TL;DR#
Multimodal Large Language Models (MLLMs) process diverse data, but supervised fine-tuning (SFT) lacks generalized reasoning. Reinforcement learning (RL) shows promise but faces challenges: unexplored multimodal tasks and training constraints like constant Kullback-Leibler divergence. These issues can lead to suboptimal solutions. The ability to handle different tasks across varied data distributions is critical for real-world deployment.
The study proposes an advanced MLLM equipped with understanding and reasoning abilities across multimodal tasks. The model uses Group Relative Policy Optimization with a dynamic Kullback-Leibler strategy (GRPO-D) to enhance RL performance. GRPO-D improves performance and cross-task generalization. Results show that models trained with GRPO-D can transfer to other tasks, reducing task-specific data needs.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces OThink-MR1, which enhances MLLM’s reasoning. It addresses the limitations of SFT and GRPO, opening new avenues for improving cross-task generalization. This research aligns with the trend of developing more versatile and capable multimodal models.
Visual Insights#
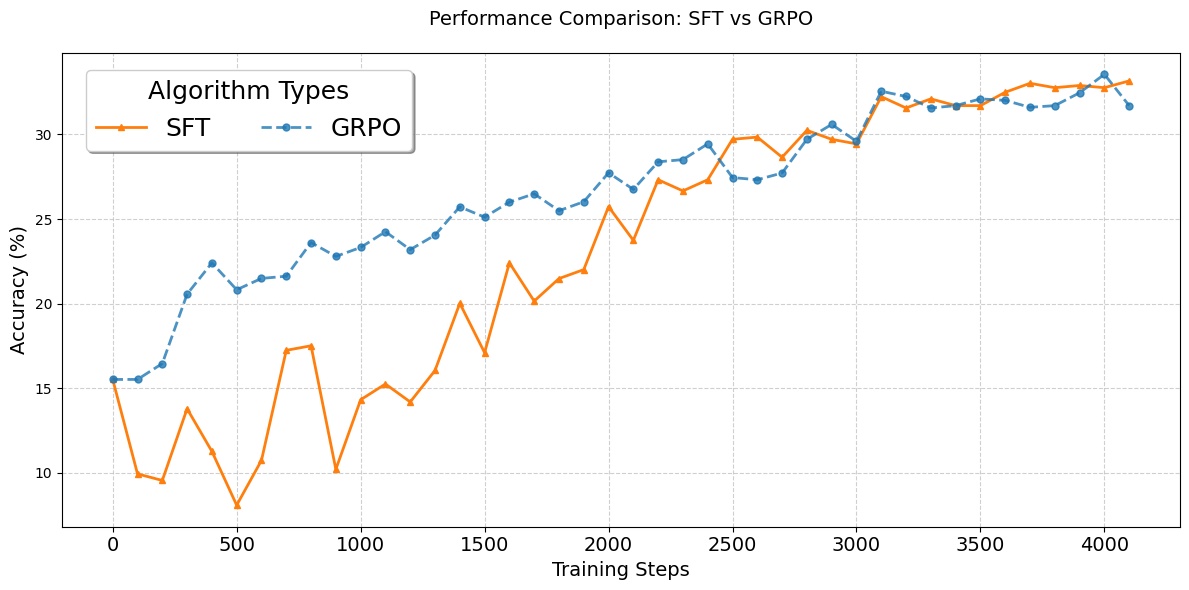
🔼 This figure shows the performance comparison between supervised fine-tuning (SFT) and Group Relative Policy Optimization (GRPO) on a geometry reasoning task. The x-axis represents the number of training steps, while the y-axis shows the accuracy achieved on a test set. The curves illustrate how the accuracy of both methods changes as training progresses. This allows for a direct visual comparison of the learning speed and final accuracy of each training method, highlighting the relative effectiveness of SFT and GRPO in improving the model’s performance on this specific geometry task.
read the caption
Figure 1. Test accuracy metric curves of SFT and GRPO on geometry reasoning task.
