TL;DR#
Multi-modal Large Language Models (MLLMs) show potential in medical diagnosis, yet face hurdles like limited visual input perception and reasoning inconsistencies. Current MLLMs primarily function in one-hop question answering, falling short of the expert-driven, evidence-based analysis needed in real-world medical diagnosis. These models often exhibit hallucinations and inconsistencies in reasoning, making it difficult to strictly adhere to established medical criteria. This limitation raises safety concerns, highlighting the need for advancements to improve reliability and clinical applicability.
To solve these issues, the paper introduces MedAgent-Pro, an evidence-based reasoning agentic system. It uses hierarchical workflow that integrates medical guidelines and expert tools. Multiple tool agents process multi-modal inputs & analyze indicators, providing diagnoses based on quantitative and qualitative evidence. The system achieves superior results in 2D & 3D medical diagnosis tasks, demonstrating its effectiveness.
Key Takeaways#
Why does it matter?#
This paper introduces a new method, that uses reasoning to improve medical diagnoses by incorporating evidence. The demonstrated enhancements in diagnostic accuracy & interpretability, is significant for pushing the boundaries of AI in healthcare. This work could inspire new research into AI-driven diagnostic tools and personalized medicine approaches.
Visual Insights#

🔼 This figure compares the performance of existing large multimodal language models (MLLMs) and the MedAgent-Pro framework in diagnosing two diseases: glaucoma and heart disease. It demonstrates that MLLMs, while capable of processing multi-modal data, often lack the precision and comprehensive reasoning necessary for reliable diagnoses. Their limitations are highlighted in red text. In contrast, MedAgent-Pro, which leverages a reasoning agentic workflow, provides more accurate and evidence-based diagnoses, supported by visual evidence and relevant literature citations (green text). This showcases MedAgent-Pro’s improved diagnostic accuracy and interpretability.
read the caption
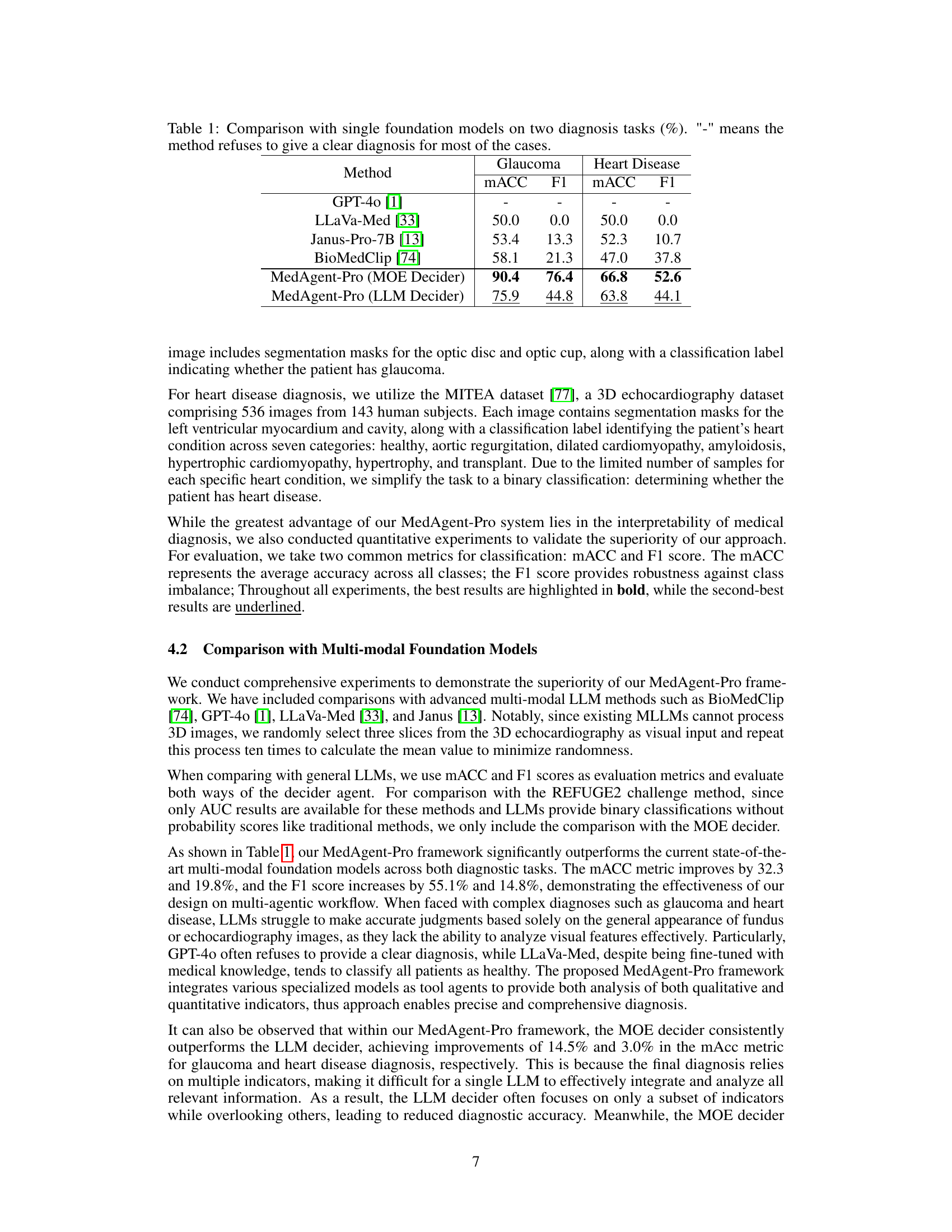
Figure 1: Comparison of existing MLLMs and our MedAgent-Pro framework on two disease diagnoses. Red text highlights the limitations of MLLMs, while green text represents the evidence-based diagnosis provided by MedAgent-Pro. Our approach enhances diagnostic accuracy while offering comprehensive literature support and visual evidence.
