TL;DR#
The detection of telecom fraud faces challenges due to the lack of high-quality multimodal training data that integrates audio signals with reasoning-oriented textual analysis. Traditional methods rely on manual verification and rule-based matching, which have low accuracy and struggle to adapt to evolving strategies. Recent advancements in LLMs offer new solutions, but current methods exhibit a significant modality gap and performance variations. This shows the importance of having a comprehensive multimodal telecom fraud dataset.
To address these issues, the authors present TeleAntiFraud-28k, the first open-source audio-text slow-thinking dataset for automated telecom fraud analysis. The dataset is constructed through privacy-preserved text-truth sample generation, semantic enhancement via LLM-based self-instruction sampling, and multi-agent adversarial synthesis. The authors construct TeleAntiFraud-Bench, a standardized evaluation benchmark, and contribute a production-optimized SFT model trained on hybrid real/synthetic data, open-sourcing the data processing framework for community-driven dataset expansion.
Key Takeaways#
Why does it matter?#
This paper introduces a novel multimodal dataset and benchmark for telecom fraud detection, addressing critical data scarcity and privacy challenges while opening new avenues for research in AI-driven fraud prevention and analysis.
Visual Insights#
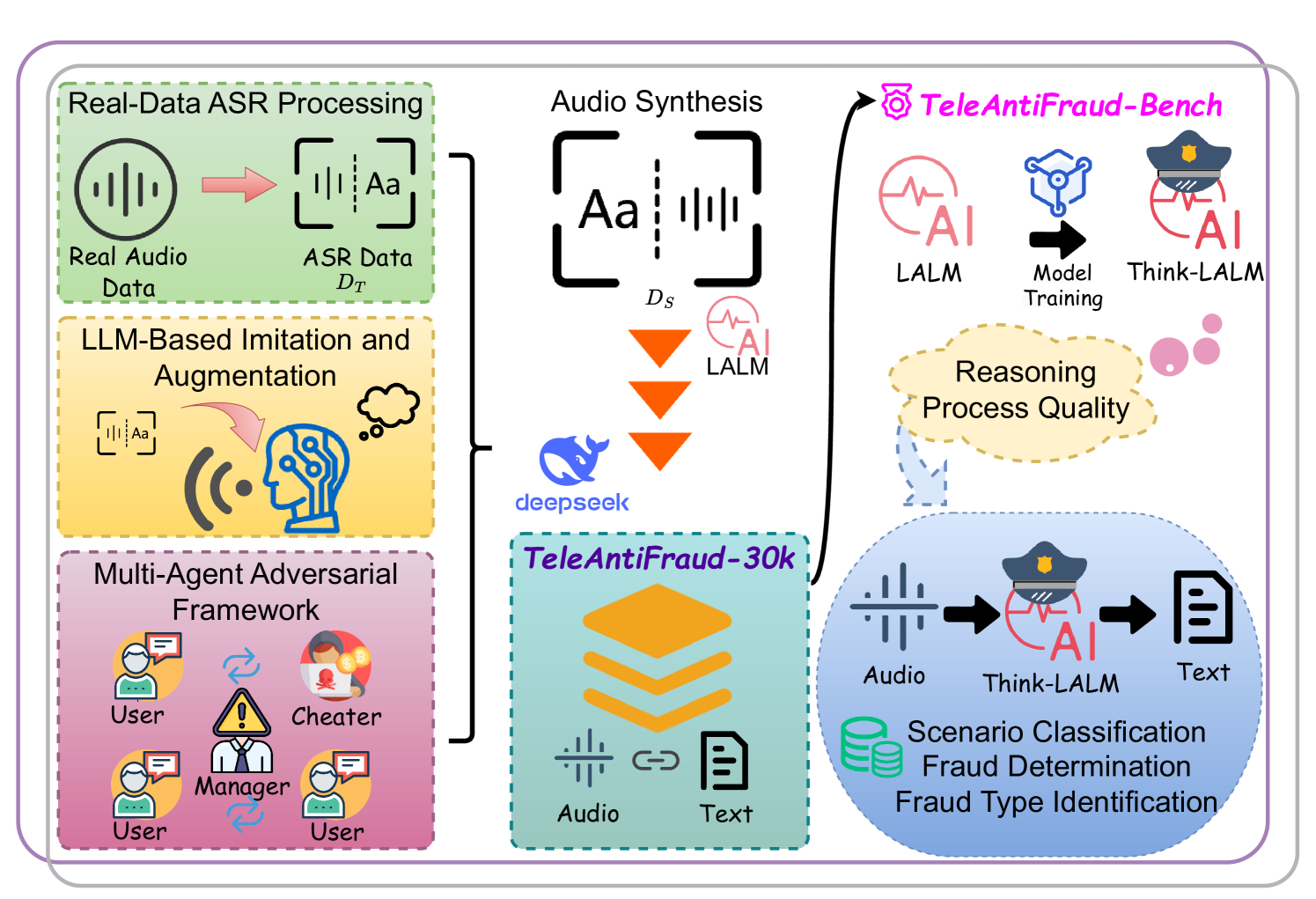
🔼 This figure illustrates the architecture of the TeleAntiFraud-30k system, designed to tackle the challenges in telecom fraud detection. It highlights the three key strategies used to build the TeleAntiFraud-28k dataset: 1) Real-Data ASR Processing, which involves transcribing real audio data while preserving privacy, 2) LLM-Based Imitation and Augmentation which uses large language models to generate synthetic data that augments the real data, and 3) Multi-agent Adversarial Synthesis, which simulates realistic and diverse fraud scenarios. The system also includes TeleAntiFraud-Bench, a standardized benchmark for evaluating model performance, and a fine-tuned, open-source model for supervised learning.
read the caption
Figure 1. An overview of TeleAntiFraud-30k. Our system addresses the challenges of telecom fraud detection. We create the TeleAntiFraud-28k dataset through three strategies: Real-Data ASR Processing, LLM-Based Imitation adn Augmention, and multi-agent adversarial synthesis. We also construct TeleAntiFraud-Bench for model evaluation and contribute a supervised fine-tuning model with an open-sourced data processing framework.
