TL;DR#
Multimodal Large Language Models (MLLMs) have excelled in 2D understanding, but lack standardized benchmarks for 4D objects(dynamic 3D). The absence of such benchmarks hinders the evaluation and enhancement of MLLMs in understanding how objects evolve over time and space. This poses a challenge, especially for tasks like digital twins and augmented reality where dynamic 3D assets are critical. Addressing this gap is essential for advancing interactive virtual experiences.
To address this, the paper introduces 4D-Bench, a benchmark for evaluating MLLMs in 4D object understanding with tasks in QA and captioning. The benchmark uses diverse 4D objects with high-quality annotations, necessitating multi-view spatial-temporal reasoning. Experiments reveal MLLMs struggle with temporal understanding, and even state-of-the-art models perform worse than humans. This underscores the need for further advancements in MLLMs for 4D object understanding.
Key Takeaways#
Why does it matter?#
This benchmark is vital for assessing MLLMs in 4D object understanding, highlighting current limitations and inspiring new approaches for improved spatial-temporal reasoning in AI models.
Visual Insights#

🔼 This figure illustrates the complexities of 4D object understanding by presenting a multi-view video sequence of a robot. The robot’s right hand is central to the task. The challenge is that the hand’s appearance varies significantly across different viewpoints and across time, creating ambiguity. To answer a simple question about what the hand transforms into requires the system to solve three subproblems: 1) resolve multi-view ambiguity by selecting the right viewpoint and time frame where the hand is clearly visible; 2) precisely locate the hand within those selected frames; and 3) track the hand’s changes across the selected time-series to determine the final state.
read the caption
Figure 1: An example demonstrating the challenges of 4D object understanding involves multi-view spatial-temporal reasoning. Given the 4D object, the robot’s right hand seems ambiguous in some views at first and eventually disappears over time. Hence, answering the question needs to (1) address multi-view ambiguity and choose proper views and time that the right hand is visible, (2) localize the right hand, (3) and track its evolutions along the time dimension.
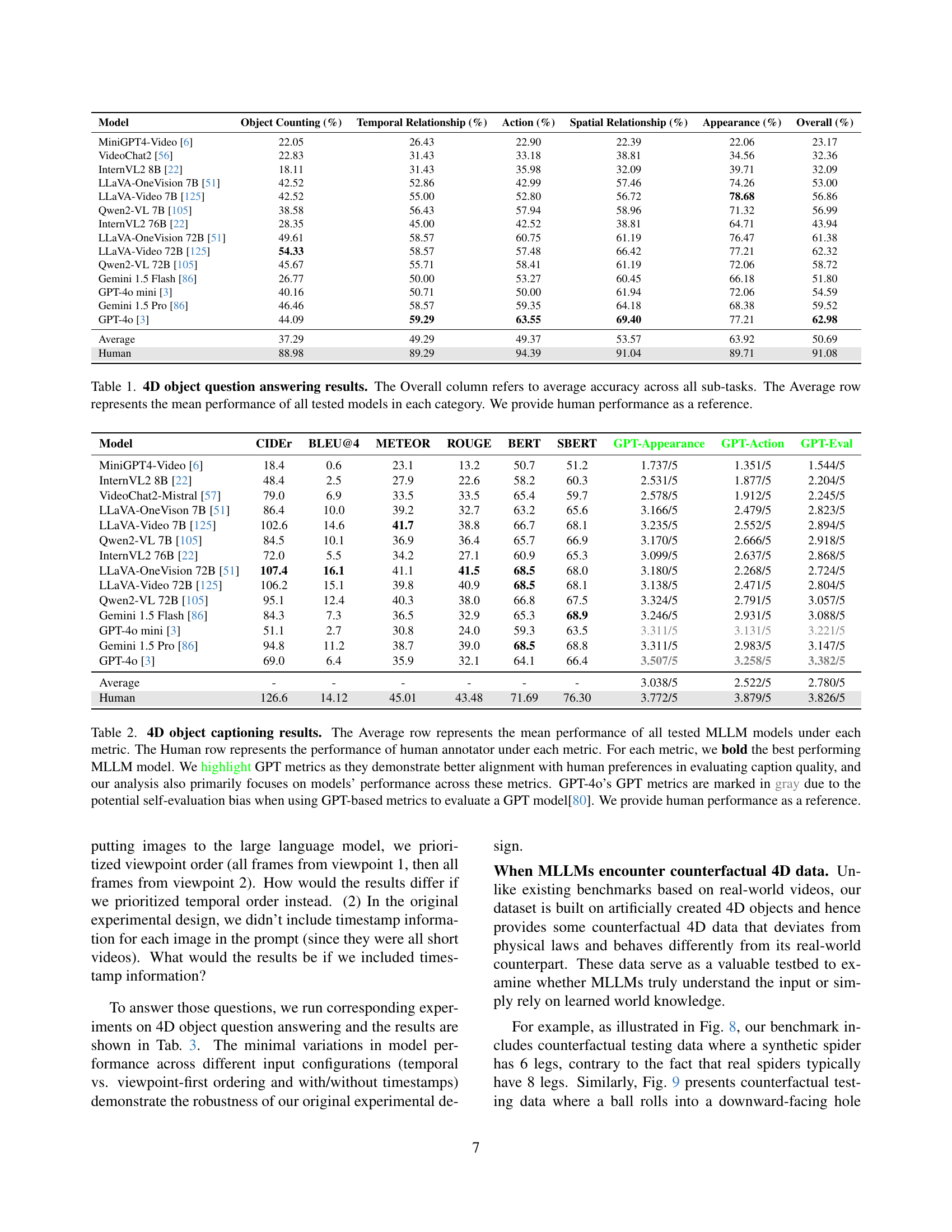
| Model | Object Counting (%) | Temporal Relationship (%) | Action (%) | Spatial Relationship (%) | Appearance (%) | Overall (%) |
|---|---|---|---|---|---|---|
| MiniGPT4-Video [6] | 22.05 | 26.43 | 22.90 | 22.39 | 22.06 | 23.17 |
| VideoChat2 [56] | 22.83 | 31.43 | 33.18 | 38.81 | 34.56 | 32.36 |
| InternVL2 8B [22] | 18.11 | 31.43 | 35.98 | 32.09 | 39.71 | 32.09 |
| LLaVA-OneVision 7B [51] | 42.52 | 52.86 | 42.99 | 57.46 | 74.26 | 53.00 |
| LLaVA-Video 7B [125] | 42.52 | 55.00 | 52.80 | 56.72 | 78.68 | 56.86 |
| Qwen2-VL 7B [105] | 38.58 | 56.43 | 57.94 | 58.96 | 71.32 | 56.99 |
| InternVL2 76B [22] | 28.35 | 45.00 | 42.52 | 38.81 | 64.71 | 43.94 |
| LLaVA-OneVision 72B [51] | 49.61 | 58.57 | 60.75 | 61.19 | 76.47 | 61.38 |
| LLaVA-Video 72B [125] | 54.33 | 58.57 | 57.48 | 66.42 | 77.21 | 62.32 |
| Qwen2-VL 72B [105] | 45.67 | 55.71 | 58.41 | 61.19 | 72.06 | 58.72 |
| Gemini 1.5 Flash [86] | 26.77 | 50.00 | 53.27 | 60.45 | 66.18 | 51.80 |
| GPT-4o mini [3] | 40.16 | 50.71 | 50.00 | 61.94 | 72.06 | 54.59 |
| Gemini 1.5 Pro [86] | 46.46 | 58.57 | 59.35 | 64.18 | 68.38 | 59.52 |
| GPT-4o [3] | 44.09 | 59.29 | 63.55 | 69.40 | 77.21 | 62.98 |
| Average | 37.29 | 49.29 | 49.37 | 53.57 | 63.92 | 50.69 |
| Human | 88.98 | 89.29 | 94.39 | 91.04 | 89.71 | 91.08 |
🔼 This table presents a comprehensive evaluation of various Multimodal Large Language Models (MLLMs) on a novel benchmark called 4D-Bench, specifically focusing on their 4D object question answering capabilities. The benchmark includes five subtasks assessing different aspects of 4D object understanding: Object Counting, Temporal Relationship, Action, Spatial Relationship, and Appearance. The table shows the accuracy of each MLLM on each subtask, an overall accuracy score, and average performance across all models. Human performance is also included as a baseline for comparison, highlighting the current gap between MLLM capabilities and human-level performance in 4D object understanding.
