TL;DR#
Large-scale language models face challenges in edge deployment due to high computational demands, energy consumption, and privacy risks. To address these issues, this work explores Small Language Models (SLMs). Edge AI runs models directly on local hardware, reducing reliance on remote servers. However, scaling down large models often compromises language understanding, and this motivates SLMs that balance performance and resource constraints. Techniques such as efficient architectures and quantization help SLMs maintain performance under tight constraints.
To achieve the benefits of the SLMs, this paper introduces the Shakti Small Language Models (SLMs): Shakti-100M, Shakti-250M, and Shakti-500M. The Shakti series combines efficient architectures, quantization, and responsible AI for on-device intelligence. They provide design insights, training pipelines, and benchmark results for general and specialized tasks. The study illustrates that compact models can meet and often exceed expectations in real-world edge-AI scenarios. The Shakti models incorporate mechanisms to mitigate bias, handle data privately, and reduce carbon footprints through on-device inference.
Key Takeaways#
Why does it matter?#
This paper introduces a series of small language models optimized for edge devices, paving the way for efficient and privacy-preserving AI applications. The models address limitations of large language models and offer researchers insights into designing compact, high-performance models. It enables further exploration of edge AI.
Visual Insights#

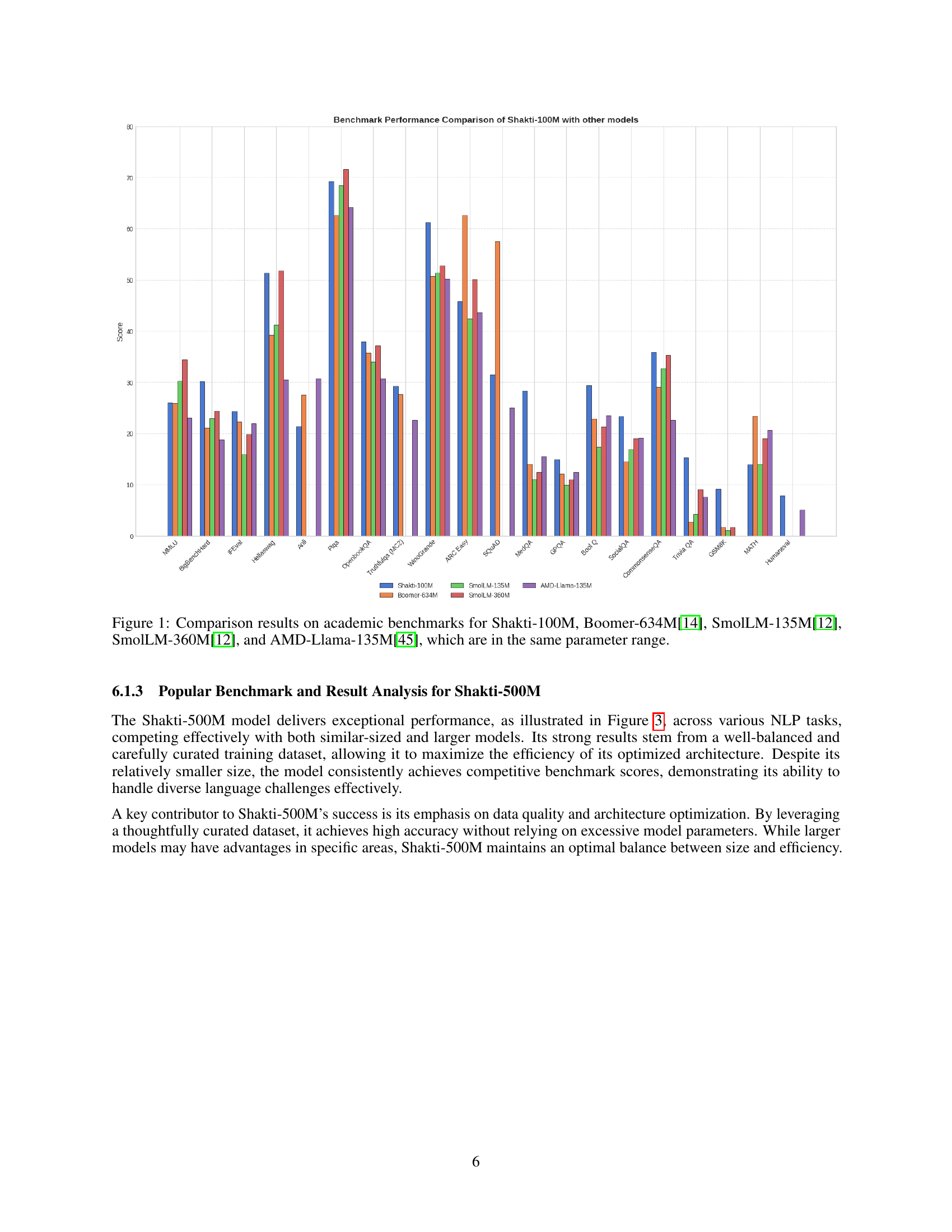
🔼 Figure 1 presents a comparative analysis of the Shakti-100M model’s performance against other similar-sized language models across various academic benchmarks. The benchmarks assess performance on diverse natural language processing tasks. The figure visually compares the scores achieved by Shakti-100M to those of Boomer-634M, SmolLM-135M, SmolLM-360M, and AMD-Llama-135M, all of which fall within a similar parameter range, allowing for a fair comparison based on model size.
