TL;DR#
Current summarization refinement often focuses on a single dimension like faithfulness, potentially compromising other quality aspects. Existing methods struggle to handle trade-offs, ordering biases, and noisy feedback when extending to multiple dimensions. Addressing these challenges is crucial for producing high-quality summaries that meet diverse criteria.
To solve the issues, this paper introduces ReFeed, a novel refinement pipeline that uses reflective reasoning on feedback to enhance multiple dimensions simultaneously. The authors release SumFeed-CoT, a large-scale dataset, and demonstrate ReFeed’s effectiveness in balancing trade-offs, mitigating biases, and maintaining robustness against noisy feedback. It offers a promising direction for developing more robust and reliable text summarization systems.
Key Takeaways#
Why does it matter?#
This paper introduces ReFeed, a novel approach for multi-dimensional summarization refinement. It offers a promising direction for developing more robust and reliable text summarization systems. It is also aligned with the growing trend of leveraging LLMs for multifaceted task optimization.
Visual Insights#

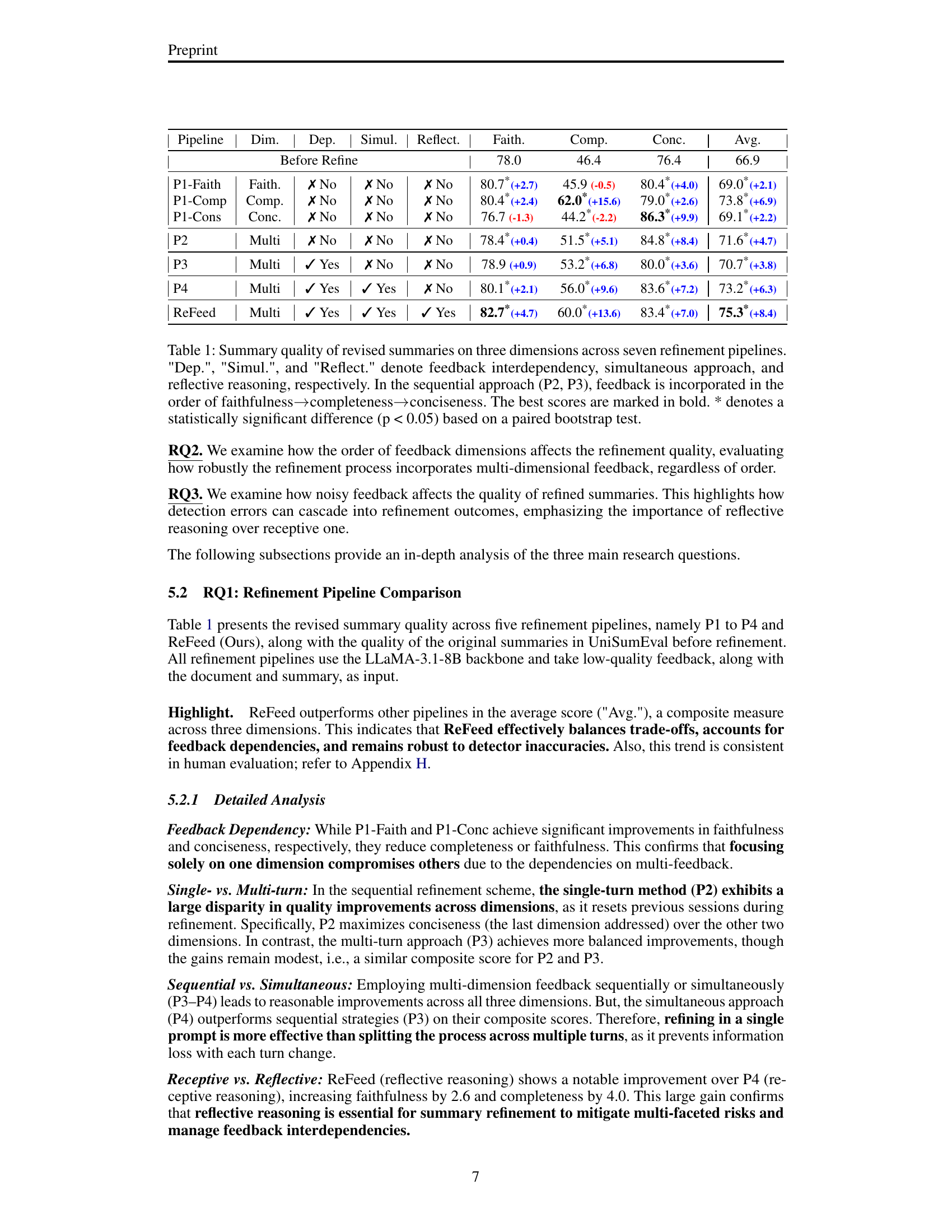
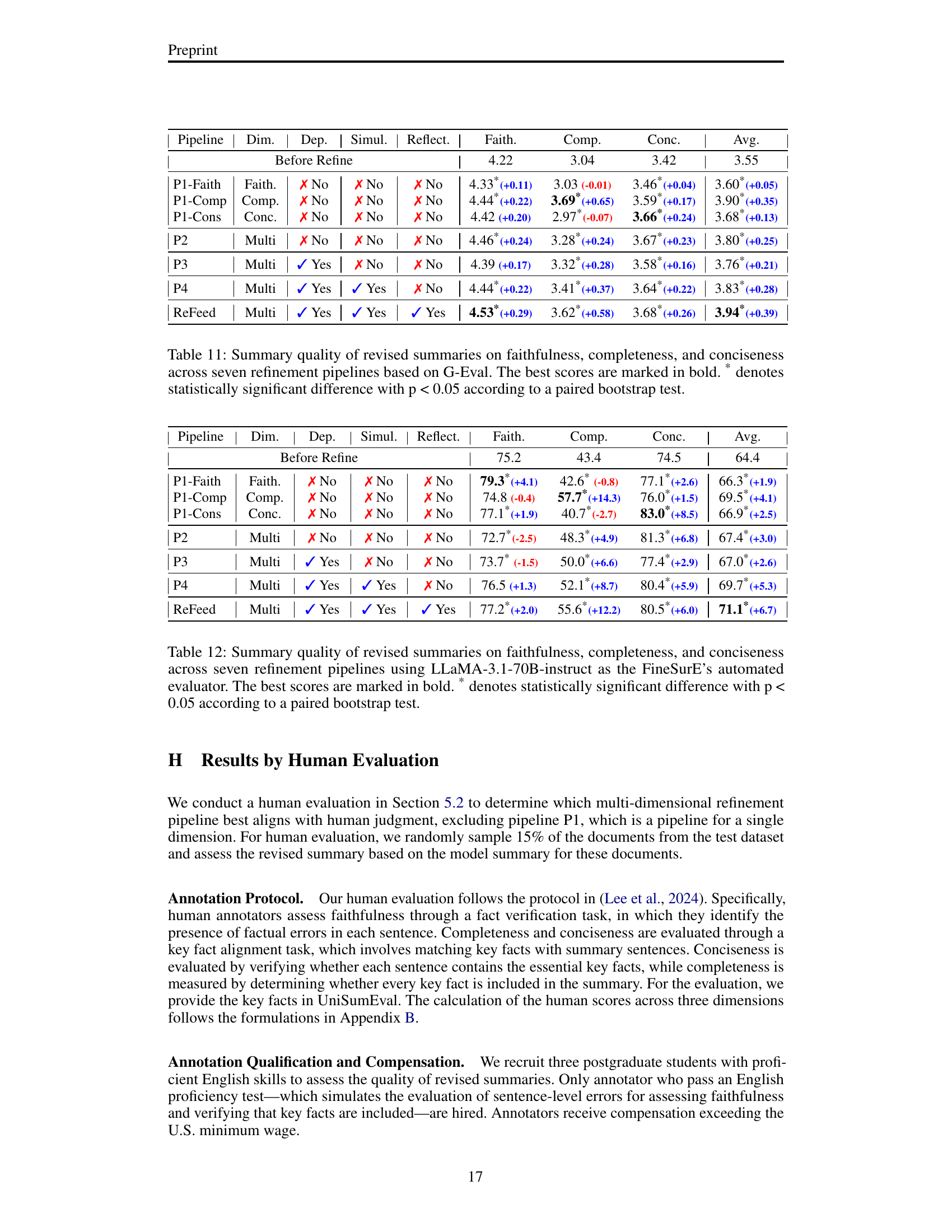
🔼 This figure illustrates the ReFeed framework, which refines summaries using multi-dimensional feedback. The left side shows the ReFeed pipeline: it begins with an initial summary generated by an LLM, followed by multi-dimensional feedback (faithfulness, completeness, conciseness) obtained through an LLM evaluator. This feedback is then processed using reflective reasoning, resolving potential trade-offs between dimensions and handling noisy feedback. The refined summary is finally produced. The right side details the construction of the SumFeed-CoT dataset used to train ReFeed. This involves generating initial feedback, creating reasoning with guidelines (backtracking, simultaneous refinement, noise filtering), and employing quality control mechanisms. This dataset is specifically designed to facilitate complex reasoning, allowing ReFeed to handle multiple dimensions effectively.
read the caption
Figure 1: Overview of ReFeed and data construction of SumFeed-CoT, a Long-CoT-based dataset for training ReFeed. Faith., Comp., and Conc. denote faithfulness, completeness, and conciseness.
