TL;DR#
Large language models (LLMs) have revolutionized NLP, but open-source multilingual LLMs are scarce, limiting language coverage. Existing models prioritize well-resourced languages, overlooking widely spoken but under-resourced ones. To bridge this gap and enhance global accessibility, this paper introduces a new open-source multilingual LLM that aims to serve over 90% of speakers worldwide. It focuses on the top 25 languages by speaker numbers, including many languages neglected by existing open-source multilingual LLMs. Additionally, given the limited high-quality training data for many languages, the paper emphasizes optimizing the data-cleaning pipeline to ensure the highest possible data quality.
This paper introduces Babel, which enhances performance through a layer extension technique, increasing its parameter space instead of traditional continue pretraining. Two variants are presented: one designed for efficient inference and fine-tuning, and another setting a new standard for open multilingual LLMs. Evaluations on multilingual tasks show its superior performance compared to open LLMs of comparable size. Moreover, using open-source supervised fine-tuning datasets, Babel achieves remarkable performance, with one variant leading among 10B-sized LLMs and the other setting a new standard for multilingual tasks, rivaling commercial models.
Key Takeaways#
Why does it matter?#
This paper is important for researchers, because it introduces a new open-source multilingual LLM, addressing the gap in language coverage, and sets a strong foundation for future research in multilingual language modeling. It also sets a new standard for open multilingual LLMs.
Visual Insights#

🔼 This figure illustrates the layer extension method used in the Babel model. The original model’s layers are shown on the left. The layer extension technique adds new layers (shown inserted and appended in the middle), which are identical in structure to the original model’s layers. This approach increases the model’s parameter count, enhancing its performance without significantly altering its core architecture. The figure highlights that only layers in the latter half of the model are extended to minimize disruption of the existing layers.
