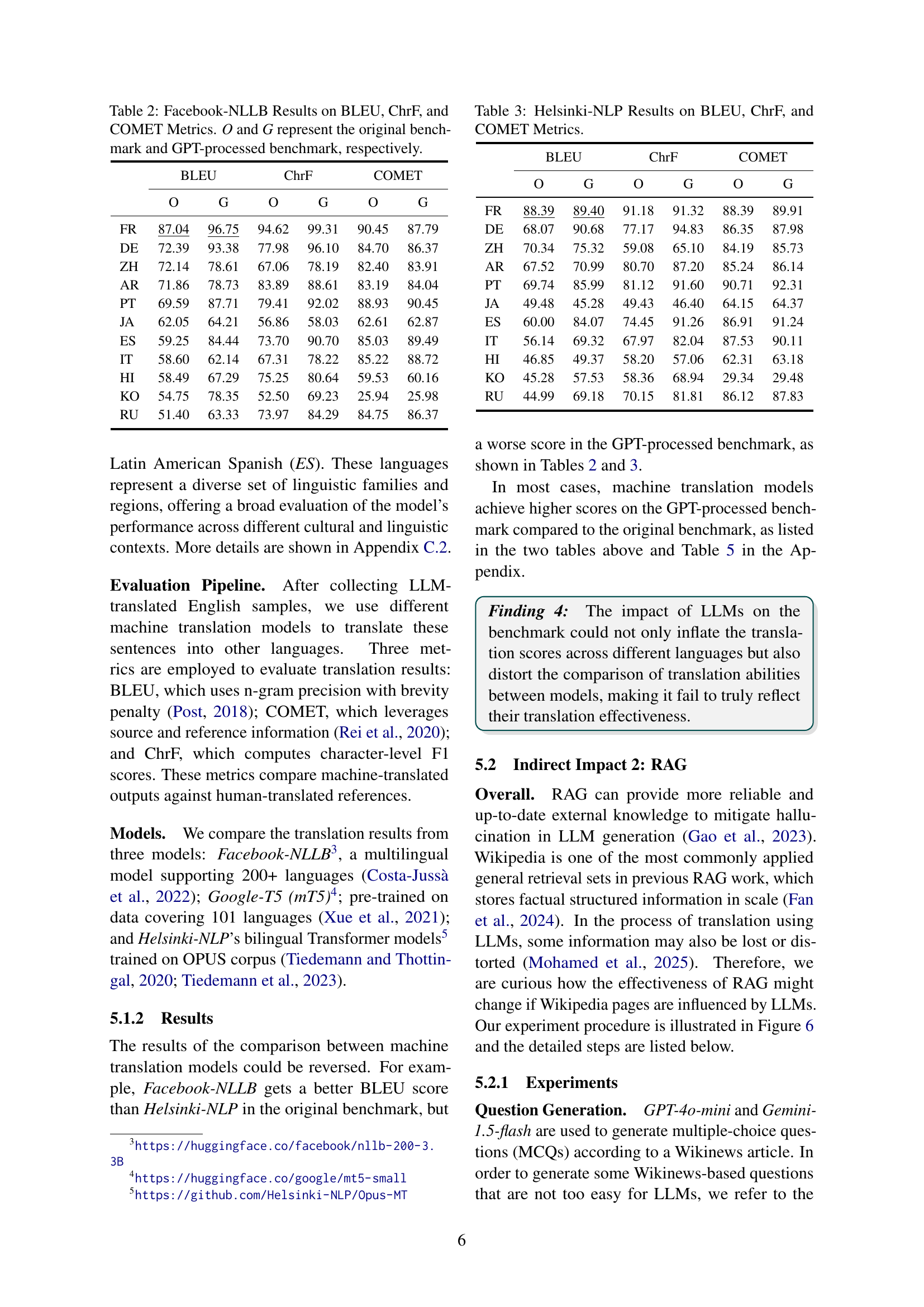
🔼 This table summarizes the observed trends in linguistic style within Wikipedia articles, both before and after processing by Large Language Models (LLMs). The first column lists the linguistic features analyzed (e.g., auxiliary verb usage, sentence length). The second column shows the impact of LLM processing on these features (e.g., increase, decrease, no change). The third column indicates the trends in these features over time within Wikipedia articles themselves, independent of LLM influence. This allows for a comparison between how LLMs are altering Wikipedia’s linguistic characteristics and the natural evolution of the Wikipedia writing style.
read the caption
Table 1: Summary of linguistic style trends. The second column indicates the effects of LLM processing. The third column shows Wikipedia trends over time.
In-depth insights#
LLM’s Wiki Impact#
Analyzing the impact of LLMs on Wikipedia is multifaceted. Quantifying the direct influence is challenging, as discerning LLM-generated edits from human contributions requires sophisticated detection methods. Metrics like page view fluctuations, word frequency shifts (increased use of LLM-favored terms), and linguistic style alterations (sentence complexity, part-of-speech distributions) offer clues, but causality is difficult to establish definitively. Simulations, where LLMs revise existing articles, provide a controlled environment to isolate LLM-induced changes, revealing potential biases (e.g., reduced auxiliary verbs, increased long words). Furthermore, the indirect impact on NLP tasks leveraging Wikipedia data is crucial. If LLMs subtly alter Wikipedia’s content, benchmarks relying on it (machine translation, RAG) may become skewed, leading to inflated scores or altered comparative model performance. The ‘pollution’ of Wikipedia with LLM-generated content could also degrade the effectiveness of RAG systems. Careful monitoring and development of robust detection mechanisms are essential to mitigate potential risks and preserve the integrity of Wikipedia as a valuable knowledge resource.
MT inflated?#
If MT benchmarks use Wikipedia-derived sentences, and LLMs influence Wikipedia content, MT scores might be inflated. This is because LLMs could subtly shape Wikipedia text towards patterns that favor certain MT architectures. If MT models are trained/evaluated on these biased sentences, their apparent performance boosts are misleading. Comparisons between models then become unreliable. Therefore, careful design of MT benchmarks is crucial to avoid this contamination and accurately reflect true translation capabilities. Constant data curation and scrutiny are must to measure real-world MT progress rather than artificial improvements.
Word use shifts#
Analyzing word use shifts provides insights into language evolution and cultural trends. By tracking changes in word frequency and context, we can understand how language adapts to new concepts and technologies. This analysis also reveals shifts in public discourse and values. Computational linguistics enables automated tracking of these shifts over large text corpora. Examining changes in sentiment analysis and topic modeling can also expose subtle yet significant shifts in how we communicate and understand the world. The research can also highlight biases and stereotypes embedded in language, as well as how they evolve or persist over time.
RAG’s content risk#
RAG systems heavily rely on the quality of the knowledge base, so LLM-generated content “polluting” the base becomes a major risk. If the RAG pulls information from a source saturated with AI-written text, the results may be skewed. The system might reinforce existing biases or generate hallucinations because AI-generated content often lacks the nuance and factual precision of human-written sources. The RAG effectiveness could be compromised, potentially leading to less reliable results, especially with complex inquiries requiring in-depth reasoning. The study suggests if trusted sources are affected by AI content, there’s a higher risk of degradation in information quality.
