TL;DR#
Recent RLHF research focuses on algorithmic advancements, with less attention to prompt-data construction and scalability. Addressing this gap, the paper explores data-driven bottlenecks that hinder RLHF performance scaling, focusing on reward hacking and decreasing response diversity. They introduce a hybrid reward system combining reasoning task verifiers (RTV) and a generative reward model (GenRM) to mitigate reward hacking. This approach not only exhibits enhanced resistance to reward hacking but also enables accurate assessment of responses against clearly defined ground-truth solutions.
To ensure response diversity and enhance learning effectiveness, the paper proposes a novel prompt-selection method named Pre-PPO, explicitly identifying training prompts that are inherently challenging and thus less prone to reward hacking. Prioritizing mathematical and coding tasks during the early phases of RLHF training significantly boosts performance, given that these tasks encode fine-grained response distinctions and possess clearly defined ground truths. Experiments across two model sizes validate the effectiveness and scalability of the proposed methods.
Key Takeaways#
Why does it matter?#
This work is crucial for improving RLHF, ensuring LLMs align with human values while being resistant to reward hacking. It provides practical methodologies for data construction, benefiting researchers working on LLM alignment and safety.
Visual Insights#
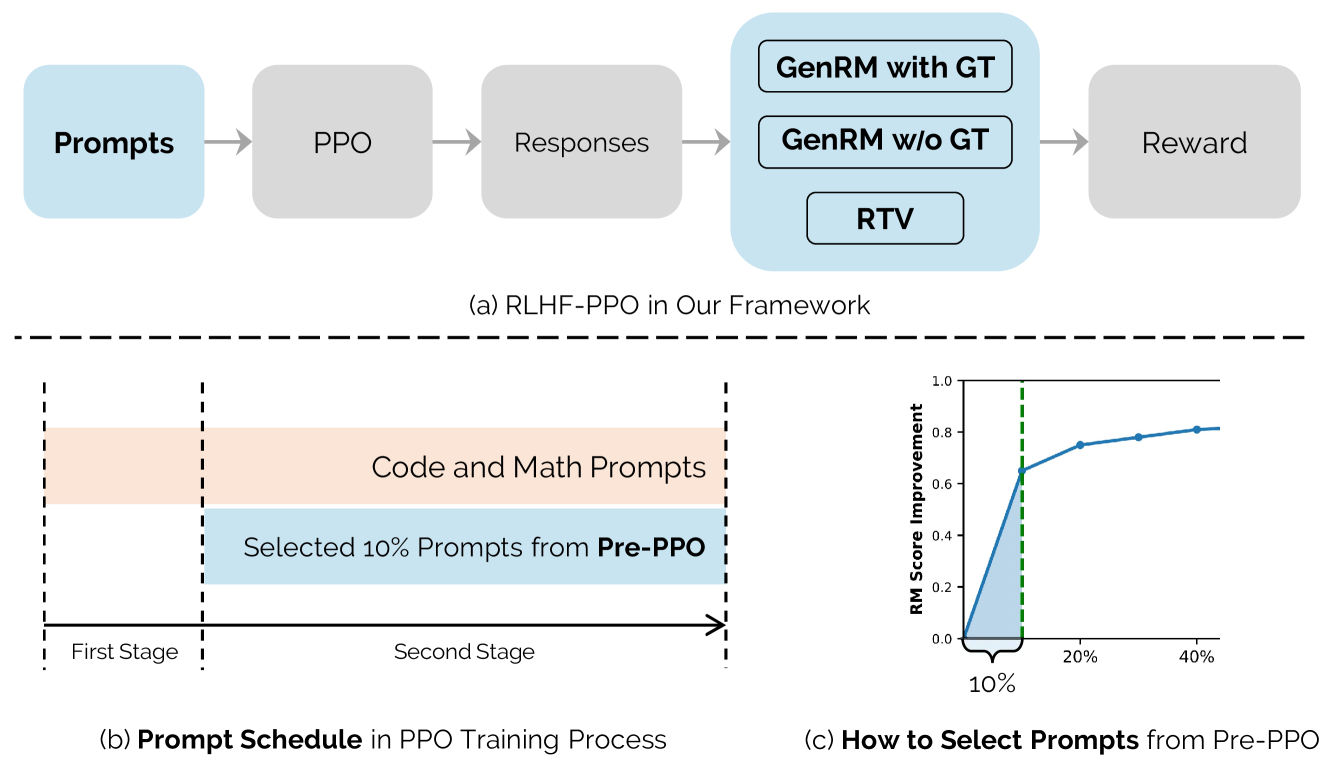
🔼 This figure illustrates the RLHF training framework, which involves two main stages. The first stage is Reward Model Training, where three reward models are trained: the Bradley-Terry (BT) model (trained on pairwise comparisons of human preferences), the Generative Reward Model (GenRM) (assigns reward scores based on ground truth or BT model’s best-of-N selections), and Reasoning Task Verifiers (RTV) (specialized validators for specific tasks, such as code execution for programming tasks). The second stage is Reinforcement Learning Optimization, where the language model is iteratively optimized using PPO, guided by GenRM and RTV. Pre-PPO prompt selection is employed to identify the most challenging prompts, leading to robust performance and alignment enhancements.
read the caption
Figure 1: Overview of the RLHF Training Framework. Our proposed pipeline consists of two sequential phases: (1) Reward Model Training, where we construct three complementary reward models—namely, the Bradley-Terry (BT) model, the Generative Reward Model (GenRM), and Reasoning Task Verifiers (RTV). Specifically, the BT model is trained on pairwise comparisons to capture human preferences, while the GenRM assigns explicit reward scores aligned with these preferences using either ground-truth solutions (for reasoning tasks) or the best-of-N selections identified by the BT model (for general tasks). The RTV component implements specialized validators tailored to specific task requirements, such as code-execution sandboxes for evaluating programming tasks; and (2) Reinforcement Learning Optimization, in which the language model is iteratively optimized using PPO under guidance from both GenRM and RTV. This stage leverages carefully selected training prompts identified through our Pre-PPO prompt-selection method and employs strategic optimization techniques to robustly enhance model performance and alignment.
| Method | Logical | IF | STEM | Coding | NLP | Knowledge | CU | OOD | Overall |
|---|---|---|---|---|---|---|---|---|---|
| Reasoning | |||||||||
| Initial-Run (V1.0) | 27.1 | 34.8 | 49.3 | 51.6 | 24.7 | 37.0 | 40.0 | 39.0 | 37.7 |
| Baseline-Small (V1.0) | 26.4 | 35.1 | 48.8 | 50.9 | 24.8 | 36.1 | 40.6 | 40.5 | 37.7 |
| Data Scale-Small (V1.0) | 28.7 | 36.1 | 50.4 | 53.3 | 24.2 | 36.6 | 39.7 | 43.6 | 38.8 |
| Improvement | +2.4 | +1.1 | +1.6 | +2.4 | -0.6 | +0.6 | -0.9 | +3.1 | +1.1 |
| Baseline-Large (V1.0) | 37.3 | 46.3 | 55.6 | 55.5 | 45.7 | 46.8 | 58.4 | 54.5 | 49.7 |
| Data Scale-Large (V1.0) | 39.6 | 46.0 | 56.5 | 58.7 | 44.9 | 47.9 | 59.6 | 55.6 | 50.8 |
| Improvement | +2.2 | -0.4 | +0.9 | +3.2 | -0.8 | +1.1 | +1.2 | +1.2 | +1.1 |
| Baseline-Small (V2.0) | 17.6 | 26.5 | 26.5 | 41.2 | 21.2 | 28.2 | 19.6 | 21.3 | 23.9 |
| Data Scale-Small (V2.0) | 19.9 | 27.3 | 29.5 | 42.3 | 21.8 | 28.9 | 20.2 | 21.7 | 25.1 |
| Improvement | +2.3 | +0.8 | +3.0 | +1.1 | +0.6 | +0.7 | +0.8 | +0.4 | +1.2 |
| Baseline-Large (V2.0) | 29.5 | 36.3 | 28.0 | 48.5 | 29.5 | 45.6 | 36.8 | 35.0 | 34.0 |
| Data Scale-Large (V2.0) | 31.2 | 36.4 | 31.9 | 50.7 | 32.3 | 45.5 | 36.6 | 37.1 | 35.4 |
| Improvement | +1.8 | +0.1 | +3.9 | +2.1 | +2.7 | -0.1 | -0.2 | +2.1 | +1.4 |
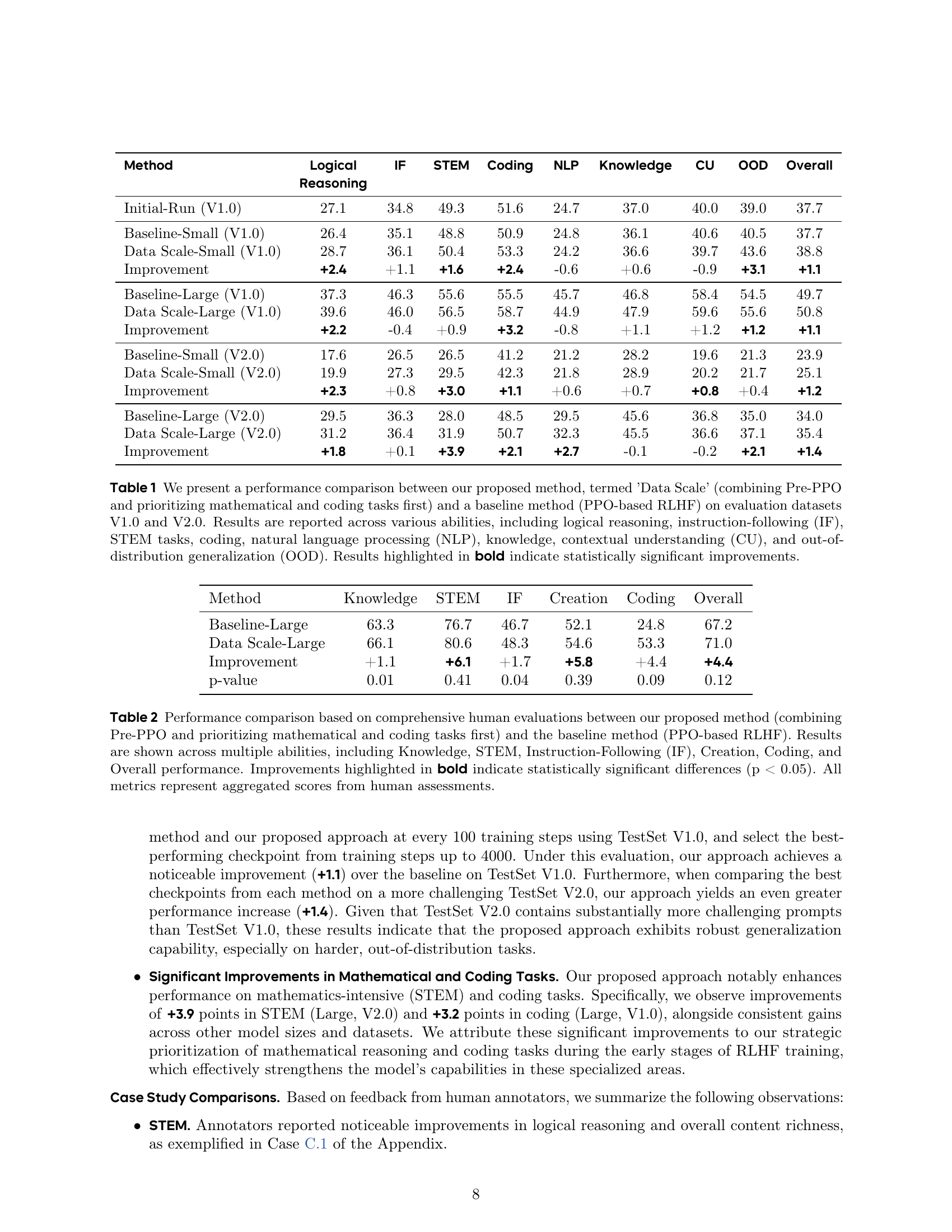
🔼 This table compares the performance of two RLHF methods: the proposed ‘Data Scale’ method (combining Pre-PPO and prioritizing math/coding tasks) and a baseline PPO-based RLHF method. The comparison is done using two evaluation datasets (V1.0 and V2.0) across eight different abilities: logical reasoning, instruction-following, STEM tasks, coding, natural language processing, knowledge, contextual understanding, and out-of-distribution generalization. Statistically significant improvements by the Data Scale method are highlighted in bold.
read the caption