read the caption
Figure 1: Layer extension for Babel.
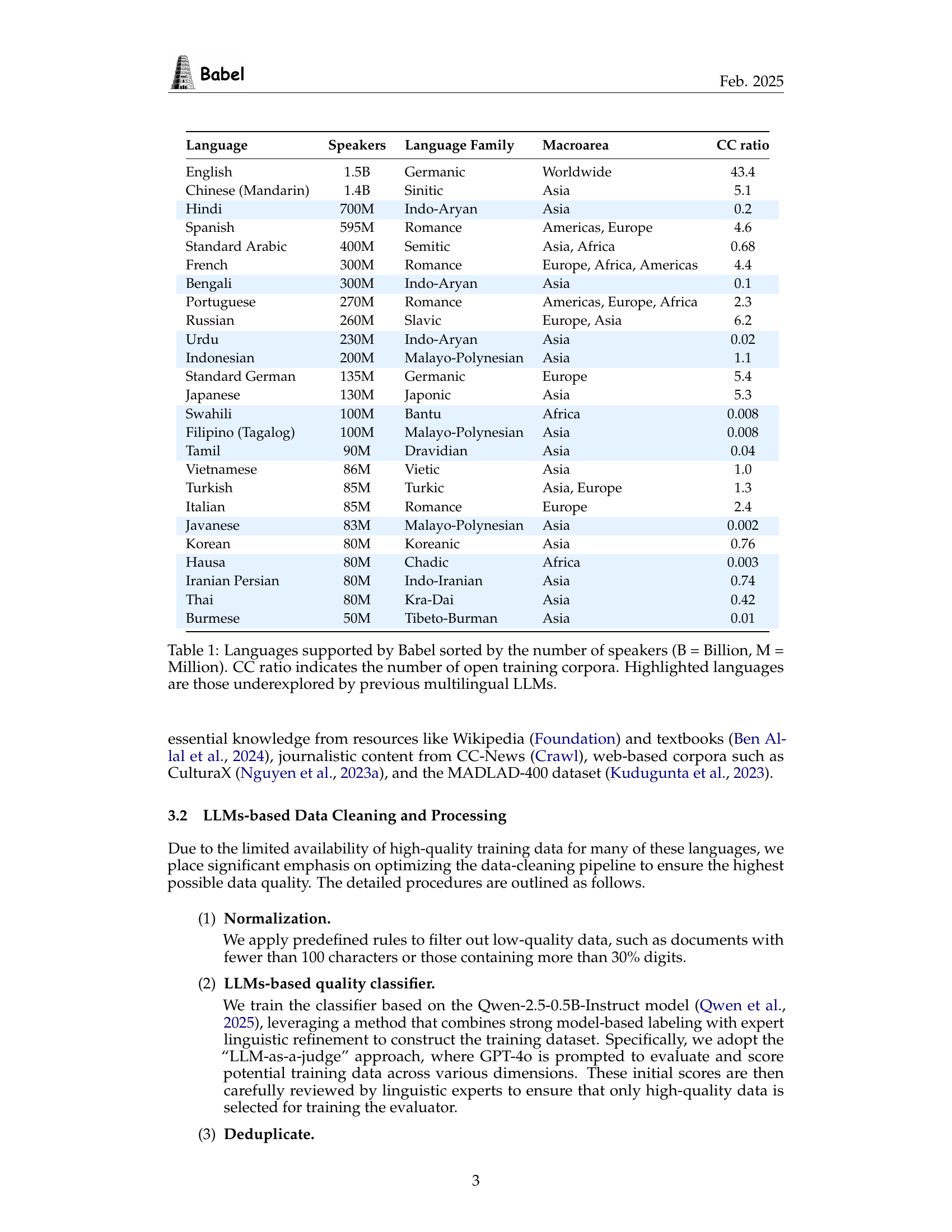
| Language | Speakers | Language Family | Macroarea | CC ratio |
|---|---|---|---|---|
| English | 1.5B | Germanic | Worldwide | 43.4 |
| Chinese (Mandarin) | 1.4B | Sinitic | Asia | 5.1 |
| Hindi | 700M | Indo-Aryan | Asia | 0.2 |
| Spanish | 595M | Romance | Americas, Europe | 4.6 |
| Standard Arabic | 400M | Semitic | Asia, Africa | 0.68 |
| French | 300M | Romance | Europe, Africa, Americas | 4.4 |
| Bengali | 300M | Indo-Aryan | Asia | 0.1 |
| Portuguese | 270M | Romance | Americas, Europe, Africa | 2.3 |
| Russian | 260M | Slavic | Europe, Asia | 6.2 |
| Urdu | 230M | Indo-Aryan | Asia | 0.02 |
| Indonesian | 200M | Malayo-Polynesian | Asia | 1.1 |
| Standard German | 135M | Germanic | Europe | 5.4 |
| Japanese | 130M | Japonic | Asia | 5.3 |
| Swahili | 100M | Bantu | Africa | 0.008 |
| Filipino (Tagalog) | 100M | Malayo-Polynesian | Asia | 0.008 |
| Tamil | 90M | Dravidian | Asia | 0.04 |
| Vietnamese | 86M | Vietic | Asia | 1.0 |
| Turkish | 85M | Turkic | Asia, Europe | 1.3 |
| Italian | 85M | Romance | Europe | 2.4 |
| Javanese | 83M | Malayo-Polynesian | Asia | 0.002 |
| Korean | 80M | Koreanic | Asia | 0.76 |
| Hausa | 80M | Chadic | Africa | 0.003 |
| Iranian Persian | 80M | Indo-Iranian | Asia | 0.74 |
| Thai | 80M | Kra-Dai | Asia | 0.42 |
| Burmese | 50M | Tibeto-Burman | Asia | 0.01 |
🔼 This table lists the top 25 languages supported by the Babel multilingual large language model, ordered by the number of speakers (in billions and millions). For each language, it shows its language family, the macroarea where it’s predominantly spoken, and a CC ratio, which represents the number of available open-source training corpora. Languages that have been historically under-represented in previous multilingual LLMs are highlighted to emphasize Babel’s broader language coverage.
read the caption
Table 1: Languages supported by Babel sorted by the number of speakers (B = Billion, M = Million). CC ratio indicates the number of open training corpora. Highlighted languages are those underexplored by previous multilingual LLMs.
