TL;DR#
Moving object segmentation is vital for high-level visual scene understanding. Previous methods often rely on optical flow, which struggles with partial motion, complex deformations, and distractions. Humans effortlessly segment moving objects, inspiring the need for more robust automated solutions. Current solutions also struggle with differentiating camera vs. object motion and tracking objects through deformations, occlusions, and rapid movements.
To solve these issues, this paper presents a novel approach for moving object segmentation, integrating long-range trajectory motion cues with DINO-based semantic features. It leverages SAM2 for pixel-level mask densification via an iterative prompting strategy. The model uses Spatio-Temporal Trajectory Attention and Motion-Semantic Decoupled Embedding to prioritize motion while integrating semantic support, leading to superior performance.
Key Takeaways#
Why does it matter?#
This paper introduces an innovative method for moving object segmentation in videos, combining long-range trajectory cues with semantic features and SAM2 for precise mask generation. This approach outperforms existing methods, particularly in complex scenarios, offering new research directions in video understanding, autonomous systems, and human-computer interaction.
Visual Insights#

🔼 This figure showcases the robustness and accuracy of the proposed method for moving object segmentation. It demonstrates the ability to successfully segment moving objects even under challenging conditions such as articulated movements (e.g., a person running), shadow reflections obscuring object boundaries, dynamic background motion that could interfere with object detection, and rapid or significant camera movements. The resulting segmentation masks are fine-grained and accurately delineate the boundaries of individual moving objects.
read the caption
Figure 1: Our method is capable of handling challenging scenarios, including articulated structures, shadow reflections, dynamic background motion, and drastic camera movements, while producing per object level fine-grained moving object masks.
| Methods | Model Settings | DAVIS2016-Moving | SegTrackv2 | FBMS-59 | DAVIS2016 | |||||||
| Motion | Appearance | |||||||||||
| CIS [69] | Optical Flow | RGB | 66.2 | 67.6 | 64.8 | 62.0 | 63.6 | - | 68.6 | 70.3 | 66.8 | |
| EM [38] | Optical Flow | ✗ | 75.2 | 76.2 | 74.3 | 55.5 | 57.9 | 56.0 | 70.0 | 69.3 | 70.7 | |
| RCF-Stage1 [35] | Optical Flow | ✗ | 77.3 | 78.6 | 76.0 | 76.7 | 69.9 | - | 78.5 | 80.2 | 76.9 | |
| RCF-All [35] | Optical Flow | DINO | 79.6 | 81.0 | 78.3 | 79.6 | 72.4 | - | 80.7 | 82.1 | 79.2 | |
| OCLR-flow [60] | Optical Flow | ✗ | 70.0 | 70.0 | 70.0 | 67.6 | 65.5 | 64.9 | 71.2 | 72.0 | 70.4 | |
| OCLR-TTA [60] | Optical Flow | RGB | 78.5 | 80.2 | 76.9 | 72.3 | 69.9 | 68.3 | 78.8 | 80.8 | 76.8 | |
| ABR [61] | Optical Flow | DINO | 72.0 | 70.2 | 73.7 | 76.6 | 81.9 | 79.6 | 72.5 | 71.8 | 73.2 | |
| Ours | Trajectory | DINO | 89.5 | 89.2 | 89.7 | 76.3 | 78.3 | 82.8 | 90.9 | 90.6 | 91.0 | |
🔼 This table presents a quantitative comparison of different methods for moving object segmentation (MOS). The results are based on the MOS task where all foreground objects in a video are grouped together for evaluation. The comparison includes several metrics, providing a comprehensive assessment of the performance of each method on various datasets, including the J (Jaccard index) and F (Dice score) scores.
read the caption
Table 1: Quantitative comparison on MOS task which grouping all foreground objects together for evaluation.
In-depth insights#
Tracks & SAM2#
The paper introduces a novel approach combining long-range point tracks with SAM2 for moving object segmentation. Long-range tracks capture motion patterns & provide prompts for visual segmentation. SAM2 enables efficient mask densification & tracking across frames. A key innovation lies in an iterative prompting strategy, leveraging the identified dynamic tracks to guide SAM2 in generating precise moving object masks. By using the tracks to create memory and prompt SAM2 at regular intervals to avoid losing track of the object, which is an important step in generating complete masks.