Style evolves#
While the provided text doesn’t explicitly contain a heading titled ‘Style Evolving,’ the research intrinsically delves into this concept by analyzing the impact of LLMs on Wikipedia’s linguistic characteristics. The study examines how word frequency, sentence structure, and overall readability are influenced by LLMs. LLMs tend to generate articles that are harder to read. This indicates that LLMs are inducing changes in the writing style. By observing these trends over time and comparing them with LLM-generated content, the research infers that Wikipedia’s style is indeed evolving, subtly shifting towards the linguistic preferences of LLMs. While the changes are not drastic, they signal a potential long-term shift in the character of a valuable and widely used knowledge base.
More visual insights#
More on figures

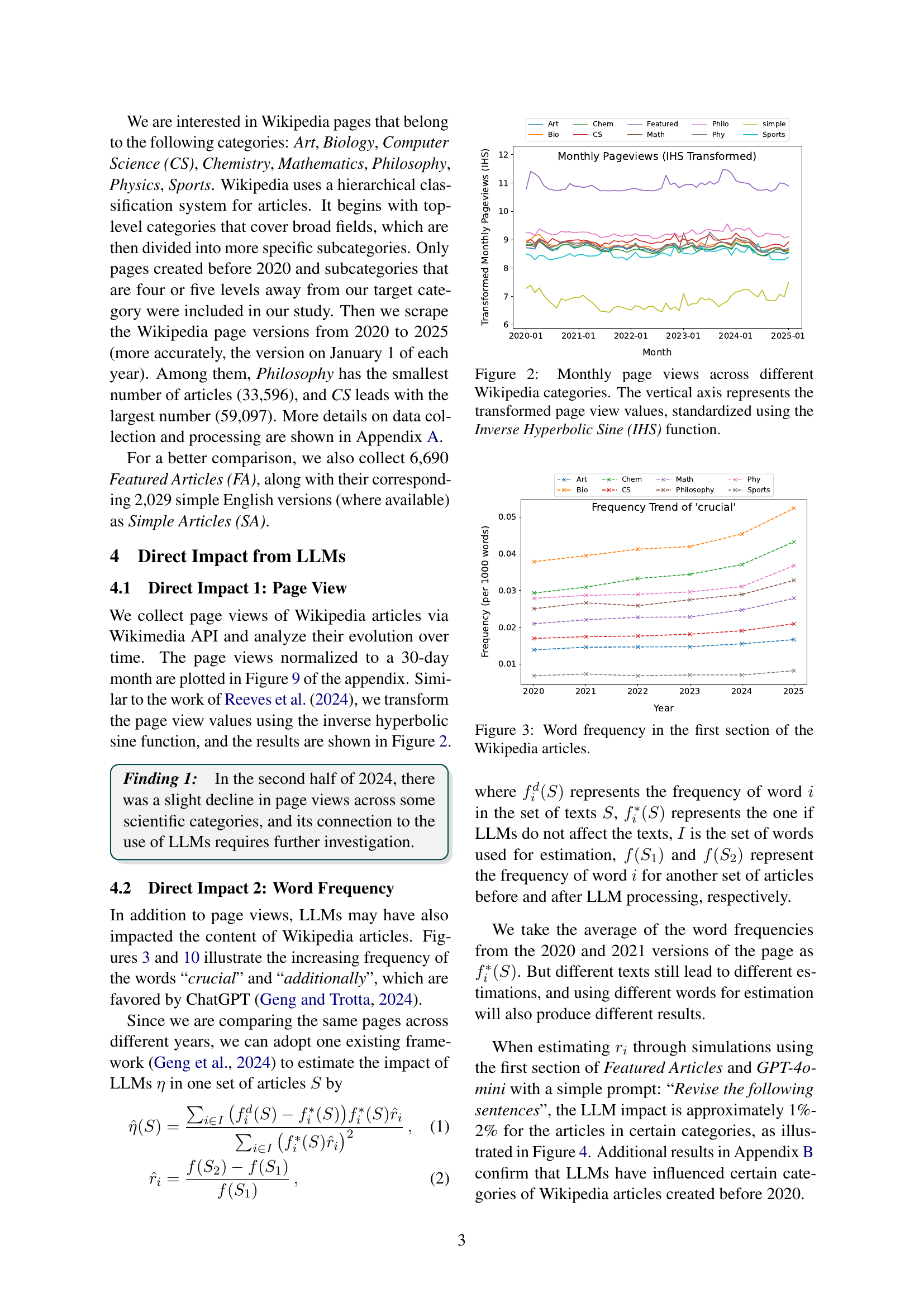
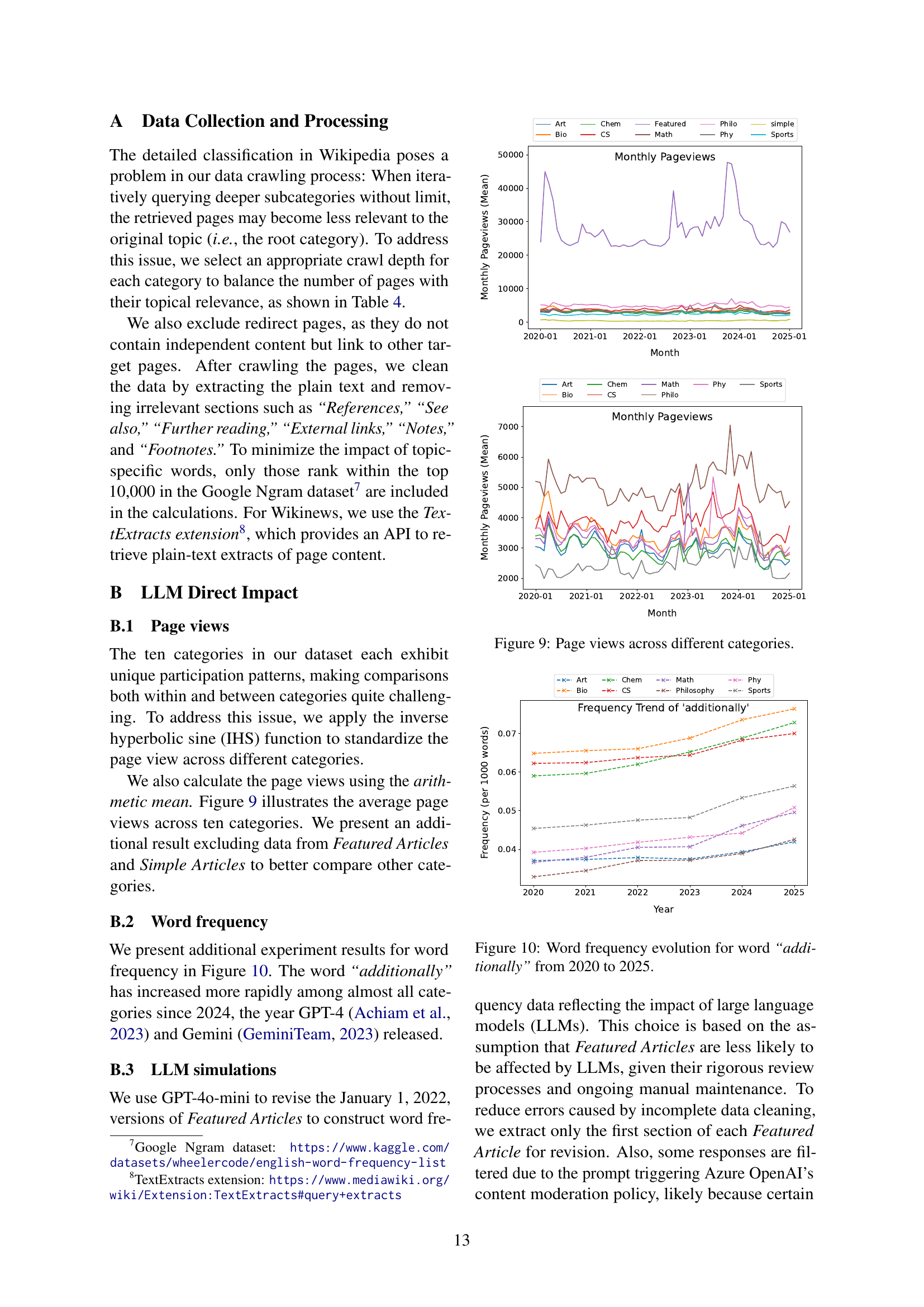
🔼 This figure displays the monthly page view counts for various Wikipedia categories from the beginning of 2020 to the beginning of 2025. To facilitate comparison across categories with differing scales of page view numbers, the raw page view data has been transformed using the Inverse Hyperbolic Sine (IHS) function, which standardizes the values. Each line represents a different Wikipedia category, allowing for a visual comparison of trends over time and across categories.