| Models | Accuracy | |
|---|---|---|
| VC | GR | |
| Qwen2-VL-2B-Instruct | 42.50% | 15.52% |
| + GRPO | 64.50% | 30.24% |
| + SFT | 68.50% | 32.49% |
| + GRPO-D | 76.50% | 34.35% |
| Qwen2-VL-7B-Instruct | 76.00% | 33.16% |
| + GRPO | 76.50% | 42.04% |
| + SFT | 74.50% | 43.50% |
| + GRPO-D | 78.00% | 45.49% |
🔼 Table 1 presents a comprehensive comparison of different model variations’ performance on two distinct tasks: visual counting (VC) and geometry reasoning (GR). It showcases the accuracy achieved by the base model (Qwen2-VL-2B/7B-Instruct) and its performance after undergoing fine-tuning using supervised fine-tuning (SFT), Group Relative Policy Optimization (GRPO), and the proposed Group Relative Policy Optimization with dynamic Kullback-Leibler strategy (GRPO-D). The table highlights the superior performance of GRPO-D across both tasks, indicating its effectiveness in enhancing the model’s reasoning capabilities. The best performing method for each model is bolded for easy identification.
read the caption
Table 1. Overall performance results for same-task validation, including the visual counting (VC) task and the geometry reasoning (GR) task. The best-performing method is bolded, and the strongest baseline is underlined.
In-depth insights#
Dynamic RL++#
While ‘Dynamic RL++’ isn’t explicitly present, the paper’s GRPO-D method embodies this concept. The “Dynamic” refers to the adaptive KL divergence, crucial for balancing exploration and exploitation in RL. The “++” suggests improvements over standard RL, specifically addressing limitations in multimodal tasks. Traditional RL struggles with complex data and generalization, so GRPO-D dynamically adjusts the exploration-exploitation trade-off, allowing for more effective learning. This dynamic adjustment is key to OThink-MR1’s superior performance, as it helps the model escape suboptimal solutions. The paper highlights how a fixed KL divergence can hinder learning, either by restricting exploration or causing instability. By dynamically weighting the KL term, GRPO-D ensures robust learning and efficient long-term rewards. This is particularly important for cross-task generalization, where the model needs to adapt to new data distributions.
GRPO-D Insight#
GRPO-D (Group Relative Policy Optimization with Dynamic Kullback-Leibler divergence strategy) offers a crucial insight into enhancing multimodal learning. Traditional reinforcement learning approaches, like standard GRPO, can falter due to insufficient exploration or over-exploration during training. GRPO-D addresses this by dynamically adjusting the KL divergence, which balances exploration (trying new strategies) and exploitation (refining existing ones). This dynamic approach allows for better adaptation to the complexities of multimodal tasks, preventing premature convergence to suboptimal solutions. It is inspired by the e-greedy strategy from Q-learning, GRPO-D ensures robust learning by favoring exploration early and exploitation later in the training process. The method enhances model performance by fine-tuning MLLMs; it surpasses the effectiveness of the conventional SFT in similar task settings. GRPO-D also demonstrates significant cross-task generalization.
Cross-Task Gen.#
Given the context of multimodal learning, “Cross-Task Gen” likely refers to cross-task generalization, a critical ability for models to perform well on tasks different from those they were trained on. In the context of MLLMs, this involves transferring knowledge gained from one modality or task to another, such as applying image understanding skills learned from image captioning to visual question answering. Effective cross-task gen is crucial because training data is often limited and real-world applications demand adaptability. This goes beyond simple memorization of training data and requires the model to extract abstract, reusable features and reasoning skills. Techniques to improve cross-task generalization might include meta-learning, domain adaptation, or regularization methods that encourage the model to learn more robust and generalizable representations. Evaluation of cross-task gen requires careful selection of tasks to ensure they are related but not identical, allowing for a meaningful assessment of the model’s ability to transfer knowledge.
Beyond Memorize#
The phrase “Beyond Memorize” suggests a critical examination of the limitations of relying solely on memorization in machine learning models, particularly in the context of multimodal learning. It implies a need to move past models that simply store and regurgitate training data, and instead, focus on building models that can truly understand, reason, and generalize. The emphasis is likely on creating models capable of handling novel situations, unseen data distributions, and complex reasoning tasks. This could involve exploring techniques that promote abstract representation learning, causal inference, or compositional generalization. The core idea is to enable models to apply learned knowledge in new and adaptive ways, rather than being constrained by the specifics of the training data. Moreover, it highlights the importance of developing robust evaluation metrics that go beyond measuring memorization capacity and instead, assess a model’s true reasoning and generalization capabilities.