Motion Emphasis#
Motion emphasis in video analysis is crucial for understanding scene dynamics. Prior research often relies on optical flow, but this method can struggle with occlusions or complex motion. The paper introduces an innovative approach to tackle these limitations, combining long-range trajectory motion cues with DINO-based semantic features and leveraging SAM2 for pixel-level mask densification. The model emphasizes motion cues while integrating semantic support, employing Spatio-Temporal Trajectory Attention and Motion-Semantic Decoupled Embedding to prioritize motion and incorporate semantic context. This approach is beneficial as it provides robustness against background clutter and motion blur, making it applicable to more challenging real-world scenarios. It also enhances the ability to differentiate between moving objects and static elements within the same semantic category. Overall, this provides a more reliable and accurate method for motion-based video analysis.
DINO Integration#
The paper leverages DINO features, likely extracted from a self-supervised model like DINOv2, to enhance moving object segmentation. DINO, pre-trained on large datasets, provides rich semantic information that complements motion cues. The integration addresses limitations of motion-based methods, which struggle with complex scenes or camera motion. The semantic context helps differentiate moving objects from static background and handles cases where motion alone is ambiguous. A key challenge is preventing the model from over-relying on semantics. The paper introduces a Motion-Semantic Decoupled Embedding to prioritize motion information while using semantics as a secondary cue. This decoupling is crucial for accurately segmenting moving objects even when they share semantic similarities with the background. Ablation studies demonstrate the importance of DINO integration, showing performance gains compared to models relying solely on motion or raw RGB data. Proper integration strategy is crucial, preventing semantic bias and ensuring robust segmentation across diverse scenarios.
Beyond Affinity#
Affinity-based methods for motion segmentation, while historically significant, often struggle with global consistency due to their reliance on local similarities. These methods, which typically employ techniques like spectral clustering on affinity matrices, are inherently sensitive to noise and can falter when faced with complex, dynamic motion patterns. Challenges arise from the difficulty in capturing motion similarities across diverse types, as affinity matrices may fail to represent the full spectrum of motion dynamics. These methods lack the ability to adapt to changing motion features over time, potentially leading to inaccurate and inconsistent segmentation results. Transitioning beyond affinity requires exploring new approaches that can capture long-range dependencies and integrate diverse cues in a more robust and adaptive manner, essential for enhancing the accuracy and reliability of motion segmentation.
No Perfect Tracks#
While “No Perfect Tracks” isn’t an explicit heading, it alludes to the core challenge in motion analysis. Real-world tracking is inherently imperfect. Occlusions, rapid movements, and changes in appearance inevitably lead to broken or noisy tracks. A robust motion segmentation system must therefore be resilient to such imperfections. This necessitates strategies for handling missing data, filtering out erroneous tracks, and inferring motion patterns from incomplete information. The algorithm should likely incorporate mechanisms for estimating track quality (confidence scores) and prioritizing reliable tracks over less certain ones. The system must also be able to leverage contextual information from nearby tracks or semantic cues to compensate for track imperfections and maintain accurate segmentation, even when individual tracks are unreliable. It must deal with situations where tracks are too short or simply terminate unexpectedly, as is often the case due to occlusions or objects leaving the field of view.
More visual insights#
More on figures

🔼 This figure demonstrates the superiority of long-range tracking over optical flow methods for moving object segmentation. It shows that as time elapses, factors like occlusion and changing lighting conditions can severely hinder the accuracy of optical flow-based tracking, while long-range tracking remains more robust. The graph visually compares the performance of the two methods over time, highlighting how long-range tracks maintain their effectiveness even when encountering challenging conditions that disrupt optical flow.
read the caption
Figure 2: The effectiveness of long-range tracks. Over longer periods of time, if a moving object experiences factors such as occlusion or changes in lighting, it can negatively affect the tracking performance of optical-flow-based methods for that object.