read the caption
Figure 2: Monthly page views across different Wikipedia categories. The vertical axis represents the transformed page view values, standardized using the Inverse Hyperbolic Sine (IHS) function.

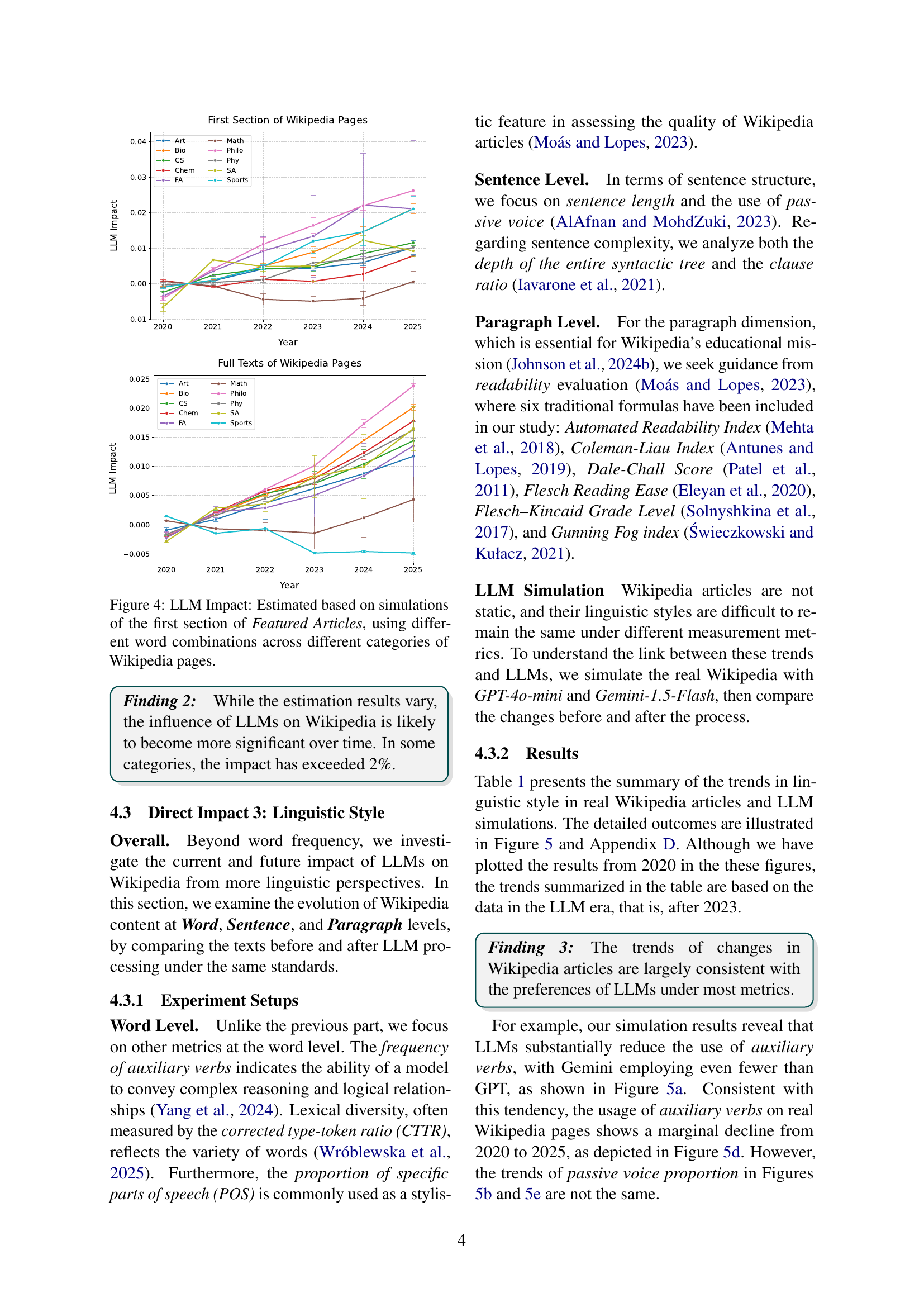
🔼 The figure shows a line graph illustrating the trend of word frequency in the introductory sections of Wikipedia articles over time. Each line represents a specific category (Art, Biology, Chemistry, Computer Science, etc.) and plots the frequency of the word ‘crucial’ within those articles. The x-axis represents the year (2020-2025) and the y-axis shows the frequency (per 1000 words). The graph helps visualize how the frequency of this specific word (and by implication, other LLM-associated words) has changed over time within each category of articles, offering insights into the possible influence of Large Language Models (LLMs).
read the caption
Figure 3: Word frequency in the first section of the Wikipedia articles.

