TL;DR#
Text-rich Graph Knowledge Bases (TG-KBs) are essential for answering queries with textual and structural knowledge. However, existing methods often retrieve these types of knowledge separately, neglecting their mutual reinforcement. Some hybrid methods bypass structural retrieval entirely after neighbor aggregation. The paper identifies three challenges: the high resource demands of rewording aggregated neighbors, the discarding of structural signals after neighbor aggregation, and the oversight of varying structural and textual knowledge desires across different queries and TG-KBs.
To address these challenges, the paper introduces a Mixture of Structural-and-Textual Retrieval (MoR) framework. MoR starts with a planning module that generates textual planning graphs to preserve structural signals. A reasoning module interweaves structural traversal and textual matching, enabling mutual reinforcement between retrieval types. An organizing module uses a structure-aware reranker to adaptively adjust the importance of retrieved knowledge. Experiments demonstrate MoR’s superiority in harmonizing structural and textual retrieval, highlighting uneven retrieving performance across query logics and the benefits of integrating structural trajectories for candidate reranking.
Key Takeaways#
Why does it matter?#
This paper offers a novel method to retrieve information by combining textual and structural data from knowledge bases, overcoming limitations of isolated approaches. It enhances question-answering systems and provides a framework for adaptive knowledge integration, inspiring data-centric reasoning designs and error control of planning.
Visual Insights#

🔼 Figure 1 demonstrates different retrieval methods on text-rich graph knowledge bases (TG-KBs). (a) illustrates textual and structural retrieval, showing how queries are processed using text-based or graph-traversal approaches, respectively. (b) highlights the performance variability of these methods across various TG-KBs, emphasizing that optimal methods can vary depending on the specific TG-KB. (c) focuses on query overlaps and differences within a single TG-KB, showing that queries successfully answered using either textual or structural retrieval alone may not always be answerable using the other method.
read the caption
Figure 1: (a) Textual retrieval and structural retrieval. (b) The effectiveness of retrieval methods varies across different TG-KBs. (c) Within the same TG-KB, queries addressed by textual (i.e., 𝒬Textsuperscript𝒬Text\mathcal{Q}^{\text{Text}}caligraphic_Q start_POSTSUPERSCRIPT Text end_POSTSUPERSCRIPT) and structural retrieval (i.e., 𝒬Structsuperscript𝒬Struct\mathcal{Q}^{\text{Struct}}caligraphic_Q start_POSTSUPERSCRIPT Struct end_POSTSUPERSCRIPT) exhibit both overlaps and distinctiveness.