| Type | Total | Scam Calls | Normal Calls |
|---|---|---|---|
| Train | 21,490 | 9,950 (46.3%) | 11,540 (53.7%) |
| Test | 7,021 | 3,697 (52.66%) | 3,324 (47.34%) |
| Total | 28,511 | 13,647 (47.86%) | 14,864 (52.13%) |
🔼 This table shows the distribution of scam and normal calls within the TeleAntiFraud-28k dataset. It breaks down the total number of calls (28,511) into training and testing sets, further categorized by whether each call is fraudulent or not. The percentages provided illustrate the proportion of scam and normal calls in each set and the overall dataset, offering insight into the class imbalance present in the data.
read the caption
Table 1. Distribution of Scam and Normal Calls in the Dataset
In-depth insights#
AntiFraud Dataset#
The paper introduces TeleAntiFraud-28k, a novel audio-text dataset for telecom fraud detection. A key aspect is its focus on slow-thinking reasoning, going beyond simple pattern recognition to simulate expert fraud analysis. The dataset addresses the critical lack of high-quality multimodal data that combines audio signals with textual context. The construction involves innovative techniques like privacy-preserved ASR transcription and LLM-based semantic augmentation. A multi-agent adversarial framework simulates diverse fraud scenarios, tackling the limited variety in existing datasets. The TeleAntiFraud-Bench evaluation framework provides a standardized way to assess model performance in scenario classification, fraud detection, and type classification. The dataset seeks to facilitate research into more robust and intelligent anti-fraud systems by offering a challenging resource that tackles issues such as data privacy and scenario diversity. The release of the data processing framework further aims to encourage community-driven dataset expansion, thereby helping to spur innovation in multimodal anti-fraud research.
Multi-Modal Models#
Multimodal models are increasingly vital, leveraging diverse data such as audio, text, and images to enhance AI systems. Their capacity to integrate varied inputs allows for more robust and nuanced understanding compared to unimodal approaches. In fraud detection, multimodal models can combine speech patterns, text analysis, and visual cues to identify deceptive behaviors more effectively. Challenges include data synchronization, feature fusion, and the need for large, diverse datasets. Future advancements will likely focus on developing more efficient fusion techniques and addressing privacy concerns in handling sensitive data.