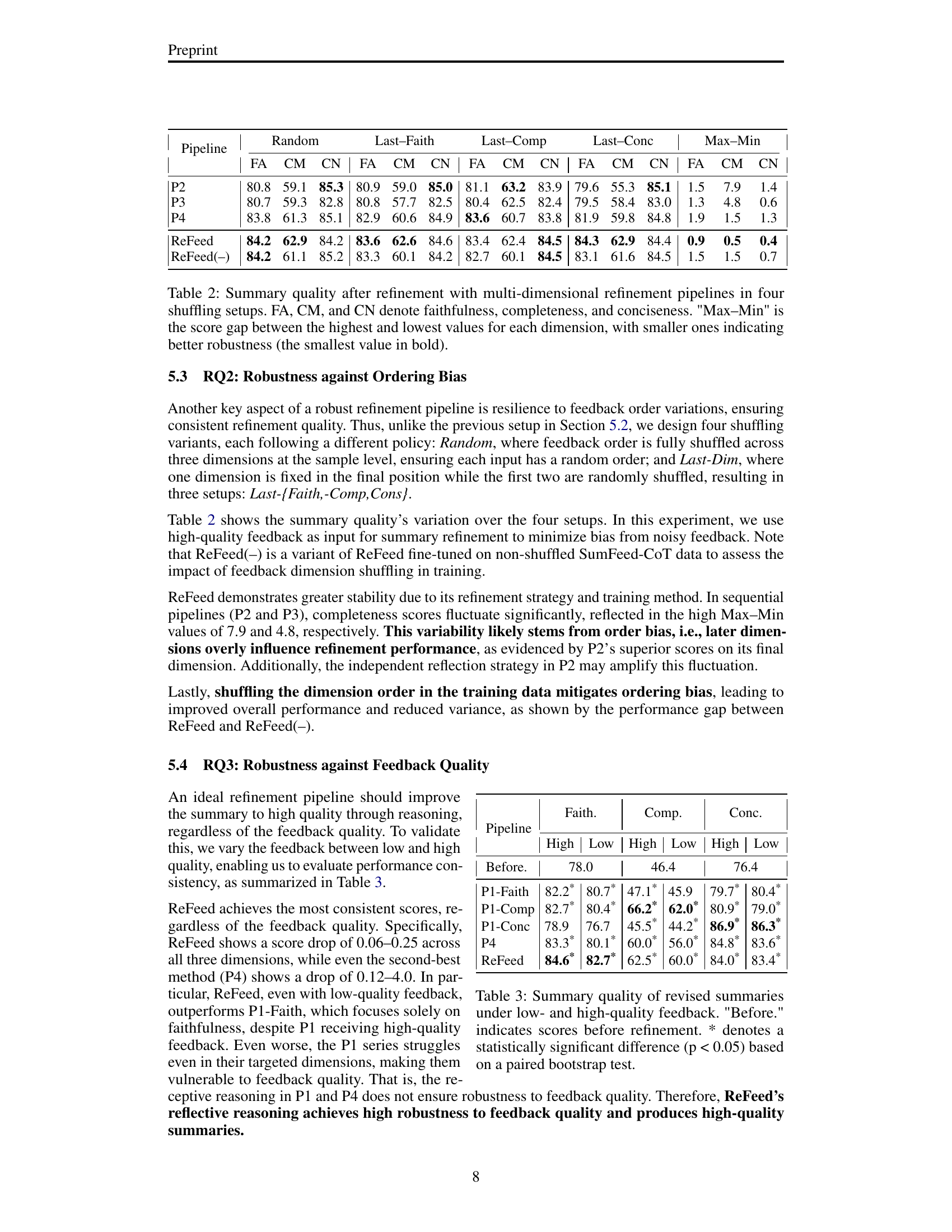
| Pipeline | Dim. | Dep. | Simul. | Reflect. | Faith. | Comp. | Conc. | Avg. |
| Before Refine | 78.0 | 46.4 | 76.4 | 66.9 | ||||
| P1-Faith | Faith. | ✗ No | ✗ No | ✗ No | 80.7*(+2.7) | 45.9 (-0.5) | 80.4*(+4.0) | 69.0*(+2.1) |
| P1-Comp | Comp. | ✗ No | ✗ No | ✗ No | 80.4*(+2.4) | 62.0*(+15.6) | 79.0*(+2.6) | 73.8*(+6.9) |
| P1-Cons | Conc. | ✗ No | ✗ No | ✗ No | 76.7 (-1.3) | 44.2*(-2.2) | 86.3*(+9.9) | 69.1*(+2.2) |
| P2 | Multi | ✗ No | ✗ No | ✗ No | 78.4*(+0.4) | 51.5*(+5.1) | 84.8*(+8.4) | 71.6*(+4.7) |
| P3 | Multi | ✓ Yes | ✗ No | ✗ No | 78.9 (+0.9) | 53.2*(+6.8) | 80.0*(+3.6) | 70.7*(+3.8) |
| P4 | Multi | ✓ Yes | ✓ Yes | ✗ No | 80.1*(+2.1) | 56.0*(+9.6) | 83.6*(+7.2) | 73.2*(+6.3) |
| ReFeed | Multi | ✓ Yes | ✓ Yes | ✓ Yes | 82.7*(+4.7) | 60.0*(+13.6) | 83.4*(+7.0) | 75.3*(+8.4) |
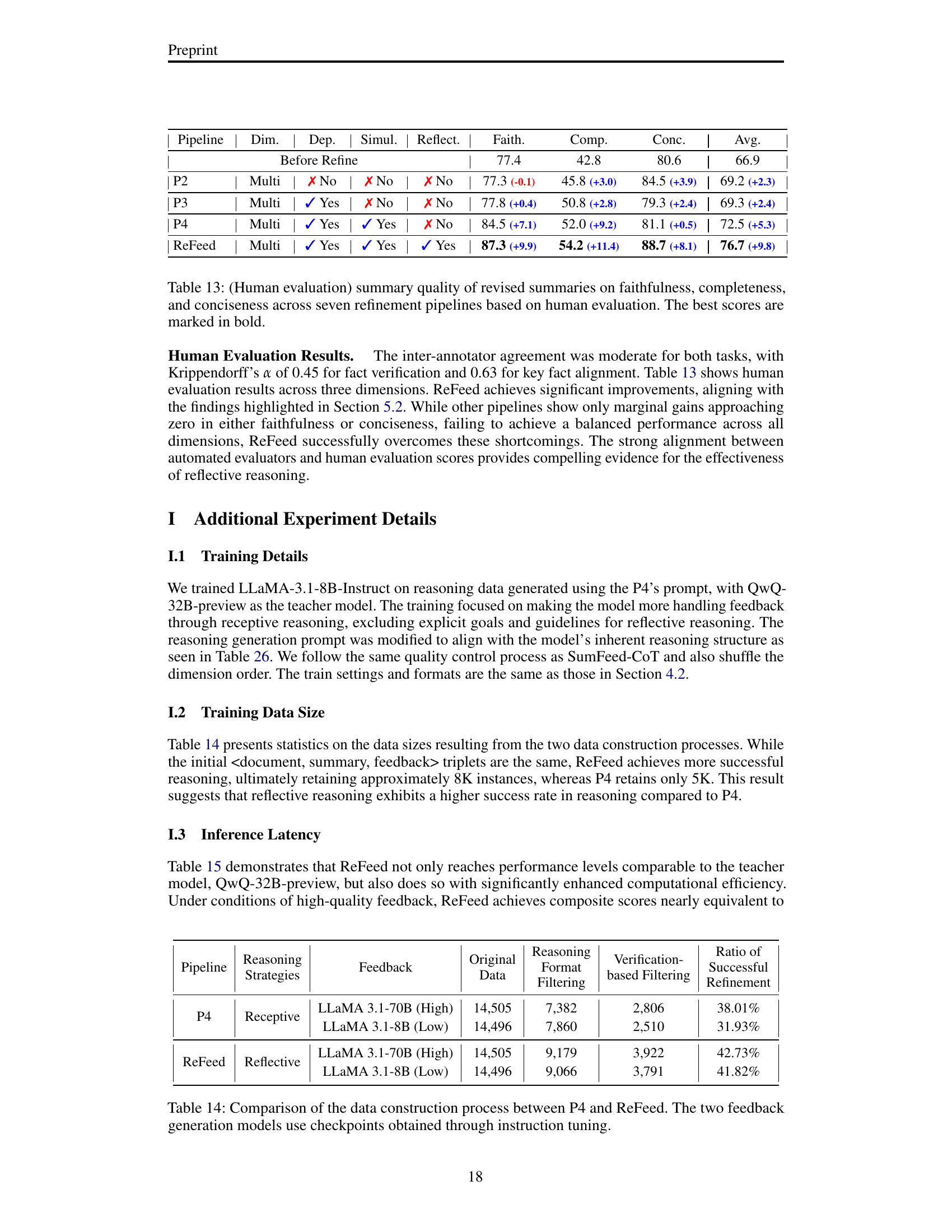
🔼 This table presents the results of a comparative analysis of seven different summarization refinement pipelines across three key dimensions: faithfulness, completeness, and conciseness. The pipelines vary in their approach to handling feedback, specifically whether feedback dependencies are considered (Dep.), feedback is incorporated sequentially or simultaneously (Simul.), and whether reflective reasoning is utilized (Reflect.). For sequential pipelines (P2 and P3), faithfulness feedback is processed before completeness and conciseness feedback. The best performance in each dimension and the overall average are highlighted in bold. A statistically significant improvement (p<0.05) over the baseline is indicated by an asterisk (*) based on a paired bootstrap test.
read the caption
Table 1: Summary quality of revised summaries on three dimensions across seven refinement pipelines. 'Dep.', 'Simul.', and 'Reflect.' denote feedback interdependency, simultaneous approach, and reflective reasoning, respectively. In the sequential approach (P2, P3), feedback is incorporated in the order of faithfulness→→\rightarrow→completeness→→\rightarrow→conciseness. The best scores are marked in bold. * denotes a statistically significant difference (p < 0.05) based on a paired bootstrap test.
