TL;DR#
Reinforcement Learning with Verifiable Rewards (RLVR) has shown great promise but mainly in structured domains like math and coding. The necessity of large-scale annotation for training domain-specific reward models is challenged by the limitation of binary rewards for unstructured answers.
This paper broadens RLVR’s use to areas like medicine by using model-based soft scoring and a cross-domain reward model. Using a distilled generative reward model as a verifier, the researchers achieved excellent results without needing domain-specific annotations. This approach surpasses current open-source LLMs in free-form answer tasks.
Key Takeaways#
Why does it matter?#
This research advances RLVR by expanding its applicability to diverse domains beyond math/coding. The work introduces a cross-domain reward model, which improves the efficiency, scalability, and robustness of the RLVR framework. This enables the use of RLVR for complex reasoning tasks with noisy labels.
Visual Insights#

🔼 This figure illustrates the process of Reinforcement Learning with Verifiable Rewards (RLVR) using a cross-domain verifier. It shows three steps. Step 1 involves using a base language model and reasoning data (prompt and expert-written reference answer) to generate exploration data that includes the model’s response and a correctness label from a teacher grader. Step 2 uses this exploration data to train a reward model. Step 3 employs the trained reward model within the RLVR framework to fine-tune the base model, resulting in a final policy that can generate more accurate and reliable responses across diverse domains.
read the caption
Figure 1: Overview paradigm of RLVR with our cross-domain verifier.
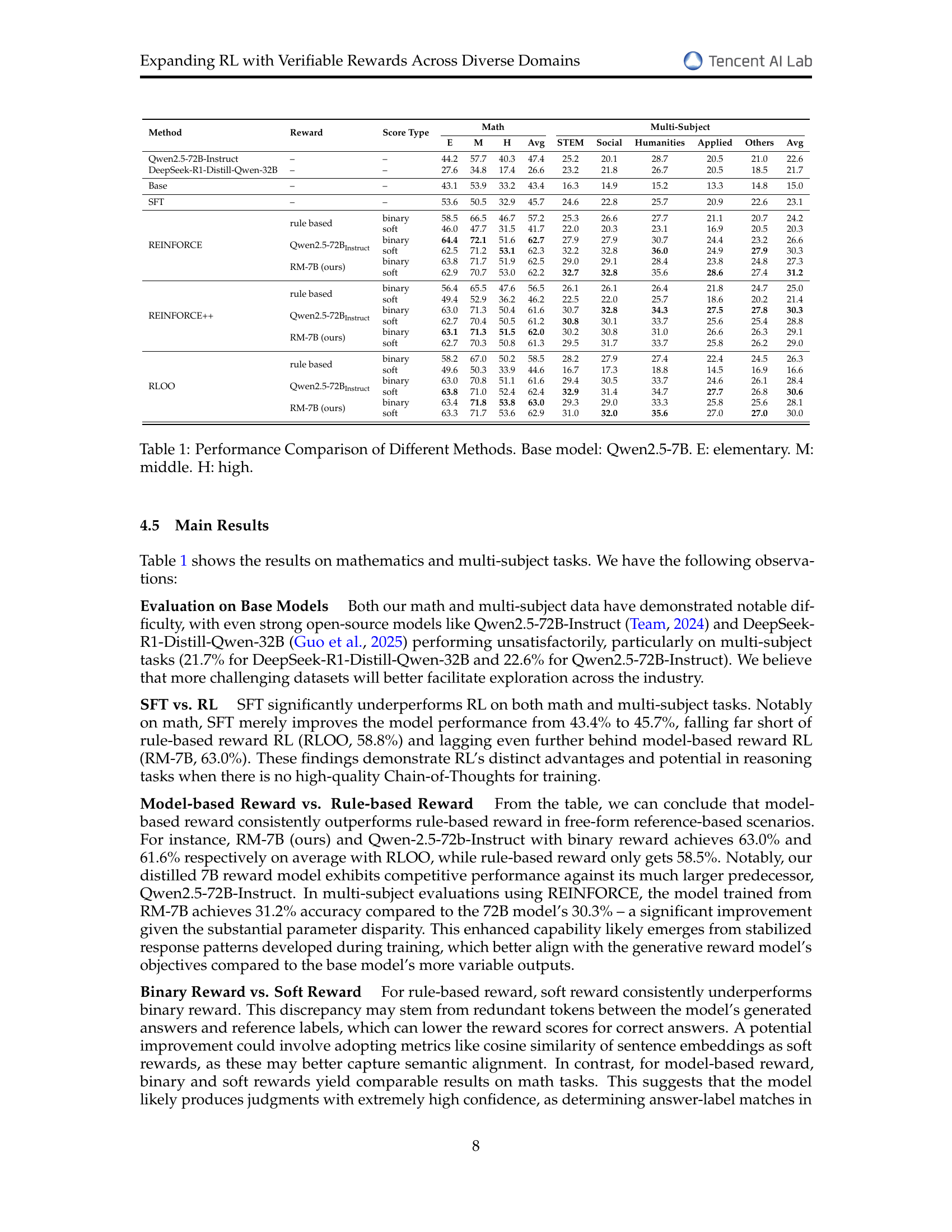
| Method | Reward | Score Type | Math | Multi-Subject | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| E | M | H | Avg | STEM | Social | Humanities | Applied | Others | Avg | |||
| Qwen2.5-72B-Instruct | – | – | 44.2 | 57.7 | 40.3 | 47.4 | 25.2 | 20.1 | 28.7 | 20.5 | 21.0 | 22.6 |
| DeepSeek-R1-Distill-Qwen-32B | – | – | 27.6 | 34.8 | 17.4 | 26.6 | 23.2 | 21.8 | 26.7 | 20.5 | 18.5 | 21.7 |
| Base | – | – | 43.1 | 53.9 | 33.2 | 43.4 | 16.3 | 14.9 | 15.2 | 13.3 | 14.8 | 15.0 |
| SFT | – | – | 53.6 | 50.5 | 32.9 | 45.7 | 24.6 | 22.8 | 25.7 | 20.9 | 22.6 | 23.1 |
| REINFORCE | rule based | binary | 58.5 | 66.5 | 46.7 | 57.2 | 25.3 | 26.6 | 27.7 | 21.1 | 20.7 | 24.2 |
| soft | 46.0 | 47.7 | 31.5 | 41.7 | 22.0 | 20.3 | 23.1 | 16.9 | 20.5 | 20.3 | ||
| Qwen2.5-72BInstruct | binary | 64.4 | 72.1 | 51.6 | 62.7 | 27.9 | 27.9 | 30.7 | 24.4 | 23.2 | 26.6 | |
| soft | 62.5 | 71.2 | 53.1 | 62.3 | 32.2 | 32.8 | 36.0 | 24.9 | 27.9 | 30.3 | ||
| RM-7B (ours) | binary | 63.8 | 71.7 | 51.9 | 62.5 | 29.0 | 29.1 | 28.4 | 23.8 | 24.8 | 27.3 | |
| soft | 62.9 | 70.7 | 53.0 | 62.2 | 32.7 | 32.8 | 35.6 | 28.6 | 27.4 | 31.2 | ||
| REINFORCE++ | rule based | binary | 56.4 | 65.5 | 47.6 | 56.5 | 26.1 | 26.1 | 26.4 | 21.8 | 24.7 | 25.0 |
| soft | 49.4 | 52.9 | 36.2 | 46.2 | 22.5 | 22.0 | 25.7 | 18.6 | 20.2 | 21.4 | ||
| Qwen2.5-72BInstruct | binary | 63.0 | 71.3 | 50.4 | 61.6 | 30.7 | 32.8 | 34.3 | 27.5 | 27.8 | 30.3 | |
| soft | 62.7 | 70.4 | 50.5 | 61.2 | 30.8 | 30.1 | 33.7 | 25.6 | 25.4 | 28.8 | ||
| RM-7B (ours) | binary | 63.1 | 71.3 | 51.5 | 62.0 | 30.2 | 30.8 | 31.0 | 26.6 | 26.3 | 29.1 | |