Table 1: We present a performance comparison between our proposed method, termed ’Data Scale’ (combining Pre-PPO and prioritizing mathematical and coding tasks first) and a baseline method (PPO-based RLHF) on evaluation datasets V1.0 and V2.0. Results are reported across various abilities, including logical reasoning, instruction-following (IF), STEM tasks, coding, natural language processing (NLP), knowledge, contextual understanding (CU), and out-of-distribution generalization (OOD). Results highlighted in bold indicate statistically significant improvements.
In-depth insights#
RLHF Data Scaling#
While algorithmic advancements in RLHF are crucial, the significance of RLHF data construction and scaling is often understated. Data-driven bottlenecks, specifically reward hacking and diminishing response diversity, hinder performance scaling. Addressing reward hacking requires hybrid reward systems like combining reasoners and generative models which shows resistance. Furthermore, preemptive prompt selection, such as identifying inherently challenging prompts (Pre-PPO) for training, can ensure diversity and enhance learning effectiveness. Prioritizing tasks, like mathematics and coding, that encode fine-grained distinctions is a strategy to enhance RLHF performance.
Hybrid Reward Model#
A hybrid reward model seems like a promising approach in reinforcement learning, particularly when dealing with complex tasks or environments. It involves combining multiple reward signals or models to provide a more comprehensive and nuanced assessment of an agent’s behavior. This could involve integrating intrinsic and extrinsic rewards, shaping rewards, or even learning from demonstrations. One potential benefit is increased robustness to reward hacking, where agents exploit loopholes in a single reward function. The key challenge lies in effectively balancing and weighting these different reward components, ensuring that they align with the desired objectives and don’t lead to unintended consequences. Careful design and experimentation are crucial for realizing the full potential of a hybrid reward model. By leveraging the strengths of diverse reward signals, hybrid reward model can improve learning efficiency, stability, and generalization capabilities, Ultimately achieving superior policy performance.
Pre-PPO Strategy#
The Pre-PPO strategy represents a critical component of enhancing Reinforcement Learning from Human Feedback (RLHF) performance. It involves selecting training prompts based on their reward model scores before PPO, aiming to address the reward hacking phenomenon where models generate syntactically correct but semantically flawed responses. The initial experiment revealed that simply increasing the number of prompts doesn’t improve RLHF performance. Analysis of reward scores of new prompts indicated a high proportion of scores, but manual inspection uncovered reward hacking behavior. The core idea is to utilize prompts with lower reward model scores, posing greater learning challenges and reducing susceptibility to reward hacking. These are then combined with the original dataset to retrain the RL model. Recognizing differing score distributions across task domains, the strategy involves normalizing these scores within each domain before selection.
Coding Task Focus#
The paper underscores a strategic emphasis on coding tasks within RLHF, noting their resistance to reward hacking due to grounded evaluation metrics like code execution sandboxes. Prioritizing these tasks early accelerates fine-grained distinction learning, boosting overall performance. Unlike tasks reliant on subjective human feedback, coding’s objective validation creates a stable learning signal. The ‘Data Scale’ method further enhances coding performance, demonstrating the value of carefully curated data and robust evaluation. Early exposure to coding’s inherent structure equips the model to discern subtle patterns, impacting mathematical reasoning. This focus combats overfitting and ensures more resilient skill acquisition, enabling sustained improvements throughout training. By strategically balancing diverse task types, the RLHF model achieves superior coding prowess and foundational knowledge that benefits the broader skill set.
Response Diversity#
Response diversity is a critical aspect of language model performance, particularly in RLHF. The paper acknowledges a decline in entropy during training, indicating a loss of variety in generated outputs, which can limit the model’s ability to handle diverse tasks and contexts. While RLHF effectively aligns models, it risks over-optimization towards specific reward signals, sacrificing the breadth of possible responses. The challenge is to balance alignment with creativity and adaptability. The authors observe that different reward models (RTV, GenRM) influence response diversity differently, highlighting the need for careful reward design. Prioritizing tasks that inherently encourage diverse responses, such as creative writing, and mitigating reward hacking are potential strategies to maintain diversity without compromising alignment. A lack of diversity constrains the model and may lead to less useful outputs, with the model learning coarse differences in response only.
More visual insights#
More on figures

