TL;DR#
Large Language Models rely on human-annotated preference data, which limits their performance. Self-Rewarding methods aim to overcome this by having LLMs generate training data and reward their own outputs. However, existing methods struggle with complex mathematical reasoning tasks and can even degrade performance. There are two main limitations in the framework: (a) algorithm can’t provide fine-grained rewards for reasoning tasks; (b) hard to design criterion for complex solution to get scores.
This paper introduces Process-based Self-Rewarding Language Models, incorporating step-wise LLM-as-a-Judge and preference optimization. It addresses the limitations of existing methods by enabling fine-grained evaluation of reasoning steps and step-wise preference optimization using the model itself as a reward model. Experiments on mathematical reasoning benchmarks demonstrate enhanced performance and potential for superhuman reasoning.
Key Takeaways#
Why does it matter?#
This paper introduces a novel approach to self-rewarding language models. It’s relevant due to its potential to surpass human-level reasoning in mathematical tasks. By focusing on fine-grained, step-wise self-evaluation, the proposed method addresses limitations of existing self-rewarding techniques, opening new avenues for AI research.
Visual Insights#

🔼 This figure illustrates the Process-based Self-Rewarding paradigm. It begins with obtaining two types of data: EFT data (obtained through tree search, initial data filtering, and annotation) and IFT data (created by segmenting solution steps). The model is initialized using both datasets. Then, a step-by-step process unfolds: The model performs search-based reasoning, uses an LLM-as-a-Judge to select the best reasoning step and create pairwise preference data, and finally, undergoes step-wise preference optimization. This entire cycle is then repeated for iterative model improvement.
read the caption
Figure 1: Illustration of our Process-based Self-Rewarding paradigm. (1) We get EFT data by tree-search, initial data filtering and data annotation. And we get IFT data by step segmentation. (2) The model is initialized on EFT and IFT data. (3) The model conducts step-by-step search-based reasoning and performs step-wise LLM-as-a-Judge to select the chosen step and generate the step-wise preference pair at each step. (4) We perform step-wise preference optimization on the model. (5) The model enters the next iteration cycle.