read the caption
Table 1: 4D object question answering results. The Overall column refers to average accuracy across all sub-tasks. The Average row represents the mean performance of all tested models in each category. We provide human performance as a reference.
In-depth insights#
4D Understanding#
4D understanding involves comprehending the interplay of 3D objects and their temporal evolution, demanding abilities beyond static image or video analysis. It necessitates grasping multi-view spatial relationships and tracking changes over time, a challenge distinct from traditional 2D or 3D scene understanding. Models must reason about object appearances, actions, and their evolution, considering viewpoints and temporal dynamics, thus requiring robust spatial-temporal reasoning capabilities. This entails overcoming ambiguities, recognizing subtle motions, and predicting future states, proving a demanding task for current MLLMs as performance lags in action recognition and temporal relationship comprehension suggest a crucial need for advancements in temporal-aware visual encoders to enhance MLLMs’ 4D understanding prowess.
4D-Bench: New Tasks#
The introduction of 4D-Bench marks a pivotal advancement in multimodal learning, extending beyond traditional 2D image and video understanding. It creates new tasks centered around understanding 4D objects (3D objects evolving over time), which presents unique challenges not found in existing benchmarks. These tasks likely involve complex spatial-temporal reasoning, requiring models to analyze multi-view data and track changes over time. The 4D object Question Answering (QA) and 4D object captioning tasks require MLLMs to describe the changes in a shape over time. Successfully addressing these new tasks will require enhancements in MLLMs’ abilities to integrate information across different modalities and effectively model temporal dynamics.
MLLMs Limitations#
MLLMs encounter limitations in 4D object understanding, particularly with tasks requiring detailed temporal reasoning and counterfactual understanding. Weak performance in action recognition suggests a need for more advanced, temporal-aware visual encoders. Object counting poses a challenge, as the models struggle to integrate multi-view information accurately. While MLLMs demonstrate proficiency in appearance and spatial relationships, accurately capturing the evolution of objects in time and understanding motions remains a key area for future improvement. The models struggle with counterfactual data, lacking the world knowledge to adapt. The current visual tokenization methods can benefit from using video as raw input to enhance performance.
Human vs. MLLMs#
The paper reveals a performance disparity: humans outperform MLLMs in understanding 4D objects. Even state-of-the-art MLLMs struggle with tasks requiring multi-view spatial-temporal reasoning, while humans demonstrate higher accuracy. MLLMs struggle with object counting, action recognition, and temporal relationships. This highlights the need for advancements in MLLM architectures and training methodologies to bridge the gap between human and machine understanding of dynamic 3D environments, especially counterfactual data. More advanced temporal-aware visual encoders can enhance MLLMs’ performance.
Spatial Reasoning#
Spatial reasoning in 4D object understanding, as highlighted by the paper, goes beyond static 3D scene analysis. It necessitates the ability to discern and interpret spatial configurations across multiple viewpoints and over time, a challenge that traditional 3D-language benchmarks overlook. This involves understanding object relationships, transformations, and handling occlusions, demanding integration of information from various angles. The benchmark evaluates if MLLMs can grasp these intricate spatial dynamics within a 4D context. It also assesses the models’ ability to infer spatial arrangements even when partial visibility presents hurdles, making spatial reasoning a crucial aspect for MLLMs.
More visual insights#
More on figures