| soft | 62.7 | 70.3 | 50.8 | 61.3 | 29.5 | 31.7 | 33.7 | 25.8 | 26.2 | 29.0 | ||
| RLOO | rule based | binary | 58.2 | 67.0 | 50.2 | 58.5 | 28.2 | 27.9 | 27.4 | 22.4 | 24.5 | 26.3 |
| soft | 49.6 | 50.3 | 33.9 | 44.6 | 16.7 | 17.3 | 18.8 | 14.5 | 16.9 | 16.6 | ||
| Qwen2.5-72BInstruct | binary | 63.0 | 70.8 | 51.1 | 61.6 | 29.4 | 30.5 | 33.7 | 24.6 | 26.1 | 28.4 | |
| soft | 63.8 | 71.0 | 52.4 | 62.4 | 32.9 | 31.4 | 34.7 | 27.7 | 26.8 | 30.6 | ||
| RM-7B (ours) | binary | 63.4 | 71.8 | 53.8 | 63.0 | 29.3 | 29.0 | 33.3 | 25.8 | 25.6 | 28.1 | |
| soft | 63.3 | 71.7 | 53.6 | 62.9 | 31.0 | 32.0 | 35.6 | 27.0 | 27.0 | 30.0 | ||
🔼 This table compares the performance of different methods for solving math and multi-subject problems. The base model used is Qwen-2.5-7B. Different methods (including fine-tuning (SFT) and reinforcement learning (RL) with rule-based and model-based rewards (both binary and soft)) are compared. The evaluation is done across three difficulty levels (elementary, middle, and high) for math problems and multiple subject categories for the multi-subject problems. The results are presented in terms of average accuracy across different categories for math and multi-subject tasks.
read the caption
Table 1: Performance Comparison of Different Methods. Base model: Qwen2.5-7B. E: elementary. M: middle. H: high.
In-depth insights#
RLVR Extension#
Extending RLVR to diverse domains is promising given its success in structured tasks. Cross-domain reward models could be key, negating the need for domain-specific annotations. Model-based soft scoring enhances flexibility when dealing with unstructured answers. This approach could improve LLMs’ reasoning across fields like medicine, economics and law. The potential for better performance over current models also exists. Scalability and robustness are increased, which is beneficial in noisy, real-world scenarios.
Cross-Domain Verifier#
A cross-domain verifier is a generalized evaluation mechanism applicable across diverse tasks. Its value lies in eliminating the need for task-specific training data. This is particularly useful when dealing with the problem of domain adaptation where knowledge is transferred from one domain to another. The efficacy hinges on its ability to discern correct and incorrect responses without being tailored to the nuances of a specific field. It streamlines the reward system in reinforcement learning, where feedback must be provided for a variety of actions. The challenge for cross-domain verifiers is to maintain accuracy while operating on different types of data. By using a single model, it greatly reduces the need to create and maintain individual reward systems, thereby making it more scalable.
Model-Based Rewards#
Model-based rewards offer a compelling alternative to rule-based systems in reinforcement learning, particularly when dealing with complex, unstructured data. Instead of relying on predefined rules (e.g., exact match), a trained reward model learns to assess the quality of generated responses. This approach offers greater flexibility and adaptability, especially in domains where nuanced understanding is required. Also, model-based rewards provide a more robust and scalable solution in the long run. Further, generative verifiers give stable and informative reward signals, enhancing the robustness of RL training in the presence of noise and ambiguity.