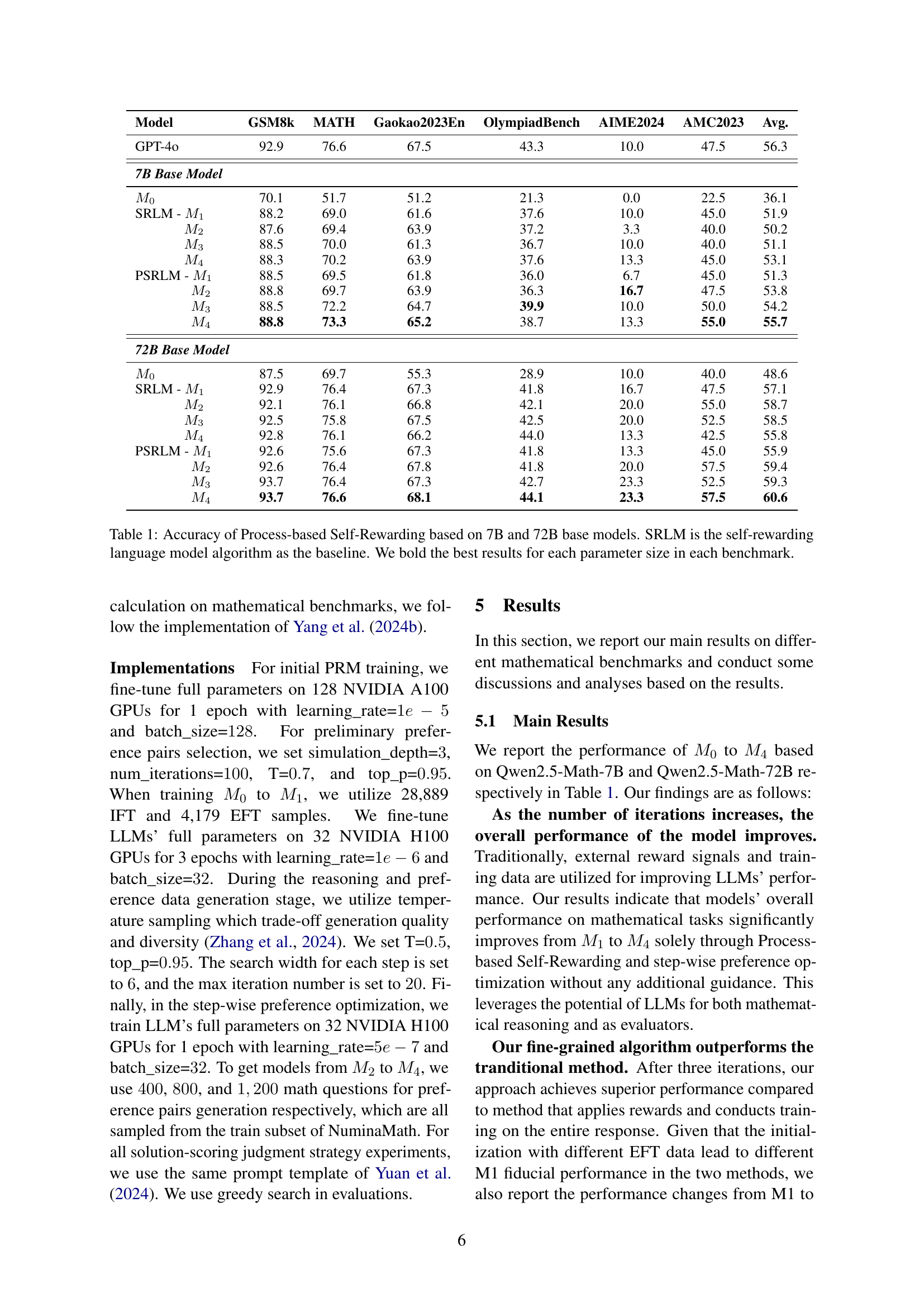
| Model | GSM8k | MATH | Gaokao2023En | OlympiadBench | AIME2024 | AMC2023 | Avg. |
|---|---|---|---|---|---|---|---|
| GPT-4o | 92.9 | 76.6 | 67.5 | 43.3 | 10.0 | 47.5 | 56.3 |
| 7B Base Model | |||||||
| 70.1 | 51.7 | 51.2 | 21.3 | 0.0 | 22.5 | 36.1 | |
| SRLM - | 88.2 | 69.0 | 61.6 | 37.6 | 10.0 | 45.0 | 51.9 |
| 87.6 | 69.4 | 63.9 | 37.2 | 3.3 | 40.0 | 50.2 | |
| 88.5 | 70.0 | 61.3 | 36.7 | 10.0 | 40.0 | 51.1 | |
| 88.3 | 70.2 | 63.9 | 37.6 | 13.3 | 45.0 | 53.1 | |
| PSRLM - | 88.5 | 69.5 | 61.8 | 36.0 | 6.7 | 45.0 | 51.3 |
| 88.8 | 69.7 | 63.9 | 36.3 | 16.7 | 47.5 | 53.8 | |
| 88.5 | 72.2 | 64.7 | 39.9 | 10.0 | 50.0 | 54.2 | |
| 88.8 | 73.3 | 65.2 | 38.7 | 13.3 | 55.0 | 55.7 | |
| 72B Base Model | |||||||
| 87.5 | 69.7 | 55.3 | 28.9 | 10.0 | 40.0 | 48.6 | |
| SRLM - | 92.9 | 76.4 | 67.3 | 41.8 | 16.7 | 47.5 | 57.1 |
| 92.1 | 76.1 | 66.8 | 42.1 | 20.0 | 55.0 | 58.7 | |
| 92.5 | 75.8 | 67.5 | 42.5 | 20.0 | 52.5 | 58.5 | |
| 92.8 | 76.1 | 66.2 | 44.0 | 13.3 | 42.5 | 55.8 | |
| PSRLM - | 92.6 | 75.6 | 67.3 | 41.8 | 13.3 | 45.0 | 55.9 |
| 92.6 | 76.4 | 67.8 | 41.8 | 20.0 | 57.5 | 59.4 | |
| 93.7 | 76.4 | 67.3 | 42.7 | 23.3 | 52.5 | 59.3 | |
| 93.7 | 76.6 | 68.1 | 44.1 | 23.3 | 57.5 | 60.6 |
🔼 This table presents the accuracy results of different language models on several mathematical reasoning benchmarks. The models tested include 7B and 72B parameter base models, along with variations using the Self-Rewarding Language Model (SRLM) algorithm and the proposed Process-based Self-Rewarding approach. The table shows the accuracy of each model across multiple iterations (M1 to M4) of the Process-based Self-Rewarding method. The best accuracy for each benchmark and parameter size is highlighted in bold, allowing for easy comparison between the models and approaches. SRLM is used as a baseline for comparison. This detailed analysis helps to evaluate the effectiveness of the proposed method for enhancing the mathematical reasoning capabilities of large language models.
read the caption
Table 1: Accuracy of Process-based Self-Rewarding based on 7B and 72B base models. SRLM is the self-rewarding language model algorithm as the baseline. We bold the best results for each parameter size in each benchmark.
