TL;DR#
Generating 3D meshes from text prompts is challenging because of insufficient high-quality 3D training data. Existing methods adapting text-to-image diffusion models for 3D often yield poor results. This is due to the limited size and quality of available 3D datasets, which affects the models’ ability to generalize across diverse textual descriptions and produce consistent 3D outputs. These models need multi-view consistent, better texture and geometry.
To solve this, this paper introduces Progressive Rendering Distillation (PRD). This approach adapts Stable Diffusion for native 3D generation without 3D ground truths by distilling knowledge from multi-view diffusion models. PRD incorporates Parameter-Efficient Triplane Adaptation (PETA) which adds only 2.5% trainable parameters to the frozen SD, allowing efficient adaptation for 3D generation. This leads to TriplaneTurbo, it surpasses existing methods in both quality and speed, by generating textured 3D meshes in approximately 1.2 seconds.
Key Takeaways#
Why does it matter?#
This paper is important for researchers because it addresses the data scarcity issue in text-to-3D mesh generation by using a novel Progressive Rendering Distillation (PRD) training scheme. It also introduces Parameter-Efficient Triplane Adaptation (PETA), which reduces computational costs and enables high-quality 3D mesh generation with shorter time, opening new directions for future research. Thus, other related generation tasks can be inspired.
Visual Insights#

