TL;DR#
Existing 4D scene generation methods either focus on object-level details, neglecting the background and dynamics, or they require costly training with vast multi-view video datasets, which limits generalization. Those are computationally expensive and data-dependent. Thus, they are infeasible for scene-level generation.
This paper presents a novel framework that addresses these issues by distilling pre-trained foundation models for consistent 4D scene representation. It first animates an input image using diffusion models, followed by 4D structure initialization. Then, it turns this coarse structure into multi-view videos using adaptive guidance and latent replacement. Finally, it lifts these observations into 4D via a modulation-based refinement to mitigate inconsistencies.
Key Takeaways#
Why does it matter?#
This research is important because it offers a tuning-free solution for 4D scene generation, overcoming the limitations of existing methods. It reduces the reliance on large-scale training data and computational resources, making high-quality dynamic 3D scene creation more accessible. The new approach can inspire future research directions and be applied in VR, AR, and film production.
Visual Insights#

🔼 This figure showcases the capabilities of the Free4D model. The top row demonstrates examples of diverse 4D scenes generated from either a single image or a textual description. The bottom row displays a sequence of images across time from a generated 4D scene, illustrating the temporal consistency maintained by Free4D. The model’s ability to generate high-quality 4D content without requiring any parameter tuning or extensive training is a key highlight. The explicit 4D controls allow for precise manipulation and generation of the scenes.
read the caption
Figure 1: Free4D can generate diverse 4D scenes from single-image or textual input. By enforcing spatial-temporal consistency in a tuning-free way, Free4D enables high-quality scene generation with explicit 4D controls.
| Method | Text Align | Consistency | Dynamic | Aesthetic |
|---|---|---|---|---|
| 4Real [75] | 26.1% | 95.7% | 32.3% | 50.9% |
| Ours | 26.1% | 96.0% | 47.4% | 64.7% |
| 4Dfy [4] | 25.7% | 91.6% | 53.3% | 54.5% |
| Ours | 26.0% | 96.9% | 54.1% | 61.9% |
| D-in-4D [81] | 25.0% | 91.0% | 53.5% | 55.1% |
| Ours | 25.9% | 95.2% | 53.2% | 65.3% |
🔼 Table 1 presents a quantitative comparison of various text-to-4D scene generation methods using the VBench [26] benchmark. The metrics evaluated include Text Alignment (how well the generated scene matches the input text prompt), Consistency (how consistent the generated 4D scene appears across different viewpoints and timeframes), Dynamics (how realistic and fluid the motion appears in the generated 4D scene), and Aesthetics (the overall visual quality and appeal of the generated 4D scene). The results are presented as percentages for each metric, offering insights into the relative strengths and weaknesses of each method. The table includes results for Free4D (the authors’ method) as well as comparative methods: 4Real [75], 4Dfy [4], D-in-4D [81] (denoted as Dream-in-4D in the table).
read the caption
Table 1: Text-to-4D comparisons on VBench [26]. We report the text alignment, consistency, dynamics, and aesthetics of the generated 4D videos. D-in-4D denotes Dream-in-4D [81].
In-depth insights#
Tuning-Free 4D#
The concept of “Tuning-Free 4D” scene generation is compelling, suggesting a method that doesn’t require extensive, dataset-specific fine-tuning, a common bottleneck in generative models. This implies a reliance on pre-trained foundation models, leveraging their existing knowledge to achieve generalization. A tuning-free approach offers significant advantages, including reduced computational cost and data requirements. The core challenge lies in effectively distilling the knowledge from these pre-trained models and adapting it to the specific task of 4D scene generation while maintaining spatial-temporal consistency. This approach likely involves clever architectural designs or training strategies that allow the model to adapt to new scenes without explicit fine-tuning, thus promising increased efficiency and broader applicability.
Spatial-Temp CFG#
Spatial-Temporal Consistency is crucial for generating realistic 4D scenes. Adaptive Classifier-Free Guidance (CFG) improves spatial consistency by adjusting guidance based on point cloud visibility, preventing oversaturation. This ensures uniform color tones and reduces motion artifacts. Temporal coherence is enhanced with Reference Latent Replacement, which replaces inconsistent content in occluded regions with information from reference frames, reducing flickering and creating smoother videos. These strategies combined enable near-complete spatial-temporal consistency in the generated multi-view videos. By informing the model about the geometry and then adaptively guiding the sampling, the results display increased visual fidelity
Modulation Refine#
Modulation-based refinement is a pivotal technique, likely employed to enhance the consistency and fidelity of generated 3D or 4D content. It works by modulating or conditioning intermediate features based on high-quality signals. This process reduces inconsistencies and introduces details. The core idea involves refining an initial, potentially coarse, representation using modulation signals derived from a reference, such as generated image or a high-quality prior. The method leverages modulation signals at each timestep, guiding the denoising process towards desired context by adjusting the denoising direction, integrating information from the generated image to enhance rendering and consistency. Y serves as scaling factor while regulating the influence of generated image.
MonST3R Init#
The paper leverages MonST3R for effective 4D structure initialization, crucial for preserving geometric and spatial consistency. It outperforms alternatives like [64], previously used by ViewCrafter [76], highlighting its superiority in this context. MonST3R’s key contribution is providing a strong geometric foundation upon which subsequent stages of the pipeline can build. Accurate initialization is paramount because errors introduced early on can propagate and amplify throughout the entire process. By using MonST3R, the authors ensure that the generated 4D scene starts with a plausible and coherent geometric representation, which is essential for achieving high-quality results and maintaining consistency across different viewpoints and time steps. This robust initialization enables subsequent refinement stages to focus on improving visual fidelity and temporal coherence without having to correct fundamental geometric errors.
ViewCraft Limits#
The reliance on ViewCrafter for multi-view video generation in Free4D introduces certain limitations. Primarily, synthesizing novel views with large view ranges from limited 3D clues poses a challenge. The system struggles to generate accurate front views when only back views are available, indicating a constraint in extrapolating geometric information across significant viewpoint shifts. Additionally, ViewCrafter’s reliance on accurate point cloud geometry results in difficulties with severely blurred or defocused regions. Such regions hinder depth estimation, leading to distortions that propagate into the 4D-GS rendered results. Addressing these limitations would involve enhancing geometric understanding and robustness to image quality variations, potentially improving overall scene representation and rendering quality.
More visual insights#
More on figures