read the caption
Figure 1: Comparison results on academic benchmarks for Shakti-100M, Boomer-634M[14], SmolLM-135M[12], SmolLM-360M[12], and AMD-Llama-135M[45], which are in the same parameter range.
| Shakti-100M | Shakti-250M | Shakti-500M | |
|---|---|---|---|
| Pre-Training | • Common Crawl [10] • Fineweb-EDU-Dedup [23] | • Fineweb-EDU-Dedup [23] • AIR-Bench/qa_finance_e_n [24] • Vidhaan/LegalCitationWorthiness [25] | • TxT360 [26] • Common Crawl [10] |
| SFT | • Cosmopedia v2 [27] • Magma-Pro-300K-Filtered-H4 [28] • OpenHermes-2.5-H4 [29] • Self-oss-instruct-sc2-H4 [30] • Everyday-conversations-llama3.1-2k [31] • Instruct-data-basics-smolim-H4 [32] | • lavita/medical-qa-datasets [33] • ruslannmv/ai-medical-chatbot [34] • axion/pmc_llama_instructions [35] • windupdate/reddit_finance_43_250k [36] • Marina-C/question-answer-Subject-Finance-instruct [37] • isacus/open-australian-legal-qa [38] • mb7419/legal-advice-reddit [39] | • The Thome [40] • Infinity-instruct [41] |
| DPO | • UltraFeedback Binarized [42] | • NickyNicky/nano_finance_200k[43] • Dhananjay22/legal-dpo [44] | |
| RLHF | • UltraFeedback Binarized [42] |
🔼 This table details the datasets used in training the three Shakti language models (Shakti-100M, Shakti-250M, and Shakti-500M) at different stages. It breaks down the datasets used for pre-training, supervised fine-tuning (SFT), direct preference optimization (DPO), and reinforcement learning from human feedback (RLHF), offering insights into the diverse data sources and training methodologies employed for each model size. This provides a comprehensive overview of the data used to build the different Shakti models.
read the caption
Table 1: Training datasets used for different Shakti model sizes.
In-depth insights#
Edge AI Shakti#
The paper introduces the Shakti Small Language Models (SLMs)—Shakti-100M, Shakti-250M, and Shakti-500M—to address challenges in deploying large-scale language models on edge devices. Edge AI, where models run directly on local hardware, is presented as a solution to limitations such as high computational demands, energy consumption, and data privacy risks. The Shakti series combines efficient architectures, quantization techniques, and responsible AI principles to enable on-device intelligence for smartphones, smart appliances, and IoT systems. The models integrate Rotary Positional Embeddings (RoPE) and specialized attention variants to rival larger models. Quantized versions minimize memory usage and increase throughput, even on constrained devices. Shakti models mitigate bias, handle data privately, and reduce carbon footprints. Pre-training and fine-tuning strategies align with user preferences and ethical standards. Evaluations on specialized tasks suggest that Shakti’s parameter sizes and domain-targeted training yield cost-effective, scalable, and privacy-preserving solutions.