🔼 This figure illustrates the 4D-Bench benchmark, which evaluates the abilities of Multimodal Large Language Models (MLLMs) to understand 4D objects. It highlights the two main tasks included: 4D object question answering (QA) and 4D object captioning. The 4D object QA task presents a question with four answer choices, testing the MLLM’s reasoning ability. The 4D object captioning task requires the MLLM to generate a caption for a 4D object (dynamic 3D object), and its performance is evaluated against five human-generated captions for the same object. The visual representation shows example 4D objects displayed as multi-view videos over time, demonstrating the complexity inherent in understanding dynamic 3D scenes.
read the caption
Figure 2: Illustration of the 4D-Bench. 4D-Bench consists of two critical tasks (a) 4D object QA and (b) 4D object captioning. 4D object QA provides one question and four choices per QA to evaluate MLLMs. 4D object captioning provides five human captions per 4D object.

🔼 This figure illustrates the process of creating the 4D-Bench dataset. It starts with 3D objects sourced from Objaverse-XL, which are then rendered into multi-view videos. These videos undergo two filtering stages: motion filtering (removing static objects) and visual quality filtering (removing poorly rendered objects). The data then passes to annotation, creating both 4D object captions (purely human-annotated) and 4D object question-answer pairs (created using a combination of human annotation and MLLMs).
read the caption
Figure 3: Pipeline for constructing the 4D-Bench dataset. The pipeline includes rendering multi-view videos for 4D objects from Objaverse-XL, motion filtering, visual quality filtering, and multi-stage annotations for QA pairs and captions. Captions are purely human-annotated, while QA pairs are generated through a hybrid approach using MLLMs and human validation.

🔼 This figure presents a detailed breakdown of the data distribution within the 4D-Bench benchmark. The left panel displays the distribution of question-answer pairs across five subtasks in the 4D object question answering section of the benchmark. It shows that a total of 751 question-answer pairs were created. The right panel shows the distribution of 4D objects across six categories in the 4D object captioning section of the benchmark, which includes 580 4D objects in total. This visualization helps to understand the composition and balance of different task types and object categories within the benchmark dataset.
read the caption
Figure 4: Subtask and category distributions in 4D object QA and captioning. Left: Distribution of five subtasks in the 4D object QA task, 751 question-answering pairs in total. Right: Distribution of 4D object categories in 4D object captioning task, 580 4D objects in total.

