TL;DR#
Large Language Models (LLMs) are showing promise in complex problem-solving through Reinforcement Learning (RL) training. However, implementing such training at scale can be challenging. The paper introduces Open-Reasoner-Zero that addresses scalability, simplicity, and accessibility. The approach focuses on training LLMs to master diverse reasoning skills under verifiable rewards.
The work presents a minimalist approach using vanilla PPO with straightforward rule-based rewards. It achieves strong performance on benchmarks like AIME2024 and MATH500. The key is scaling data quantity and diversity, rather than complex algorithms. The authors open-source their implementation, including code, models, and training data. This should enable broader participation in LLM training.
Key Takeaways#
Why does it matter?#
This paper presents a accessible, scalable approach to reasoning-oriented RL training, offering valuable resources and insights for researchers. By open-sourcing code, data, and models, the authors facilitate broader exploration and participation in advancing LLMs, spurring innovation in AI.
Visual Insights#

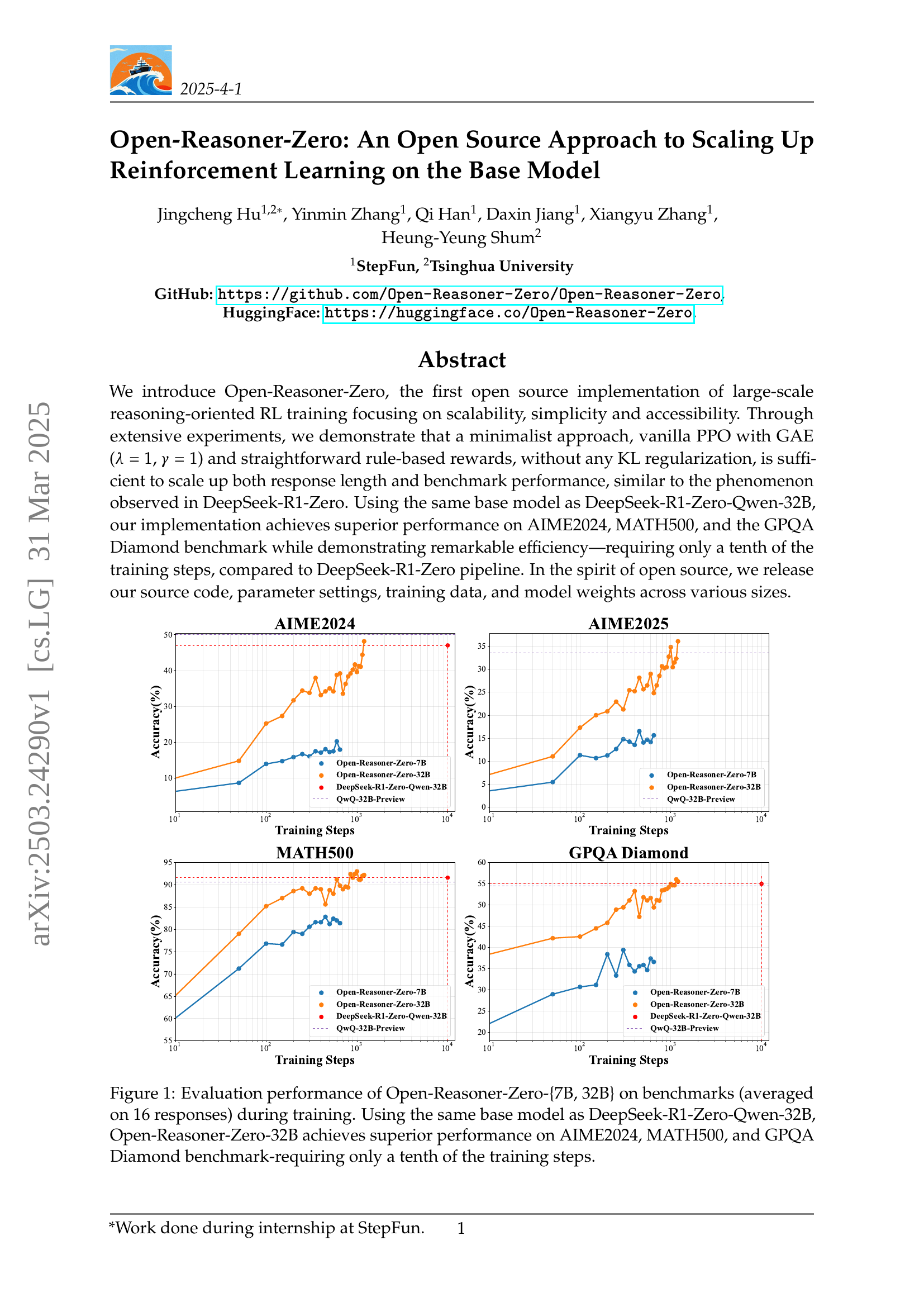
🔼 This figure displays the training performance of the Open-Reasoner-Zero models with 7 billion and 32 billion parameters on three reasoning benchmarks: AIME2024, MATH500, and GPQA Diamond. The x-axis represents the number of training steps, and the y-axis represents the accuracy achieved on each benchmark. The graph shows that the 32B parameter model surpasses the performance of the DeepSeek-R1-Zero-Qwen-32B model (which used as a baseline), reaching a similar level of accuracy with significantly fewer training steps (approximately one-tenth). This highlights the efficiency of the Open-Reasoner-Zero approach.
