TL;DR#
Large Language Models (LLMs) often appear more capable in reasoning tasks than they truly are because they memorize evaluation benchmarks. This paper highlights the problem of overestimating LLM reasoning skills due to data exposure. The research addresses this issue by introducing a new framework for creating linguistic reasoning problems that minimize the impact of memorization on performance estimates.
The authors introduce LINGOLY-TOO, a benchmark designed to challenge LLMs’ linguistic reasoning abilities. By using orthographic templates, they dynamically obfuscate writing systems of real languages, generating numerous question variations. These variations maintain the reasoning steps needed for solutions but reduce the chances of specific problem instances appearing in training data. Experiments show that even state-of-the-art models struggle, revealing prior data exposure inflates reasoning skills.
Key Takeaways#
Why does it matter?#
This paper addresses the critical issue of overestimation in LLM reasoning capabilities due to data exposure. It introduces a novel benchmark, offering a more accurate evaluation and paving the way for future research into genuinely robust and generalizable AI systems.
Visual Insights#

🔼 The figure illustrates the framework for creating the LINGOLY-TOO benchmark. It begins with an original linguistic reasoning problem from the UK Linguistics Olympiad. This problem undergoes annotation, where irrelevant metadata is removed while preserving the problem’s solvability. Then, an orthographic template is developed. This template defines rules for systematically altering the writing system of the original language (the Problemese) while maintaining the underlying linguistic structure and reasoning steps needed to solve the problem. Finally, multiple obfuscated versions of the problem are generated by applying different permutations based on the orthographic template. This process creates many variations of the same problem, reducing the likelihood that specific problem instances have been seen by language models during training.
read the caption
Figure 1: LingOly-TOO benchmark overview. Framework for developing LingOly-TOO, starting from an original problem, annotating it and developing its orthographic template to generate several obfuscations.
| Model | Answer | ||
|---|---|---|---|
| GPT-4o | Digit | 0.16 | 0.08 |
| Other | 0.07 | 0.01 | |
| Single Char | 0.03 | 0.03 | |
| Y/N | 0.62 | 0.31 | |
| Llama-3.3-70B | Digit | 0.19 | 0.11 |
| Other | 0.02 | 0.01 | |
| Single Char | 0.05 | 0.04 | |
| Y/N | 0.19 | 0.49 |
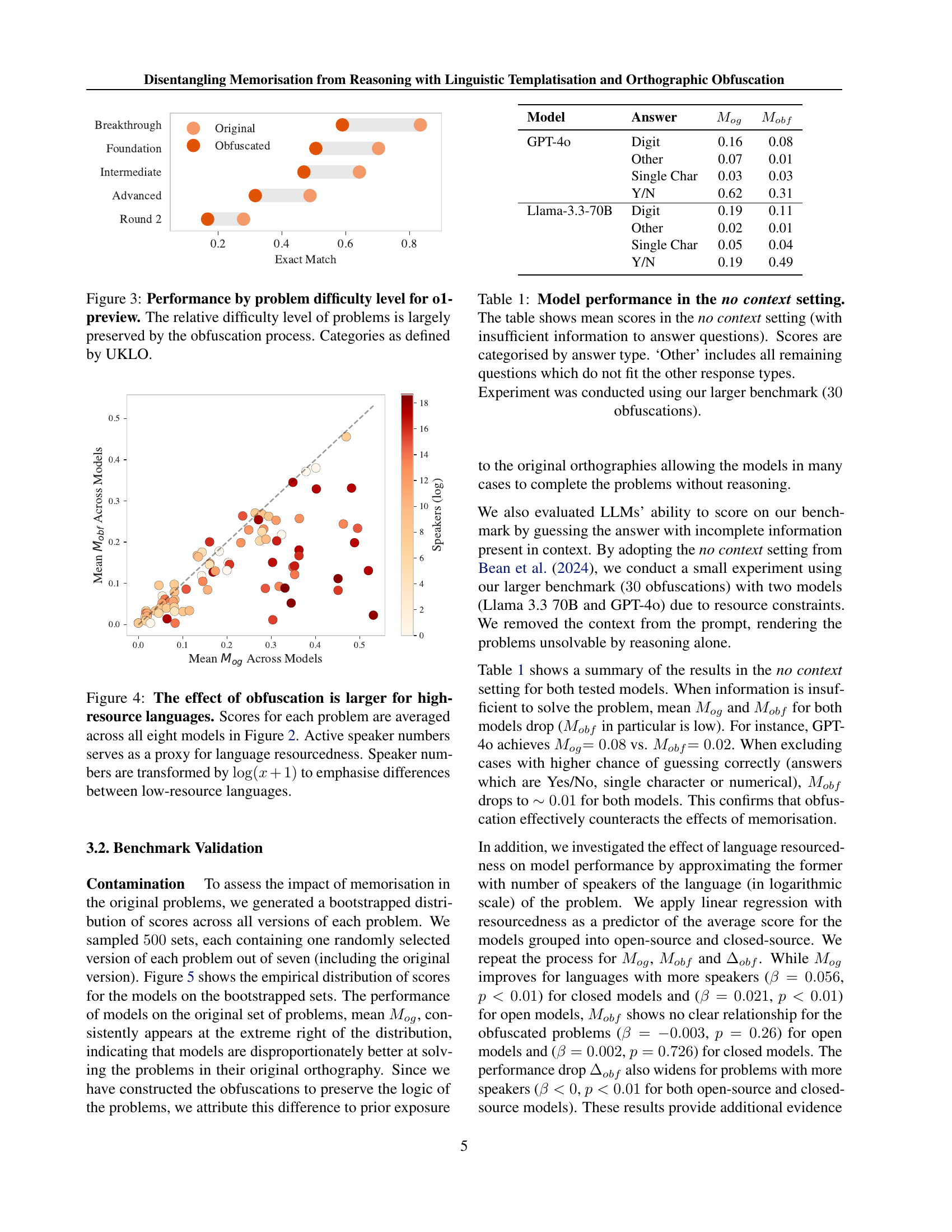
🔼 This table presents the results of an experiment evaluating the performance of large language models (LLMs) in a ’no context’ setting, meaning that insufficient information was provided to answer questions. The models’ performance is broken down by the type of answer required (digit, other, single character, yes/no), illustrating their ability to answer questions without relying on the context provided. The ‘Other’ category encompasses any question that doesn’t fall into the other categories. This helps isolate the models’ inherent capabilities versus their capacity to use the given context.