🔼 This figure showcases the high-fidelity textured 3D mesh models generated by the proposed method, Progressive Rendering Distillation (PRD). The models are created from text prompts in just 1.2 seconds, demonstrating the speed and quality of the method. The examples show diverse and complex scenes, indicating the model’s ability to handle challenging inputs and generate realistic outputs.
read the caption
Figure 1: Our method adapts Stable Diffusion [89] to generate high-fidelity textured meshes in 1.2 seconds.
| C.S. | R@1 | Latency (/sec) | |
| Shape-E [39] | 55.1 | 27.1 | 13.0 |
| Direct3D | 60.8 | 4.33 | 16.0 |
| 3DTopia [31] | 59.7 | 11.2 | 23.7 |
| PI3D∗ [67] | 65.9 | 25.2 | 3.00 |
| GVGEN [26] | 51.1 | 2.44 | 49.2 |
| LN3Diff [50] | 55.9 | 5.09 | 8.16 |
| LGM [109] | 67.4 | 28.3 | 56.1 |
| Ours | 68.2 | 32.3 | 1.23 |
| +More Text Data | 75.1 | 46.0 | 1.23 |
🔼 This table presents a quantitative comparison of different text-to-mesh generation methods. It compares the CLIP score (a measure of the visual similarity between generated meshes and text descriptions), CLIP R-precision (a measure of the ranking accuracy of generated meshes based on the text description), and generation latency (speed). The methods are compared to show the improvements in both the speed and quality of the proposed method (TriplaneTurbo). The asterisk (*) indicates results are taken from original research papers, not directly from the authors.
read the caption
Table 1: Quality and speed comparison for text-to-mesh generation. ∗indicates that the values are quoted from the original papers.
In-depth insights#
SD Adaptation#
Adapting Stable Diffusion (SD) for 3D generation is a promising avenue, leveraging SD’s robust text-image priors. Methods involve fine-tuning or distillation. The challenge lies in efficiently transferring SD’s knowledge to 3D representations, such as Triplanes, without extensive 3D training data. This adaptation aims to create high-quality 3D models from text prompts, rivaling traditional methods like NeRF optimization. SD Adaptation enhances generalization and reduces training costs, making 3D creation more accessible and faster. SD adaptation helps generating 3D content, even if multi-view inconsistency exists or the issue of the Janus problem arises.
PRD: 3D Data-Free#
PRD: 3D Data-Free represents a significant leap in text-to-3D generation by eliminating the need for expensive and often limited 3D training datasets. The core idea revolves around distilling knowledge from pre-trained 2D diffusion models, like Stable Diffusion, and multi-view diffusion models. By leveraging the rich generative priors learned from vast image datasets, PRD can effectively guide the creation of 3D meshes without directly supervising the training process with 3D ground truth. This data-free approach unlocks several key advantages: it dramatically reduces the cost and complexity of training, allows for easier scaling to larger and more diverse datasets of text prompts, and circumvents the limitations imposed by the quality and biases of existing 3D datasets. The method addresses the bottleneck of 3D data scarcity, enabling the generation of high-quality and consistent 3D assets from text descriptions more efficiently and effectively. This has implications for content creation and virtual world development.
PETA: <3% Params#
The concept of “PETA: <3% Params” likely refers to a Parameter-Efficient Transfer learning Approach (PETA) used in the research. This suggests a methodology where a pre-trained model, possibly a large one, is adapted to a new task or domain by only training a small fraction of its parameters. The significance lies in reducing computational costs and memory footprint during training, making it feasible to fine-tune large models on limited resources. A parameter budget of less than 3% implies a highly efficient adaptation strategy, likely involving techniques like low-rank adaptation (LoRA), adapter modules, or selective parameter freezing. The benefits include faster training times, reduced GPU memory requirements, and potentially better generalization performance compared to full fine-tuning. This approach is particularly relevant when dealing with large pre-trained models where full fine-tuning is computationally prohibitive, while still achieving comparable or superior results.
Multi-View Diff.#
Multi-view diffusion is a crucial element in generating consistent 3D structures from text prompts. It addresses the Janus problem by ensuring different viewpoints align and complement each other. Techniques involve camera-aware adaptations, synchronized multi-view generation, and incorporating modalities like normals and depth maps. While multi-view diffusion improves geometric quality and consistency, it often introduces computational bottlenecks due to intensive score distillation or 3D reconstruction. Balancing multi-view consistency with computational efficiency remains a key challenge, necessitating innovations in both model architecture and training strategies.
Limited # Obj.#
The limited number of objects, particularly in 3D datasets, significantly constrains the generalizability of text-to-3D models. The paucity of diverse and high-quality 3D data hinders the ability of these models to accurately translate complex textual descriptions into corresponding 3D representations. This data bottleneck forces models to rely heavily on priors learned from smaller datasets, resulting in outputs that often lack the nuance and detail present in the text prompts. Overcoming this limitation requires innovative strategies like data augmentation, transfer learning from 2D models, or the development of novel training schemes that can effectively leverage limited data while still producing high-fidelity 3D content. Data-free distillation methods can also overcome this issue by transferring knowledge from multi-view diffusion models into SD-adapted native 3D generators.
More visual insights#
More on figures
🔼 Figure 2 illustrates the core difference between traditional Stable Diffusion (SD) adaptation for 3D generation and the proposed Progressive Rendering Distillation (PRD) method. Traditional methods require ground truth 3D data (θ) and their corresponding latent codes (z₀) to train the model, using these to generate new latent codes (z₀). In contrast, PRD eliminates the need for ground truth 3D data. Instead, it progressively denoises latent codes (zₜ) starting from random noise, iteratively refining them towards z₀, which are then decoded into 3D representations (θ). Multi-view diffusion models guide this denoising process through distillation, transferring knowledge without explicit 3D supervision. This data-free approach addresses the scarcity of high-quality 3D training data.
read the caption
Figure 2: Comparison between (a) traditional SD adaptation and (b) our proposed progressive rendering distillation (PRD) for native 3D generation. Traditional approach requires ground-truth 3D representations θ𝜃\thetaitalic_θ and their latents 𝒛0subscript𝒛0\boldsymbol{z}_{0}bold_italic_z start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT for each 3D sample to generate 𝒛0subscript𝒛0\boldsymbol{z}_{0}bold_italic_z start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT. Our proposed PRD scheme progressively denoises latents 𝒛tsubscript𝒛𝑡\boldsymbol{z}_{t}bold_italic_z start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT initialized from random noise into 𝒛0subscript𝒛0\boldsymbol{z}_{0}bold_italic_z start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT, which are decoded to θ𝜃\thetaitalic_θ, using multi-view diffusion models as teachers for distillation, eliminating the need for 3D data during adaptation and overcoming data scarcity.