Data Generation#
The data generation process is crucial for telecom fraud detection due to the lack of high-quality multimodal training data. This paper addresses this by constructing ‘TeleAntiFraud-28k’, utilizing three strategies. The first is privacy-preserved text-truth sample generation using ASR-transcribed call recordings with TTS regeneration, ensuring real-world consistency. The second involves semantic enhancement via LLM-based self-instruction sampling on authentic ASR outputs to expand scenario coverage. The third strategy employs multi-agent adversarial synthesis to simulate emerging fraud tactics. This comprehensive approach aims to create a dataset that is both diverse and realistic, addressing critical challenges in data privacy and scenario diversity for multimodal anti-fraud research.
Thinking Process#
Analyzing the ‘Thinking Process’ in AI, especially concerning fraud detection, highlights the critical need for models to mimic human expert reasoning. It’s about moving beyond simple pattern recognition to structured analysis, similar to how a professional would assess a situation. Key is the model’s ability to articulate its reasoning, demonstrating a clear chain of thought from evidence to conclusion. This involves assessing emotional cues, request legitimacy, and information disclosure patterns. A successful ‘Thinking Process’ requires the AI to not only identify fraud but also explain why, increasing trust and explainability. By incorporating detailed annotations about each step of the reasoning process it helps in generating structured responses and improve the overall process.
Model Ablation#
Ablation studies are vital for understanding a model’s inner workings. By systematically removing components, such as specific layers, attention mechanisms, or input features, we can gauge each element’s contribution to overall performance. In the context of telecom fraud detection, ablating audio features reveals the text’s baseline effectiveness, while ablating slow-thinking components highlights their impact on reasoning. Such experiments not only identify redundancies but also expose crucial interactions between different modalities. This rigorous analysis guides future model development towards leaner, more effective architectures, enhancing fraud detection accuracy and efficiency by pinpointing the most influential aspects of the model, thereby making it interpretable and improving trust with business stakeholders. Furthermore, ablation of certain input features provides insight into which particular real-world interactions and indicators contribute more substantially to a model’s predictive power, leading to better understanding of telecommunication fraud.
More visual insights#
More on figures
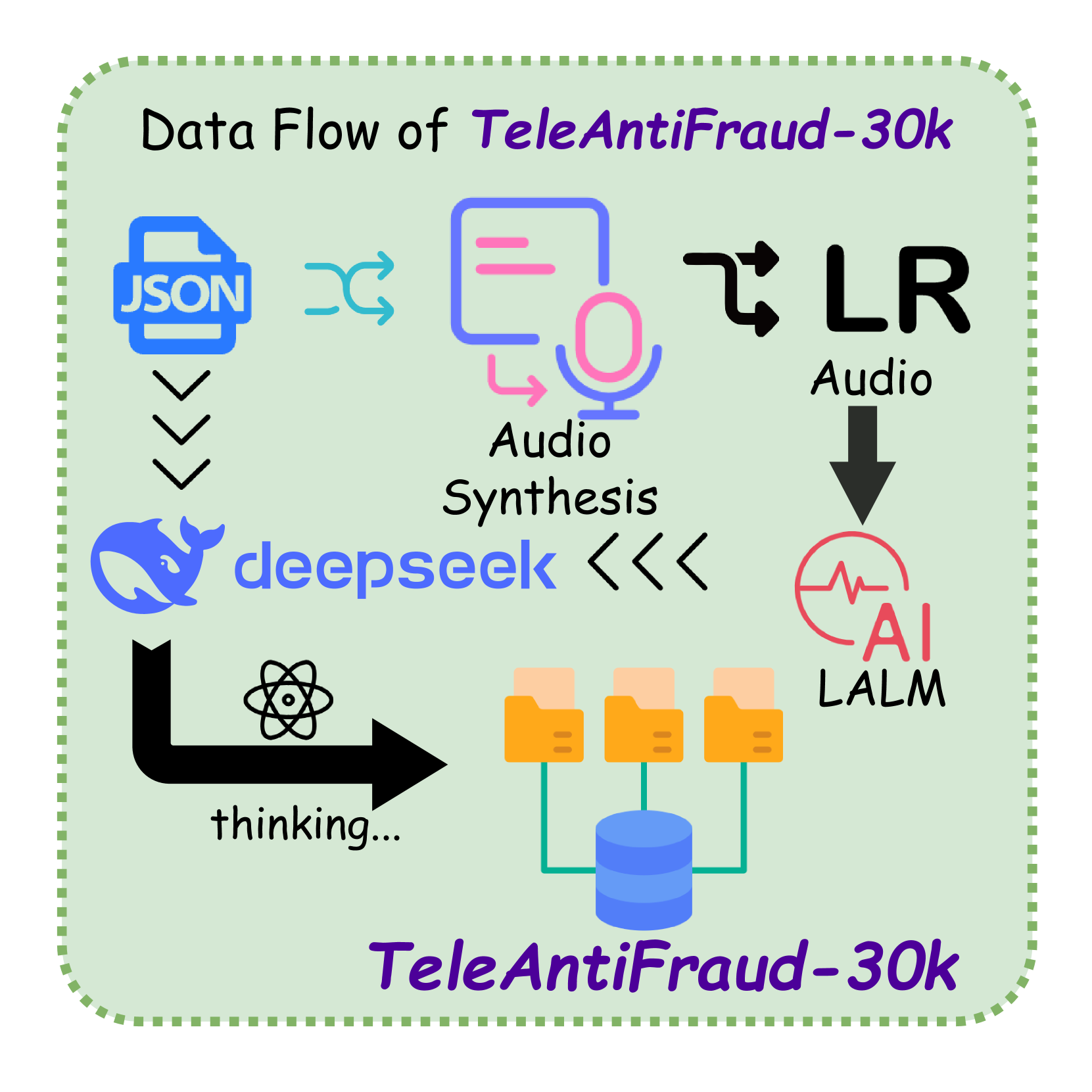
