TL;DR#
Advanced Language Models are distilled into smaller ones via instruction-following, selecting subsets for model training. Existing strategies often fail to capture instruction-following complexities. Therefore, diverse signals are needed to capture instruction-response characteristics, using Multi-LLM wisdom to understand diverse responses and reward model assessments.
To address these issues, CROWDSELECT, an integrated metric with clustering, maintains response diversity. Results showed improvements, achieving state-of-the-art performance in Full and LoRA fine-tuning. It improves Arena-Hard by 4.81% and MT-bench by 11.1% with Llama-3.2-3b-instruct, bringing new insights.
Key Takeaways#
Why does it matter?#
CROWDSELECT offers a novel method that significantly improves instruction tuning by leveraging multi-dimensional signals from multiple LLMs. It sets a new benchmark for efficiency and performance, guiding future research and applications in data selection and model distillation.
Visual Insights#

🔼 This figure illustrates the process of instruction tuning using a subset of synthetic instruction-response pairs. It begins with an original dataset of instruction-response pairs. These pairs are then evaluated using various metrics (represented by the ‘Our Metrics’ block), which assess the quality and diversity of each pair. Based on these metrics, a subset of high-quality pairs is selected. This selected dataset is then used in an efficient instruction tuning process (indicated by the ‘Efficient Instruction Tuning’ block) to train or fine-tune a smaller language model. The final output of this process is a more efficient model with improved instruction-following capabilities.
read the caption
Figure 1: A demonstration of instruction tuning with selected synthetic instruction-response pairs.
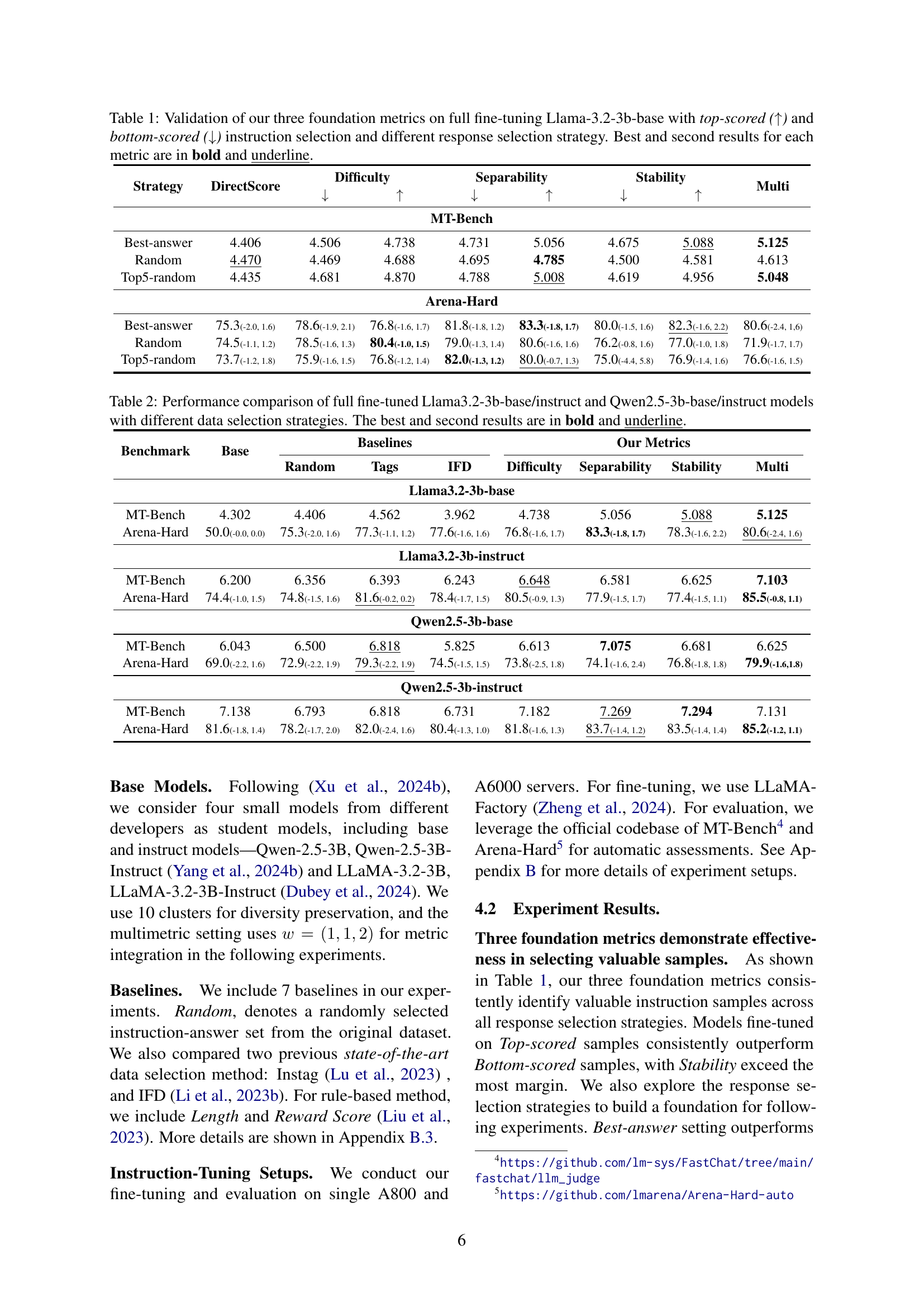
| Strategy | DirectScore | Difficulty | Separability | Stability | Multi | |||
| MT-Bench | ||||||||
| Best-answer | 4.406 | 4.506 | 4.738 | 4.731 | 5.056 | 4.675 | 5.088 | 5.125 |
| Random | 4.470 | 4.469 | 4.688 | 4.695 | 4.785 | 4.500 | 4.581 | 4.613 |
| Top5-random | 4.435 | 4.681 | 4.870 | 4.788 | 5.008 | 4.619 | 4.956 | 5.048 |
| Arena-Hard | ||||||||
| Best-answer | 75.3(-2.0, 1.6) | 78.6(-1.9, 2.1) | 76.8(-1.6, 1.7) | 81.8(-1.8, 1.2) | 83.3(-1.8, 1.7) | 80.0(-1.5, 1.6) | 82.3(-1.6, 2.2) | 80.6(-2.4, 1,6) |
| Random | 74.5(-1.1, 1.2) | 78.5(-1.6, 1.3) | 80.4(-1.0, 1.5) | 79.0(-1.3, 1.4) | 80.6(-1.6, 1.6) | 76.2(-0.8, 1.6) | 77.0(-1.0, 1.8) | 71.9(-1.7, 1.7) |
| Top5-random | 73.7(-1.2, 1.8) | 75.9(-1.6, 1.5) | 76.8(-1.2, 1.4) | 82.0(-1.3, 1.2) | 80.0(-0.7, 1.3) | 75.0(-4.4, 5.8) | 76.9(-1.4, 1.6) | 76.6(-1.6, 1.5) |
🔼 This table presents the results of an experiment designed to validate three foundation metrics for instruction data selection. The experiment uses the Llama-3.2-3b-base model and evaluates the performance of selecting instructions based on the top and bottom scores using each of the three metrics. The evaluation is performed using two different response selection strategies, ‘Best-answer’ and ‘Random’. For each metric and strategy, the top two performing results are highlighted in bold and underlined, indicating the effectiveness of each metric in identifying valuable instructions.
read the caption
Table 1: Validation of our three foundation metrics on full fine-tuning Llama-3.2-3b-base with top-scored (↑↑\uparrow↑) and bottom-scored (↓↓\downarrow↓) instruction selection and different response selection strategy. Best and second results for each metric are in bold and underline.
In-depth insights#
Multi-LLM Wisdom#
Multi-LLM Wisdom is a compelling paradigm for enhancing instruction tuning. The core idea is to leverage the diverse perspectives and capabilities of multiple LLMs, rather than relying on a single model, to create more robust and generalizable instruction data. This is valuable as individual LLMs have limitations in knowledge, skills, and perspectives. By aggregating responses from multiple LLMs, we capture a more comprehensive representation of the data, leading to improved model alignment and performance. Also, this addresses challenges in real-world scenarios. The offline approach contrasts with online methods, pre-collecting data for efficiency. The data involves the LLMs’ responses and rewards which are measured by difficulty and quality.
Metrics for Tuning#
Metrics are crucial for effective tuning, guiding the optimization process. Difficulty metrics identify challenging prompts, ensuring models learn complex concepts. Separability metrics highlight instructions that differentiate model capabilities, useful for fine-grained control. Stability metrics ensure consistent performance aligned with model size, preventing overfitting. Integrating these metrics provides a comprehensive approach to data selection and tuning. By leveraging diverse signals, models can capture nuanced instruction-following abilities.
CROWDSELECT Perf.#
From the paper, CROWDSELECT exhibits state-of-the-art performance across various models and benchmarks. This suggests it effectively leverages multi-LLM wisdom for instruction data selection. The integrated metric combines difficulty, separability, and stability signals. Results on FFT and LoRA fine-tuning highlight CROWDSELECT’s robustness. CROWDSELECT achieves significant improvements on Arena-Hard and MT-bench with Llama-3.2-3b-instruct, surpassing previous baselines. This indicates the approach enhances model instruction-following capabilities. Also, the diversity preservation strategy through clustering contributes to better generalization. This helps CROWDSELECT identify impactful subsets. Results show it performs robustly on tuning methods. It also shows consistent performance across different reward models.
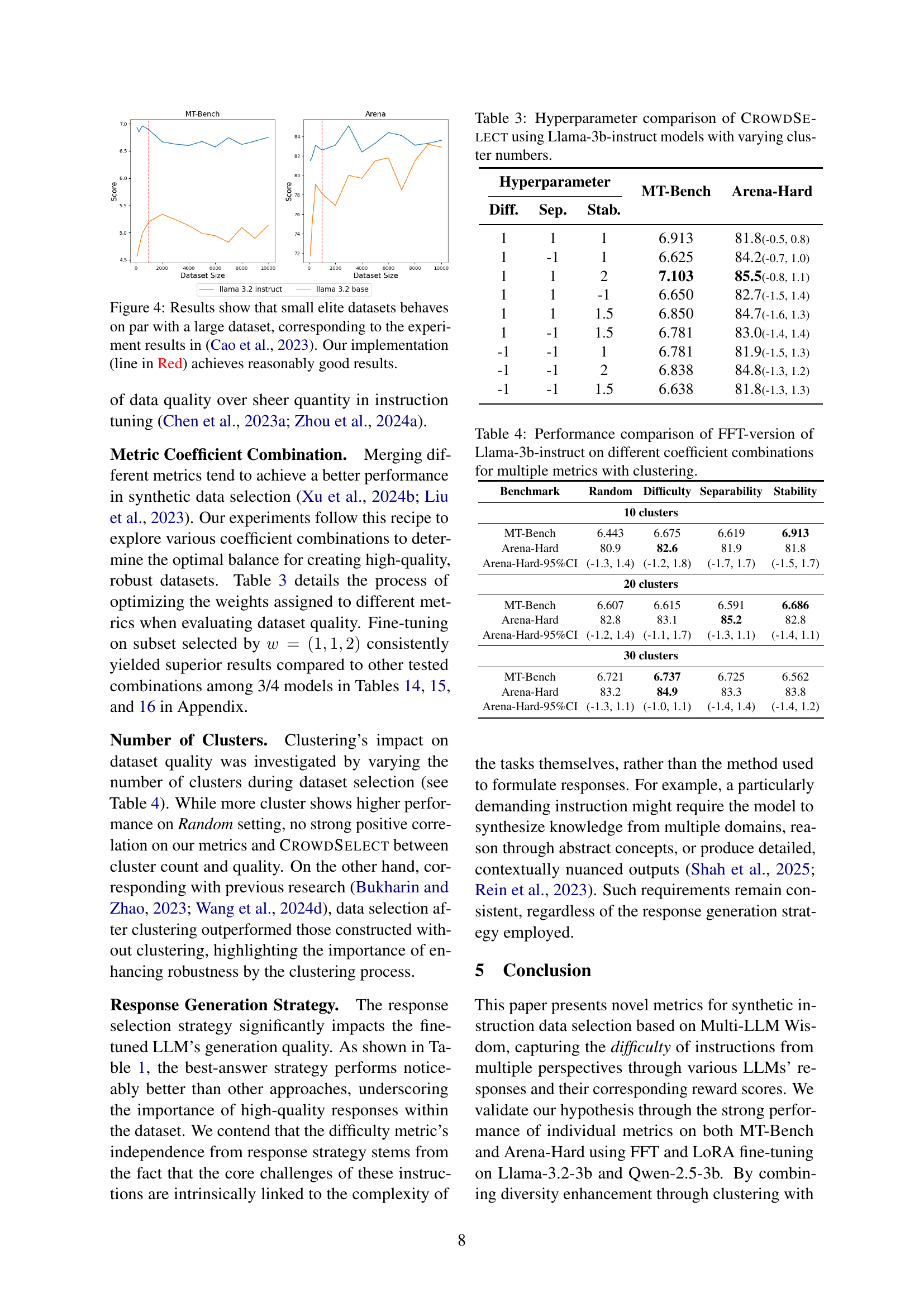
Data Size Impact#
The data size impact on instruction tuning underscores a critical trade-off. Smaller, high-quality datasets can outperform larger, less curated ones, highlighting that the selection process is crucial for efficient learning, thus ensuring the fine-tuned dataset maximizes exposure to difficult material, boosting model’s potential for great improvements. This indicates that focusing efforts on refining the dataset’s content, diversity, and relevance is superior to simply scaling up the quantity, because high-quality datasets perform on par with larger datasets, thus underscoring data quality over quantity in instruction tuning. Hence, carefully selected, concise subsets can often yield competitive, if not superior, results.
Robust SFT Needed#
Robust Supervised Fine-Tuning (SFT) is crucial for aligning Large Language Models (LLMs) with desired behaviors, ensuring reliable and consistent performance. The need for robust SFT stems from the inherent variability in LLM outputs and the potential for models to deviate from intended responses. A well-executed SFT process enhances an LLM’s ability to generalize effectively, even in novel situations, leading to improved reliability in real-world applications. Moreover, robust SFT helps mitigate the propagation of biases and harmful content, promoting safer and more ethical outcomes. High-quality, diverse training data is essential for achieving robustness, as is careful monitoring and iterative refinement of the SFT process. The benefits are far-reaching, including increased user trust, reduced risk of unintended consequences, and enhanced applicability across diverse domains.
More visual insights#
More on figures