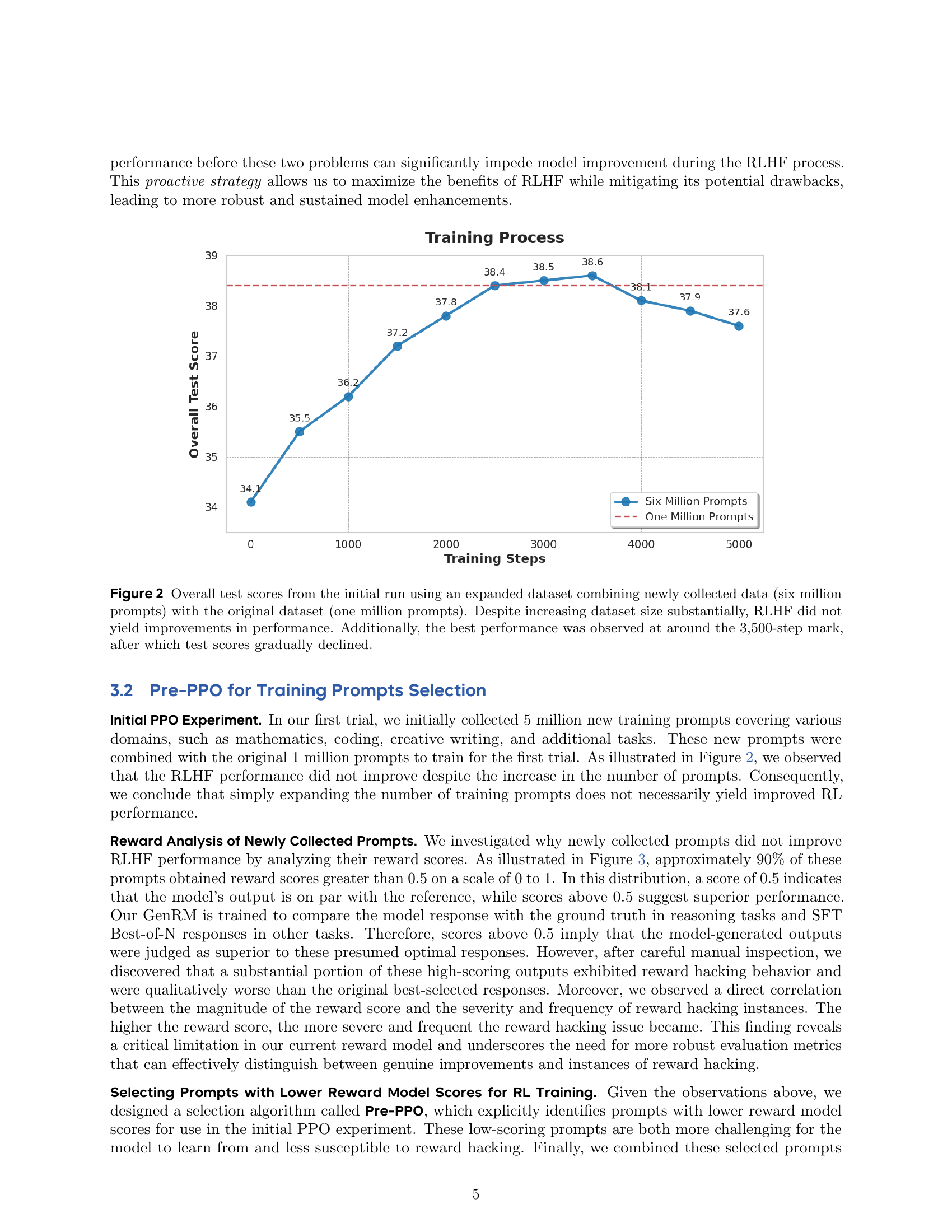
🔼 This figure displays the overall test scores obtained during the initial RLHF training experiment. Two datasets were used: an original dataset of one million prompts and a newly collected dataset of six million prompts, combined for a total of seven million prompts. Despite the substantial increase in data size, the results show that RLHF training did not lead to improved performance as measured by the overall test score. In fact, the model achieved its peak performance around training step 3500, after which the performance gradually decreased. This suggests that simply increasing the amount of training data may not guarantee improved performance in RLHF, implying the importance of data quality over quantity.
read the caption
Figure 2: Overall test scores from the initial run using an expanded dataset combining newly collected data (six million prompts) with the original dataset (one million prompts). Despite increasing dataset size substantially, RLHF did not yield improvements in performance. Additionally, the best performance was observed at around the 3,500-step mark, after which test scores gradually declined.

