TL;DR#
Large Language Models (LLMs) have shown great success in machine translation. However, they still suffer from “translationese”, which leads to unnatural and overly literal translations. This issue is due to biases that are introduced during the supervised fine-tuning (SFT) phase. Pre-training on vast amounts of natural utterances should help LLMs generate natural sounding translations, but it does not due to the supervised fine-tuning. It makes the model biased towards the literal semantic mapping instead of a natural language generation.
To address these issues, this work systematically evaluates the prevalence of translationese in LLM-generated translations and investigates its roots during supervised training. They introduce methods such as polishing golden references and filtering unnatural training instances to mitigate the biases. The results suggest that these approaches help reduce translationese while improving the naturalness. Thus, they emphasize training-aware adjustments to optimize LLM translations.
Key Takeaways#
Why does it matter?#
This paper is important for researchers to reevaluate LLM training to optimize the quality of the translation outputs. The findings highlight potential biases introduced during supervised training and offer mitigation strategies, paving the way for more fluent and natural translation systems.
Visual Insights#

🔼 This figure shows the percentage of translations containing translationese errors produced by various large language models (LLMs). All LLMs were initially tested using a standard translation prompt. However, GPT-3.5 and GPT-4 were also tested with two additional prompts: a ‘Specified’ prompt that encouraged natural language, and a ‘Polishing’ prompt that asked the models to refine their translations. The ‘Polishing’ prompt led to significantly fewer translationese errors across both GPT-3.5 and GPT-4. The figure visually compares the results across all LLMs and prompt types, illustrating the effectiveness of the refinement process.
read the caption
Figure 1: Proportions of translations exhibiting translationese errors. All LLMs adopt direct translation prompts, with the exception of GPT-3.5 and GPT-4, which incorporate supplementary prompts to facilitate more natural translations. Both “Specified” and “Polishing” prompts have identical requirements; however, the ‘Polishing’ prompt specifically instructs LLMs to refine their generated translations.
| Sentence-level Translationese | |
|---|---|
| Source | Few-shot LLMs still lag behind vanilla fine-tuned models in the task. |
| LLM | 少样本LLMs仍然落后于原始细化训练模型在任务中。 (PPL: 151.5) |
| Refine | 在任务中,少样本LLMs仍然落后于原始细化训练模型。 (PPL: 128.8) |
| Source | Bei starker Hitze ließ diese Festigkeit zwar etwas nach. |
| LLM | However, at high temperatures this hardness did diminish somewhat. (PPL: 160.1) |
| Refine | However, this hardness did diminish somewhat at high temperatures. (PPL: 96.6) |
| Phrase-level Translationese | |
| Source | cats suffer night blindness |
| LLM | 猫将遭受夜盲症 (PPL: 335.3) |
| Refine | 猫会患上夜盲症 (PPL: 154.1) |
| Source | mehr Lebensqualität zu gewinnen |
| LLM | gain more quality of life (PPL: 620.5) |
| Refine | improve the quality of life (PPL: 27.6) |
🔼 This table presents examples of sentence-level and phrase-level translationese errors produced by large language models (LLMs) in English-to-Chinese and German-to-English translations. For each example, the source text, the LLM’s initial translation, and a refined translation (with translationese corrected) are shown. The perplexity (PPL) score is given for each translation, indicating the model’s uncertainty. Source text segments are highlighted in blue, while translationese errors and their subsequent refinements are highlighted in red, illustrating how the refinement process improves the naturalness of the translations.
read the caption
Table 1: Examples of Sentence-level and Phrase-level Translationese (English-Chinese and German-English translation). Source: source text; LLM: translations of LLMs; Refine: translations with translationese refined. Each case includes an LLM-generated translation alongside a refined version, with perplexity (PPL) values provided at the end. Blue text highlights the source segments, while red text identifies segments in the LLM translation where translationese occurs and is subsequently refined.
In-depth insights#
LLM Translationese#
The study highlights the counterintuitive presence of translationese in LLMs, despite their pre-training on vast natural language corpora. This suggests that supervised fine-tuning (SFT), intended to specialize LLMs for translation, may inadvertently introduce biases that prioritize literal semantic mapping over natural language generation, leading to unnatural and overly literal translations. The work systematically assesses the prevalence of translationese across different LLMs and languages, finding that even advanced models exhibit significant levels of this phenomenon. Interestingly, LLMs demonstrate the potential to produce more natural translations when prompted to refine their own outputs, hinting at the existence of latent knowledge and the possibility of mitigating translationese through training-aware adjustments. Addressing this issue is crucial for unlocking the full potential of LLMs in machine translation, paving the way for more fluent and target-language-consistent outputs. The effectiveness of refining golden references and filtering unnatural training instances in reducing translationese is also an essential finding.
SFT Bias Origins#
Supervised Fine-Tuning (SFT) can inadvertently introduce biases that skew LLMs away from their innate capacity for natural language generation. Despite pre-training on vast datasets of natural utterances, SFT often relies on training data that contains translationese. This forces the model to prioritize literal semantic mapping over stylistic fluency. SFT data are curated from existing benchmark datasets which, unfortunately, exhibit translationese, potentially biasing the supervised training process. By treating direct transformation from source to target as the primary objective, supervised training can overemphasize faithfulness at the expense of naturalness, leading to unexpected and unnatural translations. These biases can be hard to eliminate as the model may be inclined to continue the SFT style even during inference.
