TL;DR#
Existing UAV evaluation frameworks often lack cognitive functions beyond basic navigation and racing tasks. This limitation hinders fair comparisons and exploration of higher-level cognitive abilities like reasoning, human recognition, and symbol understanding.
This paper introduces CognitiveDrone, a VLA model designed for real-time cognitive task solving and reasoning in UAVs. Paired with CognitiveDroneBench, an open-source benchmark built on Gazebo, that integrates a drone racing track with cognitive checkpoints. The system includes an auxiliary reasoning module based on the VLM model Qwen2.5-VL, creating the CognitiveDrone-R1 variant. CognitiveDrone significantly outperforms existing models in complex tasks.
Key Takeaways#
Why does it matter?#
This paper introduces the CognitiveDrone VLA model and CognitiveDroneBench, providing resources for cognitive UAV research. It demonstrates the significance of integrating advanced reasoning into UAV control, potentially spurring advancements in autonomous drone capabilities and cognitive robotics.
Visual Insights#

🔼 The figure illustrates the CognitiveDrone system architecture. It shows how the system processes first-person visual inputs and natural language instructions to generate smooth 4D control commands for a UAV. The system integrates a large Vision-Language-Action (VLA) model for control and a Vision-Language Model (VLM) for reasoning. The VLA model generates high-frequency control commands from visual inputs and refined task directives. The VLM reasoning module processes the instructions and simplifies task directives, improving performance in complex cognitive tasks. The system is evaluated using a novel benchmark called CognitiveDroneBench, which involves a drone navigating a track and selecting gates by solving cognitive tasks. The entire system, including dataset, benchmark, model weights, and code, is open-source.
read the caption
Figure 1: CognitiveDrone is a VLA system for UAVs that generates smooth 4D control commands from first-person visual inputs and natural language instructions. It combines a 7B-parameter VLA model trained on an extensive open-source dataset of cognitive tasks—including reasoning, human recognition, and symbol understanding—with a 7B-parameter VLM reasoning module that refines task directives. The system is evaluated within CognitiveDroneBench—the first evaluation benchmark for VLA systems tailored to cognitive UAVs—where the drone must navigate a track with gates by selecting the appropriate gate through solving cognitive tasks. We have released the complete dataset, benchmark environment, model weights, and training/inference code as open source.
In-depth insights#
Cognitive UAVs#
Cognitive UAVs represent a significant leap in autonomous systems, moving beyond simple navigation to complex reasoning and decision-making. Integrating vision-language models (VLMs) allows UAVs to interpret instructions, understand environments, and adapt to unpredictable scenarios. A key challenge is the lack of standardized benchmarks to evaluate cognitive abilities in UAVs, highlighting the need for datasets and environments that test reasoning, human recognition, and symbolic understanding. The development of VLA models and open-source benchmarks is crucial for advancing cognitive UAV research, paving the way for more intelligent and adaptable aerial robots capable of performing intricate tasks in dynamic real-world situations, significantly expanding their potential applications beyond traditional roles.
VLA architecture#
From the context, the paper introduces CognitiveDrone, a novel Vision-Language-Action (VLA) model designed for complex UAV tasks. The CognitiveDrone system seems to be built upon a foundational VLA architecture, likely inspired by models like OpenVLA. The core idea is to enable UAVs to not only execute precise flight maneuvers but also to reason and make decisions based on visual inputs and natural language instructions. The VLA model would process both visual data from the UAV’s camera (FPV) and textual commands from a user. The system aims to generate real-time 4D action commands (Vx, Vy, Vz, ω) to control the UAV’s movement. The CognitiveDrone-R1 variant introduces an additional VLM (Vision-Language Model) reasoning module to refine task directives, essentially pre-processing the instructions to make them easier for the VLA model to execute. This highlights the importance of a well-defined VLA architecture that can effectively integrate visual perception, language understanding, and action planning for autonomous UAV operation.
OpenVLA Limits#
While OpenVLA demonstrates proficiency in capturing drone flight dynamics and generating real-time control commands, its primary focus on flight physics may limit its effectiveness in handling more complex cognitive tasks. Ambiguities in task instructions and the challenges associated with selecting appropriate actions in multifaceted scenarios pose significant hurdles. The model’s architecture, although adept at generating high-frequency control commands, requires enhancement to address nuanced cognitive demands. Incorporating an additional VLM dedicated to high-level reasoning presents a viable solution, enabling disambiguation of instructions and translation of complex commands into clearly defined actions. This integration effectively augments the system’s cognitive capabilities, allowing for more robust decision-making and improved performance in complex UAV operations. Addressing these limitations through architectural extensions and specialized reasoning modules is crucial for unlocking the full potential of OpenVLA in demanding cognitive tasks.
CognitiveBench#
CognitiveBench, a novel open-source simulation benchmark, is introduced to address the challenge of evaluating cognitive capabilities in UAVs, which are more complex than in robotic manipulators. Implemented within a high-fidelity physical simulation environment, it accurately replicates UAV flight dynamics and physics. The benchmark requires a drone to traverse a race track composed of sequential gates, receiving a first-person view (FPV) image and task-specific instructions at each stage. The core objective is to select the correct gate by solving an embedded cognitive task, generating a 4D action command. The tasks are categorized into three types: Human Recognition, Symbol Understanding, and Reasoning, providing a comprehensive and objective measure of VLA model performance under realistic UAV operating conditions. The evaluation framework allows comparisons of VLA performance.
Reasoning Augment#
The paper highlights the critical importance of integrating advanced reasoning capabilities into VLA models for UAVs. The CognitiveDrone-R1 model, which incorporates a VLM reasoning module, demonstrates significant performance improvements compared to the base CognitiveDrone model and RaceVLA. The reasoning module enhances task comprehension and decision-making, leading to higher success rates in complex cognitive tasks. The VLM aids in disambiguating task instructions and simplifying directives for the VLA model. This is crucial for UAVs operating in dynamic environments where they need to adapt to unpredictable scenarios and resolve ambiguities in task instructions. The evaluation results show that the reasoning module improves performance across various cognitive categories, including reasoning, human recognition, and symbol understanding. This underscores the effectiveness of incorporating advanced reasoning capabilities into VLA models for UAVs, enabling them to perform more robustly and effectively in complex cognitive tasks.
More visual insights#
More on figures