🔼 This figure shows the distribution of reward scores obtained from a newly collected dataset of prompts. The x-axis displays the percentage of prompts, while the y-axis represents the reward score, ranging from 0 to 1. A score of 0.5 indicates that the model’s output is comparable to the reference output. The figure reveals that approximately 90% of the prompts received scores exceeding 0.5 for both small and large language models, seemingly outperforming the reference outputs. However, a closer manual inspection uncovered that a significant number of high-scoring outputs exhibited reward hacking behaviors and were qualitatively inferior to the initially selected best outputs.
read the caption
Figure 3: Distribution of reward scores for newly collected prompts. The x-axis shows the percentage of prompts. The y-axis represents the reward score range from 0 to 1, with 0.5 indicating parity with the reference. Approximately 90% of prompts received scores above 0.5 for both small-size and large-size models, suggesting apparent superiority over reference outputs. However, manual inspection revealed that many high-scoring outputs exhibited reward hacking behavior and were qualitatively inferior to the original best-selected outcomes.

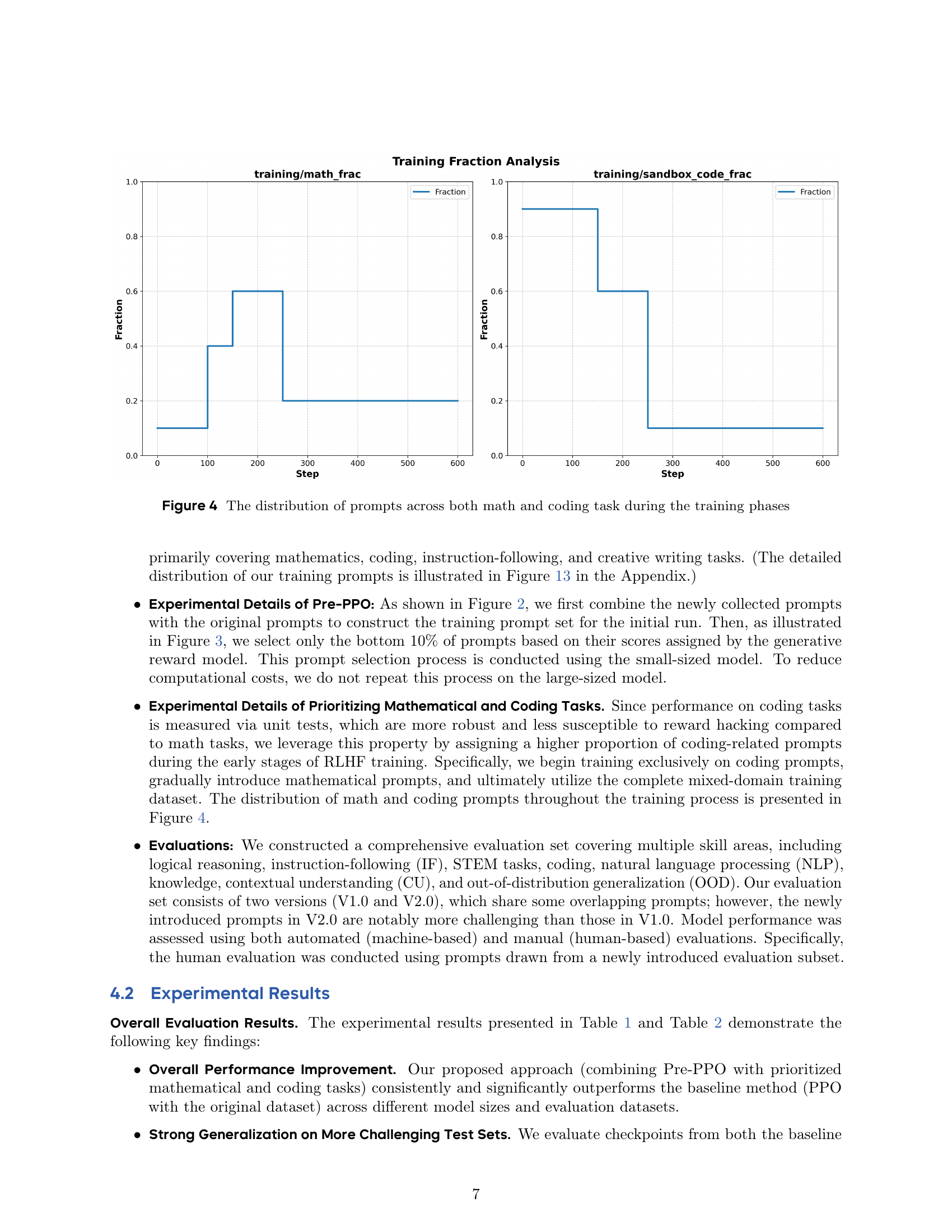
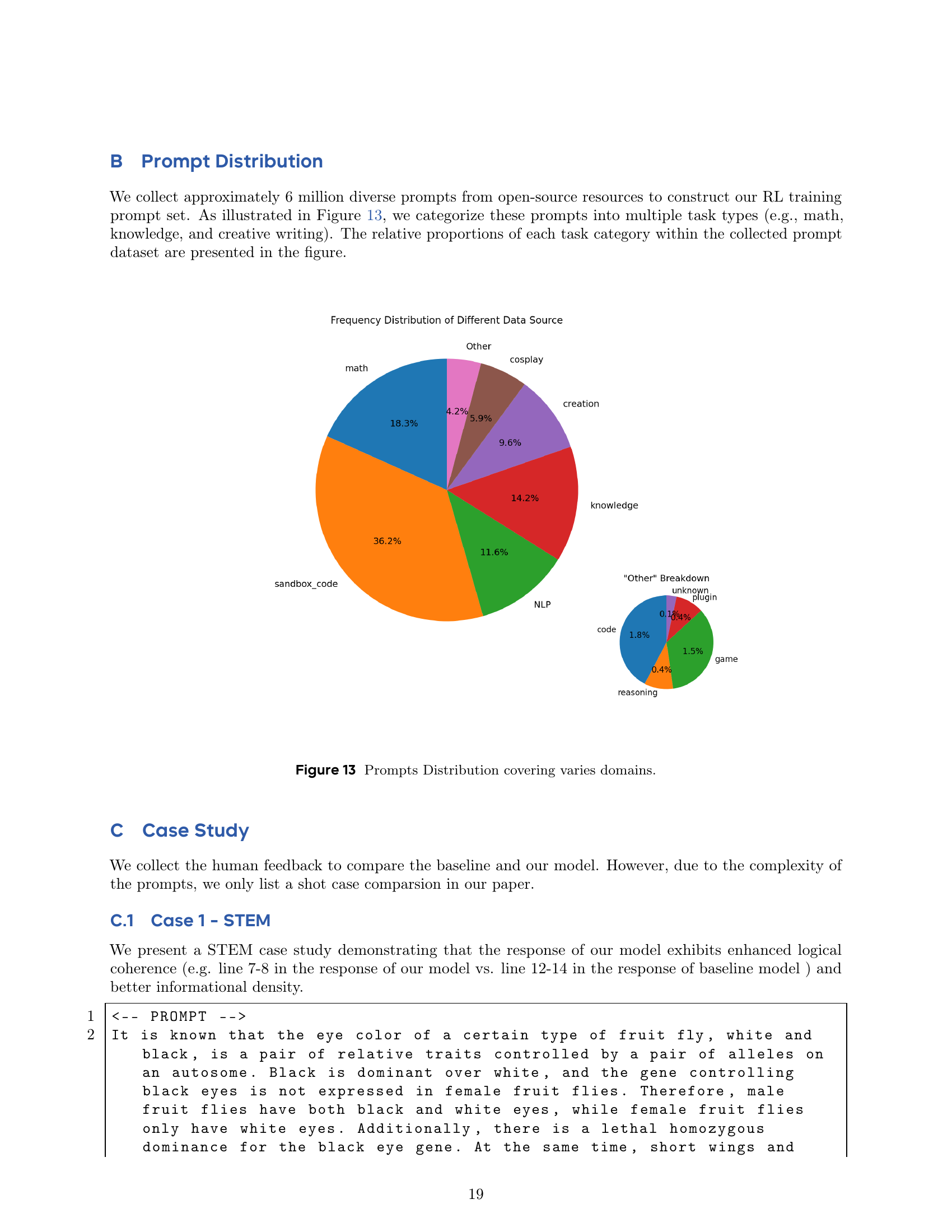
🔼 This figure shows the proportion of math and coding prompts used during each training step of the Reinforcement Learning from Human Feedback (RLHF) process. It visually represents how the focus on math and coding tasks changes over the course of training, illustrating the strategy of prioritizing these task types early in the training pipeline before incorporating other kinds of prompts. The x-axis represents the training step, and the y-axis represents the fraction of prompts dedicated to either math or coding tasks.
read the caption
Figure 4: The distribution of prompts across both math and coding task during the training phases

