TL;DR#
Current egocentric vision systems and datasets often fall short in understanding ultra-long-term behavior patterns and complex social dynamics due to limited recording durations and monographic perspectives. The EgoLife project bridges this gap by presenting a comprehensive data collection study where six participants lived together for one week, continuously recording their daily activities using AI glasses, along with synchronized third-person video references. This results in the EgoLife Dataset, a 300-hour dataset with intensive annotation.
To showcase the dataset’s potential, the project introduces EgoLifeQA, a suite of long-context, life-oriented question-answering tasks designed to provide meaningful assistance in daily life. Additionally, it presents EgoBulter, an integrated system comprising EgoGPT and EgoRAG, to address the technical challenges of developing robust visual-audio models and facilitating long-context question answering. Experimental studies verify EgoBulter’s mechanisms and guide future improvements.
Key Takeaways#
Why does it matter?#
This research introduces EgoLife, a 300-hour egocentric dataset with multimodal annotations, addressing gaps in long-term, interpersonal AI assistance. It offers EgoLifeQA, a benchmark for life-oriented QA tasks. This work can stimulate further research in egocentric AI assistants and provide meaningful assistance in daily life. The dataset, models, and benchmarks are released to encourage innovation in the field and enable long-context understanding.
Visual Insights#

🔼 The EgoLife project involves six participants living together for a week, documenting their daily lives using Meta Aria glasses to capture egocentric video and sensor data. Fifteen additional cameras and two mmWave devices simultaneously record third-person views, creating a rich multimodal dataset. The data supports development of advanced egocentric AI assistants and introduces new research tasks focused on long-term life assistance.
read the caption
Figure 1: The Overview of EgoLife Project. The EgoLife project features six participants living together for a week to prepare an Earth Day celebration. Each participant wears Meta Aria glasses [1], recording approximately 8 hours of egocentric video and signals daily. In addition, 15 cameras and 2 mmWave devices provide synchronized third-person perspective data (detailed in Figure 2). These comprehensive annotations enable the development of state-of-the-art multimodal egocentric AI assistants and introduce novel tasks to advance long-term egocentric life assistance, as illustrated in the EgoLife task board.
| Benchmark | Domain | Modality | #Captions | Size (hrs) | #Clips | Dur./Clip | Multiview |
| ||
|---|---|---|---|---|---|---|---|---|---|---|
| EPIC-KITCHENS [4] | Kitchen | 20K+ | 100 | 700 | 8.5 min | ✗ | ✗ | |||
| Ego4D [5] | Daily Activities | 3.85M | 3,670 | 9,645 | 22.8 min | ✗ | ✗ | |||
| EgoExo4D [8] | Skilled Activities | 500K+ | 1,286 | 5,035 | 1 to 42 min | ✓ | ✗ | |||
| EgoExoLearn [9] | Task Execution | - | 120 | 432 | 13.4 min | ✓ | ✗ | |||
| EgoPet [10] | Animal Actions | - | 84 | 6,646 | 45.5 sec | ✗ | ✗ | |||
| EgoLife | Daily Life | 400K+ | 266 | 6 | 44.3 h | ✓ | ✓ |
🔼 Table 1 provides a comparative overview of several egocentric datasets, highlighting their key characteristics. It lists each dataset’s domain (e.g., kitchen activities, daily life), the type of data modalities included (video, gaze, IMU, 3D scans), the total duration of recorded footage, the number of video clips, the average duration of each clip, and whether the dataset includes multi-view perspectives and interpersonal interactions. The table emphasizes that the EgoLife dataset is unique due to its significantly longer egocentric video recordings and the rich inclusion of interpersonal dynamics.
read the caption
Table 1: Related Work for EgoLife Dataset - Overview of Egocentric Datasets. For Modality, denotes video, denotes gaze, denotes IMU, denotes 3D scans. The EgoLife dataset stands out for its ultra-long egocentric footage and rich interpersonal interactions.
In-depth insights#
EgoLife dataset#
The EgoLife dataset is a new resource aimed at advancing research in egocentric AI. It addresses limitations in existing datasets like short recording durations and monographic perspectives by providing 300 hours of egocentric, multimodal, and multiview data. Collected from six participants in a fully instrumented living environment, the dataset captures rich interpersonal dynamics and extended activities relevant to daily life. The data includes synchronized third-person perspectives, offering an unparalleled opportunity to study social interactions and long-term behavior patterns. Key features are the intensive annotations, the detailed collection of multi-modal data and its ultra-long duration. Through its multimodal and multi-view perspective, the EgoLife dataset seeks to stimulate research in egocentric AI assistants by providing a new data collection strategy and comprehensive dataset structure.
