TL;DR#
Current methods for Human-Scene Interactions (HSI) often use separate controllers for specific tasks, limiting their ability to handle complex tasks requiring multiple skills. Existing unified controllers also struggle with dynamic scenarios and adapting to novel scenes, constraining their adaptability.
This paper introduces a single, unified, transformer-based policy called TokenHSI capable of multi-skill unification and flexible adaptation. It models the humanoid proprioception as a separate shared token combined with distinct task tokens via a masking mechanism. The framework can adapt to new tasks by training additional task tokenizers. Experiments demonstrate significantly improved versatility, adaptability, and extensibility in various HSI tasks.
Key Takeaways#
Why does it matter?#
This paper is important for researchers because it presents a novel framework TokenHSI for synthesizing human-scene interactions. The method’s versatility, adaptability, and extensibility improve the way of modeling and learning HSI tasks. It opens new avenues for creating more realistic and interactive virtual environments, impacting fields such as computer animation, robotics, and embodied AI.
Visual Insights#

🔼 TokenHSI is a unified model that allows physics-based characters to perform a wide variety of human-scene interaction (HSI) tasks. The model uses task tokenization to integrate multiple foundational HSI skills into a single transformer network. This design enables seamless integration and flexible adaptation of learned skills to novel and complex tasks including skill composition (combining multiple skills), handling variations in object and terrain shapes, and completing long-horizon tasks (tasks requiring a sequence of actions over an extended period).
read the caption
Figure 1: Introducing TokenHSI, a unified model that enables physics-based characters to perform diverse human-scene interaction tasks. It excels at seamlessly unifying multiple foundational HSI skills within a single transformer network and flexibly adapting learned skills to challenging new tasks, including skill composition, object/terrain shape variation, and long-horizon task completion.
| Task | Method | Success Rate (%) | Error (cm) |
|---|---|---|---|
| Follow | Specialist | 98.70.5 | 6.50.0 |
| Ours (w/o ) | 99.30.3 | 9.70.2 | |
| Ours | 99.70.0 | 9.30.1 | |
| Sit | Specialist | 98.22.0 | 5.60.0 |
| Ours (w/o ) | 98.70.4 | 5.60.1 | |
| Ours | 99.60.2 | 5.60.2 | |
| Climb | Specialist | 99.70.1 | 2.40.2 |
| Ours (w/o ) | 99.50.2 | 3.10.8 | |
| Ours | 99.80.1 | 2.70.3 | |
| Carry | Specialist | 83.15.0 | 5.10.2 |
| Ours (w/o ) | 90.93.3 | 6.00.5 | |
| Ours | 92.26.7 | 4.20.6 |
🔼 This table presents a quantitative comparison of the performance of a unified multi-task policy versus specialist policies trained for individual tasks. The comparison is made across four fundamental Human-Scene Interaction (HSI) skills: following a path, sitting down, climbing, and carrying an object. The success rate and error (in centimeters) are reported for each skill and method, with values presented as mean ± standard deviation (std). This allows for a direct comparison of the unified approach’s ability to learn multiple skills simultaneously versus the performance achieved by models trained individually for each specific task.
read the caption
Table 1: Quantitative comparison between our unified multi-task policy and specialist policies across four foundational HSI skills. Values are reported in the format of mean±plus-or-minus\pm±std.
In-depth insights#
Tokenized HSI#
The concept of “Tokenized HSI” appears to be central to the paper, suggesting a method where Human-Scene Interactions (HSI) are represented and processed using tokens. This likely involves discretizing the state space of the character and the scene into tokens that a transformer-based model can understand. The approach could involve separate tokens for proprioception and task-specific goals. This enables a unified model that can handle diverse HSI tasks. Tokenization may offer advantages in terms of modularity and transferability, allowing the model to adapt to new tasks by simply adding or modifying task-specific tokens. It facilitates knowledge sharing and generalization across different skills, as well as adaptation to novel tasks, object variations, and complex environments by training new tokenizers. Effective token design is key.
