TL;DR#
Existing spatial grounding in image generation is limited to 2D, lacking 3D orientation control. Existing 3D methods are limited to synthetic data, lack realism, or handle only single objects with restricted viewpoints. These methods also struggle with multi-object scenarios. Furthermore, accurate real-world training data with per-object orientation annotations is scarce, hindering supervised learning approaches.
ORIGEN tackles these issues with a zero-shot method for 3D orientation grounding in text-to-image generation using reward-guided sampling. By leveraging Langevin dynamics, it balances reward maximization with realism, avoiding local optima. The approach is enhanced with adaptive time rescaling for faster convergence and is implemented in a method that can be done with a single line of code. Experiments demonstrate superior performance compared to existing methods, including multi-object handling.
Key Takeaways#
Why does it matter?#
This research pioneers 3D orientation grounding in image generation, a leap beyond existing 2D spatial control methods. It offers researchers a new tool for precise image manipulation, fostering advancements in fields like robotics, virtual reality, and content creation where 3D spatial understanding is crucial.
Visual Insights#

🔼 This figure showcases the results of ORIGEN, a novel zero-shot method for 3D orientation grounding in text-to-image generation. It demonstrates ORIGEN’s ability to generate high-quality images of multiple objects from diverse categories, accurately aligning the objects’ orientations with user-specified conditions. The colored arrows in the images visually represent these specified orientations, highlighting the precision of ORIGEN’s control over 3D object placement.
read the caption
Figure 1: 3D orientaion-grounded text-to-image generation results of Origen. We present Origen, the first zero-shot method for 3D orientation grounding in text-to-image generation across multiple objects and diverse categories. Origen generates high-quality images that are accurately aligned with the grounding orientation conditions, indicated by the colored arrows, and the input text prompts.
| Ground Truth | ReNO [16] | Origen | ||
 | ||||
🔼 This table presents a quantitative comparison of different methods for 3D orientation grounded image generation. The methods are evaluated using several metrics, including accuracy at different angular tolerances (Acc.@22.5°, Acc.@5°), absolute error, CLIP score, VQA score, and PickScore, which assess the alignment of generated images with specified 3D orientations and textual descriptions. The table allows for a direct comparison of performance across various techniques, highlighting the best and second-best performers for each metric.
read the caption
Table 1: Quantitative comparisons on 3D orientation grounded image generation. Best and second-best results are highlighted in bold and underlined, respectively.
In-depth insights#
3D Orientation#
3D orientation in image generation is underexplored, with existing methods often limited to relative control, synthetic data, or single objects. Challenges include the lack of real-world training data with accurate per-object annotations. Current approaches struggle to balance orientation grounding with realism, often getting stuck in local optima or deviating from the prior latent distribution. A promising direction involves reward-guided sampling that incorporates stochasticity to avoid local optima and maintain a balance between reward maximization and adherence to the prior latent distribution. This could potentially enable more robust and generalizable control over 3D orientation in generated images.
Reward-Guided SDE#
Reward-Guided Stochastic Differential Equations (SDEs) represent a powerful paradigm for generative modeling by infusing external guidance into the sampling process. Unlike traditional SDEs that rely solely on the inherent dynamics for generation, reward-guided approaches leverage a reward function to shape the trajectory of the generated sample towards desired attributes or properties. This reward function acts as a driving force, influencing the SDE’s drift term to favor regions of the data space that align with the defined objectives. The benefit lies in the ability to exert explicit control over the generated output, enabling the generation of samples that are not only realistic but also tailored to specific criteria. However, challenges arise in designing effective reward functions that are well-behaved and capable of accurately capturing the desired attributes. Careful consideration must be given to avoid reward hacking or unintended consequences, ensuring that the guidance leads to genuine improvement rather than artificial manipulation of the generated output.
