TL;DR#
Recent advancements in video generation often neglect character-driven storytelling. To address this, the paper introduces the task of Talking Characters: generating animations from speech & text, focusing on realistic full-body actions. Current models lack control over spoken content, have limited body movement, and cannot handle multi-character interactions.
To solve these issues, the paper presents MoCha, a diffusion transformer model for high-quality talking character generation. Key innovations include a speech-video window attention mechanism for accurate lip-sync, and a joint training strategy using speech & text-labeled data for better generalization. MoCha enables multi-character conversations & sets a new standard for AI-driven cinematic storytelling with improved realism.
Key Takeaways#
Why does it matter?#
This paper pioneers movie-grade character synthesis, offering researchers a novel approach to AI-driven content creation. By addressing speech-driven animation & enabling cinematic storytelling, it paves the way for more realistic, expressive, & controllable virtual characters in film & interactive media.
Visual Insights#

🔼 Figure 1 showcases the capabilities of MoCha, a novel end-to-end model for generating talking character videos. Unlike other methods that often rely on additional input data (e.g., keypoints, reference images), MoCha uniquely generates high-quality video solely from speech and text prompts. The figure demonstrates examples of MoCha’s output across various control aspects, including scene control, emotion control, action control, and multi-character dialogues. These examples highlight the model’s ability to seamlessly integrate speech and text input for realistic character animation and lip synchronization. For additional examples, viewers are directed to the project website.
read the caption
Figure 1: MoCha is an end-to-end talking character video generation model that takes only speech and text as input, without requiring any auxiliary conditions. More videos are available on our website: https://congwei1230.github.io/MoCha
| Method | Lip-Sync Quality | Facial Expression Naturalness | Action Naturalness | Text Alignment | Visual Quality |