In-depth insights#
LLM Multilingual#
Multilingual LLMs are pivotal for bridging communication gaps across diverse linguistic communities. The paper addresses the scarcity of open-source options, particularly for under-resourced languages. By focusing on the top 25 languages by speaker count, covering 90% of the global population, the work aims for inclusivity. The introduction of Babel, a novel LLM, tackles the challenge of expanding language support while maintaining performance. The layer extension technique and two variants (Babel-9B and Babel-83B) signify a commitment to efficient inference and state-of-the-art capabilities, respectively. The significance lies in its potential to democratize access to NLP technologies, ensuring that a broader range of languages benefits from advancements in the field. Furthermore, the emphasis on data quality and model expansion suggests a dedication to both linguistic breadth and model performance.
Layer Extension#
Layer Extension seems to be a technique to scale up the capacity of a language model. Instead of just pre-training, it adds new layers to the existing architecture. It increases the total parameter count and improves the performance ceiling. Key considerations include how to initialize the weights of the new layers (duplication, adding noise) and where to insert them (between existing layers, appending at the end). Optimal approach ensures minimal disruption of the original model and efficient training. By expanding model capacity strategically, it aims to improve performance without completely retraining.
Data Cleaning#
Data cleaning is a crucial step in preparing data for training large language models (LLMs). The process involves several key steps like normalization, to remove noise and inconsistencies in the data. LLM-based quality classifiers are also employed, utilizing a combination of model-based labeling with expert linguistic refinement to construct high-quality training datasets. Deduplication techniques, such as hashing and pairing duplicates, are also implemented to ensure data uniqueness. Optimizing data quality is essential, especially for languages with limited high-quality resources, as it directly impacts the performance and reliability of the trained LLMs.
Babel Performance#