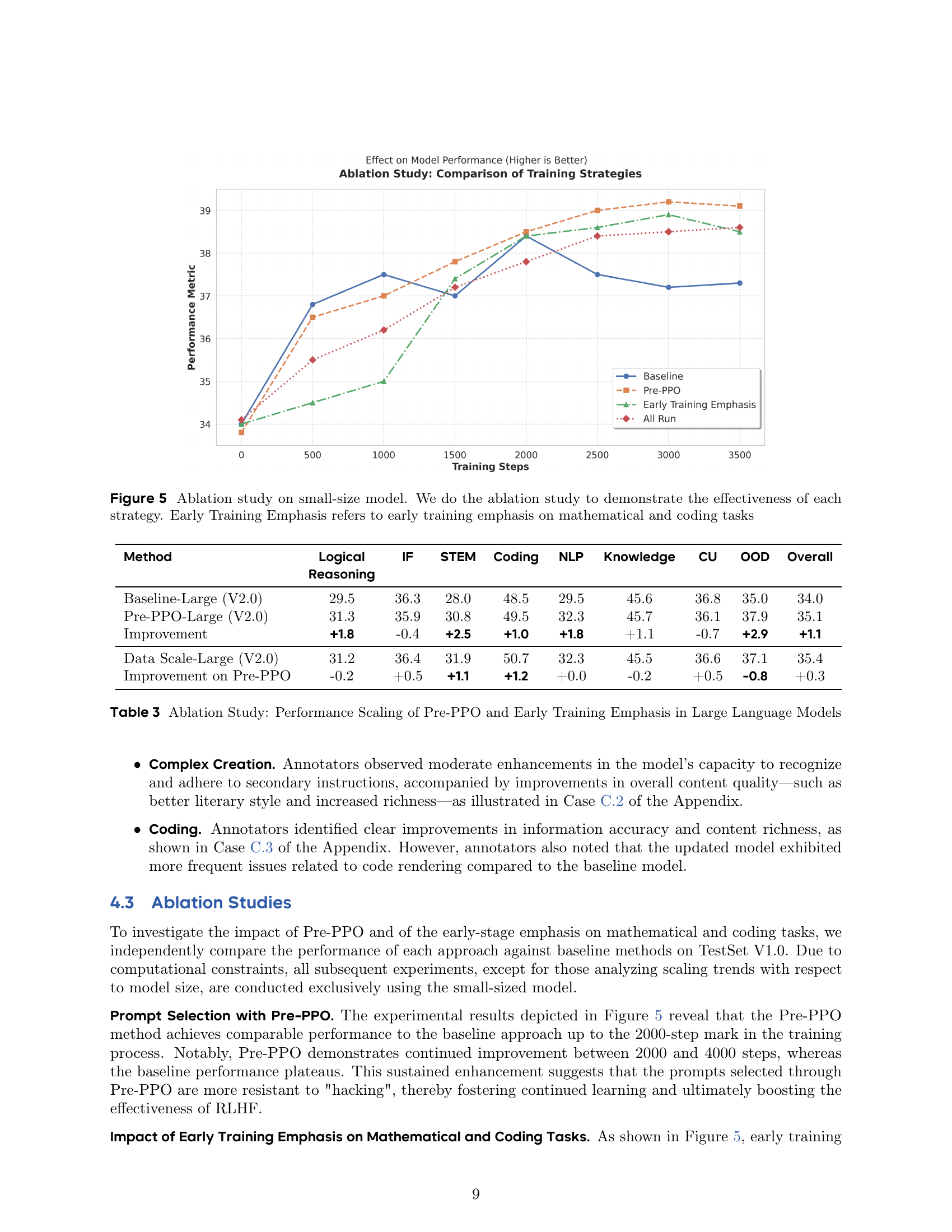
🔼 This ablation study uses a small-sized language model to evaluate the individual contributions of three different RLHF training strategies: 1) Pre-PPO prompt selection, which prioritizes more challenging prompts, 2) Early Training Emphasis, which focuses on mathematical and coding tasks in the initial training phase, and 3) a combination of both Pre-PPO and Early Training Emphasis. The graph likely shows the overall performance of the model across various tasks as a function of training steps, allowing comparison of the performance achieved using each strategy against the baseline (no additional strategies). This visualization helps determine the effectiveness and potential synergy between the proposed strategies in improving RLHF performance.
read the caption
Figure 5: Ablation study on small-size model. We do the ablation study to demonstrate the effectiveness of each strategy. Early Training Emphasis refers to early training emphasis on mathematical and coding tasks

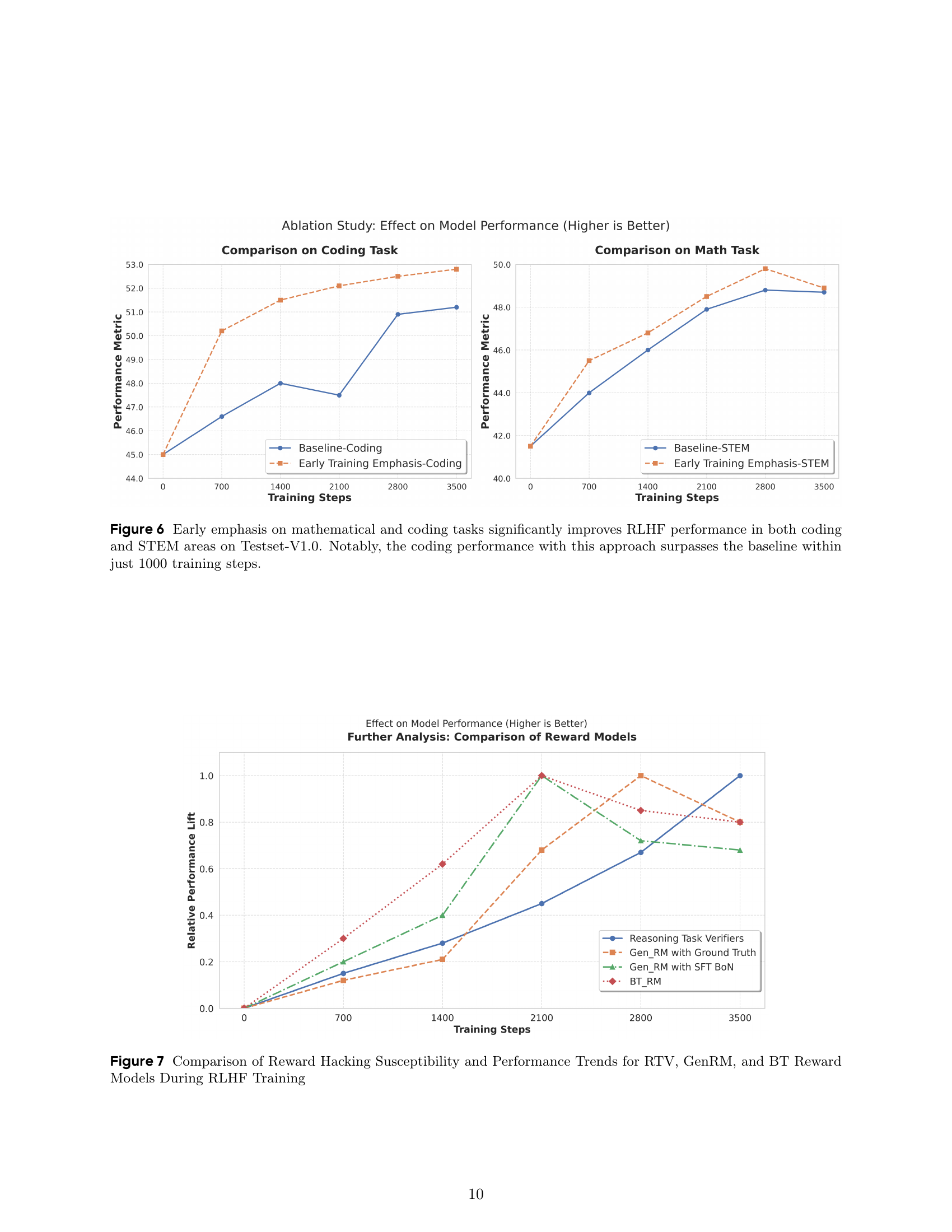
🔼 This figure displays the results of an ablation study that demonstrates the impact of prioritizing mathematical and coding tasks during the early stages of Reinforcement Learning from Human Feedback (RLHF) training. Two line graphs show the performance of a model trained with this early emphasis strategy versus a baseline model across different training steps, with performance measured in terms of test scores on coding and STEM tasks. The graph clearly shows that the model that prioritizes these tasks outperforms the baseline, achieving comparable results much faster. In particular, the model that prioritizes coding and math tasks significantly surpasses the baseline model in coding performance within 1000 training steps.
read the caption
Figure 6: Early emphasis on mathematical and coding tasks significantly improves RLHF performance in both coding and STEM areas on Testset-V1.0. Notably, the coding performance with this approach surpasses the baseline within just 1000 training steps.

