TL;DR#
The study introduces IFIR, a benchmark for evaluating instruction-following in specialized domains like finance, law, healthcare & science, where customized directions are critical. IFIR addresses limitations in existing models by incorporating instructions at varying complexity levels. A new LLM-based eval method is also proposed to assess model performance, addressing shortcomings of traditional methods.
Experiments with 15 information retrievers reveal significant challenges in effectively following domain-specific instructions. The paper highlights limitations of current models & potential of LLM-based retrievers. It introduces INSTFOL, a more reliable evaluation method and provides in-depth analyses to help future retriever development by offering insights to improve IR systems.
Key Takeaways#
Why does it matter?#
IFIR offers a new, specialized benchmark for instruction-following IR that highlights challenges in current models & informs future retriever development. Its detailed analysis and novel evaluation method could greatly improve search tech in expert domains.
Visual Insights#
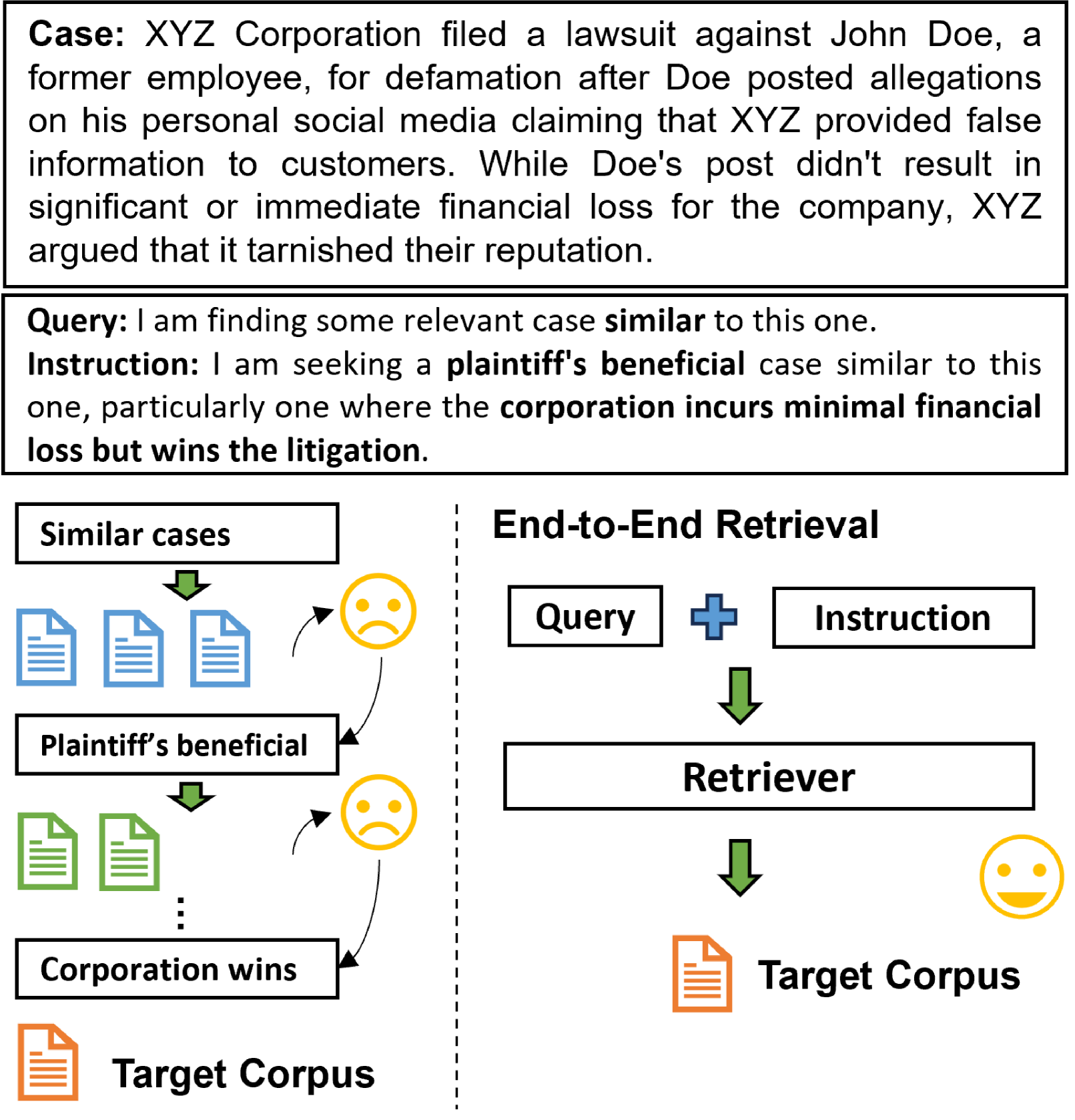
🔼 This figure illustrates instruction-following in information retrieval (IR). The top panel shows an example of a complex query for legal cases, highlighting the challenge for current IR systems. The bottom-left panel demonstrates how users typically work around this limitation by simplifying their queries and manually filtering results, a time-consuming process. The bottom-right panel emphasizes the study’s focus: evaluating the capabilities and limitations of modern end-to-end retrieval systems to handle complex instruction-following tasks in specialized domains.
read the caption
Figure 1: (Top): An illustration of instruction-following IR scenarios explored in this study. The example simulates a legal case search, where the user provides detailed instructions to retrieve relevant legal cases. Current IR systems struggle to handle such complex queries. (Bottom left): As a result, users have to break down their information needs into simpler, iterative search queries and manually filter the retrieved cases, resulting in a time-consuming and inefficient process. (Bottom right): This study focuses on evaluating the progress and limitations of current end-to-end retrieval systems in expert-domain instruction-following IR.
| Domain | Adopted Datasets | # Qry | Corpus Size | # RP | Designed Tasks Reflecting Real-world Challenges |
| Finance | FiQA Jangid et al. (2018) | 1,718 | 57,638 | 3.54 | Retrieve financial suggestions based on user-specific needs to support informed decision-making. |
| \hdashline Scientific | SciFact-open Wadden et al. (2022) | 152 | 500,000 | 4.84 | Retrieve relevant scientific literature tailored to specific scientific research needs. |
| Literature | NFCorpus Boteva et al. (2016) | 86 | 3,633 | 2.81 | |
| \hdashline Law | AILA Bhattacharya et al. (2019) | 85 | 2,914 | 2.01 | Retrieve legal cases that satisfy customized demands. |
| FIRE Mandal et al. (2017) | 168 | 1,745 | 3.36 | Retrieve legal cases to support the judicial decision. | |
| \hdashline Healthcare | TREC-PM Roberts et al. (2017, 2018) | 172 | 241,006 | 15.61 | Retrieve relevant clinical trials based on patient’s demographics (e.g., age, gender, medical history) |
| TREC-CDS Roberts et al. (2015) | 43 | 633,955 | 10.84 |
🔼 This table presents an overview of the datasets used to create the IFIR benchmark, a comprehensive benchmark for evaluating instruction-following capabilities in expert-domain information retrieval. For each of four domains (finance, scientific literature, law, and healthcare), it lists the original dataset used, the number of queries, the size of the corpus, the average number of relevant passages per query, and a brief description of the types of tasks and challenges involved in each domain. The table helps to understand the scope and diversity of IFIR.
read the caption
Table 1: Overview of the adopted datasets and designed instruction-following IR tasks in IfIR, along with basic statistics for each domain. “# RP” represents the average relevant passage number per instruction-following query.