Quantized SLMs#
The emergence of quantized Small Language Models (SLMs) signifies a crucial step towards efficient AI deployment, particularly on resource-constrained edge devices. Quantization reduces model size and accelerates inference by representing weights and activations with lower precision (e.g., int8, int5, int4) compared to traditional FP32 models. This allows SLMs to fit into devices like smartphones and IoT gadgets. This optimization does not come without trade-offs: aggressive quantization may lead to accuracy degradation. Therefore, techniques like quantization-aware training (QAT) are essential to maintain performance. Model architecture also plays a role, where certain architectures are more amenable to quantization than others. Ultimately, quantized SLMs represent a balanced approach, enabling sophisticated AI functionalities in real-world scenarios.
DPO Alignment#
Direct Preference Optimization (DPO) emerges as a pivotal technique for aligning language models with desired behaviors, offering a computationally efficient alternative to Reinforcement Learning from Human Feedback (RLHF). By directly optimizing for preferences, DPO streamlines the alignment process. Shakti-250M and Shakti-100M use DPO to achieve domain-specific accuracy and quality real-time responses, suitable for mobile devices and IoT applications. DPO achieves alignment at a significantly lower computational cost compared to models relying solely on RLHF. This enables real-time application capabilities without sacrificing quality.
Domain SLM Tasks#
Domain-Specific Small Language Models (SLMs) represent a focused approach to AI, tailoring models for specific fields like healthcare, finance, or legal. Instead of broadly capable general-purpose models, domain-specific SLMs are trained on datasets relevant to their target domain. This specialization offers several advantages. Improved Accuracy: By focusing on a narrow domain, SLMs can achieve higher accuracy and relevance compared to general models. Reduced Computational Cost: SLMs require less computational power and memory, making them suitable for deployment on edge devices with limited resources. Enhanced Privacy: Training and deploying SLMs on-premise reduces the need to transmit sensitive data to cloud servers. Faster Inference: The reduced size and complexity of SLMs lead to faster inference times, making them suitable for real-time applications. Reduced Bias: Carefully curating the datasets and training processes, biases can be mitigated.