In-depth insights#
ReFeed Pipeline#
ReFeed, a multi-dimensional summarization refinement pipeline, leverages reflective reasoning on feedback to enhance multiple dimensions simultaneously. It addresses key challenges in refinement, such as trade-offs between dimensions, ordering bias, and noisy feedback. Unlike single-dimension approaches that often compromise other aspects, ReFeed aims for balanced improvement by considering faithfulness, completeness, and conciseness. It incorporates a large-scale dataset (SumFeed-CoT) to train a lightweight model capable of complex reasoning. By distilling large reasoning models and enabling backtracking, ReFeed can mitigate risks associated with multifaceted feedback and feedback dependencies. The pipeline’s robustness against order bias and noisy feedback ensures consistent performance. ReFeed significantly enhances refinement quality and reduces inference time, making it a valuable tool for multi-dimensional summarization refinement.
SumFeed-CoT Data#
The SumFeed-CoT dataset centers on refining summaries through reflective reasoning on feedback, addressing challenges in multi-dimensional summarization. It aims to enhance faithfulness, completeness, and conciseness, using a large-scale, Long-CoT dataset optimized for training lightweight models. The approach involves distilling reasoning from larger models and integrating it into the refinement pipeline, addressing trade-offs, ordering bias, and noise. The dataset construction involves goal specification, guideline formulation, and quality control. It incorporates noisy LLM-generated feedback and utilizes strategies such as backtracking, simultaneous style refinement, and feedback validation, to identify and correct factual errors while optimizing conciseness and completeness. This also aids to validate feedback to filter noise.
Reflective Reason#
Reflective reasoning is a cognitive process that involves thinking deeply about one’s own thoughts and experiences. It entails examining assumptions, beliefs, and values to gain insights and improve decision-making. In the context of language models, reflective reasoning could involve models critically evaluating their own outputs and reasoning processes. This self-assessment can help identify errors, biases, or areas for improvement, leading to more accurate and reliable results. By incorporating feedback loops, models can refine their understanding and adapt their strategies over time. This ability to reflect on performance enhances adaptability and minimizes reliance on incorrect data, leading to high-quality results.
Multi-Dim Tradeoff#
Multi-dimensional trade-offs in summarization refinement are critical. Simply focusing on one aspect, like faithfulness, can negatively impact others, such as completeness or conciseness. The interdependence of dimensions requires careful consideration during reasoning and refinement. For example, correcting a minor factual error by deleting an entire sentence, though enhancing faithfulness, might sacrifice crucial information, decreasing completeness. Therefore, refinement strategies must balance these competing aspects, ensuring that improvements in one dimension don’t come at the expense of others. Ignoring these trade-offs can lead to summaries that, while factually sound, are incomplete or unnecessarily verbose. This requires the creation of methods that prioritize aspects of each metric without diminishing others.
Reduce Order Bias#
Order bias can significantly impact the reliability and fairness of various processes, from machine learning model training to decision-making systems. The positioning of features or data during training can skew model behavior. In decision-making, the sequence in which options are presented influences choices, leading to suboptimal outcomes. Mitigation strategies include randomizing the order of inputs, employing ensemble methods that average results across multiple orderings, or developing algorithms that are invariant to input order. Effective order bias reduction ensures that systems are robust and yield consistent results regardless of input presentation, promoting equitable and reliable performance.
More visual insights#
More on tables
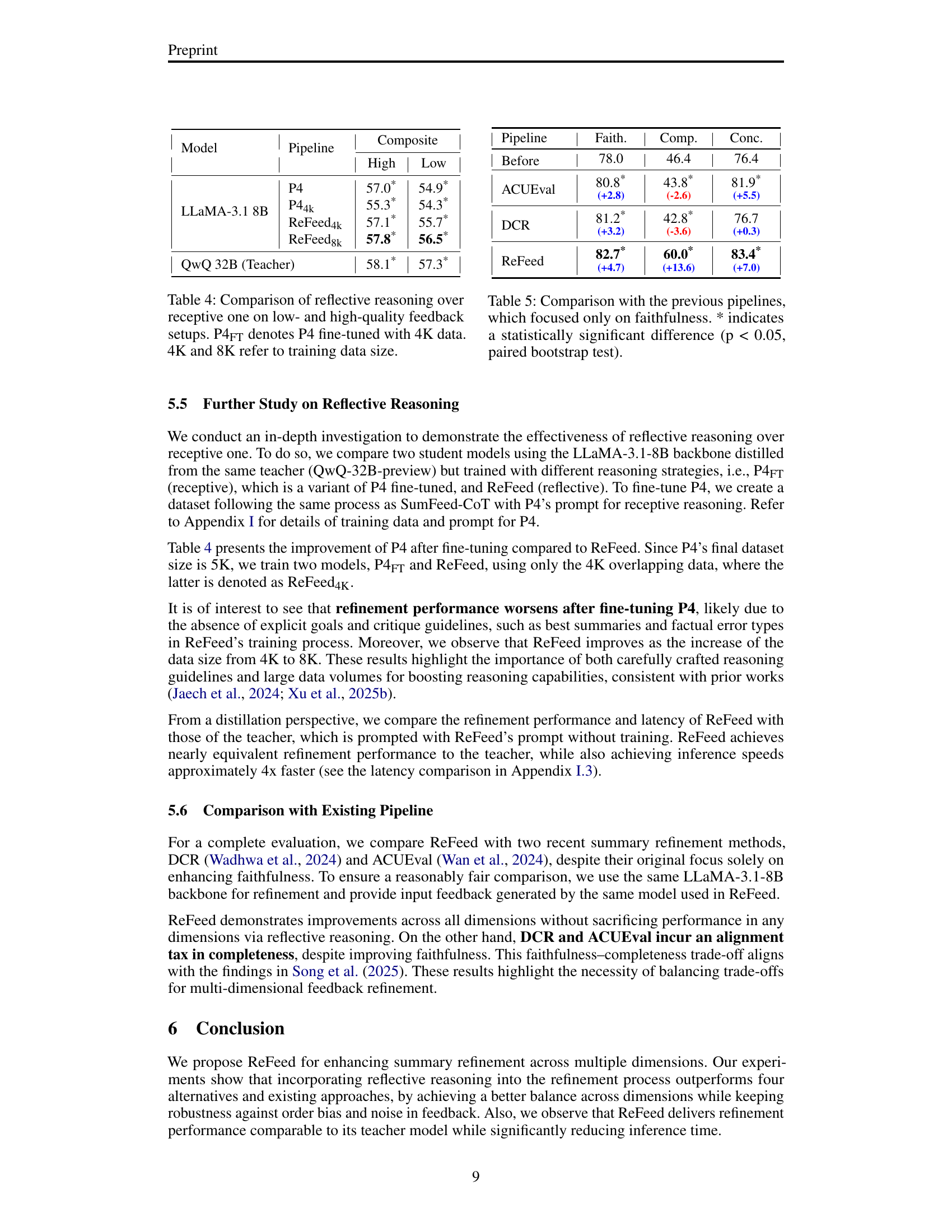
| Pipeline | Random | Last–Faith | Last–Comp | Last–Conc | Max–Min | ||||||||||
| FA | CM | CN | FA | CM | CN | FA | CM | CN | FA | CM | CN | FA | CM | CN | |
| P2 | 80.8 | 59.1 | 85.3 | 80.9 | 59.0 | 85.0 | 81.1 | 63.2 | 83.9 | 79.6 | 55.3 | 85.1 | 1.5 | 7.9 | 1.4 |
| P3 | 80.7 | 59.3 | 82.8 | 80.8 | 57.7 | 82.5 | 80.4 | 62.5 | 82.4 | 79.5 | 58.4 | 83.0 | 1.3 | 4.8 | 0.6 |
| P4 | 83.8 | 61.3 | 85.1 | 82.9 | 60.6 | 84.9 | 83.6 | 60.7 | 83.8 | 81.9 | 59.8 | 84.8 | 1.9 | 1.5 | 1.3 |
| ReFeed | 84.2 | 62.9 | 84.2 | 83.6 | 62.6 | 84.6 | 83.4 | 62.4 | 84.5 | 84.3 | 62.9 | 84.4 | 0.9 | 0.5 | 0.4 |
| ReFeed(–) | 84.2 | 61.1 | 85.2 | 83.3 | 60.1 | 84.2 | 82.7 | 60.1 | 84.5 | 83.1 | 61.6 | 84.5 | 1.5 | 1.5 | 0.7 |
🔼 This table presents the results of a multi-dimensional summarization refinement experiment. Five different refinement methods (P2, P3, P4, ReFeed, and a baseline with random feedback order) were evaluated across four different feedback order conditions: random, last-faithfulness, last-completeness, and last-conciseness. For each method and condition, the table shows the faithfulness (FA), completeness (CM), and conciseness (CN) scores of the refined summaries. The ‘Max-Min’ column represents the range between the highest and lowest scores across the four conditions for each metric. Lower values in this column indicate higher robustness of the method to different feedback orders. The best performance (lowest Max-Min score) for each metric is highlighted in bold.