Unified Control#
Unified control in HSI is a pivotal yet challenging area. The goal is to create a single controller adept at diverse interactions, moving beyond task-specific solutions. This controller should manage varied skills (like sitting, carrying) and adapt to new environments, bridging the gap between simulated and real-world agent capabilities. Key hurdles include designing architectures that unify multiple skills, handling dynamic environments requiring manipulation, and ensuring the transferability of learned skills to novel scenarios efficiently. Addressing these challenges could revolutionize simulated character interactions, enabling more versatile and adaptable AI agents. This requires a shift towards models that can not only execute individual tasks but also coordinate them seamlessly, opening new avenues for complex, realistic simulations.
Task Tokenization#
While the term “Task Tokenization” isn’t explicitly present as a heading, the paper revolves around a similar concept: representing various HSI tasks as distinct, modular units or ’tokens’ within a unified framework. The core idea is to encode both the humanoid’s proprioception and task-specific information into separate tokens, enabling the model to process them in a shared latent space. This approach fosters knowledge transfer across different skills, allowing the network to learn more efficiently and generalize better. The masking mechanism in the transformer architecture plays a crucial role, selectively combining the proprioception token with the appropriate task token to guide the character’s actions. This design facilitates multi-task training and flexible adaptation to new scenarios by adding task specific tokens. The effectiveness of this tokenization strategy is demonstrated through experiments involving skill composition, object/terrain shape variation, and long-horizon task completion, showcasing the model’s ability to seamlessly integrate diverse skills and adapt to novel situations.
Adaptation’s Key#
The concept of ‘Adaptation’s Key’ in a research paper context likely refers to the critical elements enabling a model or system to adjust and perform well in new, unseen environments or tasks. A key aspect involves the generalization capability of learned features, allowing the system to apply prior knowledge effectively. Efficient adaptation often hinges on modular design, where specific components can be modified or added without retraining the entire system. Crucially, ‘Adaptation’s Key’ involves a balance between stability and plasticity, ensuring the model retains previously acquired skills while adapting to new demands. Another component can be the identification of invariant features that remain consistent across different scenarios, allowing the model to focus on adapting to the changing aspects of the environment. Effective meta-learning strategies can also play a significant role, enabling the system to learn how to learn and adapt more quickly. Finally, the method to effectively encode proprioception helps policy to make more flexible adaption.
Limits & Future#
Looking at the work, some limitations involve reliance on engineered reward functions, a common hurdle in RL. Future work could explore methods leveraging human data or internet knowledge to reduce reliance on them. Also, the current long-horizon task completion is not fully autonomous. A next step would be a system where the simulated humanoids can complete complex, long-term tasks in realistic settings without external assistance, an open and interesting direction to explore. This suggests a future where reward engineering is minimized through imitation or learning from readily available data, and where the agent exhibits a higher degree of autonomy and planning capability.
More visual insights#
More on figures

🔼 TokenHSI’s architecture is a two-stage process. The first stage focuses on foundational skill learning where a unified transformer network learns diverse human-scene interaction (HSI) skills through multi-task training. The second stage involves policy adaptation where these learned skills are flexibly adapted to handle more challenging HSI tasks. This adaptation is efficient as it only requires training lightweight components: new task tokenizers (for example, Tnew), and adapter layers (ξA) which are added to the action head. The existing tokenizer for proprioception (Tprop) and encoder (ϕ) are reused and kept frozen.
read the caption
Figure 2: TokenHSI consists of two stages: (left) foundational skill learning and (right) policy adaptation. Through multi-task policy training, the proposed framework learns versatile interaction skills in a single transformer network. Theses learned skills can be flexibly adapted to more challenging HSI tasks by training the lightweight modules, e.g., 𝕋newsuperscript𝕋𝑛𝑒𝑤\mathbb{T}^{new}blackboard_T start_POSTSUPERSCRIPT italic_n italic_e italic_w end_POSTSUPERSCRIPT, 𝕋csuperscript𝕋𝑐\mathbb{T}^{c}blackboard_T start_POSTSUPERSCRIPT italic_c end_POSTSUPERSCRIPT, and ξ𝔸={ξ0𝔸,ξ1𝔸}superscript𝜉𝔸subscriptsuperscript𝜉𝔸0subscriptsuperscript𝜉𝔸1\xi^{\mathbb{A}}=\{\xi^{\mathbb{A}}_{0},\xi^{\mathbb{A}}_{1}\}italic_ξ start_POSTSUPERSCRIPT blackboard_A end_POSTSUPERSCRIPT = { italic_ξ start_POSTSUPERSCRIPT blackboard_A end_POSTSUPERSCRIPT start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT , italic_ξ start_POSTSUPERSCRIPT blackboard_A end_POSTSUPERSCRIPT start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT }.