| Method | Glaucoma | Heart Disease | ||
| mACC | F1 | mACC | F1 | |
| GPT-4o [1] | - | - | - | - |
| LLaVa-Med [33] | 50.0 | 0.0 | 50.0 | 0.0 |
| Janus-Pro-7B [13] | 53.4 | 13.3 | 52.3 | 10.7 |
| BioMedClip [74] | 58.1 | 21.3 | 47.0 | 37.8 |
| MedAgent-Pro (MOE Decider) | 90.4 | 76.4 | 66.8 | 52.6 |
| MedAgent-Pro (LLM Decider) | 75.9 | 44.8 | 63.8 | 44.1 |
🔼 This table compares the performance of different single foundation models (GPT-40, LLaVa-Med, Janus-Pro-7B, and BioMedClip) and the proposed MedAgent-Pro model (with two different decider agents: MOE and LLM) on two medical diagnosis tasks: glaucoma and heart disease. The comparison uses two metrics: macro-averaged accuracy (MACC) and F1 score. The ‘-’ symbol indicates that the method failed to provide a diagnosis for most cases. The results show that MedAgent-Pro significantly outperforms the other single foundation models on both tasks.
read the caption
Table 1: Comparison with single foundation models on two diagnosis tasks (%). '-' means the method refuses to give a clear diagnosis for most of the cases.
In-depth insights#
Agentic Med Diag#
Agentic medical diagnosis represents a paradigm shift in AI-driven healthcare, moving beyond isolated diagnostic tasks towards comprehensive, collaborative systems. These systems leverage the strengths of Large Language Models (LLMs) and specialized AI tools within an agentic framework to mimic the reasoning and decision-making processes of human clinicians. Key features include the ability to integrate multi-modal patient data, access and apply medical knowledge, perform quantitative image analysis, and provide explainable diagnoses with supporting evidence. Agentic architectures address the limitations of directly applying LLMs to medical diagnosis, such as hallucinations, inconsistencies, and a lack of quantitative analysis capabilities. By combining LLMs with external tools and structured workflows, agentic systems can achieve greater accuracy, reliability, and interpretability in medical decision-making. The focus on evidence-based reasoning and adherence to clinical guidelines ensures that diagnoses are well-founded and aligned with established medical protocols. Future research will likely explore enhancing the collaboration and communication between agents, incorporating more diverse data modalities, and validating the clinical utility of these systems in real-world healthcare settings.