read the caption
Table 2: Summary quality after refinement with multi-dimensional refinement pipelines in four shuffling setups. FA, CM, and CN denote faithfulness, completeness, and conciseness. 'Max–Min' is the score gap between the highest and lowest values for each dimension, with smaller ones indicating better robustness (the smallest value in bold).
| Pipeline | Faith. | Comp. | Conc. | |||
| High | Low | High | Low | High | Low | |
| Before. | 78.0 | 46.4 | 76.4 | |||
| P1-Faith | 82.2* | 80.7* | 47.1* | 45.9 | 79.7* | 80.4* |
| P1-Comp | 82.7* | 80.4* | 66.2* | 62.0* | 80.9* | 79.0* |
| P1-Conc | 78.9 | 76.7 | 45.5* | 44.2* | 86.9* | 86.3* |
| P4 | 83.3* | 80.1* | 60.0* | 56.0* | 84.8* | 83.6* |
| ReFeed | 84.6* | 82.7* | 62.5* | 60.0* | 84.0* | 83.4* |
🔼 This table presents the results of a study comparing the performance of different summarization refinement pipelines under varying feedback quality (low vs. high). The evaluation focuses on three dimensions of summarization quality: faithfulness, completeness, and conciseness. For each pipeline, the table displays the average scores for these three dimensions before refinement and after refinement using both low-quality and high-quality feedback. A statistically significant improvement (p<0.05) is indicated by an asterisk (*). The table helps to analyze how the quality of feedback and the choice of refinement pipeline affect the final quality of the refined summaries.
read the caption
Table 3: Summary quality of revised summaries under low- and high-quality feedback. 'Before.' indicates scores before refinement. * denotes a statistically significant difference (p < 0.05) based on a paired bootstrap test.
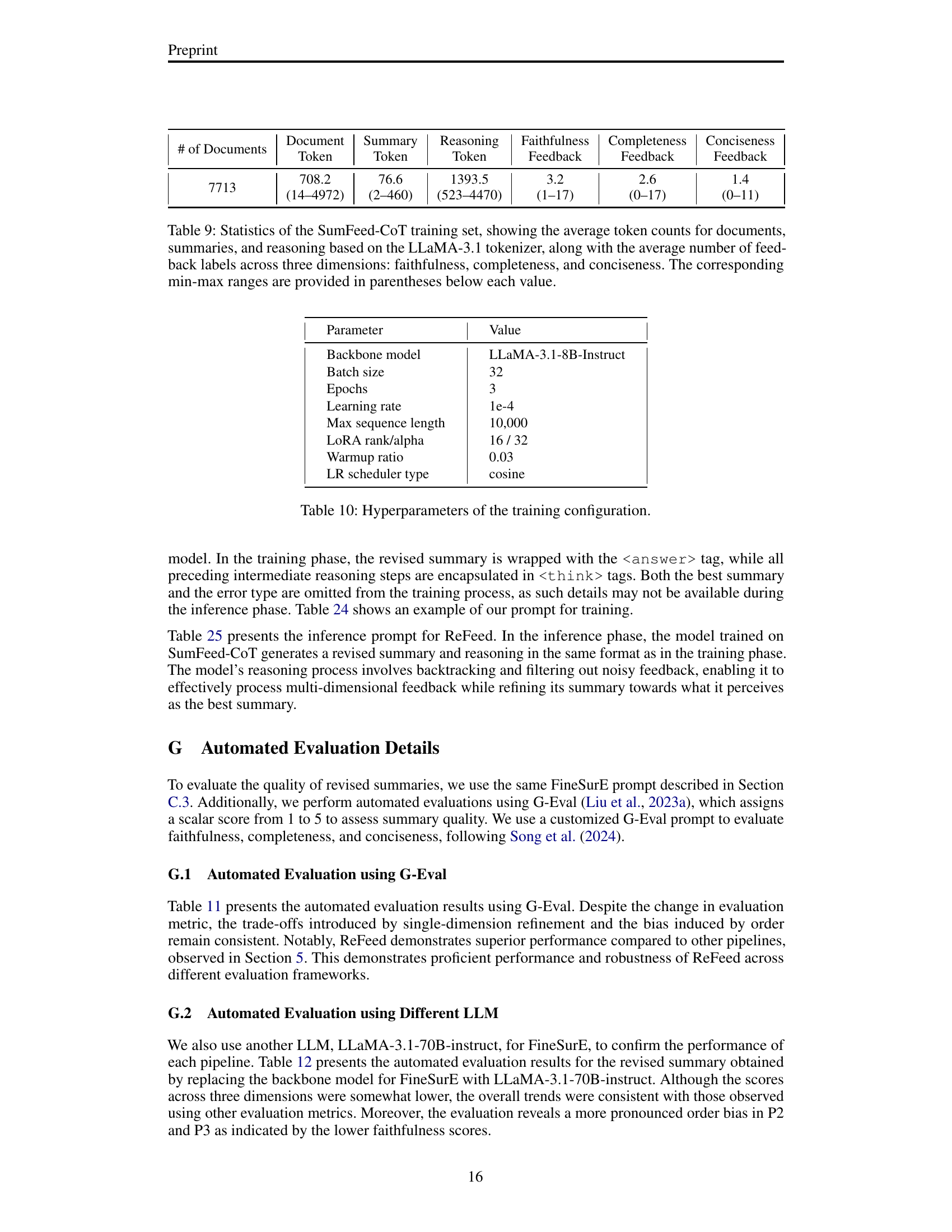
| Model | Pipeline | Composite | |
| High | Low | ||
| LLaMA-3.1 8B | P4 | 57.0* | 54.9* |
| P44k | 55.3* | 54.3* | |
| ReFeed4k | 57.1* | 55.7* | |
| ReFeed8k | 57.8* | 56.5* | |
| QwQ 32B (Teacher) | 58.1* | 57.3* | |
🔼 This table compares five different methods for refining text summaries, focusing on how each method handles multiple dimensions (faithfulness, completeness, conciseness) simultaneously. It details the approach taken by each pipeline in terms of the independence or dependence of feedback across dimensions, whether feedback is handled sequentially or simultaneously, and whether the refinement uses receptive or reflective reasoning. The table is essential for understanding the varying strategies used to address the complexities of multi-dimensional summarization refinement and how the choice of methodology influences the final output.
read the caption
Table 6: Five different pipelines for refinement on multi-dimensions.
| Pipeline | Faith. | Comp. | Conc. |
| Before | 78.0 | 46.4 | 76.4 |
| ACUEval | 80.8* | 43.8* | 81.9* |
| (+2.8) | (-2.6) | (+5.5) | |
| DCR | 81.2* | 42.8* | 76.7 |
| (+3.2) | (-3.6) | (+0.3) | |
| ReFeed | 82.7* | 60.0* | 83.4* |
| (+4.7) | (+13.6) | (+7.0) |
🔼 This table lists the specific checkpoints used for the thirteen summarization models employed in the research. For models available through open-source channels (like Hugging Face), the researchers used publicly accessible checkpoints. However, for proprietary models from companies such as OpenAI and AWS Bedrock, the researchers accessed these models via paid API services. This ensures reproducibility and clarifies the exact versions of the models used in the experiments.
read the caption
Table 7: Checkpoints of the 13 summarizers. For open-source models, we use publicly available checkpoints from Huggingface, while for proprietary models, we utilize paid API services by OpenAI and AWS Bedrock.
| Pipeline | Dim. | Feedback | Refinement | Reasoning |
| P1 | Single | Independent | Sequential | Receptive |
| P2 | Multi | Independent | Sequential | Receptive |
| P3 | Multi | Dependent | Sequential | Receptive |
| P4 | Multi | Dependent | Simultaneous | Receptive |
| ReFeed | Multi | Dependent | Simultaneous | Reflective |
🔼 This table presents the prompt used to instruct a large language model (LLM) to generate a summary. The prompt provides the input text and specifies that the output should be in JSON format, containing a single key called ‘summary’ with the generated text as its value. This standardized format is crucial for the later stages of the summarization refinement pipeline, facilitating consistent processing and analysis.