Scalable RLVR#
While “Scalable RLVR” isn’t explicitly a heading, the paper addresses scalability by demonstrating RLVR’s effectiveness beyond limited domains like math and coding, extending it to diverse areas such as medicine and economics. The paper underscores that a reasonably effective verifier can be trained for diverse domains using a relatively small LLM, achieving downstream performance comparable to much larger generative verifiers without the need for task-specific annotations. It is also important to highlight that, the model reward demonstrates consistent improvement trends throughout the training process, and this demonstrates the scalability as well.
RLVR vs. SFT#
RLVR significantly outperforms SFT. SFT’s limited gains suggest that direct fine-tuning with labels alone is insufficient for complex reasoning. The key difference likely lies in RLVR’s iterative refinement process. RLVR leverages a reward signal to guide exploration, allowing the model to discover more effective reasoning strategies compared to SFT. This shows RLVR’s exploration helps improve reasoning, it allows the model to try many strategies that it doesn’t have access to with SFT.
More visual insights#
More on figures
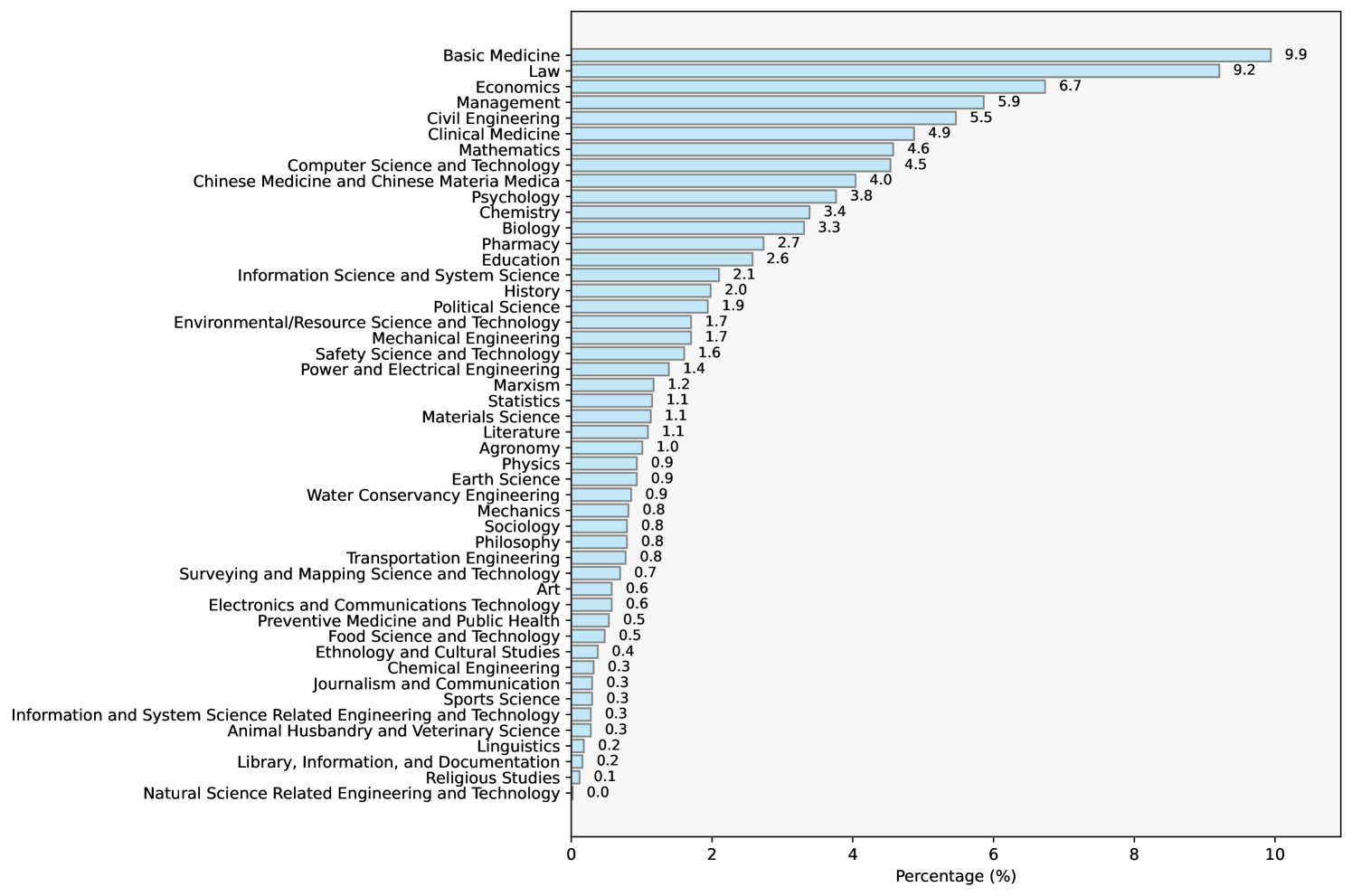
🔼 This bar chart visualizes the distribution of subjects within the ExamQA test set, excluding unclassified entries. Each bar represents a subject category, and its height corresponds to the percentage of questions belonging to that subject. The chart helps illustrate the diversity of subject matter within the dataset, showing which subjects are more prevalent than others in the test set used for evaluating the models.
read the caption
Figure 2: Distribution of subject occurrences in the test set of ExamQA (excluding unclassified).