Ethical Edge AI#
Ethical Edge AI is crucial for responsible technology deployment. It requires addressing bias in datasets and models, ensuring fairness and transparency. Privacy-preserving techniques, like federated learning, are essential to protect user data on edge devices. Accountability mechanisms should be in place to address potential harms or unintended consequences. Continuous monitoring and evaluation are necessary to detect and mitigate biases over time. Ethical guidelines and standards should be developed to guide the development and deployment of edge AI systems. User education and awareness are important to empower individuals to make informed decisions about their data and privacy. Collaboration between stakeholders, including researchers, developers, policymakers, and civil society organizations, is essential to ensure that edge AI is developed and deployed in an ethical and responsible manner. By prioritizing ethical considerations, we can harness the benefits of edge AI while minimizing potential risks and promoting a more equitable and inclusive future. Moreover, we have to ensure that AI serves humanity and adheres to the same ethical principles and norms.
More visual insights#
More on figures

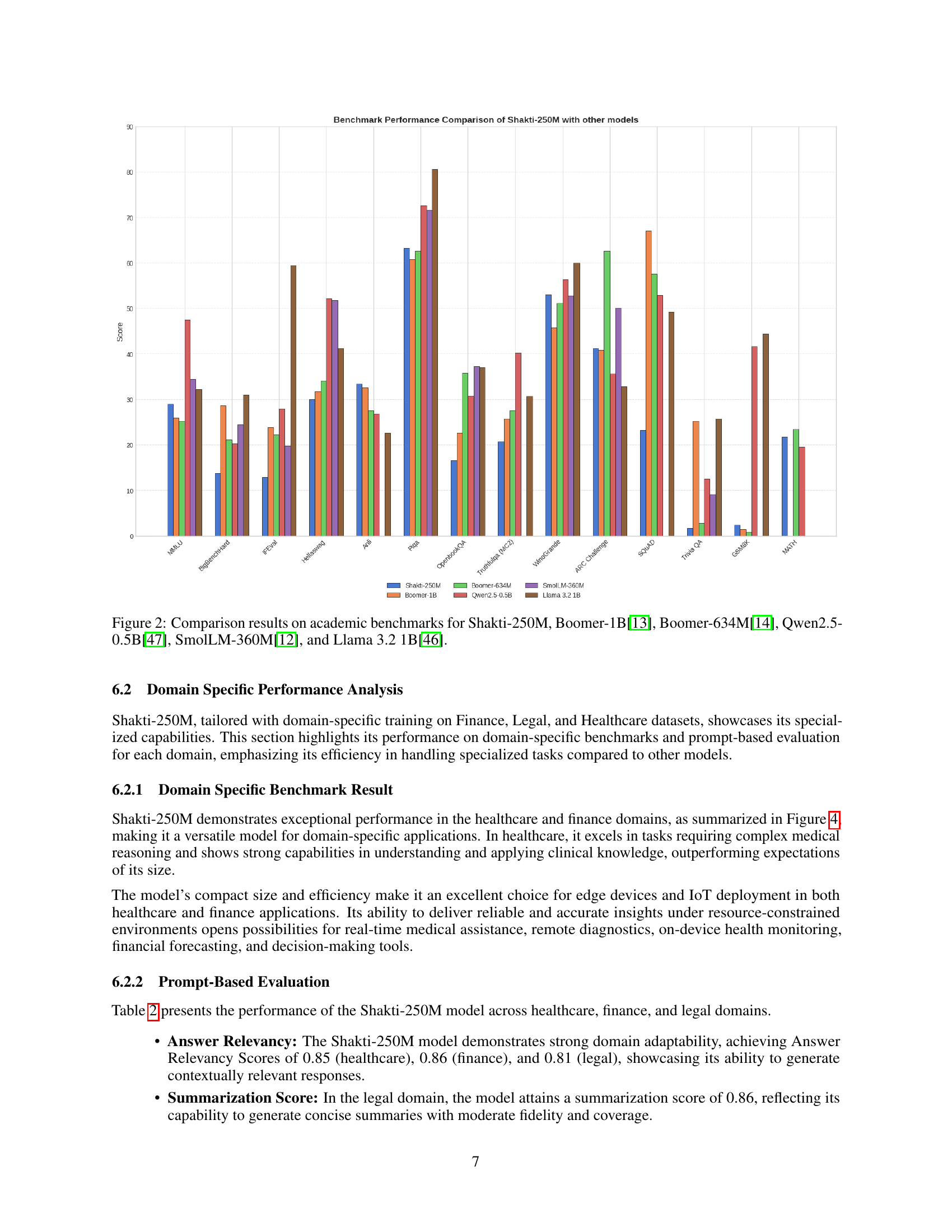
🔼 This figure compares the performance of Shakti-250M against other large language models (LLMs) across various academic benchmarks. The benchmarks assess performance on diverse tasks, allowing for a comprehensive comparison of the model’s capabilities. The LLMs included in the comparison are Boomer-1B, Boomer-634M, Qwen2.5-0.5B, SmolLM-360M, and Llama 3.2 1B, providing context for evaluating Shakti-250M’s performance relative to established models. Each bar in the chart represents the score achieved by each model on a specific benchmark task.
read the caption
Figure 2: Comparison results on academic benchmarks for Shakti-250M, Boomer-1B[13], Boomer-634M[14], Qwen2.5-0.5B[47], SmolLM-360M[12], and Llama 3.2 1B[46].