read the caption
Table 8: Prompt to generate summary
| Model Name | Checkpoints |
| Bart-large | facebook/bart-large-cnn |
| Pegasus-large | google/pegasuscnn_dailymail |
| Flan-t5-large | spacemanidol/flan-t5-large-cnndm |
| Phi-2 | microsoft/phi-2 |
| Mistral-7b-inst | mistralai/Mistral-7B-Instruct-v0.2 |
| Mixtral-8x7b-inst | mistralai/Mixtral-8x7B-Instruct-v0.1 |
| Llama2-13b-chat | meta-llama/Llama-2-13b-chat-hf |
| Mistral-nemo | mistralai/Mistral-Nemo-Instruct-2407 |
| Gemma2-27b-inst | google/gemma-2-27b-it |
| Llama3-70b | meta-llama/Meta-Llama-3-70B-Instruct |
| Claude-instant | claude-instant (AWS Bedrock) |
| GPT-3.5turbo | gpt-3.5-turbo-0125 (OpenAI) |
| GPT-4turbo | gpt-4-0125-preview (OpenAI) |
🔼 This table presents a statistical overview of the SumFeed-CoT dataset used to train the ReFeed model. It details the average number of tokens in the documents, summaries, and reasoning components of the dataset, all using the LLaMA-3.1 tokenizer. Additionally, it shows the average number of feedback labels provided for each of the three dimensions: faithfulness, completeness, and conciseness. The minimum and maximum values for each metric are also provided in parentheses for context.
read the caption
Table 9: Statistics of the SumFeed-CoT training set, showing the average token counts for documents, summaries, and reasoning based on the LLaMA-3.1 tokenizer, along with the average number of feedback labels across three dimensions: faithfulness, completeness, and conciseness. The corresponding min-max ranges are provided in parentheses below each value.
| Text: {input text} Instruction: Summarize the Text. Provide your answer in JSON format. The answer should be a dictionary with the key "summary" containing a generated summary as a string: {"summary": "your summary"} JSON Output: |
🔼 This table details the hyperparameters used during the training phase of the ReFeed model. It lists the specific values chosen for key parameters such as the base model (LLaMA-3.1-8B-Instruct), batch size, number of epochs, learning rate, maximum sequence length, LoRA rank and alpha, warmup ratio, and learning rate scheduler type. These settings are crucial in determining the model’s training process and its final performance.
read the caption
Table 10: Hyperparameters of the training configuration.
| # of Documents | Document Token | Summary Token | Reasoning Token | Faithfulness Feedback | Completeness Feedback | Conciseness Feedback |
| 7713 | 708.2 (14–4972) | 76.6 (2–460) | 1393.5 (523–4470) | 3.2 (1–17) | 2.6 (0–17) | 1.4 (0–11) |
🔼 Table 11 presents a detailed comparison of the performance of seven different summarization refinement pipelines. Each pipeline employs a unique strategy for handling multi-dimensional feedback (faithfulness, completeness, and conciseness), differing in how feedback is incorporated (sequentially or simultaneously) and whether reflective reasoning is utilized. The table shows the average scores for each dimension after refinement, using G-Eval as the evaluation metric. The best scores achieved by each pipeline are highlighted in bold. An asterisk (*) indicates that the performance improvement for a given pipeline is statistically significant compared to the original summary (p<0.05, paired bootstrap test). This table allows for a comprehensive analysis of the effectiveness of various refinement strategies in achieving improvements across all three dimensions, highlighting the tradeoffs between the different approaches and the role of reflective reasoning.
read the caption
Table 11: Summary quality of revised summaries on faithfulness, completeness, and conciseness across seven refinement pipelines based on G-Eval. The best scores are marked in bold. * denotes statistically significant difference with p < 0.05 according to a paired bootstrap test.
| Parameter | Value |
| Backbone model | LLaMA-3.1-8B-Instruct |
| Batch size | 32 |
| Epochs | 3 |
| Learning rate | 1e-4 |
| Max sequence length | 10,000 |
| LoRA rank/alpha | 16 / 32 |
| Warmup ratio | 0.03 |
| LR scheduler type | cosine |
🔼 This table presents the results of a comparative analysis of seven different summarization refinement pipelines. The pipelines are evaluated across three dimensions: faithfulness, completeness, and conciseness, using LLaMA-3.1-70B-instruct as the automated evaluator within FineSurE. The table shows the average scores for each dimension before and after refinement for each pipeline. Statistically significant improvements (p<0.05) are marked with an asterisk. The best performing pipeline in each dimension is highlighted in bold.
read the caption
Table 12: Summary quality of revised summaries on faithfulness, completeness, and conciseness across seven refinement pipelines using LLaMA-3.1-70B-instruct as the FineSurE’s automated evaluator. The best scores are marked in bold. * denotes statistically significant difference with p < 0.05 according to a paired bootstrap test.
| Pipeline | Dim. | Dep. | Simul. | Reflect. | Faith. | Comp. | Conc. | Avg. |
| Before Refine | 4.22 | 3.04 | 3.42 | 3.55 | ||||
| P1-Faith | Faith. | ✗ No | ✗ No | ✗ No | 4.33*(+0.11) | 3.03 (-0.01) | 3.46*(+0.04) | 3.60*(+0.05) |
| P1-Comp | Comp. | ✗ No | ✗ No | ✗ No | 4.44*(+0.22) | 3.69*(+0.65) | 3.59*(+0.17) | 3.90*(+0.35) |
| P1-Cons | Conc. | ✗ No | ✗ No | ✗ No | 4.42 (+0.20) | 2.97*(-0.07) | 3.66*(+0.24) | 3.68*(+0.13) |
| P2 | Multi | ✗ No | ✗ No | ✗ No | 4.46*(+0.24) | 3.28*(+0.24) | 3.67*(+0.23) | 3.80*(+0.25) |
| P3 | Multi | ✓ Yes | ✗ No | ✗ No | 4.39 (+0.17) | 3.32*(+0.28) | 3.58*(+0.16) | 3.76*(+0.21) |
| P4 | Multi | ✓ Yes | ✓ Yes | ✗ No | 4.44*(+0.22) | 3.41*(+0.37) | 3.64*(+0.22) | 3.83*(+0.28) |
| ReFeed | Multi | ✓ Yes | ✓ Yes | ✓ Yes | 4.53*(+0.29) | 3.62*(+0.58) | 3.68*(+0.26) | 3.94*(+0.39) |
🔼 This table presents the results of a human evaluation assessing the quality of revised summaries generated by seven different refinement pipelines. The evaluation focuses on three key aspects of summary quality: faithfulness (factual accuracy), completeness (inclusion of key information), and conciseness (avoidance of unnecessary details). Each pipeline’s performance is measured before and after refinement, allowing for a direct comparison of improvement across the three dimensions. The table highlights the best-performing pipeline (marked in bold) according to human judgment, providing insights into the effectiveness of various refinement strategies in enhancing the quality of summaries.
read the caption
Table 13: (Human evaluation) summary quality of revised summaries on faithfulness, completeness, and conciseness across seven refinement pipelines based on human evaluation. The best scores are marked in bold.
| Pipeline | Dim. | Dep. | Simul. | Reflect. | Faith. | Comp. | Conc. | Avg. |
| Before Refine | 75.2 | 43.4 | 74.5 | 64.4 | ||||
| P1-Faith | Faith. | ✗ No | ✗ No | ✗ No | 79.3*(+4.1) | 42.6* (-0.8) | 77.1*(+2.6) | 66.3*(+1.9) |
| P1-Comp | Comp. | ✗ No | ✗ No | ✗ No | 74.8 (-0.4) | 57.7*(+14.3) | 76.0*(+1.5) | 69.5*(+4.1) |
| P1-Cons | Conc. | ✗ No | ✗ No | ✗ No | 77.1*(+1.9) | 40.7*(-2.7) | 83.0*(+8.5) | 66.9*(+2.5) |
| P2 | Multi | ✗ No | ✗ No | ✗ No | 72.7*(-2.5) | 48.3*(+4.9) | 81.3*(+6.8) | 67.4*(+3.0) |
| P3 | Multi | ✓ Yes | ✗ No | ✗ No | 73.7* (-1.5) | 50.0*(+6.6) | 77.4*(+2.9) | 67.0*(+2.6) |
| P4 | Multi | ✓ Yes | ✓ Yes | ✗ No | 76.5 (+1.3) | 52.1*(+8.7) | 80.4*(+5.9) | 69.7*(+5.3) |
| ReFeed | Multi | ✓ Yes | ✓ Yes | ✓ Yes | 77.2*(+2.0) | 55.6*(+12.2) | 80.5*(+6.0) | 71.1*(+6.7) |
🔼 This table compares the data construction processes for two different refinement pipelines: P4 (receptive reasoning) and ReFeed (reflective reasoning). It shows the number of original reasoning attempts, the number of successfully formatted reasoning samples after filtering, the number of successfully verified samples, and the final percentage of successful refinements. Both pipelines use feedback generated by LLMs with different sizes (LLaMA-3.1-70B and LLaMA-3.1-8B) for high and low quality feedback, respectively, to highlight the impact of feedback quality. The results show that ReFeed achieves a higher success rate in obtaining successfully refined summaries compared to P4, likely due to the differences in their reasoning strategies.