OThink-MR1#
Assuming “OThink-MR1” represents the core innovation of the paper, it likely refers to a novel framework or model architecture designed to enhance the multimodal reasoning capabilities of large language models (MLLMs). Given the paper’s focus, OThink-MR1 probably tackles limitations in existing supervised fine-tuning (SFT) approaches, which often fail to foster strong generalization. The name “OThink” suggests a focus on improving the model’s cognitive processes, perhaps emphasizing more deliberate or structured reasoning. The “MR1” suffix hints at a first-generation model or a specific version within a series of developments, potentially indicating ongoing research and refinement. The paper introduces Group Relative Policy Optimization with a dynamic Kullback-Leibler strategy (GRPO-D) to improve reinforcement learning (RL) performance. Considering the context, OThink-MR1 likely integrates this GRPO-D method, aiming to achieve a better balance between exploration and exploitation during RL training. This dynamic adjustment of the KL divergence is probably a key characteristic of OThink-MR1, allowing it to surpass traditional SFT methods in both same-task performance and cross-task generalization. The framework might incorporate specific mechanisms for verifiable reward assignment in multimodal tasks, ensuring the RL signal accurately reflects the desired reasoning process. Given the emphasis on cross-task generalization, OThink-MR1 likely includes architectural components or training strategies that promote transfer learning, enabling the model to adapt quickly to new multimodal tasks with minimal retraining. Furthermore, the design probably considers memory efficiency and computational scalability, enabling deployment in resource-constrained environments. Based on the paper’s experimental results, OThink-MR1 contributes to substantial improvements.
More visual insights#
More on figures

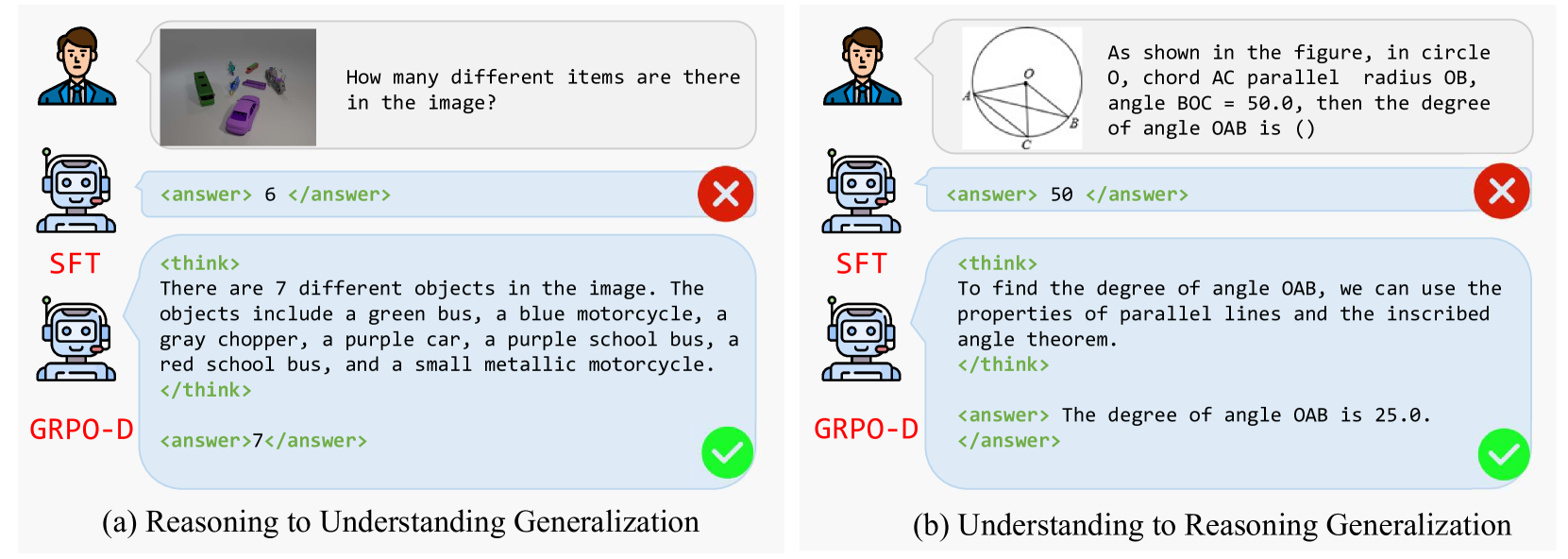
🔼 This figure displays two example tasks to illustrate the capabilities of multimodal large language models. The first example showcases multimodal content understanding, where the model must interpret both an image and a question to provide a numerical answer (how many items are present in the image?). The second example demonstrates multimodal reasoning, requiring the model to process an image depicting a geometry problem along with a text-based question to arrive at a numerical solution (finding the measure of an angle). These examples highlight the model’s ability to integrate visual and textual information to perform complex reasoning tasks.