Babel’s performance is rigorously evaluated across diverse multilingual tasks. Key findings reveal its superior performance compared to other open LLMs of comparable size, notably in multilingual reasoning, understanding, and translation. Babel achieves state-of-the-art results on various benchmarks. Babel’s novel layer extension technique and optimized data-cleaning pipeline contribute to its strong foundational performance. Babel’s effectiveness across both high-resource and low-resource languages highlights its balanced design and broader accessibility. The chat version of Babel demonstrates strong multilingual capabilities, approaching the performance of top commercial alternatives. Performance gains are attributed to both model architecture and training data strategies.
Future LLM Tuning#
Future LLM tuning will likely focus on more efficient and targeted methods. The trend will involve strategies like parameter-efficient fine-tuning (PEFT), enabling adaptation to specific tasks with minimal computational cost. Moreover, expect increased emphasis on multilingual and low-resource language tuning, leveraging techniques like cross-lingual transfer learning to overcome data scarcity. Improved alignment methods, such as reinforcement learning from human feedback (RLHF), will ensure LLMs are more helpful and less toxic. We will also see development in tuning for specialized applications such as medical and legal domains
More visual insights#
More on figures

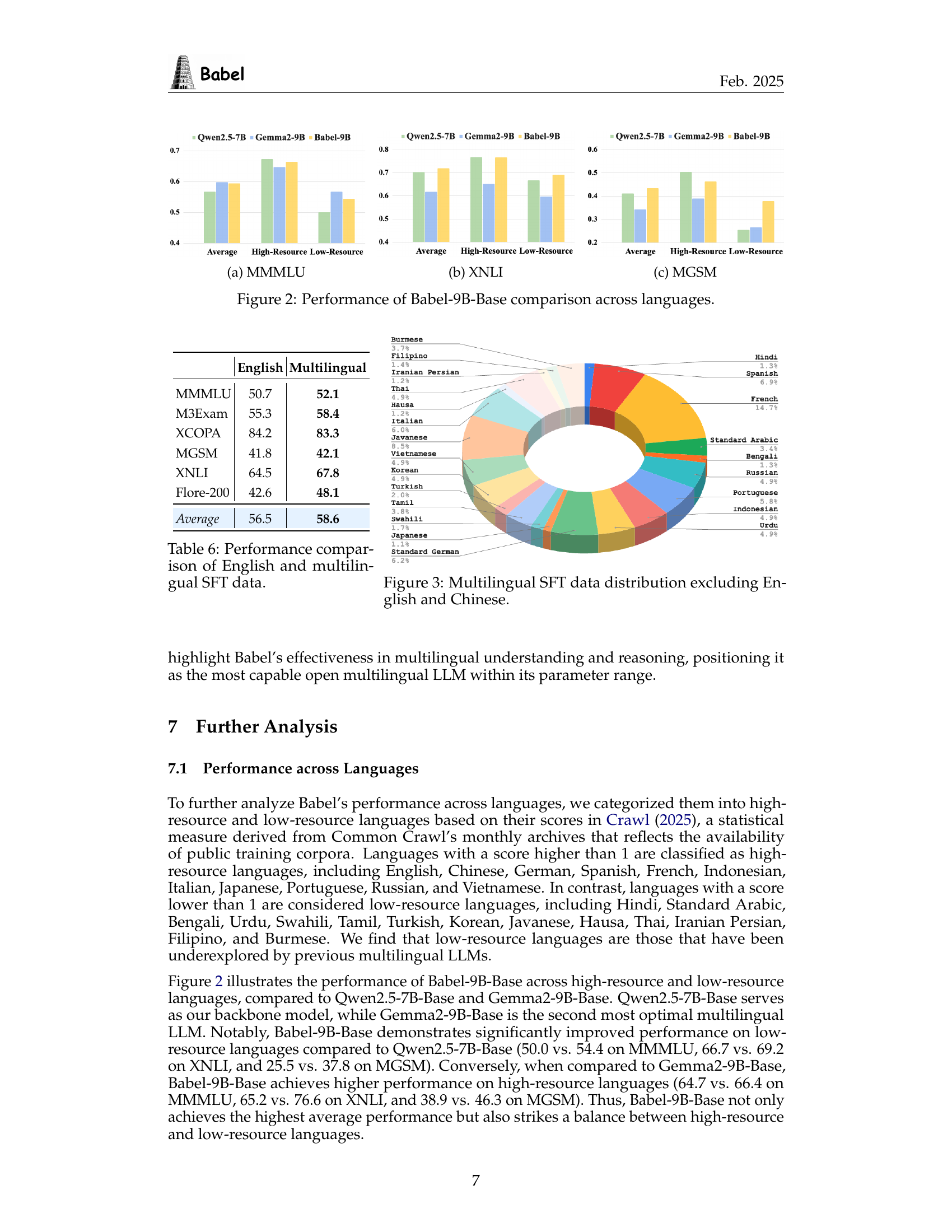
🔼 This figure presents a bar chart comparing the performance of three different 10B-parameter language models (Qwen2.5-7B, Gemma2-9B, and Babel-9B) on the MMMLU benchmark. The chart displays the average performance across all languages, as well as the performance on high-resource and low-resource languages separately. It visually demonstrates Babel-9B’s superior performance, particularly on low-resource languages, showcasing its strength in multilingual understanding.
read the caption
(a) MMMLU

🔼 The figure shows the performance comparison of Babel-9B-Base with other multilingual models on the XNLI (Cross-lingual Natural Language Inference) dataset. It displays the average performance across high and low resource languages and highlights Babel’s improved performance, especially on the low-resource languages, compared to other models such as Qwen2.5-7B and Gemma2-9B.
read the caption
(b) XNLI

🔼 This figure displays the performance comparison of Babel-9B-Base against other multilingual LLMs across the MGSM (Multi-Genre Semantic Matching) dataset. The chart likely shows performance metrics such as accuracy or F1-score, comparing Babel-9B-Base to models like Qwen2.5-7B and Gemma2-9B. It specifically highlights how Babel performs across high and low-resource languages within the MGSM dataset.