In-depth insights#
IFIR: Benchmark#
The IFIR benchmark is introduced as a novel resource to evaluate the instruction-following capabilities of information retrieval systems in specialized domains. Its creation addresses the gap in current benchmarks, which often oversimplify instructions or focus on general domains. IFIR’s strength lies in its coverage of finance, scientific literature, law, and healthcare, with varying levels of instruction complexity that replicate real-world scenarios. The benchmark’s construction involves a semi-automated, human-in-the-loop pipeline to ensure high quality and relevance. The benchmark facilitates fine-grained analysis and guide future retriever development. The LLM-based metric offers a way to accurately assess how well retrievers follow instructions in niche fields.
Expert Domains IR#
Expert domain IR benchmarks are crucial for advancing information retrieval in specialized fields like law, finance, healthcare, and science. These benchmarks address the need for systems to handle complex, context-aware queries that go beyond simple keyword searches. Developing robust IR systems for expert domains facilitates evidence-based decision-making, accelerates research, and enables efficient access to domain-specific knowledge. The challenge lies in capturing the nuanced requirements and domain-specific terminology, ensuring the retrieval systems understand and process instructions effectively to meet the needs of experts in these specialized areas.
Human-in-loop#
In the context of this research paper about instruction-following information retrieval, a “human-in-the-loop” approach is crucial for several aspects of the methodology. First, it is essential for generating high-quality training data. While Large Language Models(LLMs) can automatically create instructions or evaluate retrieval results, human experts are needed to validate and refine the generated content to ensure it is accurate and relevant. Second, human evaluations are indispensable for assessing the performance of the retrieval system. As the paper states, LLM-based metrics can be useful, but correlation with human judgement is vital to ensure that the metric is trustworthy. A human-in-the-loop approach can also be incorporated into the retrieval system itself, where user feedback is used to improve results. Such iterative approach enables a deeper understanding of user needs, leading to more relevant and accurate retrieval results.
LLM metric:INSTFOL#
The paper introduces INSTFOL, a novel LLM-based metric designed to specifically evaluate instruction-following capabilities in information retrieval (IR) systems, addressing limitations of traditional metrics like nDCG which don’t fully capture fine-grained aspects of following instructions. INSTFOL assesses the improvement a retriever demonstrates when instructions are incorporated, compared to when they are not. It leverages LLMs to score the relevance between instruction-following queries and retrieved passages, mitigating potential biases through probability normalization techniques. Experiments use GPT-40-mini and a novel ranking approach. INSTFOL exhibits a high correlation with human evaluations, highlighting its reliability in assessing a retriever’s ability to follow instructions, making it valuable in complex information retrieval tasks in specialized domains. INSTFOL aims to more accurately assess how well retrievers follow instructions, offering a more targeted and granular evaluation.
Robust Retrieval#
Robust retrieval is crucial in expert domains due to nuanced queries. The paper addresses this, introducing IFIR to evaluate instruction-following in specialized fields, highlighting the limitations of current models in handling complex, domain-specific instructions. This is evident in the challenges faced by current instruction-tuned models with long, customized requests. The study’s analysis emphasizes the need for models that exhibit stable instruction-following and better results compared to other retrievers. The strong Pearson correlation coefficient found in the proposed evaluation metric suggests that the instruction-following is key for robust performance. This all suggests potential solutions for end-to-end specialized-domain retrieval scenarios and could lead to domain adaption.
More visual insights#
More on figures
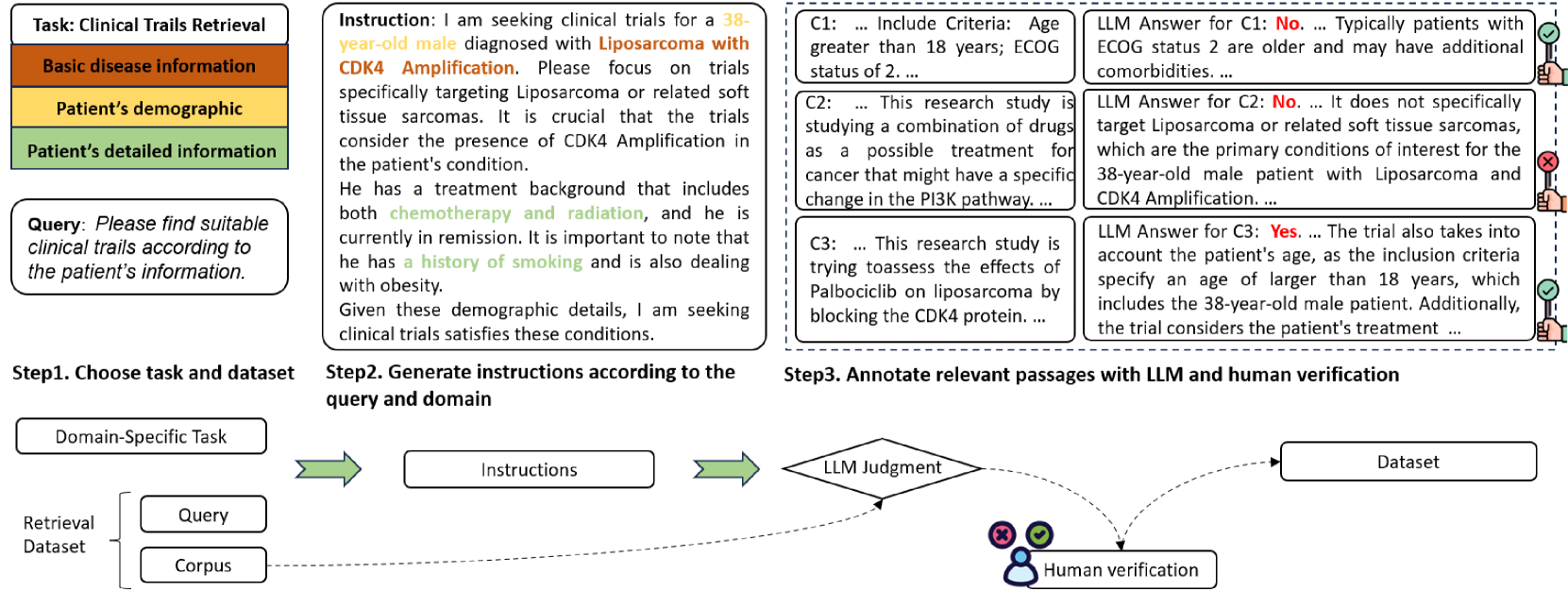
🔼 This figure illustrates the pipeline used to create the IFIR benchmark dataset. First, a domain-specific task is selected based on the source dataset. Then, instructions for that task are generated, mirroring real-world user queries. These instructions vary in complexity. An LLM (Large Language Model) then assesses the relevance of existing corpora to these newly generated instructions. The color-coding in the ‘Task’ section visually links instruction criteria to the relevant passages in the corpus. This process ensures that the dataset contains relevant passages that accurately reflect the complexity and nuance of real-world instruction-following scenarios in expert domains.
read the caption
Figure 2: Dataset Construction Pipeline: We derive a specific task according to the dataset, which then guides the generation of instructions based on the original query and task conditions. An LLM is used to assess whether the corpora are relevant to these instructions. As illustrated in the figure, different colors in the “Task” section correspond to the conditions outlined in the “Instruction” section.