Evidence Workflow#
An evidence workflow, crucial in medical AI, systematically gathers and analyzes data to support diagnoses. It begins with data collection from various sources (images, text, patient data), followed by preprocessing to standardize and clean the information. AI models then extract relevant features, which are synthesized into evidence. This evidence is evaluated against medical knowledge and guidelines, generating a diagnosis with supporting rationale. Transparency is key, detailing the evidence used. The workflow is iterative, refining diagnoses as new evidence emerges. It enhances reliability by grounding decisions in verifiable data, improving clinical trust and patient outcomes. Standardizing this process ensures consistent and explainable AI application in healthcare.
Hierarchical AI#
Hierarchical AI represents a multi-layered approach to artificial intelligence, mirroring the structured organization found in complex systems like the human brain. This paradigm facilitates sophisticated problem-solving by decomposing intricate tasks into manageable sub-tasks, each addressed by specialized AI modules. The benefits are multi-fold: enhanced modularity allows for easier updates and maintenance, improved interpretability provides insights into the decision-making process at each level, and greater scalability enables the system to handle increasingly complex scenarios. A hierarchical architecture is not without its challenges, requiring careful design to ensure seamless communication and coordination between different AI modules. Effective management of information flow and decision delegation is crucial for optimal performance. Moreover, the creation of robust and adaptable hierarchical AI systems demands advanced techniques in areas such as reinforcement learning, knowledge representation, and automated planning. The potential applications span diverse fields, including robotics, natural language processing, and autonomous systems, offering a pathway towards more intelligent and adaptable AI solutions.
Multi-Modal Focus#
In the context of medical diagnosis, a “Multi-Modal Focus” signifies the integration of diverse data types for a more comprehensive patient assessment. This includes combining visual information from medical images (X-rays, MRIs) with structured data like patient history, lab results, and clinical notes. MLLMs are limited in quantitative analysis, making them hard to apply in clinical practice. A multi-modal approach aims to leverage the strengths of each modality, enabling more accurate and robust diagnoses. This is especially crucial when a single data source is insufficient or ambiguous, relying heavily on human doctors. The development of AI systems capable of autonomously handling the entire diagnostic workflow has become a key research focus. This integration also addresses the challenge of data heterogeneity, as medical information is often stored in various formats and locations, requiring sophisticated data fusion techniques for effective analysis.
Interpretability#
While the paper doesn’t explicitly have a section labeled “Interpretability,” the core concept is woven throughout its design and evaluation. MedAgent-Pro prioritizes explainability by design, contrasting with end-to-end MLLM approaches often acting as black boxes. The hierarchical workflow – task-level planning and case-level execution – promotes transparency. Each stage leverages specialized tools, providing traceable steps in the diagnostic process. The use of both quantitative and qualitative indicators, combined with visual evidence and clinical guidelines offers a multifaceted rationale behind the diagnosis. This is further enhanced by the MOE decider, assigning weights to different indicators to promote a more in-depth understanding of how the diagnosis is made rather than just a result. The case study (illustrated in Figure 3) exemplifies how MedAgent-Pro makes decisions transparent and justified. Finally, MedAgentPro’s ability to provide supporting evidence offers users a more grounded approach compared to MLLMs.