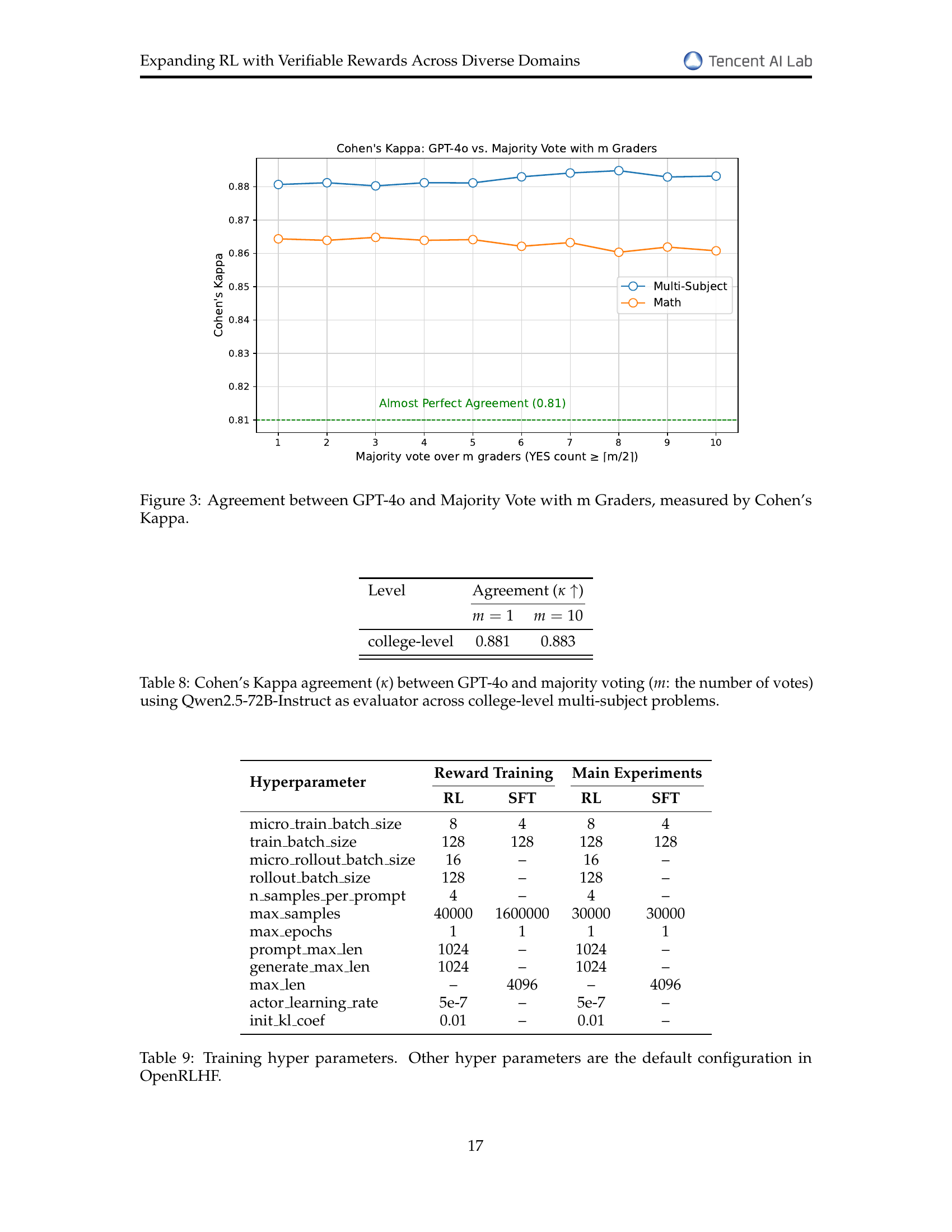
🔼 This figure displays the level of agreement between using GPT-4 as a single evaluator versus using majority voting from multiple (m) Qwen2.5-72B-Instruct evaluators. The agreement is measured using Cohen’s Kappa, a statistical measure of inter-rater reliability. The x-axis represents the number of Qwen2.5-72B-Instruct evaluators used in the majority voting (m), and the y-axis shows the corresponding Cohen’s Kappa score. Separate lines are plotted for math problems and multi-subject problems, illustrating how agreement varies depending on the type of problem and the number of evaluators. The chart shows a high level of agreement (approaching perfect agreement at 0.81 or higher) across various values of m, regardless of the problem type. This indicates robustness of the evaluation method.
read the caption
Figure 3: Agreement between GPT-4o and Majority Vote with m Graders, measured by Cohen’s Kappa.