read the caption
Table 1: Model performance in the no context setting. The table shows mean scores in the no context setting (with insufficient information to answer questions). Scores are categorised by answer type. ‘Other’ includes all remaining questions which do not fit the other response types.
In-depth insights#
Linguistics+Obfus#
Linguistic obfuscation is a key strategy to disentangle memorization from true reasoning in LLMs. By applying orthographic and ruleset based transformations to the Problemese data, this approach aims to create novel problem instances that preserve the underlying linguistic structure and reasoning steps. The goal is to prevent LLMs from relying on memorized solutions, forcing them to generalize and apply learned rules to unseen inputs. The success hinges on designing obfuscation techniques that do not inadvertently alter the problem’s difficulty or render it unsolvable. Manual annotation and external validation are implemented to ensure that reasoning element is preserved while the new variations still align. Moreover, comparing model performance on original vs. obfuscated versions provides insight into the extent to which models rely on memorization.
Lingoly Benchmark#
While “Lingoly Benchmark” isn’t explicitly a heading, the paper introduces LINGOLY-TOO, a benchmark designed to evaluate linguistic reasoning in LLMs. LINGOLY-TOO aims to disentangle memorization from genuine reasoning by using orthographic templatization to dynamically obfuscate languages, creating unseen linguistic problems. The benchmark leverages Linguistics Olympiad problems and generates numerous question variations, preserving reasoning steps while reducing memorization risk. By evaluating LLMs on these obfuscated problems, the paper provides a more robust assessment of reasoning abilities. This approach addresses the limitations of existing benchmarks susceptible to data contamination and overestimation of model performance due to prior exposure.
Tokenisation Imp#
The paper explores the impact of tokenization on LLMs’ performance in linguistic reasoning, particularly when dealing with obfuscated languages. Standard tokenization methods might inadvertently assist models by preserving sub-word units. Alternative tokenization strategies (dash or character-level) reduce model performance, indicating that the models rely on token frequencies learned during pre-training. Further research on advanced tokenization techniques could reduce their reliance, and improve generalization.
Data Exposure#
Data exposure in LLMs significantly inflates perceived reasoning abilities. If models encounter benchmark data during pre-training, they can memorize solutions rather than truly reasoning. This contamination undermines the validity of benchmarks. Techniques to mitigate this include using low-resource languages, synthetic data generation, and context removal. The paper’s approach, orthographic obfuscation, reduces the likelihood of memorization by altering the surface form of the language while preserving the underlying reasoning steps. This allows for a more accurate assessment of genuine reasoning capability. Models performed better with questions in their original orthography, suggesting prior data exposure contributed to their performance. The paper also fine-tuned models on a subset of obfuscated problems as training data and observed improvements on unseen obfuscations which also suggests overfitting of obfuscations used for training. Finally, the paper shows linear regression results that with the inclusion of resourcefulness as a predictor, there are lower effects of data exposure on model performance.
Human RCT study#
While ‘Human RCT study’ isn’t an exact heading, the paper details a human-conducted, randomized controlled trial (RCT) to validate their linguistic obfuscation approach. The core goal was to ensure that obfuscation, used to mitigate LLM memorization, doesn’t inadvertently alter the inherent reasoning difficulty of the linguistic problems. The RCT involved human participants solving both original and obfuscated versions of linguistics Olympiad problems. The findings indicate a small performance dip for humans on obfuscated tasks, which is theorized due to unfamiliar orthographies causing a perceived increase in difficulty rather than fundamentally changing the reasoning. This implies that the obfuscation method is valid and sound as it was not intended to be unnecessarily more difficult. The study is very important because in order to validate the obfuscation methods that they created are useful, humans needed to be able to answer them correctly without much difficulty and the results showed this. The goal is also to see if humans perform comparably on obfuscated problems.