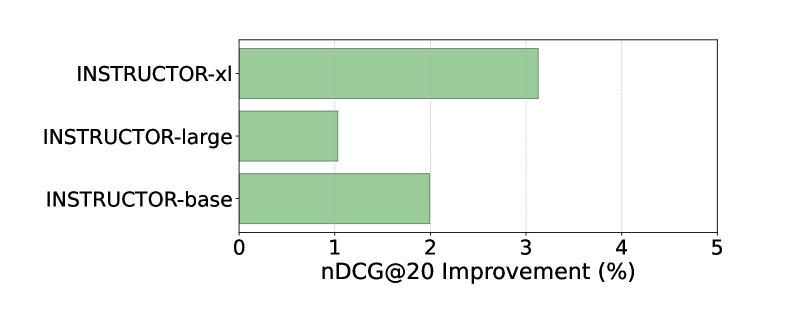
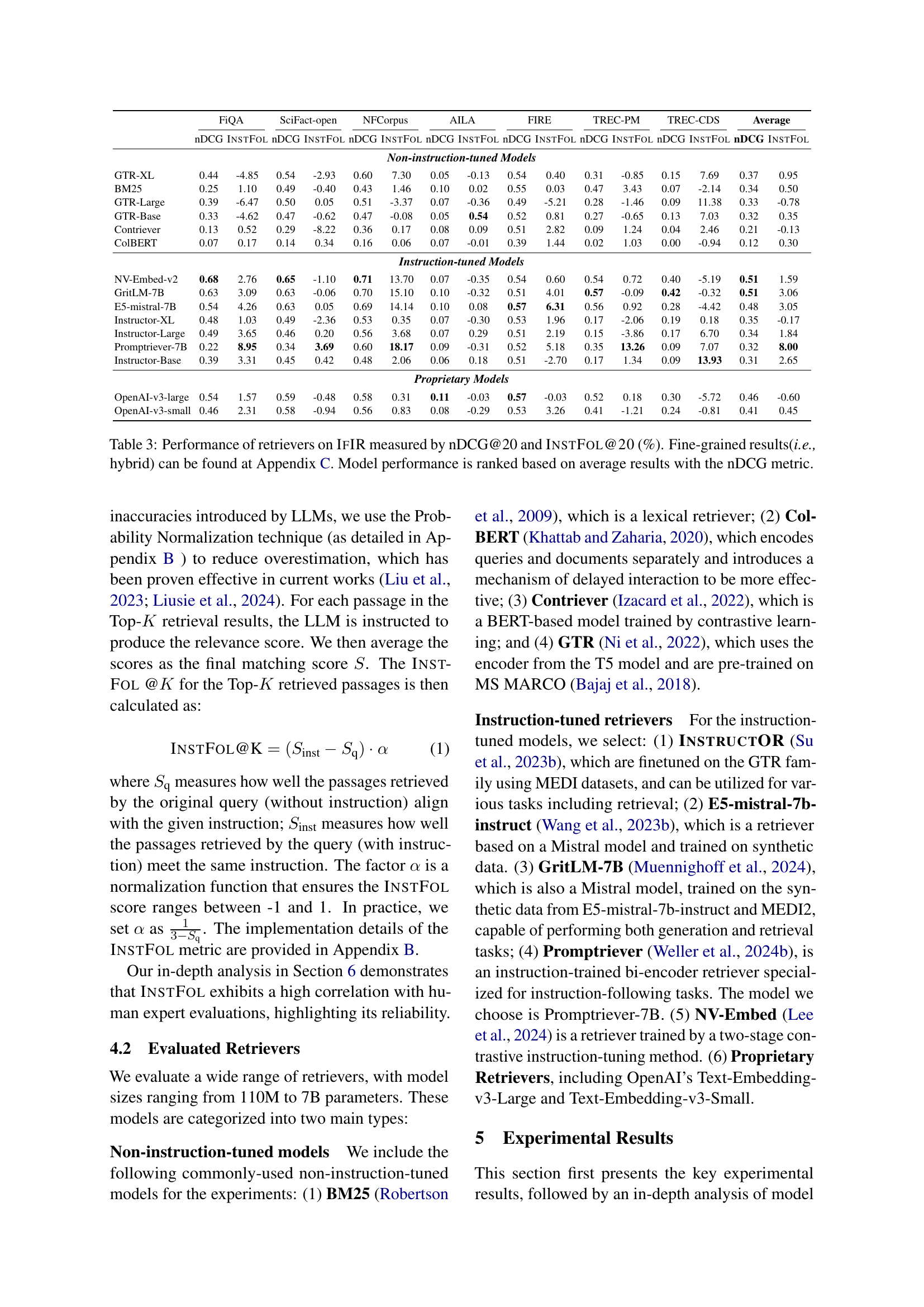
🔼 This figure displays the improvement in nDCG scores achieved by incorporating detailed instructions into retrieval queries. It compares the performance of different models with and without the use of these detailed instructions, providing insights into the effectiveness of instruction-following in retrieval tasks. The chart likely shows the percentage change in nDCG for each model when using detailed instructions, highlighting the impact of instruction detail on retrieval performance. Higher bars indicate a greater performance boost from using more detailed instructions.
read the caption
Figure 3: The nDCG improvement when the model is provided with detailed instructions for retrieval.
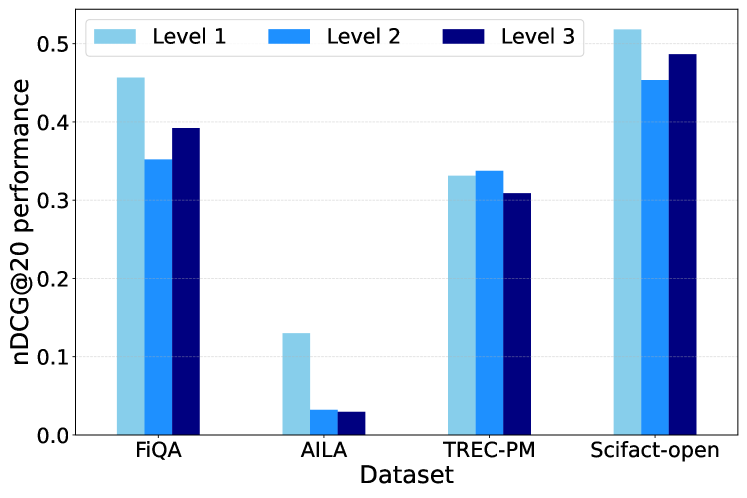
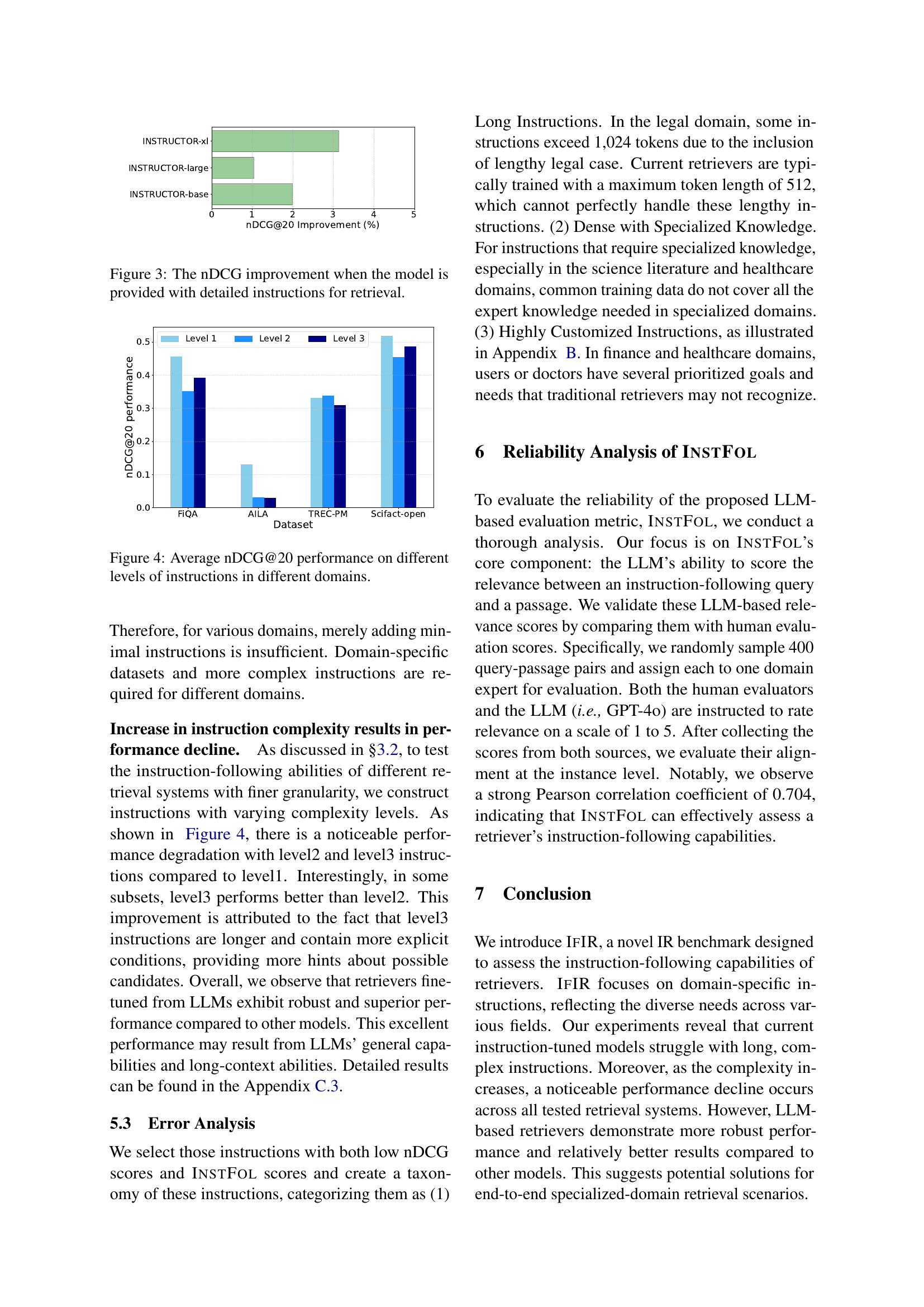
🔼 This figure displays the average normalized discounted cumulative gain (nDCG@20) scores achieved by various information retrieval models across three different levels of instruction complexity within four specialized domains: finance, scientific literature, law, and healthcare. Each bar represents the average nDCG@20 score for a given domain and instruction level. The x-axis represents the domain and the three instruction levels within each domain (Level 1, Level 2, and Level 3, with increasing complexity). The y-axis shows the nDCG@20 score, indicating the effectiveness of the models in retrieving relevant information according to the instructions provided. This visualization allows for a comparison of model performance across domains and instruction complexity levels, revealing insights into the models’ capabilities to handle instruction-following information retrieval tasks of varying difficulty.
read the caption
Figure 4: Average nDCG@20 performance on different levels of instructions in different domains.
More on tables
| Evaluation Criteria | Score (1-5) |
| Instruction-Following Query | |
| Naturalness | 4.24 |
| Fluency | 4.81 |
| Expertise | 4.87 |
| Relevant Passage (RP) | |
| Relevant Passage Agreement | 4.43 |
| \hdashline Excluded RP | |
| Exclusion Agreement | 4.32 |
🔼 This table presents the results of human evaluation of the IFIR dataset’s quality. It assesses how well the instructions reflect real-world scenarios (Naturalness), the level of agreement between human annotators and the LLM in identifying relevant passages (Relevant Passage Agreement), and the level of agreement in excluding irrelevant passages (Exclusion Agreement). The scores range from 1 to 5, with higher scores indicating better quality.