🔼 This figure illustrates the architecture of the CognitiveDrone system, which uses a combination of visual and textual inputs to generate smooth 4D control commands for UAVs. The system consists of two main modules: a high-frequency Vision-Language-Action (VLA) model for real-time control and a low-frequency Vision-Language Model (VLM) reasoning module for higher-level task understanding and simplification. The VLA model processes first-person view (FPV) images and refined textual instructions from the VLM, generating the drone’s actions. The VLM module, using Qwen2.5-VL, receives the original user instructions and FPV images and processes them to produce clarified instructions for the VLA model. The system architecture includes various components, such as image and text tokenizers, action de-tokenizers, and an autopilot SITL (Software-In-The-Loop) simulation running in Gazebo.
read the caption
Figure 2: CognitiveDrone system architecture.

🔼 This figure displays example tasks from the CognitiveDrone dataset designed to evaluate a Vision-Language-Action (VLA) model’s cognitive abilities in a UAV context. Each example shows a textual instruction given to the UAV (e.g., ‘Fly through the gate with cat’), a corresponding image from the UAV’s perspective, and the correct solution for the UAV to execute (navigating to a specific gate). The tasks test different cognitive skills, including human recognition, symbol understanding, and reasoning. The examples showcase the diversity of the dataset used to train and evaluate the CognitiveDrone model.
read the caption
Figure 3: Examples of prepared dataset tasks for VLA to solve cognitive tasks adapted for UAVs.

🔼 Figure 4 presents a detailed performance analysis of the model training process. It consists of three sub-figures: (a) shows the L1 loss, representing the absolute difference between the predicted and actual values, indicating the magnitude of prediction errors. (b) displays the action accuracy, which is the percentage of correctly predicted actions, providing a direct measure of the model’s effectiveness. (c) illustrates the cross-entropy loss, measuring the performance based on how well the predicted action probabilities align with the actual actions, giving insights into the model’s confidence in its predictions. This three-part visualization offers a comprehensive view of the model’s training progress and overall performance.
read the caption
Figure 4: Metrics Overview: (a) L1 loss indicates absolute prediction errors. (b) Action accuracy quantifies the percentage of correct predictions. (c) Cross-entropy loss measures performance on discretized action tokens.