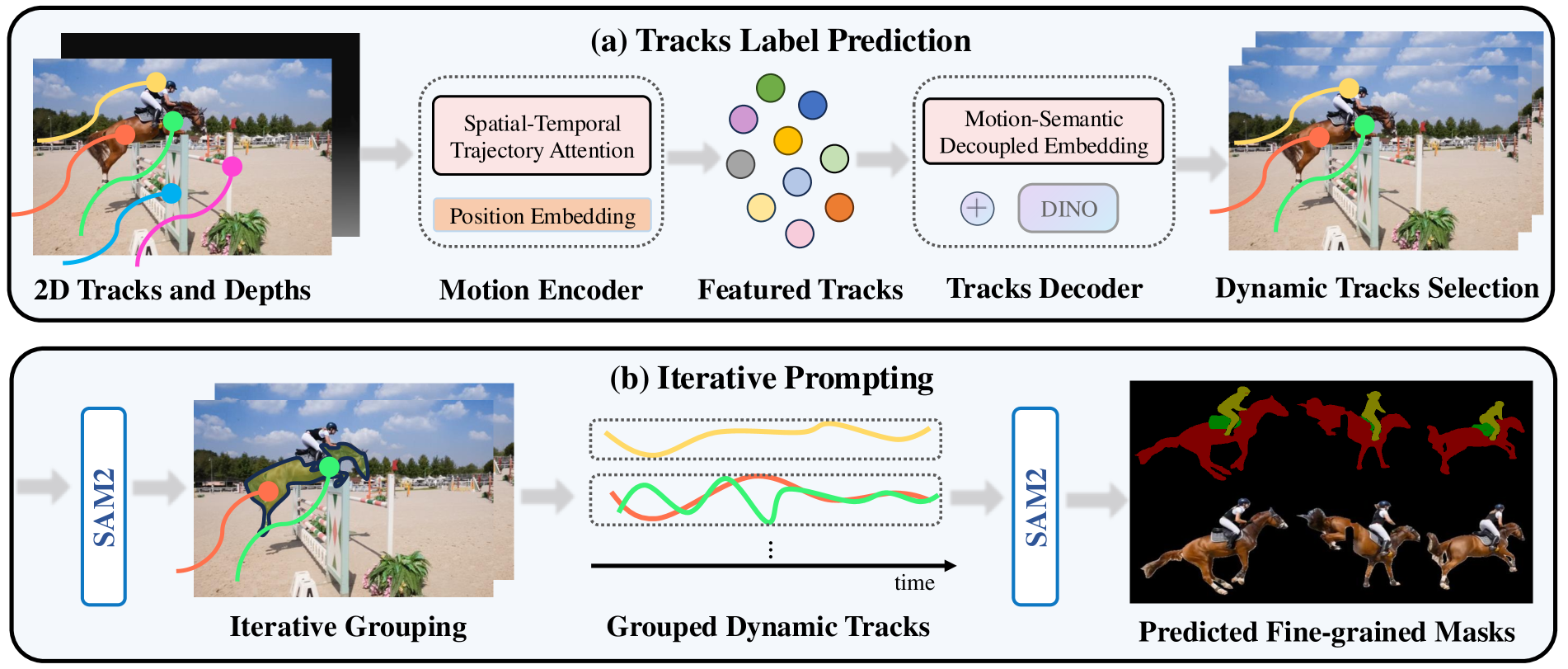
🔼 This figure illustrates the pipeline of the proposed method for moving object segmentation. It starts with 2D tracks and depth maps from external models as input. These are fed into a motion encoder to extract motion features, generating ‘featured tracks’. A tracks decoder, incorporating DINO features for semantic information, then processes these featured tracks, separating motion and semantic cues to identify dynamic trajectories. Finally, the identified trajectories are grouped using SAM2 to generate pixel-accurate masks for moving objects.
read the caption
Figure 3: Overview of Our Pipeline. We take 2D tracks and depth maps generated by off-the-shelf models [15, 66] as input, which are then processed by a motion encoder to capture motion patterns, producing featured tracks. Next, we use tracks decoder that integrates DINO feature [45] to decode the featured tracks by decoupling motion and semantic information and ultimately obtain the dynamic trajectories(a). Finally, using SAM2 [51], we group dynamic tracks belonging to the same object and generate fine-grained moving object masks(b).

🔼 Figure 4 presents a qualitative comparison of moving object segmentation results on the DAVIS17-moving benchmark dataset. Three challenging scenarios are highlighted: the left column showcases the successful segmentation of a moving object despite water reflections that would typically confuse simpler methods; the middle column demonstrates accurate segmentation of a camouflaged object, highlighting the model’s robustness to visual ambiguity; the right column shows accurate segmentation even with significant, drastic camera motion, proving the algorithm’s effectiveness under challenging conditions. Each row displays the ground truth mask (GT), followed by the masks generated by our proposed method and various other state-of-the-art methods.
read the caption
Figure 4: Qualitative comparison on DAVIS17-moving benchmarks. For each sequence we show moving object mask results. Our method successfully handles water reflections (left), camouflage appearances (middle), and drastic camera motion (right).