More on tables
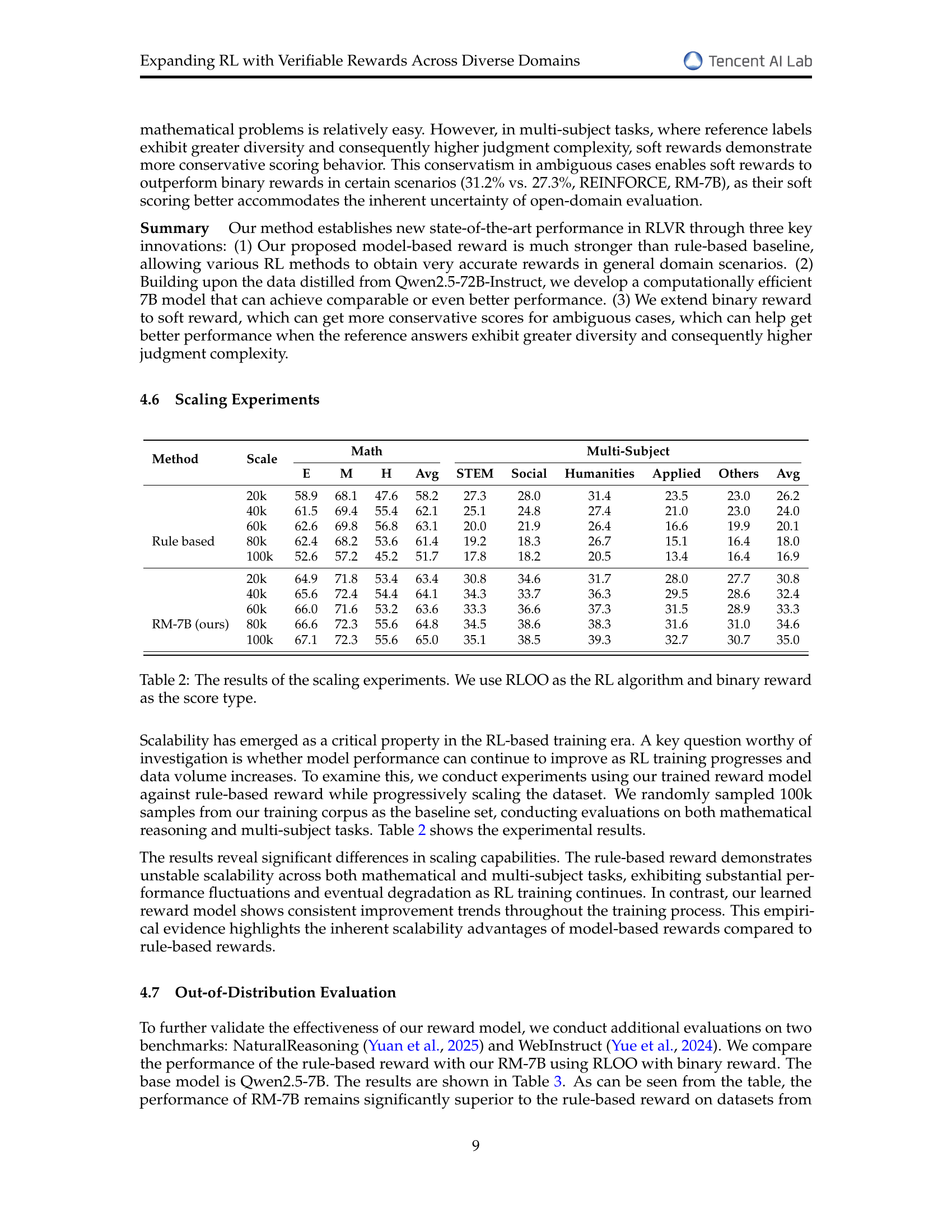
| Method | Scale | Math | Multi-Subject | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| E | M | H | Avg | STEM | Social | Humanities | Applied | Others | Avg | ||
| Rule based | 20k | 58.9 | 68.1 | 47.6 | 58.2 | 27.3 | 28.0 | 31.4 | 23.5 | 23.0 | 26.2 |
| 40k | 61.5 | 69.4 | 55.4 | 62.1 | 25.1 | 24.8 | 27.4 | 21.0 | 23.0 | 24.0 | |
| 60k | 62.6 | 69.8 | 56.8 | 63.1 | 20.0 | 21.9 | 26.4 | 16.6 | 19.9 | 20.1 | |
| 80k | 62.4 | 68.2 | 53.6 | 61.4 | 19.2 | 18.3 | 26.7 | 15.1 | 16.4 | 18.0 | |
| 100k | 52.6 | 57.2 | 45.2 | 51.7 | 17.8 | 18.2 | 20.5 | 13.4 | 16.4 | 16.9 | |
| RM-7B (ours) | 20k | 64.9 | 71.8 | 53.4 | 63.4 | 30.8 | 34.6 | 31.7 | 28.0 | 27.7 | 30.8 |
| 40k | 65.6 | 72.4 | 54.4 | 64.1 | 34.3 | 33.7 | 36.3 | 29.5 | 28.6 | 32.4 | |
| 60k | 66.0 | 71.6 | 53.2 | 63.6 | 33.3 | 36.6 | 37.3 | 31.5 | 28.9 | 33.3 | |
| 80k | 66.6 | 72.3 | 55.6 | 64.8 | 34.5 | 38.6 | 38.3 | 31.6 | 31.0 | 34.6 | |
| 100k | 67.1 | 72.3 | 55.6 | 65.0 | 35.1 | 38.5 | 39.3 | 32.7 | 30.7 | 35.0 | |
🔼 This table presents the results of scaling experiments conducted to assess the impact of increasing dataset size on model performance in reinforcement learning (RL). The experiments used the RLOO RL algorithm and a binary reward system. The table shows accuracy results for both math and multi-subject tasks at different training dataset sizes (20k, 40k, 60k, 80k, and 100k samples). Separate results are given for each task and for several subcategories within the multi-subject task, allowing for a detailed analysis of how model performance changes as the amount of training data increases.
read the caption
Table 2: The results of the scaling experiments. We use RLOO as the RL algorithm and binary reward as the score type.
| Method | Natural Reasoning | WebInstruct |
|---|---|---|
| Rule based | 29.4 | 33.9 |
| RM-7B (ours) | 39.8 | 44.0 |
🔼 This table presents the performance of the proposed model and a rule-based reward model on two out-of-distribution datasets: NaturalReasoning and WebInstruct. The results demonstrate the generalizability of the proposed model, showing that it maintains strong performance on unseen data, unlike the rule-based approach.