More visual insights#
More on figures

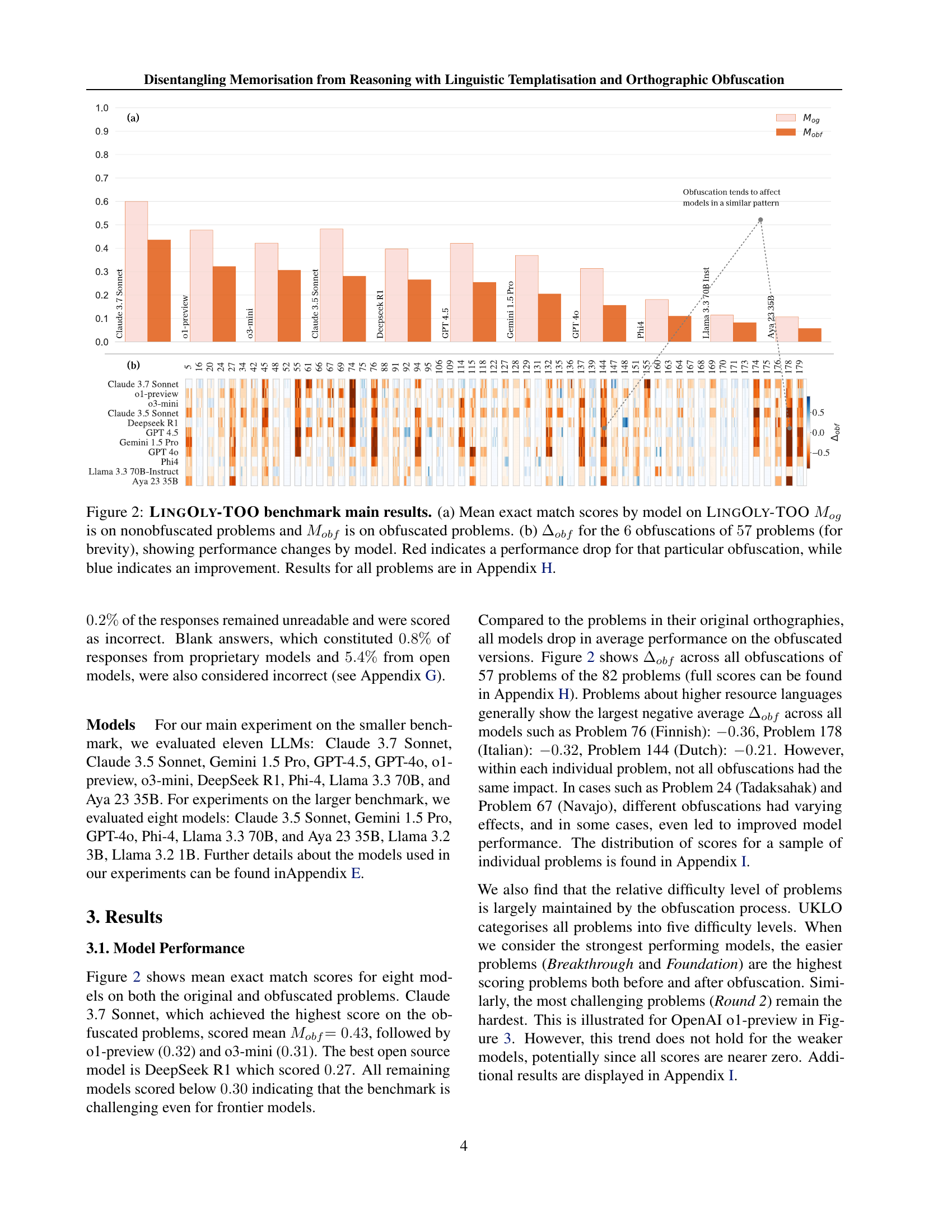
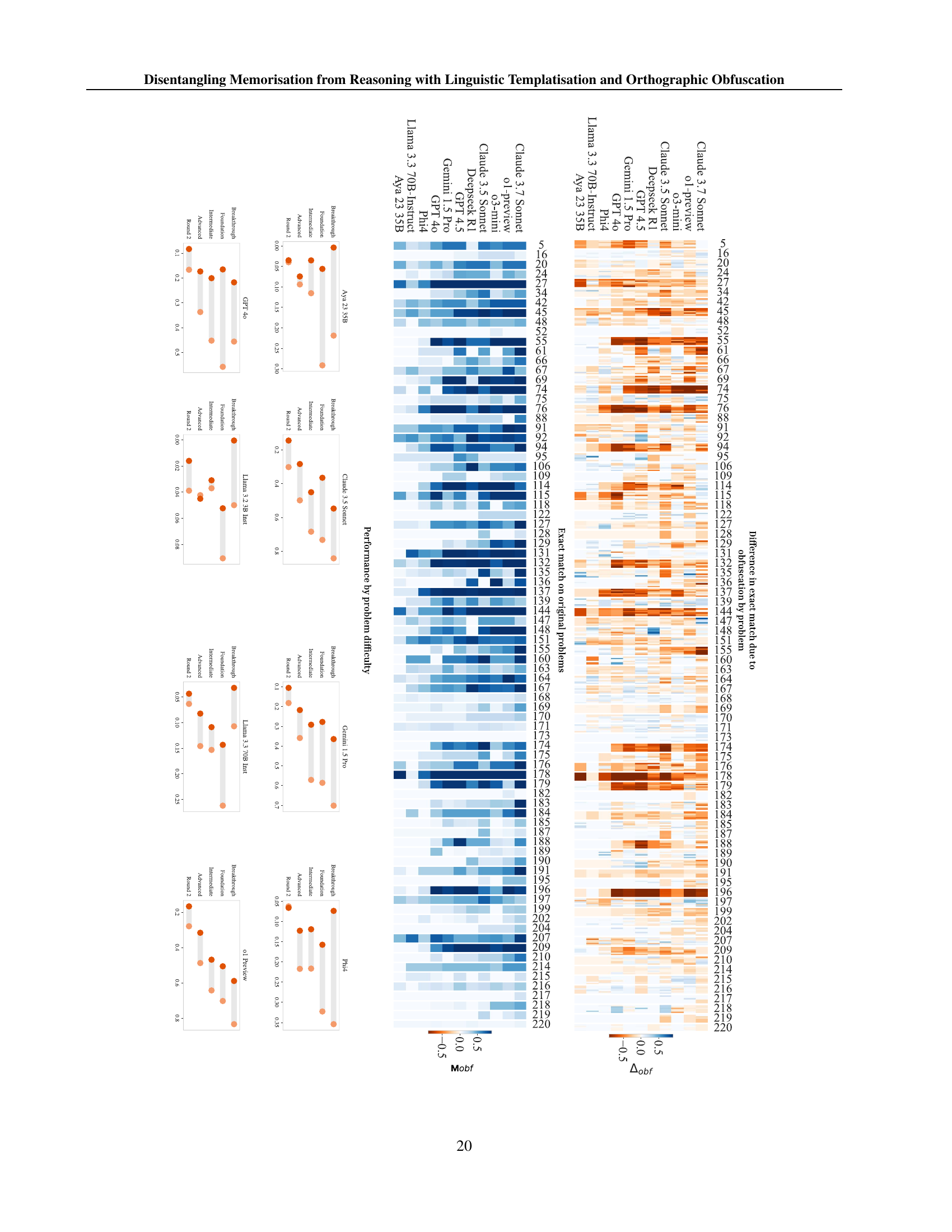
🔼 Figure 2 presents the key results from the LINGOLY-TOO benchmark. Panel (a) shows the average performance of various large language models (LLMs) on the original LINGOLY problems (Mog) and their obfuscated versions (Mobf). The original problems are those from the UK Linguistics Olympiad that were used to create the dataset. The obfuscated versions have had the orthography modified, making them different from the training data and therefore relying more on true reasoning abilities. Panel (b) shows the difference in performance (Δobf) between the original and obfuscated problems for a subset of the problems to illustrate the variation in model performance across different obfuscations. Red indicates a drop in performance, and blue an increase; this highlights how sensitive LLM performance is, even with a small change. Appendix H provides the full results for all problems.