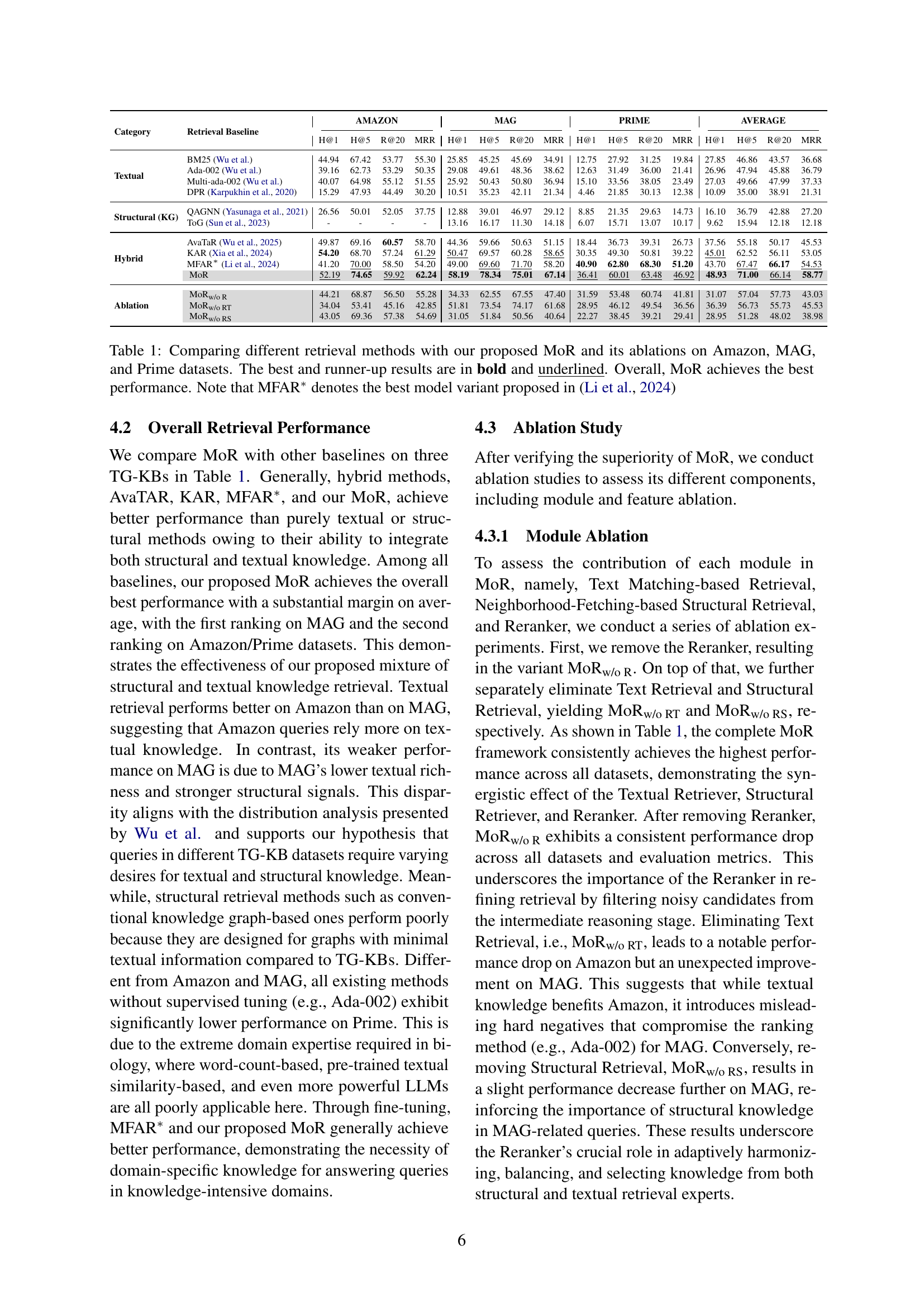
| Category | Retrieval Baseline | AMAZON | MAG | PRIME | AVERAGE | ||||||||||||
| H@1 | H@5 | R@20 | MRR | H@1 | H@5 | R@20 | MRR | H@1 | H@5 | R@20 | MRR | H@1 | H@5 | R@20 | MRR | ||
| Textual | BM25 Wu et al. | 44.94 | 67.42 | 53.77 | 55.30 | 25.85 | 45.25 | 45.69 | 34.91 | 12.75 | 27.92 | 31.25 | 19.84 | 27.85 | 46.86 | 43.57 | 36.68 |
| Ada-002 Wu et al. | 39.16 | 62.73 | 53.29 | 50.35 | 29.08 | 49.61 | 48.36 | 38.62 | 12.63 | 31.49 | 36.00 | 21.41 | 26.96 | 47.94 | 45.88 | 36.79 | |
| Multi-ada-002 Wu et al. | 40.07 | 64.98 | 55.12 | 51.55 | 25.92 | 50.43 | 50.80 | 36.94 | 15.10 | 33.56 | 38.05 | 23.49 | 27.03 | 49.66 | 47.99 | 37.33 | |
| DPR Karpukhin et al. (2020) | 15.29 | 47.93 | 44.49 | 30.20 | 10.51 | 35.23 | 42.11 | 21.34 | 4.46 | 21.85 | 30.13 | 12.38 | 10.09 | 35.00 | 38.91 | 21.31 | |
| Structural (KG) | QAGNN Yasunaga et al. (2021) | 26.56 | 50.01 | 52.05 | 37.75 | 12.88 | 39.01 | 46.97 | 29.12 | 8.85 | 21.35 | 29.63 | 14.73 | 16.10 | 36.79 | 42.88 | 27.20 |
| ToG Sun et al. (2023) | - | - | - | - | 13.16 | 16.17 | 11.30 | 14.18 | 6.07 | 15.71 | 13.07 | 10.17 | 9.62 | 15.94 | 12.18 | 12.18 | |
| Hybrid | AvaTaR Wu et al. (2025) | 49.87 | 69.16 | 60.57 | 58.70 | 44.36 | 59.66 | 50.63 | 51.15 | 18.44 | 36.73 | 39.31 | 26.73 | 37.56 | 55.18 | 50.17 | 45.53 |
| KAR Xia et al. (2024) | 54.20 | 68.70 | 57.24 | 61.29 | 50.47 | 69.57 | 60.28 | 58.65 | 30.35 | 49.30 | 50.81 | 39.22 | 45.01 | 62.52 | 56.11 | 53.05 | |
| MFAR∗ Li et al. (2024) | 41.20 | 70.00 | 58.50 | 54.20 | 49.00 | 69.60 | 71.70 | 58.20 | 40.90 | 62.80 | 68.30 | 51.20 | 43.70 | 67.47 | 66.17 | 54.53 | |
| MoR | 52.19 | 74.65 | 59.92 | 62.24 | 58.19 | 78.34 | 75.01 | 67.14 | 36.41 | 60.01 | 63.48 | 46.92 | 48.93 | 71.00 | 66.14 | 58.77 | |
| Ablation | MoR | 44.21 | 68.87 | 56.50 | 55.28 | 34.33 | 62.55 | 67.55 | 47.40 | 31.59 | 53.48 | 60.74 | 41.81 | 31.07 | 57.04 | 57.73 | 43.03 |
| MoR | 34.04 | 53.41 | 45.16 | 42.85 | 51.81 | 73.54 | 74.17 | 61.68 | 28.95 | 46.12 | 49.54 | 36.56 | 36.39 | 56.73 | 55.73 | 45.53 | |
| MoR | 43.05 | 69.36 | 57.38 | 54.69 | 31.05 | 51.84 | 50.56 | 40.64 | 22.27 | 38.45 | 39.21 | 29.41 | 28.95 | 51.28 | 48.02 | 38.98 | |