🔼 This figure showcases a sample question from the Object Counting subtask within the 4D-Bench benchmark. The task’s complexity highlights the need for multi-view spatial reasoning. A single viewpoint (like the middle row in the image) might incorrectly suggest four presents because some are partially or fully occluded, leading to an inaccurate count. Correctly answering requires integrating information from multiple perspectives to identify all presents.
read the caption
Figure 5: An example from Object Counting subtask. Answering this question requires integrating multi-view information and capturing cross-view correspondences to count the presents, necessitating multi-view reasoning abilities. If relying solely on a single view (e.g. the middle row), it would lead to wrong answers (e.g. four), since some boxes are occluded and invisible in this view.
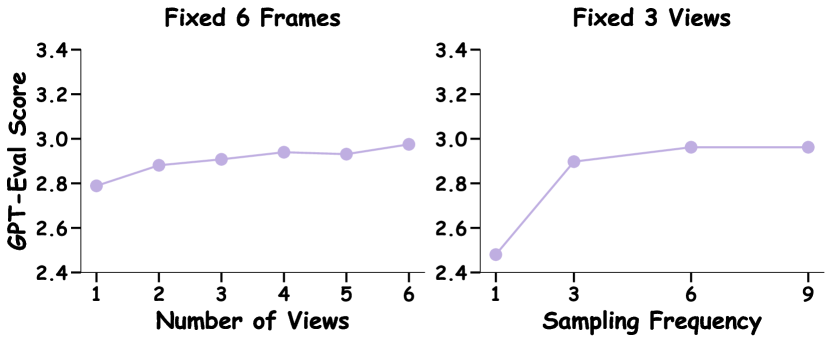
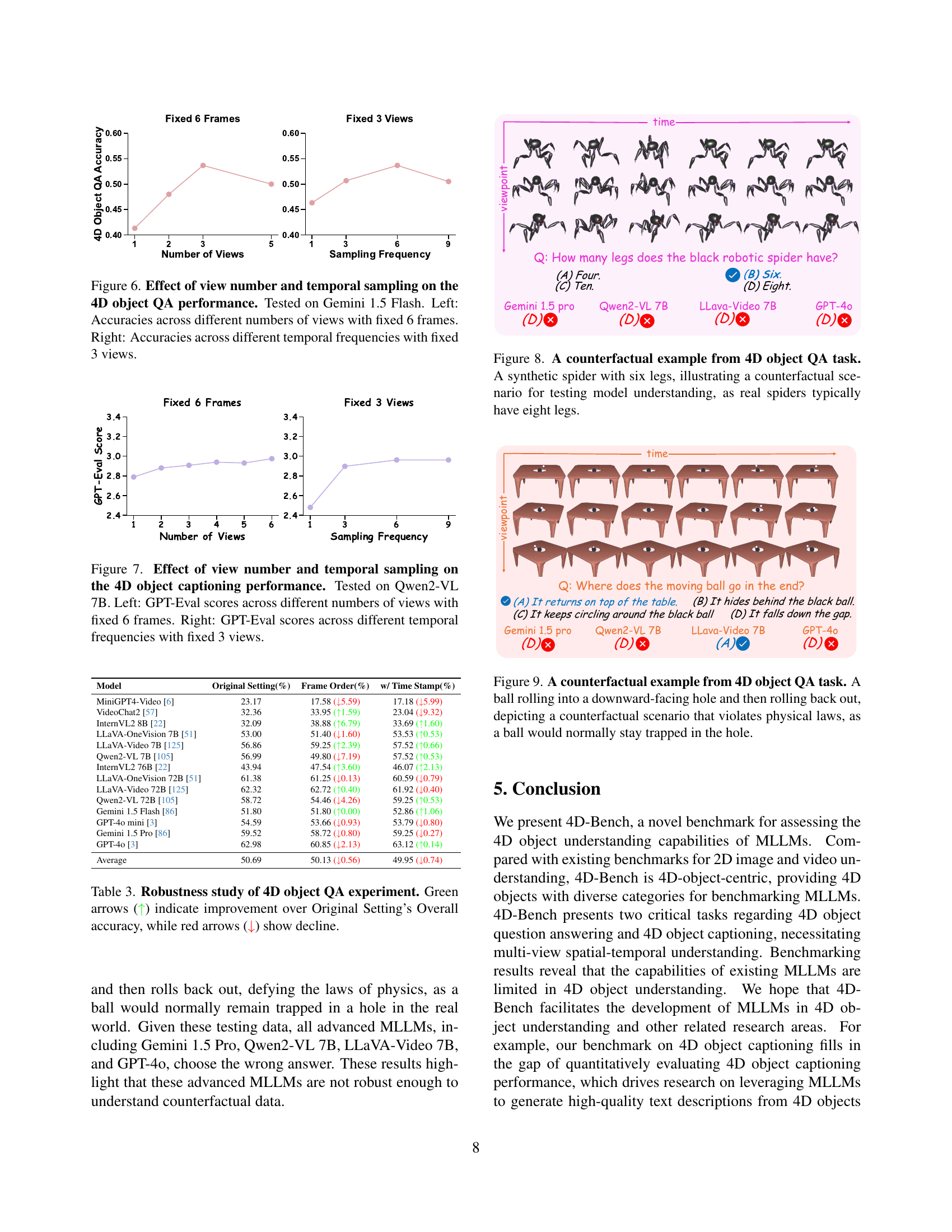
🔼 This figure displays the impact of varying the number of viewpoints and the frequency of sampled frames on the accuracy of 4D object question answering. The experiment uses the Gemini 1.5 Flash model. The left panel shows how accuracy changes as the number of views increases while keeping the number of frames per view constant at 6. The right panel shows the effect of altering the sampling frequency (frames per view) while maintaining a fixed number of 3 views. The results illustrate the interplay between the richness of visual input (number of views) and the temporal detail (sampling frequency) in influencing the model’s performance.
read the caption
Figure 6: Effect of view number and temporal sampling on the 4D object QA performance. Tested on Gemini 1.5 Flash. Left: Accuracies across different numbers of views with fixed 6 frames. Right: Accuracies across different temporal frequencies with fixed 3 views.

