TL;DR#
Autonomous Vehicles face challenges in interacting with human drivers due to limited intent expression. Recent Large Language Models (LLMs) offer potential for better communication but struggle with real-time decision-making. Issues include adapting to dynamic environments, handling unpredictable human behaviors, and navigating diverse scenarios. These limitations impact the safety and efficiency of AVs.
To address this, a parallel Actor-Reasoner framework is introduced. It leverages LLMs for real-time AV-HV interactions across various scenarios. By simulating interactions between the LLM-driven Reasoner and heterogeneous simulated HVs, an interaction memory database (Actor) is created. This framework enhances safety and efficiency. The effectiveness is confirmed through field tests.
Key Takeaways#
Why does it matter?#
This paper is vital for AV researchers, offering a novel LLM-driven framework that enhances AV interaction and intent expression. It addresses a critical gap in real-time AV-HV communication, providing a practical solution validated in diverse scenarios and real-world tests, paving the way for safer and more efficient autonomous driving.
Visual Insights#
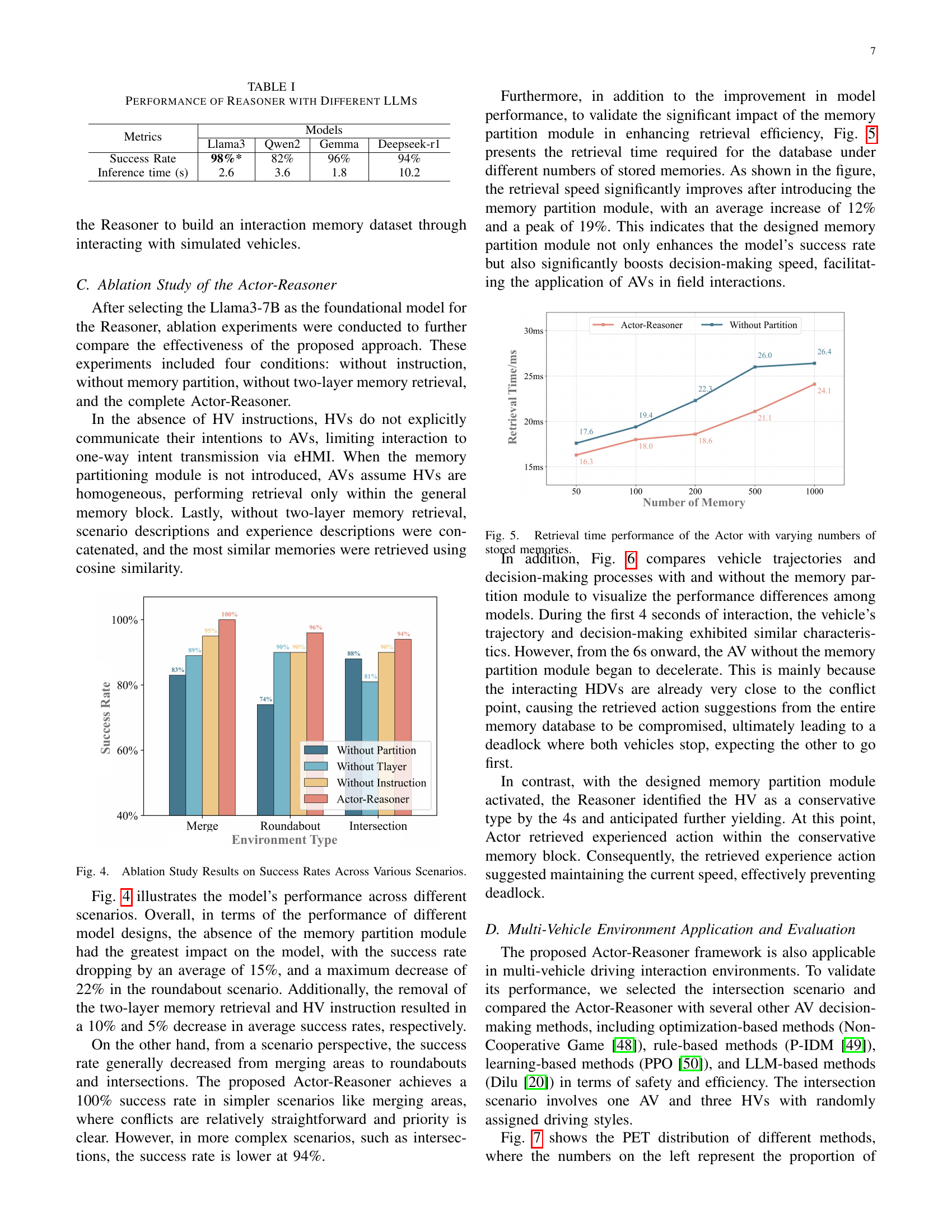
| Metrics | Models | |||
| Llama3 | Qwen2 | Gemma | Deepseek-r1 | |
| Success Rate | 98%* | 82% | 96% | 94% |
| Inference time (s) | 2.6 | 3.6 | 1.8 | 10.2 |
🔼 This table presents a comparison of various Large Language Models (LLMs) used as the foundation for the Reasoner component within the Actor-Reasoner framework. The comparison focuses on two key metrics: the success rate of the model in achieving its objective within driving interaction tasks, and the inference time, representing the speed at which the LLM processes information. This allows for an evaluation of the different LLMs’ performance in terms of both accuracy and efficiency for real-time applications.
read the caption
TABLE I: Performance of Reasoner with Different LLMs
Full paper#