read the caption
(c) MGSM

🔼 This figure compares the performance of Babel-9B-Base, Qwen2.5-7B, and Gemma2-9B across different languages, categorized into high-resource and low-resource groups. For each model and language group, the average performance is shown across three benchmark datasets: MMMLU, XNLI, and MGSM, representing world knowledge, natural language inference, and common sense reasoning, respectively. The figure visually demonstrates Babel-9B-Base’s performance improvement over other models, particularly with low-resource languages, highlighting its multilingual capabilities.
read the caption
Figure 2: Performance of Babel-9B-Base comparison across languages.
More on tables
| No-noise | Gaussian () | Gaussian () | |
|---|---|---|---|
| Among Layers | 73.1 | 43.1 | 72.8 |
| After Model | 9.4 | 3.1 | 5.2 |
🔼 This table presents the results of an ablation study on different initialization methods for the layer extension technique used in the Babel model. The study varied the position of the inserted layers (among existing layers or appended to the end) and the initialization method (copying original parameters, initializing with zeros, or adding Gaussian noise). The table shows that appending layers significantly reduces performance, while inserting layers has less impact, and copying original parameters without noise achieves the best performance. The baseline performance (before layer extension) is 79.5, providing a context for understanding the impact of different initialization strategies.
read the caption
Table 2: Layer extension initialization analysis. The original performance is 79.5.
| Model | Initialization | Layer Inserting Position |
|---|---|---|
| Babel-9B | Duplicate + Gaussian Noise | {14, 16, 18, 20, 22, 24} |
| Babel-83B | {40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62} |
🔼 This table details the specific configurations used for expanding the Babel-9B and Babel-83B models. It shows the initialization method used for the added layers (Duplicate + Gaussian Noise) and the precise layer positions where new layers were inserted within the original model architecture. The layer positions are listed as numerical indices, indicating the location of new layer insertion relative to the existing layers.