🔼 This figure demonstrates the impact of the number of views and temporal sampling frequency on the performance of the Qwen2-VL 7B model in 4D object captioning. The left panel shows how the GPT-Eval score changes as the number of views increases, while keeping the temporal sampling frequency constant at 6 frames. The right panel shows the effect of altering the temporal sampling frequency while using a fixed number of 3 views. The results illustrate the model’s sensitivity to both the spatial and temporal information presented.
read the caption
Figure 7: Effect of view number and temporal sampling on the 4D object captioning performance. Tested on Qwen2-VL 7B. Left: GPT-Eval scores across different numbers of views with fixed 6 frames. Right: GPT-Eval scores across different temporal frequencies with fixed 3 views.

🔼 This figure shows a synthetic spider with six legs, which is not a naturally occurring characteristic of spiders (they typically have eight legs). The image is a still from a multi-view video used in the 4D Object Question Answering (QA) task of the 4D-Bench benchmark. This example tests if the models can identify and reason about counterfactual scenarios, where objects have properties or traits that contradict real-world knowledge. By presenting an impossible feature, the researchers aim to evaluate whether the model truly understands the object or simply relies on its training data and pre-existing knowledge.
read the caption
Figure 8: A counterfactual example from 4D object QA task. A synthetic spider with six legs, illustrating a counterfactual scenario for testing model understanding, as real spiders typically have eight legs.

🔼 Figure 9 showcases a counterfactual scenario within the 4D object question answering task of the 4D-Bench benchmark. A ball is shown rolling into a downward-facing hole and then inexplicably rolling back out. This defies the laws of physics, as a ball would typically remain trapped in the hole. The figure highlights the benchmark’s ability to test the robustness of Multimodal Large Language Models (MLLMs) by presenting situations that violate real-world expectations.
read the caption
Figure 9: A counterfactual example from 4D object QA task. A ball rolling into a downward-facing hole and then rolling back out, depicting a counterfactual scenario that violates physical laws, as a ball would normally stay trapped in the hole.

🔼 This figure displays the distribution of video lengths in the 4D object captioning task dataset of the 4D-Bench benchmark. It shows the number of videos across different lengths, measured in the number of frames. The statistics, including mean, median, standard deviation, minimum, and maximum video length, are also provided to summarize the data.
read the caption
Figure I: The frame-length distribution of multi-view videos used in the 4D object captioning task

🔼 This histogram displays the distribution of caption lengths (number of words) in the 4D object captioning dataset. It shows the frequency of captions with different word counts, providing insights into the overall length and variability of the human-generated captions used in the benchmark.
read the caption
Figure II: The length distribution of ground-truth captions used in the 4D object captioning task

🔼 This figure shows the distribution of video lengths used in the 4D object question answering task of the 4D-Bench benchmark. It presents a histogram and kernel density estimate (KDE) plot illustrating the number of videos with varying lengths (number of frames). The mean, median, standard deviation, minimum, and maximum video lengths are also provided, giving a comprehensive view of the data distribution.
read the caption
Figure III: The frame-length distribution of multi-view videos used in the 4D object question answering task