🔼 The figure illustrates the CrowdSelect framework’s pipeline. It begins with the collection of synthetic instruction data using multiple large language models (LLMs), generating diverse responses for each instruction. These responses, along with their corresponding reward model scores, provide multiple facets of each instruction. CrowdSelect uses these facets to calculate three core metrics: Difficulty, Separability, and Stability. A clustering algorithm then groups instructions to ensure diversity. The combined metrics and clusters inform the selection of an optimal instruction subset. This refined dataset is then used for efficient instruction tuning with either full fine-tuning (FFT) or low-rank adaptation (LoRA). The effectiveness of the chosen subset is subsequently evaluated using established benchmarks.
read the caption
Figure 2: The overall pipeline of our CrowdSelect, which innovatively leverages metrics calculated from multiple facets of instructions using pre-collected synthesized responses from various LLMs and their corresponding reward model scores. We enhance data selection through clustering for diversity and metric combination to explore the method’s potential. Finally, we evaluate the effectiveness of our selected instruction subset through FFT or LoRA fine-tuning (Hu et al., 2021) for efficient instruction tuning.

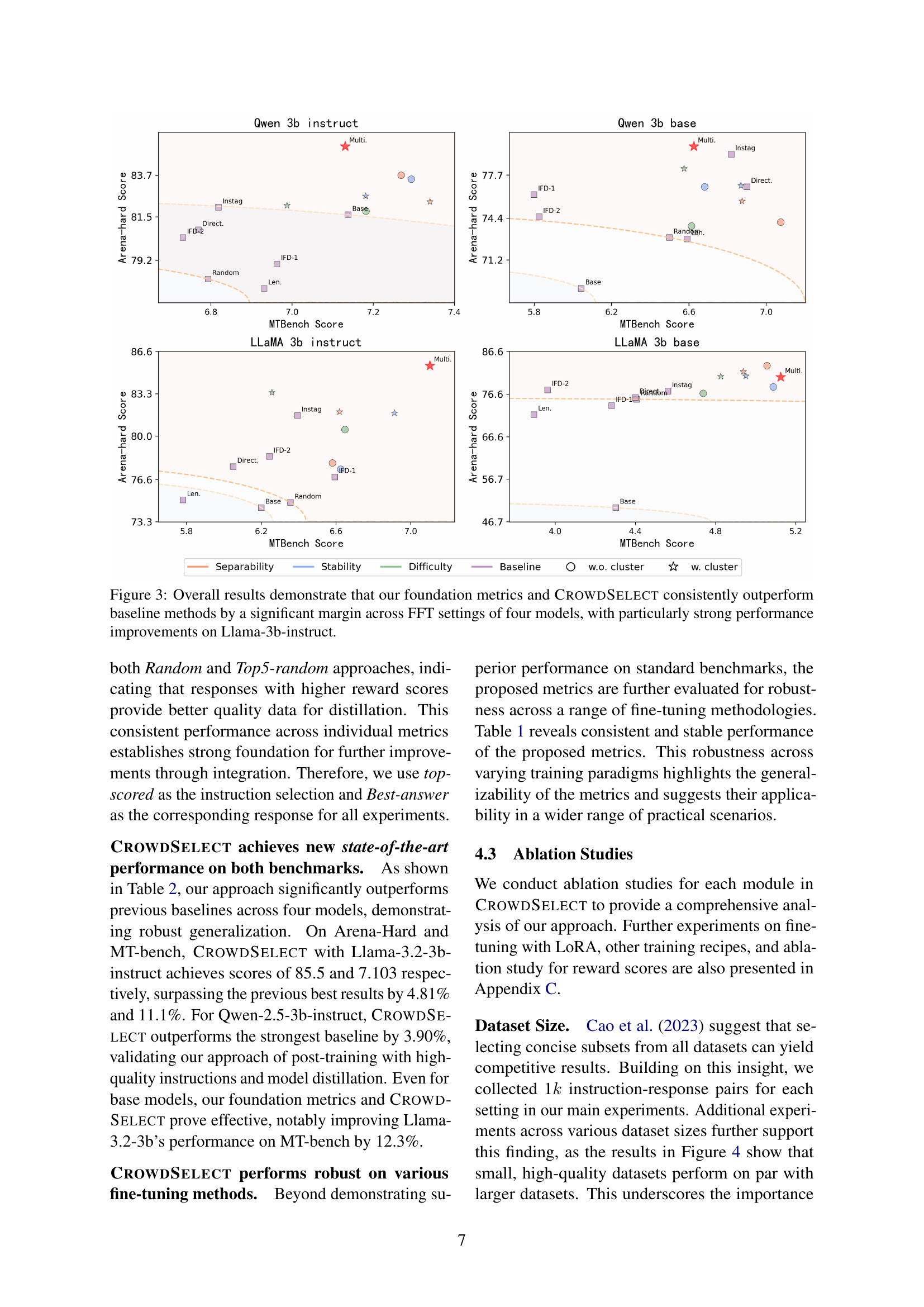
🔼 Figure 3 presents a comparative analysis of the performance of various instruction data selection methods, including the proposed CROWDSELECT framework and several baseline methods. The results are shown across four different base models (LLaMA-3.2-3b-base, LLaMA-3.2-3b-instruct, Qwen-2.5-3b-base, Qwen-2.5-3b-instruct) under full fine-tuning (FFT) settings. The performance is measured using two key metrics: MT-bench and Arena-Hard scores. The figure clearly demonstrates that CROWDSELECT and its underlying foundation metrics consistently outperform the baseline methods, with particularly significant performance improvements observed for the Llama-3b-instruct model.
read the caption
Figure 3: Overall results demonstrate that our foundation metrics and CrowdSelect consistently outperform baseline methods by a significant margin across FFT settings of four models, with particularly strong performance improvements on Llama-3b-instruct.

🔼 Figure 4 illustrates the finding that utilizing a small subset of high-quality data yields comparable performance to using a much larger dataset for instruction tuning. This aligns with the findings presented in Cao et al. (2023). The graph displays the performance (MT-Bench and Arena-Hard scores) of models trained on datasets of varying sizes. The red line represents the performance achieved by the authors’ CROWDSELECT method, demonstrating its effectiveness in selecting a small yet highly effective dataset.
read the caption
Figure 4: Results show that small elite datasets behaves on par with a large dataset, corresponding to the experiment results in (Cao et al., 2023). Our implementation (line in Red) achieves reasonably good results.

🔼 This figure shows an example of an instruction-response pair selected by the CROWDSELECT method. The instruction asks for five different methods to generate electricity, excluding common methods and those using rotating generators or turbines. The response provides five distinct methods, including photovoltaic cells, fuel cells, silicone-based piezoelectric generators, ceramic capacitor discharge devices, and photo electrochemical cells, along with explanations of how they work. This example demonstrates the method’s ability to select high-quality, diverse, and informative instruction-response pairs for effective instruction tuning.
read the caption
Figure 5: Example of our selected instruction and correspond answer.