🔼 Figure 5 presents a qualitative comparison of moving object segmentation results on the FBMS-59 benchmark dataset. It visually demonstrates that the proposed method generates masks that are more geometrically complete and detailed compared to several baseline methods. The figure showcases examples where the model’s output provides more accurate and precise boundaries for moving objects, capturing fine details that are missed by other approaches.
read the caption
Figure 5: Qualitative comparison on FBMS-59 benchmarks. The masks produced by us are geometrically more complete and detailed.

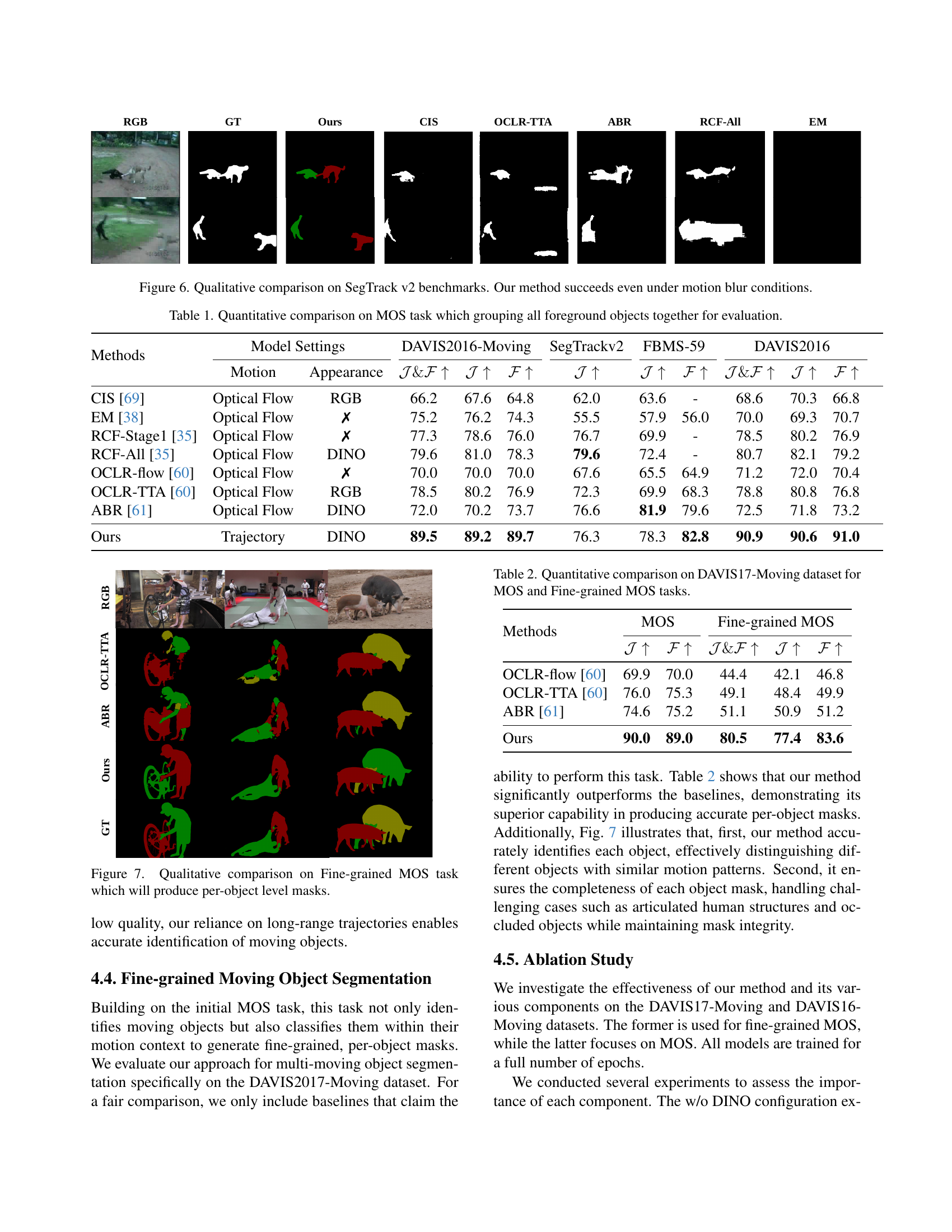
🔼 Figure 6 presents a qualitative comparison of moving object segmentation results on the SegTrack v2 benchmark dataset. The figure visually demonstrates the performance of the proposed method (Ours) against several other state-of-the-art techniques (GT, CIS, OCLR-TTA, ABR, RCF-All, EM). Each column shows the ground truth segmentation mask (GT), followed by the segmentation masks generated by each method, including the authors’ proposed method. This allows for a direct visual comparison of the accuracy and robustness of different approaches. The figure highlights the effectiveness of the proposed method in handling challenging conditions, particularly those involving significant motion blur, a scenario where other techniques often struggle. The figure showcases improved segmentation accuracy even in challenging scenarios like those with motion blur.
read the caption
Figure 6: Qualitative comparison on SegTrack v2 benchmarks. Our method succeeds even under motion blur conditions.