read the caption
Table 14: Comparison of the data construction process between P4 and ReFeed. The two feedback generation models use checkpoints obtained through instruction tuning.
| Pipeline | Dim. | Dep. | Simul. | Reflect. | Faith. | Comp. | Conc. | Avg. |
| Before Refine | 77.4 | 42.8 | 80.6 | 66.9 | ||||
| P2 | Multi | ✗ No | ✗ No | ✗ No | 77.3 (-0.1) | 45.8 (+3.0) | 84.5 (+3.9) | 69.2 (+2.3) |
| P3 | Multi | ✓ Yes | ✗ No | ✗ No | 77.8 (+0.4) | 50.8 (+2.8) | 79.3 (+2.4) | 69.3 (+2.4) |
| P4 | Multi | ✓ Yes | ✓ Yes | ✗ No | 84.5 (+7.1) | 52.0 (+9.2) | 81.1 (+0.5) | 72.5 (+5.3) |
| ReFeed | Multi | ✓ Yes | ✓ Yes | ✓ Yes | 87.3 (+9.9) | 54.2 (+11.4) | 88.7 (+8.1) | 76.7 (+9.8) |
🔼 This table compares the performance of ReFeed (reflective reasoning) against P4 (receptive reasoning), both fine-tuned with different data sizes (4K and 8K). It shows the composite scores and inference time (with a batch size of 1 on two NVIDIA L40S GPUs) for each model under low- and high-quality feedback. The results illustrate the impact of reflective reasoning on performance and efficiency, highlighting ReFeed’s ability to maintain accuracy with significantly reduced inference time compared to the teacher model.
read the caption
Table 15: Comparison of reflective reasoning over receptive reasoning on low- and high-quality feedback setups as . P4FT indicates P4 fine-tuned with 4K data. 4K and 8K refer to training data size. For inference time, we use a batch size of 1 on two NVIDIA L40S GPUs.
| Pipeline | Reasoning Strategies | Feedback | Original Data | Reasoning Format Filtering | Verification- based Filtering | Ratio of Successful Refinement |
| P4 | Receptive | LLaMA 3.1-70B (High) | 14,505 | 7,382 | 2,806 | 38.01% |
| LLaMA 3.1-8B (Low) | 14,496 | 7,860 | 2,510 | 31.93% | ||
| ReFeed | Reflective | LLaMA 3.1-70B (High) | 14,505 | 9,179 | 3,922 | 42.73% |
| LLaMA 3.1-8B (Low) | 14,496 | 9,066 | 3,791 | 41.82% |
🔼 Table 16 presents the prompts used in pipelines P1 and P2 for multi-dimensional summarization refinement. Pipeline P1 addresses each dimension (faithfulness, completeness, conciseness) sequentially using a separate prompt for each. Pipeline P2 also handles dimensions sequentially but iteratively. Each prompt in P2 incorporates the refined summary from the previous step as input, allowing for refinement based on prior adjustments. Both prompts include a specific reasoning instruction for the current dimension being addressed.
read the caption
Table 16: Prompt for P1 and P2. For P1, a prompt is sent once for a single target dimension, whereas in P2, a prompt is sent three times for each target dimension. In P2, 'Summary' in inputs can be revised summary in previous step. The prompt includes a single reasoning instruction specific to the target dimension among the three dimensions.
| Model | Pipeline | Composite | Inference Time | |
| High | Low | |||
| L3.1 8B | P44k | 55.3* | 54.3* | 54.5s |
| ReFeed4k | 57.1* | 55.7* | 53.9s | |
| ReFeed8k | 57.8* | 56.5* | 40.0s | |
| QwQ 32B (Teacher) | 58.1* | 57.3* | 196.6s | |
🔼 Table 17 shows the prompt used in the P3 pipeline of the ReFeed model for multi-dimensional summarization refinement. The prompt is a multi-turn prompt. In the first turn, the model receives instructions for reasoning across all three dimensions (faithfulness, completeness, conciseness) along with the document, summary, and feedback. Subsequent turns only provide new feedback, allowing the model to iteratively refine the summary based on the accumulated feedback.
read the caption
Table 17: Prompt for P3. In Turn 1, instruction for reasoning on three dimensions are provided. From the next turn, only feedback is given.
| Instruction for reasoning |
| - Faithfulness: reason about factual inconsistencies in the summary sentence. |
| - Completeness: reason about why the summary is each missing key content. |
| - Conciseness: reason about why the summary does not contain key content and contains unnecessary details. |
| User Prompt |
| Your task is to reason about the provided feedback and to refine the summary based on the provided feedback. |
| Instruction: |
| 1. Give reasons about the provided feedback by considering the relevant dimension and provide a suggested fix to the summary: |
| {Instruction for reasoning on the target dimension (single)} |
| 2. Revise the summary by incorporating the feedback. |
| 3. Provide your response in the following format: |
| ‘‘‘ |
| Feedback Reasoning: |
| [Your reasoning on feedback and suggested fix] |
| Revised Summary: |
| [Your revised summary] |
| “‘ |
| Document: |
| {Document} |
| Summary: |
| {Summary} |
| Feedback: |
| {Feedback} |
🔼 Table 18 shows the prompt used in pipeline P4 for multi-dimensional summarization refinement. Unlike previous pipelines, P4 provides all reasoning instructions simultaneously in a single prompt. The order of the instructions in the prompt exactly matches the order of the dimensions (faithfulness, completeness, conciseness) presented in the feedback. This design choice aims to prevent any bias that could result from presenting feedback in a specific order.
read the caption
Table 18: Prompt of P4. The prompt includes all reasoning instructions, with their order aligned to the sequence of dimensions in the feedback.
| Instruction for Reasoning |
| - Faithfulness: reason about factual inconsistencies in the summary sentence. |
| - Completeness: reason about why the summary is each missing key content. |
| - Conciseness: reason about why the summary does not contain key content and contains unnecessary details. |
| User Prompt (Turn 1) |
| Your task is to reason about the provided feedback and to refine the summary based on the provided feedback. Instruction: |
| 1. Give reasons about the provided feedback by considering the relevant dimension and provide a suggested fix to the summary: |
| {Instruction for reasoning on the dimension A} |
| {Instruction for reasoning on the dimension B} |
| {Instruction for reasoning on the dimension C} |
| 2. Revise the summary by incorporating the feedback. |
| 3. Provide your response in the following format: |
| ‘‘‘ |
| Feedback Reasoning: |
| [Your reasoning on feedback and suggested fix] |
| Revised Summary: |
| [Your revised summary] |
| ‘‘‘ |
| Document: |
| {Document} |
| Summary: |
| {Summary} |
| Feedback: |
| {Feedback on the dimension A} |
| User Prompt (Turn N) |
| Refine your refined summary again based on the provided feedback. Critique and Refine again based on the provided feedback. |
| Feedback: |
| {Feedback on Nth dimension} |
🔼 Table 19 details the prompts used in the Detection, Critique, and Refinement (DCR) pipeline. This multi-stage approach first uses a detection module to identify areas needing correction within a summary. A separate reasoning module then analyzes these identified issues and generates a critique, explaining the problems. Finally, the critique generated by the reasoning module serves as feedback for a refinement module, which produces the final, improved summary. This table highlights the separation of reasoning and refinement steps in the DCR method, showing how the output of one stage becomes the input of the next.
read the caption
Table 19: Prompt of DCR. This pipeline separates the reasoning and refinement modules. First, the reasoning module generates a critique based on detected labels. Then, the output from the reasoning module is used as the feedback input for the refinement model.
| Instruction for Reasoning |
| - Faithfulness: reason about factual inconsistencies in the summary sentence. |
| - Completeness: reason about why the summary is each missing key content. |
| - Conciseness: reason about why the summary does not contain key content and contains unnecessary details. |
| User Prompt |
| Your task is to reason about the provided feedback and to refine the summary based on the provided feedback. Instruction: |
| 1. Give reasons about the provided feedback by considering the relevant dimension and provide a suggested fix to the summary: |
| {Instruction for reasoning on dimension A} |
| {Instruction for reasoning on dimension B} |
| {Instruction for reasoning on dimension C} |
| 2. Revise the summary by incorporating the feedback. |
| 3. Provide your response in the following format: |
| ‘‘‘ |
| Feedback Reasoning: |
| [Your reasoning on feedback and suggested fix] |
| Revised Summary: |
| [Your revised summary] |
| ‘‘‘ |
| Document: |
| {Document} |
| Summary: |
| {Summary} |
| Feedback: |
| {Feedback on dimension A} |
| {Feedback on dimension B} |
| {Feedback on dimension C} |
🔼 Table 20 presents the prompt used in the ACUEval pipeline for text refinement. ACUEval differs from other methods in that it uses detection labels at the atomic fact level, identifying individual factual errors rather than labeling entire sentences. This table shows that the prompt is structured to provide the model with a document, a summary, and feedback highlighting specific incorrect atomic facts. The refinement prompt is tailored to ensure compatibility with other refinement pipelines described in the paper, allowing for a fair comparison of various refinement techniques.