read the caption
Figure 2: LingOly-TOO benchmark main results. (a) Mean exact match scores by model on LingOly-TOO Mogsubscript𝑀𝑜𝑔M_{og}italic_M start_POSTSUBSCRIPT italic_o italic_g end_POSTSUBSCRIPT is on nonobfuscated problems and Mobfsubscript𝑀𝑜𝑏𝑓M_{obf}italic_M start_POSTSUBSCRIPT italic_o italic_b italic_f end_POSTSUBSCRIPT is on obfuscated problems. (b) ΔobfsubscriptΔ𝑜𝑏𝑓\Delta_{obf}roman_Δ start_POSTSUBSCRIPT italic_o italic_b italic_f end_POSTSUBSCRIPT for the 6666 obfuscations of 57575757 problems (for brevity), showing performance changes by model. Red indicates a performance drop for that particular obfuscation, while blue indicates an improvement. Results for all problems are in Appendix H.

🔼 This figure shows the performance of the o1-preview model on the LINGOLY-TOO benchmark, broken down by the difficulty level of the problems. The x-axis represents the problem difficulty level, categorized as Breakthrough, Foundation, Intermediate, Advanced, and Round 2 by the UK Linguistics Olympiad (UKLO). The y-axis shows the exact match score, a measure of model accuracy. The bars show the average exact match score for problems at each difficulty level, comparing the model’s performance on the original (unobfuscated) problems and their obfuscated versions. The figure demonstrates that, despite the obfuscation, the relative difficulty of the problems is largely maintained. Easier problems consistently yield higher scores than harder problems, irrespective of whether the problem is obfuscated or not.
read the caption
Figure 3: Performance by problem difficulty level for o1-preview. The relative difficulty level of problems is largely preserved by the obfuscation process. Categories as defined by UKLO.

🔼 Figure 4 illustrates the impact of orthographic obfuscation on the performance of large language models (LLMs) across different language problems. The x-axis represents the average score on non-obfuscated problems (Mog) across eight LLMs, while the y-axis represents the average score on obfuscated problems (Mobf) for the same models. Each point represents a language problem, and the size of the point reflects the number of active speakers of the language (a proxy for resource abundance). The logarithmic transformation of speaker numbers highlights the differences between low-resource and high-resource languages. The figure shows that the negative impact of obfuscation (difference between Mog and Mobf) is more pronounced for high-resource languages, suggesting that LLMs rely more on memorization for these languages than on actual reasoning capabilities.
read the caption
Figure 4: The effect of obfuscation is larger for high-resource languages. Scores for each problem are averaged across all eight models in Figure 2. Active speaker numbers serves as a proxy for language resourcedness. Speaker numbers are transformed by log(x+1)𝑥1\log(x+1)roman_log ( italic_x + 1 ) to emphasise differences between low-resource languages.