🔼 This figure displays the reward hacking susceptibility and performance trends observed during Reinforcement Learning from Human Feedback (RLHF) training for three different reward models: Reasoning Task Verifiers (RTV), Generative Reward Model (GenRM), and Bradley-Terry Reward Model (BT). It illustrates how each model’s performance and resistance to reward hacking changes over the course of RLHF training. This allows for a comparison of the effectiveness and robustness of the various reward models in guiding the model’s learning process and avoiding reward hacking behavior.
read the caption
Figure 7: Comparison of Reward Hacking Susceptibility and Performance Trends for RTV, GenRM, and BT Reward Models During RLHF Training

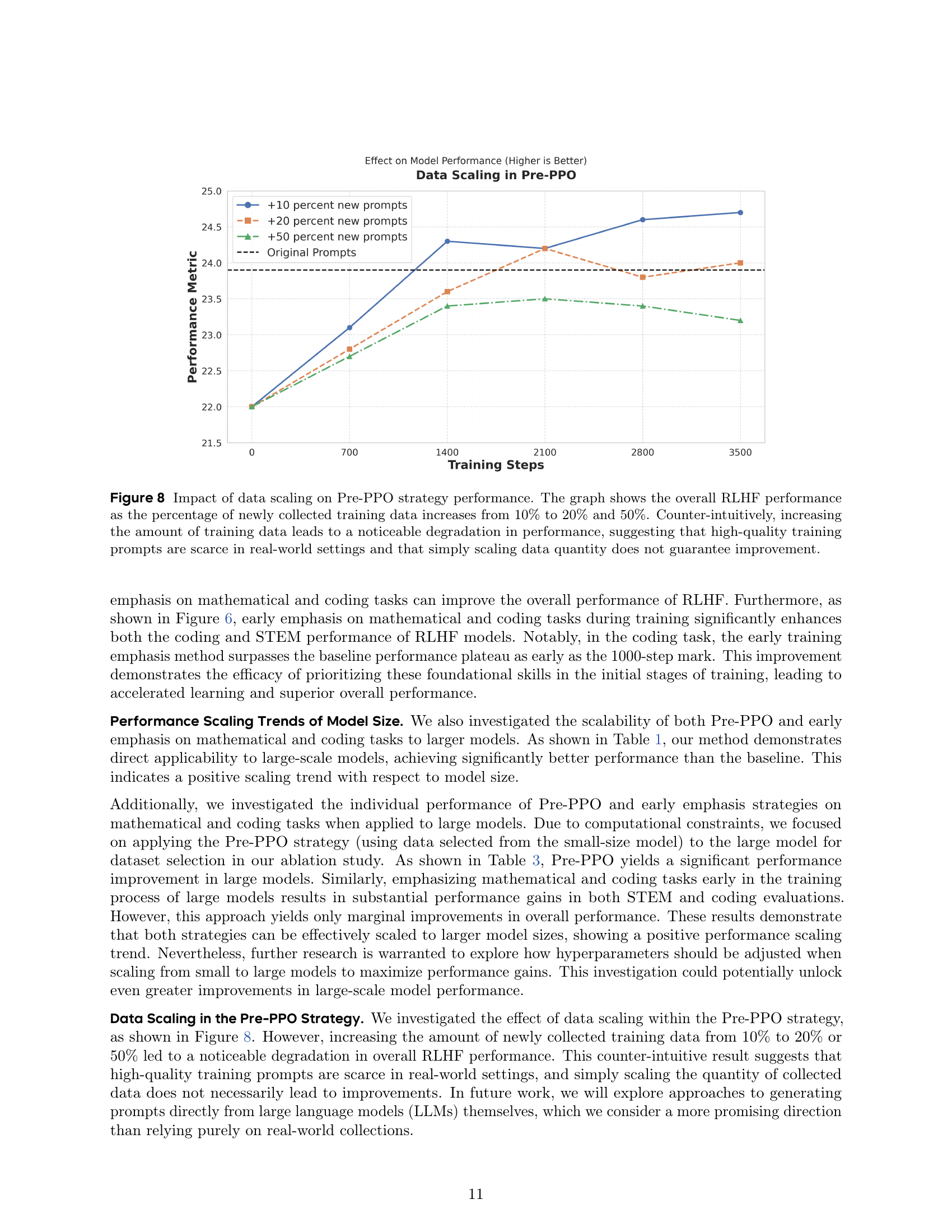
🔼 This figure displays the results of an experiment investigating the effect of increasing the amount of training data on the performance of the RLHF model using the Pre-PPO prompt selection strategy. The x-axis represents the percentage of newly collected prompts added to the original dataset (10%, 20%, and 50%), while the y-axis shows the overall RLHF performance. The results show a counter-intuitive trend: increasing the size of the training dataset, even with the Pre-PPO strategy, does not improve performance. Instead, it leads to a decrease in performance. This suggests that the quality of the training prompts is more important than the sheer quantity. In other words, simply adding more data may not improve the performance, and it may even hurt the performance if the additional data are low quality. This highlights the scarcity of high-quality training prompts in real-world scenarios and the need for carefully curated datasets.
read the caption
Figure 8: Impact of data scaling on Pre-PPO strategy performance. The graph shows the overall RLHF performance as the percentage of newly collected training data increases from 10% to 20% and 50%. Counter-intuitively, increasing the amount of training data leads to a noticeable degradation in performance, suggesting that high-quality training prompts are scarce in real-world settings and that simply scaling data quantity does not guarantee improvement.

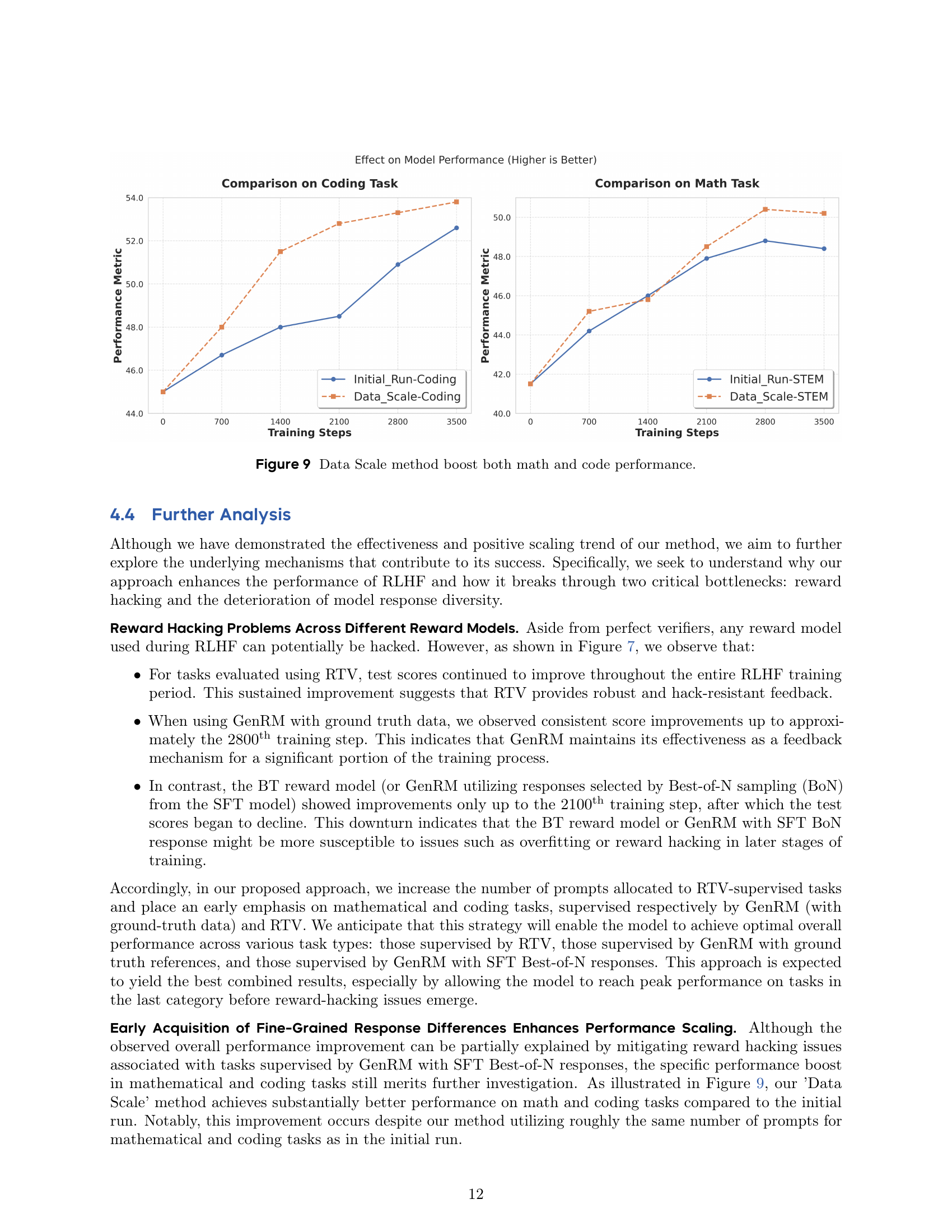
🔼 Figure 9 presents a comparison of the performance of coding and mathematical tasks between the baseline RLHF approach and the proposed ‘Data Scale’ method. The graph shows that the ‘Data Scale’ method, which combines Pre-PPO prompt selection and early emphasis on mathematical and coding tasks, leads to significantly improved performance on both task types compared to the baseline. Specifically, the ‘Data Scale’ method demonstrates faster and more substantial gains in performance over the training steps.
read the caption
Figure 9: Data Scale method boost both math and code performance.