Adaptive Scaling#
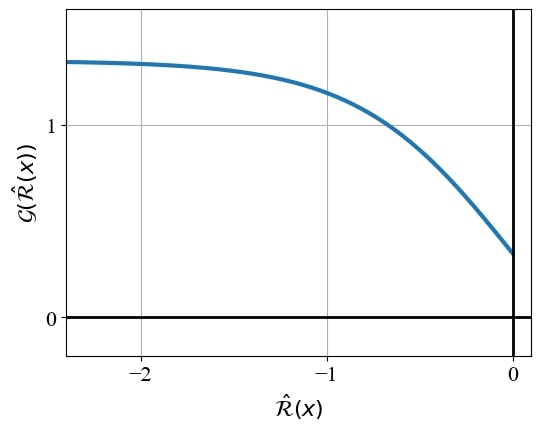
Adaptive scaling, in the context of image generation, likely refers to a dynamic adjustment of parameters, such as step size or learning rate, during the generation process. This adjustment is crucial for optimizing both the quality and efficiency of the generated images. Without adaptive scaling, the generation process might suffer from slow convergence or get stuck in local optima. Implementing such scaling mechanisms, especially through reward functions, enables the system to intelligently navigate the latent space, ensuring generated images adhere to both the input text prompt and the orientation conditions. Furthermore, the integration of time rescaling ensures a balance between convergence speed and result accuracy, proving advantageous in achieving desired outcomes.
Zero-Shot ORIGEN#
The concept of a “Zero-Shot ORIGEN” implies a significant advancement in text-to-image generation. Zero-shot learning suggests the model can generate images conditioned on 3D orientation from text descriptions without explicit training on paired data of text and 3D orientations. This tackles a major challenge: the scarcity of datasets with diverse, real-world images annotated with accurate 3D orientation information. ORIGEN leverages pre-trained models, implying a modular design. It uses a foundational discriminative model for 3D orientation estimation and a text-to-image generative model. This allows the model to infer the orientation from the generated image and guide the generation process. The zero-shot capability offers immense flexibility, allowing users to control the 3D orientation of objects in generated scenes through textual prompts alone. This facilitates greater control and customization in image generation, creating possibilities for applications where precise 3D orientation control is crucial.
MS-COCO Dataset#
The authors leverage the MS-COCO dataset, a widely recognized resource, as the foundation for constructing three novel benchmarks: MS-COCO-Single, MS-COCO-NView, and MS-COCO-Multi. Recognizing the absence of existing datasets specifically tailored for evaluating 3D orientation grounding in text-to-image generation, they curate these benchmarks. This proactive approach addresses a critical gap in the field, enabling quantitative assessments of novel methods like ORIGEN. MS-COCO’s rich set of images, captions, and object annotations provides a strong base for this challenging task. This strategy allows to compare ORIGEN to prior methods, particularly in the single-object orientation context. The deliberate choice of MS-COCO ensures that the evaluation is grounded in real-world data, enhancing the practical relevance of the findings.
More visual insights#
More on figures

🔼 This figure displays a comparison of different methods for sampling latent vectors in a generative model, aiming to maximize a reward function while maintaining realism. The top row visualizes the latent space samples (red points), and the bottom row shows the corresponding generated data samples (blue points) in the image space. The four columns illustrate: (1) the ground truth target distribution, representing the ideal outcome; (2) the results obtained using the ReNO [16] method; (3) the results from the proposed method with uniform time scaling; and (4) the results from the proposed method with reward-adaptive time rescaling. The figure demonstrates that the proposed method with reward-adaptive time rescaling most closely approximates the ideal target distribution.
read the caption
Figure 2: Toy experiment results. The top row shows latent space samples (red), while the bottom row shows the corresponding data space samples (blue). From left to right, each column represents: (1) the ground truth target distribution from Eq. (2); (2) results of ReNO [16]; (3) results of ours with uniform time scaling; and (4) results of ours with reward-adaptive time rescaling.