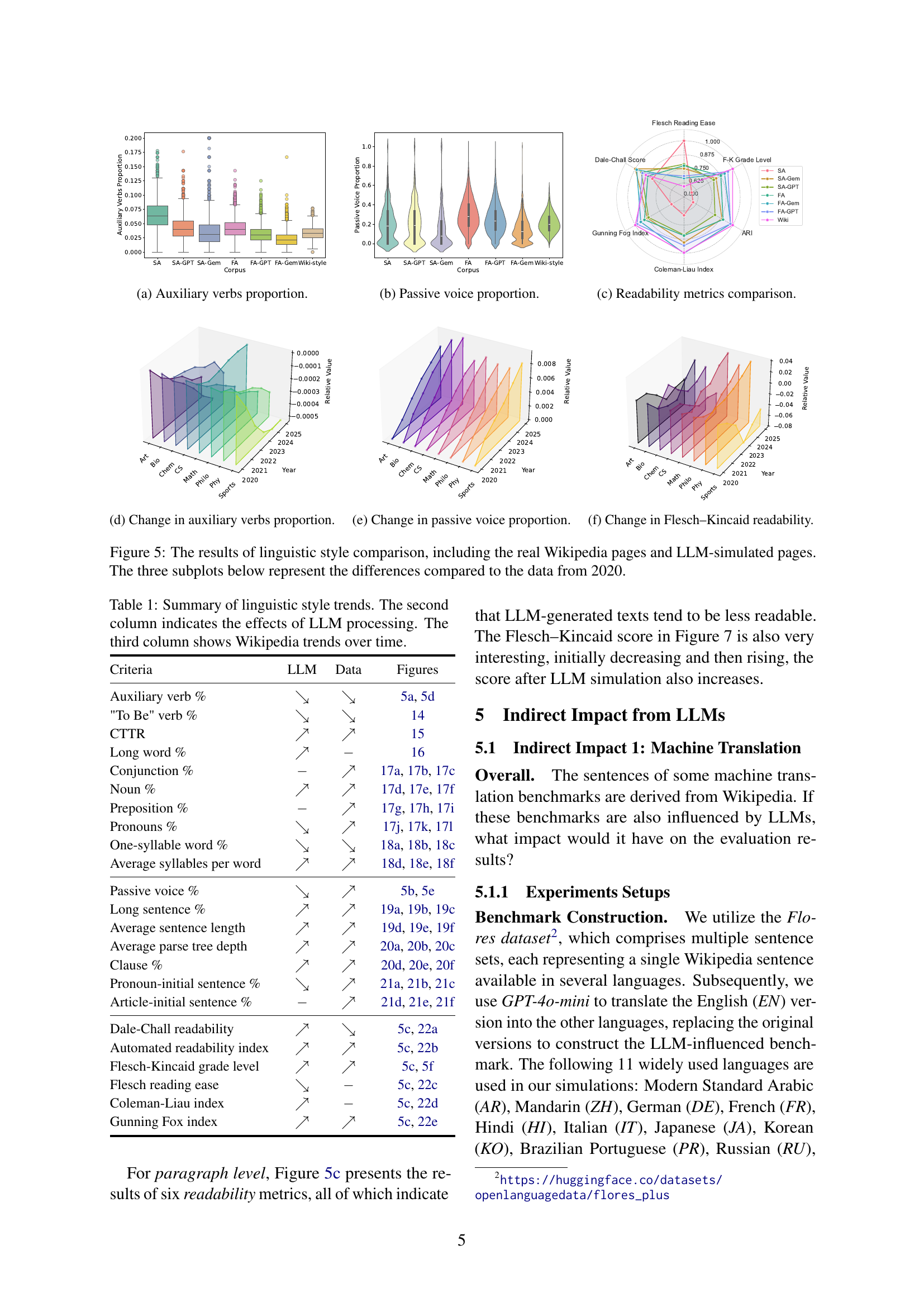
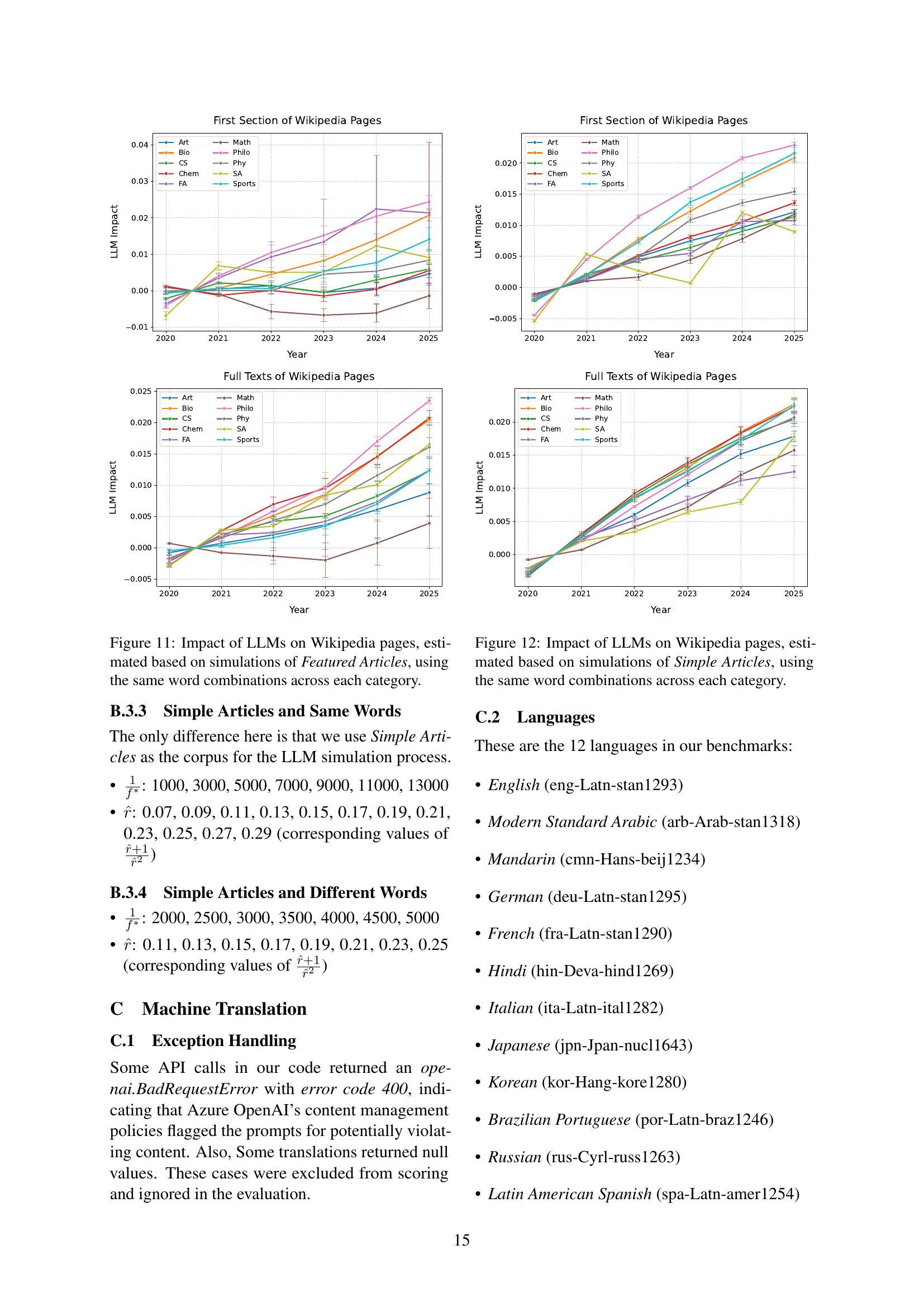
🔼 This figure displays the results of simulations conducted to quantify the impact of Large Language Models (LLMs) on Wikipedia articles. The simulations used different sets of words across various Wikipedia categories and focused on the first section of each article. The Y-axis represents the estimated LLM impact, reflecting the degree to which LLMs influenced word frequencies within those sections. The X-axis indicates the year, showing the impact of LLMs over time for different article categories. Each line on the graph corresponds to a different Wikipedia subject category. The graph helps to visualize how the impact of LLMs on Wikipedia varied between categories and across the period measured.