🔼 This figure shows the relationship between reward model scores and the diversity of model responses. It compares the performance of two versions of the Generative Reward Model (GenRM): one trained with ground truth and one without. The x-axis represents the maximum edit distance among five model responses for a given prompt. A higher edit distance indicates less diversity in the responses. The y-axis displays the average normalized reward model score for each edit distance bin. The figure demonstrates that the GenRM trained with ground truth is more sensitive to fine-grained response variations (lower edit distances) and assigns higher scores when responses show higher diversity. In contrast, the GenRM without ground truth shows a less pronounced relationship between diversity and score, reflecting a lower sensitivity to finer distinctions between responses.
read the caption
Figure 10: Comparison of Reward Model Scores across Different Edit Distance Bins for GenRM with and without Ground Truth.

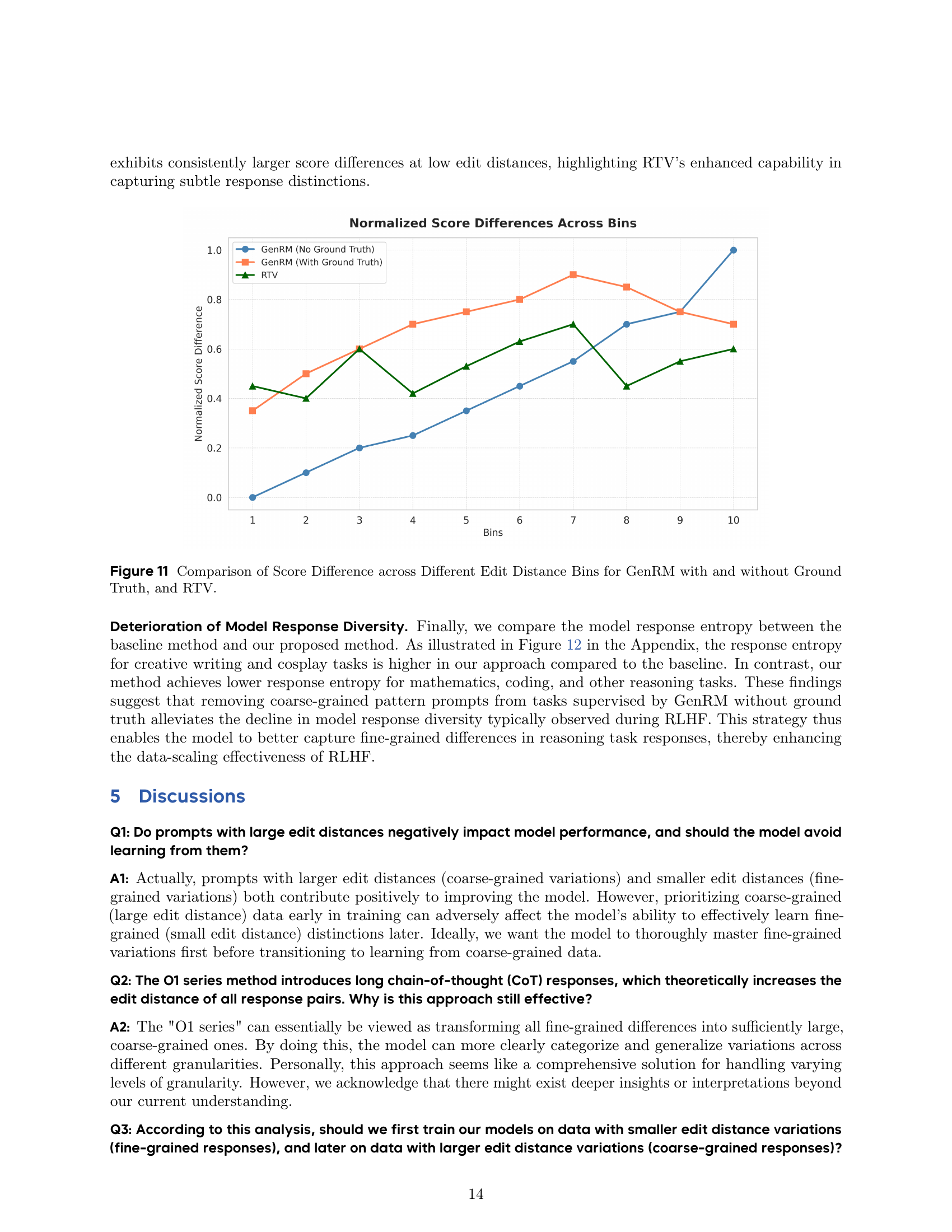
🔼 This figure compares the differences in reward scores assigned by three different reward models (GenRM with ground truth, GenRM without ground truth, and RTV) across various levels of response diversity. The x-axis represents bins of maximum edit distances between responses, indicating the granularity of response differences (smaller distances mean finer-grained distinctions). The y-axis shows the normalized score differences within each bin. The figure aims to illustrate how each reward model’s sensitivity to fine-grained response variations differs and whether that impacts the effectiveness of RLHF.
read the caption
Figure 11: Comparison of Score Difference across Different Edit Distance Bins for GenRM with and without Ground Truth, and RTV.