In-depth insights#
Stepwise Reward#
The concept of “Stepwise Reward” signifies a refined approach to reinforcing desired behaviors in language models, particularly within complex tasks. Traditional reward mechanisms often evaluate the final output, neglecting the quality of intermediate reasoning. Stepwise reward, conversely, assesses and reinforces each step within a multi-stage process. This fine-grained approach enables the model to learn from its successes and failures at each juncture, leading to more robust and accurate reasoning. It addresses the limitation where a correct final answer might mask flawed intermediate steps or vice versa. By incentivizing correct steps, it encourages exploration of more valid reasoning paths. The design of effective stepwise reward functions is crucial, possibly using techniques where the model judges its own intermediate steps. Furthermore, it aligns the learning process more closely with human problem-solving strategies where each sub-goal is accomplished before moving onto the next. By rewarding each step, models can achieve superior mathematical reasoning skills.
LLM as a Judge#
LLMs as judges present a cost-effective and scalable solution for evaluating text. They mimic human reasoning but require careful prompting to align with preferences. Challenges involve ensuring consistency and mitigating biases, as well as the need for training with preference data. The approach involves prompting LLMs to reason and evaluate inputs against predefined rules, offering a adaptable alternative to human evaluation, the need for meticulous prompting and alignment with human preferences to ensure fairness and accuracy is essential. Evaluating intermediate steps rather than final answers enables more fine-grained and accurate rewards, overcoming a key limitation in existing self-rewarding methods where complex reasoning tasks are challenging to assess with a single overall score. It is crucial for effective self-improvement in tasks that require detailed reasoning and multi-step solutions, especially in the mathematical domain.
Iterative Training#
Iterative training is a crucial aspect for enhancing LLMs. The process involves continuously refining the model by feeding it back its own outputs as new training data. This approach leverages the model’s ability to learn from its mistakes and improve its generation quality over successive iterations. The process refines the initial model which leads to an improvement in overall task performance. For complex tasks that require long-thought reasoning capabilities. This iterative self-improvement can lead to models that surpass human-level performance in specific domains. The model’s ability to perform LLM-as-a-Judge plays a key role in iteratively training the model. It is important to note that high-quality data is needed for the iterative training to be useful.
Reasoning Focus#
Reasoning focus is central to advancing language models. The paper emphasizes enhancing mathematical reasoning through a novel, process-based self-rewarding framework. It highlights the limitations of existing self-rewarding paradigms, especially in complex, multi-step reasoning. Therefore, the research pivots to focus on step-wise reasoning, step-wise LLM-as-a-Judge, and step-wise preference optimization. This involves breaking down complex problems, evaluating intermediate steps and iteratively refining preferences. The core idea is that a model can learn not only to produce correct final answers but also generate accurate intermediate steps, thereby improving the overall reasoning ability and aligning it closer to human-level cognitive processes. The reasoning focus contributes to improving LLMs on a wide range of mathematical tasks.
Beyond Human?#
The concept of AI surpassing human capabilities is a fascinating one, often framed as a ‘Beyond Human?’ scenario. It prompts us to consider the very definition of intelligence and the potential for AI to evolve in ways we cannot fully predict. Current AI systems excel at specific tasks, often outperforming humans in areas like data analysis and pattern recognition. However, true general intelligence remains elusive. The ethical implications of AI exceeding human abilities are profound, raising questions about control, autonomy, and the future of work. If AI can design better AI, where does the cycle end? While the idea of AI ’thinking’ in the same way as humans is still debated, the continued advancement of AI necessitates careful consideration of its potential impact on society and the human condition. We must strive to develop AI that aligns with human values and promotes a beneficial future for all.