🔼 This figure illustrates the process of generating audio data for the TeleAntiFraud-28k dataset. It begins with JSON data representing various conversation scenarios, which is then processed through an audio synthesis module to create realistic-sounding audio. A large language model (LALM), denoted as ‘deepseek’, plays a role in this generation process, likely contributing to the realism or complexity of the synthesized audio. The result is the final generated audio data which is used for the dataset.
read the caption
Figure 2. Data Flow of Audio Data Generation

🔼 This figure illustrates the architecture of a multi-agent adversarial framework used to generate diverse and realistic conversations for a telecom fraud detection dataset. Three agents interact: a user, a fraudster (cheater), and a manager. The user and cheater agents use large language models (LLMs) to generate their dialogue turns. The manager agent oversees the conversation to ensure it aligns with defined fraud scenarios and ensures a natural flow. This framework enables the creation of realistic and diverse conversations simulating various fraud tactics, enriching the training data for fraud detection models.
read the caption
Figure 3. Architecture Diagram of the Multi-Agent Adversarial Framework
More on tables
| Scenario Type | Training Set | Test Set |
|---|---|---|
| Customer Service Inquiries | 6,421 | 4,632 |
| Appointment Services | 1,714 | 867 |
| Daily Shopping | 924 | 340 |
| Food Ordering Services | 581 | 154 |
| Delivery Services | 494 | 448 |
| Ride-hailing Services | 353 | 489 |
| Transportation Inquiries | 223 | 91 |
| Total | 10,710 | 7,021 |
🔼 This table shows the distribution of different call scenarios in both the training and test sets of the TeleAntiFraud-28k dataset. It breaks down the number of samples for each scenario type, providing insights into the dataset’s composition and balance across various real-world communication contexts. This is useful for understanding the representativeness of the dataset and its suitability for training and evaluating models.
read the caption
Table 2. Distribution of scenario types in training and test sets
| Fraud Type | Training Set | Test Set |
|---|---|---|
| Customer Service Fraud | 2,022 | 725 |
| Banking Fraud | 1,626 | 2,408 |
| Investment Fraud | 785 | 216 |
| Phishing Fraud | 443 | 123 |
| Lottery Fraud | 418 | 99 |
| Kidnapping Fraud | 324 | 91 |
| Identity Theft | 105 | 35 |
| Total | 5,723 | 3,697 |
🔼 This table shows the distribution of different fraud types within the training and test sets of the TeleAntiFraud-28k dataset. It breaks down the number of instances of each fraud type in both the training portion (used to train machine learning models) and the testing portion (used to evaluate the performance of trained models) of the dataset. This allows researchers to understand the class distribution and potential class imbalance issues within the dataset.