read the caption
Table 2: Human Validation Results. Naturalness of instructions evaluates how well the instructions align with real-world demands. The Relevant Passage Agreement Score refers to human annotators’ agreement with the LLM on identifying a golden passage, while the Exclusion Agreement Score reflects human annotators’ agreement on excluding a passage.
| FiQA | SciFact-open | NFCorpus | AILA | FIRE | TREC-PM | TREC-CDS | Average | |||||||||
| nDCG | InstFol | nDCG | InstFol | nDCG | InstFol | nDCG | InstFol | nDCG | InstFol | nDCG | InstFol | nDCG | InstFol | nDCG | InstFol | |
| Non-instruction-tuned Models | ||||||||||||||||
| GTR-XL | 0.44 | -4.85 | 0.54 | -2.93 | 0.60 | 7.30 | 0.05 | -0.13 | 0.54 | 0.40 | 0.31 | -0.85 | 0.15 | 7.69 | 0.37 | 0.95 |
| BM25 | 0.25 | 1.10 | 0.49 | -0.40 | 0.43 | 1.46 | 0.10 | 0.02 | 0.55 | 0.03 | 0.47 | 3.43 | 0.07 | -2.14 | 0.34 | 0.50 |
| GTR-Large | 0.39 | -6.47 | 0.50 | 0.05 | 0.51 | -3.37 | 0.07 | -0.36 | 0.49 | -5.21 | 0.28 | -1.46 | 0.09 | 11.38 | 0.33 | -0.78 |
| GTR-Base | 0.33 | -4.62 | 0.47 | -0.62 | 0.47 | -0.08 | 0.05 | 0.54 | 0.52 | 0.81 | 0.27 | -0.65 | 0.13 | 7.03 | 0.32 | 0.35 |
| Contriever | 0.13 | 0.52 | 0.29 | -8.22 | 0.36 | 0.17 | 0.08 | 0.09 | 0.51 | 2.82 | 0.09 | 1.24 | 0.04 | 2.46 | 0.21 | -0.13 |
| ColBERT | 0.07 | 0.17 | 0.14 | 0.34 | 0.16 | 0.06 | 0.07 | -0.01 | 0.39 | 1.44 | 0.02 | 1.03 | 0.00 | -0.94 | 0.12 | 0.30 |
| Instruction-tuned Models | ||||||||||||||||
| NV-Embed-v2 | 0.68 | 2.76 | 0.65 | -1.10 | 0.71 | 13.70 | 0.07 | -0.35 | 0.54 | 0.60 | 0.54 | 0.72 | 0.40 | -5.19 | 0.51 | 1.59 |
| GritLM-7B | 0.63 | 3.09 | 0.63 | -0.06 | 0.70 | 15.10 | 0.10 | -0.32 | 0.51 | 4.01 | 0.57 | -0.09 | 0.42 | -0.32 | 0.51 | 3.06 |
| E5-mistral-7B | 0.54 | 4.26 | 0.63 | 0.05 | 0.69 | 14.14 | 0.10 | 0.08 | 0.57 | 6.31 | 0.56 | 0.92 | 0.28 | -4.42 | 0.48 | 3.05 |
| Instructor-XL | 0.48 | 1.03 | 0.49 | -2.36 | 0.53 | 0.35 | 0.07 | -0.30 | 0.53 | 1.96 | 0.17 | -2.06 | 0.19 | 0.18 | 0.35 | -0.17 |
| Instructor-Large | 0.49 | 3.65 | 0.46 | 0.20 | 0.56 | 3.68 | 0.07 | 0.29 | 0.51 | 2.19 | 0.15 | -3.86 | 0.17 | 6.70 | 0.34 | 1.84 |
| Promptriever-7B | 0.22 | 8.95 | 0.34 | 3.69 | 0.60 | 18.17 | 0.09 | -0.31 | 0.52 | 5.18 | 0.35 | 13.26 | 0.09 | 7.07 | 0.32 | 8.00 |