More visual insights#
More on figures

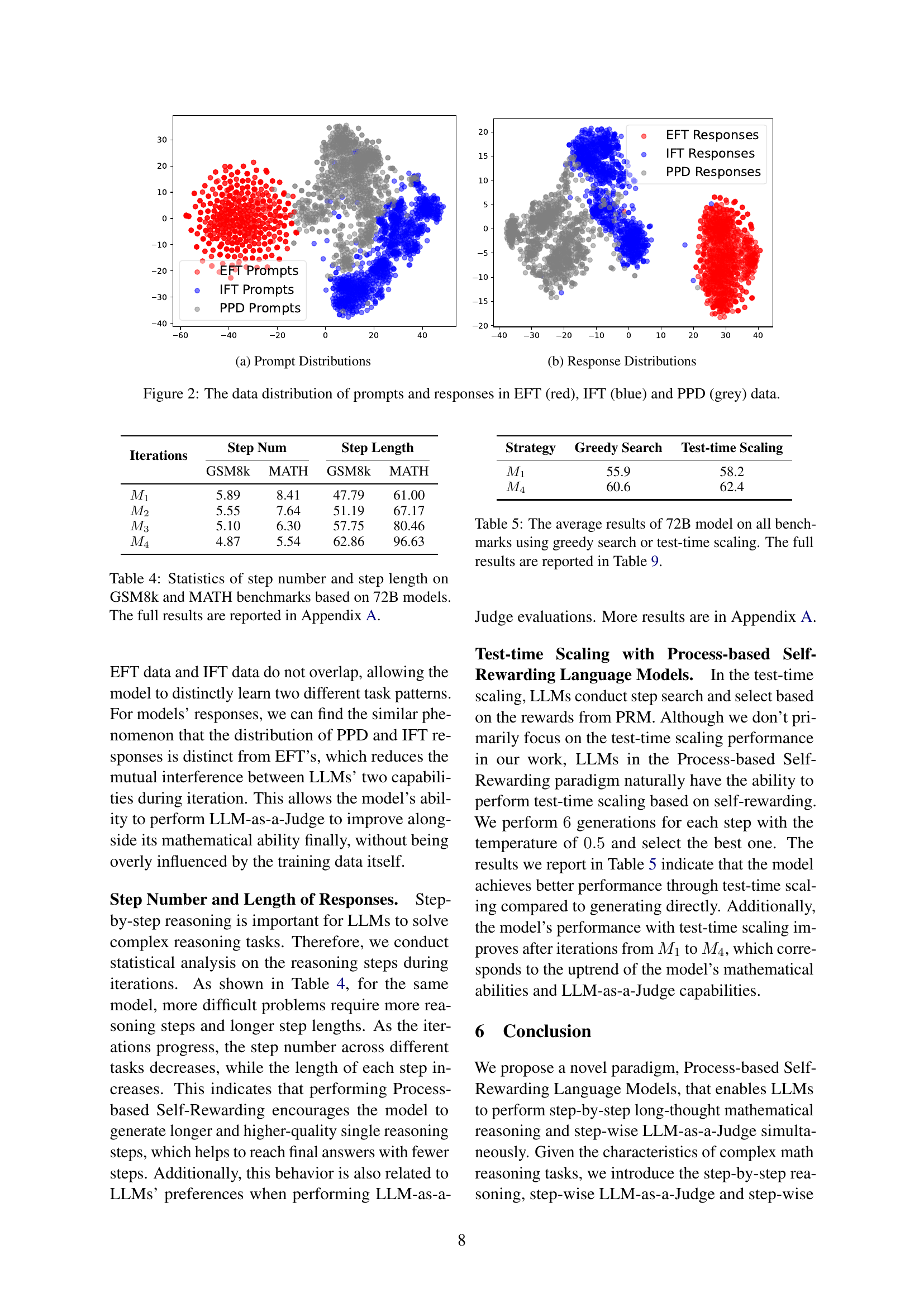
🔼 This figure visualizes the distribution of prompts and responses from three different datasets: EFT (red), IFT (blue), and PPD (grey). The left panel (a) shows the distribution of prompts, while the right panel (b) shows the distribution of the model’s responses. The visualization helps to understand how the data from each source differs and how this difference might influence the model’s learning process during iterative training. EFT data is for model evaluation, IFT data is for model initialization, and PPD data is the generated data from the process-based self-rewarding pipeline.