read the caption
Table 3: The results of the Out-of-Distribution evaluation
| ⬇ Given a problem, determine whether the final answer in the provided (incomplete) solution process matches the reference answer. The reference answer may be one single option character (e.g., A, B, C, D), a numerical value, an expression, or a list of answers if multiple questions are involved. **The reference answer may be in Chinese or another language, but your evaluation should be language-agnostic.** Your task: - Compare the final output of the solution process with the reference answer. - If they **match exactly**, output **YES**. - If they **do not match**, output **NO**. - If the solution process is unclear, incomplete, or ambiguous, assume it is incorrect and output **NO**. Your output must be strictly **’YES’** or **’NO’**, with no additional words, punctuation, or explanation. --- **Question:** {question} **Solution Process (Final Step Only):** {response} **Reference Answer:** {reference} **Output:** |
🔼 This table presents the template used for the grading task in the reinforcement learning process. It details the format and instructions for evaluating whether a model’s response correctly matches an expert-provided reference answer. The template guides the evaluation process by specifying how to compare the model’s output to the reference answer and to indicate whether there is an exact match or not. The instructions handle cases where the response might be ambiguous or incomplete. This ensures consistent evaluation across different reasoning tasks.
read the caption
Table 4: Template for the grading task.
| ⬇ Based on the content of ’Question’ and ’Answer’ classify the subject into one of the following categories. Return only the corresponding subject ID. If classification is uncertain, return 999. **Question:** {question} **Answer:** {answer} 110 Mathematics 120 Information Science and System Science 130 Mechanics 140 Physics 150 Chemistry 170 Earth Science 180 Biology 190 Psychology 210 Agronomy 230 Animal Husbandry and Veterinary Science 310 Basic Medicine 320 Clinical Medicine 330 Preventive Medicine and Public Health 350 Pharmacy 360 Chinese Medicine and Chinese Materia Medica 413 Information and System Science Related Engineering and Technology 416 Natural Science Related Engineering and Technology 420 Surveying and Mapping Science and Technology 430 Materials Science 460 Mechanical Engineering 470 Power and Electrical Engineering 510 Electronics and Communications Technology 520 Computer Science and Technology 530 Chemical Engineering 550 Food Science and Technology 560 Civil Engineering 570 Water Conservancy Engineering 580 Transportation Engineering 610 Environmental/Resource Science and Technology 620 Safety Science and Technology 630 Management 710 Marxism 720 Philosophy 730 Religious Studies 740 Linguistics 750 Literature 760 Art 770 History 790 Economics 810 Political Science 820 Law 840 Sociology 850 Ethnology and Cultural Studies 860 Journalism and Communication 870 Library, Information, and Documentation 880 Education 890 Sports Science 910 Statistics 999 Unclassified |
🔼 Table 5 presents a template used for a subject classification task. The template requires classifying a question and its answer into one of several predefined subject categories. Each category is assigned a unique numerical ID. The table lists these categories and their corresponding IDs, referencing the source (Yu et al., 2021) where these categories and IDs originated. This classification is crucial for organizing and analyzing the diverse question-answer pairs used in the paper’s experiments.
read the caption
Table 5: Template for the classification task, with subject names and IDs referenced from (Yu et al., 2021).
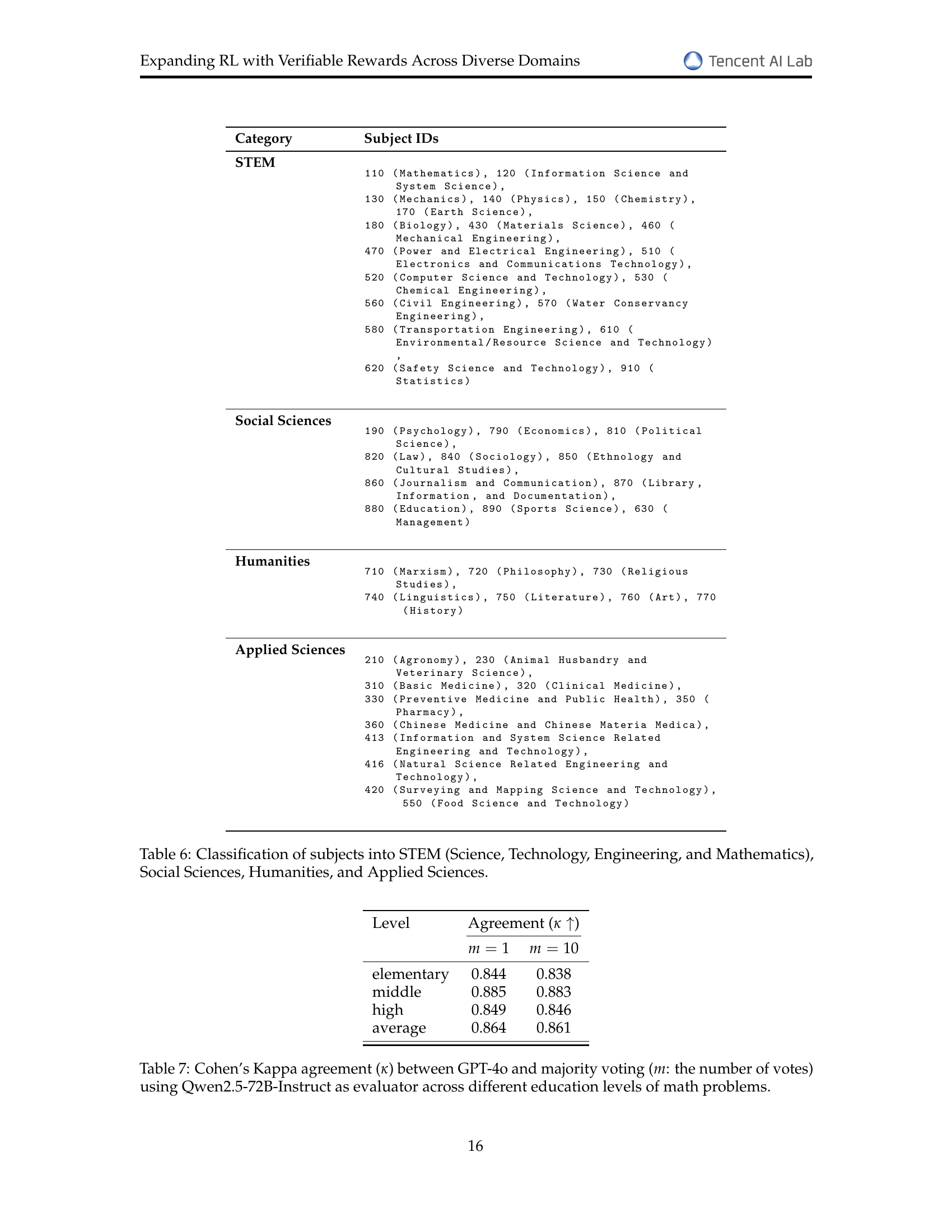
| Category | Subject IDs |
|---|---|
| STEM | ⬇ 110 (Mathematics), 120 (Information Science and System Science), 130 (Mechanics), 140 (Physics), 150 (Chemistry), 170 (Earth Science), 180 (Biology), 430 (Materials Science), 460 (Mechanical Engineering), 470 (Power and Electrical Engineering), 510 (Electronics and Communications Technology), 520 (Computer Science and Technology), 530 (Chemical Engineering), 560 (Civil Engineering), 570 (Water Conservancy Engineering), 580 (Transportation Engineering), 610 (Environmental/Resource Science and Technology), 620 (Safety Science and Technology), 910 (Statistics) |