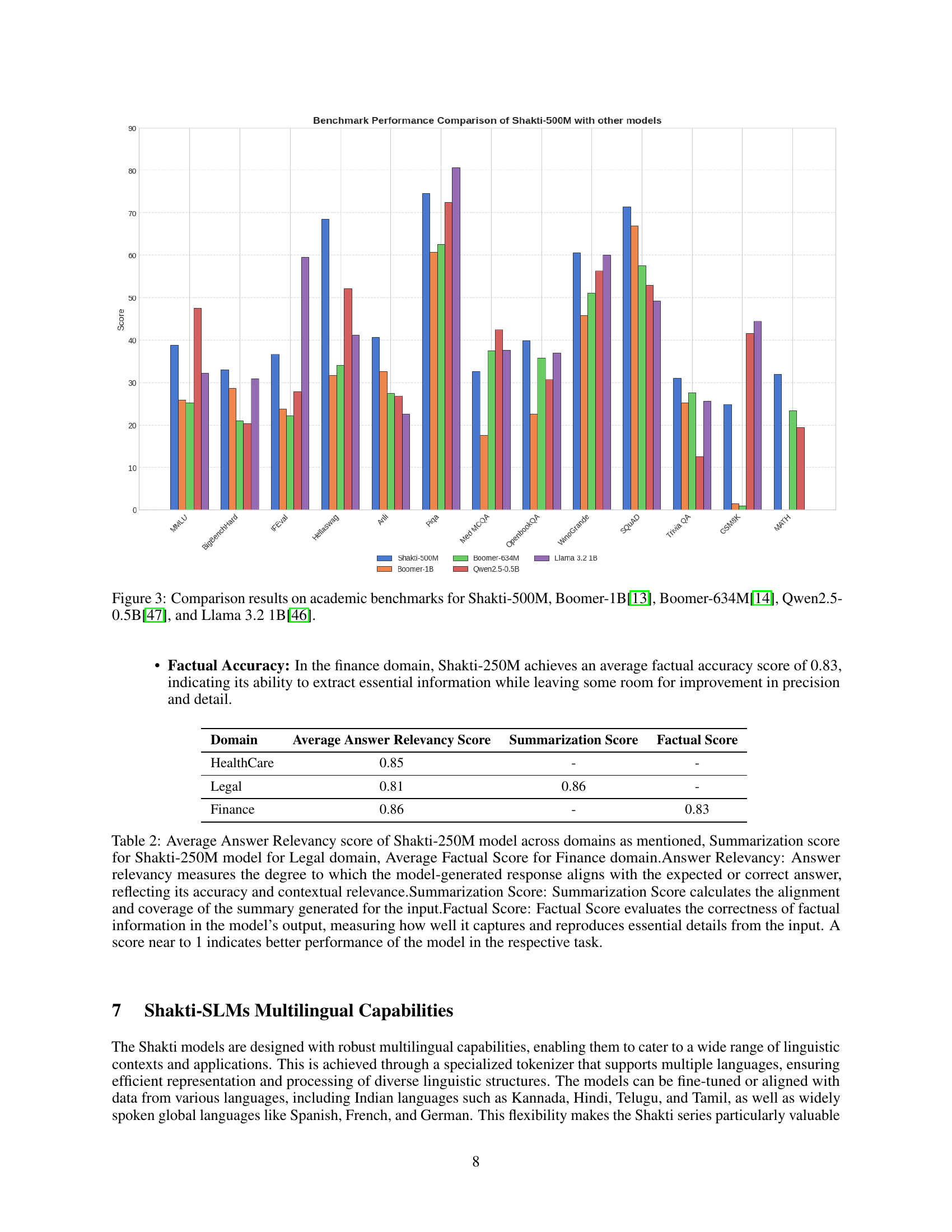
🔼 Figure 3 presents a comparative analysis of the Shakti-500M model’s performance against other prominent large language models (LLMs) across various academic benchmarks. These benchmarks assess performance on diverse natural language processing (NLP) tasks, allowing for a comprehensive evaluation of the model’s capabilities. The comparison includes Boomer-1B, Boomer-634M, Qwen2.5-0.5B, and Llama 3.2 1B, providing a nuanced understanding of Shakti-500M’s strengths and weaknesses relative to models with similar and larger parameter counts.
read the caption
Figure 3: Comparison results on academic benchmarks for Shakti-500M, Boomer-1B[13], Boomer-634M[14], Qwen2.5-0.5B[47], and Llama 3.2 1B[46].