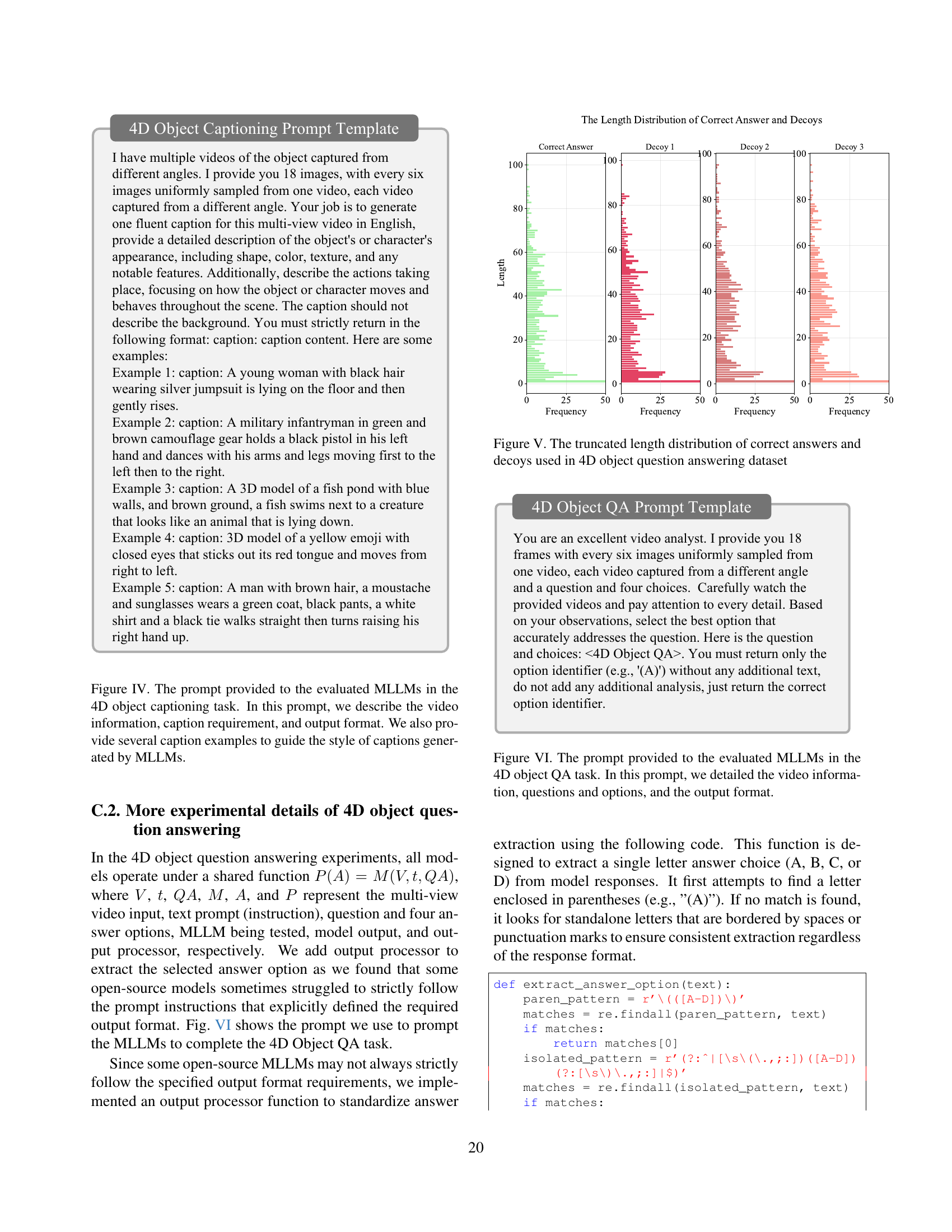
🔼 Figure IV illustrates the prompt used for the 4D object captioning task in the 4D-Bench benchmark. The prompt instructs the evaluated multi-modal large language models (MLLMs) to generate a caption for a provided 4D object (represented as a multi-view video). The prompt details the video content, specifies the required elements of the caption (appearance and actions), dictates the desired output format, and includes example captions to guide the MLLMs’ style and level of detail. This structure ensures consistency and facilitates a more objective evaluation of the MLLMs’ captioning capabilities.
read the caption
Figure IV: The prompt provided to the evaluated MLLMs in the 4D object captioning task. In this prompt, we describe the video information, caption requirement, and output format. We also provide several caption examples to guide the style of captions generated by MLLMs.

🔼 Figure V illustrates the distribution of the lengths of correct answers and incorrect options (decoys) in the 4D object question answering dataset. It shows histograms for each, revealing the frequency of different answer lengths. This helps to assess if there are biases in the dataset towards certain lengths, which could impact the evaluation of models.
read the caption
Figure V: The truncated length distribution of correct answers and decoys used in 4D object question answering dataset

🔼 Figure VI shows the prompt used in the 4D object question answering task of the 4D-Bench benchmark. The prompt instructs the evaluated Multimodal Large Language Models (MLLMs) to analyze a multi-view video (18 frames from multiple viewpoints) and select the correct answer from four given options. The prompt emphasizes the need for accurate responses and specifies that only the letter corresponding to the chosen answer (A, B, C, or D) should be returned.
read the caption
Figure VI: The prompt provided to the evaluated MLLMs in the 4D object QA task. In this prompt, we detailed the video information, questions and options, and the output format.

🔼 This figure displays the prompt template used for the GPT-Appearance metric in evaluating the quality of video captions generated by multimodal large language models (MLLMs). The prompt instructs the evaluator (GPT-4) to assess the predicted caption based on its accuracy in describing the visual appearance and shape of the objects in the video, comparing it to a human-annotated reference caption. A scoring rubric from 0 to 5 is provided, with detailed descriptions for each score level to guide the evaluation. Several example pairs of human and predicted captions with their corresponding scores are also given to illustrate how the scoring should be applied.
read the caption
Figure VII: Prompt used in GPT-Appearance metric

🔼 This figure shows the prompt template used for evaluating the quality of video captions generated by large language models (LLMs) using the GPT-Action metric. The prompt guides the evaluator to focus specifically on the accuracy and completeness of the action descriptions in the captions, ignoring other aspects like appearance or context. A scoring rubric (0-5) is provided, with detailed descriptions for each score level, illustrating expected qualities like precision, recall, and handling of synonyms/paraphrases. Several examples of human-generated captions paired with predicted captions and their corresponding scores are included to help the evaluator understand the scoring criteria.
read the caption
Figure VIII: Prompt used in GPT-Action metric

🔼 This figure showcases a qualitative comparison of how various multi-modal large language models (MLLMs) perform on the 4D object captioning task within the 4D-Bench benchmark. It presents several example 4D objects (dynamic 3D objects) and displays the captions generated by different MLLMs alongside a human-generated caption for comparison. This allows for a visual assessment of each model’s ability to accurately and comprehensively describe both the visual appearance and the actions depicted in the 4D object sequences.
read the caption
Figure IX: Qualitative results of different MLLMs on the 4D object captioning task of 4D-Bench