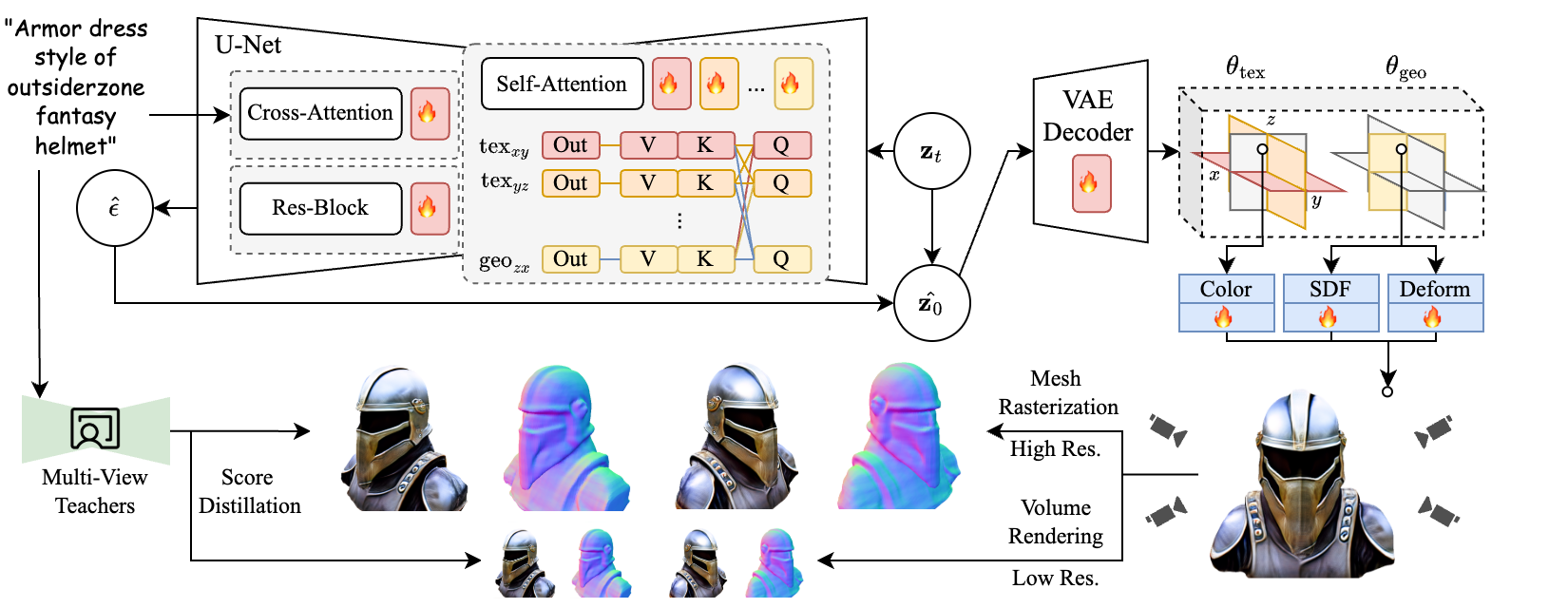
🔼 Figure 3 illustrates TriplaneTurbo, a novel 3D mesh generator built by adapting Stable Diffusion (SD). Unlike training a 3D generator from scratch, TriplaneTurbo leverages the pre-trained capabilities of SD, significantly reducing training time and data requirements. The core of the method is Progressive Rendering Distillation (PRD), which uses multi-view teacher models to guide the adaptation without relying on 3D ground truth data. The architecture generates six feature planes in four steps: two Triplanes (one for geometry and one for texture) and four accompanying features. The Parameter-Efficient Triplane Adaptation (PETA) method only adds 2.5% additional trainable parameters to the pre-trained SD model, keeping the adaptation computationally efficient.
read the caption
Figure 3: Illustration of TriplaneTurbo: an SD-adapted native 3D generator using our PRD scheme. Our model generates six feature planes comprising geometry Triplane θgeosubscript𝜃geo\theta_{\mathrm{geo}}italic_θ start_POSTSUBSCRIPT roman_geo end_POSTSUBSCRIPT and texture Triplane θtexsubscript𝜃tex\theta_{\mathrm{tex}}italic_θ start_POSTSUBSCRIPT roman_tex end_POSTSUBSCRIPT in 4 steps. We introduce Parameter Efficient Triplane Adaptation (PETA), which requires only 2.5%percent2.52.5\%2.5 % additional parameters for adaptation. The parameter arrangement is illustrated in the figure.