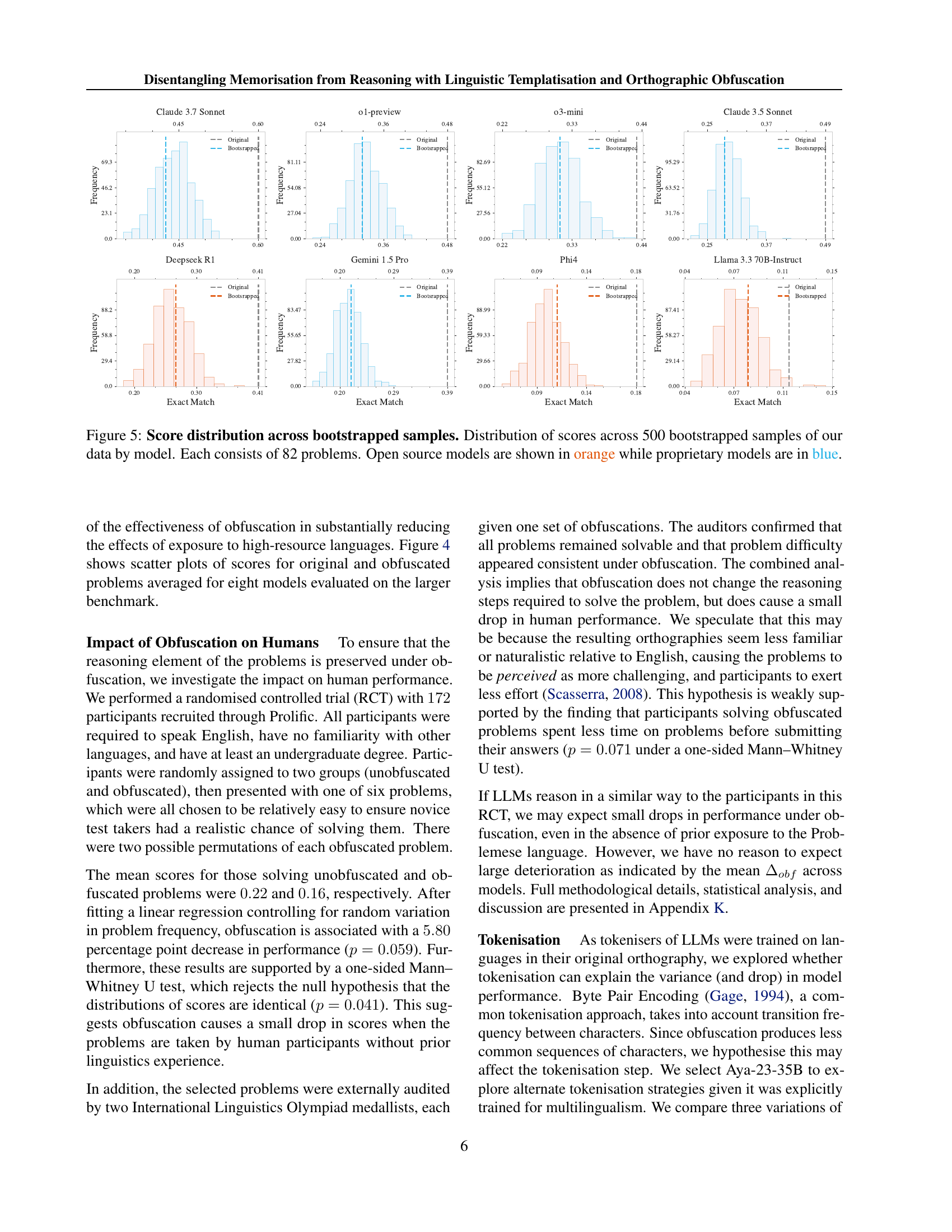
🔼 This figure displays the distribution of scores obtained from 500 bootstrapped samples for each of the models evaluated in the paper. Each bootstrapped sample contains scores for 82 problems. The distributions are shown as histograms. Open-source models are represented in orange, while proprietary models are in blue. The figure helps visualize the variability in model performance across different problem sets and highlights potential differences between open-source and proprietary models.
read the caption
Figure 5: Score distribution across bootstrapped samples. Distribution of scores across 500 bootstrapped samples of our data by model. Each consists of 82 problems. Open source models are shown in orange while proprietary models are in blue.

🔼 This figure displays the performance of various large language models (LLMs) on linguistic reasoning problems categorized by linguistic subdiscipline. The left panel shows the average performance across all evaluated LLMs, indicating comparable performance across most subdisciplines except for ’numbers’ problems. The obfuscation technique, aimed at reducing memorization, shows relatively consistent effects across different subdisciplines. The right panel focuses on the four top-performing LLMs, revealing a significant negative impact of obfuscation specifically on ‘compounding’ problems.
read the caption
Figure 6: Performance by linguistic subdiscipline. Left: Averaged across all models. Models perform comparably across linguistic subdisciplines, with the exception of numbers problems. The effect of obfuscation is relatively even across subdisciplines. Right: Averaged across the four highest-scoring models (o1 Preview, Claude 3.5 Sonnet, GPT 4o, Gemini 1.5 Pro). Compounding problems are affected particularly severely by obfuscation.

🔼 This figure displays a comparison of exact match scores achieved using standard versus alternative tokenization methods. The x-axis represents scores from standard tokenization, and the y-axis represents scores from the alternative methods. The dashed line indicates where the scores are equal. Points above the line show improved performance with the alternative method, and points below show worse performance. The figure is divided into four subplots: (a) unobfuscated problems with dash tokenization, (b) obfuscated problems with dash tokenization, (c) unobfuscated problems with character-level tokenization, and (d) obfuscated problems with character-level tokenization. This allows for a detailed analysis of how different tokenization approaches impact performance on both original and obfuscated linguistic problems.
read the caption
Figure 7: Problem-level comparison of exact match scores between standard and alternative tokenisation. The dashed line represents the threshold where the score remains unchanged after altering the tokenisation. Point above the dashed line indicate better performance with alternative tokenisation, while points below the line indicate worse performance. (a) The problems are unobfuscated and we compare scores of standard tokenisation against dash tokenisation. (b) The problems are obfuscated and we compare scores of standard tokenisation against dash tokenisation. (c) The problems are unobfuscated and we compare scores of standard tokenisation against character-level tokenisation. (d) The problems are obfuscated and we compare scores of standard tokenisation against character-level tokenisation.