read the caption
Figure 4: LLM Impact: Estimated based on simulations of the first section of Featured Articles, using different word combinations across different categories of Wikipedia pages.

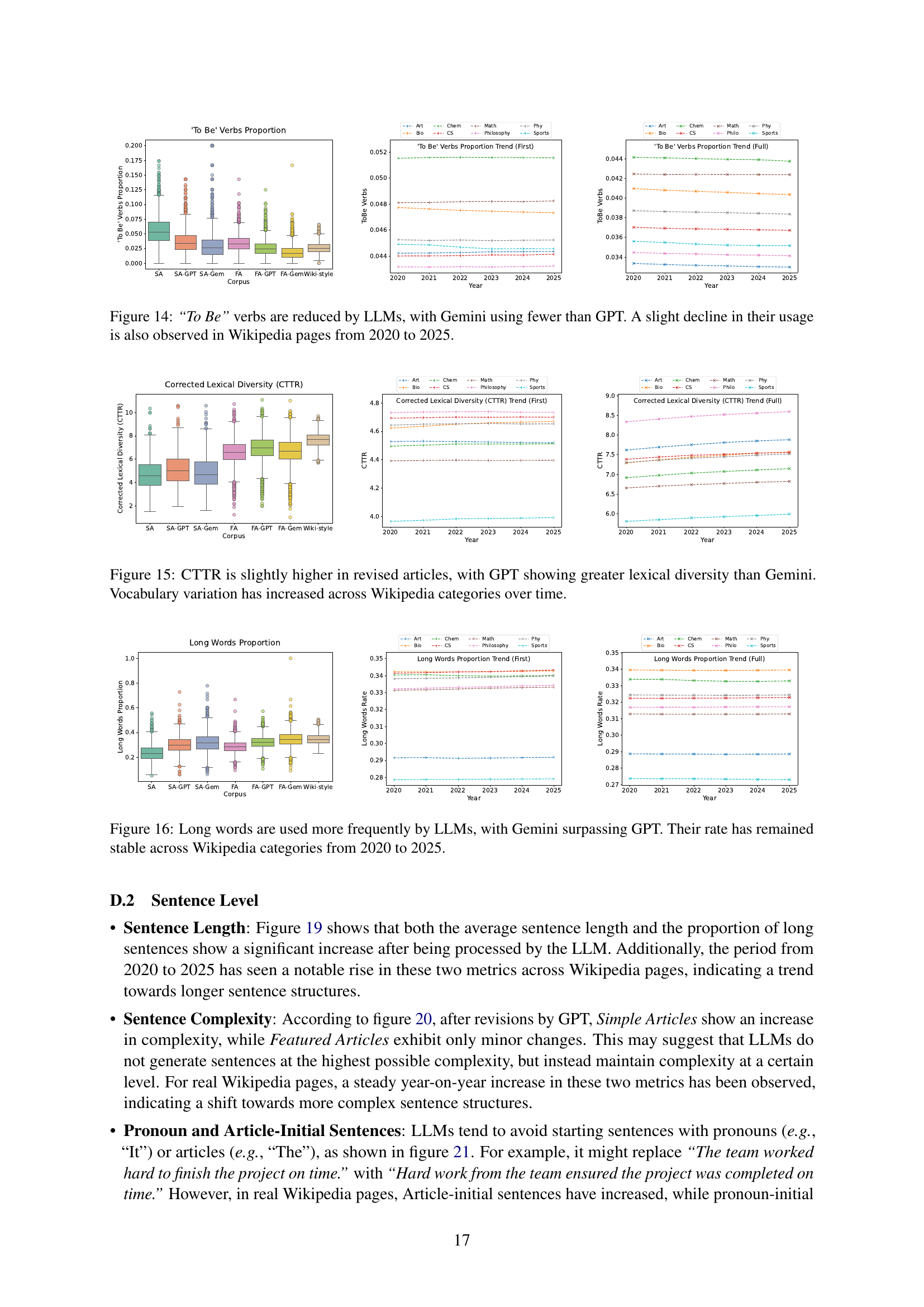
🔼 This figure presents a comparison of the proportion of auxiliary verbs across different categories of Wikipedia articles and their counterparts after being processed by LLMs (Large Language Models). It compares the baseline proportion of auxiliary verbs (before LLM processing) with the proportions after processing by two different LLMs, GPT and Gemini. The data is visualized using box plots for each Wikipedia category. The purpose is to show how the use of auxiliary verbs is affected by LLMs.
read the caption
(a) Auxiliary verbs proportion.

🔼 This figure presents a comparison of the proportion of passive voice usage across various categories of Wikipedia articles and their LLM-simulated counterparts. It helps to visualize the effect of LLMs on the linguistic style of Wikipedia content by showing how the passive voice is used differently before and after LLM processing. The comparison includes both Featured Articles (FA), Simple Articles (SA), and the results of LLM simulations (FA-GPT, FA-Gem, SA-GPT, SA-Gem). This allows for an analysis of how LLMs might alter the linguistic style of the articles.
read the caption
(b) Passive voice proportion.

🔼 This figure compares the readability metrics (Automated Readability Index, Coleman-Liau Index, Dale-Chall Score, Flesch Reading Ease, Flesch-Kincaid Grade Level, and Gunning Fog Index) of Wikipedia articles before and after processing by LLMs (GPT and Gemini). It shows the relative readability differences between the original Wikipedia text and the LLM-processed versions for Featured Articles (FA) and Simple Articles (SA).
read the caption
(c) Readability metrics comparison.

🔼 This figure shows the change in the proportion of auxiliary verbs used in Wikipedia articles over time, comparing the proportion before and after the impact of LLMs. It specifically visualizes how the frequency of auxiliary verbs has changed across different categories of Wikipedia articles from 2020 to 2025. The graph helps to illustrate one aspect of the linguistic style changes potentially caused by Large Language Models (LLMs) on Wikipedia.
read the caption
(d) Change in auxiliary verbs proportion.