🔼 Figure 3 presents a comparison of training efficiency across different methods for skill composition tasks. The learning curves show the success rate (or a related metric reflecting task performance) over the number of training iterations. Four methods are compared: TokenHSI, a model trained from scratch (Scratch), the original CML method, and an improved version of CML (CML Dual). The shaded regions around each curve indicate the standard deviation of results across three separate runs, each initialized with different random seeds, providing a measure of variability and confidence in the results. This helps to illustrate how quickly each method learns to perform the skill composition tasks and the relative stability of each approach’s performance.
read the caption
Figure 3: Learning curves comparing the efficiency on skill composition tasks using TokenHSI, policies trained from scratch [79], CML [108], and its improved version CML (dual). Colored regions denote mean values ±plus-or-minus\pm± a standard deviation based on 3333 models initialized with different random seeds.

🔼 This figure showcases the adaptability of the TokenHSI model. It demonstrates how foundational skills (learned in a simpler setting) are successfully generalized to more complex and diverse human-scene interaction tasks through the process of policy adaptation. The six subfigures illustrate examples of skill composition (combining multiple skills), object shape variation (adapting to differently-shaped objects), terrain shape variation (navigating uneven terrain), and long-horizon task completion (executing a sequence of tasks). Each subfigure visually presents a physics-based character performing the specified challenging interaction successfully.
read the caption
Figure 4: Through policy adaptation, TokenHSI can generalize learned foundational skills to more challenging scene interaction tasks.