More on tables
| Prompt type | Unobfuscated | Obfuscated |
|---|---|---|
| Standard | 0.087 | 0.050 |
| Dash | 0.051 | 0.045 |
| Character | 0.053 | 0.035 |
🔼 This table presents the results of an experiment evaluating the impact of different tokenization methods on the performance of the Aya-23-35B language model. The model’s performance is assessed using the exact match metric on both obfuscated and unobfuscated linguistic reasoning problems. The experiment compares three tokenization approaches: standard tokenization, dash tokenization (inserting a dash between each character of the Problemese), and character tokenization (treating each character as a separate token). The results reveal a decrease in model performance when alternative tokenization techniques are applied, regardless of whether the problems are obfuscated or not.
read the caption
Table 2: Exact match results with varying input to the tokeniser. Performance of Aya-23-35B decreases when alternative tokenisation techniques are used, both on obfuscated and unobfuscated problems. ‘Dash’ tokenisation inserts a dash between each character in the Problemese data. ‘Character’ tokenisation forces the model to tokenise each character individually.
| Model | Answer | Train | Val | Held out Q | Held out O | Held out Q/O | Held out P |
|---|---|---|---|---|---|---|---|
| Llama 3.2 1B Inst | All | 0.58 | 0.02 | 0.04 | 0.32 | 0.03 | 0.03 |
| Same | 0.88 | 0.03 | 0.10 | 0.60 | 0.06 | 0.06 | |
| Changed | 0.15 | 0.00 | 0.00 | 0.06 | 0.01 | 0.01 | |
| LLama 3.2 3B Inst | All | 0.71 | 0.01 | 0.02 | 0.38 | 0.02 | 0.01 |
| Same | 0.89 | 0.01 | 0.04 | 0.61 | 0.03 | 0.00 | |
| Changed | 0.45 | -0.01 | 0.01 | 0.17 | 0.02 | 0.02 |
🔼 This table presents the results of an experiment evaluating the impact of fine-tuning on large language models’ performance on a linguistic reasoning benchmark. The benchmark uses linguistic problems where the orthography (writing system) of the language has been modified to reduce memorization. The table shows the change in the model’s exact match score (a binary metric indicating whether the model’s answer exactly matches the correct answer) after fine-tuning, broken down by different subsets of the data: all questions, only questions where the correct answer was changed by the obfuscation, only questions where the correct answer was not changed by the obfuscation, only obfuscations, questions and obfuscations, and the entire problem. The results are analyzed for both ‘Same’ answers (obfuscation did not alter the correct answer) and ‘Changed’ answers (obfuscation did alter the correct answer). This allows for a nuanced understanding of how the models generalize to unseen linguistic problems with and without orthographic changes.
read the caption
Table 3: Performance change after fine-tuning. Difference in mean exact match after fine-tuning on each of the held out splits. Answer changed refers to when obfuscation altered the correct answer, same refers to when the answer after obfuscation was not altered. Q: Questions, O: Obfuscations, Q/O: Questions and Obfuscations, P: Problems.
| Word | Meaning |
|---|---|
| cognate | Word or word-part with the same historical origin as another. E.g. English father, German Vater, Swedish far. |
| diacritic | Symbol added to a letter or other basic glyph; often called ‘accent’. |
| (language) family | Group of languages all derived from a common ancestor. E.g. the Romance language family is derived from Latin. |
| grapheme | Letter or group of letters that typically represent a single sound or suprasegmental feature. See (Kohrt, 1986) for a discussion of other definitions in common usage. |
| lexeme | Basic unit of the lexicon (vocabulary) of a language. E.g. sit, sits, sitting, sat are all inflected forms of the same lexeme. |
| (transparent) loanword | Word borrowed from another language. A loanword is transparent if it is obviously a loanword. E.g. Nepali pēnsil ‘pencil’. |
| morpheme | Basic unit of meaning within a word. E.g. help-less-ness consists of three morphemes. |
| morphology | Branch of linguistics dealing with the internal structure and formation of words. |
| -graph | Collection of letters representing a single grapheme. E.g. th and sh are English digraphs. |
| orthography | System for writing a language, including the choice letters or other glyphs and spelling conventions. |
| phonetics | Branch of linguistics dealing with the production and perception of speech sounds or signs. |
| phonology | Branch of linguistics dealing with the systematisation and organisation of sounds or signs within a language. |
| phonological distinction | Distinction between two speech sounds that is treated as meaningful within a language. |
| Problemese | Unknown language that is the focus of a Linguistics Olympiad problem. |
| semantics | Branch of linguistics dealing with the study of meaning. |
| Solverese | Language that a Linguistics Olympiad problem is written in; assumed to be the working language of the solver. |
| suprasegmental | Phonetic or phonological feature that extends beyond a single speech sound. E.g. stress, intonation, pitch. |
| syllabification | Procedure for forming valid syllables out of a string of speech sounds. |
| syntax | Branch of linguistics dealing with the organisation of words into phrases, clauses and sentences. |
🔼 This table provides definitions for linguistic terms used throughout the paper, clarifying the meaning of key concepts in linguistics and the methodology of the study.
read the caption
Table 4: Glossary of linguistic terms.
| Problem | Original | Annotated |
|---|---|---|
| This problem is about the way in which Navajo speakers build sentences out of a verb V. | This problem is about the way in which $$$Language X$$$ speakers build sentences out of a verb V. | |
| Ulwa is a language spoken in Nicaragua. It contains quite a few loanwords from English, which is spoken in the Bluefields area of the country. | $$$Language X$$$ &&& &&& contains quite a few loanwords from English &&& &&&. | |
| dinaldalusanda they were cleaning it | @@@dinaldalusanda@@@ they were cleaning it | |
| t(in)ak+takaw+da ida | tinaktakawda ida |
🔼 This table showcases examples of the annotation process applied to problems from the LINGOLY-TOO benchmark. It demonstrates three types of annotations: language name replacement, cultural context removal, and grading guideline removal. Each row presents a snippet from a problem, showing the original text from the UKLO problem sheet (left column) and the annotated version (right column). Specific examples highlight how language names are replaced with placeholders, cultural details are removed, and grading information is removed to prepare the data for the obfuscation process and facilitate objective performance evaluation.