🔼 This figure presents a qualitative comparison of how different Multi-modal Large Language Models (MLLMs) perform the 4D object captioning task within the 4D-Bench benchmark. It shows example 4D objects and the captions generated by several MLLMs, alongside a human-generated caption for each object, allowing for a visual assessment of each model’s ability to understand both visual appearance and temporal aspects of dynamic 3D objects. The GPT-Appearance and GPT-Action scores, which evaluate the quality of appearance and action description, respectively, are included for each model’s caption to provide a quantitative comparison.
read the caption
Figure X: Qualitative results of different MLLMs on the 4D object captioning task of 4D-Bench

🔼 This figure presents a qualitative comparison of how different large multimodal language models (MLLMs) perform on the 4D object captioning task within the 4D-Bench benchmark. It shows examples of 4D objects and captions generated by various MLLMs, including MiniGPT4-Video, VideoChat2-Mistral, Qwen2-VL 7B, and Gemini 1.5 Pro, alongside a human-generated caption for comparison. The goal is to illustrate the strengths and weaknesses of each MLLM in terms of visual and motion understanding and the ability to generate accurate and descriptive captions for dynamic 3D objects.
read the caption
Figure XI: Qualitative results of different MLLMs on the 4D object captioning task of 4D-Bench

🔼 Figure XII presents a qualitative comparison of how different Multi-modal Large Language Models (MLLMs) perform on the 4D object captioning task within the 4D-Bench benchmark. It shows example 4D objects (dynamic 3D objects over time) and the captions generated by several MLLMs, alongside a human-generated caption for comparison. This allows for a visual assessment of each model’s ability to understand and describe both the visual appearance and the temporal evolution of the objects in the videos.
read the caption
Figure XII: Qualitative results of different MLLMs on the 4D object captioning task of 4D-Bench

🔼 This figure showcases the performance of various Multimodal Large Language Models (MLLMs) on a 4D object question answering task within the 4D-Bench benchmark. It presents a specific question and four possible answers, revealing which answer each MLLM selected. This allows for a direct comparison of the models’ abilities to understand and reason about spatiotemporal information in a 4D context, highlighting strengths and weaknesses in their 4D object understanding capabilities.
read the caption
Figure XIII: Qualitative results of different MLLMs on the 4D object question answering task of 4D-Bench

🔼 This figure showcases the performance of various large language models (LLMs) on a 4D object question answering task within the 4D-Bench benchmark. The task involves a video of a pink flamingo performing an action, and the LLMs must correctly identify the sequence of actions from the given choices. The results demonstrate the varying abilities of different LLMs to comprehend temporal dynamics and spatial reasoning in 4D object understanding.
read the caption
Figure XIV: Qualitative results of different MLLMs on the 4D object question answering task of 4D-Bench