read the caption
Figure 2. Examples of multimodal content understanding and multimodal reasoning tasks.

🔼 This figure provides a qualitative comparison of the performance of the Group Relative Policy Optimization with Dynamic KL divergence (GRPO-D) and Supervised Fine-tuning (SFT) methods within the OThink-MR1 model. It showcases examples of both same-task and cross-task validation scenarios. The same-task validation demonstrates how both GRPO-D and SFT approach solving geometry reasoning problems, but GRPO-D exhibits more accurate reasoning. The cross-task validation depicts how the models perform when trained on one task (e.g., geometry reasoning) and evaluated on a different multimodal task (e.g., visual counting). This demonstrates the superior cross-task generalization ability of GRPO-D, as it shows more accurate and logical answers compared to SFT.
read the caption
Figure 3. Qualitative illustration of GRPO-D vs SFT in OThink-MR1.
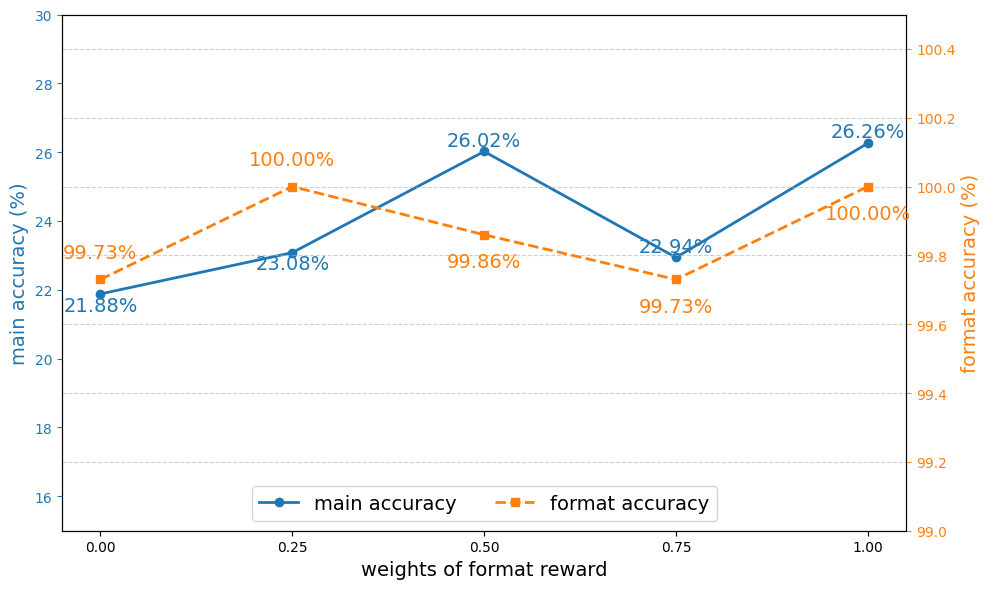
🔼 This figure shows how varying the weight of the format reward in the GRPO (Group Relative Policy Optimization) model affects both the main accuracy and format accuracy. The x-axis represents different weights assigned to the format reward, ranging from 0 to 1. The y-axis shows the corresponding accuracy percentages. The lines represent the main accuracy and format accuracy for each weight. The results demonstrate that including a format reward generally improves accuracy, but an excessively high weight can negatively impact performance. An optimal balance is needed.
read the caption
Figure 4. Impact of the weight of format reward.