More visual insights#
More on figures

🔼 MedAgent-Pro uses a hierarchical workflow for medical diagnosis. The task-level reasoning stage uses a planner agent (an LLM) to generate a diagnostic plan based on retrieved clinical guidelines and available tools. This plan is then executed in the case-level diagnosis stage using orchestrator and tool agents. The orchestrator agent manages the process, while tool agents (e.g., image processing models, coding agents, VQA models) handle specific tasks. Finally, a decider agent integrates the results and delivers the final diagnosis, supported by evidence from the case-level analysis.
read the caption
Figure 2: The overall structure of our MedAgent-Pro framework. The blue text indicates different roles of agents, and the black text indicates medical information.

🔼 Figure 3 presents a detailed case study of glaucoma diagnosis using the MedAgent-Pro framework. It visually outlines the workflow, starting from the knowledge-based task-level reasoning where a diagnostic plan is generated based on retrieved medical guidelines and available tools. The figure then moves to the evidence-based case-level diagnosis, showing how multi-modal patient information (e.g., fundus image) is processed through various agents (orchestrator, tool, coding, and summary agents) to extract relevant features. The process culminates in a final diagnosis decision made by a decider agent, demonstrating how the system integrates clinical criteria and visual evidence for an accurate and explainable diagnosis.
read the caption
Figure 3: A case study for glaucoma diagnosis, which illustrates the workflow for a case in our MedAgent-Pro framework.
More on tables
| REFUGE2 winners | Ophthalmology Expert MLLMs | ||||
| Team Name | AUC | Rank | Method | mAcc | F1 |
| VUNO EYE TEAM | 88.3 | 1 | RetiZero [63] | 50.8 | 18.4 |
| MIG | 87.6 | 2 | VisionUnite [38] | 85.8 | 73.1 |
| MAI | 86.1 | 3 | MedAgent-Pro (LLM decider) | 75.9 | 44.8 |
| MedAgent-Pro (MOE decider) | 95.1 | - | MedAgent-Pro (MOE decider) | 90.4 | 76.4 |