|---|---|---|---|---|---|
| Hallo3 [40] | 2.45 | 2.25 | 2.13 | 2.35 | 2.36 |
| SadTalker [44] | 1.21 | 1.14 | 1.00 | N/A | 2.95 |
| AniPortrait [38] | 1.16 | 1.12 | 1.00 | N/A | 1.45 |
| MoCha (Ours) | 3.85 (+1.40) | 3.82 (+1.57) | 3.82 (+1.69) | 3.85 (+1.50) | 3.72 (+1.36) |
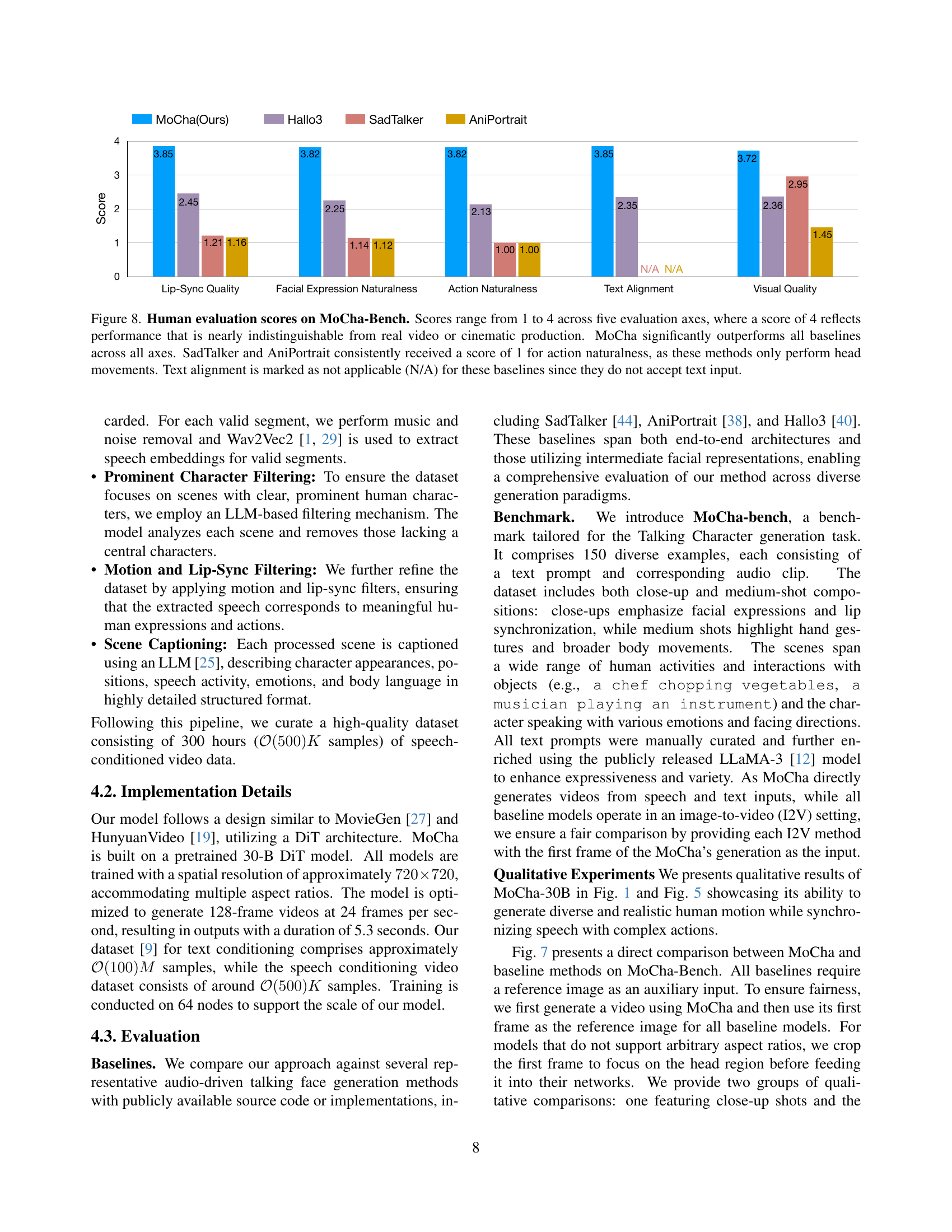
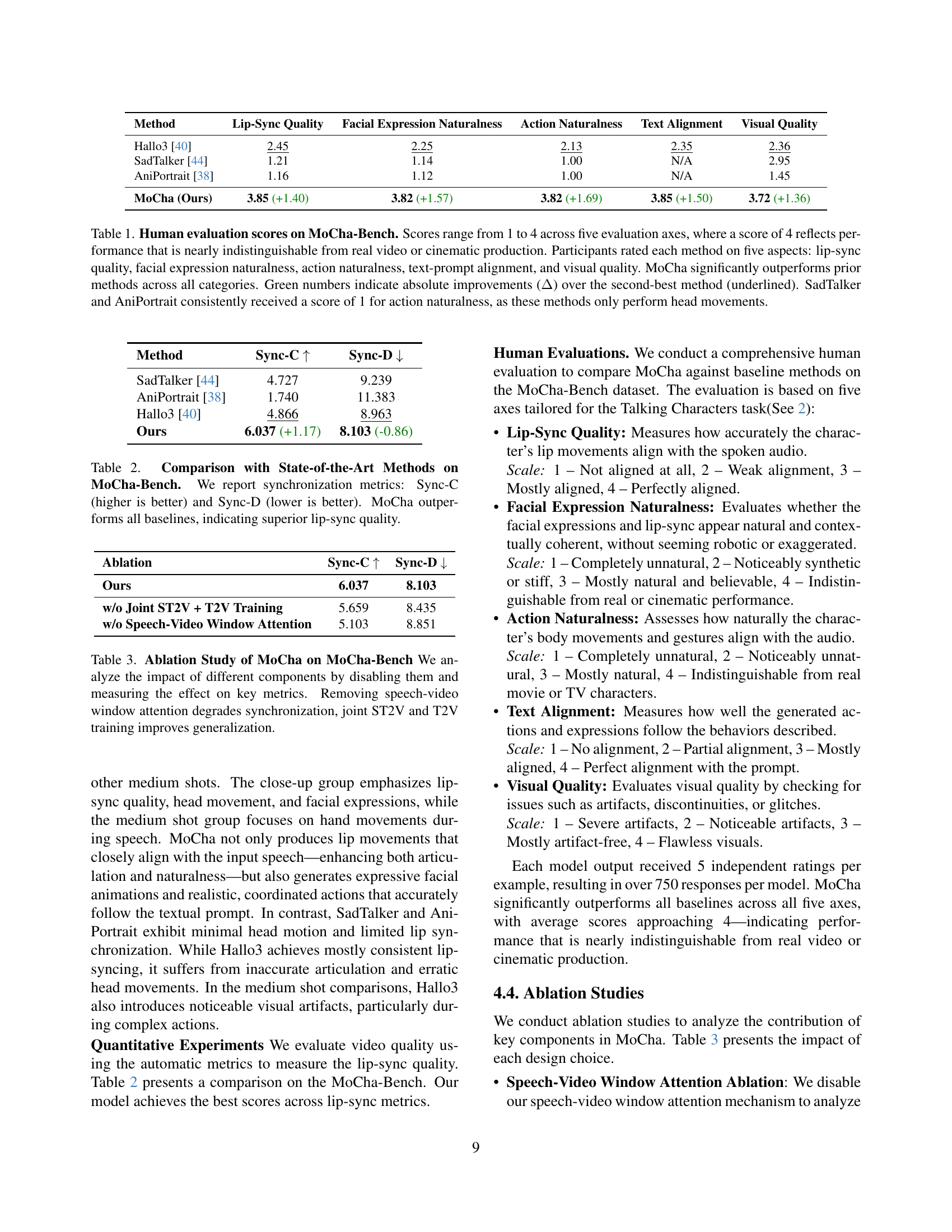
🔼 This table presents the results of a human evaluation comparing MoCha’s performance to several baseline methods on the MoCha-Bench dataset. The evaluation used a 1-to-4 scale across five criteria: lip-sync quality, facial expression naturalness, action naturalness, text-prompt alignment, and visual quality. A score of 4 indicates performance nearly indistinguishable from real film or video. MoCha substantially outperforms all other methods across all five metrics. The table highlights MoCha’s improvements over the next-best performing method for each metric. Importantly, it notes that SadTalker and AniPortrait received a consistent score of 1 for action naturalness because their animations are limited to head movements only.
read the caption
Table 1: Human evaluation scores on MoCha-Bench. Scores range from 1 to 4 across five evaluation axes, where a score of 4 reflects performance that is nearly indistinguishable from real video or cinematic production. Participants rated each method on five aspects: lip-sync quality, facial expression naturalness, action naturalness, text-prompt alignment, and visual quality. MoCha significantly outperforms prior methods across all categories. Green numbers indicate absolute improvements (ΔΔ\Deltaroman_Δ) over the second-best method (underlined). SadTalker and AniPortrait consistently received a score of 1 for action naturalness, as these methods only perform head movements.
In-depth insights#
MoCha: Overview#
MoCha: Overview could encompass the model’s architecture, training methodologies, and unique features for generating movie-grade talking character videos. End-to-end training without auxiliary conditions simplifies architecture and enhances motion diversity. The innovative speech-video window attention mechanism improves lip-sync accuracy. A joint speech-text training