read the caption
Table 20: Prompt for ACUEval. ACUEval uses detection labels at the atomic fact level. We follow the detection prompt from Wan et al. (2024) and adjust the refinement prompt to ensure compatibility with other pipelines.
| User Prompt (Reasoning Model) |
| I summarized the following document: |
| {Document} |
| Summary of the above document: |
| {Summary} |
| Reason about the factually inconsistent span in the sentence. A span is factually inconsistent if it cannot be substantiated by the document. Give reasons for the factual inconsistency, point to the error span by stating “The error span: <span from sentence> and end your answer with a suggested fix to the summary. |
| User Prompt (Refinement Model) |
| Your task is to refine the summary based on the provided feedback. |
| Instruction: |
| 1. Revise the summary by incorporating the feedback. |
| 2. Provide your response in the following format: |
| ‘‘‘ |
| Revised Summary: |
| [Your revised summary] |
| ‘‘‘ |
| Document: |
| {Document} |
| Summary: |
| {Summary} |
| Feedback: |
| {Feedback} |
🔼 This table details the prompt used in the FineSurE model for fact-checking tasks. The prompt instructs the model to compare a given summary against its source document and classify the factuality of each summary sentence across nine specific error categories (no error, out-of-context error, entity error, predicate error, circumstantial error, grammatical error, coreference error, linking error, and other error). The model’s response should be in JSON format, providing for each sentence: the sentence itself, the reason for the error classification, and the error category.
read the caption
Table 21: Prompt of the FineSurE for fact-checking tasks.
| User Prompt |
| Your task is to refine the summary based on the provided feedback. |
| Instruction: |
| 1. Revise the summary by incorporating the feedback. |
| 2. Provide your response in the following format: |
| ‘‘‘ |
| Revised Summary: |
| [Your revised summary] |
| ‘‘‘ |
| Document: |
| {Document} |
| Summary: |
| {Summary} |
| Feedback: |
| The summary is not consistent with the source text. The source text does not mention the following facts: |
| {Incorrect Atomic Fact 1} |
| {Incorrect Atomic Fact 2} |
| … |
| {Incorrect Atomic Fact N} |
| The summary should not include information that is not present in the article. Please check the document for the correct information and make appropriate edits. |
🔼 This table presents the prompts used in FineSurE, a tool for evaluating the quality of summaries. It details the instructions given to the language model for two separate tasks: key fact extraction and key fact alignment. The key fact extraction task involves breaking down a summary into a set of concise, factual statements (key facts), while the key fact alignment task assesses whether each key fact can be found in the original summary. The prompts provide specific guidance on the desired level of granularity and the expected format of the output (JSON).
read the caption
Table 22: Prompt of the FineSurE for key fact extraction and key fact alignment tasks.
| Fact Check | You will receive a document followed by a corresponding summary. Your task is to assess the factuality of each summary sentence across nine categories: * no error: the statement aligns explicitly with the content of the document and is factually consistent with it. * out-of-context error: the statement contains information not present in the document. * entity error: the primary arguments (or their attributes) of the predicate are wrong. * predicate error: the predicate in the summary statement is inconsistent with the document. * circumstantial error: the additional information (like location or time) specifying the circumstance around a predicate is wrong. * grammatical error: the grammar of the sentence is so wrong that it becomes meaningless. * coreference error: a pronoun or reference with wrong or non-existing antecedent. * linking error: error in how multiple statements are linked together in the discourse (for example temporal ordering or causal link). * other error: the statement contains any factuality error which is not defined here. Instruction: First, compare each summary sentence with the document. Second, provide a single sentence explaining which factuality error the sentence has. Third, answer the classified error category for each sentence in the summary. Provide your answer in JSON format. The answer should be a list of dictionaries whose keys are "sentence", "reason", and "category": ["sentence": "first sentence", "reason": "your reason", "category": "no error", "sentence": "second sentence", "reason": "your reason", "category": "out-of-context error", "sentence": "third sentence", "reason": "your reason", "category": "entity error",] Document: {document} Summary with of sentences sentences: {sentences} JSON Output: |
🔼 This table presents the prompt used to generate reasoning data for the ReFeed model within the SumFeed-CoT dataset. The prompt guides a large language model (LLM) through a reflective reasoning process to analyze multi-dimensional feedback (faithfulness, completeness, conciseness) and generate refined summaries. It includes detailed instructions for the LLM, focusing on careful consideration of feedback validity, trade-offs between dimensions, and iterative refinement to ensure high-quality outputs.
read the caption
Table 23: Reflective reasoning prompt for generating reasoning data in SumFeed-CoT (ReFeed)
| Key Fact Extraction | You will be provided with a transcript. Your task is to decompose the summary into a set of "key facts".
A "key fact" is a single fact written as briefly and clearly as possible, encompassing at most 2-3 entities.
Here are nine examples of key facts to illustrate the desired level of granularity:
* Kevin Carr set off on his journey from Haytor.
* Kevin Carr set off on his journey from Dartmoor.
* Kevin Carr set off on his journey in July 2013.
* Kevin Carr is less than 24 hours away from completing his trip.
* Kevin Carr ran around the world unsupported.
* Kevin Carr ran with his tent.
* Kevin Carr is set to break the previous record.
* Kevin Carr is set to break the record by 24 hours.
Instruction:
First, read the summary carefully.
Second, decompose the summary into (at most 16) key facts.
Provide your answer in JSON format. The answer should be a dictionary with the key "key facts" containing the key facts as a list:
{"key facts": ["first key fact", "second key facts", "third key facts"]}
Summary: {summary} JSON Output: |
| Key Fact Alignment | You will receive a summary and a set of key facts for the same document. Your task is to assess if each key fact is inferred from the summary. Instruction: First, compare each key fact with the summary. Second, check if the key fact is inferred from the summary and then response "Yes" or "No" for each key fact. If "Yes", specify the line number(s) of the summary sentence(s) relevant to each key fact. Provide your answer in JSON format. The answer should be a list of dictionaries whose keys are "key fact", "response", and "line number": ["key fact": "first key fact", "response": "Yes", "line number": [1], "key fact": "second key fact", "response": "No", "line number": [], "key fact": "third key fact", "response": "Yes", "line number": [1, 2, 3]] Summary: {summary} of key facts key facts: {key facts} JSON Output: |
🔼 This table displays an example of the input and output used to train the LLaMA-3.1-8b-Instruct model. The input consists of a system prompt that instructs the model to reason thoroughly, a user prompt that provides a document, summary, and feedback, and instructions for refining the summary. The output shows the model’s reasoning process (Think section) and the revised summary (Answer section). This example illustrates how the model processes multi-dimensional feedback (faithfulness, completeness, and conciseness) and refines the summary accordingly.
read the caption
Table 24: An example of an input (system prompt and user prompt) and its corresponding reasoning and revised summary (assistant prompt) used to train LLaMA-3.1-8b-instruct.
| Instruction for Reasoning |
| - Faithfulness: Does this feedback accurately identify summary sentences? |
| Out-of-article Error: Facts, new information or subjective opinions not found or verifiable by the document. |
| Entity Error: Incorrect or misreferenced details about key entities such as names, dates, locations, numbers, pronouns, and events in the summary. |
| Relation Error: Misrepresented relationships, such as incorrect use of verbs, prepositions, and adjectives. |
| Sentence Error: the entire sentence entirely contradicts the information in the document. |
| - Completeness: Does this feedback correctly identify missing key content in the summary? |
| - Conciseness: Does the feedback correctly identify sentences that include unnecessary details and lack key content? |
| User Prompt |
| Your goal is to deliberate on the provided feedback and propose actionable and specific aggregated feedback based on it. Provide your response in the following format: |
| “‘ |
| *Final Reviesed Summary**: |
| \\[ \\boxed{\\text{Your revised summary}}\] |
| “‘ Instruction: |
| 1. Deliberate on the characteristics an ideal summary should achieve. |
| 2. Assess and choose the validity of the given feedback in improving the summary considering feedback quality criteria: |
| {Instruction for reasoning on dimension A} |
| {Instruction for reasoning on dimension B} |
| {Instruction for reasoning on dimension C} |
| 3. Aggregate the valid feedback and Revise summary by incorporating it. |
| 4. Carefully check whether each feedback and suggestion compromise other quality dimensions. Backtrack your reasoning If you need to. |
| Document: |
| {Document} |
| Summary: |
| {Summary} |
| Ideal Summary: |
| {Best Summary} |
| Feedback: |
| {Feedback on dimension A} |
| {Feedback on dimension B} |
| {Feedback on dimension C} |
🔼 This table displays the prompt used during the inference stage of the ReFeed model. The prompt is designed to guide the model through a multi-dimensional refinement process, focusing on faithfulness, completeness, and conciseness. Crucially, it incorporates reflective reasoning, prompting the model to critically analyze the provided feedback and validate its accuracy before incorporating it into the refinement process. The order of dimensions in the feedback is carefully considered and aligns with the structure of the prompt, ensuring that the model processes the feedback in a structured and logical manner.