EgoButler system#
The EgoButler system tackles complex tasks posed by EgoLifeQA, comprising EgoGPT and EgoRAG. EgoGPT handles clip-level omni-modal understanding through continuous video captioning using visual and audio inputs, providing context for EgoRAG. It also aids question-answering using retrieved clues. To align with egocentric video and incorporate audio understanding, EgoIT-99K, a dataset with QA pairs from video annotations, is introduced to fine-tune EgoGPT on LLaVA-OneVision. An audio branch, like Ola, is developed, encoding audio with Whisper Large v3 and training an audio projection module on LibriSpeech. EgoRAG addresses long-horizon, long-context scenarios, enhancing memory and query capabilities for personalized comprehension. It employs a two-stage approach: memory bank construction with video clip captions and structured storage, and content retrieval and response generation using a relevance-based scoring function and language models like EgoGPT or GPT-40. Integration of EgoGPT and EgoRAG combines efficient video interpretation with long-context memory, enabling accurate, context-aware responses, and personalized egocentric data gathering.
Egocentric future#
The concept of an ‘Egocentric Future’ paints a picture where AI is deeply intertwined with our personal lives through wearable devices like smart glasses. Personalized assistance becomes paramount, with AI anticipating needs based on habits and social dynamics. Data privacy and ethical considerations are vital, ensuring user autonomy and trust. Imagine AI companions enhancing daily efficiency and offering context-aware support. The potential for revolutionizing education, healthcare, and personal organization is immense, but requires thoughtful development focused on safety and inclusivity. Navigating challenges of long-term video understanding and complex multimodal data are key to realizing the full potential of an egocentric future and building empathetic AI.
Multimodal AI#
Multimodal AI is the capability of AI models to process and understand data from multiple modalities such as video, audio, text, and sensor data. EgoLife highlights the significance of robust multimodal AI, emphasizing the integration of visual and audio data for nuanced understanding. This project presents data and methodologies to propel research in this field, particularly for long-term egocentric perception.
Long-term assist#
While the term ‘Long-term Assist’ isn’t directly used, the paper’s core revolves around it. EgoLife pioneers prolonged egocentric data collection, a leap from existing datasets’ limited durations. This unlocks potential for AI assistants to learn user habits, predict needs, and offer personalized support over extended periods. Key challenges include developing robust models that understand nuanced audio-visual cues in egocentric data and handling the complexities of long-context question answering. EgoButler, with its EgoGPT and EgoRAG components, represents a significant stride toward a practical long-term life assistant. The dataset’s richness in interpersonal dynamics also lays the groundwork for AI to assist in social interactions, fostering a more empathetic and supportive user experience, key for any ‘Long-term assist’ system.
More visual insights#
More on figures

🔼 This 3D model of the EgoLife house shows the placement of 15 standard cameras and two mmWave radar devices within the house. The cameras are spread throughout the common areas to capture third-person perspectives of participant activities. The mmWave radar devices, highlighted in red, are located on the second floor for additional motion capture data. Color-coded lines represent 10-minute movement tracks for each participant, indicating their movements within the space during the study.
read the caption
Figure 2: 3D reconstruction of the shared house using Aria Multi-MPS [1], showcasing the locations of 15 Exo cameras in the common area and 2 mmWave devices (highlighted in red) on the second floor. Color-coded 10-minute participant traces are also displayed.

🔼 This figure presents a visual overview of the activities undertaken by six participants over a week-long period within the EgoLife project. Each horizontal band represents a single participant’s activities, and the entire timeline spans seven days. The timeline is divided into 20-minute intervals, with each interval color-coded and labeled with an icon to represent the type of activity (e.g., social, housekeeping, cooking, etc.). A legend provides a complete list of the 14 activity categories used, along with the total number of times each activity occurred throughout the week. Notably, the activity categorization was automatically determined using GPT-4, which analyzed both the audio and video data associated with each 20-minute interval.
read the caption
Figure 3: The Activity Timeline of the EgoLife Dataset. It visualizes the activity timeline of six participants over one week. Each block represents a 20-minute interval, color-coded and marked with icons for different activities. The legend shows 14 activity categories with their total occurrence counts. The categorization is automatically performed using GPT-4o on visual-audio captions with timestamps.