🔼 The figure shows the training loss curves for the Llama-3b model when trained using different sizes of randomly selected datasets. The x-axis represents the training step, while the y-axis shows the training loss. Multiple lines are plotted, each representing a different dataset size (0.25k, 0.5k, 1k, 2k, 3k, 4k, 5k, 6k, 7k, 8k, 9k, 10k). For each dataset size, two curves are shown: one for the original training loss and another for a smoothed version of the training loss. The smoothed curve is used to visualize the overall trend of the training loss while reducing the influence of noise and minor fluctuations.
read the caption
0.25k𝑘kitalic_k

🔼 The figure shows the LORA training loss for Llama-3b model when training with different sizes of randomly chosen data. The x-axis represents the training step, and the y-axis represents the training loss. Multiple lines are plotted, each representing a different dataset size (0.25k, 0.5k, 1k, 2k, 3k, 4k, 5k, 6k, 7k, 8k, 9k, and 10k). For each dataset size, two lines are shown: one for the original loss values and another smoothed line to better visualize the overall trend. The figure is used to show how data quantity impacts the training process and loss.
read the caption
0.5k𝑘kitalic_k

🔼 This figure visualizes the overall pipeline of the CROWDSELECT framework. It starts with synthetic instruction data collection using multiple LLMs and their reward model scores. These diverse signals are then used to calculate three base metrics: Difficulty, Separability, and Stability. These metrics help determine the quality of instruction-response pairs. The framework then employs a clustering-based approach to enhance response diversity and combines the three metrics into a single integrated metric. Finally, the pipeline selects a subset of high-quality instruction-response pairs, which are then used for efficient instruction tuning in the downstream tasks. The figure also shows a comparison of performance on two benchmarks (MT-Bench and Arena-Hard) between CROWDSELECT and several baseline methods.
read the caption
1k𝑘kitalic_k

🔼 The figure displays the training loss curves for the Llama-3b model during LoRA fine-tuning. Different curves represent various sizes of training datasets, all selected using a method that prioritizes data quality over quantity. The x-axis represents the training step, and the y-axis shows the training loss. The curves illustrate how training loss decreases as the model learns, and the impact of the dataset size on this learning process. Smoother curves are also shown to provide a clearer visualization of trends in the loss data.
read the caption
2k𝑘kitalic_k

🔼 The figure illustrates the overall pipeline of the CROWDSELECT framework. It starts with synthetic instruction data collection, utilizing multiple LLMs and reward models to generate diverse responses and scores. These responses and scores are then used to calculate three foundational metrics: Difficulty, Separability, and Stability. These metrics are used to select a subset of high-quality instruction-response pairs through a metric-based selection process incorporating a clustering-based approach for diversity. Finally, the selected dataset is evaluated using full fine-tuning or LoRA fine-tuning on benchmark datasets (MT-bench and Arena-Hard).
read the caption
3k𝑘kitalic_k

🔼 This figure shows the overall pipeline of the CROWDSELECT method. It starts with synthetic instruction data collection, using multiple LLMs and reward models to generate a large number of instruction-response pairs. Then, the method calculates three core metrics: Difficulty, Separability, and Stability. These metrics assess various aspects of instruction-response pairs. Finally, a metric-based data selection is performed using a clustering-based approach to select a smaller, more effective subset of the data for instruction tuning. The selected dataset is then used for efficient instruction tuning, which is further evaluated using automated benchmark validation.
read the caption
4k𝑘kitalic_k

🔼 This figure shows the results of using different dataset sizes for fine-tuning Llama-3b using LoRA. The x-axis represents the training step, while the y-axis shows the training loss. Multiple lines are plotted, each corresponding to a different dataset size (0.25k, 0.5k, 1k, 2k, 3k, 4k, 5k, 6k, 7k, 8k, 9k, 10k). Each line displays both the original training loss and a smoothed version of the loss for better visualization. This visualization helps understand how dataset size influences the training process and the resulting model’s performance.
read the caption
5k𝑘kitalic_k

🔼 The figure shows the LORA training loss for the Llama-3b model using different sizes of randomly chosen data. The x-axis represents the training step, and the y-axis represents the loss. Multiple lines are plotted, each corresponding to a different dataset size. The lines show how the loss changes over the training process for different dataset sizes, illustrating the effect of dataset size on model training.
read the caption
6k𝑘kitalic_k

🔼 This figure visualizes the training loss curves of the Llama-3b model during fine-tuning using different sizes of instruction datasets chosen randomly. The x-axis represents the training steps, and the y-axis shows the training loss. Multiple lines are presented, each corresponding to a different dataset size (0.25k, 0.5k, 1k, 2k, 3k, 4k, 5k, 6k, 7k, 8k, 9k, 10k). Each line may also include two variations: the original training loss and a smoothed version of the loss, providing a clearer trend visualization. The figure aims to illustrate the impact of dataset size on the model’s training efficiency and convergence.
read the caption
7k𝑘kitalic_k

🔼 This figure shows the training loss curves for the Llama-3b model using different sizes of randomly selected data. The x-axis represents the training step, and the y-axis represents the training loss. Multiple lines are shown, each corresponding to a different dataset size (e.g., 0.25k, 0.5k, 1k, etc.). The purpose of the figure is to illustrate how the size of the dataset impacts the training loss, and potentially the model’s performance. The smoothed curves likely represent the application of a smoothing technique (like moving average) to the raw training loss data. This smoothing helps to visualize trends more clearly by reducing the effect of noise or short-term fluctuations.
read the caption
8k𝑘kitalic_k