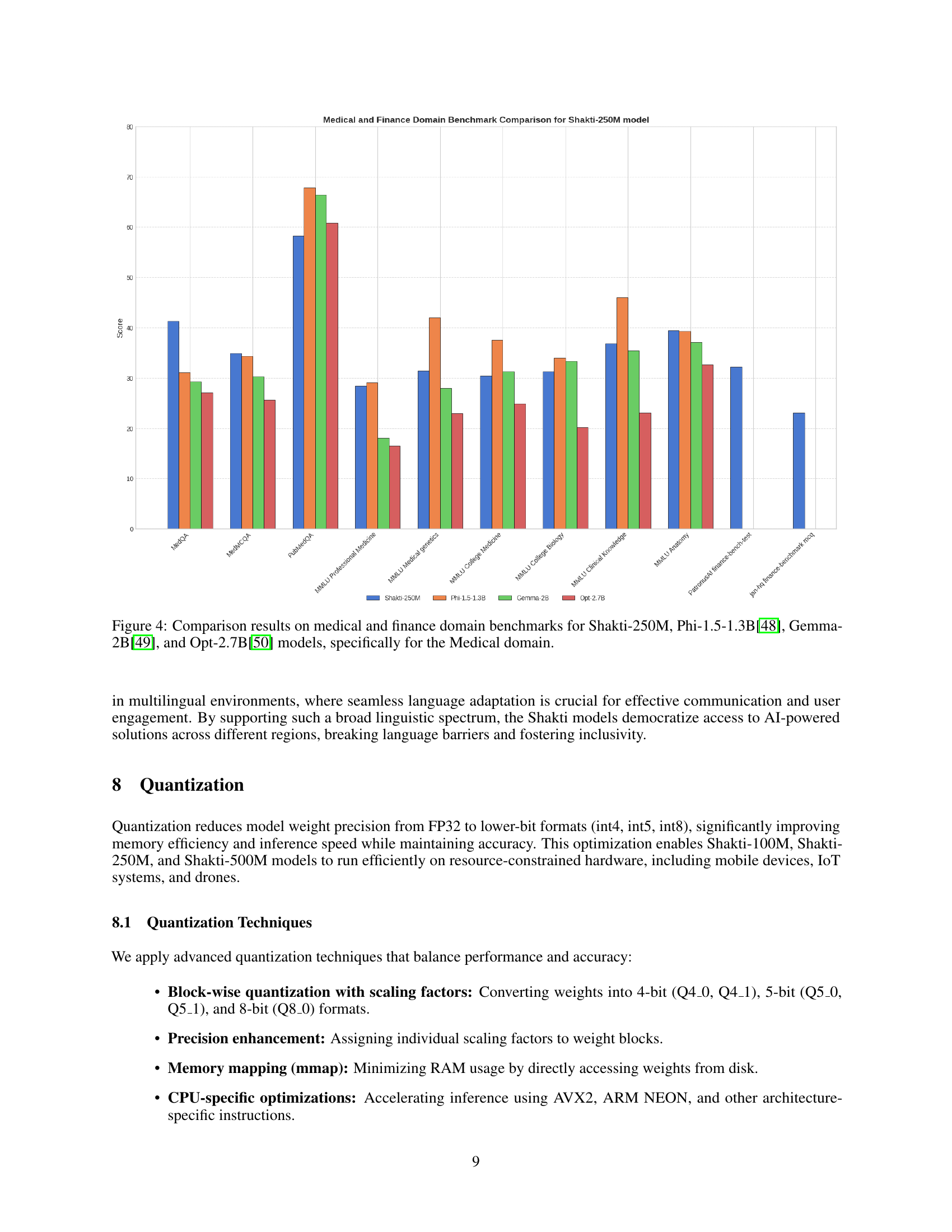
🔼 Figure 4 presents a comparative analysis of the performance of several large language models (LLMs) on medical domain benchmark tasks. The LLMs compared include Shakti-250M, Phi-1.5-1.3B, Gemma-2B, and Opt-2.7B. The figure specifically highlights performance on tasks relevant to the medical field. The results are likely displayed using bar charts or similar visualizations, showing each model’s score on each benchmark task to allow for direct comparison.
read the caption
Figure 4: Comparison results on medical and finance domain benchmarks for Shakti-250M, Phi-1.5-1.3B[48], Gemma-2B[49], and Opt-2.7B[50] models, specifically for the Medical domain.

🔼 This figure compares the memory usage of several language models before and after applying different quantization techniques. The original, unquantized model size is represented by ‘FP32’. The levels of quantization are shown by ‘Q8’, ‘Q5’, and ‘Q4’, where Q4 uses the most aggressive quantization and reduces the model’s memory footprint the most. The bar chart visually demonstrates how much smaller the quantized models are compared to their original size. Specifically, it shows that using Q4 quantization results in models requiring approximately 8 times less memory than the original FP32 versions.
read the caption
Figure 5: Model size comparison before and after quantization. FP32 represents the original model size, while Q8, Q5, and Q4 represent increasingly aggressive quantization levels. Note the substantial reduction in memory footprint, with Q4 models requiring approximately 8x less memory than their FP32 counterparts.