🔼 The figure illustrates the data processing pipeline for the EgoLife project. It begins with the synchronization of data streams from Meta Aria glasses and GoPro cameras using the EgoSync codebase. This synchronized data (video, audio, and IMU) then undergoes privacy protection via the EgoBlur module. Next, the data is processed by EgoCaption for dense caption generation and by EgoTranscript for transcription. Finally, the processed and annotated data is fed into the EgoLifeQA system for further analysis and task completion.
read the caption
Figure 4: The Overview of Data Process Pipeline. The pipeline synchronizes multi-source data (video, audio, IMU) from Aria glasses and GoPro cameras using EgoSync codebase, processes them through privacy protection (EgoBlur), dense captioning (EgoCaption), and transcription (EgoTranscript) modules, ultimately feeding into the EgoLifeQA system.
🔼 This figure showcases the five question types within the EgoLifeQA benchmark designed to assess an egocentric AI assistant’s capabilities. These question types cover entity logging (tracking objects), event recall (remembering past events), task tracking (monitoring ongoing tasks), and two human-centric problem areas: habit analysis (identifying personal habits) and relationship understanding (analyzing social interactions). Each example displays a multiple-choice question with its answer, along with timestamps linking the answer back to relevant evidence in the recorded data. The timestamps are at least 5 minutes before the question to demonstrate the AI’s ability to use long-term contextual information. Vertical black lines mark question timestamps; colored arcs connect to relevant evidence timestamps.
read the caption
Figure 5: Question Types and Examples in the EgoLifeQA Benchmark. We design five types of questions to evaluate egocentric assistants’ capabilities in entity logging, event recall, task tracking, and human-centric problems (habit analysis and relationship understanding). Each example includes a multiple-choice Q&A with supporting evidence from timestamps at least 5 minutes prior to the question. Black vertical lines indicate question timestamps, while colored curved lines connect to relevant evidence timestamps.

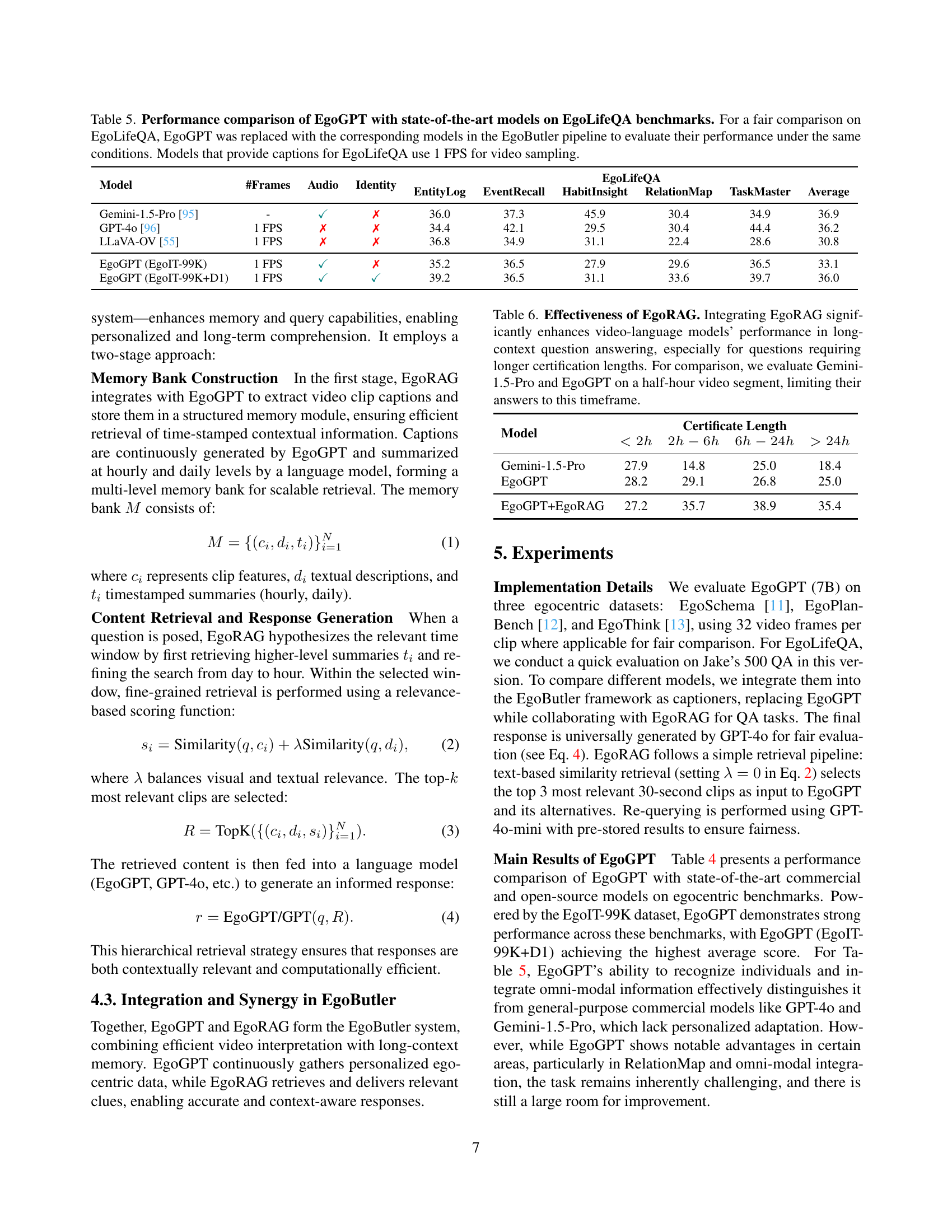
🔼 The figure presents a statistical overview of the EgoLifeQA dataset, showing the distribution of different question types and their temporal characteristics. It features two visualizations: a pie chart illustrating the proportion of questions that require audio input and a bar chart depicting the daily distribution of questions across question types, with color intensity indicating the certification length (time span between the question and relevant evidence). The dataset comprises 3000 QAs (500 per participant).