🔼 Table 1 presents a comprehensive comparison of various retrieval methods on three distinct Text-rich Graph Knowledge Bases (TG-KBs): Amazon, MAG, and Prime. The methods compared include several baselines (textual, structural, and hybrid approaches), along with the authors’ proposed Mixture of Structural-and-Textual Retrieval (MoR) method and several ablation variants of MoR. The table shows the performance of each method on each dataset across multiple evaluation metrics (H@1, H@5, R@20, MRR). The best and second-best performing methods for each metric and dataset are highlighted. The results demonstrate that MoR consistently outperforms other methods across all datasets and metrics, showcasing the effectiveness of combining structural and textual retrieval approaches. A note clarifies that MFAR* represents the best-performing variant from a previous work by Li et al. (2024).
read the caption
Table 1: Comparing different retrieval methods with our proposed MoR and its ablations on Amazon, MAG, and Prime datasets. The best and runner-up results are in bold and underlined. Overall, MoR achieves the best performance. Note that MFAR∗ denotes the best model variant proposed in Li et al. (2024)
In-depth insights#
Mixture Retrieval#
The concept of ‘Mixture Retrieval,’ as implied by the paper, centers around harmonizing structural and textual knowledge retrieval from Text-rich Graph Knowledge Bases (TG-KBs). This approach is crucial because TG-KBs inherently store information in both structured (graph-based) and unstructured (textual) forms. Traditional methods often treat these retrieval processes in isolation, failing to leverage their mutual reinforcement. A true mixture retrieval system, as envisioned in this work, would intelligently interleave structural traversal and textual matching, adaptively balancing their contributions based on query characteristics and dataset properties. The core challenge lies in creating a framework that can dynamically determine when and how to prioritize structural versus textual cues, overcoming the limitations of rigid, pre-defined rules or simple aggregation techniques. The paper addresses this by introducing a Planning-Reasoning-Organizing framework that facilitates better retrieval performance by integrating both knowledge graphs.
Planning graphs#
Planning graphs are crucial for effective retrieval by outlining the logic for answering queries. They preserve structural signals without rewording neighbors, addressing limitations of existing methods. They encode query-specific constraints and entity categories, enabling generalization to new queries with similar underlying logic. Unlike rigid heuristics or step-by-step LLMs, planning graphs are generated in one shot, reducing computational costs. The method generalizes learned patterns adapting efficiently to new queries with same logic.