Refined Data SFT#
Refining data for SFT (Supervised Fine-Tuning) focuses on enhancing the quality of training data to improve model performance, particularly in areas like translation where subtle nuances are crucial. A key aspect is reducing ’translationese’, unnatural language arising from overly literal translations. This involves techniques like polishing golden references (high-quality, human-created translations) to make them more natural and target-language consistent. Another strategy is filtering unnatural training instances based on metrics such as perplexity to eliminate examples likely to introduce translationese bias. The goal is to create a training dataset that encourages the LLM to generate fluent and natural translations, rather than simply mimicking literal correspondences between source and target languages.
PPL-TSR Relation#
Perplexity (PPL) and Translationese Span Ratio (TSR) relation is a crucial aspect of evaluating machine translation quality, particularly in the context of large language models (LLMs). PPL, an intrinsic metric, reflects a model’s confidence in its generated text; lower PPL generally indicates more natural and fluent output. Conversely, TSR quantifies the presence of translationese, characterized by overly literal and unnatural translations. High TSR values suggest a stronger influence of the source language structure on the translated text, diminishing target language fluency. Ideally, a strong negative correlation between PPL and TSR is desired, signifying that as a translation becomes more natural (lower PPL), it exhibits fewer signs of translationese (lower TSR). However, establishing this relationship requires careful consideration, as other factors like domain specificity and text complexity can influence both metrics independently. Further research is needed to refine methods for accurately assessing and mitigating translationese using PPL and TSR in LLM-based translation systems.
Need Data Adjust#
Based on the broader context of mitigating translationese in machine translation, the concept of ‘Need Data Adjust’ would likely revolve around recognizing and rectifying biases or unnatural patterns present within the training datasets used to fine-tune large language models (LLMs). It highlights the importance of data quality in shaping the output of these models, suggesting that simply training on large volumes of data is insufficient. Instead, the focus shifts to curating and refining the training data to ensure it reflects natural and fluent language usage. This adjustment might involve techniques like filtering out translationese-prone instances, polishing existing translations to remove unnatural expressions, or augmenting the dataset with more examples of natural language. The goal is to reduce the model’s tendency to produce overly literal or stylistically awkward translations, ultimately improving the overall naturalness and fluency of the generated text. By proactively addressing data-related issues, the translationese effect can be greatly lessened.
More visual insights#
More on figures

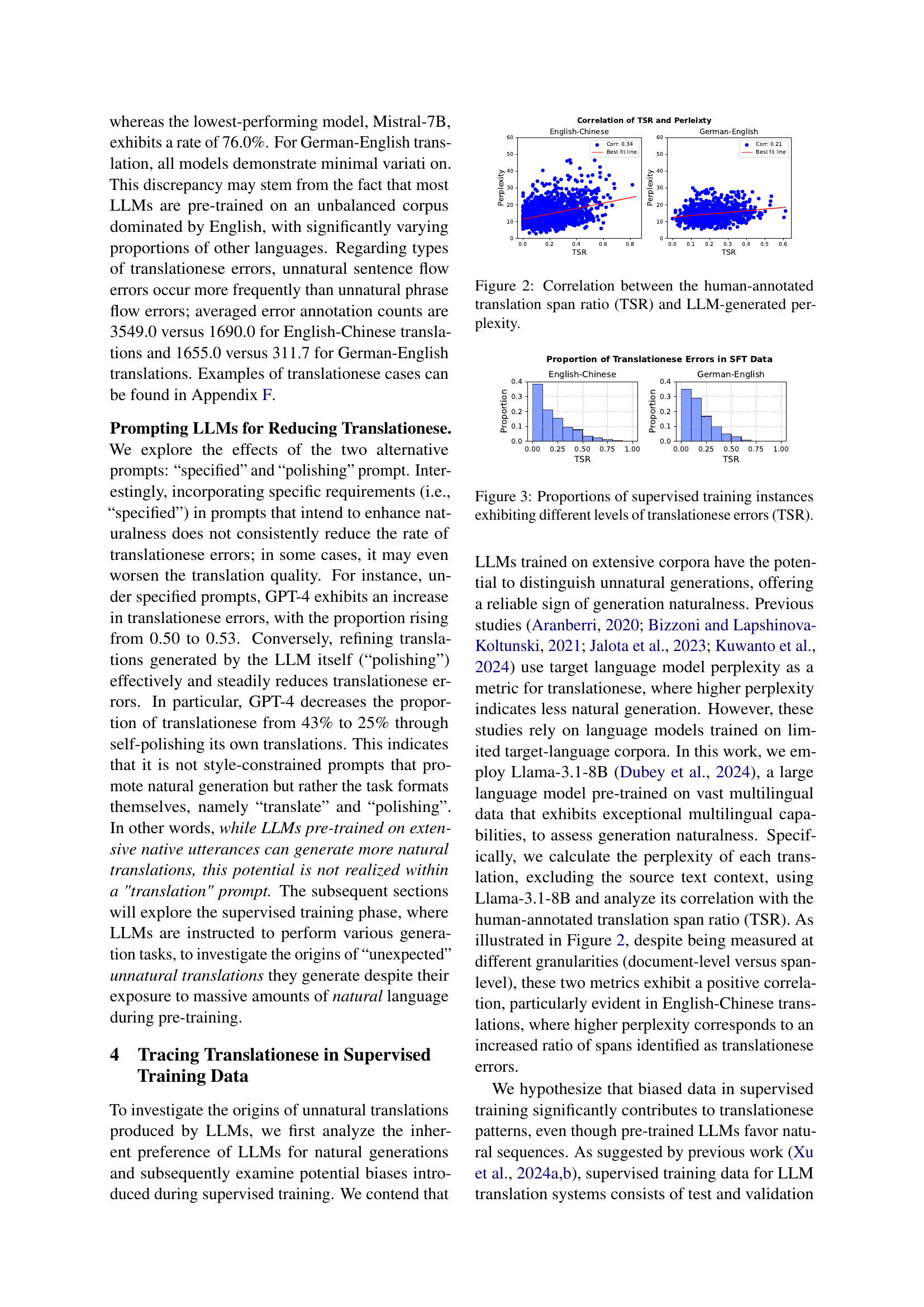
🔼 This figure displays the correlation between the translation span ratio (TSR), representing the proportion of a translation exhibiting translationese errors as determined by human annotators, and the perplexity scores generated by LLMs for the same translations. Higher TSR values indicate more unnatural translations, while higher perplexity values generally suggest less fluent and natural language. The correlation is shown separately for English-to-Chinese and German-to-English translations, providing insights into the relationship between human judgment of naturalness and LLM-predicted perplexity as a measure of translation quality.