🔼 Figure 2 illustrates the Free4D framework. Starting with a single image or text input, a dynamic video is generated using an existing video generation model. This video then undergoes dynamic reconstruction using MonST3R, resulting in a 4D geometric structure. This structure guides the generation of a coarse multi-view video, which is subsequently refined using ViewCrafter to ensure spatial-temporal consistency. Techniques such as Adaptive Classifier-Free Guidance, Point Cloud Guided Denoising, and Reference Latent Replacement are used to enhance consistency. Finally, a modulation-based refinement optimizes the multi-view video to produce a coherent 4D representation.
read the caption
Figure 2: Overview of Free4D. Given an input image or text prompt, we first generate a dynamic video 𝒱={I(t,1)}t=1T𝒱superscriptsubscript𝐼𝑡1𝑡1𝑇\mathcal{V}=\{I(t,1)\}_{t=1}^{T}caligraphic_V = { italic_I ( italic_t , 1 ) } start_POSTSUBSCRIPT italic_t = 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_T end_POSTSUPERSCRIPT using an off-the-shelf video generation model [59]. Then, we employ MonST3R [77] with a progressive static point cloud aggregation strategy for dynamic reconstruction, obtaining a 4D geometric structure. Next, guided by this structure, we render a coarse multi-view video 𝒮′={{I′(t,k)}t=1T}k=1Ksuperscript𝒮′superscriptsubscriptsuperscriptsubscriptsuperscript𝐼′𝑡𝑘𝑡1𝑇𝑘1𝐾\mathcal{S}^{\prime}=\{\{I^{\prime}(t,k)\}_{t=1}^{T}\}_{k=1}^{K}caligraphic_S start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT = { { italic_I start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT ( italic_t , italic_k ) } start_POSTSUBSCRIPT italic_t = 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_T end_POSTSUPERSCRIPT } start_POSTSUBSCRIPT italic_k = 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_K end_POSTSUPERSCRIPT along a predefined camera trajectory and refine it into 𝒮={{I(t,k)}t=1T}k=1K𝒮superscriptsubscriptsuperscriptsubscript𝐼𝑡𝑘𝑡1𝑇𝑘1𝐾\mathcal{S}=\{\{I(t,k)\}_{t=1}^{T}\}_{k=1}^{K}caligraphic_S = { { italic_I ( italic_t , italic_k ) } start_POSTSUBSCRIPT italic_t = 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_T end_POSTSUPERSCRIPT } start_POSTSUBSCRIPT italic_k = 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_K end_POSTSUPERSCRIPT using ViewCrafter [76]. To ensure spatial-temporal consistency, we introduce Adaptive Classifer-Free Guidance (CFG) and Point Cloud Guided Denoising for spatial coherence, along with Reference Latent Replacement for temporal coherence. Finally, we propose an efficient training strategy with a Modulation-Based Refinement to lift the generated multi-view video 𝒮𝒮\mathcal{S}caligraphic_S into a consistent 4D representation ℛℛ\mathcal{R}caligraphic_R.