strategy utilizes both labeled datasets to enhance generalization across character actions, enabling universal controllability through prompts. MoCha uniquely supports multi-character conversation generation with turn-based dialogues, advancing cinematic video synthesis. The overview demonstrates MoCha’s ability to produce realistic, expressive, and controllable talking characters, setting a new benchmark for AI-generated cinematic storytelling by overcoming limitations of previous approaches.
Talk. Characters#
The section on Talking Characters introduces a novel task centered on generating realistic and expressive character animations directly from natural language and speech inputs. This goes beyond simple “talking head” generation, aiming for full-body portrayals with synchronized speech, realistic emotions, and contextually relevant actions. A key aspect is achieving accurate lip-sync and expressive facial animations that align with both the spoken words and the text prompt. Furthermore, the generated characters should exhibit natural body movements and gestures that correspond to the described actions, all within a scene that aligns with the text prompt. The visual quality of the generated video should be consistent and free of artifacts. The evaluation focuses on five key axes: lip-sync quality, facial expression naturalness, action naturalness, text alignment, and visual quality. This work aims to produce AI-generated cinematic storytelling
Window Attention#
The speech-video window attention mechanism addresses the challenges of aligning audio and video in DiT architectures, particularly due to temporal compression from 3D VAEs and parallel frame generation. Unlike autoregressive models that inherently maintain sync, DiT requires a strategy to prevent misaligned phoneme associations across frames. This mechanism restricts each video token’s attention to a localized window of audio tokens, mirroring the short-term dependency of lip movements on audio cues. By attending to a limited audio span, it enhances lip-sync accuracy and temporal smoothness. The window size balances local context with broader descriptions, ensuring coherent motion synchronized with speech.