🔼 Figure 5 presents a comparison of training efficiency across three different methods for adapting a pre-trained box-carrying policy to handle novel object shapes (chairs and tables). The learning curves illustrate how quickly each method achieves high success rates. The methods compared are: TokenHSI (the proposed method), full fine-tuning of the pre-trained policy (a common approach which requires retraining the entire model), and AdaptNet [109] (a state-of-the-art policy adaptation method). The x-axis represents the number of training iterations, and the y-axis represents the success rate. The figure demonstrates TokenHSI’s superior efficiency in adapting to new object shapes compared to the other two methods.
read the caption
Figure 5: Learning curves comparing the efficiency on object shape variation tasks using TokenHSI, full fine-tuning of pre-trained policies, and AdaptNet [109].

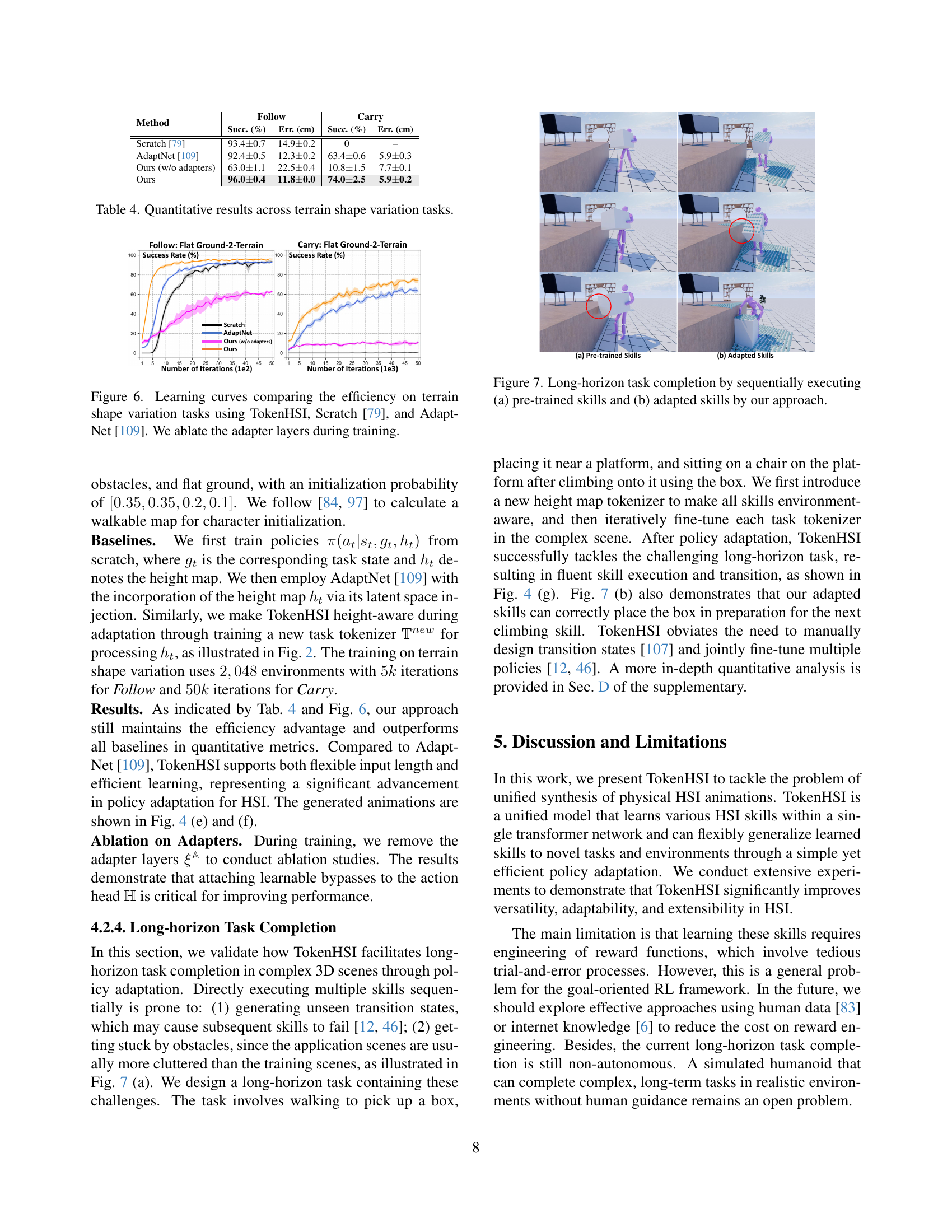
🔼 Figure 6 presents learning curves that compare the training efficiency of three different methods for adapting a physics-based character controller to handle terrain with varying shapes. The three methods are TokenHSI, Scratch [79] (a method that trains a new policy from scratch), and AdaptNet [109] (a method that incrementally adapts a pre-trained policy). The curves show the success rate achieved by each method over a range of training iterations. Importantly, the figure also includes results for TokenHSI where the adapter layers (a component designed to improve efficiency of adaptation) have been removed, demonstrating their contribution to the model’s overall performance.
read the caption
Figure 6: Learning curves comparing the efficiency on terrain shape variation tasks using TokenHSI, Scratch [79], and AdaptNet [109]. We ablate the adapter layers during training.

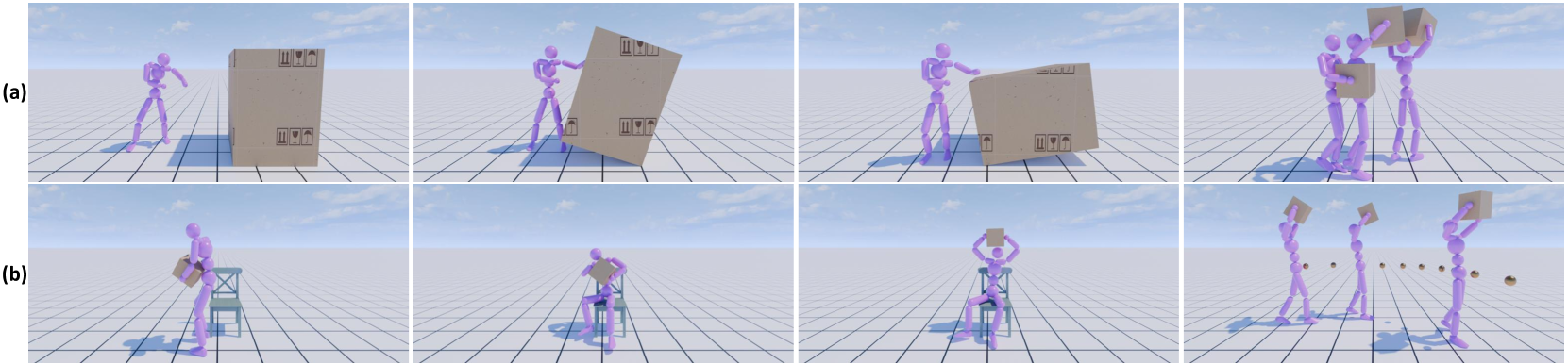
🔼 This figure demonstrates the capability of the TokenHSI model to perform a complex, long-horizon task involving multiple skills. Subfigure (a) shows the execution of the task using only pre-trained skills, highlighting potential limitations due to the lack of adaptation to the specific environment and task complexities. Subfigure (b) shows the improved performance after policy adaptation, where TokenHSI successfully executes the task sequentially and seamlessly transitions between skills. This showcases the model’s ability to adapt to novel scenarios and handle complex tasks that involve integrating multiple skills in a dynamic and coordinated manner.