| Instructor-Base | 0.39 | 3.31 | 0.45 | 0.42 | 0.48 | 2.06 | 0.06 | 0.18 | 0.51 | -2.70 | 0.17 | 1.34 | 0.09 | 13.93 | 0.31 | 2.65 |
| Proprietary Models | ||||||||||||||||
| OpenAI-v3-large | 0.54 | 1.57 | 0.59 | -0.48 | 0.58 | 0.31 | 0.11 | -0.03 | 0.57 | -0.03 | 0.52 | 0.18 | 0.30 | -5.72 | 0.46 | -0.60 |
| OpenAI-v3-small | 0.46 | 2.31 | 0.58 | -0.94 | 0.56 | 0.83 | 0.08 | -0.29 | 0.53 | 3.26 | 0.41 | -1.21 | 0.24 | -0.81 | 0.41 | 0.45 |
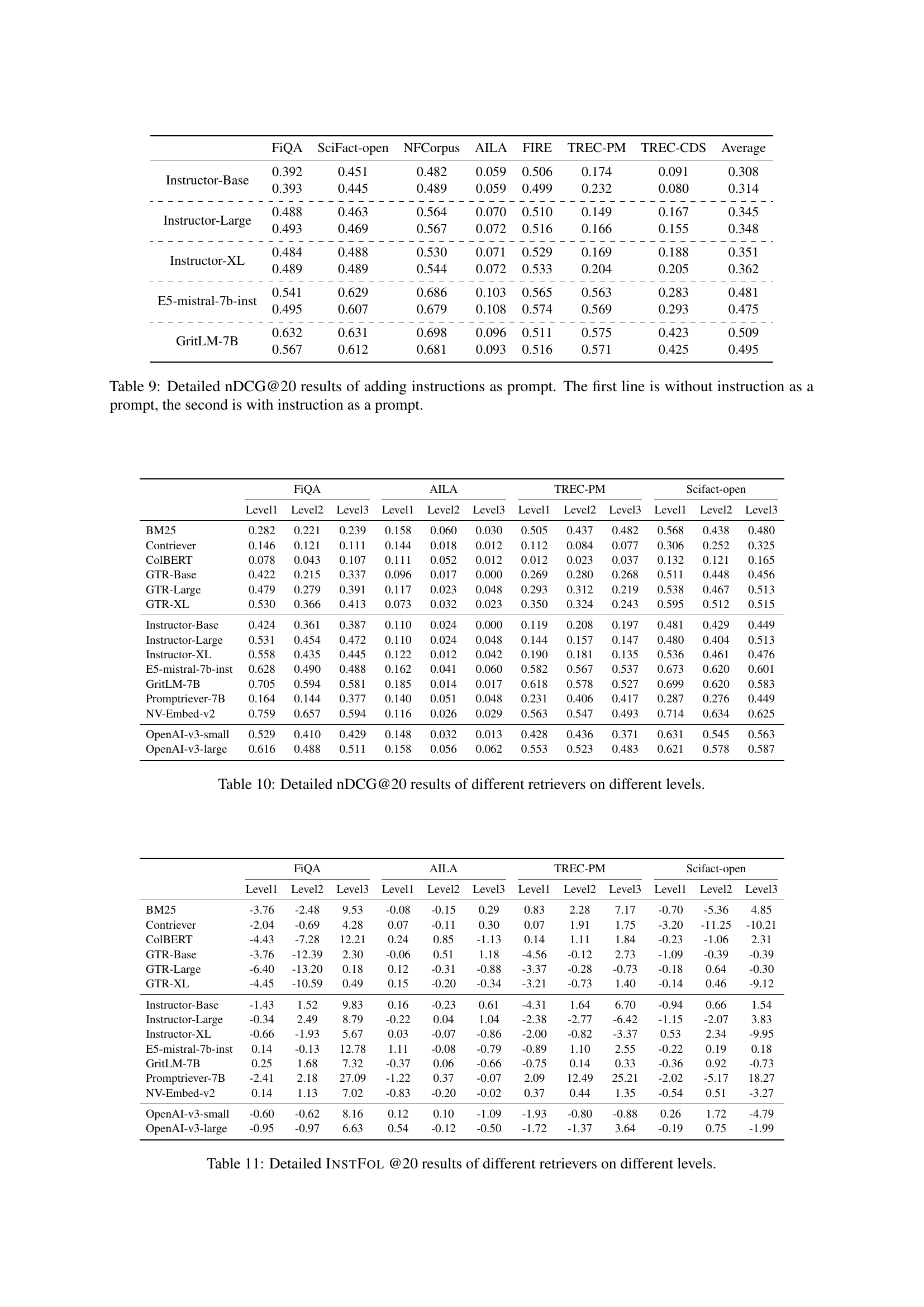
🔼 This table presents the performance of various information retrieval models on the IFIR benchmark. The performance is evaluated using two metrics: nDCG@20 (normalized Discounted Cumulative Gain at rank 20), a standard measure of ranking quality, and INSTFOL@20 (a novel instruction-following metric proposed in the paper). The table is organized to show the results for different model types (instruction-tuned and non-instruction-tuned), broken down by dataset. Note that the average nDCG@20 score is used for model ranking, and further details, including results for a hybrid retrieval approach, are available in Appendix C.
read the caption
Table 3: Performance of retrievers on IfIR measured by nDCG@20 and InstFol@20 (%). Fine-grained results(i.e., hybrid) can be found at Appendix C. Model performance is ranked based on average results with the nDCG metric.
| ID | Fluent in English | Major | Annotation tasks |
| 1 | > 10 yrs | Legal | Legal subset annotation |
| 2 | > 7 yrs | Legal | Legal subset annotation |
| 3 | > 10 yrs | Biology | Healthcare subset annotation; Science Literature subset annotation; Annotation Validation |
| 4 | > 7 yrs | Pharmacy | Healthcare subset annotation; Science Literature subset annotation |
| 5 | > 10 yrs | Biomedical engineering | Healthcare subset annotation; Science Literature subset annotation; Annotation Validation |
| 6 | > 7 yrs | Mathematics | Financial subset annotation; Annotation Validation. |
| 7 | > 6 yrs | Finance | Financial subset annotation; |
| 8 | Native Speaker | Finance | Financial Subset Annotation |
| 9 | > 10 yrs | Legal | Legal subset annotation |
🔼 This table details the background of the human annotators who worked on the IFIR benchmark dataset creation. For each annotator, it lists their years of experience, area of expertise, and the specific annotation tasks they performed. This information is useful to understand the level of expertise and the scope of tasks related to the construction of the benchmark.
