TL;DR#
Large Reasoning Models (LRMs) enhance performance via Chain-of-Thought reasoning but produce excessively long, redundant reasoning traces, causing inefficiency in training, inference and deployment. This survey offers a comprehensive overview of recent efforts for improving reasoning efficiency in LRMs. It identifies common patterns of inefficiency, examines methods across the LRM lifecycle (pretraining to inference) while focusing on unique challenges.
The survey categorizes recent developments in efficient reasoning, aligned with stages in the LLM lifecycle. This involves analyzing inefficiency patterns, methods for inference-time efficiency, Supervised Fine-tuning techniques, Reinforcement Learning strategies and model structures enhancing efficiency. It further highlights new research directions aiming to address limitations in each stage, offering strategies to refine future models and support development in efficient, scalable LRMs.
Key Takeaways#
Why does it matter?#
This survey provides a structured analysis of efficient reasoning techniques in LRMs, a crucial area for scaling AI. It offers insights to optimize LRM efficiency, fostering innovation and addressing deployment bottlenecks for more practical AI applications.
Visual Insights#
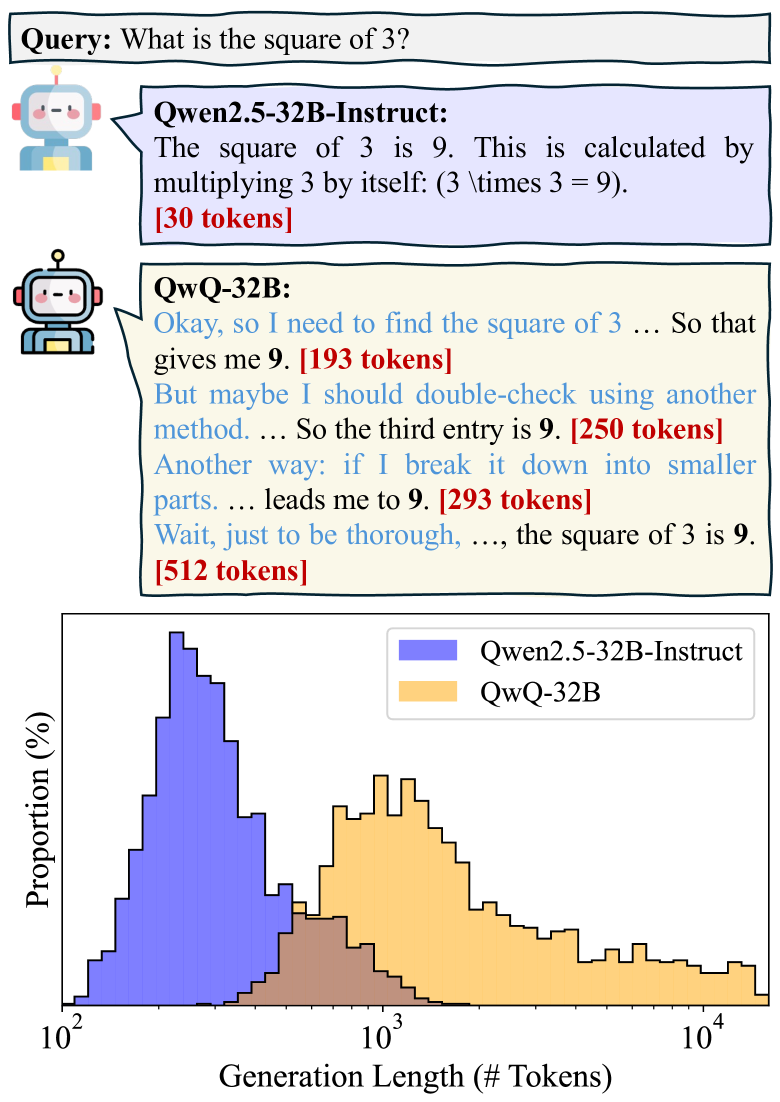
🔼 Figure 1 demonstrates the inefficiency of Large Reasoning Models (LRMs) compared to instruction-tuned LLMs. The top panel shows a simple math problem where the LRM QwQ-32B generates an excessively long response (1248 tokens), while the instruction-tuned LLM Qwen2.5-32B-Instruct provides a concise answer (30 tokens). The bottom panel presents histograms illustrating the distribution of generated token lengths for both models across a more extensive set of math problems from three benchmark datasets (GSM8K, MATH-500, and AIME 2024). The significant difference in token length highlights the inefficiency of the LRM, underscoring the paper’s focus on improving reasoning efficiency.