Structure rerank#
Structure-aware reranking is a crucial step in refining retrieval results, especially when dealing with diverse knowledge sources. After initial retrieval from textual and structural sources, a reranking mechanism helps to prioritize the most relevant candidates. It leverages trajectory information and structural features to refine the results. A key idea is the emphasis on structural trajectories, which capture how candidates are reached through structural paths, along with semantic matching using models.
Ablation studies#
The ablation studies systematically dissect the contribution of each component within the proposed model, offering granular insights into their individual and collective impacts. Module ablation identifies the synergistic effect of Text Retrieval, Structural Retrieval, and Reranker. Eliminating the Reranker consistently degrades performance, highlighting its importance in noise filtering. Feature ablation reveals that in structural-heavy knowledge, features contribute less but contribute more when a structured signal is found, showing the importance of trajectory structural knowledge.
Limits of MoR#
The paper acknowledges limitations of Mixture of Retrieval (MoR). The primary bottleneck is lack of domain-specific knowledge, hindering performance especially in specialized areas like biomedicine, as seen with the PRIME dataset, this indicates even advanced LLMs struggle without tailored expertise. Second, Reranking limitations as it uses every retrieval layer. Current reranker is also limited to the most informative path. Overcoming these limitations could involve adaptive path integration and MoE.
More visual insights#
More on figures

🔼 The figure illustrates the MoR (Mixture of Structural-and-Textual Retrieval) framework, which is composed of three key modules: a planning module, a reasoning module, and an organizing module. The planning module generates a planning graph that outlines the logic of a query. This graph guides the reasoning module, which employs mixed traversal by interweaving structural traversal (following the relationships in the knowledge base) and textual matching (comparing text content with the query) to identify candidate answers. Finally, the organizing module reranks the retrieved candidates, prioritizing those that align best with the query’s logical structure based on their traversal trajectories.
read the caption
Figure 2: Our MoR framework consists of a planning module to generate a planning graph, a reasoning module to conduct mixed traversal, and an organizing module to rerank the retrieved candidates.

🔼 This figure displays a bar chart showing the performance of three different retrieval methods (Textual Retriever, Structural Retriever, and Mixture-of-Retrievers) across various logical structures found within the Amazon dataset. The x-axis represents the different logical structures (e.g., patterns of relationships between entities such as Product to Category, etc.), while the y-axis shows the Hit@5 score (percentage of times the correct answer is within the top 5 retrieved results). The chart highlights the varying success rates of each retrieval method depending on the complexity and type of logical relationships involved in the query. The Mixture-of-Retrievers consistently outperforms the other two methods across most of the query patterns.
read the caption
Figure 3: Imbalance number of queries and performance of different retrievers across different logical structures.

🔼 This figure visualizes how the model’s attention is distributed across the three entities within the retrieved paths for different queries. It uses saliency maps to show the relative importance of each entity in determining the final ranking of candidates. The heatmap representation shows which entities significantly contribute to the model’s decision-making process for each query.
read the caption
Figure 4: Saliency map visualization of query attention over three entities along the retrieved paths

🔼 Figure 5 presents a detailed analysis of query patterns within the MAG dataset, showcasing the varying performance of different retrieval methods across diverse logical structures. The x-axis categorizes queries based on their underlying logical structure (e.g., P→A→P representing Paper-to-Author-to-Paper relationships), while the y-axis displays the count of queries for each category. The bars illustrate the hit@5 performance for each pattern, indicating the success rate of various retrieval approaches—Textual, Structural, and Mixture-of-Retrievers—in correctly retrieving the top-5 relevant results. The figure reveals that the performance of the Mixture-of-Retrievers model generally improves with increasing numbers of queries for each pattern, except for those with repeated entity types, highlighting the effectiveness of the integrated approach in handling intricate query structures. It also demonstrates a correlation between query pattern complexity and the relative performance of the different retrieval methods.
read the caption
Figure 5: Imbalance number of queries and performance of different retrievers across different logic patterns.