🔼 This figure visualizes the performance of CROWDSELECT on various fine-tuning methods across four different models. It shows the Arena-Hard and MT-bench scores for Llama 3B base/instruct and Qwen 3B base/instruct, illustrating the consistent outperformance of CROWDSELECT compared to baseline methods such as Random, Direct, Instag, IFD, and Length. The chart highlights the substantial performance improvements achieved by CROWDSELECT, especially on Llama 3B instruct. The y-axis represents the Arena-Hard score and the x-axis represents the MT-bench score. Each point on the graph represents the performance of a model fine-tuned with a specific data selection strategy.
read the caption
9k𝑘kitalic_k
More on tables
| Benchmark | Base | Baselines | Our Metrics | |||||
| Random | Tags | IFD | Difficulty | Separability | Stability | Multi | ||
| Llama3.2-3b-base | ||||||||
| MT-Bench | 4.302 | 4.406 | 4.562 | 3.962 | 4.738 | 5.056 | 5.088 | 5.125 |
| Arena-Hard | 50.0(-0.0, 0.0) | 75.3(-2.0, 1.6) | 77.3(-1.1, 1.2) | 77.6(-1.6, 1.6) | 76.8(-1.6, 1.7) | 83.3(-1.8, 1.7) | 78.3(-1.6, 2.2) | 80.6(-2.4, 1.6) |
| Llama3.2-3b-instruct | ||||||||
| MT-Bench | 6.200 | 6.356 | 6.393 | 6.243 | 6.648 | 6.581 | 6.625 | 7.103 |
| Arena-Hard | 74.4(-1.0, 1.5) | 74.8(-1.5, 1.6) | 81.6(-0.2, 0.2) | 78.4(-1.7, 1.5) | 80.5(-0.9, 1.3) | 77.9(-1.5, 1.7) | 77.4(-1.5, 1.1) | 85.5(-0.8, 1.1) |
| Qwen2.5-3b-base | ||||||||
| MT-Bench | 6.043 | 6.500 | 6.818 | 5.825 | 6.613 | 7.075 | 6.681 | 6.625 |
| Arena-Hard | 69.0(-2.2, 1.6) | 72.9(-2.2, 1.9) | 79.3(-2.2, 1.9) | 74.5(-1.5, 1.5) | 73.8(-2.5, 1.8) | 74.1(-1.6, 2.4) | 76.8(-1.8, 1.8) | 79.9(-1.6,1.8) |
| Qwen2.5-3b-instruct | ||||||||
| MT-Bench | 7.138 | 6.793 | 6.818 | 6.731 | 7.182 | 7.269 | 7.294 | 7.131 |
| Arena-Hard | 81.6(-1.8, 1.4) | 78.2(-1.7, 2.0) | 82.0(-2.4, 1.6) | 80.4(-1.3, 1.0) | 81.8(-1.6, 1.3) | 83.7(-1.4, 1.2) | 83.5(-1.4, 1.4) | 85.2(-1.2, 1.1) |
🔼 This table presents a performance comparison between two foundational language models, Llama-3.2-3b-base/instruct and Qwen-2.5-3b-base/instruct, after fine-tuning using different data selection strategies. The models are evaluated on two benchmarks: MT-Bench and Arena-Hard. The results show the scores achieved by each model with various instruction data selection methods, including baseline methods (Base, Random, Tags, IFD) and the proposed methods (Difficulty, Separability, Stability, and Multi). The best and second-best performances for each model and metric are highlighted for easy comparison. This allows for assessment of the effectiveness of different data selection strategies on the overall performance of the language models.
read the caption
Table 2: Performance comparison of full fine-tuned Llama3.2-3b-base/instruct and Qwen2.5-3b-base/instruct models with different data selection strategies. The best and second results are in bold and underline.
| Hyperparameter | MT-Bench | Arena-Hard | ||
| Diff. | Sep. | Stab. | ||
| 1 | 1 | 1 | 6.913 | 81.8(-0.5, 0.8) |
| 1 | -1 | 1 | 6.625 | 84.2(-0.7, 1.0) |
| 1 | 1 | 2 | 7.103 | 85.5(-0.8, 1.1) |
| 1 | 1 | -1 | 6.650 | 82.7(-1.5, 1.4) |
| 1 | 1 | 1.5 | 6.850 | 84.7(-1.6, 1.3) |
| 1 | -1 | 1.5 | 6.781 | 83.0(-1.4, 1.4) |
| -1 | -1 | 1 | 6.781 | 81.9(-1.5, 1.3) |
| -1 | -1 | 2 | 6.838 | 84.8(-1.3, 1.2) |
| -1 | -1 | 1.5 | 6.638 | 81.8(-1.3, 1.3) |
🔼 This table presents the results of experiments conducted to determine the optimal hyperparameters for the CrowdSelect model, specifically focusing on the impact of varying cluster numbers. The experiments were performed using the Llama-3b-instruct model, and the table shows the performance metrics (MT-Bench and Arena-Hard scores) obtained with different combinations of hyperparameters. It helps determine the best number of clusters to use for optimal performance and balance between model robustness and efficiency.
read the caption
Table 3: Hyperparameter comparison of CrowdSelect using Llama-3b-instruct models with varying cluster numbers.
| Benchmark | Random | Difficulty | Separability | Stability |
| 10 clusters | ||||
| MT-Bench | 6.443 | 6.675 | 6.619 | 6.913 |
| Arena-Hard | 80.9 | 82.6 | 81.9 | 81.8 |
| Arena-Hard-95%CI | (-1.3, 1.4) | (-1.2, 1.8) | (-1.7, 1.7) | (-1.5, 1.7) |
| 20 clusters | ||||
| MT-Bench | 6.607 | 6.615 | 6.591 | 6.686 |
| Arena-Hard | 82.8 | 83.1 | 85.2 | 82.8 |
| Arena-Hard-95%CI | (-1.2, 1.4) | (-1.1, 1.7) | (-1.3, 1.1) | (-1.4, 1.1) |
| 30 clusters | ||||
| MT-Bench | 6.721 | 6.737 | 6.725 | 6.562 |
| Arena-Hard | 83.2 | 84.9 | 83.3 | 83.8 |
| Arena-Hard-95%CI | (-1.3, 1.1) | (-1.0, 1.1) | (-1.4, 1.4) | (-1.4, 1.2) |
🔼 This table presents a detailed analysis of the performance of the Llama-3b-instruct model when fine-tuned using different combinations of weights assigned to three key metrics (Difficulty, Separability, Stability) within the CROWDSELECT framework. The experiments incorporate a clustering strategy to ensure diversity in the selected instruction-response pairs. The results show the impact of various weight combinations on the final model’s performance, as measured by two benchmarks: MT-bench and Arena-Hard. This allows researchers to understand how the balance between these metrics affects the effectiveness of the data selection process. The table includes for each combination the training loss, evaluation loss, and resulting scores on both benchmarks.
read the caption
Table 4: Performance comparison of FFT-version of Llama-3b-instruct on different coefficient combinations for multiple metrics with clustering.
| Model Family | Release Date | Model ID | Size |
| Qwen2-1.5B-Instruct | 1.5B | ||
| Qwen2 | Jun, 2024 | Qwen2-7B-Instruct | 7B |
| (Yang et al., 2024a) | Qwen2-72B-Instruct | 72B | |
| Qwen2.5-3B | 3B | ||
| Qwen2.5-3B-Instruct | 3B | ||
| Qwen2.5 | Qwen2.5-7B-Instruct | 7B | |
| (Yang et al., 2024b) | Sept, 2024 | Qwen2.5-14B-Instruct | 14B |
| Qwen2.5-32B-Instruct | 32B | ||
| Qwen2.5-72B-Instruct | 72B | ||
| Llama 3 | Apr, 2024 | Llama-3-8B-Instruct | 8B |
| (Dubey et al., 2024) | Llama-3-70B-Instruct | 70B | |
| Llama-3.1-8B-Instruct | 8B | ||
| Llama 3.1 | Jul, 2024 | Llama-3.1-70B-Instruct | 70B |
| (Dubey et al., 2024) | Llama-3.1-405B-Instruct | 405B | |
| Llama 3.2 | Jul, 2024 | Llama-3.2-3B | 3B |
| (Dubey et al., 2024) | Llama-3.2-3B-Instruct | 3B | |
| Gemma-2-2B-it | 2B | ||
| Gemma 2 | Jun, 2024 | Gemma-2-9B-it | 9B |
| (Team et al., 2024) | Gemma-2-27B-it | 27B | |
| Phi-3-mini-128k-instruct | 3.5B | ||
| Phi-3 | Jun, 2024 | Phi-3-small-128k-instruct | 7B |
| (Abdin et al., 2024) | Phi-3-medium-128k-instruct | 14B |
🔼 This table lists the 22 large language models (LLMs) used in the study, categorized by their model family, release date, model ID, and size (in terms of parameters). It provides a comprehensive overview of the models used for instruction tuning and evaluation, allowing for a clear understanding of the diversity and scale of the models employed in the experiments.
read the caption
Table 5: Overview of 22 models used in our study.
| Hyper-parameter | Value |
| Learning Rate | |
| Number of Epochs | 3 |
| Per-device Batch Size | 1 |
| Gradient Accumulation Steps | 2 |
| Optimizer | Adamw |
| Learning Rate Scheduler | cosine |
| Warmup Steps | 150 |
| Max Sequence Length | 2048 |
🔼 This table details the hyperparameters used in the supervised fine-tuning process of the models. It includes settings for the learning rate, number of epochs, batch size, gradient accumulation steps, optimizer, learning rate scheduler, warmup steps, and maximum sequence length.
read the caption
Table 6: This table includes the hyper-parameters for supervised fine-tuning.
| Data Size | Train Loss | Eval. Loss | MT-Bench | Arena-Hard | |||
| Score | Avg. Tokens | Score | 95% CI | Avg. Tokens | |||
| 0.25 | 0.418 | 0.951 | 6.850 | 301 | 81.9 | 275 | |
| 0.5 | 0.406 | 1.004 | 6.962 | 276 | 83.1 | 275 | |
| 1 | 0.407 | 0.942 | 6.887 | 271 | 82.6 | 273 | |
| 2 | 0.405 | 0.929 | 6.668 | 301 | 83.1 | 273 | |
| 3 | 0.415 | 0.871 | 6.625 | 304 | 85.1 | 276 | |
| 4 | 0.413 | 0.869 | 6.600 | 279 | 82.4 | 268 | |
| 5 | 0.415 | 0.867 | 6.675 | 295 | 83.3 | 272 | |
