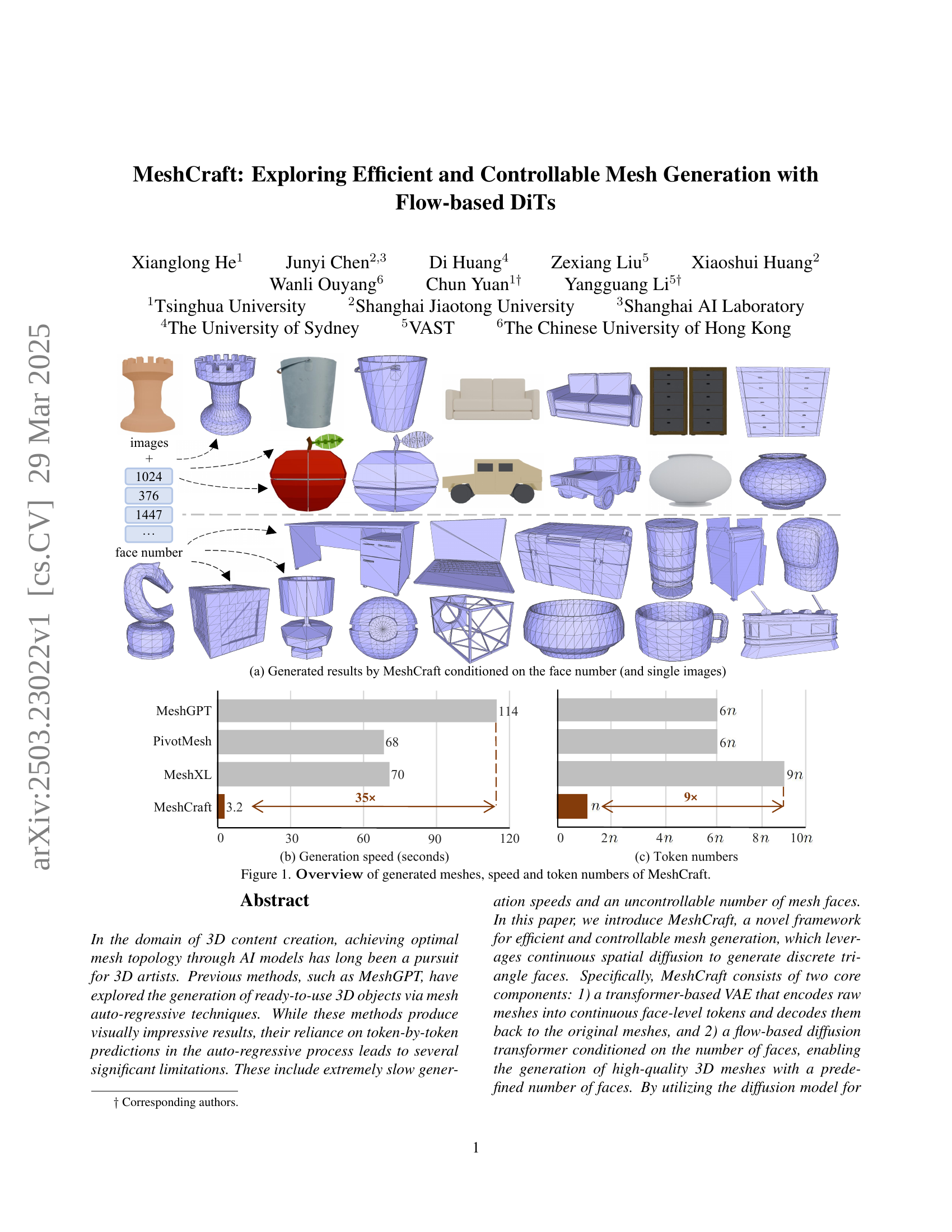
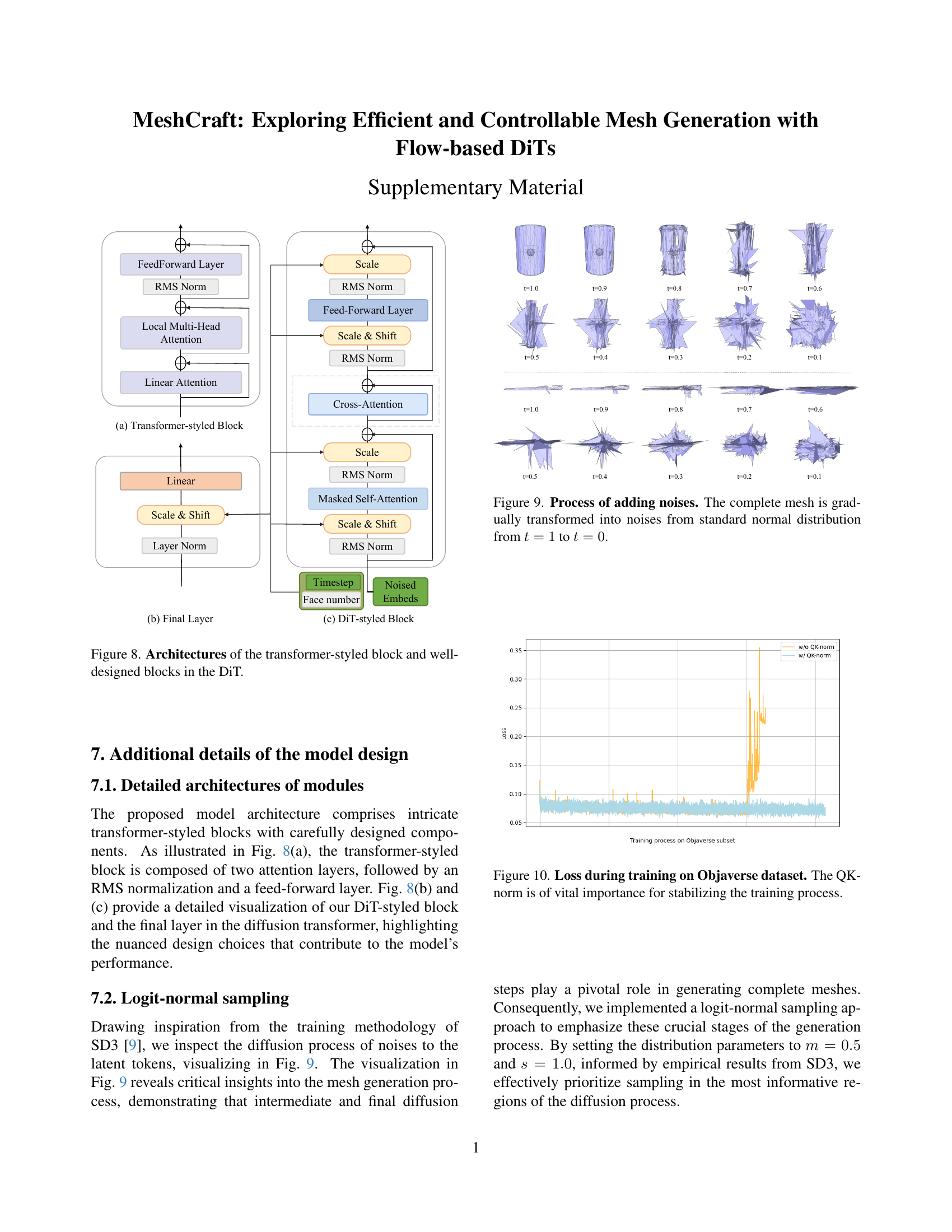
TL;DR#
Achieving optimal mesh topology through AI models has long been a pursuit, but previous methods face limitations such as slow generation speeds and uncontrollable face counts. Existing methods rely on token-by-token predictions, leading to inefficiency and restricted user control. Therefore, there is a need for faster methods with better user control.
This paper introduces MeshCraft, a novel framework for efficient and controllable mesh generation, leveraging continuous spatial diffusion to generate triangle faces. MeshCraft uses a transformer-based VAE and a flow-based diffusion transformer conditioned on the number of faces. This method demonstrates superior speed and controllability, achieving new state-of-the-art results on the ShapeNet dataset and superior performance on the Objaverse dataset.
Key Takeaways#
Why does it matter?#
This paper introduces MeshCraft, a novel framework that enables efficient and controllable mesh generation. This is important for researchers because it overcomes the limitations of existing methods and opens new avenues for AI-driven 3D content creation.
Visual Insights#
🔼 Table 1 presents the reconstruction performance results on the ShapeNet dataset. The table compares the proposed method’s performance with existing state-of-the-art methods. The key metric used for comparison is the reconstruction error, specifically the L2 distance between the original and reconstructed meshes. It also includes the triangle accuracy which shows how well the model has reconstructed the triangular facets of the mesh. Notably, the table highlights that even though the proposed autoencoder uses a continuous latent space representation (instead of the vector quantization used by prior works), it still achieves comparable reconstruction performance.
read the caption
Table 1: Reconstruction performance on ShapeNet dataset. Our continuous auto-encoder behaves competitively with prior works using the vector quantization.