More on tables
| BLEU | ChrF | COMET | ||||
| O | G | O | G | O | G | |
| FR | 87.04 | 96.75 | 94.62 | 99.31 | 90.45 | 87.79 |
| DE | 72.39 | 93.38 | 77.98 | 96.10 | 84.70 | 86.37 |
| ZH | 72.14 | 78.61 | 67.06 | 78.19 | 82.40 | 83.91 |
| AR | 71.86 | 78.73 | 83.89 | 88.61 | 83.19 | 84.04 |
| PT | 69.59 | 87.71 | 79.41 | 92.02 | 88.93 | 90.45 |
| JA | 62.05 | 64.21 | 56.86 | 58.03 | 62.61 | 62.87 |
| ES | 59.25 | 84.44 | 73.70 | 90.70 | 85.03 | 89.49 |
| IT | 58.60 | 62.14 | 67.31 | 78.22 | 85.22 | 88.72 |
| HI | 58.49 | 67.29 | 75.25 | 80.64 | 59.53 | 60.16 |
| KO | 54.75 | 78.35 | 52.50 | 69.23 | 25.94 | 25.98 |
| RU | 51.40 | 63.33 | 73.97 | 84.29 | 84.75 | 86.37 |
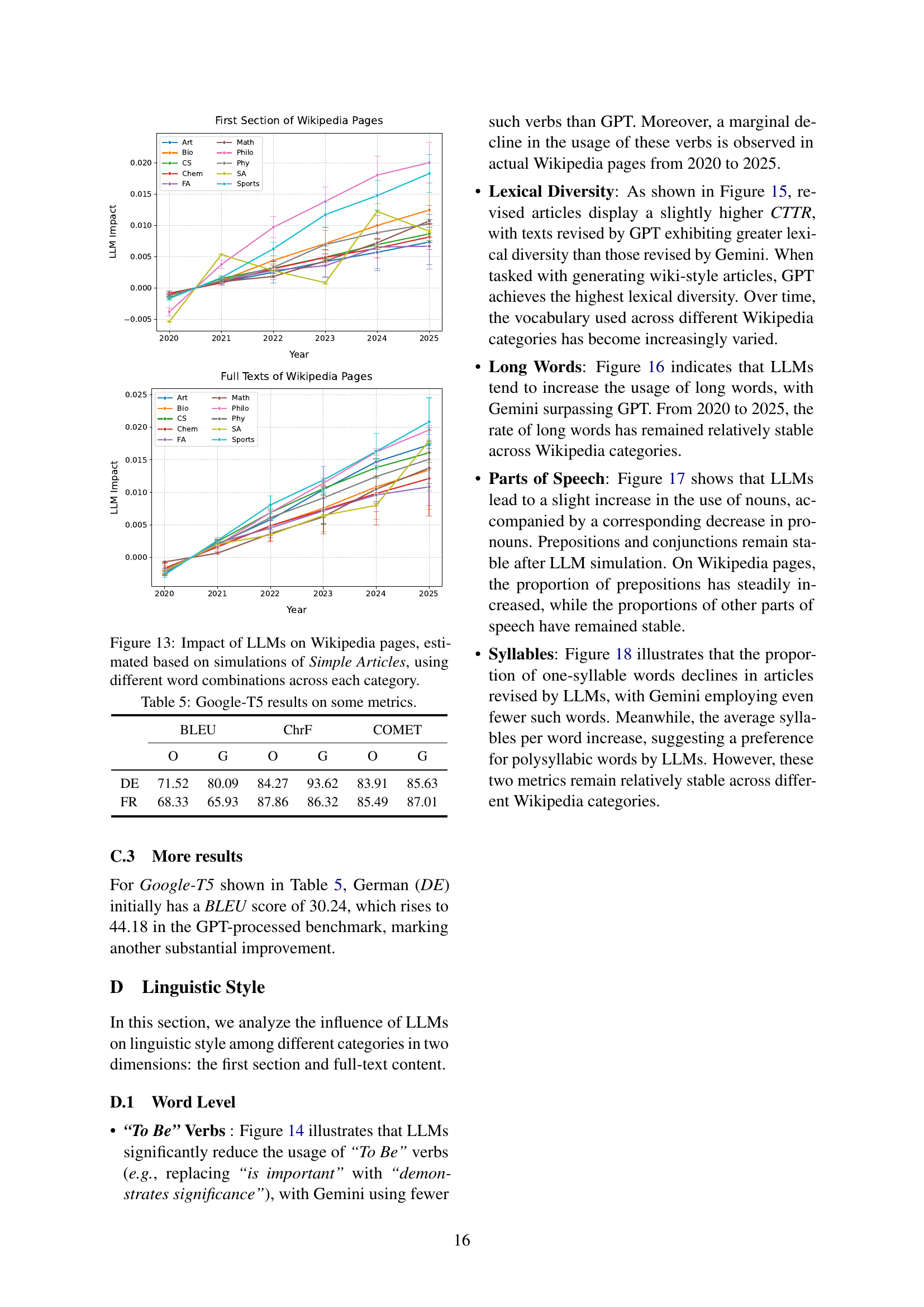
🔼 This table presents the performance comparison of the Facebook-NLLB machine translation model on three evaluation metrics (BLEU, ChrF, and COMET) using two different benchmarks: the original benchmark (O) and a GPT-processed benchmark (G). The GPT-processed benchmark involves translating English sentences from the original benchmark into multiple languages using GPT-40-mini and then using those translated sentences to test the machine translation models. This comparison aims to reveal how the modifications introduced by LLMs, such as changes in vocabulary and linguistic style, affect the performance of machine translation models.
read the caption
Table 2: Facebook-NLLB Results on BLEU, ChrF, and COMET Metrics. O and G represent the original benchmark and GPT-processed benchmark, respectively.
| BLEU | ChrF | COMET | ||||
| O | G | O | G | O | G | |
| FR | 88.39 | 89.40 | 91.18 | 91.32 | 88.39 | 89.91 |
| DE | 68.07 | 90.68 | 77.17 | 94.83 | 86.35 | 87.98 |
| ZH | 70.34 | 75.32 | 59.08 | 65.10 | 84.19 | 85.73 |
| AR | 67.52 | 70.99 | 80.70 | 87.20 | 85.24 | 86.14 |
| PT | 69.74 | 85.99 | 81.12 | 91.60 | 90.71 | 92.31 |
| JA | 49.48 | 45.28 | 49.43 | 46.40 | 64.15 | 64.37 |
| ES | 60.00 | 84.07 | 74.45 | 91.26 | 86.91 | 91.24 |
| IT | 56.14 | 69.32 | 67.97 | 82.04 | 87.53 | 90.11 |
| HI | 46.85 | 49.37 | 58.20 | 57.06 | 62.31 | 63.18 |
| KO | 45.28 | 57.53 | 58.36 | 68.94 | 29.34 | 29.48 |
| RU | 44.99 | 69.18 | 70.15 | 81.81 | 86.12 | 87.83 |
🔼 This table presents the evaluation results of three machine translation metrics (BLEU, ChrF, and COMET) on the Helsinki-NLP machine translation benchmark. The results are shown for both the original benchmark and a modified benchmark where the English sentences have been translated by LLMs (GPT-40-mini) into other languages before being evaluated by machine translation models. This comparison illustrates the impact of LLM-processed data on machine translation evaluation metrics.