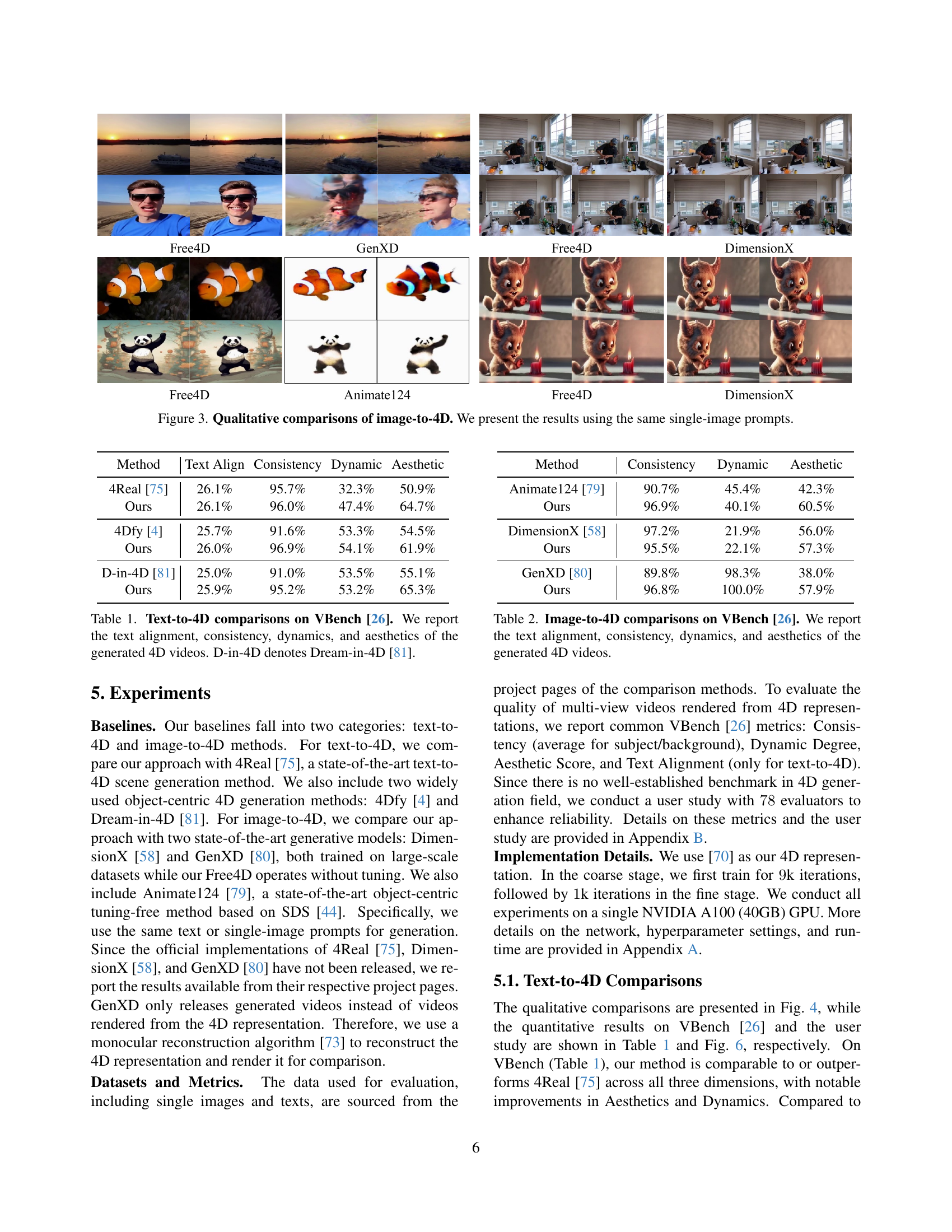
🔼 This figure shows a qualitative comparison of the image-to-4D scene generation results produced by Free4D and three other methods (GenXD, Free4D, DimensionX, Animate124). The comparison uses the same single-image prompts as input for all four methods, allowing for a direct visual assessment of the relative strengths and weaknesses of each approach in terms of generating high-quality 4D scenes from a single image. The differences in scene fidelity, realism, and overall visual quality are clearly evident in the generated output.
read the caption
Figure 3: Qualitative comparisons of image-to-4D. We present the results using the same single-image prompts.

🔼 This figure displays a qualitative comparison of the results produced by different methods for text-to-4D scene generation. Each row corresponds to a different text prompt, and several generated scenes, each produced by different methods, are shown side-by-side for comparison. This allows for a visual assessment of the differences in terms of generation quality, realism, detail level, and consistency across different methods. The visual comparison helps to demonstrate the advantages of the proposed Free4D model.
read the caption
Figure 4: Qualitative comparisons of text-to-4D. We show the results based on the same text prompts.