read the caption
Figure 1: Top: To answer the elementary school-level math problem, LRM (QwQ-32B) consumes altogether 1248 tokens, while the instruct LLM counterpart (Qwen2.5-32B-Instruct) only needs 30 tokens. Bottom: The distribution of generation length of two models on a mixed set of math problems sourced from GSM8K, MATH-500, and AIME 2024.
| User Query: A robe takes 2 bolts of blue fiber and half that much white fiber. How many bolts in total does it take? | ||||||||||||||||||||
|
🔼 Table 1 presents an example of reasoning inefficiency in Large Reasoning Models (LRMs). It displays the response of the QwQ-32B LRM to a simple math problem. The LRM’s response is excessively long, filled with redundant phrases and repetitive lines of reasoning, highlighted in red and blue respectively, demonstrating inefficiency in solving the problem. This illustrates how LRMs can overthink and produce lengthy output even for elementary tasks.
read the caption
Table 1: The answer produced by the recent LRM QwQ-32B for a math question. The model generates redundant content (highlighted in red), including repetitive phrasing. Additionally, it goes through multiple rounds of reasoning (explained in blue for clarity), which further undermines reasoning efficiency on such a straightforward problem.
In-depth insights#
LRM Inefficiency#
LRM inefficiency stems from several key issues. Redundant content generation is a major problem, where models produce verbose explanations without significantly advancing the reasoning process. This is exacerbated by the overthinking of simple questions, where LRMs allocate excessive computational resources to trivial tasks. Incoherent and suboptimal reasoning further contributes to inefficiency, with models prematurely switching reasoning directions and failing to explore promising paths. These patterns are often due to a lack of explicit optimization for minimizing intermediate reasoning tokens. Quantifying reasoning utility remains a significant challenge, as it’s difficult to evaluate the contribution of each step in a chain. Controlling thinking length is another open frontier, requiring models to “think just enough” without being too shallow or too deep. Finally, architectural bottlenecks, particularly the quadratic complexity of the Transformer architecture, limit scalability for long reasoning traces. Overall, there are a host of LRM inefficiency issues related to managing LRM’s token usage.
Inference Tactics#
Inference tactics in large reasoning models (LRMs) aim to enhance efficiency and accuracy. Key strategies include length budgeting to limit verbosity, system switching between fast and deliberate reasoning, model switching to allocate tasks to optimal models, and parallel search to generate and prune candidate outputs. Despite their effectiveness, challenges remain in precisely eliminating redundant elements and integrating model features into length control. Balancing search depth and width is crucial for reducing inference latency. Further research is needed to improve evaluation metrics, explore new model architectures, and refine the balance between reasoning conciseness and answer correctness. Overall, inference tactics play a crucial role in optimizing resource utilization and achieving high-quality reasoning in LRMs.
SFT Compression#
SFT Compression, within the context of efficient reasoning for Large Reasoning Models (LRMs), likely refers to techniques aimed at reducing the length and complexity of reasoning chains during Supervised Fine-Tuning (SFT). The goal is to distill more concise and efficient reasoning strategies into the LRM without sacrificing accuracy, which leads to less computing resources used. This may involve training with datasets containing shorter, more direct reasoning paths, or employing methods that encourage the model to skip redundant or irrelevant steps. Key considerations include balancing conciseness with answer correctness and ensuring that the compressed reasoning chains are still faithful to the underlying logic. This is a crucial area as long reasoning chains contribute significantly to the computational overhead of LRMs and may not be effective.