read the caption
Figure 6: Statistics of EgoLifeQA. We gathered 500 long-context QAs per participant, totaling 3K QAs. The sum of QAs for each question type is reported. In the pie chart, darker segments indicate the proportion of questions requiring audio. The bar chart presents the daily count of QAs per question type, with brightness levels reflecting 4-level certification length [11] (from <<<2h to >>>24h).

🔼 EgoButler is a two-stage system. First, EgoGPT processes egocentric video clips to generate detailed visual-audio captions. Then, EgoRAG retrieves relevant information from these captions based on user queries, enabling it to answer questions requiring temporal reasoning across multiple days. The figure shows an example of how EgoButler answers a breakfast-related question by extracting keywords, retrieving evidence from past days’ captions, and generating a context-aware response.
read the caption
Figure 7: The EgoBulter Architecture. The system comprises (a) a Captioning Stage powered by EgoGPT for dense visual-audio understanding of egocentric clips, and (b) a Question Answering Stage utilizing EgoRAG for memory retrieval and response generation. The example demonstrates temporal reasoning across multiple days, with keyword extraction, evidence retrieval, and context-aware answer generation for a breakfast-related query.

🔼 Figure 8 demonstrates a qualitative comparison of EgoGPT and Gemini-1.5-Pro within the EgoButler framework. The top half shows a side-by-side comparison of captions generated by each model for the same 30-second egocentric video clip. This highlights EgoGPT’s superior performance in generating personalized captions that accurately reflect the content of the video, while also exhibiting fewer hallucinations (inventions of facts not present in the source video). The bottom half presents a question-answering scenario. It illustrates how EgoRAG, a retrieval-augmented generation component, leverages temporal information from the video to correctly identify and utilize relevant time segments to answer the question accurately.
read the caption
Figure 8: Qualitative Comparison of EgoGPT and Gemini-1.5-Pro under the EgoButler Framework. The top section compares captions from two models on a 30-second clip: EgoGPT excels in personalization and hallucinates less on the egocentric videos. The bottom section features a question that is answered by the clip, showcasing EgoRAG’s skill in pinpointing relevant time slots and key clues.