In-depth insights#
Flow-based DiTs#
Flow-based diffusion transformers (DiTs) represent a significant advancement in generative modeling. Unlike traditional diffusion models that rely on iterative denoising processes, flow-based DiTs aim for more direct and efficient generation by mapping data to a latent space with a well-defined probability distribution, often a Gaussian. This allows for sampling new data points through a deterministic flow, potentially leading to faster inference times. The ‘flow-based’ aspect refers to the use of techniques like normalizing flows to learn an invertible mapping between the data and the latent space, enabling both encoding and decoding. In the context of mesh generation, this could mean learning a continuous representation of mesh topologies, allowing for controlled generation by manipulating the latent space. The DiT architecture, characterized by the use of transformers, brings the benefits of attention mechanisms to capture long-range dependencies within the mesh structure, potentially resulting in more coherent and realistic 3D models. Key advantages include the potential for controllability (e.g., guiding the generation process with constraints on the number of faces or desired geometric features) and the possibility of learning disentangled representations that allow for manipulating individual aspects of the mesh.
VAE & Diffusion#
The convergence of VAEs and diffusion models represents a powerful paradigm in generative modeling, leveraging the strengths of both approaches. VAEs excel at learning compressed latent spaces, enabling efficient representation and manipulation of complex data distributions. However, their generative capacity can be limited by the information bottleneck imposed by the encoder-decoder architecture. Diffusion models, on the other hand, shine in generating high-fidelity samples by learning to reverse a gradual noising process. By integrating VAEs and diffusion models, one can harness the benefits of both worlds. For example, a VAE can be used to learn a meaningful latent space, which then serves as the target for a diffusion model. This approach allows for efficient sampling from a well-structured latent space while retaining the ability to generate high-quality, diverse samples. Further exploration includes using diffusion models for regularizing the VAE latent space or employing VAEs as efficient proposal distributions within a diffusion framework.
Fast Generation#
The pursuit of “Fast Generation” in 3D mesh creation is paramount, addressing the inherent slowness of auto-regressive methods like MeshGPT. Diffusion models, leveraging continuous spatial diffusion, offer a viable path to speedier generation by processing the entire mesh topology simultaneously, a departure from token-by-token prediction. Techniques like rectified flow, by streamlining the diffusion process, further amplify the speed gains. A crucial aspect is trading off complexity for speed. Simplifications in mesh representation, such as face-level tokens, curtail the computational burden, potentially sacrificing fine details. Optimizing model architecture is necessary like with SiT. The ideal solution balances fidelity with speed, empowering artists to generate numerous iterations rapidly. Effective conditional guidance and user controls are essential. Masking strategies, and diffusion-based approaches stand out.
MeshCraft Details#
MeshCraft likely focuses on the technical implementation of the framework. It probably delves into the architecture of the VAE (Variational Autoencoder) used for encoding and decoding meshes, providing details on the transformer network, loss functions, and training procedures. Details of the flow-based diffusion transformer would likely be covered, emphasizing the network architecture and conditioning strategies employed for controlling the generation process. Hyperparameter settings, dataset preprocessing steps, and specific implementation choices that contribute to the efficiency and controllability of MeshCraft are important details to look for. The choice of loss functions and the training regime is critical for the performance and how those are defined specifically for meshes are a central point to analyze.
Controllability#
The aspect of “Controllability” in mesh generation is crucial for practical applications. Users often require precise control over the output, such as the number of faces or specific geometric features. AI models should allow users to guide the generation process based on various conditions like number of faces. Effective controllability reduces the need for manual adjustments. It enables artists to iterate and refine designs efficiently. Incorporating techniques like classifier-free guidance and adaptive sampling weights can improve controllability. User-friendly interfaces and intuitive parameters are essential for accessibility. Overly complex controls can hinder usability. Balancing flexibility with ease of use is key. Evaluating controllability involves assessing how well the model adheres to user-defined constraints and generates meshes. It meet specific requirements while maintaining overall quality and diversity.