More on tables
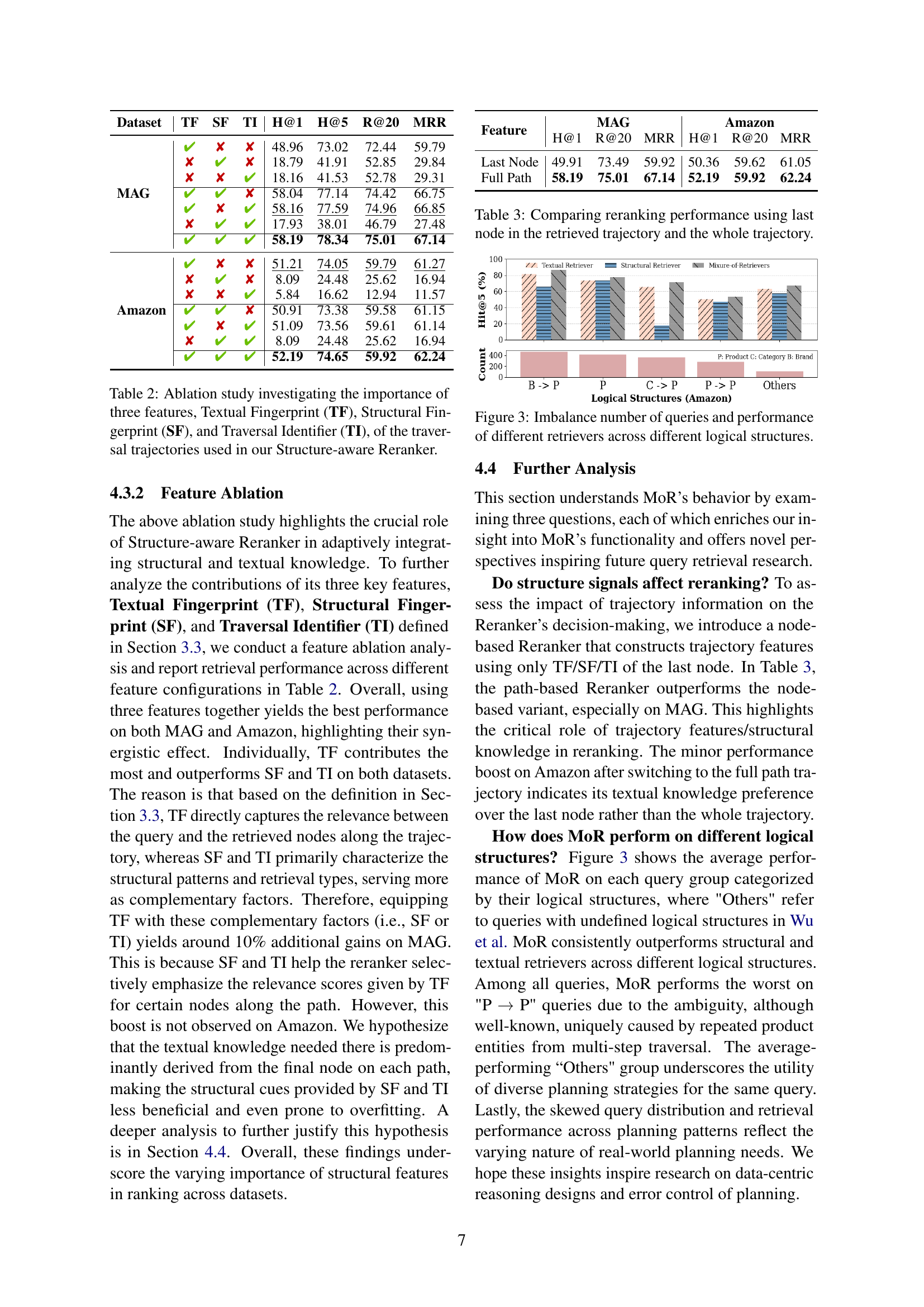
| Dataset | TF | SF | TI | H@1 | H@5 | R@20 | MRR |
| MAG | ✔ | ✘ | ✘ | 48.96 | 73.02 | 72.44 | 59.79 |
| ✘ | ✔ | ✘ | 18.79 | 41.91 | 52.85 | 29.84 | |
| ✘ | ✘ | ✔ | 18.16 | 41.53 | 52.78 | 29.31 | |
| ✔ | ✔ | ✘ | 58.04 | 77.14 | 74.42 | 66.75 | |
| ✔ | ✘ | ✔ | 58.16 | 77.59 | 74.96 | 66.85 | |
| ✘ | ✔ | ✔ | 17.93 | 38.01 | 46.79 | 27.48 | |
| ✔ | ✔ | ✔ | 58.19 | 78.34 | 75.01 | 67.14 | |
| Amazon | ✔ | ✘ | ✘ | 51.21 | 74.05 | 59.79 | 61.27 |
| ✘ | ✔ | ✘ | 8.09 | 24.48 | 25.62 | 16.94 | |
| ✘ | ✘ | ✔ | 5.84 | 16.62 | 12.94 | 11.57 | |
| ✔ | ✔ | ✘ | 50.91 | 73.38 | 59.58 | 61.15 | |
| ✔ | ✘ | ✔ | 51.09 | 73.56 | 59.61 | 61.14 | |
| ✘ | ✔ | ✔ | 8.09 | 24.48 | 25.62 | 16.94 | |
| ✔ | ✔ | ✔ | 52.19 | 74.65 | 59.92 | 62.24 |
🔼 This table presents an ablation study analyzing the impact of different features used within the Structure-aware Reranker component of the MoR model. It shows how removing one or more features (Textual Fingerprint, Structural Fingerprint, and Traversal Identifier) affects the model’s performance, helping to understand the contribution of each feature to the overall accuracy.