read the caption
Table 5: Annotation examples. Each row is an extract from a problem in LingOly-TOO. On the left, the extract appears in the original UKLO problem sheet. On the right, the extract after annotation. Problem 67 (Navajo by Babette Verhoeven) is an example of the language name annotation. Problem 16 (Ulwa by Richard Sproat) is example of the cultural context annotation. Problem 61 (Ilokano by Bozhidar Bozhanov) illustrates the annotation of Problemese in preparation for further obfuscation, and is an example of removing grading guidelines from the dataset to prepare it for checking exact matching.
| p | t | k |
| b | d | g |
🔼 This table presents a summary of the model’s performance on the LINGOLY-TOO benchmark, specifically focusing on the larger dataset with 30 obfuscations per problem. It shows the total number of responses, the count of empty responses, and the count of responses with bad parsing for each model evaluated. The models are compared across the benchmark’s larger size, which includes more obfuscated versions of the problems than the smaller benchmark. This allows for a more robust assessment of memorization effects.
read the caption
Table 6: Summary of responses on larger benchmark (30303030 obfuscations).
| m | n |
| p, b, f | t, d, s |
🔼 This table presents a summary of the model’s responses on a smaller version of the LINGOLY-TOO benchmark. The smaller benchmark consists of 6 obfuscations per problem, unlike the larger benchmark which uses 30. The table shows the total number of questions, number of empty responses, and number of responses with bad parsing for each of the 11 models evaluated.
read the caption
Table 7: Summary of responses on smaller benchmark (6666 obfuscations).
| Slot 1 | Slot 2 | Slot 3 | Slot 4 | Slot 5 |
|---|---|---|---|---|
| Nasal | Non-sib. fricatives | Liquid (l or r) | plosive/sibilant | Any non-plosive + non-sib. |
| m v | \textipaz if Slot 4 is sibilant | fricative affricate, | ||
| n | z otherwise | unless Slot 5 is a nasal |
🔼 This table presents the results of an experiment comparing the performance of a language model using different tokenization techniques on unobfuscated linguistic reasoning problems. The standard tokenization method is compared to two alternative methods: inserting dashes between characters (‘Dash’) and tokenizing each character individually (‘Character’). For each problem, the average performance across all questions is calculated for each tokenization method. Then, the change in performance relative to the standard tokenization method is categorized as either ‘Increased’, ‘Decreased’, or ‘Unchanged’. This analysis helps to understand how sensitive the model’s performance is to changes in tokenization.
read the caption
Table 8: Performance change under alternative tokenisation for unobfuscated problems. Score for each problem was averaged over all questions within the problem for the two alternative tokenisation methods (Dash and Character) then compared to the score obtained using standard tokenisation and categorized into Increased, Decreased or Unchanged.
| Model | Version | Model Type | Quantization |
|---|---|---|---|
| Aya 23 35B | CohereForAI/aya-23-35B | Open-source | 8-bit |
| Claude 3.5 Sonnet | claude-3-5-sonnet-20241022 | Proprietary | |
| Claude 3.7 Sonnet | claude-3-7-sonnet-20250219 | Proprietary | |
| Deepseek R1 | deepseek/deepseek-r1 | Open-source | |
| Gemini 1.5 Pro | gemini-1.5-pro | Proprietary | |
| GPT 4o | gpt-4o-2024-05-13 | Proprietary | |
| GPT 4.5 | gpt-4.5-preview-2025-02-27 | Proprietary | |
| Llama 3.2 3B Inst | meta-llama/Llama-3.2-3B-Instruct | Open-source | |
| Llama 3.2 1B Inst | meta-llama/Llama-3.2-1B-Instruct | Open-source | |
| Llama 3.3 70B | meta-llama/Llama-3.3-70B-Instruct | Open-source | 8-bit |
| o1-preview | o1-preview | Proprietary | |
| o3-mini | o3-mini-2025-01-31 | Proprietary | |
| Ours 1B | Checkpoint will be shared in published version | Open-source | |
| Ours 3B | Checkpoint will be shared in published version | Open-source | |
| Phi4 | microsoft/phi-4 | Open-source | 8-bit |
🔼 This table presents the results of an experiment comparing the performance of a language model using three different tokenization methods (standard, dash, and character) on obfuscated linguistic reasoning problems. For each problem, the average performance across all obfuscations was computed for each tokenization method. The table shows the number of problems where performance increased, decreased, or remained unchanged compared to the standard tokenization method for each of the alternative tokenization methods.
read the caption
Table 9: Performance change under alternative tokenisation for obfuscated problems. For each alternative tokenisation, the score for each problem was averaged over all obfuscations then compared to the score obtained using standard tokenisation and categorized into Increased, Decreased or Unchanged.
| Model | Obfuscated | Exact Match | Exact Match (CoT) |
|---|---|---|---|
| GPT 4o | False | ||
| True | |||
| Llama 3.3 70B | False | ||
| True |
🔼 This table lists six linguistic reasoning problems selected for a human evaluation experiment. The problems are categorized by their language of origin, UKLO (United Kingdom Linguistics Olympiad) difficulty level (Breakthrough or Foundation, suitable for 10-14 year olds), problem ID number, and the original author(s). A key criterion for selection was that the languages should not be readily translatable via Google Translate, to ensure participants solved problems using reasoning rather than relying on machine translation. The table provides context for the human evaluation described in section K.