🔼 Figure 7 displays a qualitative comparison of fine-grained moving object segmentation results. It showcases the per-object level mask generation capabilities of the proposed model, highlighting its ability to produce detailed and accurate masks for each individual object, even in complex scenarios with multiple interacting objects. This contrasts with methods that only produce a single mask for all moving objects.
read the caption
Figure 7: Qualitative comparison on Fine-grained MOS task which will produce per-object level masks.

🔼 This figure presents a qualitative comparison of ablation study results on challenging scenarios. The top row shows the results on sequences with drastic camera motion and complex motion patterns, highlighting the impact of different components of the proposed model. The bottom row showcases results when both static and dynamic objects of the same category are present, demonstrating the model’s ability to differentiate between them. The detailed experimental setup can be found in Section 4.5 of the paper.
read the caption
Figure 8: Visual comparison for the ablation study on two critical and challenging cases. The top sequence shows scenarios involves drastic camera motion and complex motion patterns, while the bottom sequence with both static and dynamic objects of the same category. The experimental setup is detailed in Sec. 4.5.
More on tables
| Methods | MOS | Fine-grained MOS | |||
| OCLR-flow [60] | 69.9 | 70.0 | 44.4 | 42.1 | 46.8 |
| OCLR-TTA [60] | 76.0 | 75.3 | 49.1 | 48.4 | 49.9 |
| ABR [61] | 74.6 | 75.2 | 51.1 | 50.9 | 51.2 |
| Ours | 90.0 | 89.0 | 80.5 | 77.4 | 83.6 |
🔼 Table 2 presents a quantitative comparison of different methods for moving object segmentation on the DAVIS17-Moving dataset. It assesses performance on two distinct tasks: standard Moving Object Segmentation (MOS), where all foreground moving objects are grouped together for evaluation; and Fine-grained MOS, which requires the accurate segmentation of individual moving objects. The table shows the J and F scores for each method on both tasks, allowing for a detailed comparison of accuracy in segmenting moving objects at both a coarse and fine level of granularity.
read the caption
Table 2: Quantitative comparison on DAVIS17-Moving dataset for MOS and Fine-grained MOS tasks.
| Methods | DAVIS17-Moving | DAVIS16-Moving | ||||
| w/o Depth | 69.2 | 65.6 | 72.8 | 82.5 | 78.6 | 86.4 |
| w/o Tracks | 19.6 | 14.5 | 24.7 | 20.9 | 9.8 | 31.9 |
| w/o DINO | 65.0 | 62.1 | 67.9 | 75.5 | 71.4 | 79.5 |
| w/o MOE | 72.0 | 68.7 | 75.4 | 81.8 | 81.0 | 82.7 |
| w/o MSDE | 63.0 | 59.3 | 66.7 | 78.2 | 77.3 | 79.1 |
| w/o PE | 66.4 | 64.7 | 68.2 | 82.0 | 81.5 | 82.5 |
| w/o ST-ATT | 65.5 | 61.9 | 69.1 | 78.3 | 74.3 | 82.4 |
| Ours-full | 80.5 | 77.4 | 83.6 | 89.1 | 89.0 | 89.2 |
🔼 This table presents the results of an ablation study evaluating the impact of different components of the proposed model on the DAVIS17-Moving and DAVIS16-Moving datasets. The DAVIS17-Moving dataset assesses fine-grained moving object segmentation (per-object masks), while DAVIS16-Moving evaluates standard moving object segmentation (grouping all moving objects together). The table shows the performance (J&F scores and Intersection over Union (IoU) scores) when removing different model components, such as depth information, long-range tracks, DINO features, the motion-only encoding module, motion-semantic decoupled embedding, positional encoding, and spatio-temporal attention. This allows for a quantitative analysis of the contribution of each component to the overall model performance.
read the caption
Table 3: Quantitative comparison for the ablation study on the DAVIS17-Moving and DAVIS16-Moving benchmarks, which evaluate fine-grained MOS and MOS tasks, respectively. The experimental setup is detailed in Sec. 4.5.
Full paper#