read the caption
Table 3. Distribution of fraud types in training and test sets
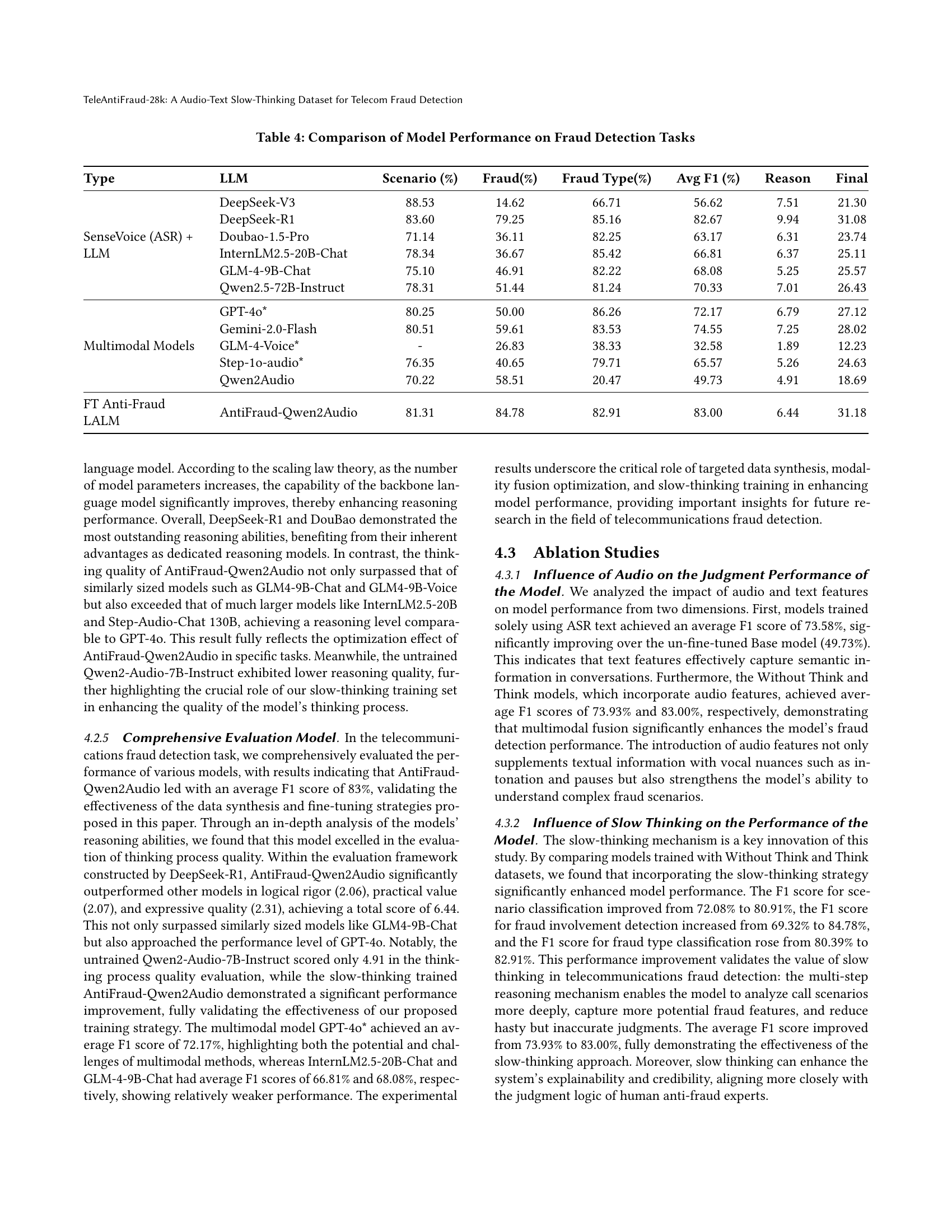
| Type | LLM | Scenario (%) | Fraud(%) | Fraud Type(%) | Avg F1 (%) | Reason | Final | ||
|---|---|---|---|---|---|---|---|---|---|
| SenseVoice (ASR) + LLM | DeepSeek-V3 | 88.53 | 14.62 | 66.71 | 56.62 | 7.51 | 21.30 | ||
| DeepSeek-R1 | 83.60 | 79.25 | 85.16 | 82.67 | 9.94 | 31.08 | |||
| Doubao-1.5-Pro | 71.14 | 36.11 | 82.25 | 63.17 | 6.31 | 23.74 | |||
| InternLM2.5-20B-Chat | 78.34 | 36.67 | 85.42 | 66.81 | 6.37 | 25.11 | |||
| GLM-4-9B-Chat | 75.10 | 46.91 | 82.22 | 68.08 | 5.25 | 25.57 | |||
| Qwen2.5-72B-Instruct | 78.31 | 51.44 | 81.24 | 70.33 | 7.01 | 26.43 | |||
| Multimodal Models | GPT-4o* | 80.25 | 50.00 | 86.26 | 72.17 | 6.79 | 27.12 | ||
| Gemini-2.0-Flash | 80.51 | 59.61 | 83.53 | 74.55 | 7.25 | 28.02 | |||
| GLM-4-Voice* | - | 26.83 | 38.33 | 32.58 | 1.89 | 12.23 | |||
| Step-1o-audio* | 76.35 | 40.65 | 79.71 | 65.57 | 5.26 | 24.63 | |||
| Qwen2Audio | 70.22 | 58.51 | 20.47 | 49.73 | 4.91 | 18.69 | |||
| AntiFraud-Qwen2Audio | 81.31 | 84.78 | 82.91 | 83.00 | 6.44 | 31.18 |
🔼 This table presents a comparative analysis of various models’ performance across three key tasks in fraud detection: scenario classification, fraud detection, and fraud type identification. For each model, the table shows the F1-score achieved in each