read the caption
Table 10: Problems selected for the randomised controlled trial. All problems are Breakthrough and Foundation-level, designed to be taken by 10-14 year olds. None of these languages are available on Google translate in a manner that would aid the solvability of the problem. UKLO problem is the listing of the problem in the UKLO past problems database (United Kingdom Linguistics Olympiad, 2023).
| Model | Total | Empty Response | Bad Parsing |
|---|---|---|---|
| Aya 23 35B | 27,325 | 1,602 | 0 |
| GPT 4o | 27,325 | 536 | 169 |
| Gemini 1.5 Pro | 27,325 | 0 | 56 |
| Llama 3.2 1B Inst | 27,276 | 10,687 | 0 |
| Llama 3.2 3B Inst | 27,325 | 1,022 | 0 |
| Llama 3.3 70B- Instruct | 27,325 | 1,202 | 0 |
| Ours 1B | 27,325 | 3,073 | 0 |
| Ours 3B | 27,325 | 2,809 | 0 |
| Phi4 | 27,325 | 2,086 | 0 |
| Claude 3.5 Sonnet | 27,325 | 7 | 140 |
🔼 Table 11 presents the average human performance on both original and obfuscated linguistic reasoning problems. The scores are percentages out of 100%, representing the percentage of questions answered correctly. The table breaks down the results by individual problem (specifying the language used), showing the mean score for both original and obfuscated versions of each problem and the difference between them. Sample sizes for each group are also provided. The ‘Random guessing’ column indicates the expected score if participants randomly selected answers, offering a baseline for comparison against human performance.
read the caption
Table 11: Human performance across original and obfuscated problems. Sample size is in brackets. All scores are out of 100%percent100100\%100 %. Random guessing is the expected score from random answers, given the basic formatting instructions in each question are followed.
| Model | Total | Empty Response | Bad Parsing |
|---|---|---|---|
| Aya 23 35B | 6,995 | 370 | 0 |
| Claude 3.5 Sonnet | 6,995 | 8 | 0 |
| Claude 3.7 Sonnet | 6,995 | 22 | 0 |
| Deepseek R1 | 6,995 | 128 | 0 |
| GPT 4.5 | 6,995 | 0 | 6 |
| GPT 4o | 6,995 | 176 | 0 |
| Gemini 1.5 Pro | 6,995 | 16 | 0 |
| Llama 3.3 70B-Instruct | 6,995 | 316 | 0 |
| Phi4 | 6,995 | 287 | 0 |
| o1-preview | 6,995 | 148 | 0 |
| o3-mini | 6,995 | 38 | 11 |
🔼 This table presents the results of three linear regression models analyzing the factors influencing participant scores in a human evaluation experiment. The dependent variable in all models is the participant’s score. Model 1 includes all participants (n=172). Model 2 removes participants suspected of cheating, those with more than 50% missing data, and those with a mean ChrF score below 10 (n=146). Model 3 further removes participants who scored below random guessing (n=86). The table shows the regression coefficients, standard errors, statistical significance, R-squared, F-statistic, residual standard error, and degrees of freedom for each model. It highlights how removing certain participants changes the effect sizes of the variables.
read the caption
Table 12: Linear regressions for participant score under different inclusion criteria. The dependent variable is participant score in all models. The participant inclusion criteria are as follows. Model 1: All participants (n=172172172172). Model 2: Excluding participants who we suspect may have cheated, those who returned more than 50%percent5050\%50 % missing data, and those with mean ChrF score below 10101010 (n=146146146146). Model 3. Excluding participants who scored below random guessing (n=86868686). SE: Heteroskedasticity-consistent standard errors. df: Degrees of freedom. p∗<.1superscript𝑝.1{}^{*}p<.1start_FLOATSUPERSCRIPT ∗ end_FLOATSUPERSCRIPT italic_p < .1; p∗∗<.05superscript𝑝absent.05{}^{**}p<.05start_FLOATSUPERSCRIPT ∗ ∗ end_FLOATSUPERSCRIPT italic_p < .05; p∗∗∗<.01superscript𝑝absent.01{}^{***}p<.01start_FLOATSUPERSCRIPT ∗ ∗ ∗ end_FLOATSUPERSCRIPT italic_p < .01
| Prompt type | Decreased | Unchanged | Increased |
|---|---|---|---|
| Dash | 57 | 19 | 5 |
| Character | 58 | 19 | 4 |
🔼 This table presents the results of a logistic regression model used to predict whether a participant’s score on a linguistic reasoning problem was above or below the level of random chance. The model’s independent variables include whether the problem was obfuscated or not (original), as well as individual problem effects. A significant negative coefficient for the ‘obfuscated’ variable indicates that obfuscated problems were significantly associated with a below-random score, suggesting that the obfuscation process increased the difficulty for participants.
read the caption
Table 13: A logistic regression predicting above random guessing score. The dependent variable is a binary variable indicating whether a participant’s score was above random. Obfuscated problems are more likely to lead to below random guessing performance with a coefficient significant at the 5%percent55\%5 % level. SE: Heteroskedasticity-consistent standard errors. df: Degrees of freedom. p∗<.1superscript𝑝.1{}^{*}p<.1start_FLOATSUPERSCRIPT ∗ end_FLOATSUPERSCRIPT italic_p < .1; p∗∗<.05superscript𝑝absent.05{}^{**}p<.05start_FLOATSUPERSCRIPT ∗ ∗ end_FLOATSUPERSCRIPT italic_p < .05; p∗∗∗<.01superscript𝑝absent.01{}^{***}p<.01start_FLOATSUPERSCRIPT ∗ ∗ ∗ end_FLOATSUPERSCRIPT italic_p < .01
Full paper#