read the caption
Figure 2: Correlation between the human-annotated translation span ratio (TSR) and LLM-generated perplexity.

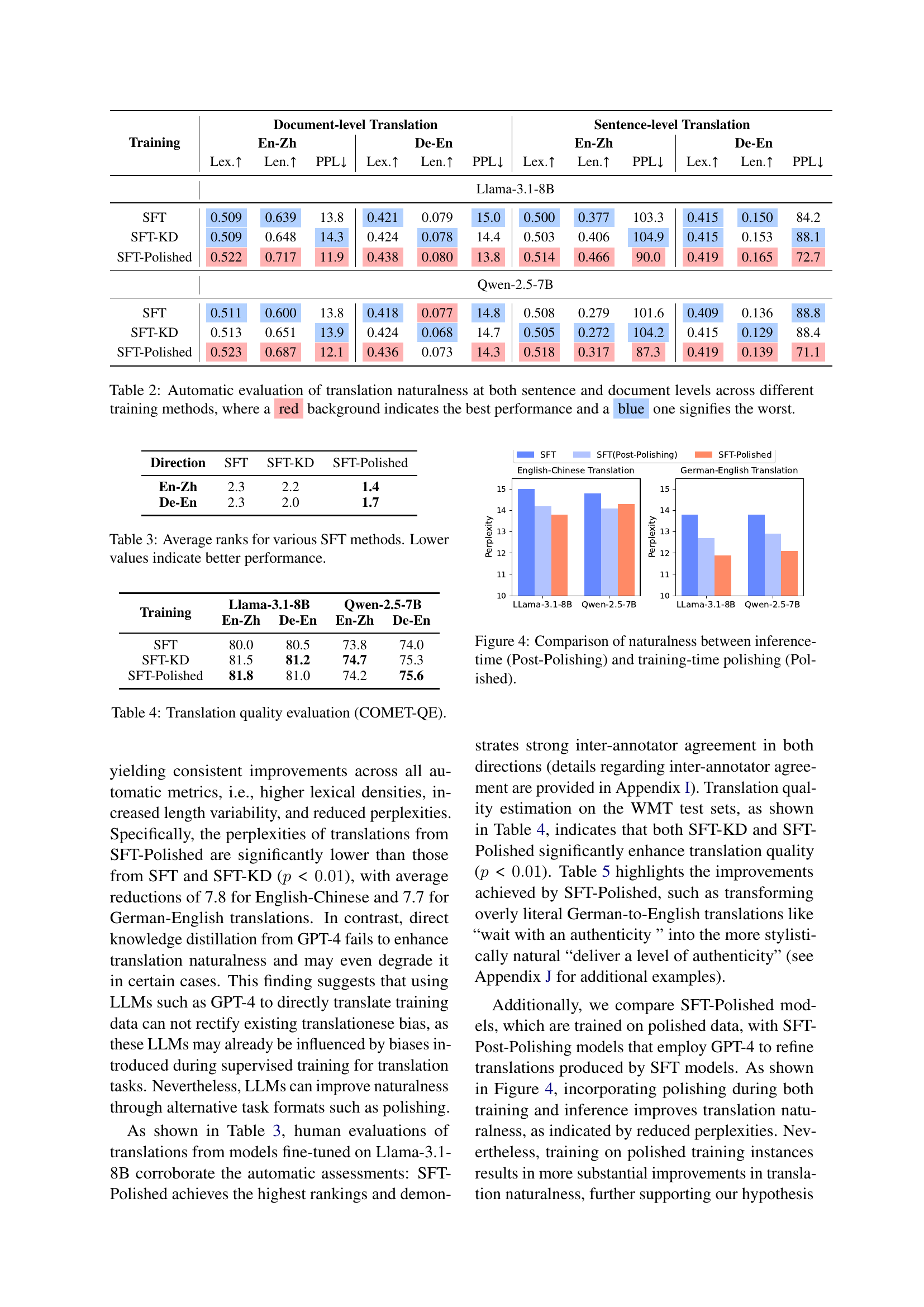
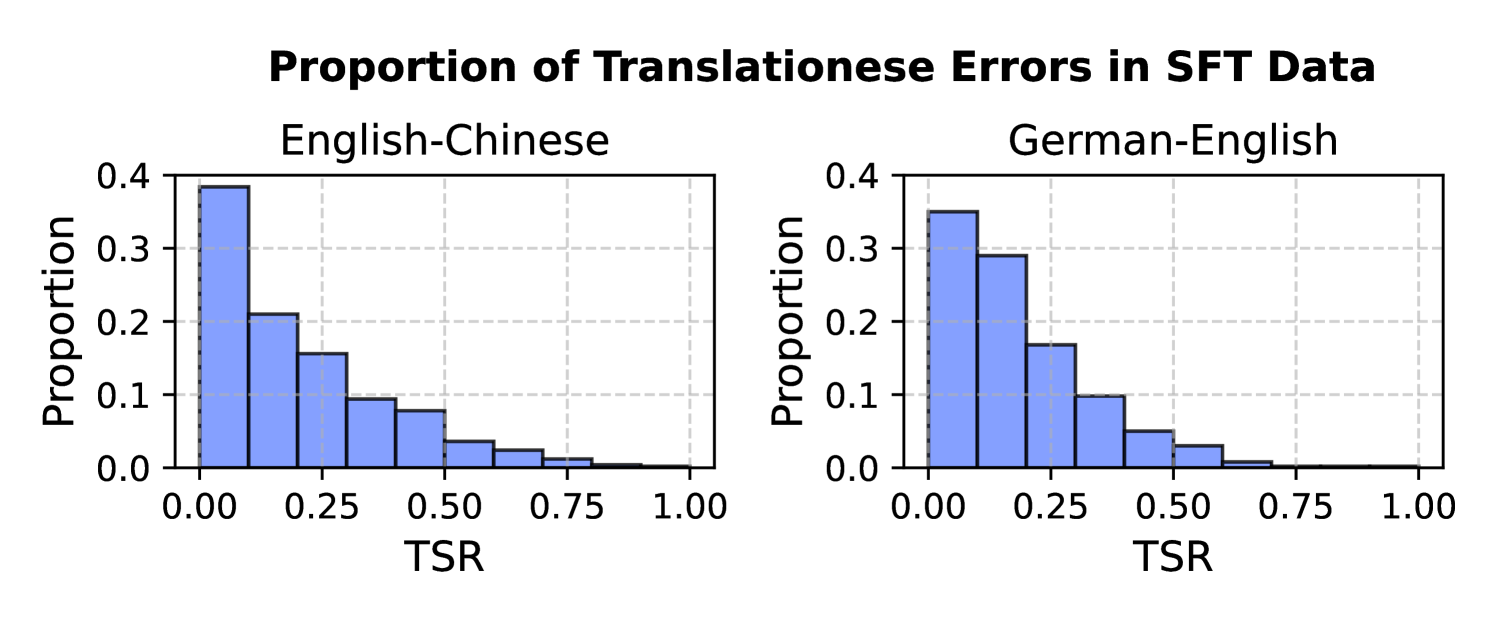
🔼 This figure shows the percentage of training examples in supervised fine-tuning datasets that contain varying degrees of translationese errors, as measured by the Translationese Span Ratio (TSR). A higher TSR indicates a greater proportion of the text exhibiting translationese. The figure visually represents the prevalence of translationese in the training data for both English-to-Chinese and German-to-English translation tasks.
read the caption
Figure 3: Proportions of supervised training instances exhibiting different levels of translationese errors (TSR).
🔼 Figure 4 presents a bar chart comparing the naturalness of translations generated using two different approaches: inference-time polishing (post-polishing) and training-time polishing (polished). The chart visualizes the perplexity scores achieved by Llama-3.1-8B and Qwen-2.5-7B models trained with the two methods for both English-to-Chinese and German-to-English translations. Lower perplexity indicates better translation naturalness. By comparing the perplexity for both approaches, the figure illustrates the effectiveness of incorporating polishing during the training phase versus only during inference on improving the translation quality and reducing translationese.
read the caption
Figure 4: Comparison of naturalness between inference-time (Post-Polishing) and training-time polishing (Polished).

🔼 This figure displays the impact of filtering out the least natural training samples on the quality and naturalness of machine translation. The x-axis represents the proportion of filtered training instances, while the y-axis shows two metrics: perplexity (lower is better, indicating