🔼 Figure 6 presents a comparative analysis of the Shakti models’ performance (measured in tokens per second) across various hardware platforms, ranging from high-performance GPUs to resource-constrained devices like Raspberry Pi and mobile phones. The bar chart visually represents the throughput achieved by Shakti-100M, Shakti-250M, and Shakti-500M, in their quantized versions (Q4), compared to similar-sized competitor models on each platform. This comparison highlights the Shakti models’ ability to maintain high processing speeds even on devices with limited computational resources.
read the caption
Figure 6: Performance comparison (tokens per second) of Shakti models across different hardware platforms. The graph demonstrates how our models maintain high throughput even on resource-constrained devices compared to similar-sized competitors.
More on tables
| Domain | Average Answer Relevancy Score | Summarization Score | Factual Score |
|---|---|---|---|
| HealthCare | 0.85 | - | - |
| Legal | 0.81 | 0.86 | - |
| Finance | 0.86 | - | 0.83 |
🔼 This table presents a performance analysis of the Shakti-250M model across three domains: Healthcare, Finance, and Legal. For each domain, it provides three key metrics: Average Answer Relevancy, Summarization Score (Legal domain only), and Factual Score (Finance domain only). Answer Relevancy assesses how well the model’s responses match the expected answers, reflecting accuracy and context. Summarization Score measures the quality and completeness of summaries produced by the model. Factual Score evaluates the correctness of facts in the model’s output, indicating how effectively it extracts and reproduces crucial details from the input. Scores closer to 1.0 indicate better model performance in each respective task.
read the caption
Table 2: Average Answer Relevancy score of Shakti-250M model across domains as mentioned, Summarization score for Shakti-250M model for Legal domain, Average Factual Score for Finance domain.Answer Relevancy: Answer relevancy measures the degree to which the model-generated response aligns with the expected or correct answer, reflecting its accuracy and contextual relevance.Summarization Score: Summarization Score calculates the alignment and coverage of the summary generated for the input.Factual Score: Factual Score evaluates the correctness of factual information in the model’s output, measuring how well it captures and reproduces essential details from the input. A score near to 1 indicates better performance of the model in the respective task.
| Dataset | Accuracy of Shakti-250M | Accuracy of Shakti-500M |
|---|---|---|
| BBQ Average | 50.2 | 54.08 |
| Toxigen | 47.5 | 51.5 |
| ImplicitHate | 63 | 69.04 |
🔼 This table presents the performance of Shakti-250M and Shakti-500M models on three benchmark datasets designed to evaluate bias and toxicity in language models: Bias Benchmark for QA (BBQ), ToxiGen, and Implicit Hate Speech. Higher accuracy scores reflect a better ability of the model to avoid generating biased or harmful outputs, demonstrating alignment with responsible AI practices. The BBQ dataset assesses biases related to gender, race, and religion. ToxiGen focuses on detecting both explicit and implicit hate speech. The Implicit Hate Speech dataset specifically evaluates the model’s ability to identify nuanced forms of hateful language. The results show how the larger Shakti-500M model generally outperforms the smaller Shakti-250M model in terms of accuracy on these important benchmarks, highlighting the importance of model size and training in mitigating bias and toxicity.
read the caption
Table 3: Accuracy scores of the Shakti models on Bias Benchmark for QA (BBQ), ToxiGen, and Implicit Hate Speech datasets. Higher accuracy indicates the model’s improved ability to mitigate biases, detect nuanced toxicity, and accurately classify implicit hate speech, showcasing alignment with Responsible AI principles.