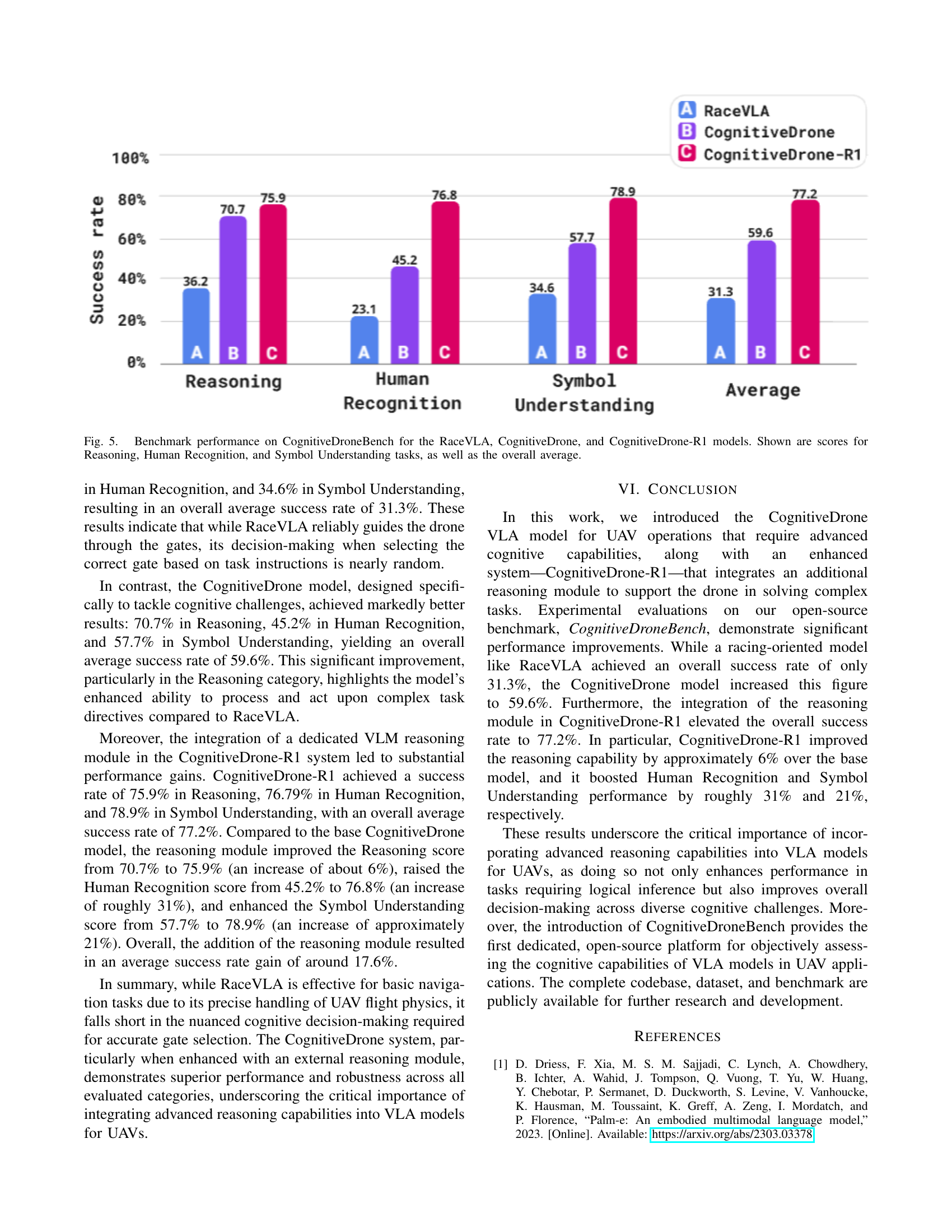
🔼 Figure 5 presents a bar chart comparing the performance of three different models—RaceVLA, CognitiveDrone, and CognitiveDrone-R1—on the CognitiveDroneBench benchmark. The benchmark evaluates the models’ abilities across three cognitive task categories: Reasoning, Human Recognition, and Symbol Understanding. The chart displays the success rate (percentage) achieved by each model in each category and provides an overall average success rate. This allows for a direct comparison of the models’ strengths and weaknesses in handling different types of cognitive tasks and helps quantify the impact of integrating a reasoning module (as in CognitiveDrone-R1) on overall performance.
read the caption
Figure 5: Benchmark performance on CognitiveDroneBench for the RaceVLA, CognitiveDrone, and CognitiveDrone-R1 models. Shown are scores for Reasoning, Human Recognition, and Symbol Understanding tasks, as well as the overall average.
Full paper#