Multi-Clip Gen#
Multi-clip generation, a facet of video synthesis, holds significant promise in expanding the narrative scope and visual richness of AI-generated content. Unlike single-clip generation, which focuses on producing a single, continuous video segment, multi-clip generation involves the creation of multiple, distinct video clips that can be stitched together to form a more complex and dynamic narrative. This approach offers several advantages. It allows for the creation of longer and more elaborate storylines, as each clip can represent a different scene, location, or time period. It also enables the incorporation of multiple characters and perspectives, as each clip can focus on a different character’s actions or emotions. Moreover, multi-clip generation facilitates the creation of more visually diverse and engaging content, as each clip can be rendered with different styles, camera angles, or special effects. The design considerations involve maintaining character consistency across clips, ensuring smooth transitions between scenes, and orchestrating the clips to achieve a cohesive and compelling narrative flow.
Ablation Details#
In an ablation study, the impact of individual components on overall performance is analyzed by systematically removing or modifying them. In this paper, Speech-Video Window Attention Ablation analyzes the effect of the speech-video window attention mechanism on lip synchronization, where disabling it led to a drop in Sync-C and an increase in Sync-D. This shows its key role in improving lip synchronization. Also, Joint ST2V and T2V Training Ablation study shows the importance of ST2V data with text-only video training in overall video quality, where removing it leads to a decrease in overall performance. Thus confirming the need for speech-video window attention and joint training strategy for achieving high-quality motion, realistic speech alignment, and overall superior generation performance.
More visual insights#
More on figures

🔼 MoCha, an end-to-end Diffusion Transformer model, takes both speech and text as input to generate video frames. It doesn’t use any additional signals (like pre-computed poses or images). The model processes both the speech and text inputs, converting them into token representations. These tokens are then aligned with video tokens using cross-attention to generate synchronized video output.
read the caption
Figure 2: MoCha Architecture. MoCha is a end-to-end Diffusion Transformer model that generates video frames from the joint conditioning of speech and text, without relying on any auxiliary signals. Both speech and text inputs are projected into token representations and aligned with video tokens through cross-attention.

🔼 This figure illustrates MoCha’s novel Speech-Video Window Cross Attention mechanism. Unlike traditional methods that generate video frames sequentially, MoCha processes all frames in parallel using a cross-attention method. Crucially, instead of each video token attending to the entire audio sequence, each video token only attends to a localized ‘window’ of audio tokens. This localized attention significantly improves the alignment between the generated video and the input audio, leading to a much better lip-sync quality.
read the caption
Figure 3: MoCha’s Speech-Video Window Cross Attention MoCha generates all video frames in parallel using a window cross-attention mechanism, where each video token attends to a local window of audio tokens to improve alignment and lip-sync quality.

🔼 Figure 4 illustrates MoCha’s capacity for generating multi-character conversations with scene changes. A structured prompt template is used, beginning with the number of video clips to be generated. Following this, each character is introduced with a description and a unique tag. Subsequent descriptions of the clips only utilize these tags, streamlining the prompt while retaining clarity. MoCha uses self-attention across video tokens to maintain consistency in character appearance and the environment across multiple clips. The model implicitly switches between clips based on the audio input, indicating a speaker change.
read the caption
Figure 4: Multi-character Conversation and Character Tagging. MoCha supports generates multi-character conversion with scene cut. We design a specialized prompt template: it first specifies the number of clips, then introduces the characters along with their descriptions and associated tags. Each clip is subsequently described using only the character tags, simplifying the prompt while preserving clarity. MoCha leverages self-attention across video tokens to ensures character and environment consistency. The audio conditioning signal implicitly guides the model on when to transition between clips.