read the caption
(a) Prompt Distributions
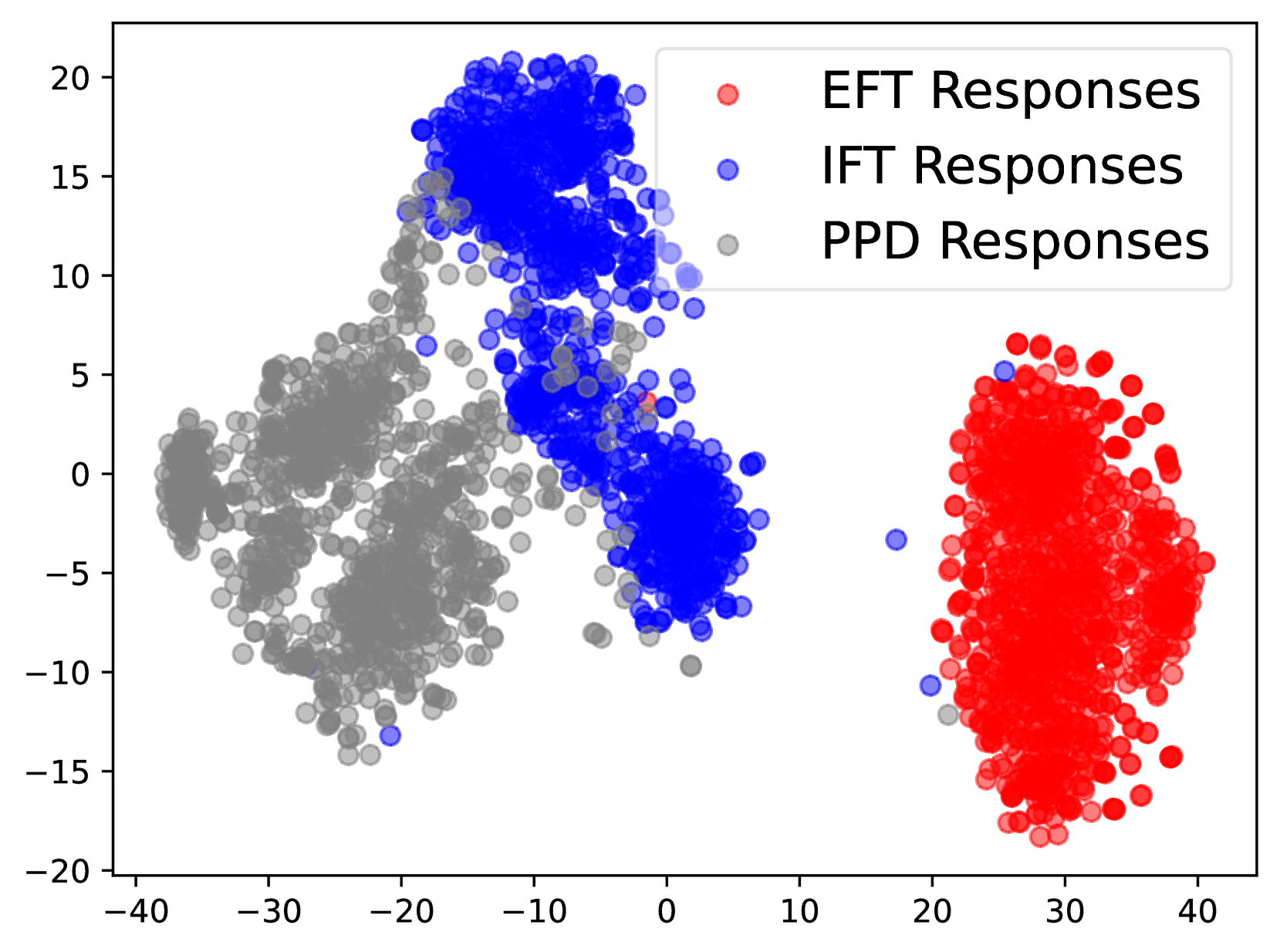
🔼 This figure visualizes the distribution of responses generated by the model during different stages of training. Specifically, it compares the response distributions of the model’s initial outputs (EFT), intermediate outputs (IFT), and outputs generated during process-based self-rewarding optimization (PPD). By comparing these distributions, we can observe how the model’s response patterns evolve throughout the training process, providing insights into the effectiveness of the self-rewarding mechanism.
read the caption
(b) Response Distributions

🔼 This figure visualizes the distribution of prompts and responses from three different datasets: EFT (Evaluation Fine-Tuning), IFT (Instruction Fine-Tuning), and PPD (Pair-wise Preference Data). The visualization helps illustrate how the data points cluster and whether there’s significant overlap or separation between the datasets. This is useful for understanding how the model’s training data is structured and might influence its performance.
read the caption
Figure 2: The data distribution of prompts and responses in EFT (red), IFT (blue) and PPD (grey) data.

🔼 This figure displays the prompt used to instruct the model to convert a given solution into a step-by-step format. The prompt explicitly instructs the model to maintain the original information and only separate the solution into logical steps, each prefixed with ‘Step n:’, where n represents the step number.
read the caption
Figure 3: The prompt for converting the the given solution into step-by-step format logically without altering any information in the original solution.