🔼 This figure provides a qualitative comparison of text-to-mesh generation results from several competing methods. It showcases various 3D model outputs generated from the same set of text prompts, allowing for a visual comparison of the quality, detail, and accuracy of each method in rendering diverse objects described by text. Section 4.2 of the paper provides detailed quantitative analysis that complements the qualitative overview presented in this figure.
read the caption
Figure 4: Qualitative comparison of text-to-mesh generation results by competing methods. Please refer to Sec. 4.2 for details.

🔼 This figure showcases additional results generated by the model after training with an expanded dataset. The images depict diverse 3D models of varying complexity and artistic styles, demonstrating the model’s improved ability to generate high-fidelity and text-consistent 3D meshes from creative and complex prompts. The variety of subjects, from fantasy characters to everyday objects, highlights the model’s capacity for generalization.
read the caption
Figure 5: More results of our model trained with expanded corpus.

🔼 This figure presents a qualitative comparison of the results obtained using the Progressive Rendering Distillation (PRD) algorithm with different numbers of steps (K). The results demonstrate that increasing the number of steps (K) in PRD leads to improved 3D model generation, specifically the quality of both geometry and textures. The models generated with more steps show more refined details and better overall quality.
read the caption
Figure 6: Visualizations on the ablation studies of PRD algorithm.

🔼 This figure visualizes the ablation study on the effectiveness of the Parameter-Efficient Triplane Adaptation (PETA) module. It compares the results of using a fully-trained model, a model with basic LoRA adaptation, and the proposed PETA model. The comparison highlights PETA’s superior performance in generating high-quality, text-consistent 3D meshes. Visual examples are provided to illustrate the differences in the quality of the generated outputs from each method.
read the caption
Figure 7: Visualizations on the ablation study of PETA.

🔼 This figure showcases additional results generated by the model after training with an expanded dataset. The images demonstrate the model’s ability to generate diverse and high-fidelity 3D meshes from a wide range of complex and creative text prompts. The examples highlight the model’s improved ability to handle challenging prompts and produce consistent, detailed outputs.
read the caption
Figure 8: More results of our model trained with expanded corpus.

🔼 This figure compares the results of the proposed Progressive Rendering Distillation (PRD) method with those of the LATTE3D method [134]. It showcases side-by-side visual results for two example text prompts: ‘A blue tulip’ and ‘A pile of dice on a green tabletop.’ The comparison highlights the differences in generated 3D model quality and realism between the two approaches, demonstrating PRD’s ability to produce higher-fidelity results.
read the caption
Figure 9: Qualitative comparison with LATTE3D [134].

🔼 This figure presents a qualitative comparison of 3D model generation results between the proposed method and PI3D [67]. It showcases several examples of text prompts and their corresponding generated 3D models, highlighting the differences in visual quality, geometric accuracy, and text consistency between the two approaches. This visual comparison allows for a direct assessment of the advantages of the proposed method over PI3D in terms of generating high-fidelity and text-consistent 3D outputs.
read the caption
Figure 10: Qualitative comparison with PI3D [67].