task, along with the average F1-score across all three tasks. Additionally, it provides scores reflecting the quality of the model’s reasoning process, and the final score (a weighted average). Model types are categorized as LLM (Large Language Model) based approaches, multimodal models, and a fine-tuned Anti-Fraud LALM (Large Audio Language Model). This allows for a comparison of different model architectures and strategies in the context of telecom fraud detection.
read the caption
Table 4. Comparison of Model Performance on Fraud Detection Tasks
| FT Anti-Fraud |
| LALM |
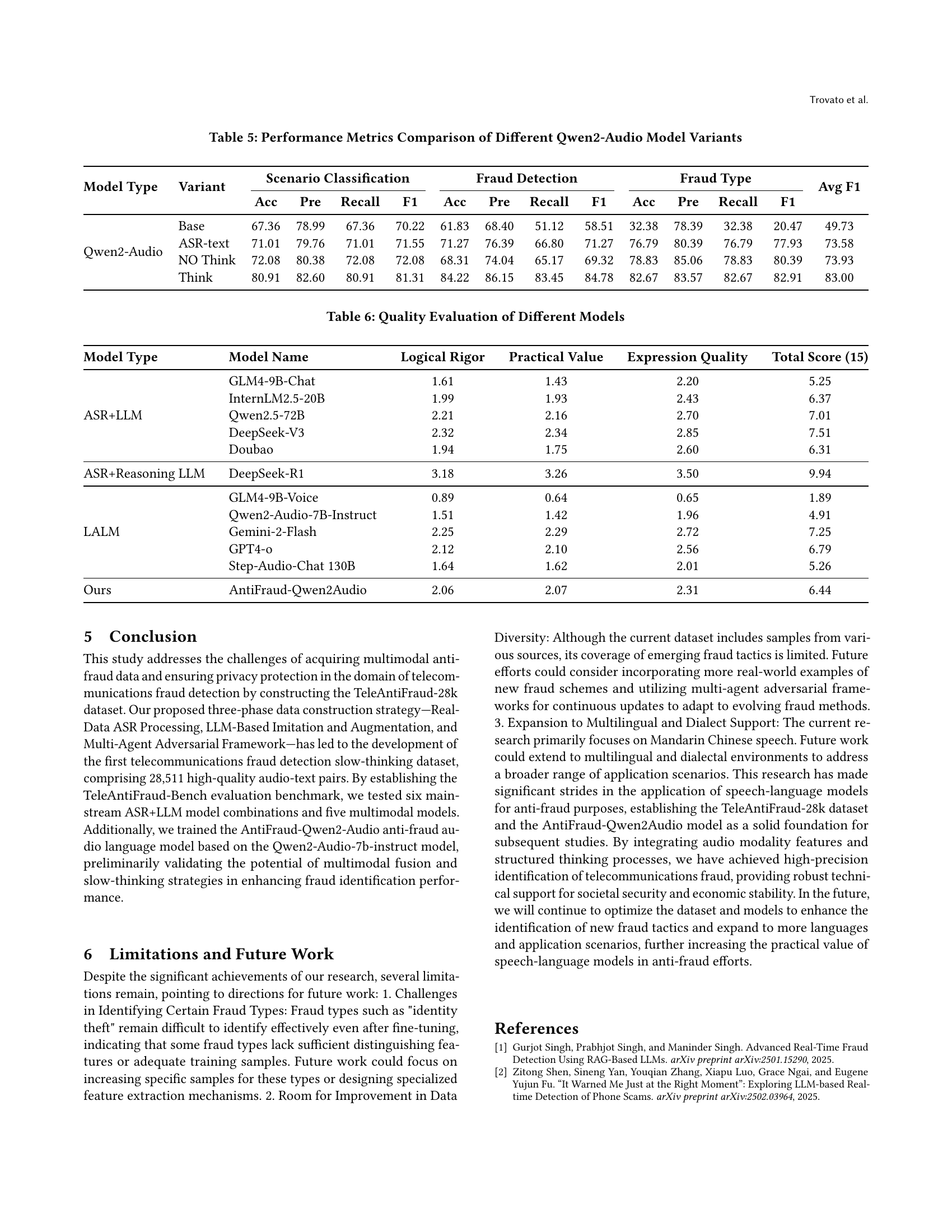
🔼 This table presents a comparison of the performance metrics for different variants of the Qwen2-Audio model on three tasks: scenario classification, fraud detection, and fraud type identification. The variants include a baseline model, a model trained only on ASR text, a model without the ‘Think’ mechanism (which incorporates slow-thinking reasoning), and a model with the ‘Think’ mechanism. The metrics shown for each variant and task include accuracy, precision, recall, and F1-score. This allows for a detailed analysis of how different training methods and model features impact the overall performance in identifying fraudulent activity.
read the caption
Table 5. Performance Metrics Comparison of Different Qwen2-Audio Model Variants