read the caption
Table 3: Helsinki-NLP Results on BLEU, ChrF, and COMET Metrics.
| Category | Art | Bio | Chem | CS | Math | Philo | Phy | Sports |
| Crawl Depth | 4 | 4 | 5 | 5 | 5 | 5 | 5 | 4 |
| Number of Pages | 57,028 | 44,617 | 53,282 | 59,097 | 47,004 | 33,596 | 40,986 | 53,900 |
🔼 This table presents the number of Wikipedia articles used in the study for each of the eight categories analyzed: Art, Biology, Computer Science, Chemistry, Mathematics, Philosophy, Physics, and Sports. It also shows the depth of the hierarchical Wikipedia category structure that was crawled to obtain those articles.
read the caption
Table 4: Number of Wikipedia articles crawled per category.
| BLEU | ChrF | COMET | ||||
| O | G | O | G | O | G | |
| DE | 71.52 | 80.09 | 84.27 | 93.62 | 83.91 | 85.63 |
| FR | 68.33 | 65.93 | 87.86 | 86.32 | 85.49 | 87.01 |
🔼 This table presents the results of Google’s T5 multilingual machine translation model performance on a benchmark. The benchmark evaluates translations across several languages, comparing the model’s outputs to human references using three metrics: BLEU, ChrF, and COMET. The ‘O’ column represents the original benchmark, while the ‘G’ column shows results after the benchmark was processed using GPT, illustrating the impact of LLMs on the benchmark and evaluation results.
read the caption
Table 5: Google-T5 results on some metrics.
| Year | Direct Ask | RAG | RAG (GPT) | RAG (Gem) | Full (Original) | Full (GPT) | Full (Gem) |
| 2020 | 75.86% | 85.34% | 85.63% | 79.60% | 95.98% | 95.40% | 87.36% |
| 2021 | 71.74% | 86.31% | 88.96% | 79.69% | 96.03% | 96.03% | 88.08% |
| 2022 | 80.00% | 89.49% | 87.18% | 84.10% | 95.64% | 95.64% | 88.97% |
| 2023 | 77.46% | 87.09% | 87.09% | 83.33% | 96.01% | 94.84% | 87.09% |
| 2024 | 66.67% | 83.33% | 84.58% | 82.08% | 95.83% | 95.83% | 88.75% |
🔼 This table presents the performance of the GPT-40-mini language model on a question answering task using the Retrieval Augmented Generation (RAG) technique. The questions were generated by another GPT model. The table shows the accuracy of GPT-40-mini across different question answering methods (Direct Ask, RAG using original content, RAG using GPT-modified content, RAG using Gemini-modified content, and Full Context using original, GPT-modified, and Gemini-modified content), and across different years (2020-2024). This allows for evaluating the impact of LLMs on the accuracy of RAG.
read the caption
Table 6: GPT-4o-mini performance on RAG task (problem generated by GPT).
| Year | Direct Ask | RAG | RAG (GPT) | RAG (Gem) | Full (Original) | Full (GPT) | Full (Gem) |
| 2020 | 66.95% | 82.76% | 82.47% | 75.86% | 93.68% | 91.38% | 84.20% |
| 2021 | 64.68% | 81.90% | 82.34% | 75.06% | 94.04% | 93.82% | 82.12% |
| 2022 | 73.54% | 86.01% | 85.75% | 78.88% | 94.66% | 93.89% | 83.21% |
| 2023 | 69.95% | 82.39% | 83.10% | 78.40% | 92.49% | 92.25% | 83.57% |
| 2024 | 61.25% | 79.58% | 75.42% | 75.42% | 92.92% | 92.92% | 82.92% |
🔼 This table presents the performance of the GPT-40-mini language model on a question answering task using the Retrieval Augmented Generation (RAG) method. The questions for this task were generated by the Gemini language model. The table shows the accuracy of GPT-40-mini under different conditions: Direct Ask (no RAG), RAG using the original Wikipedia text, RAG using Wikipedia text modified by GPT-40-mini, RAG using Wikipedia text modified by Gemini, and Full (original) text, Full (GPT-processed), and Full (Gemini-processed) showing the performance with the full original, GPT processed, and Gemini processed Wikipedia content available as context.
read the caption
Table 7: GPT-4o-mini performance on RAG task (problem generated by Gemini).
| Year | Direct Ask | RAG | RAG (GPT) | RAG (Gem) | Full (Original) | Full (GPT) | Full (Gem) |
| 2020 | 68.68% | 77.59% | 78.16% | 74.14% | 86.21% | 87.93% | 87.36% |
| 2021 | 67.11% | 79.25% | 79.25% | 74.17% | 87.42% | 88.30% | 84.99% |
| 2022 | 70.26% | 82.82% | 80.77% | 78.97% | 88.46% | 90.51% | 88.46% |
| 2023 | 64.08% | 74.88% | 76.06% | 71.83% | 86.85% | 88.73% | 84.27% |
| 2024 | 60.42% | 77.92% | 75.83% | 75.83% | 92.08% | 89.17% | 83.75% |
🔼 This table presents the performance of the GPT-3.5 language model on a question answering task using the RAG (Retrieval Augmented Generation) method. The questions were generated by the GPT language model, and the performance is measured across different settings and time periods (years). The metrics used likely assess the accuracy of the answers provided by GPT-3.5 when retrieving information from a knowledge base using the RAG technique. The settings likely involve variations in question answering techniques such as directly asking the model, using RAG with original content, and using RAG with content modified by different LLMs.
read the caption
Table 8: GPT-3.5 Performance on RAG task (problem generated by GPT).
| Year | Direct Ask | RAG | RAG (GPT) | RAG (Gem) | Full (Original) | Full (GPT) | Full (Gem) |
| 2020 | 66.95% | 72.70% | 72.41% | 68.97% | 77.87% | 79.31% | 77.59% |
| 2021 | 58.72% | 73.73% | 71.74% | 68.21% | 81.02% | 79.47% | 74.17% |
| 2022 | 62.09% | 74.05% | 72.77% | 69.47% | 82.44% | 82.19% | 80.41% |
| 2023 | 56.57% | 73.24% | 74.88% | 67.14% | 77.46% | 79.58% | 74.65% |
| 2024 | 55.00% | 71.67% | 70.00% | 65.00% | 77.92% | 80.42% | 76.67% |
🔼 This table presents the performance of the GPT-3.5 language model on the RAG (Retrieval-Augmented Generation) task. The questions for this task were generated by the Gemini language model. The table shows the accuracy of GPT-3.5 in answering questions across different scenarios and time periods (years 2020-2024). The scenarios include directly asking the question, using RAG with the original Wikipedia text, using RAG with GPT-3.5 revised text, using RAG with Gemini revised text, using the full original Wikipedia text, using the full GPT-3.5 revised text, and using the full Gemini revised text. The results are expressed as percentages.