🔼 This figure shows the prompt template used for the step-by-step long-thought reasoning task in the Process-based Self-Rewarding Language Model experiments. The prompt instructs the LLM to solve a given math problem step-by-step, clearly labeling each reasoning step with the prefix ‘Step n:’, where n is a positive integer. The final answer should be enclosed in boxes. This approach encourages the LLM to break down complex problems into smaller, manageable steps, improving the reasoning process and reducing the chance of errors.
read the caption
Figure 4: The prompt for LLMs conducting step-by-step long-thought reasoning.
More on tables
| 7B | GSM8k | MATH | Gaokao2023En | OlympiadBench | AIME2024 | AMC2023 |
|---|---|---|---|---|---|---|
| SRLM | +0.1 | +1.2 | +2.3 | 0.0 | +3.3 | 0.0 |
| Process-based (Ours) | +0.3 | +3.8 | +3.4 | +2.7 | +6.6 | +10.0 |
| 72B | GSM8k | MATH | Gaokao2023En | OlympiadBench | AIME2024 | AMC2023 |
| SRLM | -0.1 | -0.3 | -1.1 | +2.2 | -3.4 | -5.0 |
| Process-based (Ours) | +1.1 | +1.0 | +0.8 | +2.3 | +10.0 | +12.5 |
🔼 This table presents the changes in the mathematical performance of Large Language Models (LLMs) after iterative training using the Process-based Self-Rewarding method. It shows the improvements across multiple benchmarks (GSM8K, MATH, Gaokao2023En, OlympiadBench, AIME2024, AMC2023) for both 7B and 72B parameter models after each iteration from M1 to M4. The improvements are expressed as the difference in performance compared to the baseline Self-Rewarding Language Model (SRLM). Positive values indicate improvements, while negative values indicate performance degradation.
read the caption
Table 2: The results of LLMs’ mathematical performance changes after all iterations from M1subscript𝑀1M_{1}italic_M start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT to M4subscript𝑀4M_{4}italic_M start_POSTSUBSCRIPT 4 end_POSTSUBSCRIPT.
| Model | 7B | 72B |
|---|---|---|
| (3-shot) | 57.2 | 73.4 |
| 92.8 () | 95.6 () | |
| 91.6 () | 95.8 () | |
| 92.0 () | 95.2 () | |
| 92.2 () | 95.6 () |
🔼 This table presents the accuracy of the step-wise LLM-as-a-Judge model across different iterations. It shows how well the model, acting as a judge, evaluates the quality of reasoning steps produced by another LLM. The results are broken down by model size (7B and 72B parameters) and iteration number, providing a clear view of the model’s performance improvement throughout the iterative process. Arrows indicate whether the accuracy increased (↑) or decreased (↓) between iterations for each model size.