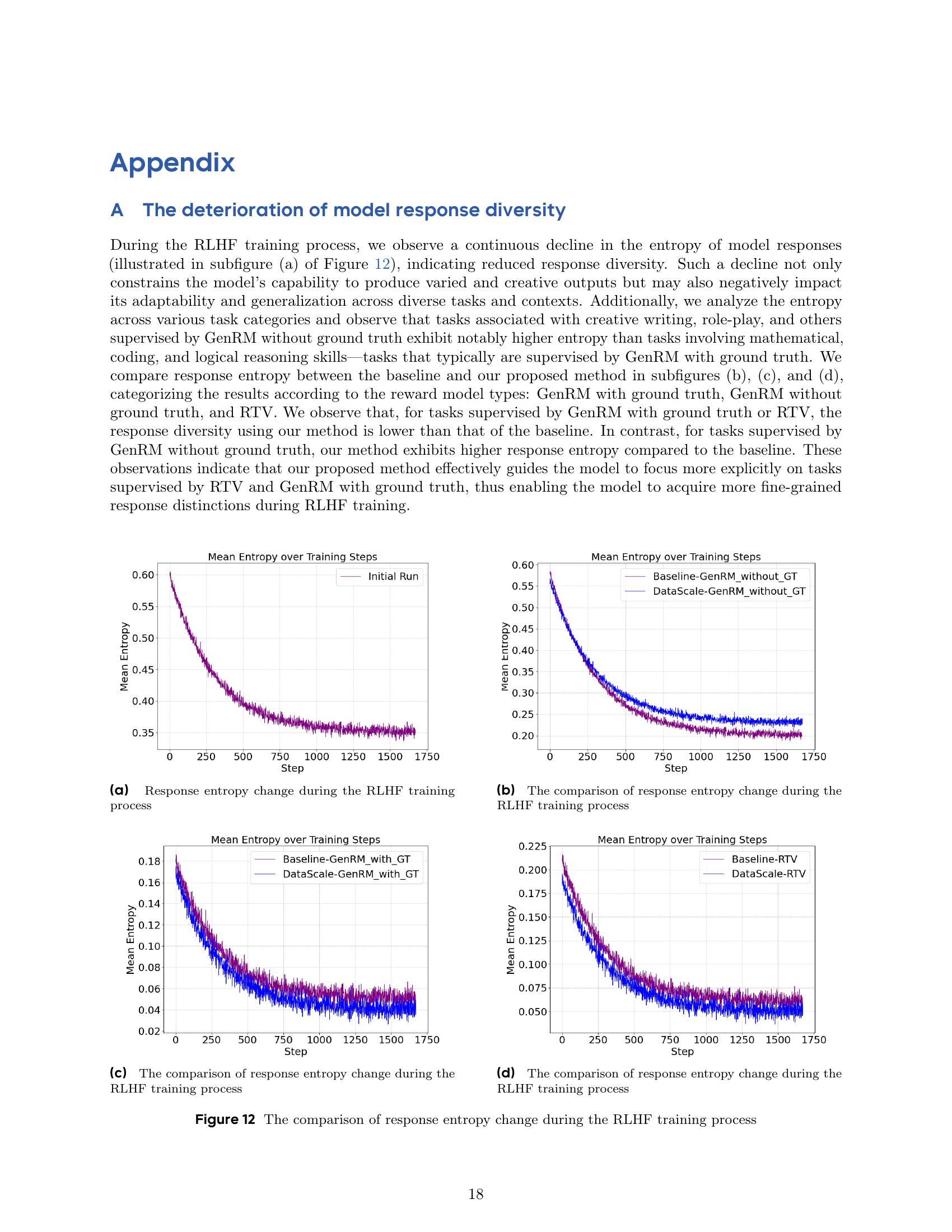
🔼 This figure illustrates the change in response entropy throughout the reinforcement learning from human feedback (RLHF) training process. Response entropy is a measure of the diversity of the model’s generated responses. A higher entropy indicates greater response diversity, while a lower entropy suggests less diversity, with the model tending to produce more similar responses. The x-axis represents the training steps, and the y-axis shows the response entropy at each step. The plot reveals how the diversity of the model’s responses changes over the course of RLHF training. This is a key metric to assess whether the training process is successfully improving the model’s ability to generate a wide range of responses or is narrowing its output over time.
read the caption
(a) Response entropy change during the RLHF training process

🔼 Figure 12(b) displays the change in response entropy during RLHF training for models using GenRM without ground truth. It compares the entropy of responses generated by the baseline RLHF model and the model trained using the improved method (DataScale). The x-axis represents training steps, while the y-axis represents the mean entropy across various responses. The plot visually demonstrates the impact of the proposed methods on maintaining response diversity throughout the training process.
read the caption
(b) The comparison of response entropy change during the RLHF training process

🔼 This figure compares the response entropy change during RLHF training between the baseline method and the proposed method. The response entropy is calculated separately for three different types of reward models: GenRM with ground truth, GenRM without ground truth, and RTV. The figure helps to analyze the impact of the proposed method on the response diversity of the model during training and how this method affects different types of reward models differently.
read the caption
(c) The comparison of response entropy change during the RLHF training process

🔼 Figure 12(d) displays the change in response entropy over the course of RLHF training, specifically focusing on the performance of the RTV reward model. The graph visually represents how the diversity of model responses evolves as training progresses. It allows for a comparison between the baseline model’s response diversity and the response diversity achieved by the model using the improved strategy. This comparison helps in evaluating the effectiveness of the proposed techniques in maintaining response diversity throughout the RLHF training process. The x-axis of the graph represents the training steps, while the y-axis corresponds to the mean response entropy.
read the caption
(d) The comparison of response entropy change during the RLHF training process

🔼 Figure 12 presents a detailed analysis of how response diversity changes during the Reinforcement Learning from Human Feedback (RLHF) training process. It visualizes the entropy of model responses across various task categories, offering insights into the impact of different reward models and training strategies. Subfigures (a) to (d) show the change in response entropy over training steps for tasks supervised by distinct reward methods: Generative Reward Model (GenRM) with ground truth, GenRM without ground truth, and Reasoning Task Verifiers (RTV). These subfigures provide a granular view of how response diversity evolves under different reward mechanisms and highlight the effects of the proposed data selection and prioritization strategies on response diversity across different task types. The figure illustrates a decline in overall response diversity during RLHF training but highlights the importance of careful data curation and strategic training to maintain diversity.
read the caption
Figure 12: The comparison of response entropy change during the RLHF training process
More on tables
| Method | Knowledge | STEM | IF | Creation | Coding | Overall |
|---|---|---|---|---|---|---|
| Baseline-Large | 63.3 | 76.7 | 46.7 | 52.1 | 24.8 | 67.2 |
| Data Scale-Large | 66.1 | 80.6 | 48.3 | 54.6 | 53.3 | 71.0 |
| Improvement | +1.1 | +6.1 | +1.7 | +5.8 | +4.4 | +4.4 |
| p-value | 0.01 | 0.41 | 0.04 | 0.39 | 0.09 | 0.12 |
🔼 This table presents a human evaluation comparing the performance of two RLHF methods: the proposed method (Pre-PPO with prioritized math and coding tasks) and a baseline PPO method. Evaluations were conducted across six abilities: Knowledge, STEM, Instruction-Following (IF), Creation, Coding, and an overall assessment. Statistically significant improvements (p<0.05) from the proposed method are highlighted in bold. All scores represent aggregated results from human raters.
read the caption
Table 2: Performance comparison based on comprehensive human evaluations between our proposed method (combining Pre-PPO and prioritizing mathematical and coding tasks first) and the baseline method (PPO-based RLHF). Results are shown across multiple abilities, including Knowledge, STEM, Instruction-Following (IF), Creation, Coding, and Overall performance. Improvements highlighted in bold indicate statistically significant differences (p < 0.05). All metrics represent aggregated scores from human assessments.
| Method | Logical | IF | STEM | Coding | NLP | Knowledge | CU | OOD | Overall |
|---|---|---|---|---|---|---|---|---|---|
| Reasoning | |||||||||
| Baseline-Large (V2.0) | 29.5 | 36.3 | 28.0 | 48.5 | 29.5 | 45.6 | 36.8 | 35.0 | 34.0 |
| Pre-PPO-Large (V2.0) | 31.3 | 35.9 | 30.8 | 49.5 | 32.3 | 45.7 | 36.1 | 37.9 | 35.1 |
| Improvement | +1.8 | -0.4 | +2.5 | +1.0 | +1.8 | +1.1 | -0.7 | +2.9 | +1.1 |
| Data Scale-Large (V2.0) | 31.2 | 36.4 | 31.9 | 50.7 | 32.3 | 45.5 | 36.6 | 37.1 | 35.4 |
| Improvement on Pre-PPO | -0.2 | +0.5 | +1.1 | +1.2 | +0.0 | -0.2 | +0.5 | -0.8 | +0.3 |
🔼 This ablation study investigates the individual contributions of two proposed strategies to the performance scaling of Reinforcement Learning from Human Feedback (RLHF) in large language models. The strategies are Pre-PPO, a prompt selection method, and an early training emphasis on mathematical and coding tasks. The table compares the performance across different evaluation metrics (Logical Reasoning, IF, STEM, Coding, NLP, Knowledge, CU, OOD, and Overall) of three different model configurations: the baseline model (no additional techniques), the model with Pre-PPO only, the model with early training emphasis only, and the model incorporating both Pre-PPO and early training emphasis. This allows for isolating and quantifying the effect of each strategy on various aspects of the model’s capabilities and their synergistic effect when combined.
read the caption
Table 3: Ablation Study: Performance Scaling of Pre-PPO and Early Training Emphasis in Large Language Models
Full paper#