more natural language) and COMET score (higher is better, indicating better overall translation quality). The chart shows that filtering a moderate amount of the least natural training data improves both perplexity and COMET scores. However, excessive filtering negatively affects both metrics.
read the caption
Figure 5: Translation naturalness and quality w.r.t. filtered training samples.

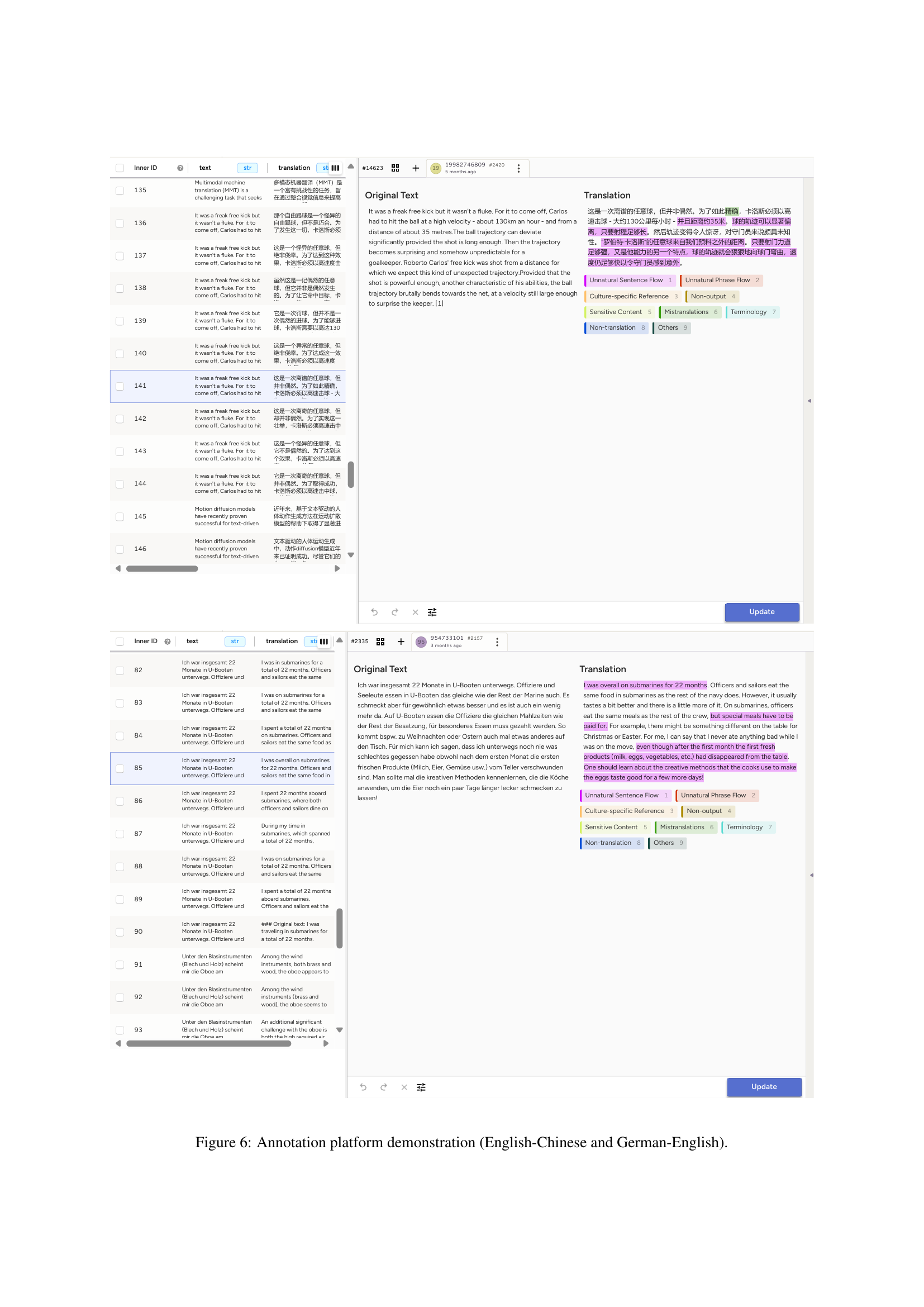
🔼 This figure shows screenshots of the annotation platform used in the study. The platform, built using Label Studio, allows expert translators to annotate text spans exhibiting translationese errors in machine-translated documents. The examples shown are for English-Chinese and German-English translations. The interface displays the original text, machine translation, and tools for highlighting specific segments and categorizing the type of translationese error (unnatural sentence flow or unnatural phrase flow).
read the caption
Figure 6: Annotation platform demonstration (English-Chinese and German-English).
More on tables
| Training | Document-level Translation | Sentence-level Translation | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| En-Zh | De-En | En-Zh | De-En | |||||||||
| Lex. | Len. | PPL | Lex. | Len. | PPL | Lex. | Len. | PPL | Lex. | Len. | PPL | |
| Llama-3.1-8B | ||||||||||||
| SFT | 0.509 | 0.639 | 13.8 | 0.421 | 0.079 | 15.0 | 0.500 | 0.377 | 103.3 | 0.415 | 0.150 | 84.2 |
| SFT-KD | 0.509 | 0.648 | 14.3 | 0.424 | 0.078 | 14.4 | 0.503 | 0.406 | 104.9 | 0.415 | 0.153 | 88.1 |
| SFT-Polished | 0.522 | 0.717 | 11.9 | 0.438 | 0.080 | 13.8 | 0.514 | 0.466 | 90.0 | 0.419 | 0.165 | 72.7 |
| Qwen-2.5-7B | ||||||||||||
| SFT | 0.511 | 0.600 | 13.8 | 0.418 | 0.077 | 14.8 | 0.508 | 0.279 | 101.6 | 0.409 | 0.136 | 88.8 |
| SFT-KD | 0.513 | 0.651 | 13.9 | 0.424 | 0.068 | 14.7 | 0.505 | 0.272 | 104.2 | 0.415 | 0.129 | 88.4 |