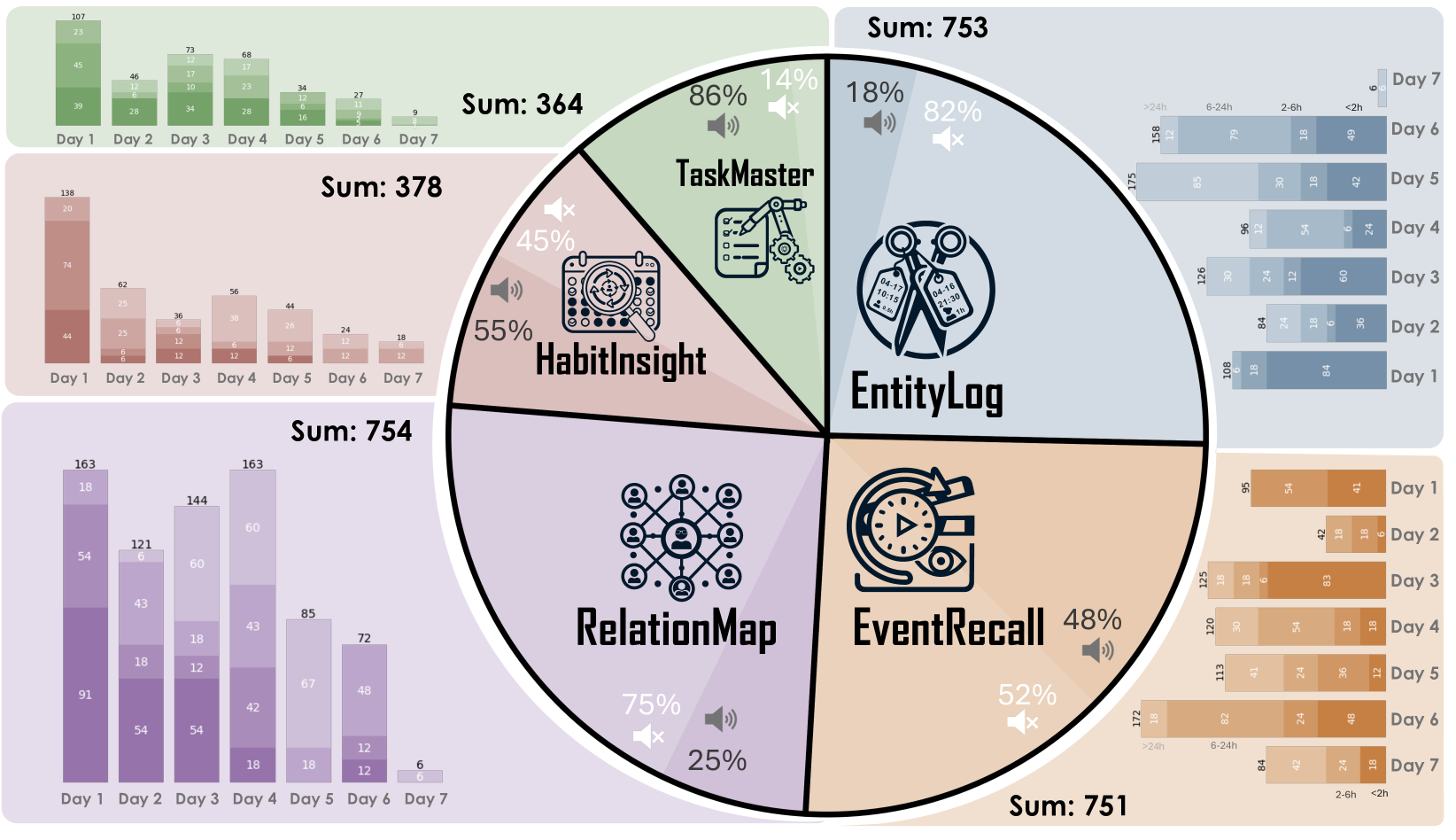
🔼 This figure provides a comprehensive overview of existing egocentric datasets. It presents a timeline of dataset releases, highlighting the evolution of data modalities (video, RGB-D, gaze, IMU, 3D scans, touch, point clouds), annotation types (activity labels, bounding boxes, pixel-level masks, timestamps, narrations, QA pairs), and the expansion of domains captured (sports, kitchen activities, assembly, daily life, interactions). The figure also summarizes key features and statistics of each dataset, such as the number of videos, duration, and types of annotations. This visualization helps readers understand the context of the EgoLife dataset by showing its position relative to other egocentric datasets in terms of scope, complexity, and features.
read the caption
Figure A1: The Overview of Egocentric Datasets. The figure summarizes the domain, modality, annotation type, release time, dataset statistics, and other aspects of datasets, providing a comprehensive view of existing egocentric datasets.