read the caption
Figure 7: Long-horizon task completion by sequentially executing (a) pre-trained skills and (b) adapted skills by our approach.

🔼 This figure showcases three variations of a simulated character model used in the paper’s experiments. Model (a) is based on the AMP model. The authors improved upon this design in two ways, resulting in models (b) and (c). Model (b) is optimized for tasks performed on flat ground, while model (c) is specifically designed for tasks involving stairs or uneven terrain, reflecting differences in foot geometry and collision detection capabilities necessary for realistic interaction with stairs.
read the caption
Figure A: Different simulated character models. Building on (a) AMP’s model, we devise two improved versions: (b) and (c), which are used for tasks on flat ground and tasks on stairs terrain, respectively.
🔼 Figure B shows the learning curves for a long-horizon task, comparing three different approaches: TokenHSI, Scratch [79], and Finetune. The x-axis represents the number of training iterations, while the y-axis indicates the number of completed sub-tasks within the long-horizon task. The plot illustrates the training efficiency of each method. TokenHSI demonstrates faster convergence and achieves a higher number of completed subtasks compared to the other two approaches. This highlights the effectiveness of TokenHSI in learning complex, multi-stage tasks efficiently.
read the caption
Figure B: Learning curves comparing the efficiency on long-horizon task completion using TokenHSI, Scratch [79], and iterative fine-tuning of multiple pre-trained specialist policies, namely Finetune.
More on tables
| Method | Follow + Carry | Sit + Carry | Climb + Carry | |||
|---|---|---|---|---|---|---|
| Succ. (%) | Err. (cm) | Succ. (%) | Err. (cm) | Succ. (%) | Err. (cm) | |
| Scratch [79] | 98.10.7 | 12.50.1 | 82.95.0 | 5.90.1 | 26.837.8 | 5.74.8 |
| CML [108] | 97.60.8 | 9.90.0 | 96.70.6 | 6.20.2 | 68.321.9 | 4.80.5 |
| CML (dual) | 99.10.2 | 10.00.0 | 94.92.0 | 5.90.0 | 51.340.2 | 9.17.3 |
| Ours (w/o ) | 99.20.5 | 11.50.2 | 82.04.2 | 6.90.9 | 81.99.0 | 5.00.5 |
| Ours | 99.10.4 | 10.80.3 | 96.31.1 | 5.50.0 | 99.20.1 | 3.50.1 |
🔼 This table presents a quantitative comparison of different methods for performing skill composition tasks in human-scene interaction. It compares the success rates and errors of three different skill combinations: Follow + Carry, Sit + Carry, and Climb + Carry. The methods compared include a specialist policy (trained only on that specific task), the proposed TokenHSI method, and two versions of the CML method, one with single and one with dual specialists. The results show how TokenHSI achieves high success rates and low errors even on complex tasks, demonstrating its efficiency and effectiveness in skill composition compared to existing approaches.
read the caption
Table 2: Quantitative results across skill composition tasks.