| Social Sciences | ⬇ 190 (Psychology), 790 (Economics), 810 (Political Science), 820 (Law), 840 (Sociology), 850 (Ethnology and Cultural Studies), 860 (Journalism and Communication), 870 (Library, Information, and Documentation), 880 (Education), 890 (Sports Science), 630 (Management) |
| Humanities | ⬇ 710 (Marxism), 720 (Philosophy), 730 (Religious Studies), 740 (Linguistics), 750 (Literature), 760 (Art), 770 (History) |
| Applied Sciences | ⬇ 210 (Agronomy), 230 (Animal Husbandry and Veterinary Science), 310 (Basic Medicine), 320 (Clinical Medicine), 330 (Preventive Medicine and Public Health), 350 (Pharmacy), 360 (Chinese Medicine and Chinese Materia Medica), 413 (Information and System Science Related Engineering and Technology), 416 (Natural Science Related Engineering and Technology), 420 (Surveying and Mapping Science and Technology), 550 (Food Science and Technology) |
🔼 This table categorizes the subjects from the ExamQA dataset into four broader categories: STEM (Science, Technology, Engineering, and Mathematics), Social Sciences, Humanities, and Applied Sciences. For each category, it lists the specific subject IDs from the ExamQA dataset that fall under that category, providing a more granular understanding of the dataset’s composition.
read the caption
Table 6: Classification of subjects into STEM (Science, Technology, Engineering, and Mathematics), Social Sciences, Humanities, and Applied Sciences.
| Level | Agreement () | |
|---|---|---|
| elementary | 0.844 | 0.838 |
| middle | 0.885 | 0.883 |
| high | 0.849 | 0.846 |
| average | 0.864 | 0.861 |
🔼 This table displays the level of agreement between evaluations performed by GPT-40 and majority voting using Qwen2.5-72B-Instruct, assessing the correctness of answers to math problems at various educational levels (elementary, middle, and high school). The Cohen’s Kappa (κ) statistic quantifies the agreement, indicating the consistency between the two evaluation methods. Different numbers of votes (m) in the majority voting are considered. Higher Kappa values indicate stronger agreement. This demonstrates how well the majority voting approach using Qwen2.5-72B-Instruct aligns with the judgements made by GPT-40.
read the caption
Table 7: Cohen’s Kappa agreement (κ𝜅\kappaitalic_κ) between GPT-4o and majority voting (m𝑚mitalic_m: the number of votes) using Qwen2.5-72B-Instruct as evaluator across different education levels of math problems.
| Level | Agreement () | |
|---|---|---|
| college-level | 0.881 | 0.883 |
🔼 This table presents the level of agreement between evaluations performed by GPT-40 and a majority voting system using Qwen2.5-72B-Instruct on college-level multi-subject problems. It shows Cohen’s Kappa (κ), a statistical measure of inter-rater reliability, for different numbers of votes (m) in the majority voting process. A higher Kappa value indicates stronger agreement between the two evaluation methods.
read the caption
Table 8: Cohen’s Kappa agreement (κ𝜅\kappaitalic_κ) between GPT-4o and majority voting (m𝑚mitalic_m: the number of votes) using Qwen2.5-72B-Instruct as evaluator across college-level multi-subject problems.
| Hyperparameter | Reward Training | Main Experiments | ||
| RL | SFT | RL | SFT | |
| micro_train_batch_size | 8 | 4 | 8 | 4 |
| train_batch_size | 128 | 128 | 128 | 128 |
| micro_rollout_batch_size | 16 | – | 16 | – |
| rollout_batch_size | 128 | – | 128 | – |
| n_samples_per_prompt | 4 | – | 4 | – |
| max_samples | 40000 | 1600000 | 30000 | 30000 |
| max_epochs | 1 | 1 | 1 | 1 |
| prompt_max_len | 1024 | – | 1024 | – |
| generate_max_len | 1024 | – | 1024 | – |
| max_len | – | 4096 | – | 4096 |
| actor_learning_rate | 5e-7 | – | 5e-7 | – |
| init_kl_coef | 0.01 | – | 0.01 | – |
🔼 Table 9 presents the hyperparameters used during training of the reward model and the main RL experiments. It lists values for parameters such as batch size (both micro and macro), number of rollout samples, maximum number of samples, number of epochs, maximum sequence lengths (for prompts and generation), learning rate, and the initial KL coefficient. The table highlights that some hyperparameters, not explicitly listed, were set to their default values within the OpenRLHF framework.
read the caption
Table 9: Training hyper parameters. Other hyper parameters are the default configuration in OpenRLHF.