read the caption
Table 4: Human annotator’s tasks
| Dataset | query | instruction |
| FiQA | Full-time work + running small side business: Best business structure for taxes? | As a 40-year-old accountant with a steady income and moderate savings, I am seeking advice on the best business structure for taxes when combining full-time work with running a small side business. I am particularly interested in understanding the tax implications, legal considerations, and potential benefits of different business structures. Additionally, I am looking for insights on how to optimize tax efficiency while balancing the demands of my full-time job and side business. |
| SciFact-open | A deficiency of folate decreases blood levels of homocysteine. | As an expert in the field of science, I need to find a peer-reviewed research article or a review paper that presents contradicting evidence regarding the relationship between folate deficiency and homocysteine levels in the blood. The passage should offer evidence that opposes the claim stating that a deficiency of folate results in decreased blood levels of homocysteine. |
| NFCorpus | Why are Cancer Rates so Low in India? | I am a student researching the factors contributing to low cancer rates in India, and I am specifically interested in understanding the role of dietary habits. I need to find scientific studies or articles from the fields of oncology, nutrition, and epidemiology that focus on the relationship between Indian dietary patterns and cancer prevention. My objective is to analyze the types of foods commonly consumed in India and their potential protective effects against cancer. To meet my customized needs, I require information on specific dietary components, such as spices, fruits, vegetables, and traditional Indian dishes, that have been associated with lower cancer rates. Additionally, I am interested in any experimental studies or clinical trials investigating the effects of these dietary factors on cancer cells or animal models. |
| AILA | The appellant, once a prime witness in a bribery trial, became a Cabinet Minister and resigned after critical judicial remarks during an appeal that acquitted the first respondent. The High Court questioned the evidence and the appellant’s credibility, overturning the initial conviction for accepting bribes. | I represent the appellant and I seek cases involving a defendant who benefitted from a reversal of a conviction due to lack of acceptable evidence and a plausible explanation for the incriminating evidence found in their possession, despite adverse remarks made by the Appellate Judge regarding the credibility of the appellant’s testimony in a bribery case where the defendant was acquitted based on insufficient prosecution evidence. |
| FIRE | [A legal case summary] What was the decision and legal principle established in the case referred to as [?CITATION?] in relation to the doctrine of promissory estoppel in the context of government representations and obligations? | Retrieve the prior case referred to as [?CITATION?] and focus on the court’s analysis and ruling regarding the application of promissory estoppel against the government, particularly in situations where representations are made by governmental authorities and the subsequent obligations arising from such representations. Pay attention to any discussion on the enforceability of promises made by the government, the limitations of promissory estoppel against the government, and the factors determining the applicability of the doctrine in cases involving governmental representations. |
| TREC-PM | A patient diagnosed with Liposarcoma with CDK4 Amplification. I am looking for possible clinical trials suitable for this patient. | I am seeking clinical trials for a 38-year-old male diagnosed with Liposarcoma with CDK4 Amplification. Please focus on trials specifically targeting Liposarcoma or related soft tissue sarcomas. It is crucial that the trials consider the presence of CDK4 Amplification in the patient’s condition. Additionally, the patient’s age and gender should be taken into account when selecting suitable clinical trial options. Patient Profile: The patient is a 38-year-old male who has been diagnosed with Liposarcoma with CDK4 Amplification. He has a treatment background that includes both chemotherapy and radiation, and he is currently in remission. It is important to note that he has a history of smoking and is also dealing with obesity. Given these demographic details, I am seeking clinical trials that specifically target Liposarcoma or related soft tissue sarcomas, taking into consideration the presence of CDK4 Amplification. The trials should also consider the patient’s age and gender, as well as any potential influences from his treatment background, smoking history, and obesity. |
| TREC-CDS | Given some infomation about patient. 58-year-old woman with hypertension and obesity presents with exercise-related episodic chest pain radiating to the back.What is the patient’s diagnosis? | A 58-year-old African-American woman presents to the ER with episodic pressing/burning anterior chest pain that began two days earlier for the first time in her life. The pain started while she was walking, radiates to the back, and is accompanied by nausea, diaphoresis and mild dyspnea, but is not increased on inspiration. The latest episode of pain ended half an hour prior to her arrival. She is known to have hypertension and obesity. She denies smoking, diabetes, hypercholesterolemia, or a family history of heart disease. She currently takes no medications. Physical examination is normal. The EKG shows nonspecific changes. |
🔼 This table showcases example instructions from each of the four domains included in the IFIR benchmark: finance, scientific literature, law, and healthcare. For each domain, it presents one query and three levels of instruction complexity to illustrate the nuances in real-world information retrieval. The increasing complexity demonstrates the challenging aspects of instruction-following in expert domains.
read the caption
Table 5: Examples of instructions in different domains.
| Dataset | level1 | level2 | level3 |
| FiQA | Please help me to find the financial suggestions for my query. | I am a 40-year-old accountant with a steady income and moderate savings. | As a 40-year-old accountant with a steady income and moderate savings, I am seeking advice on the best business structure for taxes when combining full-time work with running a small side business. I am particularly interested in understanding the tax implications, legal considerations, and potential benefits of different business structures. Additionally, I am looking for insights on how to optimize tax efficiency while balancing the demands of my full-time job and side business |
| SciFact-open | Please find the science passage which related to the claim | Please help me to find the contradict evidence. | As an expert in the field of science, I need to find a peer-reviewed research article or a review paper that presents contradicting evidence regarding the relationship between folate deficiency and homocysteine levels in the blood. The passage should offer evidence that opposes the claim stating that a deficiency of folate results in decreased blood levels of homocysteine. |
| AILA | Please help me find the relevant legal cases. | As a defendant player, I want the case where the defendant is beneficial. | I represent the appellant and I seek cases involving a defendant who benefitted from a reversal of a conviction due to lack of acceptable evidence and a plausible explanation for the incriminating evidence found in their possession, despite adverse remarks made by the Appellate Judge regarding the credibility of the appellant’s testimony in a bribery case where the defendant was acquitted based on insufficient prosecution evidence. |
| TREC-PM | I’m looking for clinical trials suitable for a 38-year-old male patient diagnosed with Liposarcoma with CDK4 Amplification. | I am seeking clinical trials for a 38-year-old male diagnosed with Liposarcoma with CDK4 Amplification. Please focus on trials specifically targeting Liposarcoma or related soft tissue sarcomas. It is crucial that the trials consider the presence of CDK4 Amplification in the patient’s condition. Additionally, the patient’s age and gender should be taken into account when selecting suitable clinical trial options. | I am seeking clinical trials for a 38-year-old male diagnosed with Liposarcoma with CDK4 Amplification. Please focus on trials specifically targeting Liposarcoma or related soft tissue sarcomas. It is crucial that the trials consider the presence of CDK4 Amplification in the patient’s condition. Additionally, the patient’s age and gender should be taken into account when selecting suitable clinical trial options. Patient Profile: The patient is a 38-year-old male who has been diagnosed with Liposarcoma with CDK4 Amplification. He has a treatment background that includes both chemotherapy and radiation, and he is currently in remission. It is important to note that he has a history of smoking and is also dealing with obesity. Given these demographic details, I am seeking clinical trials that specifically target Liposarcoma or related soft tissue sarcomas, taking into consideration the presence of CDK4 Amplification. The trials should also consider the patient’s age and gender, as well as any potential influences from his treatment background, smoking history, and obesity. |
🔼 This table presents examples of instructions with varying levels of complexity across different domains included in the IFIR benchmark. Each domain (Finance, Scientific Literature, Law, Healthcare) shows three levels of instructions, progressing from simple to highly complex and detailed, reflecting real-world scenarios. This illustrates the gradation of instruction complexity used in IFIR to comprehensively evaluate instruction-following abilities of information retrieval systems.
read the caption
Table 6: Examples for different levels’ instruction in various domains.
| Type | Example |
| Long Instruction | [A long legal case] As the defendant player, seek cases where the prosecution’s evidence relies heavily on circumstantial evidence and lacks direct proof of intent or direct involvement in the alleged crime, similar to a situation where the accused individuals were convicted based on circumstantial evidence and witness testimonies, despite maintaining their innocence throughout the trial and appeal process. |
| Dense with specialized knowledge | CHEK2 has a significant role in breast cancer As a scientist investigating the claim that ’CHEK2 has a significant role in breast cancer,’ I should search for research articles or review papers that provide support evidence on the specific functions of the CHEK2 gene in relation to breast cancer development. |
| Highly customized instructions | I am seeking clinical trials suitable for a 35-year-old female diagnosed with colorectal cancer and exhibiting FGFR1 Amplification. Please prioritize trials that focus on colorectal cancer specifically or a narrower focus related to this patient’s condition. Additionally, it is crucial to include trials that directly match the FGFR1 Amplification gene mutation in the patient. The patient’s age and gender are also important factors to consider in selecting appropriate clinical trials. Please ensure that the trials selected meet these criteria for optimal patient care and treatment options. |
🔼 This table categorizes examples of instructions from the IFIR benchmark that yielded low performance scores (both nDCG and INSTFOL). It analyzes the reasons for the poor performance and helps identify patterns in instruction characteristics that hinder effective information retrieval.
read the caption
Table 7: Taxonomy of instructions with low nDCG score and InstFol score.