| Model Type | Variant | Scenario Classification | Fraud Detection | Fraud Type | Avg F1 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc | Pre | Recall | F1 | Acc | Pre | Recall | F1 | Acc | Pre | Recall | F1 | |||
| Qwen2-Audio | Base | 67.36 | 78.99 | 67.36 | 70.22 | 61.83 | 68.40 | 51.12 | 58.51 | 32.38 | 78.39 | 32.38 | 20.47 | 49.73 |
| ASR-text | 71.01 | 79.76 | 71.01 | 71.55 | 71.27 | 76.39 | 66.80 | 71.27 | 76.79 | 80.39 | 76.79 | 77.93 | 73.58 | |
| NO Think | 72.08 | 80.38 | 72.08 | 72.08 | 68.31 | 74.04 | 65.17 | 69.32 | 78.83 | 85.06 | 78.83 | 80.39 | 73.93 | |
| Think | 80.91 | 82.60 | 80.91 | 81.31 | 84.22 | 86.15 | 83.45 | 84.78 | 82.67 | 83.57 | 82.67 | 82.91 | 83.00 | |
🔼 This table presents a comprehensive quality assessment of various models used in the paper, focusing on their performance in a telecommunications fraud detection task. It evaluates three key aspects of the models’ reasoning processes: logical rigor, practical value, and expressive quality. Each model receives a score for each aspect, and a final total score is calculated to provide an overall ranking of their performance in terms of their ability to mimic the thoughtful, detailed reasoning process of a human expert. This is done to measure not just the accuracy of model answers, but the quality of their reasoning.
read the caption
Table 6. Quality Evaluation of Different Models
Full paper#