read the caption
Table 3: Layer extension method details.
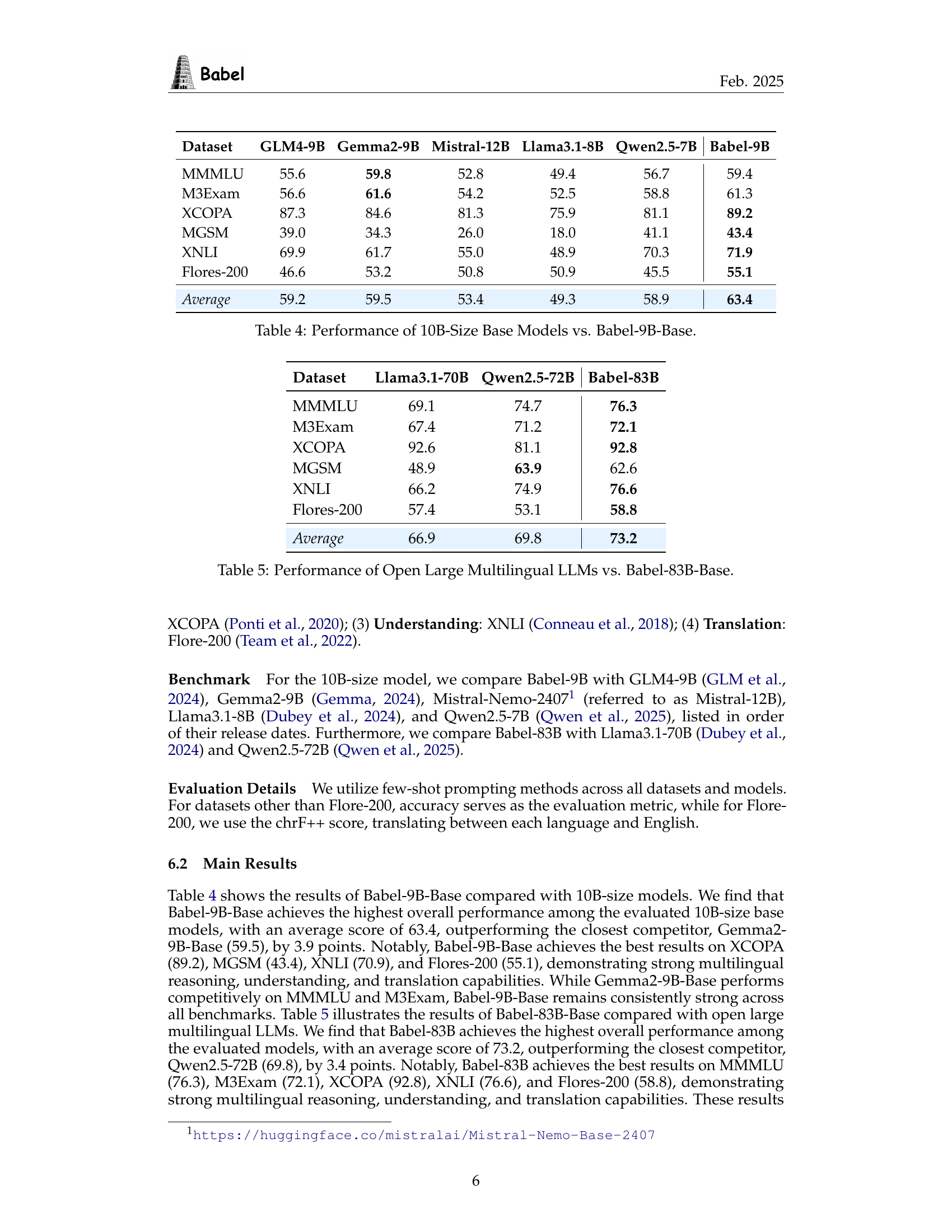
| Dataset | GLM4-9B | Gemma2-9B | Mistral-12B | Llama3.1-8B | Qwen2.5-7B | Babel-9B |
|---|---|---|---|---|---|---|
| MMMLU | 55.6 | 59.8 | 52.8 | 49.4 | 56.7 | 59.4 |
| M3Exam | 56.6 | 61.6 | 54.2 | 52.5 | 58.8 | 61.3 |
| XCOPA | 87.3 | 84.6 | 81.3 | 75.9 | 81.1 | 89.2 |
| MGSM | 39.0 | 34.3 | 26.0 | 18.0 | 41.1 | 43.4 |
| XNLI | 69.9 | 61.7 | 55.0 | 48.9 | 70.3 | 71.9 |
| Flores-200 | 46.6 | 53.2 | 50.8 | 50.9 | 45.5 | 55.1 |
| Average | 59.2 | 59.5 | 53.4 | 49.3 | 58.9 | 63.4 |
🔼 This table compares the performance of Babel-9B-Base, a 9-billion parameter multilingual large language model, against other open-source multilingual LLMs with around 10 billion parameters across six different benchmark datasets. The datasets assess various aspects of language understanding, including world knowledge, commonsense reasoning, natural language inference, and cross-lingual understanding. The results show Babel-9B-Base’s performance relative to other models of similar size.
read the caption
Table 4: Performance of 10B-Size Base Models vs. Babel-9B-Base.
| Dataset | Llama3.1-70B | Qwen2.5-72B | Babel-83B |
|---|---|---|---|
| MMMLU | 69.1 | 74.7 | 76.3 |
| M3Exam | 67.4 | 71.2 | 72.1 |
| XCOPA | 92.6 | 81.1 | 92.8 |
| MGSM | 48.9 | 63.9 | 62.6 |
| XNLI | 66.2 | 74.9 | 76.6 |
| Flores-200 | 57.4 | 53.1 | 58.8 |
| Average | 66.9 | 69.8 | 73.2 |
🔼 This table compares the performance of Babel-83B-Base, a large multilingual language model, against other open-source large multilingual language models. It assesses their performance across six different benchmark datasets: MMMLU (multitask language understanding), M3Exam (multilingual exam questions), XCOPA (causal commonsense reasoning), MGSM (multilingual general-purpose reasoning), XNLI (cross-lingual natural language inference), and Flores-200 (cross-lingual translation). The results show the average performance across these tasks for each model, indicating Babel-83B-Base’s performance relative to its competitors.