| 6 | 0.414 | 0.857 | 6.572 | 282 | 84.4 | 265 | |
| 7 | 0.413 | 0.848 | 6.743 | 286 | 84.1 | 266 | |
| 8 | 0.411 | 0.836 | 6.618 | 275 | 83.1 | 268 | |
| 9 | 0.411 | 0.822 | 6.681 | 274 | 83.3 | 269 | |
| 10 | 0.409 | 0.828 | 6.750 | 279 | 83.6 | 266 | |
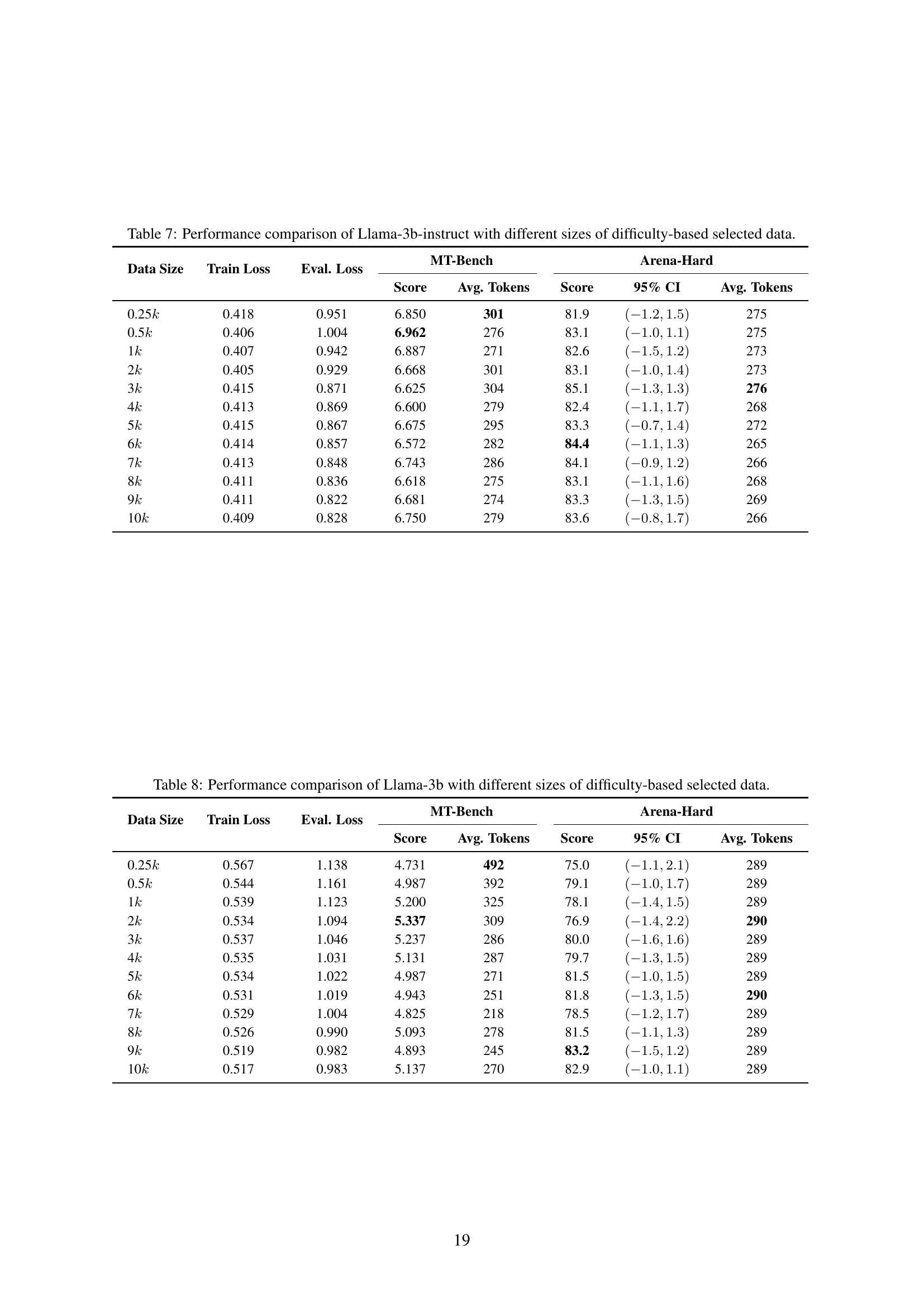
🔼 This table presents the performance of the Llama-3b-instruct model trained using different sizes of datasets. The datasets were selected based on the difficulty metric proposed in the paper. The results are shown for both the MT-Bench and Arena-Hard benchmarks. For each dataset size, the table displays the training loss, evaluation loss, average score, and average number of tokens used in the instruction-response pairs.
read the caption
Table 7: Performance comparison of Llama-3b-instruct with different sizes of difficulty-based selected data.
| Data Size | Train Loss | Eval. Loss | MT-Bench | Arena-Hard | |||
| Score | Avg. Tokens | Score | 95% CI | Avg. Tokens | |||
| 0.25 | 0.567 | 1.138 | 4.731 | 492 | 75.0 | 289 | |
| 0.5 | 0.544 | 1.161 | 4.987 | 392 | 79.1 | 289 | |
| 1 | 0.539 | 1.123 | 5.200 | 325 | 78.1 | 289 | |
| 2 | 0.534 | 1.094 | 5.337 | 309 | 76.9 | 290 | |
| 3 | 0.537 | 1.046 | 5.237 | 286 | 80.0 | 289 | |
| 4 | 0.535 | 1.031 | 5.131 | 287 | 79.7 | 289 | |
| 5 | 0.534 | 1.022 | 4.987 | 271 | 81.5 | 289 | |
| 6 | 0.531 | 1.019 | 4.943 | 251 | 81.8 | 290 | |
| 7 | 0.529 | 1.004 | 4.825 | 218 | 78.5 | 289 | |
| 8 | 0.526 | 0.990 | 5.093 | 278 | 81.5 | 289 | |
| 9 | 0.519 | 0.982 | 4.893 | 245 | 83.2 | 289 | |
| 10 | 0.517 | 0.983 | 5.137 | 270 | 82.9 | 289 | |
🔼 This table presents the performance of the Llama-3b base model fine-tuned using different sizes of datasets. The datasets were selected based on the difficulty metric, which identifies challenging instructions that are beneficial for model learning. The table shows the training loss, evaluation loss, MT-Bench score, average tokens, Arena-Hard score, and 95% confidence interval (CI) for each dataset size. This allows for the analysis of the impact of dataset size on the model’s performance, revealing the relationship between data quantity and quality in instruction tuning.
read the caption
Table 8: Performance comparison of Llama-3b with different sizes of difficulty-based selected data.
| Benchmark | Base | Difficulty | Separability | Stability | |||
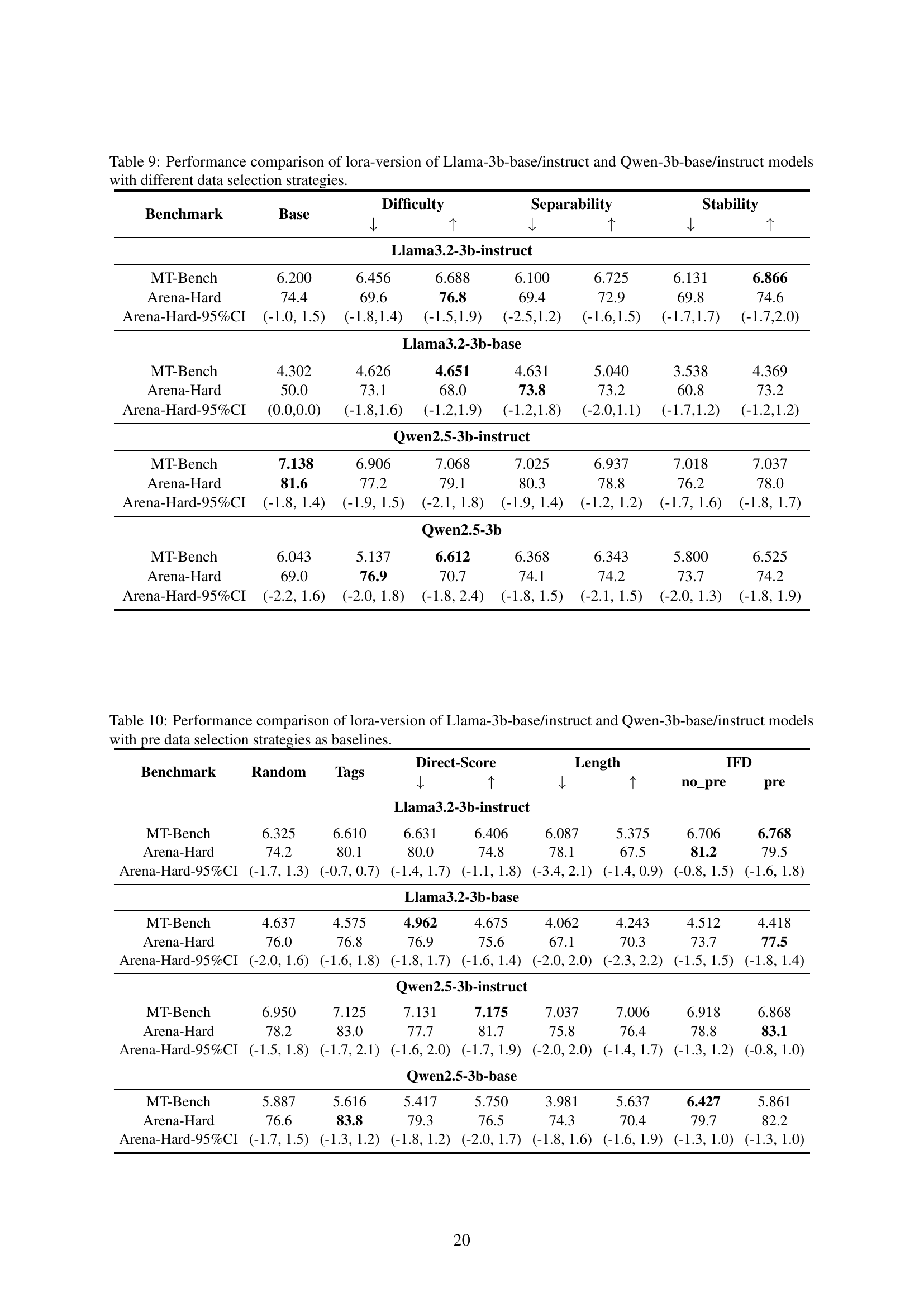
| Llama3.2-3b-instruct | |||||||
| MT-Bench | 6.200 | 6.456 | 6.688 | 6.100 | 6.725 | 6.131 | 6.866 |
| Arena-Hard | 74.4 | 69.6 | 76.8 | 69.4 | 72.9 | 69.8 | 74.6 |
| Arena-Hard-95%CI | (-1.0, 1.5) | (-1.8,1.4) | (-1.5,1.9) | (-2.5,1.2) | (-1.6,1.5) | (-1.7,1.7) | (-1.7,2.0) |
| Llama3.2-3b-base | |||||||
| MT-Bench | 4.302 | 4.626 | 4.651 | 4.631 | 5.040 | 3.538 | 4.369 |
| Arena-Hard | 50.0 | 73.1 | 68.0 | 73.8 | 73.2 | 60.8 | 73.2 |
| Arena-Hard-95%CI | (0.0,0.0) | (-1.8,1.6) | (-1.2,1.9) | (-1.2,1.8) | (-2.0,1.1) | (-1.7,1.2) | (-1.2,1.2) |
| Qwen2.5-3b-instruct | |||||||
| MT-Bench | 7.138 | 6.906 | 7.068 | 7.025 | 6.937 | 7.018 | 7.037 |
| Arena-Hard | 81.6 | 77.2 | 79.1 | 80.3 | 78.8 | 76.2 | 78.0 |
| Arena-Hard-95%CI | (-1.8, 1.4) | (-1.9, 1.5) | (-2.1, 1.8) | (-1.9, 1.4) | (-1.2, 1.2) | (-1.7, 1.6) | (-1.8, 1.7) |
| Qwen2.5-3b | |||||||
| MT-Bench | 6.043 | 5.137 | 6.612 | 6.368 | 6.343 | 5.800 | 6.525 |
| Arena-Hard | 69.0 | 76.9 | 70.7 | 74.1 | 74.2 | 73.7 | 74.2 |
| Arena-Hard-95%CI | (-2.2, 1.6) | (-2.0, 1.8) | (-1.8, 2.4) | (-1.8, 1.5) | (-2.1, 1.5) | (-2.0, 1.3) | (-1.8, 1.9) |
🔼 This table presents the performance comparison results of LoRA (Low-Rank Adaptation) fine-tuning on two different base models: Llama-3b-base/instruct and Qwen-3b-base/instruct. The models were fine-tuned using instruction data selected via various strategies. The table shows the performance of each model on two benchmarks, MT-Bench and Arena-Hard, broken down by different data selection methods (Difficulty, Separability, and Stability). The results highlight the impact of different instruction data selection methods on the model’s performance in both full and LoRA fine-tuning.
read the caption
Table 9: Performance comparison of lora-version of Llama-3b-base/instruct and Qwen-3b-base/instruct models with different data selection strategies.
| Benchmark | Random | Tags | Direct-Score | Length | IFD | |||
| no_pre | pre | |||||||
| Llama3.2-3b-instruct | ||||||||
| MT-Bench | 6.325 | 6.610 | 6.631 | 6.406 | 6.087 | 5.375 | 6.706 | 6.768 |
| Arena-Hard | 74.2 | 80.1 | 80.0 | 74.8 | 78.1 | 67.5 | 81.2 | 79.5 |
| Arena-Hard-95%CI | (-1.7, 1.3) | (-0.7, 0.7) | (-1.4, 1.7) | (-1.1, 1.8) | (-3.4, 2.1) | (-1.4, 0.9) | (-0.8, 1.5) | (-1.6, 1.8) |
| Llama3.2-3b-base | ||||||||
| MT-Bench | 4.637 | 4.575 | 4.962 | 4.675 | 4.062 | 4.243 | 4.512 | 4.418 |
| Arena-Hard | 76.0 | 76.8 | 76.9 | 75.6 | 67.1 | 70.3 | 73.7 | 77.5 |
| Arena-Hard-95%CI | (-2.0, 1.6) | (-1.6, 1.8) | (-1.8, 1.7) | (-1.6, 1.4) | (-2.0, 2.0) | (-2.3, 2.2) | (-1.5, 1.5) | (-1.8, 1.4) |
| Qwen2.5-3b-instruct | ||||||||
| MT-Bench | 6.950 | 7.125 | 7.131 | 7.175 | 7.037 | 7.006 | 6.918 | 6.868 |
| Arena-Hard | 78.2 | 83.0 | 77.7 | 81.7 | 75.8 | 76.4 | 78.8 | 83.1 |
| Arena-Hard-95%CI | (-1.5, 1.8) | (-1.7, 2.1) | (-1.6, 2.0) | (-1.7, 1.9) | (-2.0, 2.0) | (-1.4, 1.7) | (-1.3, 1.2) | (-0.8, 1.0) |
| Qwen2.5-3b-base | ||||||||
| MT-Bench | 5.887 | 5.616 | 5.417 | 5.750 | 3.981 | 5.637 | 6.427 | 5.861 |
| Arena-Hard | 76.6 | 83.8 | 79.3 | 76.5 | 74.3 | 70.4 | 79.7 | 82.2 |
| Arena-Hard-95%CI | (-1.7, 1.5) | (-1.3, 1.2) | (-1.8, 1.2) | (-2.0, 1.7) | (-1.8, 1.6) | (-1.6, 1.9) | (-1.3, 1.0) | (-1.3, 1.0) |
🔼 This table presents a performance comparison between LoRA (Low-Rank Adaptation) fine-tuned Llama-3b-base/instruct and Qwen-3b-base/instruct models. The performance is evaluated using two benchmarks, MT-Bench and Arena-Hard. Different data selection strategies are compared as baselines, including Random selection, Tags, Direct-Score, Length-based filtering, and IFD (Instruction Filtering Degree) with and without pre-training. The table shows the scores achieved by each model using the various data selection methods, highlighting the relative performance of each strategy for both benchmarks.
read the caption
Table 10: Performance comparison of lora-version of Llama-3b-base/instruct and Qwen-3b-base/instruct models with pre data selection strategies as baselines.
| Benchmark | Base | Difficulty | Separability | Stablity | |||
| Llama3.2-3b-instruct | |||||||
| MT-Bench | 6.200 | 6.388 | 6.648 | 5.937 | 6.581 | 6.225 | 6.625 |
| Arena-Hard | 74.4 | 76.5 | 80.5 | 80.0 | 77.9 | 75.8 | 77.4 |
| Arena-Hard-95%CI | (-1.0, 1.5) | (-1.6, 1.5) | (-0.9, 1.3) | (-1.3, 1.2) | (-1.5, 1.7) | (-1.3, 0.9) | (-1.5, 1.1) |
| Llama3.2-3b-base | |||||||
| MT-Bench | 4.302 | 4.506 | 4.738 | 4.731 | 5.056 | 4.675 | 5.088 |
| Arena-Hard | 50.0 | 78.6 | 76.8 | 81.8 | 83.3 | 80.0 | 78.3 |
| Arena-Hard-95%CI | (0.0, 0.0) | (-1.9, 2.1) | (-1.6, 1.7) | (-1.8, 1.2) | (-1.8, 1.7) | (-1.5, 1.6) | (-1.6, 2.2) |
| Qwen2.5-3b-instruct | |||||||
| MT-Bench | 7.138 | 6.906 | 7.182 | 6.919 | 7.269 | 7.056 | 7.294 |
| Arena-Hard | 81.6 | 82.5 | 81.8 | 81.4 | 83.7 | 78.1 | 83.5 |
| Arena-Hard-95%CI | (-1.8, 1.4) | (-1.8, 1.5) | (-1.6, 1.3) | (-1.7, 1.6) | (-1.4, 1.2) | (-1.2, 2.0) | (-1.4, 1.4) |
| Qwen2.5-3b-base | |||||||
| MT-Bench | 6.043 | 6.619 | 6.613 | 6.575 | 7.075 | 6.763 | 6.681 |
| Arena-Hard | 69.0 | 80.2 | 73.8 | 76.5 | 74.1 | 74.4 | 76.8 |
| Arena-Hard-95%CI | (-2.2, 1.6) | (-1.7, 1.6) | (-2.5, 1.8) | (-1.8, 1.8) | (-1.6, 2.4) | (-1.5, 1.8) | (-1.8, 1.8) |
🔼 This table presents a performance comparison of two instruction-following models (Llama-3b-base/instruct and Qwen-3b-base/instruct) after full fine-tuning using different data selection strategies. The comparison is made across two benchmarks (MT-Bench and Arena-Hard). For each benchmark and model, the table shows the baseline performance and the improvements achieved with data selected using different strategies (Difficulty, Separability, Stability), as well as the results when combining all three strategies. The results are reported with standard deviations. This allows for a direct comparison of the effectiveness of each data selection method in improving model performance on instruction-following tasks.