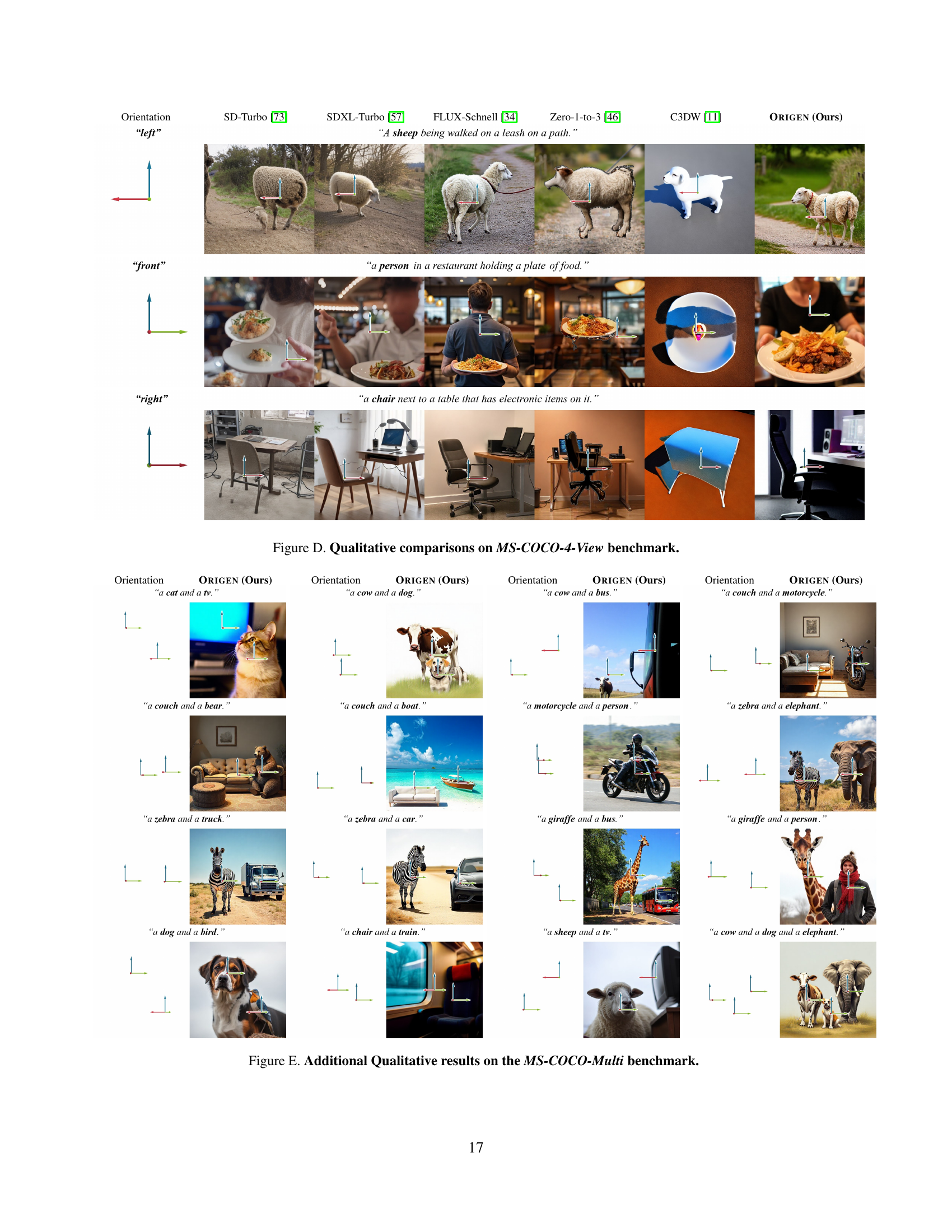
🔼 Figure 3 presents a qualitative comparison of image generation results on the MS-COCO-Single benchmark dataset. Three methods are compared: Zero-1-to-3 [46], C3DW [11], and the proposed ORIGEN model. The figure shows that ORIGEN generates more realistic images that better align with the specified object orientations than the existing methods. The specified object orientation is visually indicated by colored arrows overlaid on each generated image.
read the caption
Figure 3: Qualitative comparisons on MS-COCO-Single benchmark (Sec. 4.3). Compared to the existing orientation-to-image models [11, 46], Origen generates the most realistic images, which also best align with the grounding conditions, indicated by the overlapped arrow in each image.
More on tables




🔼 This table presents a quantitative comparison of different methods for 3D orientation grounding in text-to-image generation, specifically on the MS-COCO-Single benchmark (described in Section 4.3 of the paper). It compares ORIGEN (the proposed method) with several baselines, including other methods for orientation-conditioned image generation and training-free guided generation methods. The comparison uses multiple metrics, evaluating both the accuracy of the orientation grounding (Azimuth Accuracy @ 22.5°, Azimuth Absolute Error) and the overall quality of the generated images (CLIP score, VQA score, PickScore). The table also includes results for ORIGEN* (without reward-adaptive time rescaling) to highlight the impact of this technique on performance.
read the caption
(a) Comparisons on MS-COCO-Single (Sec. 4.3). Origen∗ denotes ours without reward-adaptive time rescaling, where Origen represents our full method.