read the caption
Table 5: Performance of Open Large Multilingual LLMs vs. Babel-83B-Base.
| English | Multilingual | |
|---|---|---|
| MMMLU | 50.7 | 52.1 |
| M3Exam | 55.3 | 58.4 |
| XCOPA | 84.2 | 83.3 |
| MGSM | 41.8 | 42.1 |
| XNLI | 64.5 | 67.8 |
| Flore-200 | 42.6 | 48.1 |
| Average | 56.5 | 58.6 |
🔼 This table compares the performance of models fine-tuned using only English supervised fine-tuning (SFT) data versus models trained with multilingual SFT data. The comparison is done across six different multilingual benchmarks: MMMLU, M3Exam, XCOPA, MGSM, XNLI, and Flores-200. It shows the performance difference when using English-only versus multilingual datasets for fine-tuning, highlighting the improvement in performance achieved by using multilingual data.
read the caption
Table 6: Performance comparison of English and multilingual SFT data.
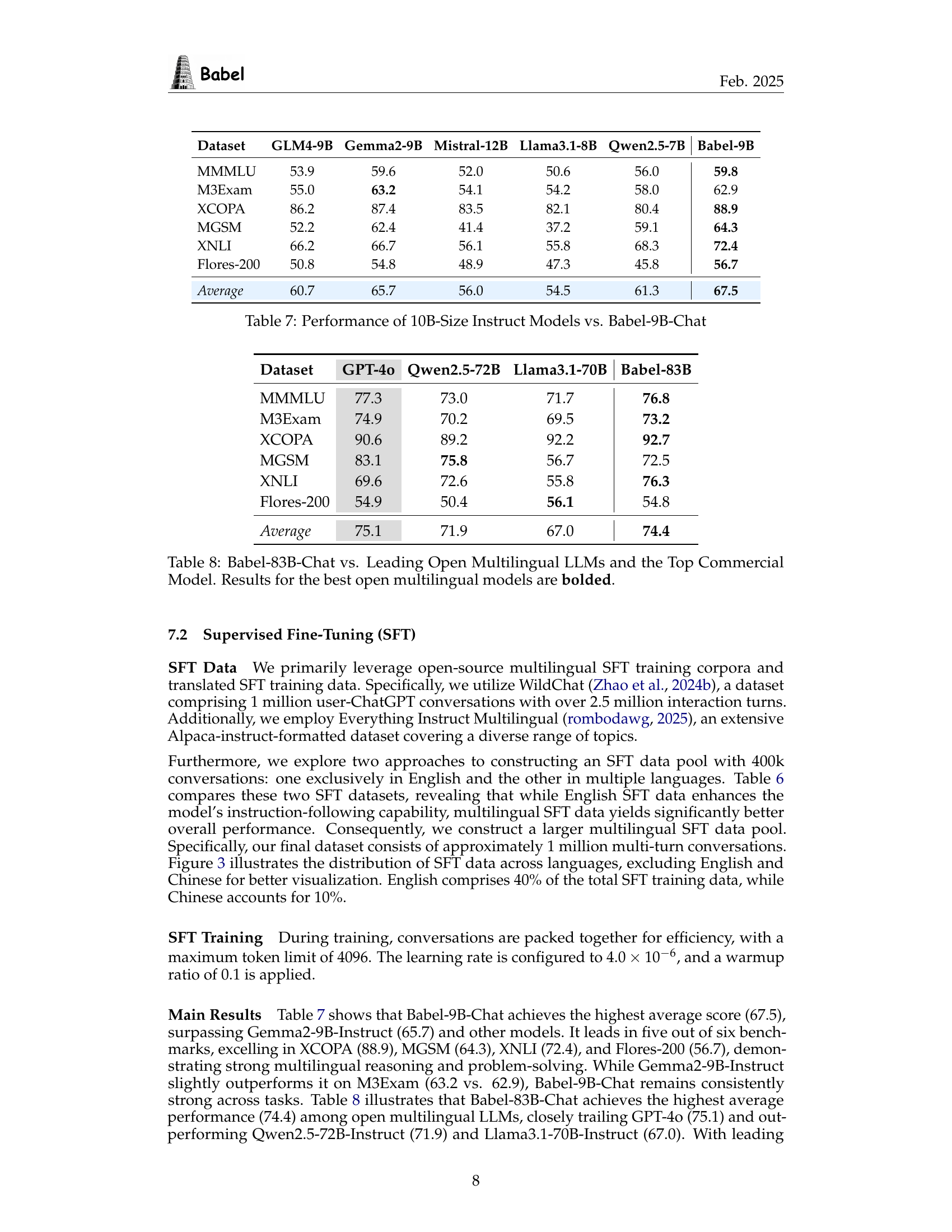
| Dataset | GLM4-9B | Gemma2-9B | Mistral-12B | Llama3.1-8B | Qwen2.5-7B | Babel-9B |
|---|---|---|---|---|---|---|
| MMMLU | 53.9 | 59.6 | 52.0 | 50.6 | 56.0 | 59.8 |
| M3Exam | 55.0 | 63.2 | 54.1 | 54.2 | 58.0 | 62.9 |
| XCOPA | 86.2 | 87.4 | 83.5 | 82.1 | 80.4 | 88.9 |
| MGSM | 52.2 | 62.4 | 41.4 | 37.2 | 59.1 | 64.3 |
| XNLI | 66.2 | 66.7 | 56.1 | 55.8 | 68.3 | 72.4 |
| Flores-200 | 50.8 | 54.8 | 48.9 | 47.3 | 45.8 | 56.7 |
| Average | 60.7 | 65.7 | 56.0 | 54.5 | 61.3 | 67.5 |