| Object | Method | Success Rate (%) | Error (cm) |
|---|---|---|---|
| Chair | Finetune | 87.50.6 | 6.40.2 |
| AdaptNet [109] | 84.53.0 | 6.80.5 | |
| Ours | 88.83.1 | 5.60.2 | |
| Table | Finetune | 83.41.6 | 6.00.1 |
| AdaptNet [109] | 82.43.9 | 6.40.3 | |
| Ours | 83.61.6 | 6.30.2 |
🔼 This table presents a quantitative comparison of different methods for adapting a physics-based character controller to handle variations in object shape during human-scene interaction tasks. It shows the success rate and error achieved by three different approaches: a method that fully fine-tunes a pre-trained model (‘Finetune’), AdaptNet (a state-of-the-art model for policy adaptation), and the proposed TokenHSI method. The results are presented for two different object types: chairs and tables. The metrics assess the ability of each method to successfully carry a box to a target location while adapting to the new object geometries. This comparison demonstrates the generalization capacity of each controller in scenarios with varying object shapes.
read the caption
Table 3: Quantitative results across object shape variation tasks.
| Method | Follow | Carry | ||
|---|---|---|---|---|
| Succ. (%) | Err. (cm) | Succ. (%) | Err. (cm) | |
| Scratch [79] | 93.40.7 | 14.90.2 | 0 | – |
| AdaptNet [109] | 92.40.5 | 12.30.2 | 63.40.6 | 5.90.3 |
| Ours (w/o adapters) | 63.01.1 | 22.50.4 | 10.81.5 | 7.70.1 |
| Ours | 96.00.4 | 11.80.0 | 74.02.5 | 5.90.2 |
🔼 This table presents a quantitative comparison of different methods for adapting character control policies to handle terrain variations. It shows the success rate and error (in centimeters) for the ‘Follow’ and ‘Carry’ tasks across different terrain types, comparing the proposed method (TokenHSI) against the baseline methods of Scratch and AdaptNet. The results highlight TokenHSI’s effectiveness in adapting to more challenging scenarios with greater success and lower error compared to the baselines, illustrating the robustness and efficiency of its policy adaptation technique. The ‘Ours (w/o adapters)’ row shows results without the adapter layers used in TokenHSI’s policy adaptation.