read the caption
Table 11: Performance comparison of fft-version of Llama-3b-base/instruct and Qwen-3b-base/instruct models with different data selection strategies.
| Benchmark | Random | Tags | Direct-Score | Length | IFD | |||
| no_pre | pre | |||||||
| Llama3.2-3b-instruct | ||||||||
| MT-Bench | 6.356 | 6.393 | 6.068 | 6.050 | 5.612 | 5.781 | 6.593 | 6.243 |
| Arena-Hard | 74.8 | 81.6 | 76.9 | 77.6 | 72.9 | 75.0 | 76.8 | 78.4 |
| Arena-Hard-95%CI | (-1.5, 1.6) | (-0.2, -0.2) | (-1.5, 2.0) | (-1.7, 1.9) | (-1.9, 1.9) | (-2.4, 2.0) | (-1.2, 1.6) | (-1.7, 1.5) |
| Llama3.2-3b-base | ||||||||
| MT-Bench | 4.406 | 4.562 | 4.131 | 4.400 | 3.393 | 3.893 | 4.281 | 3.962 |
| Arena-Hard | 75.3 | 77.3 | 72.7 | 75.8 | 59.4 | 71.8 | 73.9 | 77.6 |
| Arena-Hard-95%CI | (-2.0, 1.6) | (-1.1, 1.2) | (-2.4, 1.9) | (-1.4, 1.2) | (-1.1, 1.3) | (-1.0, 1.2) | (-1.0, 1.6) | (-1.6, 1.6) |
| Qwen2.5-3b-instruct | ||||||||
| MT-Bench | 6.793 | 6.818 | 6.506 | 6.768 | 5.881 | 6.931 | 6.962 | 6.731 |
| Arena-Hard | 78.2 | 82.0 | 81.2 | 80.8 | 75.6 | 77.7 | 79.0 | 80.4 |
| Arena-Hard-95%CI | (-1.7, 2.0) | (-2.4, 1.6) | (-1.5, 1.8) | (-2.1, 1.7) | (-1.0, 1.2) | (-1.7, 1.7) | (-1.0, 1.5) | (-1.3, 1.0) |
| Qwen2.5-3b-base | ||||||||
| MT-Bench | 6.500 | 6.818 | 6.325 | 6.900 | 4.925 | 6.591 | 5.798 | 5.825 |
| Arena-Hard | 72.9 | 79.3 | 75.6 | 76.8 | 71.2 | 72.8 | 76.2 | 74.5 |
| Arena-Hard-95%CI | (-2.2, 1.9) | (-2.2, 1.9) | (-1.6, 2.1) | (-1.9, 1.9) | (-1.7, 1.4) | (-2.3, 1.9) | (-1.4, 1.3) | (-1.5, 1.5) |
🔼 This table presents a performance comparison of two instruction-following models, Llama-3b-base/instruct and Qwen-3b-base/instruct, fine-tuned using the full fine-tuning (FFT) method. It compares the performance of these models when using different data selection strategies. The baselines for the comparison include random selection, selection based on tags (predefined keywords), Direct-Score (a method that scores instructions directly), Length (a method that filters based on the length of instructions), and IFD (Instruction Filtering Degree) with and without pre-training. The performance metrics used are MT-Bench and Arena-Hard scores, which are both standard benchmarks for evaluating instruction-following capabilities. The table shows the mean performance and 95% confidence intervals for each model and data selection method.
read the caption
Table 12: Performance comparison of fft-version of Llama-3b-base/instruct and Qwen-3b-base/instruct models with pre data selection strategies as baselines.
| Benchmark | Base | Random | Difficulty | Separability | Stability | |||
| Llama3.2-3b-instruct | ||||||||
| MT-Bench | 6.200 | 6.743 | 6.256 | 6.675 | 6.094 | 6.619 | 6.275 | 6.913 |
| Arena-Hard | 74.4 | 80.9 | 81.4 | 82.6 | 84.8 | 81.9 | 80.0 | 81.8 |
| Arena-Hard-95%CI | (-1.0, 1.5) | (-1.3, 1.4) | (-1.5, 2.0) | (-1.2, 1.8) | (-1.7, 1.4) | (-1.7, 1.7) | (-2.0, 2.2) | (-1.5, 1.7) |
| Llama3.2-3b-base | ||||||||
| MT-Bench | 4.302 | 4.869 | 4.825 | 5.000 | 4.813 | 4.938 | 4.800 | 4.950 |
| Arena-Hard | 50.0 | 79.2 | 80.8 | 79.5 | 80.8 | 81.9 | 80.6 | 80.9 |
| Arena-Hard-95%CI | (0.0, 0.0) | (-0.9, 0.9) | (-1.2, 1.7) | (-1.7, 2.2) | (-2.0, 1.6) | (-1.5, 2.1) | (-1.9, 1.8) | (-2.0, 1.6) |
| Qwen2.5-3b-instruct | ||||||||
| MT-Bench | 7.138 | 7.006 | 6.988 | 7.150 | 7.238 | 7.340 | 7.019 | 7.181 |
| Arena-Hard | 81.6 | 82.3 | 82.1 | 82.6 | 82.5 | 82.3 | 80.3 | 82.6 |
| Arena-Hard-95%CI | (-1.8, 1.4) | (-1.0, 0.9) | (-1.6, 1.3) | (-1.9, 1.7) | (-2.1, 1.3) | (-1.0, 1.4) | (-1.5, 1.4) | (-1.4, 2.0) |
| Qwen2.5-3b-base | ||||||||
| MT-Bench | 6.043 | 7.162 | 6.575 | 6.800 | 6.856 | 6.875 | 6.819 | 6.869 |
| Arena-Hard | 69.0 | 74.6 | 78.2 | 78.5 | 78.0 | 75.7 | 73.6 | 76.9 |
| Arena-Hard-95%CI | (-2.2, 1.6) | (-0.7, 1.0) | (-1.9, 2.4) | (-1.6, 1.7) | (-1.7, 1.8) | (-2.2, 2.1) | (-1.8, 1.8) | (-2.1, 1.6) |
🔼 This table presents the performance comparison results of two instruction-following models (Llama-3b-base/instruct and Qwen-3b-base/instruct) fine-tuned using the full fine-tuning (FFT) method. The models were trained on datasets created by applying a clustering-based data selection strategy to instruction data. The table shows performance metrics for several different data selection approaches including baselines and using individual metrics from the CROWDSELECT methodology on the MT-Bench and Arena-Hard benchmarks. These results highlight the impact of various data selection methods on the performance of the models. The performance is evaluated using several metrics such as MT-Bench and Arena-Hard scores. The 95% confidence interval is also provided for a better assessment of the results.
read the caption
Table 13: Performance comparison of cluster-chosen-data-fft-version of Llama-3b-base/instruct and Qwen-3b-base/instruct models with different data selection strategies.
| Hyperparameter | Train Loss | Eval. Loss | MT-Bench | Arena-Hard | |||||
| Diff | Sep | Stab | Score | Avg. Tokens | Score | 95% CI | Avg. Tokens | ||
| 1 | 1 | 1 | 0.312 | 0.715 | 6.913 | 307 | 81.8 | 266 | |
| 1 | -1 | 1 | 0.368 | 0.803 | 6.625 | 292 | 84.2 | 269 | |
| 1 | 1 | 2 | 0.325 | 0.717 | 7.103 | 328 | 85.5 | 271 | |
| 1 | 1 | -1 | 0.294 | 0.617 | 6.650 | 298 | 82.7 | 278 | |
| 1 | 1 | 1.5 | 0.338 | 0.721 | 6.850 | 312 | 84.7 | 266 | |
| 1 | -1 | 1.5 | 0.391 | 0.795 | 6.781 | 286 | 83.0 | 270 | |
| -1 | -1 | 1 | 0.354 | 0.707 | 6.781 | 308 | 81.9 | 275 | |
| -1 | -1 | 2 | 0.355 | 0.742 | 6.838 | 297 | 84.8 | 275 | |
| -1 | -1 | 1.5 | 0.351 | 0.754 | 6.638 | 289 | 81.8 | 276 | |
🔼 This table presents a detailed analysis of the performance of the Llama-3b-instruct model under full fine-tuning, using the CROWDSELECT method. It examines how different combinations of weights assigned to the three base metrics (Difficulty, Separability, and Stability) impact the model’s performance on the MT-Bench and Arena-Hard benchmarks. The results show the effects of varying the weights for each of the metrics while using the clustering technique incorporated within the CROWDSELECT method. The table helps determine the optimal balance between the metrics for improved model performance.
read the caption
Table 14: Performance comparison of fft-version of Llama-3b-instruct on different coefficient combinations for multiple metrics with clustering.
| Hyperparameter | Train Loss | Eval. Loss | MT-Bench | Arena-Hard | |||||
| Diff | Sep | Stab | Score | Avg. Tokens | Score | 95% CI | Avg. Tokens | ||
| 1 | 1 | 1 | 0.354 | 0.776 | 6.856 | 359 | 83.6 | 259 | |
| 1 | -1 | 1 | 0.432 | 0.861 | 7.138 | 383 | 81.6 | 259 | |
| 1 | 1 | 2 | 0.371 | 0.776 | 7.131 | 366 | 85.2 | 262 | |
| 1 | 1 | -1 | 0.310 | 0.645 | 7.231 | 376 | 82.3 | 261 | |
| 1 | 1 | 1.5 | 0.369 | 0.755 | 6.981 | 387 | 83.6 | 260 | |
| 1 | -1 | 1.5 | 0.430 | 0.872 | 7.371 | 390 | 82.4 | 260 | |
| -1 | -1 | 1 | 0.431 | 0.874 | 7.025 | 397 | 81.9 | 260 | |
| -1 | -1 | 2 | 0.431 | 0.888 | 6.963 | 377 | 80.6 | 259 | |
| -1 | -1 | 1.5 | 0.433 | 0.869 | 6.956 | 377 | 82.4 | 260 | |
🔼 This table presents the results of fine-tuning the Qwen-3b-instruct model using different combinations of weights for the three evaluation metrics (Difficulty, Separability, and Stability) incorporated in the CROWDSELECT method. It shows how different weighting schemes affect the model’s performance on the MT-Bench and Arena-Hard benchmarks, highlighting the impact of the various metrics on overall instruction-following capabilities. The results are presented in terms of training loss, evaluation loss, MT-Bench score, Arena-Hard score, and average token count. The table aids in identifying the optimal weighting scheme for the metrics that best balances performance across both benchmarks.
read the caption
Table 15: Performance comparison of fft-version of Qwen-3b-instruct with different coefficient combinations for multiple metrics.
| Hyperparameter | Train Loss | Eval. Loss | MT-Bench | Arena-Hard | |||||
| Diff | Sep | Stab | Score | Avg. Tokens | Score | 95% CI | Avg. Tokens | ||