🔼 Table 1b presents a quantitative comparison of different methods for 3D orientation grounding in text-to-image generation on the MS-COCO-NView benchmark. The benchmark uses images with single objects but controlled viewpoints (front, left, right, and back). The table compares ORIGEN to several baselines, including other orientation-conditioned image generation methods and training-free guided generation methods, across multiple metrics such as orientation alignment accuracy (Acc.@22.5° and absolute error), and text-to-image alignment (CLIP score, VQA score, and PickScore). This allows for a comprehensive evaluation of ORIGEN’s performance in various aspects.
read the caption
(b) Comparisons on MS-COCO-NView (Sec. 4.4).
| Orientation | Origen (Ours) | Orientation | Origen (Ours) | Orientation | Origen (Ours) | Orientation | Origen (Ours) |
 |  |  |  | ||||
 |  |  |  | ||||
🔼 Quantitative comparison of different models on the MS-COCO-Multi benchmark focusing on 3D orientation grounding in text-to-image generation. The table presents the performance of the ORIGEN model against other baselines in terms of orientation alignment (accuracy at 22.5 degrees and absolute error), as well as text-to-image alignment metrics (CLIP score, VQA score, and PickScore). This dataset tests the model’s ability to accurately generate images of multiple objects with specified orientations.
read the caption
(c) Comparisons on MS-COCO-Multi (Sec. 4.5).
| Id | Model | Orientation Alignment | Text Alignment | |||
| Acc.@22.5° | Abs. Err. | CLIP | VQA | PickScore | ||
| 1 | C3DW [11] | 0.426 | 64.77 | 0.220 | 0.439 | 0.197 |
| 2 | Zero-1-to-3 [46] | 0.499 | 59.03 | 0.272 | 0.663 | 0.213 |
| 3 | FreeDoM [74] | 0.741 | 20.90 | 0.259 | 0.728 | 0.225 |
| 4 | ReNO [16] | 0.796 | 20.56 | 0.247 | 0.663 | 0.212 |
| 5 | Origen∗ (Ours) | 0.854 | 18.28 | 0.265 | 0.732 | 0.224 |
| 6 | Origen (Ours) | 0.871 | 17.41 | 0.265 | 0.735 | 0.224 |
🔼 This table presents the results of a user study comparing the 3D orientation grounding capabilities of ORIGEN against two baseline methods (C3DW [11] and Zero-1-to-3 [46]). A total of 100 participants on Amazon Mechanical Turk were asked to choose the image that best matched a given text prompt and 3D orientation condition from the images generated by each method. ORIGEN significantly outperformed the baselines, with 58.18% of participants preferring its results. The table shows the percentage of user preference for each method, broken down for 3-view and 4-view alignment scenarios.
read the caption
Table 2: User Study Results. 3D orientation-grounded text-to-image generation results of Origen was preferred by 58.18% of the participants on Amazon Mechanical Turk [9], significantly outperforming the baselines [11, 46].
| Id | Model | 3-view Alignment | 4-view Alignment | ||
| Acc.@22.5° | Abs. Err. | Acc.@22.5° | Abs. Err. | ||
| 1 | SD-Turbo [73] | 0.257 | 75.09 | 0.244 | 78.47 |
| 2 | SDXL-Turbo [57] | 0.189 | 78.44 | 0.196 | 81.88 |
| 3 | FLUX-Schnell [34] | 0.312 | 75.04 | 0.424 | 60.26 |
| 4 | C3DW [11] | 0.504 | 53.53 | - | - |
| 5 | Zero-1-to-3 [46] | 0.366 | 68.70 | 0.321 | 75.10 |
| 6 | Origen (Ours) | 0.824 | 20.99 | 0.866 | 17.45 |
🔼 This table lists the 25 object classes used in the MS-COCO-Single dataset benchmark. These classes represent a variety of common objects with distinct visual characteristics suitable for evaluating 3D orientation grounding in image generation. The classes were carefully selected to ensure a balance of complexity and representation of different object types.
read the caption
Table A: Selected object classes in our dataset.