read the caption
Table 4: Quantitative results across terrain shape variation tasks.
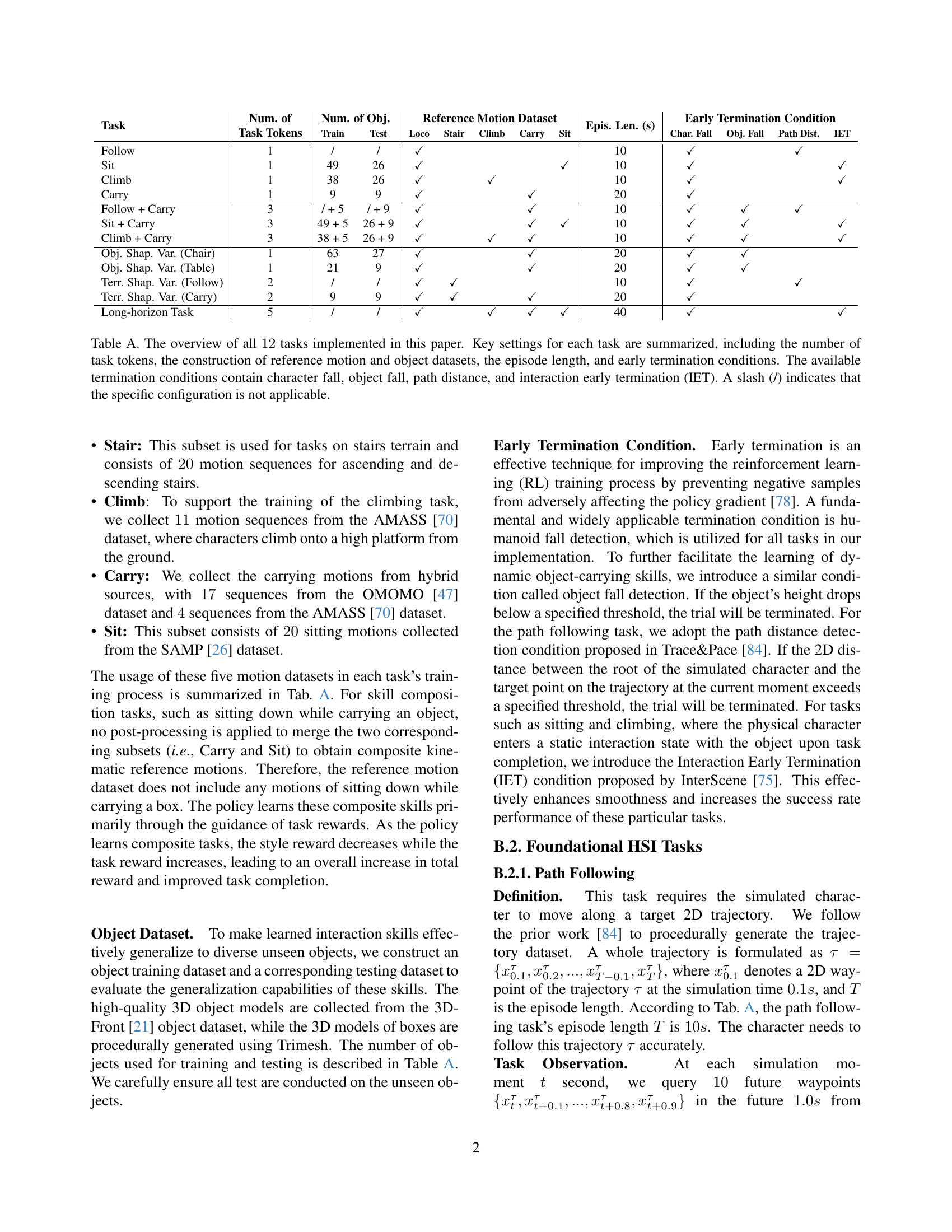
| Task | Num. of | Num. of Obj. | Reference Motion Dataset | Epis. Len. (s) | Early Termination Condition | ||||||||
| Task Tokens | Train | Test | Loco | Stair | Climb | Carry | Sit | Char. Fall | Obj. Fall | Path Dist. | IET | ||
| Follow | 1 | / | / | ✓ | 10 | ✓ | ✓ | ||||||
| Sit | 1 | 49 | 26 | ✓ | ✓ | 10 | ✓ | ✓ | |||||
| Climb | 1 | 38 | 26 | ✓ | ✓ | 10 | ✓ | ✓ | |||||
| Carry | 1 | 9 | 9 | ✓ | ✓ | 20 | ✓ | ||||||
| Follow + Carry | 3 | / + 5 | / + 9 | ✓ | ✓ | 10 | ✓ | ✓ | ✓ | ||||
| Sit + Carry | 3 | 49 + 5 | 26 + 9 | ✓ | ✓ | ✓ | 10 | ✓ | ✓ | ✓ | |||
| Climb + Carry | 3 | 38 + 5 | 26 + 9 | ✓ | ✓ | ✓ | 10 | ✓ | ✓ | ✓ | |||
| Obj. Shap. Var. (Chair) | 1 | 63 | 27 | ✓ | ✓ | 20 | ✓ | ✓ | |||||
| Obj. Shap. Var. (Table) | 1 | 21 | 9 | ✓ | ✓ | 20 | ✓ | ✓ | |||||
| Terr. Shap. Var. (Follow) | 2 | / | / | ✓ | ✓ | 10 | ✓ | ✓ | |||||
| Terr. Shap. Var. (Carry) | 2 | 9 | 9 | ✓ | ✓ | ✓ | 20 | ✓ | |||||
| Long-horizon Task | 5 | / | / | ✓ | ✓ | ✓ | ✓ | 40 | ✓ | ✓ | |||
🔼 Table A provides a comprehensive overview of the twelve tasks used in the study. For each task, it details key settings such as the number of task tokens, the datasets used for reference motion and objects, the length of each episode, and the early termination conditions. Early termination conditions include character falls, object falls, exceeding path distance, and interaction early termination (IET). A ‘/’ indicates that a particular setting isn’t applicable to a given task.
read the caption
Table A: The overview of all 12121212 tasks implemented in this paper. Key settings for each task are summarized, including the number of task tokens, the construction of reference motion and object datasets, the episode length, and early termination conditions. The available termination conditions contain character fall, object fall, path distance, and interaction early termination (IET). A slash (/) indicates that the specific configuration is not applicable.
Full paper#