More on tables
| Interpersonal |
| Dynamics |
🔼 This table compares the EgoLifeQA benchmark with other related egocentric video benchmarks. The key differentiator of EgoLifeQA is its use of ultra-long video footage (spanning a week, totaling 266 hours across six participants), which allows for the exploration of novel tasks such as habit discovery and the analysis of complex relational interactions between people over extended periods. A ‘clip’ is defined as a continuous segment of video with a narrative thread. The duration per clip for EgoLife is derived from the total footage length and is not a fixed value.
read the caption
Table 2: Related Work for EgoLifeQA Benchmark. The EgoLifeQA dataset is distinguished by its ultra-long video footage and certificate length, facilitating novel tasks such as habit discovery and relational interaction pattern analysis (see Figure 5 for details). Note on Dur./Clip: A clip is defined as a session with narrative continuity. For the EgoLife dataset, this value is derived from 266 hours of retained footage distributed across six participants.
| Dataset | Source | #QAs | Size (hrs) | #Clips | Dur./Clip | Certificate Length [11] | |
|---|---|---|---|---|---|---|---|
| Below 2h | Over 2h | ||||||
| EgoSchema [11] | Ego4D | 5,063 | 250 | 5,063 | 3 min | 5,063 | 0 |
| EgoPlan-Bench [12] | Ego4D & EpicKitchen | 4,939 | - | 4,939 | - | 4,939 | 0 |
| EgoThink [13] | Ego4D | 700 | - | 595 | - | 700 | 0 |
| EgoMemoria [14] | Ego4D | 7,026 | - | 629 | 30 s to 1 h | 7,026 | 0 |
| HourVideo [15] | Ego4D | 12,976 | 381 | 500 | 20 min to 2 h | 12,976 | 0 |
| EgoLifeQA | EgoLife | 6,000 | 266 | 6 | 44.3 h | 997 | 2,003 |
🔼 The EgoIT-99K dataset is a curated collection of nine classic egocentric video datasets used for fine-tuning the EgoGPT model. These datasets were selected to provide a wide range of activities, contexts, and interaction types, building upon the LLaVA-OneVision base model. The table details the composition of EgoIT-99K, specifying for each source dataset: its duration, the number of videos (including those with audio), and the types of question-answering tasks used (Video Captioning (VC), Audio-Video Captioning (AVC), Multiple Choice Questions (MCQ), Multi-Round Questions (MRC), and Image Question-Answering (IQA)). The inclusion of diverse question types is intended to comprehensively evaluate the model’s capabilities.
read the caption
Table 3: Dataset Composition of EgoIT-99K. We curated 9 classic egocentric video datasets and leveraged their annotations to generate captioning and QA instruction-tuning data for fine-tuning EgoGPT, building on the LLaVA-OneVision base model [55]. #AV means the number of videos with audio used for training. QAs include multiple types - VC: Video Captioning, AVC: Audio-Video Captioning, MCQ: Multiple Choice Questions, MRC: Multi-Round Questions, IQA: Image Question-Answering.
| Dataset | Duration | #Videos (#AV) | #QA | QA Type |
|---|---|---|---|---|
| Ego4D [5] | 3.34h | 523 (458) | 1.41K | VC, AVC, MCQ, MRC |
| Charades-Ego [25] | 5.04h | 591 (228) | 18.46K | VC, AVC, MRC |
| HoloAssist [29] | 9.17h | 121 | 33.96K | VC, MCQ, MRC, IQA |
| EGTEA Gaze+ [26] | 3.01h | 16 | 11.20K | VC, MCQ, MRC, IQA |
| IndustReal [28] | 2.96h | 44 | 11.58K | VC, MCQ, MRC, IQA |
| EgoTaskQA [93] | 8.72h | 172 | 3.59K | VC, MCQ, MRC |
| EgoProceL [27] | 3.11h | 18 | 5.90K | VC, MCQ, MRC, IQA |
| Epic-Kitchens [4] | 4.15h | 36 | 10.15K | VC, MCQ, MRC, IQA |
| ADL [24] | 3.66h | 8 | 3.23K | VC, MCQ, MRC, IQA |
| Total | 43.16h | 1529 (686) | 99.48K |
🔼 This table presents a quantitative comparison of the EgoGPT model’s performance against other state-of-the-art video-language models on several established egocentric vision benchmarks. The benchmarks evaluate different aspects of video understanding, including video captioning and question answering. The results highlight EgoGPT’s strengths and weaknesses relative to these other models, offering insights into its capabilities and limitations in processing egocentric video data.
read the caption
Table 4: Performance of EgoGPT. The table compares EgoGPT with state-of-the-art commercial and open-source models on existing egocentric benchmarks.