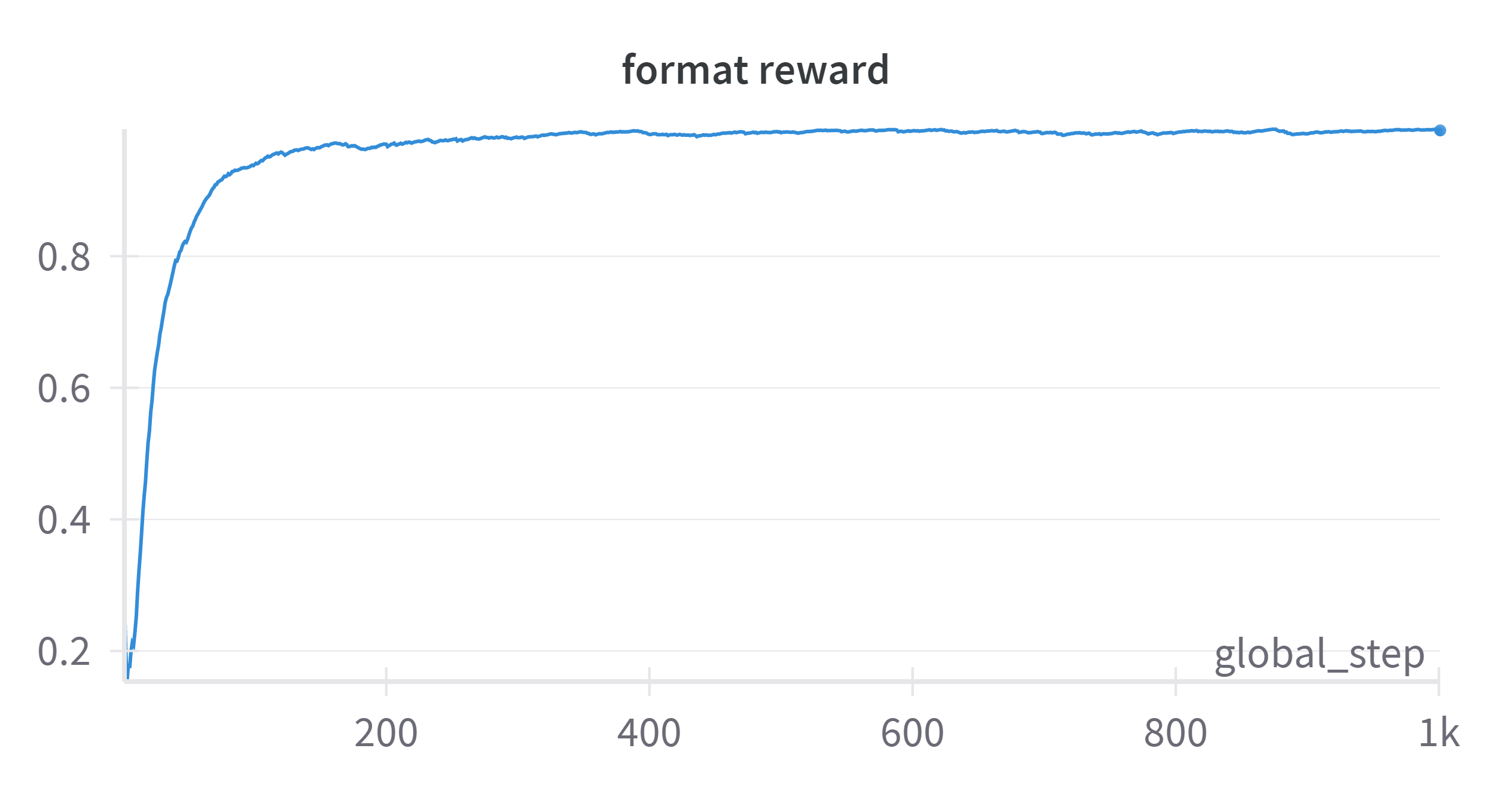
🔼 The figure shows the training curve for the format reward. It illustrates how the format reward changes with respect to the number of training steps. The x-axis represents the training steps, and the y-axis represents the format reward value. The curve’s trajectory shows how well the model learns to generate outputs in the correct format during training.
read the caption
(a) format reward w.r.t training steps.