🔼 Figure 5 showcases the capabilities of the MoCha model by presenting three example videos generated using different prompts. Each example highlights MoCha’s ability to generate realistic and nuanced video output. The videos demonstrate well-synchronized lip movements with the input audio, natural facial expressions reflecting the specified emotion and context of the prompt, and accurate, realistic hand gestures and full-body actions that appropriately correspond to the text and audio descriptions.
read the caption
Figure 5: Qualitative results of MoCha on MoCha-Bench. MoCha not only generates lip movements that are well-synchronized with the input speech, but also produces natural facial expressions that reflect the prompt along with realistic hand gestures and action movements

🔼 MoCha’s training strategy involves a multi-stage approach. Training begins with easy tasks: close-up shots of single characters, where speech is highly influential in driving the video generation. As training progresses, the difficulty increases. At each stage, the amount of data from the previous stage is halved, and new data is introduced with more challenging conditions, including less explicit speech and more complex shots (e.g. medium shots, multiple characters). This gradual increase in difficulty helps the model generalize better. Crucially, Stage 0 uses only text-based video data to create a foundational understanding of video structures before introducing speech.
read the caption
Figure 6: Multi-Stage Training Strategy for MoCha. Text-Speech Joint training starts with close-up shots where speech conditioning has the strongest influence. At each stage, previous data is reduced by 50%, and harder tasks with weaker speech conditioning are introduced. Stage 0 uses text-only video data to establish a foundation for the future stages.

🔼 Figure 7 presents a qualitative comparison of MoCha against three baseline methods (SadTalker, AniPortrait, and Hallo3) on the MoCha-Bench benchmark. The figure showcases video clips generated by each model in response to the same prompts, highlighting the differences in lip synchronization, facial expressions, and overall motion realism. MoCha demonstrates superior performance, accurately aligning lip movements with speech, exhibiting natural facial expressions, and generating complex actions consistent with the textual prompts. In contrast, the baseline models show limitations. SadTalker and AniPortrait exhibit very limited head motion and lip synchronization. Hallo3, while showing better lip sync, suffers from inaccurate articulation, erratic head movements, and noticeable visual artifacts. To ensure a fair comparison, the first frame generated by MoCha was provided as input to the baseline models, which were then tasked with generating the rest of the video sequence. The first frames were cropped and resized as necessary to meet the individual input requirements of each baseline method.
read the caption
Figure 7: Qualitative comparison between MoCha and baselines on MoCha-Bench. MoCha not only produces lip movements that align closely with the input speech—enhancing the clarity and naturalness of articulation—but also generates expressive facial animations and realistic, complex actions that faithfully follow the textual prompt. In contrast, SadTalker and AniPortrait exhibit minimal head motion and limited lip synchronization. Hallo3 mostly follows the lip-syncing but suffers from inaccurate articulation, erratic head movements, and noticeable visual artifacts. Since the baselines operate in an image-to-video (I2V) setting, we provide them with the first frame generated by MoCha as input for comparison. The first frame is cropped and resized as needed to meet the requirements of each baseline.
More on tables
| Method | Sync-C | Sync-D |
|---|---|---|
| SadTalker [44] | 4.727 | 9.239 |
| AniPortrait [38] | 1.740 | 11.383 |
| Hallo3 [40] | 4.866 | 8.963 |
| Ours | 6.037 (+1.17) | 8.103 (-0.86) |
🔼 Table 2 presents a quantitative comparison of MoCha’s lip synchronization performance against state-of-the-art methods on the MoCha-Bench benchmark dataset. Two metrics are used to evaluate lip synchronization: Sync-C (higher scores indicate better synchronization) and Sync-D (lower scores indicate better synchronization). The results show that MoCha significantly outperforms all baseline methods, demonstrating superior lip-sync quality.
read the caption
Table 2: Comparison with State-of-the-Art Methods on MoCha-Bench. We report synchronization metrics: Sync-C (higher is better) and Sync-D (lower is better). MoCha outperforms all baselines, indicating superior lip-sync quality.
| Ablation | Sync-C | Sync-D |
|---|---|---|
| Ours | 6.037 | 8.103 |
| w/o Joint ST2V + T2V Training | 5.659 | 8.435 |
| w/o Speech-Video Window Attention | 5.103 | 8.851 |
🔼 This ablation study investigates the impact of key architectural components within the MoCha model on its performance using the MoCha-Bench benchmark. Specifically, it examines the effects of removing the speech-video window attention mechanism and the joint training strategy that combines speech-text-to-video (ST2V) and text-to-video (T2V) data. The results quantify the influence of these components on key metrics, demonstrating the importance of speech-video alignment and the benefit of the joint training approach for model generalization.
read the caption
Table 3: Ablation Study of MoCha on MoCha-Bench We analyze the impact of different components by disabling them and measuring the effect on key metrics. Removing speech-video window attention degrades synchronization, joint ST2V and T2V training improves generalization.
Full paper#