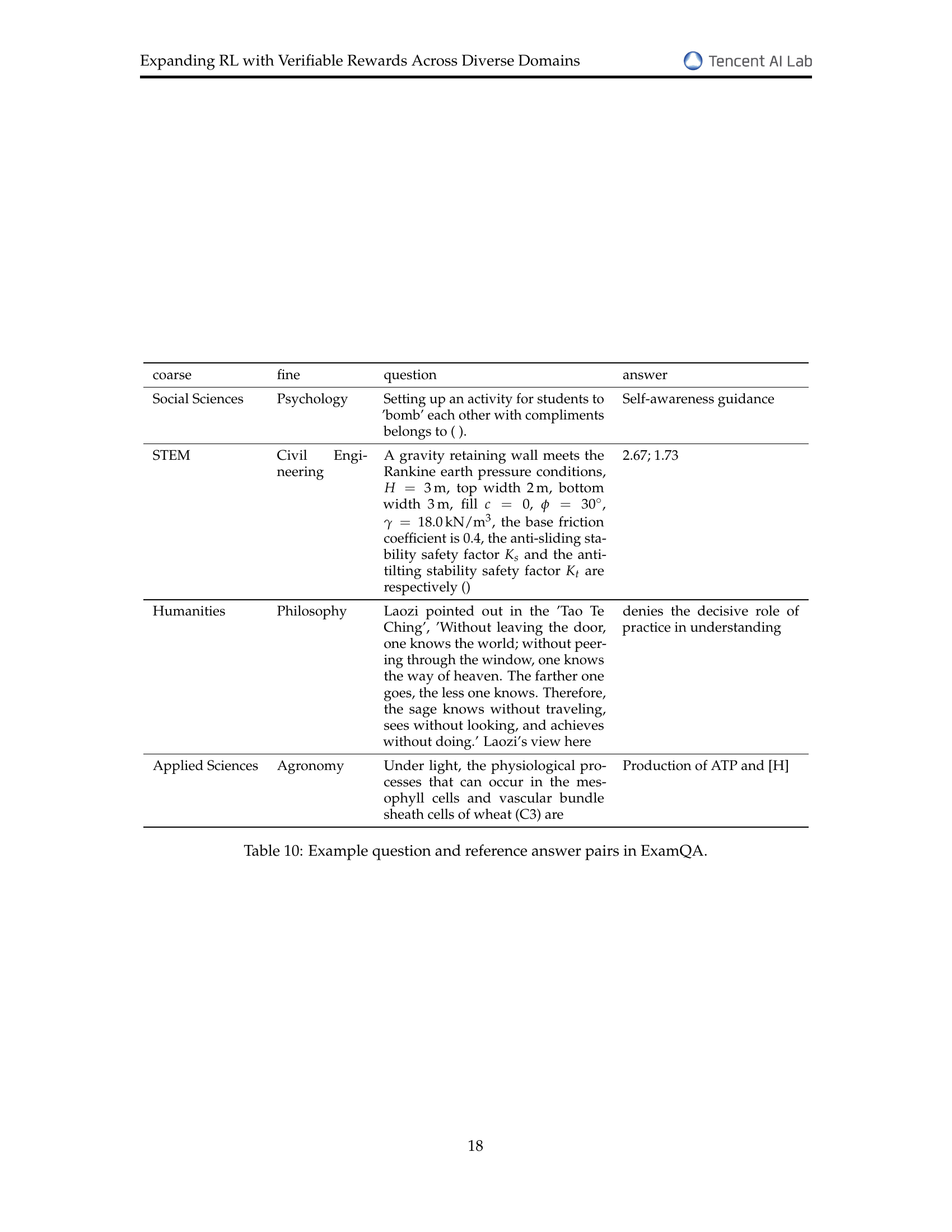
| coarse | fine | question | answer |
|---|---|---|---|
| Social Sciences | Psychology | Setting up an activity for students to ’bomb’ each other with compliments belongs to ( ). | Self-awareness guidance |
| STEM | Civil Engineering | A gravity retaining wall meets the Rankine earth pressure conditions, , top width , bottom width , fill , , , the base friction coefficient is 0.4, the anti-sliding stability safety factor and the anti-tilting stability safety factor are respectively () | 2.67; 1.73 |
| Humanities | Philosophy | Laozi pointed out in the ’Tao Te Ching’, ’Without leaving the door, one knows the world; without peering through the window, one knows the way of heaven. The farther one goes, the less one knows. Therefore, the sage knows without traveling, sees without looking, and achieves without doing.’ Laozi’s view here | denies the decisive role of practice in understanding |
| Applied Sciences | Agronomy | Under light, the physiological processes that can occur in the mesophyll cells and vascular bundle sheath cells of wheat (C3) are | Production of ATP and [H] |
🔼 This table provides example question and reference answer pairs from the ExamQA dataset used in the paper. It showcases the diversity of questions and the free-form nature of the answers across multiple domains (Social Sciences, STEM, Humanities, and Applied Sciences). Each row represents a question from a specific domain, its corresponding reference answer and the domain it belongs to.
read the caption
Table 10: Example question and reference answer pairs in ExamQA.
Full paper#