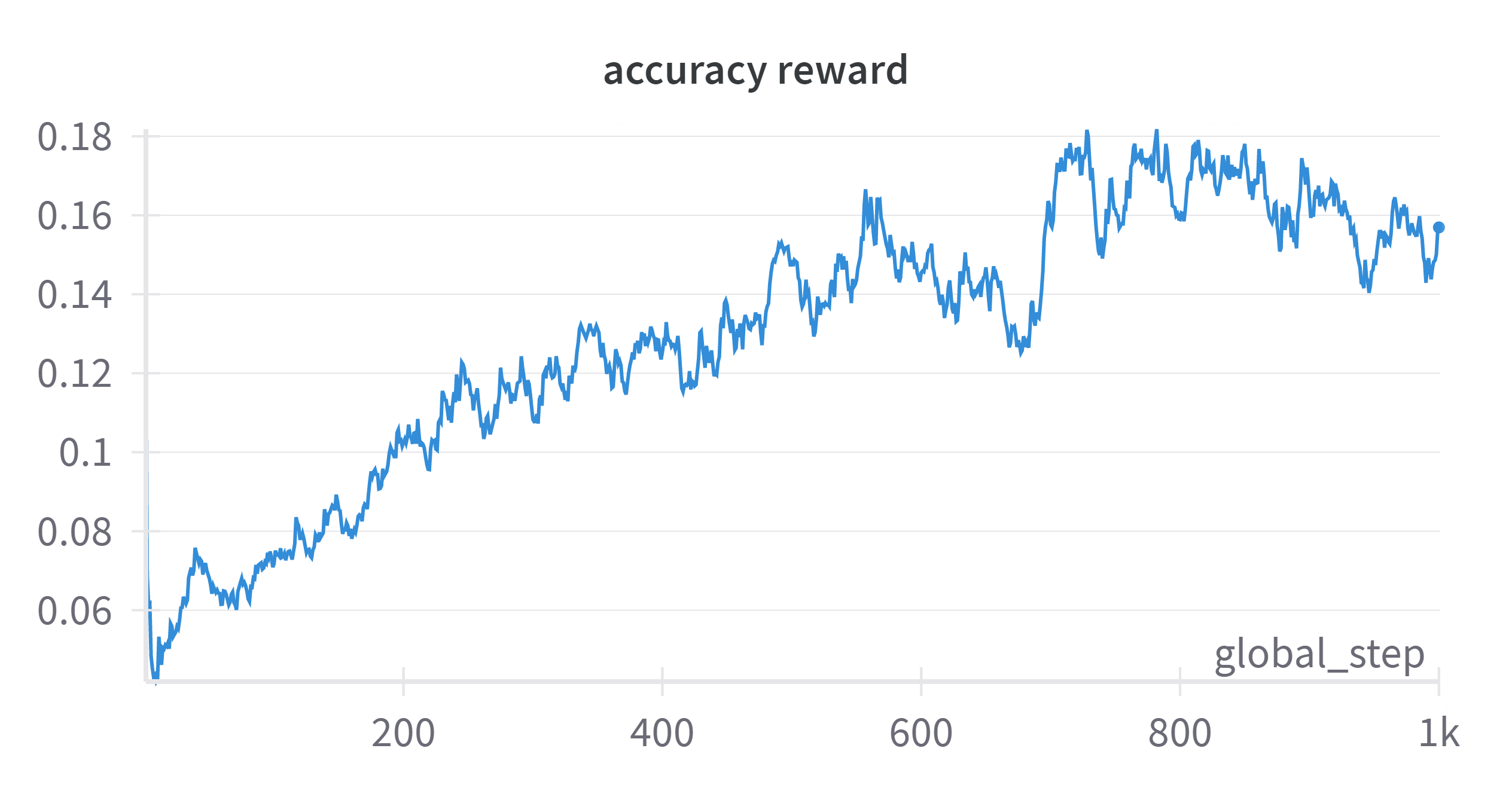
🔼 This figure shows the training curve for the accuracy reward during the training process. The x-axis represents the number of training steps, while the y-axis shows the value of the accuracy reward. The curve illustrates how the accuracy reward changes as the training progresses, indicating the improvement in the model’s performance on the task over time.