🔼 This table compares the performance of MedAgent-Pro with the top-performing methods from the REFUGE2 challenge, a benchmark for glaucoma diagnosis, and with state-of-the-art ophthalmology-specific large language models (LLMs). It shows the AUC (Area Under the Curve) scores and ranks from the REFUGE2 leaderboard, along with mACC (mean accuracy across classes) and F1 scores for MedAgent-Pro and the other models. The comparison highlights MedAgent-Pro’s performance relative to established methods in the field.
read the caption
Table 2: Comparison with REFUGE2 challenge winners and ophthalmology MLLMs (%).
| Indicators | Single Indicator | Multiple Indicators | |||||||
| vCDR | RT | PPA | DH | mACC | F1 | MOE decider | LLM decider | ||
| mACC | F1 | mACC | F1 | ||||||
| ✓ | 81.7 | 65.9 | - | - | - | - | |||
| ✓ | 70.8 | 31.3 | - | - | - | - | |||
| ✓ | 81.0 | 74.6 | - | - | - | - | |||
| ✓ | 66.8 | 29.6 | - | - | - | - | |||
| ✓ | ✓ | - | - | 87.0 | 55.0 | 71.5 | 55.4 | ||
| ✓ | ✓ | - | - | 93.8 | 78.7 | 69.7 | 52.0 | ||
| ✓ | ✓ | - | - | 80.4 | 70.4 | 52.8 | 14.3 | ||
| ✓ | ✓ | ✓ | - | - | 90.1 | 81.5 | 73.3 | 61.3 | |
| ✓ | ✓ | ✓ | ✓ | - | - | 90.4 | 76.4 | 75.9 | 44.8 |
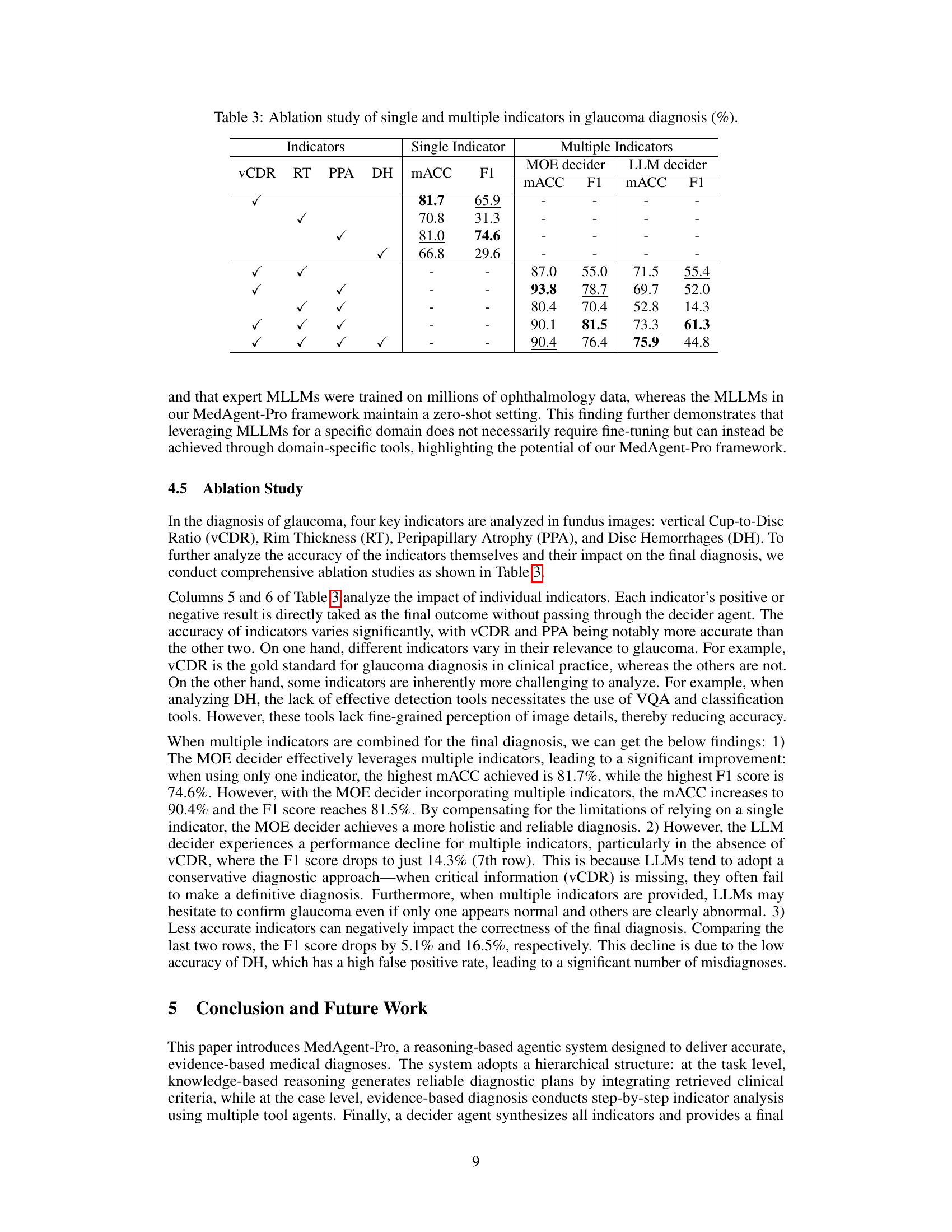
🔼 This ablation study analyzes the impact of individual indicators (vertical Cup-to-Disc Ratio (vCDR), Rim Thickness (RT), Peripapillary Atrophy (PPA), and Disc Hemorrhages (DH)) on glaucoma diagnosis accuracy. It compares the performance of using each indicator alone against using all indicators together with two different decision-making methods (MOE decider and LLM decider). The results show how much each individual indicator contributes to the overall diagnostic accuracy and highlight the differences in performance between the two decision-making methods, particularly when some indicators are missing or less accurate.
read the caption
Table 3: Ablation study of single and multiple indicators in glaucoma diagnosis (%).
Full paper#