read the caption
Table 9: GPT-3.5 Performance on RAG task (problem generated by Gemini).
| Year | Direct Ask | RAG | RAG (GPT) | RAG (Gem) | Full (Original) | Full (GPT) | Full (Gem) |
| 2020 | 75.86% | 85.76% | 86.28% | 80.03% | 96.19% | 95.76% | 89.15% |
| 2021 | 71.74% | 86.53% | 89.24% | 80.08% | 96.25% | 96.36% | 89.85% |
| 2022 | 80.00% | 89.87% | 88.14% | 84.55% | 95.90% | 95.96% | 90.51% |
| 2023 | 77.52% | 87.44% | 87.32% | 83.69% | 96.24% | 95.18% | 89.14% |
| 2024 | 67.60% | 83.75% | 85.21% | 82.92% | 96.15% | 96.15% | 90.10% |
🔼 This table presents the performance of the GPT-40-mini language model on a question answering task using the RAG (Retrieval-Augmented Generation) method. The questions were generated by the GPT language model. A key feature of this table is that instances where the model produced no output (Null Output) were assigned a score of 0.25 to account for these cases in the overall performance evaluation. The table is broken down by year and shows the performance across different question answering methods.
read the caption
Table 10: GPT-4o-mini performance on RAG task (problem generated by GPT), Null Output is counted as 0.25.
| Year | Direct Ask | RAG | RAG (GPT) | RAG (Gem) | Full (Original) | Full (GPT) | Full (Gem) |
| 2020 | 67.53% | 82.90% | 82.54% | 76.29% | 93.75% | 91.45% | 85.70% |
| 2021 | 65.01% | 81.95% | 82.40% | 75.22% | 94.21% | 93.87% | 83.83% |
| 2022 | 73.98% | 86.20% | 85.94% | 79.07% | 94.85% | 94.08% | 84.80% |
| 2023 | 70.42% | 82.63% | 83.39% | 78.64% | 92.72% | 92.55% | 85.27% |
| 2024 | 62.50% | 80.00% | 75.83% | 75.94% | 93.65% | 93.33% | 85.00% |
🔼 This table presents the results of GPT-40-mini’s performance on the RAG (Retrieval Augmented Generation) task. The questions for this task were generated by the Gemini language model. A key aspect of this experiment is that a ‘Null Output’ (when the model failed to produce a response) is treated as having 0.25 accuracy, influencing the overall accuracy scores reported. The table shows accuracy percentages across different question types (Direct Ask, RAG using original text, RAG with GPT-processed text, RAG with Gemini-processed text) and across different years (2020-2024). This allows for analysis of how well the model performs under various conditions and over time.
read the caption
Table 11: GPT-4o-mini performance on RAG task (problem generated by Gemini) , Null Output is counted as 0.25.
| Year | Direct Ask | RAG | RAG (GPT) | RAG (Gem) | Full (Original) | Full (GPT) | Full (Gem) |
| 2020 | 68.68% | 77.59% | 78.16% | 74.14% | 86.35% | 87.93% | 87.36% |
| 2021 | 67.11% | 79.25% | 79.25% | 74.17% | 87.42% | 88.30% | 85.15% |
| 2022 | 70.26% | 82.82% | 80.77% | 78.97% | 88.59% | 90.51% | 88.65% |
| 2023 | 64.08% | 74.88% | 76.06% | 71.83% | 86.91% | 88.79% | 84.51% |
| 2024 | 60.42% | 77.92% | 75.83% | 75.83% | 92.29% | 89.17% | 83.75% |
🔼 This table presents the results of using the GPT-3.5 language model to answer questions generated by another GPT model, within the framework of Retrieval Augmented Generation (RAG). The questions are based on the Wikinews dataset. The performance is measured by accuracy, with ‘Null Output’ scenarios (where the model fails to provide an answer) being assigned an accuracy score of 0.25. The table shows the accuracy across different querying methods (direct ask, RAG using original content, RAG using GPT-processed content, and RAG using Gemini-processed content) and across different years (2020-2024), to illustrate the impact of LLMs on RAG’s effectiveness over time.
read the caption
Table 12: GPT-3.5 performance on RAG task (problem generated by GPT) , Null Output is counted as 0.25.
| Year | Direct Ask | RAG | RAG (GPT) | RAG (Gem) | Full (Original) | Full (GPT) | Full (Gem) |
| 2020 | 66.95% | 72.70% | 72.49% | 68.97% | 77.95% | 79.31% | 77.66% |
| 2021 | 58.72% | 73.79% | 71.74% | 68.21% | 81.13% | 79.53% | 74.34% |
| 2022 | 62.28% | 74.11% | 72.84% | 69.53% | 82.44% | 82.25% | 80.47% |
| 2023 | 56.57% | 73.24% | 74.88% | 67.14% | 77.70% | 79.69% | 74.82% |
| 2024 | 55.00% | 71.67% | 70.00% | 65.00% | 78.12% | 80.52% | 76.67% |
🔼 This table presents the results of using GPT-3.5 for the RAG task. The questions for this task were generated by Gemini. The results show the accuracy of GPT-3.5 in answering questions, broken down by different methods (Direct Ask, RAG using original text, RAG using GPT-revised text, RAG using Gemini-revised text, and using full original text, full GPT-revised text, and full Gemini-revised text). The performance is evaluated across different years (2020-2024) and a null output is counted as 0.25 accuracy.
read the caption
Table 13: GPT-3.5 performance on RAG task (problem generated by Gemini) , Null Output is counted as 0.25.
| Models | Knowledge Cutoff | Temperature | Top-p |
| GPT-3.5 | September 2021 | 1.0 | 1.0 |
| GPT-4o-mini | October 2023 | 1.0 | 1.0 |
| Gemini-1.5-flash | May 2024 | 1.0 | 0.95 |
🔼 This table lists the parameters used for the Large Language Models (LLMs) during the Retrieval Augmented Generation (RAG) simulations in the study. It shows the specific LLM models used (GPT-3.5, GPT-40-mini, and Gemini-1.5-flash), the knowledge cutoff date for each model (the most recent date the model was trained on), and the temperature and top-p values used to control the randomness and creativity of the model’s outputs during the RAG process.
read the caption
Table 14: LLM parameters Used in RAG simulations.
| Year | 2020 | 2021 | 2022 | 2023 | 2024 |
| Number of GPT genertated Questions | 348 | 453 | 390 | 426 | 240 |
| Number of Gemini genertated Question | 348 | 453 | 393 | 426 | 240 |
🔼 This table shows the number of questions generated annually by two different large language models (LLMs), GPT and Gemini, from 2020 to 2024. These questions were used in the RAG (Retrieval Augmented Generation) experiments detailed in the paper. The data provides context on the volume of queries used in the study’s evaluation of LLM performance in a question-answering scenario.
read the caption
Table 15: Annual Number of Questions Generated by Different LLMs.
Full paper#