read the caption
(b) accuracy reward w.r.t training steps.
🔼 The figure shows two line graphs illustrating the training progress of a multimodal large language model (MLLM). The top graph displays the format reward over training steps, showing rapid initial improvement before plateauing. The bottom graph shows the accuracy reward, which increases gradually and steadily throughout training. These graphs demonstrate the difference in the speed of improvement between achieving correct formatting and generating accurate answers during model training. The curves highlight that ensuring correctly formatted responses is much easier than achieving accurate reasoning in the geometry reasoning task.
read the caption
Figure 5. Training curves for format reward and accuracy reward.
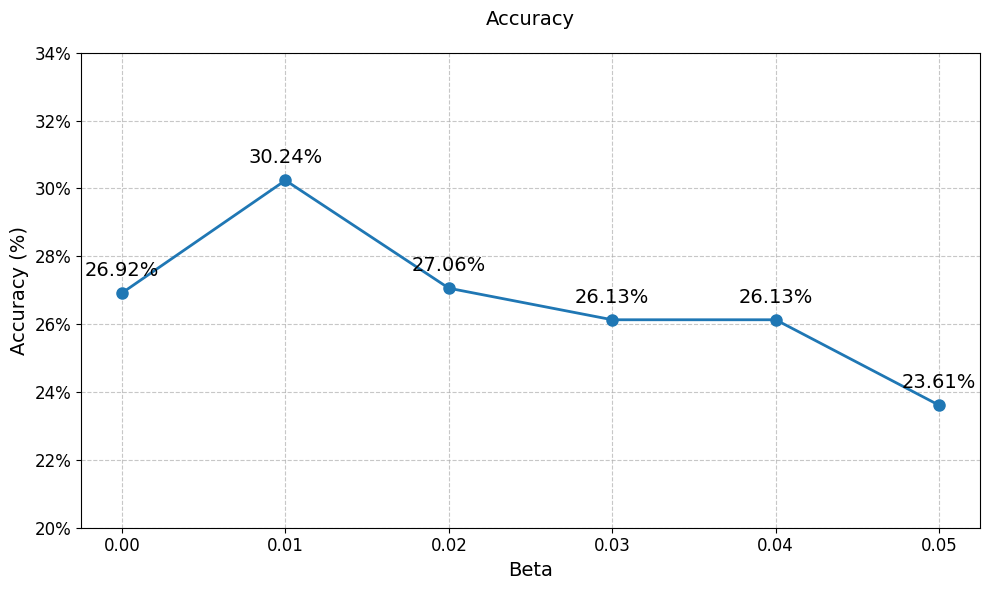
🔼 This figure shows how different constant weights of the KL divergence term in the GRPO algorithm affect the model’s performance in the geometry reasoning task. As the KL divergence weight increases, performance initially improves due to better regularization, but then decreases as excessive regularization leads to underfitting and reduced performance. The x-axis represents the weight of the KL divergence, and the y-axis shows the resulting accuracy.