read the caption
Table 25: Prompt of ReFeed for inference. The prompt includes all reasoning instructions, tailored for reflective reasoning to validate noisy feedback, with their order aligned to the sequence of dimensions in the feedback.
| System | <|begin_of_text|><|start_header_id|>system<|end_header_id|> Your role as an assistant involves thoroughly exploring questions through a systematic long thinking process before providing the final precise and accurate solutions…<|eot_id|> |
| Input (User) | <|start_header_id|>user<|end_header_id|> Your goal is to deliberate on the provided feedback and propose actionable and specific aggregated feedback based on it. Instructions: 1. Deliberate on the characteristics an ideal summary should achieve. 2. Assess and choose the validity of the given feedback in improving the summary considering feedback quality criteria: - Conciseness: Does the feedback correctly identify sentences that include unnecessary details and lack key content? - Faithfulness: Does this feedback accurately identify summary sentences that align with one of the following four factual inconsistencies types?: - Completeness: Does this feedback correctly identify missing key content in the summary? 3. Aggregate the valid feedback and Revise summary by incorporating it. if no revision is needed, just answer "no revision needed". 4. Carefully check whether each feedback and suggestion compromise other quality dimensions. Backtrack your reasoning If you need to. Document: Person1: Good Morning. What can I do for you? \n’ Person2: Good Morning, I have a bad cough, and I want to see an internist. \n’ Person1: Do you have a registration card? \n’ Person2: No, I don’t. I’m a tourist. \n’ Person1: Then you need to register as a new patient. Can I have a look at you ID card? I need your name, age, occupation, address and contacting number. \n’ Person2: Here you are. \n’ Person1: Thanks. Which kind of medicine do you prefer, western medicine or traditional Chinese medicine? \n’ Person2: I’d like to try traditional Chinese medicine. I heard it really works quite well if you know what you’re doing. \n’ Person1: All right. Yes, he does. The registration fee is 7 yuan, please. Summary: A tourist asks to see an internist because he has a bad cough. The doctor asks for his name, age, occupation, address and contacting number. The tourist says he would like to try traditional Chinese medicine. The internist agrees to see him for a fee of 7 yuan. Feedback: ***Conciseness Feedback*** These summary sentences do not contain key content: Sentence 2: The doctor asks for his name, age, occupation, address and contacting number. Sentence 4: The internist agrees to see him for a fee of 7 yuan. ***Faithfulness Feedback*** These summary sentences are factually inconsistent with the Document: - Sentence 4: The internist agrees to see him for a fee of 7 yuan. ***Completeness Feedback*** These key contents are missing in the summary: Missing key content 1: The registration fee is 7 yuan. <|eot_id|> |
| Output (Assistant) | <|begin_of_text|><|start_header_id|>assistant<|end_header_id|> <think> Alright, I have this task to review a summary based on a given document and some feedback. I need to make sure the summary is accurate, complete, and concise. Let’s break this down step by step. First, I need to understand what an ideal summary should look like. A good summary should capture the main points of the document without including unnecessary details…. …. Now, let’s look at the feedback provided: Faithfulness Feedback: - Sentence 4: "The internist agrees to see him for a fee of 7 yuan." This feedback suggests that this sentence is factually inconsistent with the document. I need to check the document to see if this is accurate. In the document: - Person1 (likely a staff member) says, "The registration fee is 7 yuan, please." There’s no explicit statement that the internist agrees to see him for that fee. The fee seems to be for registration, not directly for the internist’s service…. … Let me try to revise the summary based on this analysis. First, clarify the roles: It’s likely that Person1 is a receptionist or a staff member, not the internist. The internist is probably the doctor the tourist wants to see…. … </think> <answer> **Final Revised Summary:** \[\boxed{\text{A tourist visits a medical facility with a bad cough and requests to see an internist. Since he doesn’t have a registration card, he needs to register as a new patient. The staff member asks for his ID card to record his name, age, occupation, address, and contact number. The tourist expresses a preference for traditional Chinese medicine, and the staff informs him that the registration fee is 7 yuan.}} \] </answer> <|eot_id|> |
🔼 This table displays the prompt used to generate reasoning data for the P4 pipeline, which utilizes receptive reasoning. The prompt guides the language model to refine a summary based on provided feedback across three dimensions: faithfulness, completeness, and conciseness. It directs the model to give reasons for the feedback, considering each dimension separately, and then revise the summary according to these reasons.
read the caption
Table 26: Prompt for generating reasoning data through receptive reasoning (P4)
| Instruction for Reasoning |
| - Faithfulness: Does this feedback accurately identify summary sentences? |
| - Completeness: Does this feedback correctly identify missing key content in the summary? |
| - Conciseness: Does the feedback correctly identify sentences that include unnecessary details and lack key content? |
| System Prompt |
| Your role as an assistant involves thoroughly exploring questions through a systematic long thinking process before providing the final precise and accurate solutions. This requires engaging in a comprehensive cycle of analysis, summarizing, exploration, reassessment, reflection, backtracing, and iteration to develop well-considered thinking process. Please structure your response into two main sections: Think and Answer. In the Think section, detail your reasoning process using the specified format: <think> {thought with steps separated with ’\n \n’} </think> Each step should include detailed considerations such as analyzing questions, summarizing relevant findings, brainstorming new ideas, verifying the accuracy of the current steps, refining any errors, and revisiting previous steps. In the Answer section, based on various attempts, explorations, and reflections from the Think section, systematically present the final solution that you deem correct. The solution should remain a logical, accurate, concise expression style and detail necessary step needed to reach the conclusion, formatted as follows: <answer> {final formatted, precise, and clear solution} </answer> Now, try to solve the following question through the above guidelines: |
| User Prompt |
| Your goal is to deliberate on the provided feedback and propose actionable and specific aggregated feedback based on it. Instruction: |
| 1. Deliberate on the characteristics an ideal summary should achieve. |
| 2. Assess and choose the validity of the given feedback in improving the summary considering feedback quality criteria: |
| {Instruction for reasoning on dimension A} |
| {Instruction for reasoning on dimension B} |
| {Instruction for reasoning on dimension C} |
| 3. Aggregate the valid feedback and Revise summary by incorporating it. |
| 4. Carefully check whether each feedback and suggestion compromise other quality dimensions. Backtrack your reasoning If you need to. |
| Document: |
| {Document} |
| Summary: |
| {Summary} |
| Feedback: |
| {Feedback on dimension A} |
| {Feedback on dimension B} |
| {Feedback on dimension C} |
🔼 This table illustrates an example of the summarization refinement process using the receptive reasoning approach (P4). It showcases the original summary, the ground truth feedback (manual evaluation), the machine-generated feedback, and the scores (using FineSurE) for the original summary. The table also presents the revised summary generated using P4 and its corresponding scores. The use of red highlights the instances where the feedback was incorrect or the reasoning flawed, demonstrating the limitations of the receptive reasoning approach and its susceptibility to errors.
read the caption
Table 27: An example of refinement through receptive reasoning (P4). Red indicates incorrect feedback or flawed reasoning.
| Instruction for Reasoning |
| - Faithfulness: reason about factual inconsistencies in the summary sentence. |
| - Completeness: reason about why the summary is each missing key content. |
| - Conciseness: reason about why the summary does not contain key content and contains unnecessary details. |
| User Prompt |
| Your task is to reason about the provided feedback and to refine the summary based on the provided feedback. |
| Provide your response in the following format: |
| “‘ |
| *Final Reviesed Summary**: |
| \\[ \\boxed{\\text{Your revised summary}}\] |
| “‘ Instruction: |
| 1. Give reasons about the provided feedback by considering the relevant dimension and provide a suggested fix to the summary: |
| {Instruction for reasoning on dimension A} |
| {Instruction for reasoning on dimension B} |
| {Instruction for reasoning on dimension C} |
| 2. Revise the summary by incorporating the feedback. |
| Document: |
| {Document} |
| Summary: |
| {Summary} |
| Feedback: |
| {Feedback on dimension A} |
| {Feedback on dimension B} |
| {Feedback on dimension C} |
🔼 This table showcases a comparison between the Receptive Reasoning (P4) and Reflective Reasoning (ReFeed) approaches in refining a summary. It uses a specific example to illustrate how ReFeed addresses challenges by employing a process that involves verifying and filtering out inaccurate feedback. The table highlights the initial summary and its evaluation scores (faithfulness, completeness, conciseness). It then contrasts this with the output generated by the P4 method and its evaluation scores, showing how it’s susceptible to errors arising from flawed feedback. Finally, it presents the refined summary produced by ReFeed and its improved scores, demonstrating the effectiveness of this approach in correcting flaws and improving the quality of the summary.
read the caption
Table 28: An example of refinement through reflective reasoning (ReFeed). The original summary and summary scores are identical in Table 27. Red indicates incorrect feedback or flawed reasoning, while Blue highlights the proper validation of feedback, ensuring that only incorrect feedback is filtered out.
Full paper#