read the caption
Table 3: Judgment accuracy in step-wise LLM-as-a-Judge. We report the results of models with different parameter sizes. Additionally, we use arrows to indicate the changes in accuracy during the iterations.
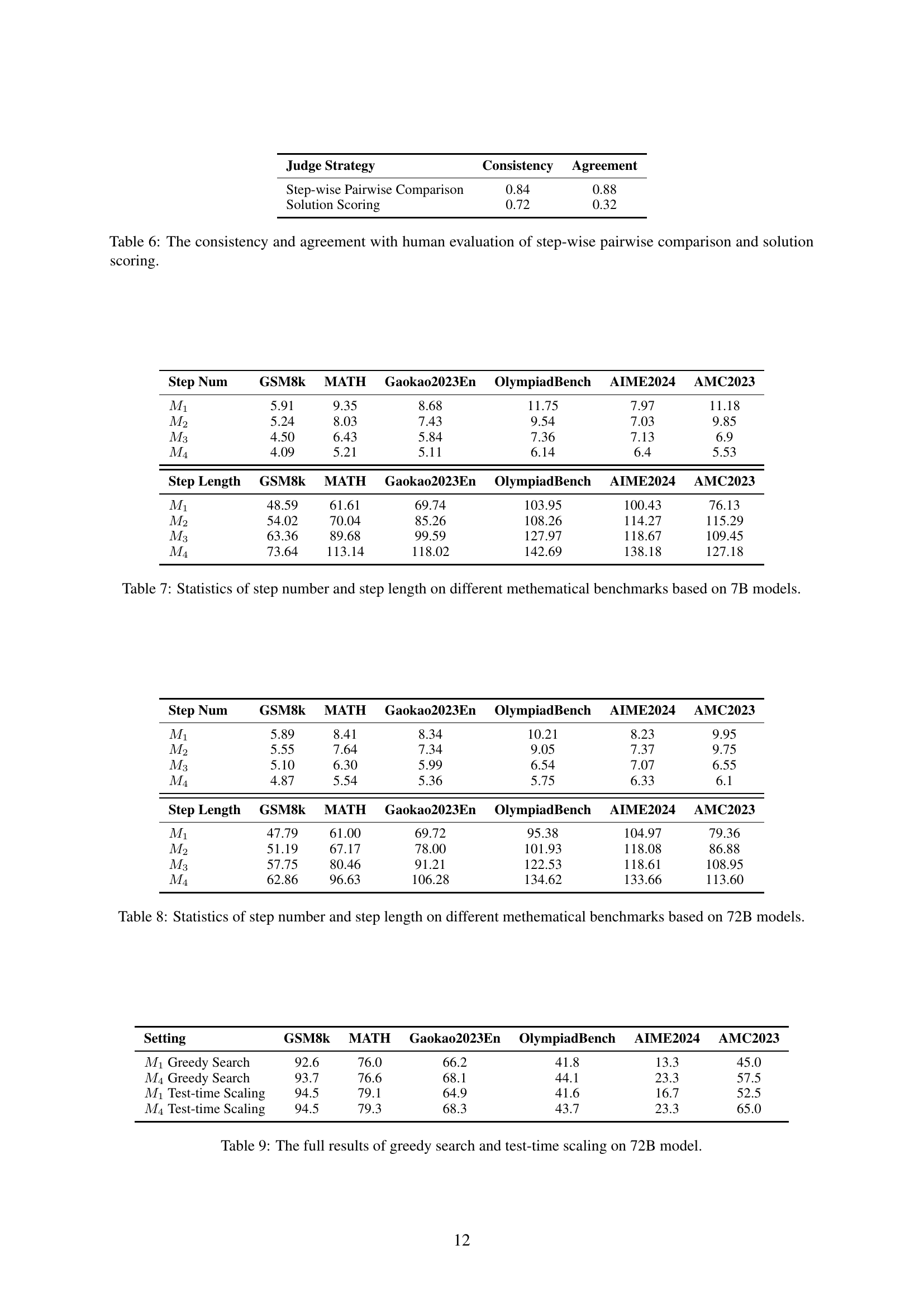
| Iterations | Step Num | Step Length | ||
|---|---|---|---|---|
| GSM8k | MATH | GSM8k | MATH | |
| 5.89 | 8.41 | 47.79 | 61.00 | |
| 5.55 | 7.64 | 51.19 | 67.17 | |
| 5.10 | 6.30 | 57.75 | 80.46 | |
| 4.87 | 5.54 | 62.86 | 96.63 | |
🔼 This table presents a statistical analysis of the number of reasoning steps and the average length of each step generated by the 72B parameter model when solving problems from the GSM8K and MATH benchmark datasets. It shows how these metrics vary across different problem types and model iterations, offering insights into the efficiency and complexity of the model’s reasoning process. More detailed results for all benchmarks and model sizes are available in Appendix A.
read the caption
Table 4: Statistics of step number and step length on GSM8k and MATH benchmarks based on 72B models. The full results are reported in Appendix A.
| Strategy | Greedy Search | Test-time Scaling |
|---|---|---|
| 55.9 | 58.2 | |
| 60.6 | 62.4 |
🔼 This table presents the average performance of the 72B parameter model on various mathematical reasoning benchmarks. The performance is evaluated using two different search strategies: greedy search and test-time scaling. Test-time scaling allows the model to utilize more time and resources during inference, potentially improving accuracy. The table shows the average scores across all benchmarks for both search methods, with the complete results detailed in Table 9 of the paper. This provides a comparison of model efficiency and accuracy when employing different search techniques.
read the caption
Table 5: The average results of 72B model on all benchmarks using greedy search or test-time scaling. The full results are reported in Table 9.
| Judge Strategy | Consistency | Agreement |
|---|---|---|
| Step-wise Pairwise Comparison | 0.84 | 0.88 |
| Solution Scoring | 0.72 | 0.32 |
🔼 This table presents a comparison of two different methods used for evaluating the quality of large language model (LLM) responses in mathematical reasoning tasks: step-wise pairwise comparison and solution scoring. It shows the consistency and agreement of these methods with human evaluations, indicating which approach aligns better with human judgment in determining the quality of complex mathematical reasoning steps.
