TL;DR#
Large language models (LLMs) are powerful but can be limited by size or training data. Combining different LLMs can improve performance, but methods like ensembling are costly. Explicit model fusion is adaptable, but can struggle with vocabulary alignment. This paper tackles the challenge of improving LLMs by implicitly combining strengths of different open-source LLMs into smaller models.
The study introduces FuseChat-3.0, a framework that leverages supervised fine-tuning and direct preference optimization to train target models. It leverages diverse datasets to improve instruction following, math, and coding. Evaluations show FuseChat-3.0 enhances performance, improving results across established benchmarks and creating state-of-the-art performance.
Key Takeaways#
Why does it matter?#
This paper introduces a novel framework for enhancing LLMs, offering a practical approach for researchers. By combining diverse models & preference optimization, it paves the way for building efficient & robust LLMs for various applications.
Visual Insights#

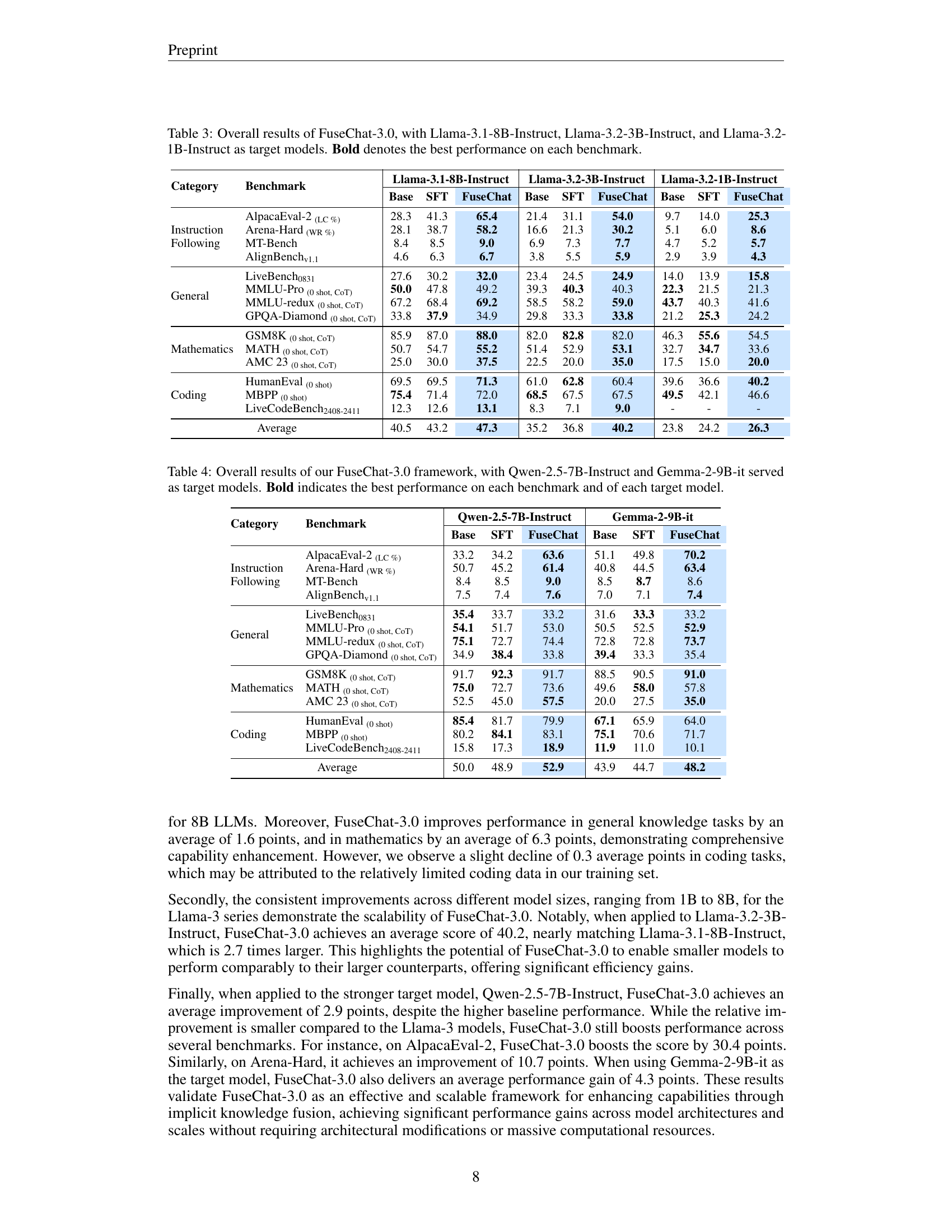
🔼 This figure illustrates the FuseChat-3.0 framework’s three-stage process for implicit model fusion. First, data is constructed by generating multiple responses from various source LLMs for each prompt, then these responses are evaluated using an external reward model (for instruction-following) or rule-based methods (for math and coding). Second, supervised fine-tuning (SFT) addresses distribution shifts by fine-tuning target models on optimal responses. Finally, Direct Preference Optimization (DPO) incorporates controlled preference signals from same-source response pairs to further fine-tune the target model.
read the caption
Figure 2: Overview of our proposed FuseChat-3.0 framework for implicit model fusion.