Efficient Reward#
While the paper doesn’t have a direct heading ‘Efficient Reward,’ many sections touch upon optimizing rewards for reasoning. Reinforcement Learning (RL) is a key area where reward shaping plays a vital role in training Large Reasoning Models (LRMs). Efficient reasoning requires carefully designed reward functions that balance accuracy and conciseness. Simply rewarding correct answers might not suffice; penalties for excessive length or unnecessary steps are crucial. The challenge lies in aligning the reward with desired reasoning behavior, avoiding ’length hacking’ where models exploit the reward structure without genuine problem-solving. Further exploration might be on inherent models features and adapting them when problem looks ’trivial’. The ultimate goal is to incentivize efficient exploration of reasoning paths, guiding the model towards optimal solutions with minimal computational cost. Ultimately designing and finding more comprehensive benchmarks and diverse dataset are more valuable.
Future Scales#
While “Future Scales” isn’t explicitly a heading in the provided paper, the idea of scaling future reasoning models (LRMs) is heavily implied within the “Future Directions” section. A critical point is the need to balance increased model size and reasoning chain length with efficiency. Scaling shouldn’t simply mean more parameters or longer CoTs. The challenge lies in developing models that can intelligently allocate computational resources, using them judiciously only where complexity demands it. Addressing the architectural bottlenecks of transformers is crucial, exploring subquadratic attention mechanisms to handle longer reasoning contexts without prohibitive computational costs. Crucially, scaling must consider multi-modality, developing reasoning models that can effectively integrate diverse inputs (text, image, video) is crucial. Evaluating and benchmarking efficient reasoning at scale, going beyond simple metrics to assess creativity and trustworthiness, is a must. The question of scaling efficiently relates to the model’s ability to generalize, avoid overthinking, and maintain safety.
More visual insights#
More on figures
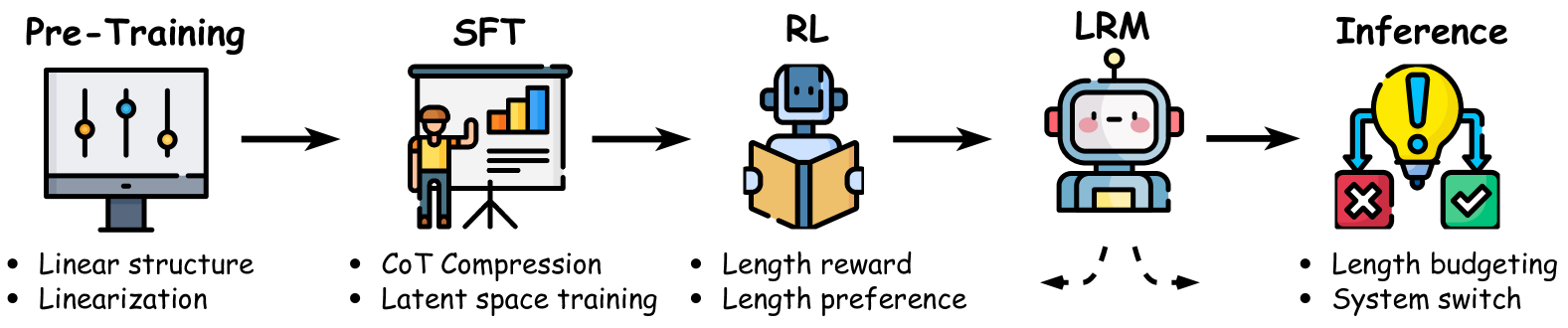
🔼 This figure illustrates the stages involved in achieving efficient reasoning in large reasoning models (LRMs). It highlights the different methods used at each stage, starting from pre-training where the model’s foundational knowledge is established. Then, the model undergoes supervised fine-tuning (SFT) to refine its reasoning capabilities, followed by reinforcement learning (RL) to further optimize its performance. Finally, the inference stage depicts how the model uses this learned knowledge to solve problems efficiently. Each stage is visually represented and connected to show the flow of development from foundational training to efficient reasoning.
read the caption
Figure 2: In this paper, we comprehensively study methods for efficient reasoning from the stages of Per-training, Supervised Fine-tuning (SFT), Reinforcement Learning (RL), and Inference.

🔼 This figure presents a taxonomy of methods designed to improve reasoning efficiency in Large Reasoning Models (LRMs). It categorizes techniques based on when they are applied in the LRM lifecycle: pre-training, supervised fine-tuning (SFT), reinforcement learning (RL), and inference. The taxonomy includes several categories of methods such as Length Budgeting, System Switching, Model Switching and Parallel Search. For each category, specific techniques are listed and referenced. The figure also highlights promising future research directions related to efficient reasoning in LRMs, including efficient multimodality and video reasoning, linearization, and the development of improved benchmarks for evaluation.
read the caption
Figure 3: Taxonomy of efficient reasoning methods for LRMs and future directions.