| SFT-Polished | 0.523 | 0.687 | 12.1 | 0.436 | 0.073 | 14.3 | 0.518 | 0.317 | 87.3 | 0.419 | 0.139 | 71.1 |
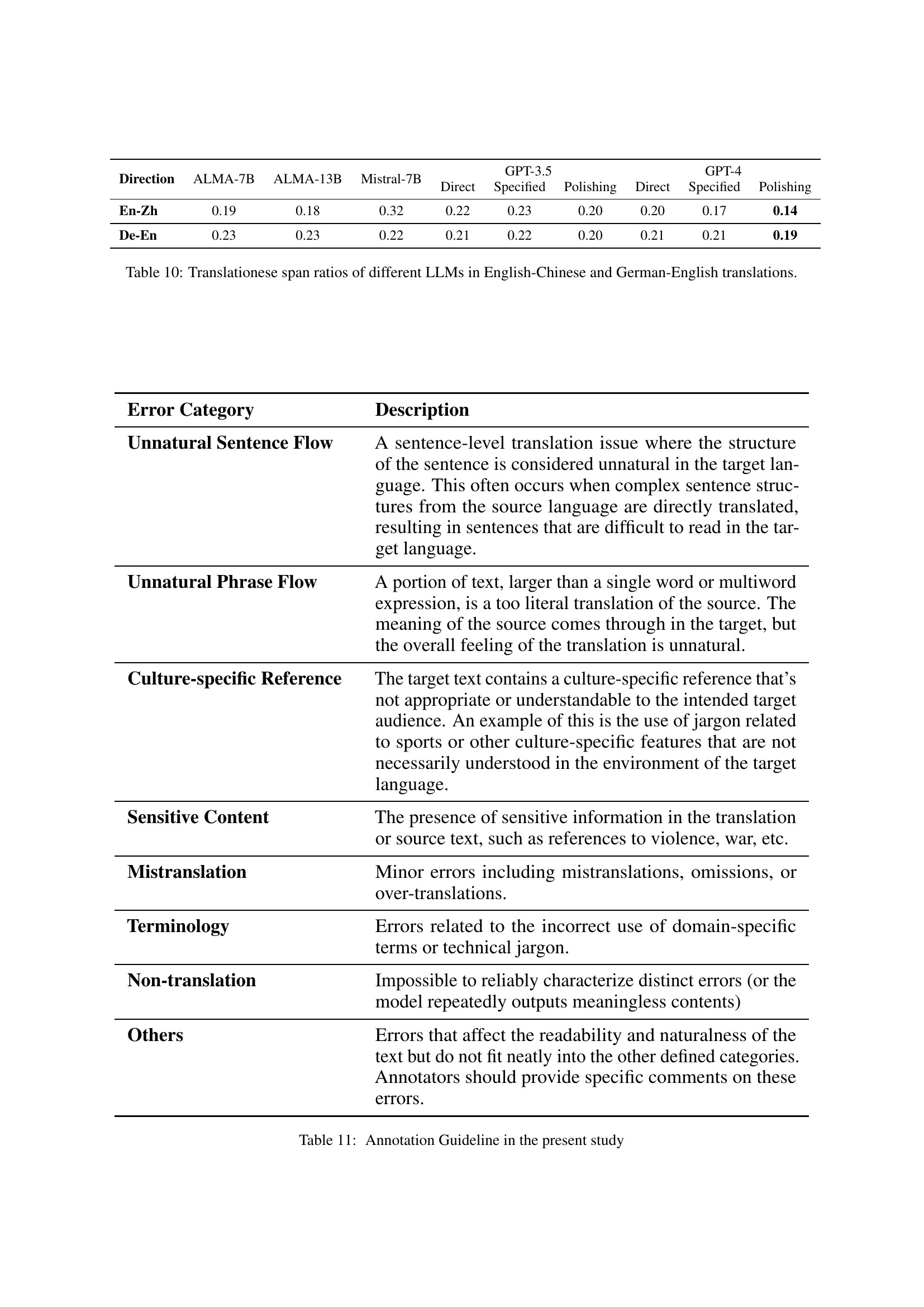
🔼 This table presents a quantitative analysis of the translation naturalness achieved by different large language models (LLMs) trained using various methods. The evaluation considers both sentence-level and document-level metrics, providing a comprehensive assessment of translation quality. Performance is measured automatically using perplexity (PPL), lexical density (Lex.), length variance (Len.), and COMET-QE scores. Color-coding helps visualize the best and worst performing models for each metric, allowing for an easy comparison of different training strategies. This detailed evaluation is crucial for understanding the effectiveness of different LLM training approaches and the challenges associated with achieving natural-sounding translations.
read the caption
Table 2: Automatic evaluation of translation naturalness at both sentence and document levels across different training methods, where a red background indicates the best performance and a blue one signifies the worst.
| Direction | SFT | SFT-KD | SFT-Polished |
|---|---|---|---|
| En-Zh | 2.3 | 2.2 | 1.4 |
| De-En | 2.3 | 2.0 | 1.7 |
🔼 This table presents the average ranks assigned by human evaluators to different supervised fine-tuning (SFT) methods for machine translation. Lower ranks indicate better performance in terms of translation naturalness. The methods compared include the baseline SFT approach, knowledge distillation from GPT-4 (SFT-KD), and a method that refines training references using GPT-4 before fine-tuning (SFT-Polished). The ranks are averaged across three human evaluators for English-to-Chinese and German-to-English translation tasks.
read the caption