More visual insights#
More on tables
| Class | Method | COV | MMD | 1-NNA | JSD | FID | KID | Class | Method | COV | MMD | 1-NNA | JSD | FID | KID |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Chair | MeshGPT [32] | 45.98 | 10.34 | 60.06 | 11.67 | 25.43 | 4.10 | Table | MeshGPT [32] | 48.85 | 9.23 | 57.82 | 8.50 | 21.98 | 2.99 |
| PivotMesh [38] | 47.99 | 10.00 | 60.06 | 13.51 | 34.40 | 10.33 | PivotMesh [38] | 47.42 | 9.08 | 58.35 | 10.42 | 24.97 | 7.99 | ||
| MeshXL* [4] | 49.43 | 10.17 | 56.90 | 11.37 | 20.09 | 1.70 | MeshXL* [4] | 50.98 | 9.38 | 57.82 | 9.07 | 22.08 | 2.88 | ||
| Ours | 51.44 | 9.61 | 54.31 | 11.03 | 20.40 | 1.76 | Ours | 55.42 | 8.74 | 54.26 | 8.73 | 16.63 | 1.70 | ||
| Bench | MeshGPT [32] | 56.06 | 8.44 | 58.33 | 28.34 | 66.30 | 9.45 | Lamp | MeshGPT [32] | 43.90 | 20.82 | 60.37 | 36.21 | 73.21 | 6.04 |
| PivotMesh [38] | 59.09 | 8.25 | 48.48 | 25.76 | 64.48 | 5.17 | PivotMesh [38] | 50.00 | 19.17 | 56.71 | 39.75 | 67.76 | 7.09 | ||
| MeshXL* [4] | 59.09 | 7.74 | 53.79 | 26.37 | 19.30 | 3.44 | MeshXL* [4] | 42.68 | 21.64 | 63.41 | 35.96 | 62.46 | 5.32 | ||
| Ours | 57.58 | 7.90 | 50.76 | 27.17 | 59.83 | 1.53 | Ours | 62.20 | 18.69 | 48.17 | 37.33 | 62.81 | 2.17 |
🔼 Table 2 presents a quantitative comparison of MeshCraft against three other state-of-the-art mesh generation methods (MeshGPT, PivotMesh, and MeshXL) on the ShapeNet dataset. The comparison uses several metrics to evaluate shape quality, visual fidelity, and compactness of generated meshes. These metrics include Coverage (COV), Maximum Mean Discrepancy (MMD), 1-Nearest Neighbor Accuracy (1-NNA), Jensen-Shannon Divergence (JSD), Fréchet Inception Distance (FID), and Kernel Inception Distance (KID). Note that MMD values are multiplied by 1000, while COV and 1-NNA values are multiplied by 100 for easier interpretation. Results marked with an asterisk (*) indicate that pre-trained models were used for the comparison. The table clearly shows MeshCraft’s superior performance across all metrics, highlighting its efficacy and efficiency.
read the caption
Table 2: Quantitative results on ShapeNet dataset. MeshCraft outperforms the baselines on shape quality, visual and compactness metrics. MMD values are multiplied by 103superscript10310^{3}10 start_POSTSUPERSCRIPT 3 end_POSTSUPERSCRIPT. COV and 1-NNA are scaled by 102superscript10210^{2}10 start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT. * stands for using the released pre-trained models.
| Method | Tri. Accu. | L2 Dist. |
|---|---|---|
| KL (4-dim) | 90.41 | 0.63 |
| KL (8-dim) | 99.66 | 0.12 |
| RVQ [40] | 65.12 | 8.63 |
🔼 This table presents a quantitative analysis of the MeshCraft model’s performance on the Objaverse dataset. It compares the model’s reconstruction accuracy (measured by Tri. Accu. and L2 Dist.) across different configurations, specifically focusing on the impact of the dimensionality of the KL regularization in the autoencoder (4-dim vs. 8-dim) and the use of a Residual Vector Quantization (RVQ) method. The table helps to evaluate the effectiveness of the different model choices in terms of generating accurate and high-fidelity 3D mesh reconstructions on a challenging and diverse dataset.
read the caption
Table 3: Reconstruction performance study on Objverse.
| CFG | COV | MMD | 1-NNA |
|---|---|---|---|
| 0.0 | 30.70 | 12.61 | 84.75 |
| 1.0 | 38.20 | 11.34 | 75.00 |
| 2.0 | 44.80 | 10.72 | 67.65 |
| 3.0 | 48.60 | 10.33 | 61.05 |
| 4.0 | 50.80 | 9.89 | 58.40 |
| 5.0 | 51.70 | 10.05 | 57.55 |
| 6.0 | 51.00 | 9.97 | 56.55 |
| 7.0 | 51.70 | 9.65 | 56.70 |
| 8.0 | 53.30 | 9.90 | 56.85 |
| 9.0 | 52.50 | 9.85 | 56.75 |
| 10.0 | 52.30 | 9.86 | 57.90 |
🔼 This table presents the quantitative results of mesh generation on the ShapeNet dataset, showing the impact of different classifier-free guidance (CFG) weights on the face number condition. Specifically, it demonstrates how varying weights (w1 and w2) influence the quality of generated meshes when conditioned on both the desired number of faces and image input. The metrics used likely include those common in 3D mesh generation evaluation, possibly assessing aspects such as shape accuracy and visual fidelity. The table helps analyze the optimal CFG weights for balancing the influence of the face number and image conditions to achieve the best mesh generation results.
read the caption
Table 4: Effects of CFG weights over the face number condition to mesh generation results on ShapeNet dataset.
Full paper#