🔼 The figure illustrates the excessive token consumption by Large Reasoning Models (LRMs) during inference. A simple task of translating the Chinese sentence “如何实现高效推理?” (How to think efficiently?) into English requires over 2000 tokens. This highlights the inefficiency of current LRMs in terms of token economy, where concise reasoning is crucial for both efficiency and scalability. The high token usage suggests the need for methods and techniques to make LRMs more efficient in their reasoning processes.
read the caption
Figure 4: To translate a single Chinese sentence (“How to think efficiently?”) into English, recent LRM consumes more than 2000 tokens to reason.

🔼 This figure illustrates four key strategies for efficient reasoning during inference. Length budgeting controls the number of tokens used to limit computational overhead. System switching dynamically shifts between fast, intuitive System 1 reasoning and slower, more deliberate System 2 reasoning, optimizing for task difficulty. Model switching routes queries to models best suited for that task based on its complexity. Parallel search simultaneously explores multiple reasoning paths and discards less promising ones to reduce latency.
read the caption
Figure 5: Illustration of efficient reasoning during inference. (1) Length Budgeting limits intermediate tokens to reduce overhead; (2) System Switch dynamically alternates between fast, intuitive and slow, deliberate reasoning; (3) Model Switch directs queries to optimal models based on task difficulty; (4) Parallel Search generates and prunes candidate outputs concurrently to cut latency.

🔼 Figure 6 illustrates three different approaches to efficient reasoning during supervised fine-tuning (SFT). (a) shows the standard SFT process, where models are trained to generate a sequence of tokens representing a reasoning chain. (b) demonstrates reasoning chain compression. Here, training data is modified to skip less important tokens, leading to shorter, more efficient reasoning chains. (c) depicts latent-space SFT, where the training process iteratively uses continuous hidden states, thus avoiding the need to generate explicit reasoning steps, resulting in greater efficiency.
read the caption
Figure 6: Illustration of efficient reasoning during SFT. (a) Original SFT: Standard training with sequential token generation. (b) Reasoning Chain Compression: Training with token skipping to simplify reasoning. (c) Latent-Space SFT: Iterative training using continuous hidden states for more efficient reasoning.

🔼 Figure 7 illustrates two distinct reinforcement learning (RL) strategies for enhancing efficiency in large language models (LLMs). Subfigure (a) depicts a method that incorporates a length reward into the training process. This reward incentivizes the model to generate concise and efficient reasoning chains, balancing the need for brevity with the goal of accurate responses. Subfigure (b) presents an alternative RL approach that does not rely on explicit length rewards. Instead, it focuses on optimizing other aspects of the model’s behavior, possibly related to reasoning quality or computational cost, to achieve efficient performance without explicitly targeting chain length. Both subfigures showcase how RL can be used to shape the model’s behavior to maximize the intelligence per token.
read the caption
Figure 7: Illustration of efficiency training during the RL phase. Sub-Figures (a) and (b) illustrate the representative approach using length reward and not using length reward, respectively.

🔼 Figure 8 illustrates various approaches to efficient reasoning during the pretraining phase of large language models (LLMs). Panel (a) shows standard transformer-based pretraining using text tokens, which incurs high computational costs due to the quadratic complexity of self-attention. Panel (b) presents an alternative approach where the transformer is pretrained in a latent space, aiming to reduce complexity by operating on lower-dimensional representations. Panel (c) explores the use of linear models in pretraining to further decrease computational burden by avoiding the quadratic complexity of self-attention mechanisms altogether. Lastly, Panel (d) shows linearization methods that transform standard transformer models into linear models, offering an additional path towards more efficient pretraining.
read the caption
Figure 8: Illustration of efficient reasoning during pretraining: (a) Standard transformer pretraining utilizing text tokens; (b) Pretraining the transformer in latent space; (c) Employing linear models for pretraining instead of self-attention transformers; (d) Linearization methods that transform standard transformer models into linear models.
Full paper#