| Model | #Param | #Frames | EgoSchema | EgoPlan | EgoThink |
|---|---|---|---|---|---|
| GPT-4v [94] | - | 32 | 56.6 | 38.0 | 65.5 |
| Gemini-1.5-Pro [95] | - | 32 | 72.2 | 31.3 | 62.4 |
| GPT-4o [96] | - | 32 | 72.2 | 32.8 | 65.5 |
| LLaVA-Next-Video [97] | 7B | 32 | 49.7 | 29.0 | 40.6 |
| LongVA [98] | 7B | 32 | 44.1 | 29.9 | 48.3 |
| IXC-2.5 [99] | 7B | 32 | 54.6 | 29.4 | 56.0 |
| InternVideo2 [100] | 8B | 32 | 55.2 | 27.5 | 43.9 |
| Qwen2-VL [101] | 7B | 32 | 66.7 | 34.3 | 59.3 |
| Oryx [57] | 7B | 32 | 56.0 | 33.2 | 53.1 |
| LLaVA-OV [55] | 7B | 32 | 60.1 | 30.7 | 54.2 |
| LLaVA-Videos [102] | 7B | 32 | 57.3 | 33.6 | 56.4 |
| EgoGPT (EgoIT) | 7B | 32 | 73.2 | 32.4 | 61.7 |
| EgoGPT (EgoIT+EgoLifeD1) | 7B | 32 | 75.4 | 33.4 | 61.4 |
🔼 This table presents a quantitative comparison of EgoGPT’s performance against other state-of-the-art models on the EgoLifeQA benchmark. To ensure a fair comparison, the EgoGPT model was swapped out with each competing model within the EgoButler pipeline, keeping all other parameters consistent. The results are presented in terms of accuracy across five different question types within the EgoLifeQA benchmark: EntityLog, EventRecall, HabitInsight, RelationMap, and TaskMaster. A crucial consideration is that models providing captions for the EgoLifeQA benchmark utilized a video sampling rate of 1 frame per second (FPS). The table highlights the relative strengths and weaknesses of each model across various question types, revealing which models perform better at certain aspects of egocentric life assistance.
read the caption
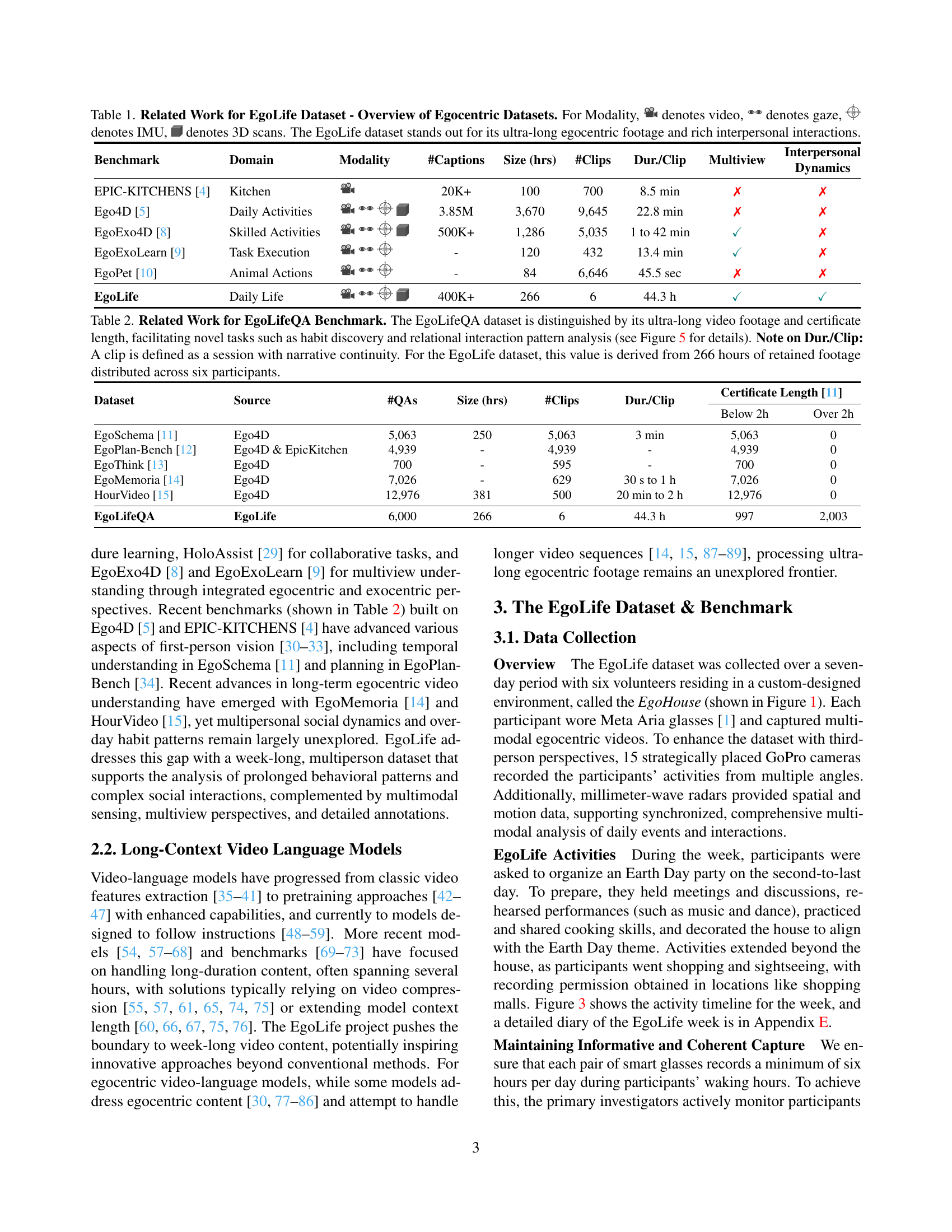
Table 5: Performance comparison of EgoGPT with state-of-the-art models on EgoLifeQA benchmarks. For a fair comparison on EgoLifeQA, EgoGPT was replaced with the corresponding models in the EgoButler pipeline to evaluate their performance under the same conditions. Models that provide captions for EgoLifeQA use 1 FPS for video sampling.
| Model | #Frames | Audio | Identity | EgoLifeQA | |||||
|---|---|---|---|---|---|---|---|---|---|
| EntityLog | EventRecall | HabitInsight | RelationMap | TaskMaster | Average | ||||
| Gemini-1.5-Pro [95] | - | ✓ | ✗ | 36.0 | 37.3 | 45.9 | 30.4 | 34.9 | 36.9 |
| GPT-4o [96] | 1 FPS | ✗ | ✗ | 34.4 | 42.1 | 29.5 | 30.4 | 44.4 | 36.2 |
| LLaVA-OV [55] | 1 FPS | ✗ | ✗ | 36.8 | 34.9 | 31.1 | 22.4 | 28.6 | 30.8 |