Table 3: Average ranks for various SFT methods. Lower values indicate better performance.
| Training | Llama-3.1-8B | Qwen-2.5-7B | ||
|---|---|---|---|---|
| En-Zh | De-En | En-Zh | De-En | |
| SFT | 80.0 | 80.5 | 73.8 | 74.0 |
| SFT-KD | 81.5 | 81.2 | 74.7 | 75.3 |
| SFT-Polished | 81.8 | 81.0 | 74.2 | 75.6 |
🔼 This table presents the results of the COMET-QE (Quality Estimation) metric applied to translations generated using different training methods. COMET-QE is a reference-free metric assessing the quality of machine translation. Lower scores indicate better translation quality. The table compares the quality of translations using standard supervised fine-tuning (SFT), knowledge distillation from GPT-4 (SFT-KD), and a refined approach that polishes the training data with GPT-4 (SFT-Polished), across English-to-Chinese and German-to-English translation directions.
read the caption
Table 4: Translation quality evaluation (COMET-QE).
| Training | En-Is | En-Cs | En-De | En-Ru |
|---|---|---|---|---|
| Perplexity | ||||
| SFT | 27.0 | 59.9 | 56.5 | 42.8 |
| SFT-Polished | 24.9 | 50.9 | 44.0 | 35.9 |
| COMET-QE | ||||
| SFT | 80.6 | 81.3 | 63.0 | 81.0 |
| SFT-Polished | 84.1 | 83.1 | 65.7 | 82.4 |
🔼 This table presents a qualitative comparison of translations generated by different large language models (LLMs) for the same source text in English and their respective translations into Chinese and German. It showcases examples of how different LLMs handle translation tasks and highlights the issue of translationese, where the translations are too literal and unnatural. The models compared are the baseline SFT (Supervised Fine-Tuning), SFT-KD (Knowledge Distillation from GPT-4), and SFT-Polished (Fine-tuning with GPT-4 polished references). The table provides insights into how different training techniques affect the naturalness and fluency of the generated translations.