| FiQA | SciFact-open | NFCorpus | AILA | FIRE | TREC-PM | TREC-CDS | Average | |||||||||
| nDCG | MRR | nDCG | MRR | nDCG | MRR | nDCG | MRR | nDCG | MRR | nDCG | MRR | nDCG | MRR | nDCG | MRR | |
| End-to-end retrieval | ||||||||||||||||
| GTR-XL | 0.44 | 0.40 | 0.54 | 0.49 | 0.60 | 0.57 | 0.05 | 0.04 | 0.54 | 0.50 | 0.31 | 0.27 | 0.15 | 0.12 | 0.37 | 0.34 |
| BM25 | 0.25 | 0.21 | 0.49 | 0.45 | 0.43 | 0.40 | 0.10 | 0.08 | 0.55 | 0.51 | 0.47 | 0.43 | 0.07 | 0.05 | 0.34 | 0.30 |
| GTR-Large | 0.39 | 0.34 | 0.50 | 0.46 | 0.51 | 0.46 | 0.07 | 0.07 | 0.49 | 0.41 | 0.28 | 0.23 | 0.09 | 0.06 | 0.33 | 0.29 |
| GTR-Base | 0.33 | 0.28 | 0.47 | 0.43 | 0.47 | 0.42 | 0.05 | 0.04 | 0.52 | 0.47 | 0.27 | 0.24 | 0.13 | 0.09 | 0.32 | 0.28 |
| Contriever | 0.13 | 0.10 | 0.29 | 0.24 | 0.36 | 0.29 | 0.08 | 0.06 | 0.51 | 0.48 | 0.09 | 0.06 | 0.04 | 0.04 | 0.21 | 0.18 |
| ColBERT | 0.07 | 0.05 | 0.14 | 0.12 | 0.16 | 0.13 | 0.07 | 0.05 | 0.39 | 0.35 | 0.02 | 0.01 | 0.00 | 0.00 | 0.12 | 0.10 |
| \hdashline NV-Embed-v2 | 0.68 | 0.66 | 0.65 | 0.62 | 0.71 | 0.70 | 0.07 | 0.04 | 0.54 | 0.51 | 0.54 | 0.53 | 0.40 | 0.36 | 0.51 | 0.49 |
| GritLM-7B | 0.63 | 0.61 | 0.63 | 0.60 | 0.70 | 0.69 | 0.10 | 0.06 | 0.51 | 0.46 | 0.57 | 0.54 | 0.42 | 0.38 | 0.51 | 0.48 |
| E5-mistral-7b-inst | 0.54 | 0.51 | 0.63 | 0.59 | 0.69 | 0.67 | 0.10 | 0.06 | 0.57 | 0.54 | 0.56 | 0.52 | 0.28 | 0.23 | 0.48 | 0.45 |
| Instructor-XL | 0.48 | 0.44 | 0.49 | 0.44 | 0.53 | 0.47 | 0.07 | 0.05 | 0.53 | 0.49 | 0.17 | 0.12 | 0.19 | 0.15 | 0.35 | 0.31 |
| Instructor-Large | 0.49 | 0.45 | 0.46 | 0.42 | 0.56 | 0.51 | 0.07 | 0.06 | 0.51 | 0.45 | 0.15 | 0.11 | 0.17 | 0.12 | 0.34 | 0.30 |
| Promptriever-7B | 0.22 | 0.17 | 0.34 | 0.28 | 0.60 | 0.59 | 0.09 | 0.07 | 0.52 | 0.48 | 0.35 | 0.29 | 0.09 | 0.06 | 0.32 | 0.28 |
| Instructor-Base | 0.39 | 0.34 | 0.45 | 0.42 | 0.48 | 0.42 | 0.06 | 0.05 | 0.51 | 0.46 | 0.17 | 0.13 | 0.09 | 0.07 | 0.31 | 0.27 |
| \hdashline OpenAI-v3-large | 0.54 | 0.51 | 0.59 | 0.54 | 0.58 | 0.55 | 0.11 | 0.08 | 0.57 | 0.54 | 0.52 | 0.46 | 0.30 | 0.26 | 0.46 | 0.42 |
| OpenAI-v3-small | 0.46 | 0.41 | 0.58 | 0.52 | 0.56 | 0.52 | 0.08 | 0.06 | 0.53 | 0.48 | 0.41 | 0.38 | 0.24 | 0.21 | 0.41 | 0.37 |
| Hybrid retrieval | ||||||||||||||||
| GritLM-7B | 0.59 | 0.54 | 0.62 | 0.58 | 0.57 | 0.51 | 0.10 | 0.07 | 0.55 | 0.50 | 0.59 | 0.56 | 0.39 | 0.32 | 0.49 | 0.44 |
| GTR-XL | 0.43 | 0.38 | 0.57 | 0.51 | 0.52 | 0.47 | 0.06 | 0.06 | 0.56 | 0.53 | 0.33 | 0.29 | 0.14 | 0.13 | 0.37 | 0.34 |
| Instructor-XL | 0.46 | 0.41 | 0.54 | 0.51 | 0.52 | 0.46 | 0.09 | 0.07 | 0.56 | 0.52 | 0.23 | 0.20 | 0.20 | 0.16 | 0.37 | 0.33 |
| Promptriever-7B | 0.25 | 0.21 | 0.42 | 0.38 | 0.54 | 0.49 | 0.09 | 0.07 | 0.56 | 0.53 | 0.42 | 0.37 | 0.11 | 0.09 | 0.34 | 0.31 |
🔼 This table presents the performance of various information retrieval models on the IFIR benchmark. The performance is evaluated using two standard metrics: Normalized Discounted Cumulative Gain at rank 20 (nDCG@20) and Mean Reciprocal Rank at rank 20 (MRR@20). The table shows the scores for each model across different specialized domains covered by the IFIR benchmark, allowing for a comparison of their effectiveness in different contexts.
read the caption
Table 8: Performance of retrievers on IfIR measured by nDCG@20 and MRR@20.
| FiQA | SciFact-open | NFCorpus | AILA | FIRE | TREC-PM | TREC-CDS | Average | |
| Instructor-Base | 0.392 | 0.451 | 0.482 | 0.059 | 0.506 | 0.174 | 0.091 | 0.308 |
| 0.393 | 0.445 | 0.489 | 0.059 | 0.499 | 0.232 | 0.080 | 0.314 | |
| \hdashline Instructor-Large | 0.488 | 0.463 | 0.564 | 0.070 | 0.510 | 0.149 | 0.167 | 0.345 |
| 0.493 | 0.469 | 0.567 | 0.072 | 0.516 | 0.166 | 0.155 | 0.348 | |
| \hdashline Instructor-XL | 0.484 | 0.488 | 0.530 | 0.071 | 0.529 | 0.169 | 0.188 | 0.351 |
| 0.489 | 0.489 | 0.544 | 0.072 | 0.533 | 0.204 | 0.205 | 0.362 | |
| \hdashline E5-mistral-7b-inst | 0.541 | 0.629 | 0.686 | 0.103 | 0.565 | 0.563 | 0.283 | 0.481 |
| 0.495 | 0.607 | 0.679 | 0.108 | 0.574 | 0.569 | 0.293 | 0.475 | |
| \hdashline GritLM-7B | 0.632 | 0.631 | 0.698 | 0.096 | 0.511 | 0.575 | 0.423 | 0.509 |
| 0.567 | 0.612 | 0.681 | 0.093 | 0.516 | 0.571 | 0.425 | 0.495 |
🔼 This table presents a detailed comparison of nDCG@20 scores achieved by various information retrieval models across different datasets. It shows the performance difference between two conditions: (1) when no instruction is provided as a prompt and (2) when the corresponding instruction is used as a prompt. The results are broken down by dataset and model, allowing for a direct comparison of the impact of adding instructions to the query on retrieval performance.