| EgoGPT (EgoIT-99K) | 1 FPS | ✓ | ✗ | 35.2 | 36.5 | 27.9 | 29.6 | 36.5 | 33.1 |
| EgoGPT (EgoIT-99K+D1) | 1 FPS | ✓ | ✓ | 39.2 | 36.5 | 31.1 | 33.6 | 39.7 | 36.0 |
🔼 This table demonstrates the significant performance improvement achieved by integrating EgoRAG (Retrieval-Augmented Generation) into a video-language model for long-context question answering. It compares the performance of EgoRAG combined with EgoGPT (a multimodal video-language model) against the performance of Gemini-1.5-Pro and EgoGPT alone, all evaluated on the task of answering questions requiring various lengths of contextual information (certification lengths). The results show EgoRAG’s substantial benefit, particularly for questions demanding ultra-long temporal context understanding (over 24 hours). The comparison with Gemini-1.5-Pro and EgoGPT alone on shorter video segments (half-hour) highlights EgoRAG’s effectiveness in handling long-context scenarios.
read the caption
Table 6: Effectiveness of EgoRAG. Integrating EgoRAG significantly enhances video-language models’ performance in long-context question answering, especially for questions requiring longer certification lengths. For comparison, we evaluate Gemini-1.5-Pro and EgoGPT on a half-hour video segment, limiting their answers to this timeframe.
| Model | Certificate Length | |||
|---|---|---|---|---|
| Gemini-1.5-Pro | 27.9 | 14.8 | 25.0 | 18.4 |
| EgoGPT | 28.2 | 29.1 | 26.8 | 25.0 |
| EgoGPT+EgoRAG | 27.2 | 35.7 | 38.9 | 35.4 |
🔼 This ablation study investigates the impact of caption quality on the EgoButler system’s performance. Different EgoRAG memory banks were constructed using captions generated by various EgoGPT models, including human-annotated captions as a baseline. All response generation models used the same EgoGPT (EgoIT-99K+D1) to maintain a fair comparison. The results demonstrate the effect of caption quality on the overall performance of EgoButler.
read the caption
Table 7: Ablation Study on EgoGPT. We construct different EgoRAG memory banks using generated captions from EgoGPT variants. The first three rows use captions from human annotations as a reference. All response generation models utilize EgoGPT (EgoIT-99K+D1) to ensure fair comparison. The result indicates how caption quality affects of EgoBulter performance.
Full paper#