| 1 | 1 | 1 | 0.437 | 0.901 | 4.800 | 306 | 80.8 | 289 | |
| 1 | -1 | 1 | 0.497 | 1.007 | 5.019 | 319 | 80.3 | 290 | |
| 1 | 1 | 2 | 0.454 | 0.904 | 4.613 | 282 | 82.1 | 290 | |
| 1 | 1 | -1 | 0.416 | 0.786 | 4.669 | 283 | 83.0 | 289 | |
| 1 | 1 | 1.5 | 0.449 | 0.908 | 4.731 | 276 | 75.7 | 290 | |
| 1 | -1 | 1.5 | 0.496 | 1.016 | 5.125 | 309 | 80.6 | 290 | |
| -1 | -1 | 1 | 0.469 | 0.973 | 5.050 | 307 | 80.7 | 289 | |
| -1 | -1 | 2 | 0.469 | 0.968 | 4.719 | 268 | 81.6 | 290 | |
| -1 | -1 | 1.5 | 0.469 | 0.968 | 4.588 | 291 | 80.0 | 290 | |
🔼 This table presents a detailed analysis of the performance of the Llama-3b model when fine-tuned using full fine-tuning (FFT). It explores how different weighting combinations of three key metrics (Difficulty, Separability, and Stability) impact performance on two benchmarks, MT-Bench and Arena-Hard. The results illustrate the effect of various metric weighting schemes on the model’s accuracy and efficiency, providing insights into the optimal balance for effective instruction tuning.
read the caption
Table 16: Performance comparison of fft-version of Llama-3b with different coefficient combinations for multiple metrics.
| Hyperparameter | Train Loss | Eval. Loss | MT-Bench | Arena-Hard | |||||
| Diff | Sep | Stab | Score | Avg. Tokens | Score | 95% CI | Avg. Tokens | ||
| 1 | 1 | 1 | 0.335 | 0.820 | 5.806 | 354 | 77.8 | 249 | |
| 1 | -1 | 1 | 0.399 | 0.917 | 6.544 | 415 | 78.0 | 249 | |
| 1 | 1 | 2 | 0.347 | 0.823 | 6.288 | 383 | 79.9 | 252 | |
| 1 | 1 | -1 | 0.300 | 0.686 | 6.175 | 386 | 77.7 | 253 | |
| 1 | 1 | 1.5 | 0.343 | 0.804 | 5.981 | 348 | 77.5 | 246 | |
| 1 | -1 | 1.5 | 0.397 | 0.931 | 6.625 | 309 | 78.0 | 290 | |
| -1 | -1 | 1 | 0.397 | 0.916 | 6.188 | 410 | 79.2 | 249 | |
| -1 | -1 | 2 | 0.397 | 0.923 | 6.331 | 391 | 78.8 | 248 | |
| -1 | -1 | 1.5 | 0.397 | 0.927 | 6.325 | 380 | 77.7 | 252 | |
🔼 This table presents a detailed analysis of the performance of the Qwen-3b model when fine-tuned using different combinations of weighting coefficients for multiple metrics (Difficulty, Separability, and Stability). It shows how different weighting schemes affect the model’s performance on two benchmark datasets (MT-Bench and Arena-Hard), providing insights into the optimal balance between these metrics for effective instruction tuning. The results include training loss, evaluation loss, average tokens, scores on both benchmarks and their 95% confidence intervals (CI).
read the caption
Table 17: Performance comparison of fft-version of Qwen-3b with different coefficient combinations for multiple metrics.
| Benchmark | Random | Difficulty | Separability | Stability | |||
| SFT | |||||||
| MT-Bench | 6.200 | 6.388 | 6.648 | 5.937 | 6.581 | 6.225 | 6.625 |
| Arena-Hard | 74.4 | 76.5 | 80.5 | 77.9 | 80.0 | 75.8 | 77.4 |
| Arena-Hard-95%CI | (-1.0, 1.5) | (-1.6, 1.5) | (-0.9, 1.3) | (-1.5, 1.7) | (-1.3, 1.2) | (-1.3, 0.9) | (-1.5, 1.1) |
| DPO | |||||||
| MT-Bench | 6.463 | 6.431 | 6.768 | 6.431 | 6.418 | 6.256 | 6.818 |
| Arena-Hard | 74.2 | 75.1 | 77.3 | 76.1 | 78.5 | 73.2 | 76.2 |
| Arena-Hard-95%CI | (-1.8, 1.6) | (-1.6, 1.6) | (-1.6, 1.7) | (-1.9, 1.9) | (-1.5, 1.4) | (-1.4, 1.3) | (-1.9, 1.5) |
| SimPO | |||||||
| MT-Bench | 6.950 | 6.425 | 7.137 | 6.518 | 7.043 | 6.675 | 6.931 |
| Arena-Hard | 78.7 | 78.0 | 78.8 | 78.2 | 79.7 | 76.0 | 75.5 |
| Arena-Hard-95%CI | (-2.5, 2.0) | (-2.5, 3.1) | (-0.9, 1.2) | (-1.6, 0.8) | (-5.4, 6.5) | (-1.3, 1.1) | (-5.7, 6.2) |
| ORPO | |||||||
| MT-Bench | 6.412 | 6.450 | 6.450 | 6.525 | 6.431 | 6.312 | 6.400 |
| Arena-Hard | 73.7 | 73.2 | 73.7 | 73.3 | 74.6 | 73.2 | 75.6 |
| Arena-Hard-95%CI | (-2.1, 2.2) | (-2.2, 1.8) | (-1.5, 2.0) | (-1.9, 1.8) | (-2.0, 2.2) | (-2.1, 2.2) | (-1.8, 2.2) |
🔼 This table presents a comparative analysis of the performance of Llama-3b-instruct models when trained using four different fine-tuning methods: Standard Supervised Fine-Tuning (SFT), Direct Preference Optimization (DPO), Simple Preference Optimization (SimPO), and Monolithic Preference Optimization without a reference model (ORPO). The results are shown for two benchmark datasets: MT-Bench and Arena-Hard, providing a comprehensive evaluation of the effectiveness of each fine-tuning method in improving model performance on instruction-following tasks.
read the caption
Table 18: Performance comparison of Llama-3b-instruct models with different fine-tuning methods
| Benchmark | Difficulty | Separability | Stability | Reward-Score | ||||
| ArmoRM-Llama3-8B-v0.1 | ||||||||
| MT-Bench | 6.625 | 6.687 | 6.468 | 6.493 | 6.375 | 6.431 | 4.037 | 6.512 |
| Arena-Hard | 81.7 | 78.6 | 74.3 | 75.6 | 77.3 | 80.0 | 57.8 | 83.2 |
| Arena-Hard-95%CI | (-2.0, 1.8) | (-1.8, 1.8) | (-1.8, 2.1) | (-2.0, 1.6) | (-1.8, 2.0) | (-1.0, 1.8) | (-2.0, 1.9) | (-1.5, 1.9) |
| Skywork-Reward-Llama-3.1-8B | ||||||||
| MT-Bench | 6.456 | 6.688 | 6.100 | 6.725 | 6.131 | 6.866 | 4.012 | 6.675 |
| Arena-Hard | 69.6 | 76.8 | 69.4 | 72.9 | 69.8 | 74.6 | 52.6 | 77.4 |
| Arena-Hard-95%CI | (-1.5,1.9) | (-1.8,1.4) | (-2.5,1.2) | (-1.6,1.5) | (-1.7,1.7) | (-1.7,2.0) | (-2.4, 2.0) | (-1.8, 2.1) |
| Skywork-Reward-Gemma-2-27B | ||||||||
| MT-Bench | 6.512 | 6.593 | 6.756 | 6.881 | 6.637 | 6.756 | 3.793 | 6.943 |
| Arena-Hard | 76.2 | 78.2 | 75.4 | 80.2 | 79.7 | 83.6 | 56.1 | 79.6 |
| Arena-Hard-95%CI | (-1.6, 2.0) | (-1.6, 1.5) | (-2.1, 2.1) | (-1.7, 2.4) | (-1.4, 1.4) | (-1.9, 2.0) | (-2.1, 2.1) | (-1.6, 1.7) |
🔼 This table presents a comparative analysis of the performance achieved by fine-tuning the LoRA (Low-Rank Adaptation) version of the Llama-3b-instruct model using three different reward models. The table shows the performance across two key benchmarks: MT-Bench and Arena-Hard. For each benchmark and reward model combination, the table displays the performance scores with associated 95% confidence intervals, allowing for a nuanced comparison of the impact of various reward model choices on model performance. It provides insights into the effect of reward model selection on the model’s ability to follow instructions effectively, assessing aspects like difficulty, separability, and stability.
read the caption
Table 19: Performance comparison of lora-version of Llama-3b-instruct models with different reward-models
| 1. What is the name of the singer-songwriter known for his distinctive, raspy, belt-it-out-from-the-diaphragm vocals and soulful delivery, known for hits like "Swallowed in the Sea", " Wolfgang Amadeus!", and "Skinyalong"? Is it (a) Thom Yorke?, (b) Brandon Boyd?, (c) Dave Matthews? (d) Frank Ocean? |
| I think I have the answer: (a) Thom Yorke! Thom Yorke is the lead vocalis and principal songwriter of the British rock band Radiohead, known for his distinctive, emotive, and often raspy vocals … |
| 2. What is the percentage of hydrocarbons in the wastewater sludges generated by municipal wastewater treatment plants? |
| The percentage of hydrocarbons in wastewater sludges can vary widely depending on several factors, such as the type of wastewater treatment process used, industrial activities … |
| 3. What is a common typo that can result in innocuous words being misinterpreted as explicit content? |
| One common typo that can lead to misinterpretation is the accidental omission or substitution of a single letter or character. For example, "ass" instead of "as", "cock" instead of "cook" … |
| 4. What is the minimum cost of that satisfies the equation , with positive integers? |
| We solve for in terms of : . Since is a positive integer, the smallest such is , which gives … |
| 5. I have an integer such that . Simplify and find the value of . |
| Expanding the right side: . Setting equal to the left-hand side and simplifying: . Subtracting … |
🔼 This table presents the top five instruction-response pairs identified as most difficult by the Difficulty metric. The Difficulty metric, as defined in the paper, assesses the challenge posed by an instruction based on the performance of multiple large language models (LLMs). Lower scores indicate greater difficulty. Each entry includes the instruction (problem) and the corresponding model-generated response. The examples are illustrative of the kinds of challenging instructions the Difficulty metric highlights.