🔼 Figure 11 presents a qualitative comparison of 3D model generation results between the proposed method and HexaGen3D [78]. It showcases example text prompts and their corresponding generated outputs from both methods, allowing for a visual assessment of the differences in terms of mesh quality, texture detail, and overall fidelity. The figure highlights the advantages of the proposed approach in generating higher-quality 3D models.
read the caption
Figure 11: Qualitative comparison with HexaGen3D [78].

🔼 This ablation study visualizes the impact of using different combinations of Stable Diffusion (SD), Multi-view Dream (MV), and RichDreamer (RD) as multi-view teachers during the training process. Each row shows the results for a different configuration, with ‘w/o SD’ indicating SD was excluded, ‘w/o MV’ indicating MV was excluded, ‘w/o RD’ indicating RD was excluded, and ‘w/ All (Proposed)’ indicating all three models were used. The images show generated 3D models for the same prompts across different conditions to highlight how the exclusion of a teacher model affects the quality and consistency of the output. Notice the significant drop in quality when SD or MV are removed.
read the caption
Figure 12: Visualizations for the ablation study on jointly using SD, MV and RD as multi-view teachers.

🔼 This ablation study investigates the impact of using both volume rendering and mesh rasterization for supervising the training of the 3D generator. The results show that using only volume rendering leads to training instability and failure to generate valid meshes. Conversely, only using mesh rasterization results in low-quality mesh geometry and texture. The study demonstrates that combining both methods is crucial for achieving stable training and high-quality 3D generation.
read the caption
Figure 13: Ablation study on dual rendering. The cross mark means the model fails to generate mesh due to training instability.
More on tables
| C.S. | R@1 | |
|---|---|---|
| K=1 | 50.9 | 14.4 |
| K=2 | 62.6 | 22.4 |
| K=4 (Proposed) | 68.2 | 32.3 |
🔼 This table presents the results of an ablation study on the hyper-parameters of the Progressive Rendering Distillation (PRD) method. It shows how different numbers of denoising steps (K) in the PRD algorithm affect the quality of generated 3D models, as measured by CLIP Score (C.S.) and CLIP R-precision (R@1). The results demonstrate the impact of the hyperparameter K on the model’s performance.
read the caption
Table 2: Ablation study on the hyper-parameters of PRD.
| C.S. | R@1 | |
|---|---|---|
| Full Param Tuning | 35.8 | 0.35 |
| w/ Basic LoRA | 54.2 | 11.1 |
| w/ PETA (Proposed) | 68.2 | 32.3 |
🔼 This ablation study analyzes the impact of different adaptation methods on the performance of TriplaneTurbo, a 3D mesh generator adapted from Stable Diffusion. It compares the full parameter tuning approach, a basic LoRA adaptation, and the proposed Parameter-Efficient Triplane Adaptation (PETA). The results show PETA’s effectiveness in achieving a balance between adaptation quality and efficiency, significantly outperforming the other methods.
read the caption
Table 3: Ablation study on the effectiveness of PETA.
| C.S. | R@1 | |
|---|---|---|
| w/o SD | 63.0 | 20.1 |
| w/o MV | 67.4 | 25.9 |
| w/o RD | 41.5 | 11.4 |
| w/ All (Proposed) | 68.2 | 32.3 |
🔼 This table presents the results of an ablation study investigating the impact of using different combinations of Stable Diffusion (SD), Multiview Dream (MV), and RichDreamer (RD) as multi-view teachers during the training process. It shows how the performance of the model, measured by CLIP Score (C.S.) and CLIP R-precision (R@1), varies when one or more of these teacher models are excluded. This helps determine the contribution of each model to the overall performance and identifies the optimal combination for generating high-quality 3D meshes.
read the caption
Table 4: Ablation study on jointly using SD, MV and RD as multi-view teachers.
Full paper#



