read the caption
Figure 6. Impact of the weight of KL divergence
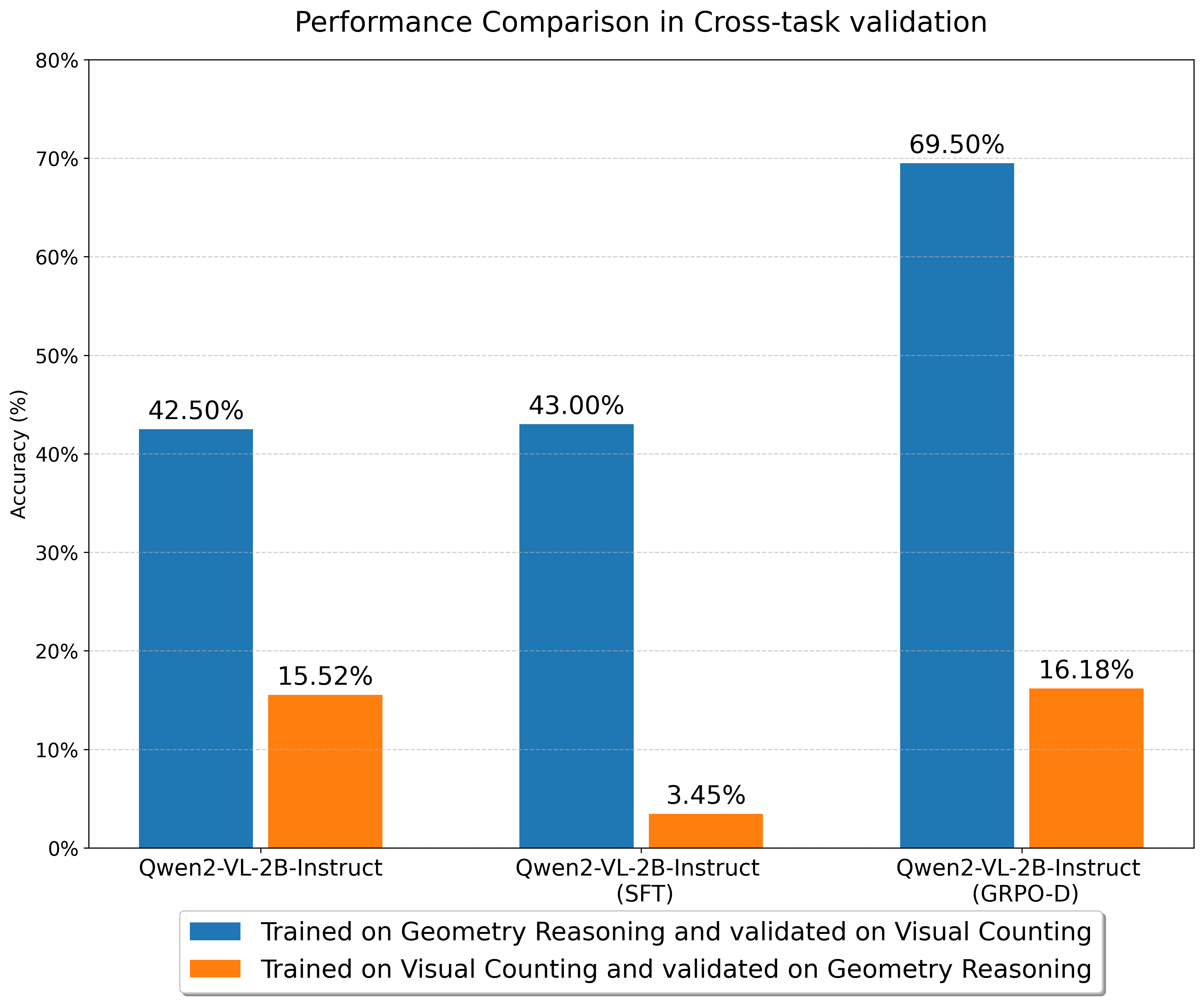
🔼 This figure displays the results of cross-task validation experiments. Two tasks were used: visual counting (a simpler task involving identifying objects) and geometry reasoning (a more complex task requiring logical analysis). Models were trained on one task and then evaluated on the other, demonstrating the ability of the models to generalize to unseen tasks. The bars show the accuracy achieved by different models (Qwen2-VL-2B-Instruct with various post-training methods: Supervised Fine-Tuning (SFT), Group Relative Policy Optimization (GRPO), and the Dynamic KL version of GRPO (GRPO-D)) on each cross-task scenario. The results highlight the superior generalization ability of GRPO-D compared to SFT and GRPO in transferring knowledge between different types of multimodal reasoning tasks.
read the caption
Figure 7. Cross-task validation.
Full paper#