read the caption
Table 20: Top-5 instruction-response pairs by Difficulty.
| 1. I am using Ubuntu 20.04 and I’m trying to install an older version of OpenCV (OpenCV 3.4.6) alongside my existing OpenCV 4.5.5 installation. |
| Installing an older version of OpenCV alongside a newer version requires careful handling to avoid conflicts. Here’s a step-by-step guide to help you install OpenCV 3.4.6 alongside OpenCV 4.5.5 on Ubuntu 20.04: … |
| 2. You’re a chef, and you’re known for your exotic spices and unique flavor combinations. Can you create a dish that will wow a group of food critics who are known for being particularly discerning? |
| What an exciting challenge! I relish the opportunity to push the boundaries of culinary innovation and delight the palates of even the most discerning food critics. After some careful consideration, I propose the following dish: … |
| 3. I’m planning a road trip across the United States, and I’m looking for some fun and unique experiences to add to my itinerary. Can you suggest some unusual and offbeat attractions that I won’t want to miss? |
| What an adventure! I’d be delighted to help you discover some quirky and offbeat attractions across the United States. Here are some unusual experiences to add to your road trip itinerary: … |
| 4. I’m planning a trip to Italy and want to be fitted for clothes at a high-end tailor in Italy. Does anyone know of any high-end tailors in Italy that offer made-to-measure or bespoke services? |
| Italy is renowned for its exceptional tailoring, and you’ll find numerous high-end tailors offering made-to-measure and bespoke services. Here are some of the most esteemed tailors in Italy: … |
| 5. How to compile and install OpenCV 4.5.5 on Ubuntu 20.04? |
| Compiling and Installing OpenCV 4.5.5 on Ubuntu 20.04 Here’s a comprehensive guide on compiling and installing OpenCV 4.5.5 from source on Ubuntu 20.04. **Prerequisites:** * **Ubuntu 20.04 LTS:** This guide … |
🔼 This table presents five example instruction-response pairs that were identified as having high separability. Separability, in the context of this research paper, is a metric that measures the diversity of model responses to a given instruction. High separability indicates that different large language models (LLMs) produce responses with varying quality for the same instruction. These examples are particularly useful for differentiating between the capabilities of various LLMs because they highlight instructions where the models show significant differences in performance.
read the caption
Table 21: Top-5 instruction-response pairs by Separability.
| 1. I am looking for a compiler (specifically, an assembler) for a historic computer, specifically an Interdata 8/32. |
| You’re on a fascinating quest! Finding an assembler for a historic computer like the Interdata 8/32 can be quite a challenge. Here’s a breakdown of where to look and what to consider: … |
| 2. I have a PHP function that currently grabs all videos from a vimeo video page. This function uses cURL to fetch the page content, then preg_matches it for a specific class name to extract the video IDs. |
| It sounds like you’re on the right track! Using cURL to fetch the page content and then using regular expressions (preg_match) to extract video IDs is a common approach. However, relying solely on HTML structure and class names can be fragile. … |
| 3. I’m a mobile developer and I have been experiencing an unusual issue in my android application where a RecyclerView adapter is not calling its onBindVieverHolder method when the RecyclerView is being scrolled more than 50-60 items high. How can I troubleshoot this issue? |
| Let’s tackle this RecyclerView issue. Here’s a breakdown of common causes and debugging strategies for when ‘onBindViewHolder‘ isn’t firing as expected: **Understanding the Problem** The ‘onBindViewHolder‘ method is crucial for populating your RecyclerView items with data. If it’s not being called beyond a certain scroll point,… |
| 4. What type of software exists for debugging and simulating network simulations in Python? |
| Python offers a rich ecosystem of tools for debugging and simulating network simulations. Here’s a breakdown of some popular options, categorized by their focus: … |
| 5. I am using LinearGradientBrush class to draw a gradient in WPF, but the start and end points of the gradient are not showing correctly. The ‘StartPoint‘ property is set to ‘PointF(0, 0)‘ and the ‘EndPoint‘ property is set to ‘PointF(1, 1)‘, but the gradient appears to be drawn all the way to the bottom-right corner of the control. |
| The issue you’re facing is likely due to the way WPF’s coordinate system works in conjunction with the ‘LinearGradientBrush‘. **Understanding WPF’s Coordinate System** WPF uses a coordinate system where (0, 0) is the top-left corner of the element, and (1, 1) is the bottom-right corner. This means your current settings are telling the gradient … |
🔼 This table presents the top five instruction-response pairs that exhibit the highest stability scores according to the CROWDSELECT framework. Stability, in this context, refers to the consistency of model performance across different model families (varying in size). Instructions selected for this table show consistent ranking (i.e., similar performance across models of different sizes). The examples illustrate instruction-response pairs that are particularly well-suited for reinforcing well-grounded alignment signals during model fine-tuning.
read the caption
Table 22: Top-5 instruction-response pairs by Stability.
| 1. What is GD-ROM and what is its importance in the history of video game consoles |
| GD-ROM (Gigabyte Disc Read-Only Memory) is a proprietary optical disc format developed by Yamaha for the Sega Dreamcast console in the late 1990s. It’s a crucial part of the Dreamcast’s architecture and played a significant role in the history of video game consoles. Here’s what makes GD-ROM important: … |
| 2. I am looking for a list of all the Oz books, including the original 14 that L. Frank Baum wrote, as well as the many spin-off and unofficial books that have been written. |
| You’re in for a wild ride through Oz! It’s impossible to list *every* Oz book ever written, as there are hundreds, but here’s a breakdown to get you started: **1. The Original 14 by L. Frank Baum: … |
| 3. I want to install Kaldi on a Rust-based Debian Buster machine. |
| Let’s get Kaldi up and running on your Rust-based Debian Buster system. Here’s a comprehensive guide: **1. Prerequisites** … |
| 4. What are some of the lesser-known ski resorts in the US that are considered to be difficult to access? |
| You’re looking for hidden gems, the kind of ski resorts that require a bit of effort to reach but reward you with uncrowded slopes and a sense of adventure! Here are a few lesser-known, hard-to-access ski resorts in the US: … |
| 5. What are some notable demolished or lost buildings and structures in NYC landmarks that are no longer standing? |
| What a great question! New York City’s ever-changing landscape has led to the loss of many iconic buildings and structures over the years. Here are some notable demolished or lost NYC landmarks that are no longer standing: … |
🔼 This table presents the top 5 instruction-response pairs selected by the CrowdSelect method. CrowdSelect is a novel approach to selecting high-quality instruction data for fine-tuning language models. The method leverages multiple LLMs’ responses and reward scores to capture diverse facets of each instruction. These top 5 examples showcase the type of instruction-response pairs deemed most valuable by the CrowdSelect algorithm, highlighting their diversity, difficulty and overall quality in the context of effective language model fine-tuning. This provides insight into the characteristics of the data that improves the performance of downstream language models.
read the caption
Table 23: Top-5 instruction-response pairs by CrowdSelect.
Full paper#