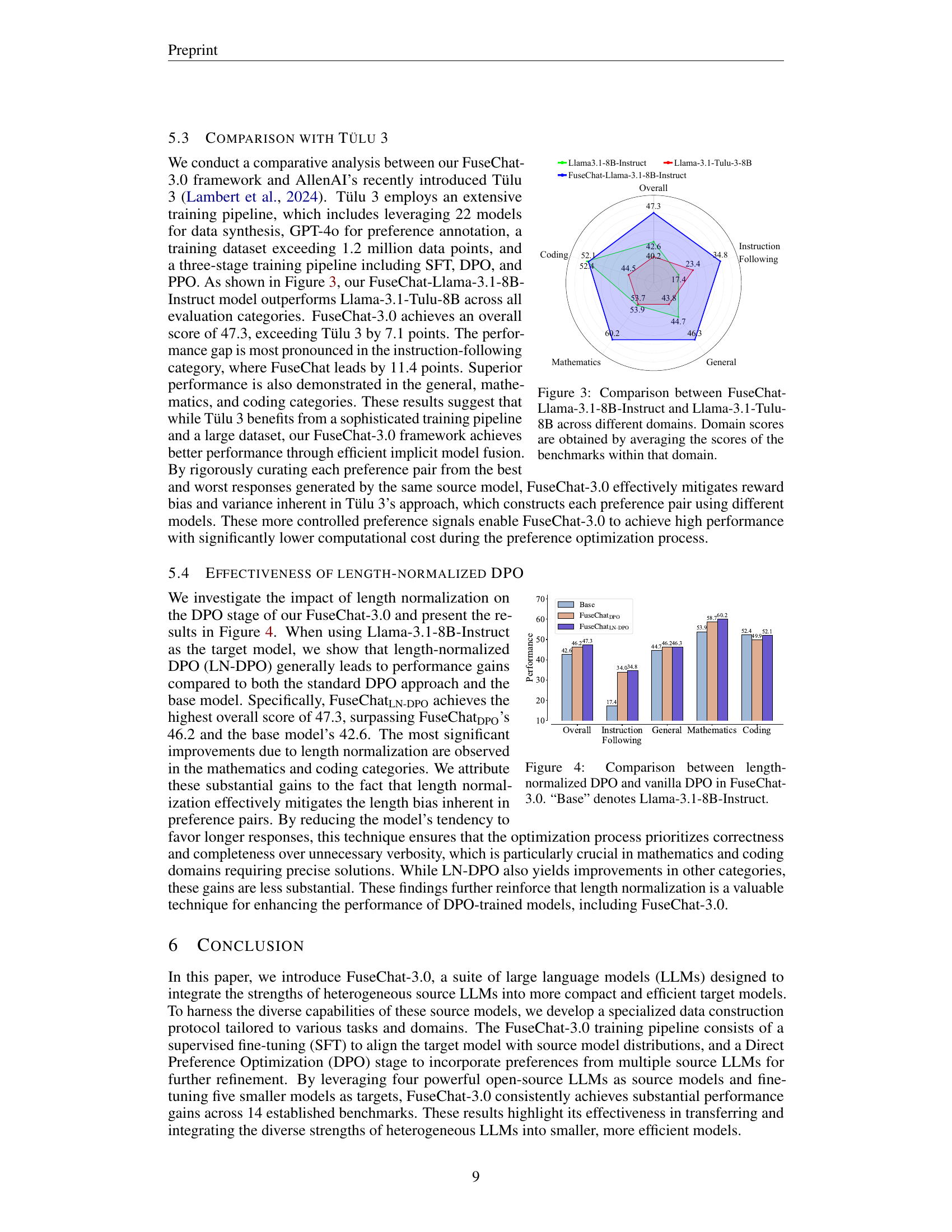
| Category | Dataset | Count | # | # |
| Instruction Following | UltraFeedback | 51,098 | 20,439 | 30,659 |
| Magpie-Pro-DPO | 20,374 | 8,149 | 12,225 | |
| HelpSteer2 | 9,435 | 3,774 | 5,661 | |
| Mathematics | OpenMathInstruct-2 | 51,803 | 40,188 | 11,615 |
| Coding | LeetCode | 3,113 | 1,877 | 1,236 |
| Self-Oss-Instruct-SC2 | 12,892 | 10,160 | 2,732 | |
| Chinese Language | Alpaca-GPT4-Zh | 2,471 | 2,471 | 0 |
| Magpie-Qwen2-Pro-Zh | 7,481 | 7,481 | 0 | |
| Total | 158,667 | 94,539 | 64,128 |
🔼 This table details the composition of the FuseChat-3.0 dataset used for training. It’s broken down into two phases: Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO). The dataset includes samples from multiple categories: instruction following, mathematics, coding, and Chinese language. The number of samples used in each phase is specified for each category. Note that, due to a lack of suitable reward models, all Chinese language samples were only used for SFT and excluded from the DPO phase.
read the caption
Table 1: The constitution of FuseChat-3.0 dataset in SFT phase and DPO phase. As no suitable reward models were available for Chinese, we used all samples for SFT and omitted the DPO phase.
Full paper#