| Model | Orientation Alignment | Text alignment | |||
| Acc.@22.5° | Abs. Err. | CLIP | VQA | PickScore | |
| Origen (Ours) | 0.634 | 34.27 | 0.281 | 0.764 | 0.219 |
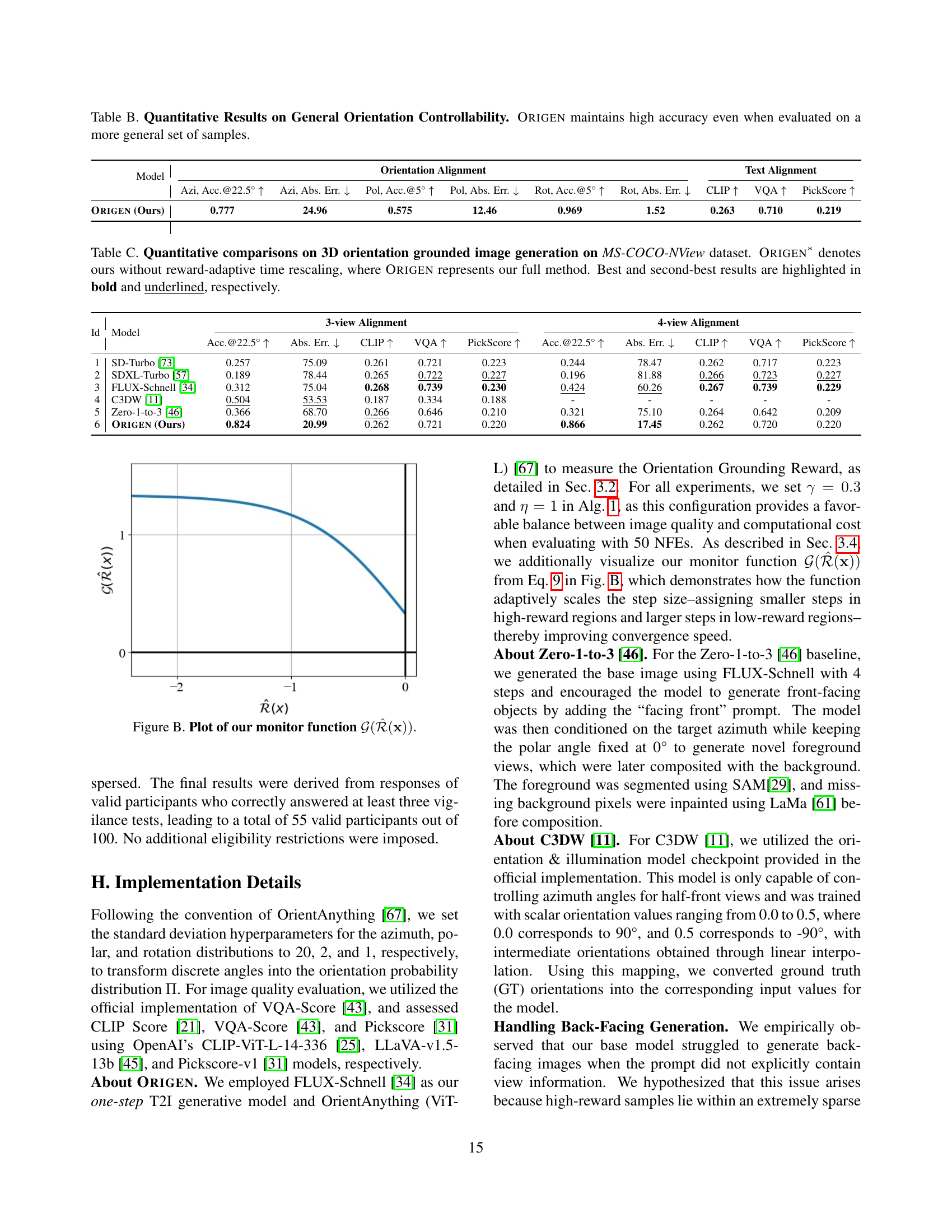
🔼 Table B presents a quantitative analysis of ORIGEN’s performance on general orientation controllability. It shows the accuracy of ORIGEN in predicting azimuth, polar, and rotation angles, along with text-to-image alignment metrics (CLIP, VQA, PickScore). The results demonstrate that ORIGEN maintains high accuracy even when evaluated on a more diverse set of samples than those used in the previous, more constrained experiments.
read the caption
Table B: Quantitative Results on General Orientation Controllability. Origen maintains high accuracy even when evaluated on a more general set of samples.
🔼 Table C presents a quantitative comparison of different methods for 3D orientation-grounded image generation using the MS-COCO-NView dataset. The table compares the performance of ORIGEN (with and without reward-adaptive time rescaling) against several baselines (SD-Turbo, SDXL-Turbo, FLUX-Schnell, C3DW, and Zero-1-to-3). Evaluation metrics include accuracy at 22.5° and absolute error for azimuth angle, along with CLIP score, VQA score, and PickScore for text-to-image alignment. The best and second-best results for each metric are highlighted.
read the caption
Table C: Quantitative comparisons on 3D orientation grounded image generation on MS-COCO-NView dataset. Origen∗ denotes ours without reward-adaptive time rescaling, where Origen represents our full method. Best and second-best results are highlighted in bold and underlined, respectively.
Full paper#