🔼 This figure showcases a qualitative comparison of how various large language models (LLMs) perform on a 4D object question answering task within the 4D-Bench benchmark. It presents a sample question and the responses generated by different LLMs, highlighting their strengths and weaknesses in understanding temporal and spatial aspects of 4D objects (3D objects changing over time). The models’ answers are contrasted with the correct answer to illustrate performance differences.
read the caption
Figure XV: Qualitative results of different MLLMs on the 4D object question answering task of 4D-Bench
More on tables
| Model | CIDEr | BLEU@4 | METEOR | ROUGE | BERT | SBERT | GPT-Appearance | GPT-Action | GPT-Eval |
|---|---|---|---|---|---|---|---|---|---|
| MiniGPT4-Video [6] | 18.4 | 0.6 | 23.1 | 13.2 | 50.7 | 51.2 | 1.737/5 | 1.351/5 | 1.544/5 |
| InternVL2 8B [22] | 48.4 | 2.5 | 27.9 | 22.6 | 58.2 | 60.3 | 2.531/5 | 1.877/5 | 2.204/5 |
| VideoChat2-Mistral [57] | 79.0 | 6.9 | 33.5 | 33.5 | 65.4 | 59.7 | 2.578/5 | 1.912/5 | 2.245/5 |
| LLaVA-OneVison 7B [51] | 86.4 | 10.0 | 39.2 | 32.7 | 63.2 | 65.6 | 3.166/5 | 2.479/5 | 2.823/5 |
| LLaVA-Video 7B [125] | 102.6 | 14.6 | 41.7 | 38.8 | 66.7 | 68.1 | 3.235/5 | 2.552/5 | 2.894/5 |
| Qwen2-VL 7B [105] | 84.5 | 10.1 | 36.9 | 36.4 | 65.7 | 66.9 | 3.170/5 | 2.666/5 | 2.918/5 |
| InternVL2 76B [22] | 72.0 | 5.5 | 34.2 | 27.1 | 60.9 | 65.3 | 3.099/5 | 2.637/5 | 2.868/5 |
| LLaVA-OneVision 72B [51] | 107.4 | 16.1 | 41.1 | 41.5 | 68.5 | 68.0 | 3.180/5 | 2.268/5 | 2.724/5 |
| LLaVA-Video 72B [125] | 106.2 | 15.1 | 39.8 | 40.9 | 68.5 | 68.1 | 3.138/5 | 2.471/5 | 2.804/5 |
| Qwen2-VL 72B [105] | 95.1 | 12.4 | 40.3 | 38.0 | 66.8 | 67.5 | 3.324/5 | 2.791/5 | 3.057/5 |
| Gemini 1.5 Flash [86] | 84.3 | 7.3 | 36.5 | 32.9 | 65.3 | 68.9 | 3.246/5 | 2.931/5 | 3.088/5 |
| GPT-4o mini [3] | 51.1 | 2.7 | 30.8 | 24.0 | 59.3 | 63.5 | 3.311/5 | 3.131/5 | 3.221/5 |
| Gemini 1.5 Pro [86] | 94.8 | 11.2 | 38.7 | 39.0 | 68.5 | 68.8 | 3.311/5 | 2.983/5 | 3.147/5 |
| GPT-4o [3] | 69.0 | 6.4 | 35.9 | 32.1 | 64.1 | 66.4 | 3.507/5 | 3.258/5 | 3.382/5 |
| Average | - | - | - | - | - | - | 3.038/5 | 2.522/5 | 2.780/5 |
| Human | 126.6 | 14.12 | 45.01 | 43.48 | 71.69 | 76.30 | 3.772/5 | 3.879/5 | 3.826/5 |
🔼 Table 2 presents a comprehensive evaluation of various Multimodal Large Language Models (MLLMs) on a 4D object captioning task. The table compares the performance of several open-source and closed-source MLLMs against human performance using a variety of metrics. These metrics include traditional n-gram based metrics (BLEU, ROUGE, METEOR, CIDEr, BERTScore, Sentence-BERT) and GPT-based metrics (GPT-Appearance, GPT-Action, GPT-Eval). The GPT metrics are highlighted because they show a stronger correlation with human judgment of caption quality. The ‘Average’ row provides the average performance across all MLLMs for each metric, while the ‘Human’ row displays the average human performance, serving as a baseline. GPT-4’s GPT scores are presented in gray due to potential bias inherent in self-evaluating GPT models using GPT-based metrics. The table enables a detailed comparison of different MLLM capabilities in generating descriptive and accurate captions for dynamic 3D objects.
read the caption
Table 2: 4D object captioning results. The Average row represents the mean performance of all tested MLLM models under each metric. The Human row represents the performance of human annotator under each metric. For each metric, we bold the best performing MLLM model. We highlight GPT metrics as they demonstrate better alignment with human preferences in evaluating caption quality, and our analysis also primarily focuses on models’ performance across these metrics. GPT-4o’s GPT metrics are marked in gray due to the potential self-evaluation bias when using GPT-based metrics to evaluate a GPT model[80]. We provide human performance as a reference.
| Model | Original Setting(%) | Frame Order(%) | w/ Time Stamp(%) |
|---|---|---|---|
| MiniGPT4-Video [6] | 23.17 | 17.58 (↓5.59) | 17.18 (↓5.99) |
| VideoChat2 [57] | 32.36 | 33.95 (↑1.59) | 23.04 (↓9.32) |
| InternVL2 8B [22] | 32.09 | 38.88 (↑6.79) | 33.69 (↑1.60) |
| LLaVA-OneVision 7B [51] | 53.00 | 51.40 (↓1.60) | 53.53 (↑0.53) |
| LLaVA-Video 7B [125] | 56.86 | 59.25 (↑2.39) | 57.52 (↑0.66) |
| Qwen2-VL 7B [105] | 56.99 | 49.80 (↓7.19) | 57.52 (↑0.53) |
| InternVL2 76B [22] | 43.94 | 47.54 (↑3.60) | 46.07 (↑2.13) |
| LLaVA-OneVision 72B [51] | 61.38 | 61.25 (↓0.13) | 60.59 (↓0.79) |
| LLaVA-Video 72B [125] | 62.32 | 62.72 (↑0.40) | 61.92 (↓0.40) |
| Qwen2-VL 72B [105] | 58.72 | 54.46 (↓4.26) | 59.25 (↑0.53) |
| Gemini 1.5 Flash [86] | 51.80 | 51.80 (↑0.00) | 52.86 (↑1.06) |
| GPT-4o mini [3] | 54.59 | 53.66 (↓0.93) | 53.79 (↓0.80) |
| Gemini 1.5 Pro [86] | 59.52 | 58.72 (↓0.80) | 59.25 (↓0.27) |
| GPT-4o [3] | 62.98 | 60.85 (↓2.13) | 63.12 (↑0.14) |
| Average | 50.69 | 50.13 (↓0.56) | 49.95 (↓0.74) |
🔼 This table presents a robustness analysis of the 4D object question answering (QA) task within the 4D-Bench benchmark. It examines how variations in experimental setup affect model performance. Specifically, it compares the original experimental setting’s overall accuracy against results obtained by altering the order of viewpoint processing (viewpoint-first vs. temporal-first) and the inclusion of timestamp information in the prompts. Green upward arrows (↑) highlight improvements in overall accuracy compared to the original setting, while red downward arrows (↓) indicate decreases.
read the caption
Table 3: Robustness study of 4D object QA experiment. Green arrows (↑) indicate improvement over Original Setting’s Overall accuracy, while red arrows (↓) show decline.
Full paper#