read the caption
Table 5: Case study of different model translations.
| Translation Prompt | Please translate the following {source_language} text to {target_language}. |
| ### Source text: {source_text} | |
| ### Translation: | |
| Specified Prompt | Please translate the following {source_language} text to {target_language}, ensuring that the translation is fluent, accurate, and conforms to typical {target_language} expressions and style. |
| ### Source text: {source_text} | |
| ### Translation: | |
| Polishing Prompt | Please polish the corresponding {target_language} translation of an {source_language} text, ensuring that the translation is fluent, accurate, and conforms to typical {target_language} expressions and style. |
| ### Source text: {source_text} | |
| ### Original Translation: {target_text} | |
| ### Translation: |
🔼 This table presents the results of an experiment evaluating the impact of a proposed method (SFT-Polished) on the naturalness and quality of machine translations generated by large language models (LLMs). The experiment focused on translating English sentences into four additional languages: Czech, Icelandic, German, and Russian. For each language, the table displays two metrics: perplexity (PPL), a measure of the LLM’s uncertainty in generating the translation, with lower values indicating better fluency and naturalness; and COMET-QE, a quality metric reflecting the overall translation adequacy. The table compares the performance of the baseline supervised fine-tuning (SFT) approach to that of the SFT-Polished approach, highlighting the improvements achieved in translation quality and naturalness through the proposed method. These results demonstrate the generalizability of the SFT-Polished method across multiple languages.
read the caption
Table 6: Generation naturalness (perplexity) and quality (COMET-QE) of translations from English to four additional languages.
| Direction | Domains | Avg. Tokens | #. Docs. |
|---|---|---|---|
| En-Zh | CNN, Arixv, Wikipedia, Quora | 225.6 | 1,800 |
| De-En | Focus, Quora | 138.1 | 9,00 |
🔼 This table details the three different prompts used for machine translation experiments in the paper. The first prompt is a basic translation request used for all language models tested. The second and third prompts are more specific, aiming to encourage more natural language generation. These latter two prompts were only used for the GPT models (GPT-3.5 and GPT-4). The table highlights the differences in prompt wording to elicit different translation styles. The variations in prompts help to evaluate the models’ ability to adapt to nuanced instructions and produce translations of higher quality.
read the caption
Table 7: Three types of prompts used in large language model translation. The first one is utilized for all models whereas the other two are only used in GPT models.
| English-Chinese Translation | |||
|---|---|---|---|
| Judge | A-1 | A-2 | A-3 |
| A-1 | - | 0.592 | 0.742 |
| A-2 | 0.592 | - | 0.603 |
| A-3 | 0.742 | 0.603 | - |
| German-English Translation | |||
| Judge | A-1 | A-2 | A-3 |
| A-1 | - | 0.753 | 0.587 |
| A-2 | 0.753 | - | 0.553 |
| A-3 | 0.587 | 0.553 | - |
🔼 This table presents a summary of the datasets used in the paper, providing details on the number of documents and the average number of tokens per document for both English-to-Chinese and German-to-English translation tasks.
read the caption
Table 8: Data statistics of document-level translations.
| Direction | ALMA-7B | ALMA-13B | Mistral-7B | GPT-3.5 | GPT-4 | ||||
|---|---|---|---|---|---|---|---|---|---|
| Direct | Specified | Polishing | Direct | Specified | Polishing | ||||
| En-Zh | 0.19 | 0.18 | 0.32 | 0.22 | 0.23 | 0.20 | 0.20 | 0.17 | 0.14 |
| De-En | 0.23 | 0.23 | 0.22 | 0.21 | 0.22 | 0.20 | 0.21 | 0.21 | 0.19 |
🔼 This table presents the inter-annotator agreement scores, calculated using Kendall’s Tau, for the human evaluation task focused on assessing the naturalness of translations. The scores reflect the level of consistency between different annotators in their rankings of translation naturalness, providing a measure of the reliability of the human evaluation process.
read the caption
Table 9: Inter-annotator agreement (Kendall’s Tau scores) on naturalness voting.