read the caption
Table 2: Ablation study investigating the importance of three features, Textual Fingerprint (TF), Structural Fingerprint (SF), and Traversal Identifier (TI), of the traversal trajectories used in our Structure-aware Reranker.
| Feature | MAG | Amazon | ||||
| H@1 | R@20 | MRR | H@1 | R@20 | MRR | |
| Last Node | 49.91 | 73.49 | 59.92 | 50.36 | 59.62 | 61.05 |
| Full Path | 58.19 | 75.01 | 67.14 | 52.19 | 59.92 | 62.24 |
🔼 This table presents a comparison of reranking performance using two different approaches: considering only the last node in the retrieved trajectory and utilizing the entire trajectory. The results show how effectively each approach integrates structural and textual information to improve the overall ranking accuracy of retrieved candidates. It highlights the impact of incorporating trajectory information in the reranking process.
read the caption
Table 3: Comparing reranking performance using last node in the retrieved trajectory and the whole trajectory.
| Notations | Definitions or Descriptions |
| Text-rich Graph Knowledge Base (TG-KB) | |
| Set of Nodes, Categories and Documents of TG-KB | |
| Document and Category of Node | |
| Query from Query set | |
| Query targeted by structural and textual retrieval | |
| Planning Graph consisting of multiple reasoning paths | |
| Reasoning path consisting of sequential entities | |
| Textual category and restriction of path entity | |
| Retrieved candidates after reasoning module. | |
| Retrieved candidates at layer for path including structurally retrieved ones and textually retrieved ones. | |
| Final retrieved candidates after organizing module. | |
| Joint distribution of query and planning graph. | |
| Neighborhood of entity | |
| Traversal Identifier of Structural and Textual Retrieval | |
| Planning module with its parameters | |
| Reasoning module with its parameters | |
| Organizing module with its parameters |
🔼 This table lists notations used in the paper and their corresponding descriptions. It includes symbols for the text-rich graph knowledge base (TG-KB), its components (nodes, edges, documents), queries, retrieved candidates, planning graphs and reasoning paths, entity categories and restrictions, and probability distributions for each module in the proposed framework.
read the caption
Table 4: Notations and the corresponding descriptions.
| Dataset | # Entities | # Text Tokens | # Relations | Avg. Degree |
| AMAZON | 1,035,542 | 592,067,882 | 9,443,802 | 18.2 |
| MAG | 1,872,968 | 212,602,571 | 39,802,116 | 43.5 |
| PRIME | 129,375 | 31,844,769 | 8,100,498 | 125.2 |
🔼 This table presents a statistical overview of three text-rich graph knowledge bases (TG-KBs) used in the STaRK benchmark. For each TG-KB (Amazon, MAG, and Prime), it shows the number of entities, text tokens, and relations, along with the average node degree. These statistics provide insights into the size and complexity of the datasets, which are crucial for understanding the experimental results and the challenges of knowledge retrieval in these specific TG-KBs.
read the caption
Table 5: Statistics of text-rich graph knowledge bases in STaRK benchmark Wu et al. .
Full paper#