🔼 This ablation study visually compares the results of Free4D with different components removed or modified to highlight their individual contributions to the model’s performance. It shows how each part of the pipeline (4D Structure Initialization, Adaptive CFG, Point Cloud Guided Denoising, Latent Replacement, Coarse-to-Fine Optimization, Modulation-Based Refinement, and Static Point Cloud Aggregation) affects the consistency, dynamics, and aesthetics of the generated video. The results are shown qualitatively through side-by-side comparisons of the full model’s output versus the modified versions.
read the caption
Figure 5: Qualitative Comparison of Ablation Studies.

🔼 This figure presents a bar chart summarizing the results of a user study comparing Free4D to other methods in terms of consistency, dynamics, and aesthetics. Each bar represents the win rate of a particular method against Free4D, indicating how often users preferred a given method over Free4D. Higher bars represent better performance relative to Free4D, suggesting which aspects of the compared methods users found most compelling. The chart provides a visual comparison of user preferences for each criteria across the various methods, offering valuable insights into the strengths and weaknesses of Free4D relative to state-of-the-art approaches.
read the caption
Figure 6: Comparison of different methods based on the user study.

🔼 This figure displays the web interface used for the user studies conducted in the paper. Participants were presented with an input prompt, which could be either a single image or a short text description. The interface allows users to compare two different methods’ results side-by-side, evaluating each based on criteria like consistency, dynamics, aesthetics, and an overall assessment. Participants can navigate through multiple comparison sets and submit their judgments.
read the caption
Figure A: The web interface of our user studies. The input prompt can be either a single image or a short text.
More on tables
| Method | Consistency | Dynamic | Aesthetic |
|---|---|---|---|
| Animate124 [79] | 90.7% | 45.4% | 42.3% |
| Ours | 96.9% | 40.1% | 60.5% |
| DimensionX [58] | 97.2% | 21.9% | 56.0% |
| Ours | 95.5% | 22.1% | 57.3% |
| GenXD [80] | 89.8% | 98.3% | 38.0% |
| Ours | 96.8% | 100.0% | 57.9% |
🔼 This table presents a quantitative comparison of different image-to-4D generation methods on the VBench benchmark [26]. The metrics used for comparison are Text Alignment, Consistency (measuring both subject and background consistency), Dynamics (the degree of motion in the generated videos), and Aesthetics (overall visual appeal). The results offer a comprehensive evaluation of the methods’ performance across these key aspects of 4D scene generation, revealing strengths and weaknesses in generating realistic and visually pleasing 4D content from single images.
read the caption
Table 2: Image-to-4D comparisons on VBench [26]. We report the text alignment, consistency, dynamics, and aesthetics of the generated 4D videos.
| Method | Consistency | Dynamic | Aesthetic |
|---|---|---|---|
| wo / w MonST3R | 14% / 86% | 30% / 70% | 9% / 91% |
| wo / w Ada. CFG | 14% / 86% | 36% / 64% | 25% / 75% |
| wo / w PGD∗ | 14% / 86% | 11% / 89% | 13% / 87% |
| wo / w RLR† | 24% / 76% | 31% / 69% | 17% / 83% |
| wo / w Fine Stage | 4% / 96% | 21% / 79% | 6% / 94% |
| wo / w MBR‡ | 5% / 95% | 14% / 86% | 6% / 94% |
| SDS vs. Ours | 8% / 92% | 10% / 90% | 9% / 91% |
🔼 This table presents the results of a user study conducted to evaluate the impact of different components within the Free4D model on the quality of generated videos. The study compares the full Free4D model against versions where specific components have been removed. The components evaluated include Point Cloud Guided Denoising (PGD), Reference Latent Replacement (RLR), and Modulation-Based Refinement (MBR). The table shows the win rates (percentage of times a particular model was rated higher) for each ablation across four evaluation metrics: Consistency, Dynamic, Aesthetic, and Overall. This allows for a quantitative assessment of the contribution of each component to the overall performance of the Free4D model.
read the caption
Table 3: User study results on ablations. PGD∗, RLR†, and MBR‡ refer to point cloud guided denoising, reference latent replacement, and modulation-based refinement, respectively.
🔼 This table compares the runtime of Free4D with other methods for 4D scene generation. It breaks down the runtime by considering the number of video frames generated and the number of viewpoints produced. The runtime for Structure from Motion (SfM), a common preprocessing step, is excluded due to significant variability in processing time depending on the input scene’s complexity.
read the caption
Table A: Comparison of runtime with other methods. Frames and Views represent the number of video frames and the number of viewpoints, respectively. The running time of Structure from Motion (SfM), such as colmap [52], is not included due to significant variations across different scenes.
Full paper#