🔼 This table compares the performance of Babel-9B-Chat, a 10B parameter instruct model, against other 10B parameter instruction-tuned multilingual large language models across six benchmark datasets. The datasets evaluate various aspects of language understanding, including world knowledge, commonsense reasoning, natural language inference, and cross-lingual understanding. The comparison allows for a quantitative assessment of Babel-9B-Chat’s capabilities relative to other similar-sized models in the open-source domain.
read the caption
Table 7: Performance of 10B-Size Instruct Models vs. Babel-9B-Chat
| Dataset | GPT-4o | Qwen2.5-72B | Llama3.1-70B | Babel-83B |
|---|---|---|---|---|
| MMMLU | 77.3 | 73.0 | 71.7 | 76.8 |
| M3Exam | 74.9 | 70.2 | 69.5 | 73.2 |
| XCOPA | 90.6 | 89.2 | 92.2 | 92.7 |
| MGSM | 83.1 | 75.8 | 56.7 | 72.5 |
| XNLI | 69.6 | 72.6 | 55.8 | 76.3 |
| Flores-200 | 54.9 | 50.4 | 56.1 | 54.8 |
| Average | 75.1 | 71.9 | 67.0 | 74.4 |
🔼 This table compares the performance of Babel-83B-Chat against leading open-source multilingual large language models (LLMs) and a top commercial model across several benchmark datasets. The datasets assess various aspects of language understanding, such as multilingual reasoning, translation, and commonsense knowledge. The best performing open-source model for each dataset is highlighted in bold, providing a clear visual indication of Babel’s competitive standing compared to existing alternatives.
read the caption
Table 8: Babel-83B-Chat vs. Leading Open Multilingual LLMs and the Top Commercial Model. Results for the best open multilingual models are bolded.
Full paper#