| Error Category | Description |
|---|---|
| Unnatural Sentence Flow | A sentence-level translation issue where the structure of the sentence is considered unnatural in the target language. This often occurs when complex sentence structures from the source language are directly translated, resulting in sentences that are difficult to read in the target language. |
| Unnatural Phrase Flow | A portion of text, larger than a single word or multiword expression, is a too literal translation of the source. The meaning of the source comes through in the target, but the overall feeling of the translation is unnatural. |
| Culture-specific Reference | The target text contains a culture-specific reference that’s not appropriate or understandable to the intended target audience. An example of this is the use of jargon related to sports or other culture-specific features that are not necessarily understood in the environment of the target language. |
| Sensitive Content | The presence of sensitive information in the translation or source text, such as references to violence, war, etc. |
| Mistranslation | Minor errors including mistranslations, omissions, or over-translations. |
| Terminology | Errors related to the incorrect use of domain-specific terms or technical jargon. |
| Non-translation | Impossible to reliably characterize distinct errors (or the model repeatedly outputs meaningless contents) |
| Others | Errors that affect the readability and naturalness of the text but do not fit neatly into the other defined categories. Annotators should provide specific comments on these errors. |
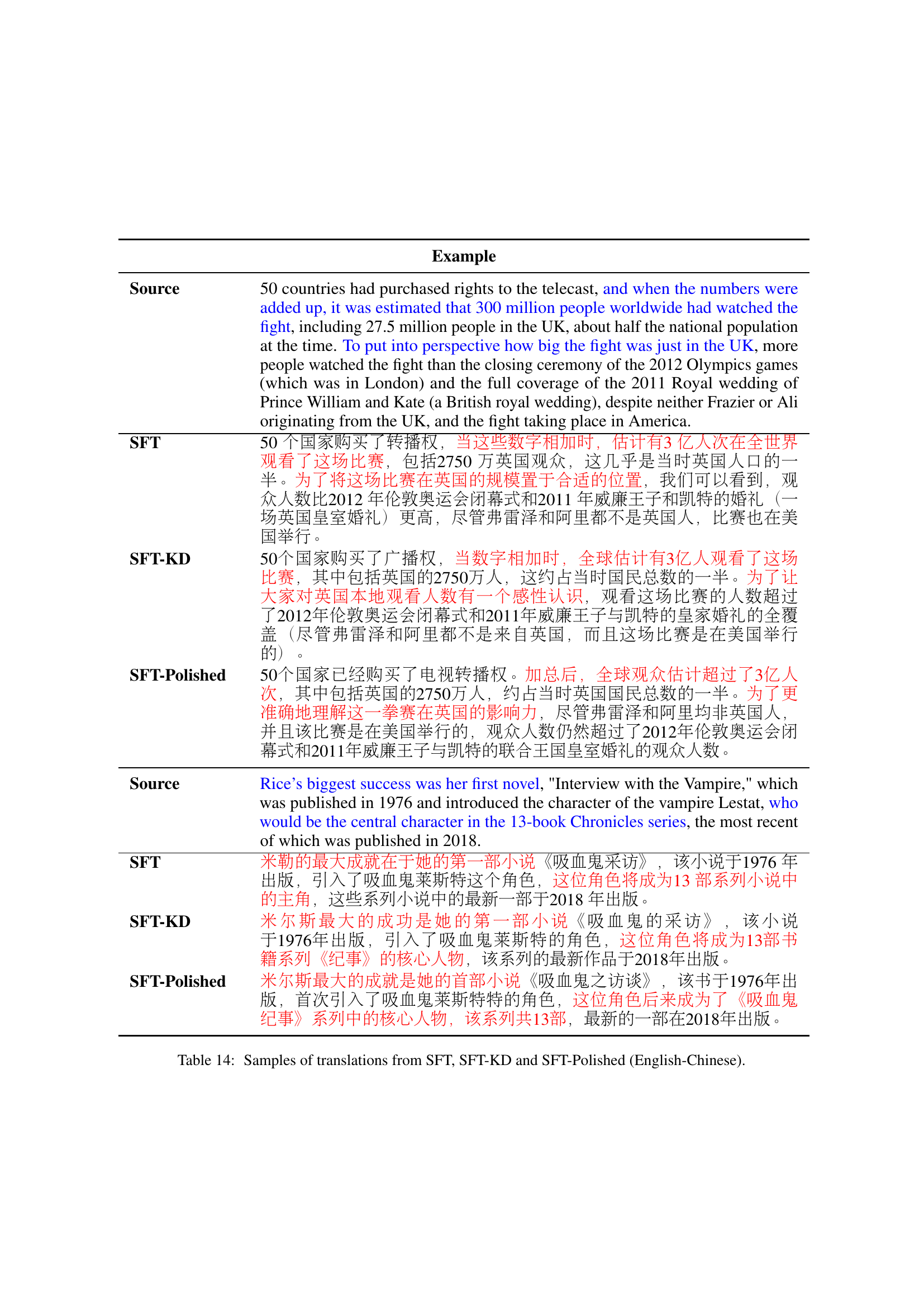
🔼 This table presents the Translationese Span Ratio (TSR) for different Large Language Models (LLMs) across English-to-Chinese and German-to-English translation tasks. The TSR represents the proportion of spans in a translation identified as containing translationese errors by expert human annotators. Results are shown for various LLMs, including both specialized translation models and general-purpose chat models. Different prompting strategies are compared for the GPT models, illustrating the impact of prompting on translationese prevalence.
read the caption
Table 10: Translationese span ratios of different LLMs in English-Chinese and German-English translations.
| Error Category | Example | |
|---|---|---|
| Unnatural Sentence Flow | Source | So geht es nicht, findet die italienische Regierung und ließ Dutzende von elektrischen Fiat Topolinos beschlagnahmen. |
| Translation | This is not acceptable, finds the Italian government and seized dozens of electric Fiat Topolinos. | |
| Source | Das zweite Gruppenspiel bestreitet die DFB-Elf fünf Tage später am 19. Juni in Stuttgart gegen Ungarn. | |
| Translation | The second group game will be played five days later on 19 June in Stuttgart against Hungary. | |
| Source | Nach meinem Wissen sind wir die Ersten in Deutschland, die das angewendet haben, sogar in Europa | |
| Translation | To the best of my knowledge, we are the pioneers in Germany in using it, even in Europe, | |
| Unnatural Phrase Flow | Source | schufen aber einen rockigeren sound |
| Translation | crafted a grittier sound | |
| Source | sie sich stark mit anderen Arten vermischt | |
| Translation | it mixes strongly with other species | |
| Source | sind wir in der USA in Urlaub gewesen | |
| Translation | we vacationed in the US | |
🔼 Table 11 provides a detailed guideline for annotating translation errors, categorized into: Unnatural Sentence Flow (structural issues), Unnatural Phrase Flow (literal translations), Culture-Specific Reference (inappropriate cultural references), Sensitive Content (offensive or sensitive information), Mistranslation (incorrect translations), Terminology (domain-specific errors), Non-translation (unrelated or incomprehensible translations), and Others (miscellaneous errors). Each category includes a description to help annotators accurately identify and classify the translation errors.
read the caption
Table 11: Annotation Guideline in the present study
Full paper#