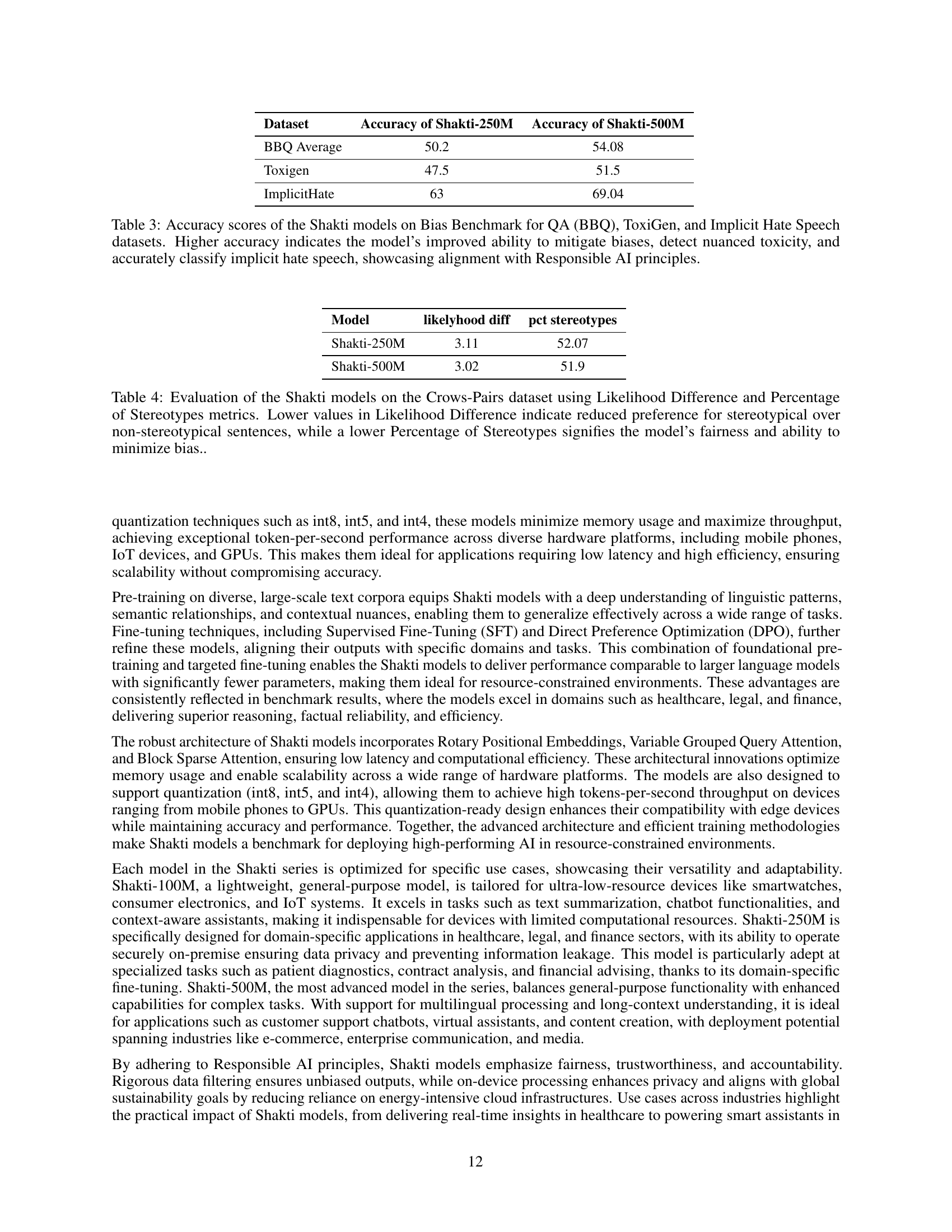
| Model | likelyhood diff | pct stereotypes |
|---|---|---|
| Shakti-250M | 3.11 | 52.07 |
| Shakti-500M | 3.02 | 51.9 |
🔼 Table 4 presents the results of evaluating the Shakti-250M and Shakti-500M models for bias using the CrowS-Pairs dataset. The CrowS-Pairs dataset assesses the tendency of language models to exhibit stereotypical biases. The table reports two key metrics: Likelihood Difference and Percentage of Stereotypes. A lower Likelihood Difference score indicates that the model shows less of a preference for stereotypical sentences compared to non-stereotypical sentences. A lower Percentage of Stereotypes score signifies that the model is less likely to generate stereotypical statements. Lower scores on both metrics suggest better fairness and bias mitigation in the model.
read the caption
Table 4: Evaluation of the Shakti models on the Crows-Pairs dataset using Likelihood Difference and Percentage of Stereotypes metrics. Lower values in Likelihood Difference indicate reduced preference for stereotypical over non-stereotypical sentences, while a lower Percentage of Stereotypes signifies the model’s fairness and ability to minimize bias..
Full paper#