read the caption
Table 6: The consistency and agreement with human evaluation of step-wise pairwise comparison and solution scoring.
| Step Num | GSM8k | MATH | Gaokao2023En | OlympiadBench | AIME2024 | AMC2023 |
|---|---|---|---|---|---|---|
| 5.91 | 9.35 | 8.68 | 11.75 | 7.97 | 11.18 | |
| 5.24 | 8.03 | 7.43 | 9.54 | 7.03 | 9.85 | |
| 4.50 | 6.43 | 5.84 | 7.36 | 7.13 | 6.9 | |
| 4.09 | 5.21 | 5.11 | 6.14 | 6.4 | 5.53 | |
| Step Length | GSM8k | MATH | Gaokao2023En | OlympiadBench | AIME2024 | AMC2023 |
| 48.59 | 61.61 | 69.74 | 103.95 | 100.43 | 76.13 | |
| 54.02 | 70.04 | 85.26 | 108.26 | 114.27 | 115.29 | |
| 63.36 | 89.68 | 99.59 | 127.97 | 118.67 | 109.45 | |
| 73.64 | 113.14 | 118.02 | 142.69 | 138.18 | 127.18 |
🔼 This table presents a statistical analysis of the number of reasoning steps and the average length of each step generated by the 7B parameter model across various mathematical reasoning benchmarks. The benchmarks include GSM8K, MATH, Gaokao2023En, OlympiadBench, AIME2024, and AMC2023. The data is broken down by model iteration (M1 through M4), illustrating how these metrics change as the model undergoes iterative self-rewarding training.
read the caption
Table 7: Statistics of step number and step length on different methematical benchmarks based on 7B models.
| Step Num | GSM8k | MATH | Gaokao2023En | OlympiadBench | AIME2024 | AMC2023 |
|---|---|---|---|---|---|---|
| 5.89 | 8.41 | 8.34 | 10.21 | 8.23 | 9.95 | |
| 5.55 | 7.64 | 7.34 | 9.05 | 7.37 | 9.75 | |
| 5.10 | 6.30 | 5.99 | 6.54 | 7.07 | 6.55 | |
| 4.87 | 5.54 | 5.36 | 5.75 | 6.33 | 6.1 | |
| Step Length | GSM8k | MATH | Gaokao2023En | OlympiadBench | AIME2024 | AMC2023 |
| 47.79 | 61.00 | 69.72 | 95.38 | 104.97 | 79.36 | |
| 51.19 | 67.17 | 78.00 | 101.93 | 118.08 | 86.88 | |
| 57.75 | 80.46 | 91.21 | 122.53 | 118.61 | 108.95 | |
| 62.86 | 96.63 | 106.28 | 134.62 | 133.66 | 113.60 |
🔼 This table presents a statistical overview of the step number and step length observed in the responses generated by the 72B parameter model across various mathematical reasoning benchmarks. For each benchmark, the table shows the average number of steps and average length of each step for four different iterations (M1 through M4) of the Process-based Self-Rewarding model. This data provides insight into how the model’s reasoning process evolves over iterative refinement.
read the caption
Table 8: Statistics of step number and step length on different methematical benchmarks based on 72B models.
| Setting | GSM8k | MATH | Gaokao2023En | OlympiadBench | AIME2024 | AMC2023 |
|---|---|---|---|---|---|---|
| Greedy Search | 92.6 | 76.0 | 66.2 | 41.8 | 13.3 | 45.0 |
| Greedy Search | 93.7 | 76.6 | 68.1 | 44.1 | 23.3 | 57.5 |
| Test-time Scaling | 94.5 | 79.1 | 64.9 | 41.6 | 16.7 | 52.5 |
| Test-time Scaling | 94.5 | 79.3 | 68.3 | 43.7 | 23.3 | 65.0 |
🔼 This table presents a comprehensive evaluation of a 72B parameter language model’s performance on six mathematical reasoning benchmarks using two different search strategies: greedy search and test-time scaling. For each benchmark and search strategy, the accuracy is reported for two model states: M1 (after the initial fine-tuning and process-based self-rewarding iteration) and M4 (after several additional iterations). This allows for a direct comparison of the model’s performance improvement throughout the iterative process of the Process-based Self-Rewarding algorithm and showcases the impact of the test-time scaling strategy on the final performance.
read the caption
Table 9: The full results of greedy search and test-time scaling on 72B model.
Full paper#