read the caption
Table 9: Detailed nDCG@20 results of adding instructions as prompt. The first line is without instruction as a prompt, the second is with instruction as a prompt.
| FiQA | AILA | TREC-PM | Scifact-open | |||||||||
| Level1 | Level2 | Level3 | Level1 | Level2 | Level3 | Level1 | Level2 | Level3 | Level1 | Level2 | Level3 | |
| BM25 | 0.282 | 0.221 | 0.239 | 0.158 | 0.060 | 0.030 | 0.505 | 0.437 | 0.482 | 0.568 | 0.438 | 0.480 |
| Contriever | 0.146 | 0.121 | 0.111 | 0.144 | 0.018 | 0.012 | 0.112 | 0.084 | 0.077 | 0.306 | 0.252 | 0.325 |
| ColBERT | 0.078 | 0.043 | 0.107 | 0.111 | 0.052 | 0.012 | 0.012 | 0.023 | 0.037 | 0.132 | 0.121 | 0.165 |
| GTR-Base | 0.422 | 0.215 | 0.337 | 0.096 | 0.017 | 0.000 | 0.269 | 0.280 | 0.268 | 0.511 | 0.448 | 0.456 |
| GTR-Large | 0.479 | 0.279 | 0.391 | 0.117 | 0.023 | 0.048 | 0.293 | 0.312 | 0.219 | 0.538 | 0.467 | 0.513 |
| GTR-XL | 0.530 | 0.366 | 0.413 | 0.073 | 0.032 | 0.023 | 0.350 | 0.324 | 0.243 | 0.595 | 0.512 | 0.515 |
| Instructor-Base | 0.424 | 0.361 | 0.387 | 0.110 | 0.024 | 0.000 | 0.119 | 0.208 | 0.197 | 0.481 | 0.429 | 0.449 |
| Instructor-Large | 0.531 | 0.454 | 0.472 | 0.110 | 0.024 | 0.048 | 0.144 | 0.157 | 0.147 | 0.480 | 0.404 | 0.513 |
| Instructor-XL | 0.558 | 0.435 | 0.445 | 0.122 | 0.012 | 0.042 | 0.190 | 0.181 | 0.135 | 0.536 | 0.461 | 0.476 |
| E5-mistral-7b-inst | 0.628 | 0.490 | 0.488 | 0.162 | 0.041 | 0.060 | 0.582 | 0.567 | 0.537 | 0.673 | 0.620 | 0.601 |
| GritLM-7B | 0.705 | 0.594 | 0.581 | 0.185 | 0.014 | 0.017 | 0.618 | 0.578 | 0.527 | 0.699 | 0.620 | 0.583 |
| Promptriever-7B | 0.164 | 0.144 | 0.377 | 0.140 | 0.051 | 0.048 | 0.231 | 0.406 | 0.417 | 0.287 | 0.276 | 0.449 |
| NV-Embed-v2 | 0.759 | 0.657 | 0.594 | 0.116 | 0.026 | 0.029 | 0.563 | 0.547 | 0.493 | 0.714 | 0.634 | 0.625 |
| OpenAI-v3-small | 0.529 | 0.410 | 0.429 | 0.148 | 0.032 | 0.013 | 0.428 | 0.436 | 0.371 | 0.631 | 0.545 | 0.563 |
| OpenAI-v3-large | 0.616 | 0.488 | 0.511 | 0.158 | 0.056 | 0.062 | 0.553 | 0.523 | 0.483 | 0.621 | 0.578 | 0.587 |
🔼 This table presents a detailed breakdown of the nDCG@20 scores achieved by various information retrieval models across three different levels of instruction complexity. The results are categorized by model type and are shown for each of the four specialized domains included in the IFIR benchmark: Finance, Scientific Literature, Law, and Healthcare. This granular analysis helps to understand how well different models handle increasing complexity in instruction-following tasks.
read the caption
Table 10: Detailed nDCG@20 results of different retrievers on different levels.
| FiQA | AILA | TREC-PM | Scifact-open | |||||||||
| Level1 | Level2 | Level3 | Level1 | Level2 | Level3 | Level1 | Level2 | Level3 | Level1 | Level2 | Level3 | |
| BM25 | -3.76 | -2.48 | 9.53 | -0.08 | -0.15 | 0.29 | 0.83 | 2.28 | 7.17 | -0.70 | -5.36 | 4.85 |
| Contriever | -2.04 | -0.69 | 4.28 | 0.07 | -0.11 | 0.30 | 0.07 | 1.91 | 1.75 | -3.20 | -11.25 | -10.21 |
| ColBERT | -4.43 | -7.28 | 12.21 | 0.24 | 0.85 | -1.13 | 0.14 | 1.11 | 1.84 | -0.23 | -1.06 | 2.31 |
| GTR-Base | -3.76 | -12.39 | 2.30 | -0.06 | 0.51 | 1.18 | -4.56 | -0.12 | 2.73 | -1.09 | -0.39 | -0.39 |
| GTR-Large | -6.40 | -13.20 | 0.18 | 0.12 | -0.31 | -0.88 | -3.37 | -0.28 | -0.73 | -0.18 | 0.64 | -0.30 |
| GTR-XL | -4.45 | -10.59 | 0.49 | 0.15 | -0.20 | -0.34 | -3.21 | -0.73 | 1.40 | -0.14 | 0.46 | -9.12 |
| Instructor-Base | -1.43 | 1.52 | 9.83 | 0.16 | -0.23 | 0.61 | -4.31 | 1.64 | 6.70 | -0.94 | 0.66 | 1.54 |
| Instructor-Large | -0.34 | 2.49 | 8.79 | -0.22 | 0.04 | 1.04 | -2.38 | -2.77 | -6.42 | -1.15 | -2.07 | 3.83 |
| Instructor-XL | -0.66 | -1.93 | 5.67 | 0.03 | -0.07 | -0.86 | -2.00 | -0.82 | -3.37 | 0.53 | 2.34 | -9.95 |
| E5-mistral-7b-inst | 0.14 | -0.13 | 12.78 | 1.11 | -0.08 | -0.79 | -0.89 | 1.10 | 2.55 | -0.22 | 0.19 | 0.18 |
| GritLM-7B | 0.25 | 1.68 | 7.32 | -0.37 | 0.06 | -0.66 | -0.75 | 0.14 | 0.33 | -0.36 | 0.92 | -0.73 |
| Promptriever-7B | -2.41 | 2.18 | 27.09 | -1.22 | 0.37 | -0.07 | 2.09 | 12.49 | 25.21 | -2.02 | -5.17 | 18.27 |
| NV-Embed-v2 | 0.14 | 1.13 | 7.02 | -0.83 | -0.20 | -0.02 | 0.37 | 0.44 | 1.35 | -0.54 | 0.51 | -3.27 |
| OpenAI-v3-small | -0.60 | -0.62 | 8.16 | 0.12 | 0.10 | -1.09 | -1.93 | -0.80 | -0.88 | 0.26 | 1.72 | -4.79 |
| OpenAI-v3-large | -0.95 | -0.97 | 6.63 | 0.54 | -0.12 | -0.50 | -1.72 | -1.37 | 3.64 | -0.19 | 0.75 | -1.99 |
🔼 This table presents a detailed breakdown of the INSTFOL@20 scores achieved by various information retrieval models across three different levels of instruction complexity. Each level represents a progressively more challenging instruction-following task. The scores reflect the models’ ability to accurately retrieve relevant information based on the nuanced instructions provided. The table allows for a granular analysis of model performance, revealing strengths and weaknesses in handling complex, domain-specific queries.
read the caption
Table 11: Detailed InstFol @20 results of different retrievers on different levels.
Full paper#