read the caption
Figure 1: Evaluation performance of Open-Reasoner-Zero-{7B, 32B} on benchmarks (averaged on 16 responses) during training. Using the same base model as DeepSeek-R1-Zero-Qwen-32B, Open-Reasoner-Zero-32B achieves superior performance on AIME2024, MATH500, and GPQA Diamond benchmark-requiring only a tenth of the training steps.
| A conversation between User and Assistant. The user asks a question, and the Assistant solves it. |
| The assistant first thinks about the reasoning process in the mind and then provides the user |
| with the answer. The reasoning process and answer are enclosed within <think> </think> and |
| <answer> </answer> tags, respectively, i.e., <think> reasoning process here </think> |
| <answer> answer here </answer>. User: You must put your answer inside <answer> </answer> tags, i.e., |
| <answer> answer here </answer>. And your final answer will be extracted automatically by the \boxed{} tag. |
| {{prompt}} |
| Assistant: <think> |
🔼 This table shows the template used for creating prompts in the Open-Reasoner-Zero training process. The template includes placeholders for the user’s question and the assistant’s response, clearly defining how the model should format its answer. The key element is the use of
<think>and<answer>tags to structure the reasoning process and the final answer, enabling automated extraction of the correct response for evaluating the model’s performance.read the caption
Table 1: Template for Open-Reasoner-Zero. prompt will be replaced with the specific reasoning question during training.
In-depth insights#
RLHF Scaling#
Scaling Reinforcement Learning from Human Feedback (RLHF) involves optimizing language models based on human preferences. Key areas include data scaling, ensuring sufficient high-quality feedback data; model scaling, leveraging larger models for improved performance; and algorithm scaling, developing more efficient RL algorithms and exploration strategies. Challenges involve reward hacking, instability, and generalization. Effective RLHF requires careful reward design, regularization techniques, and diverse training scenarios to achieve robust and scalable reasoning capabilities in language models. The process also involves efficient loss functions and thoughtful scaling for training data.
ORZ Framework#
While the paper doesn’t explicitly detail an “ORZ Framework” section, we can infer its components based on the Open-Reasoner-Zero’s overall methodology. At its core, the ORZ framework likely encompasses a minimalist yet scalable RL training pipeline for LLMs, emphasizing simplicity and accessibility. It probably features a vanilla PPO implementation with GAE, relying on straightforward, rule-based rewards, eschewing complex KL regularization to promote stable and efficient training. Crucially, the framework stresses high-quality, diverse training data curation to drive continuous improvement in reasoning capabilities. It also contains an efficient RL training using OpenRLHF with the flexibility to support GPU collocation generation, along with offload and backload support. ORZ framework can scale up the base models like Qwen 2.5 using PPO with careful hyperparameter tuning.
Vanilla PPO Key#
Vanilla PPO, a straightforward implementation of Proximal Policy Optimization, plays a crucial role in RL. Its simplicity allows for easier implementation and debugging, making it a good starting point for researchers and practitioners. Key benefits include its sample efficiency, as it reuses data through multiple gradient updates, and its ability to handle continuous action spaces. However, it has its challenges, such as the need for careful hyperparameter tuning to balance exploration and exploitation, and potential instability during training. In some domains, vanilla PPO’s performance might be limited compared to more sophisticated RL algorithms. Despite these limitations, it provides a robust framework for solving many control tasks.
Step Momenum#
While the provided document doesn’t explicitly use the term “Step Momentum,” the analysis of training dynamics reveals a related phenomenon. The observations of sudden, step-function-like increases in reward and response length at certain points during training, particularly in benchmarks like GPQA Diamond and AIME2024, strongly suggest a phase transition. This indicates that the models progressively master detailed and comprehensive reasoning capabilities as training advances. This “step moment” could represent a critical point where the model has internalized sufficient knowledge or developed a more efficient reasoning strategy, leading to a rapid improvement in performance. Further investigation into the underlying mechanisms driving this transition is warranted to potentially optimize training strategies and accelerate the development of reasoning abilities. Understanding what triggers these leaps could lead to more efficient training protocols. This could be because of a change in data distribution, sample noise and the nature of problem-solving complexity.
Data & Model Up#
While “Data & Model Up” wasn’t explicitly a section in the provided research paper, it encapsulates a core theme: scaling both data and model size is crucial for improved performance in reasoning-oriented reinforcement learning (RL). The paper emphasizes the importance of scaling data quantity, quality, and diversity for Reasoner-Zero training, noting that limited datasets like MATH lead to performance plateaus. They curate a large-scale, diverse dataset enabling continuous scaling without saturation. The impact of data scale is evidenced by results in Fig 9. Furthermore, the paper showcases the impact of model scaling by demonstrating consistent improvements in reasoning abilities as the model size increases from 0.5B to 32B parameters, substantiating the effectiveness of the minimalist RL approach. This underscores that the most significant gains come from increasing the scale of training data and model size, rather than focusing on complex design choices, echoing the “bitter lesson” in AI. This suggests a simple, scalable RL algorithm is key.
More visual insights#
More on figures

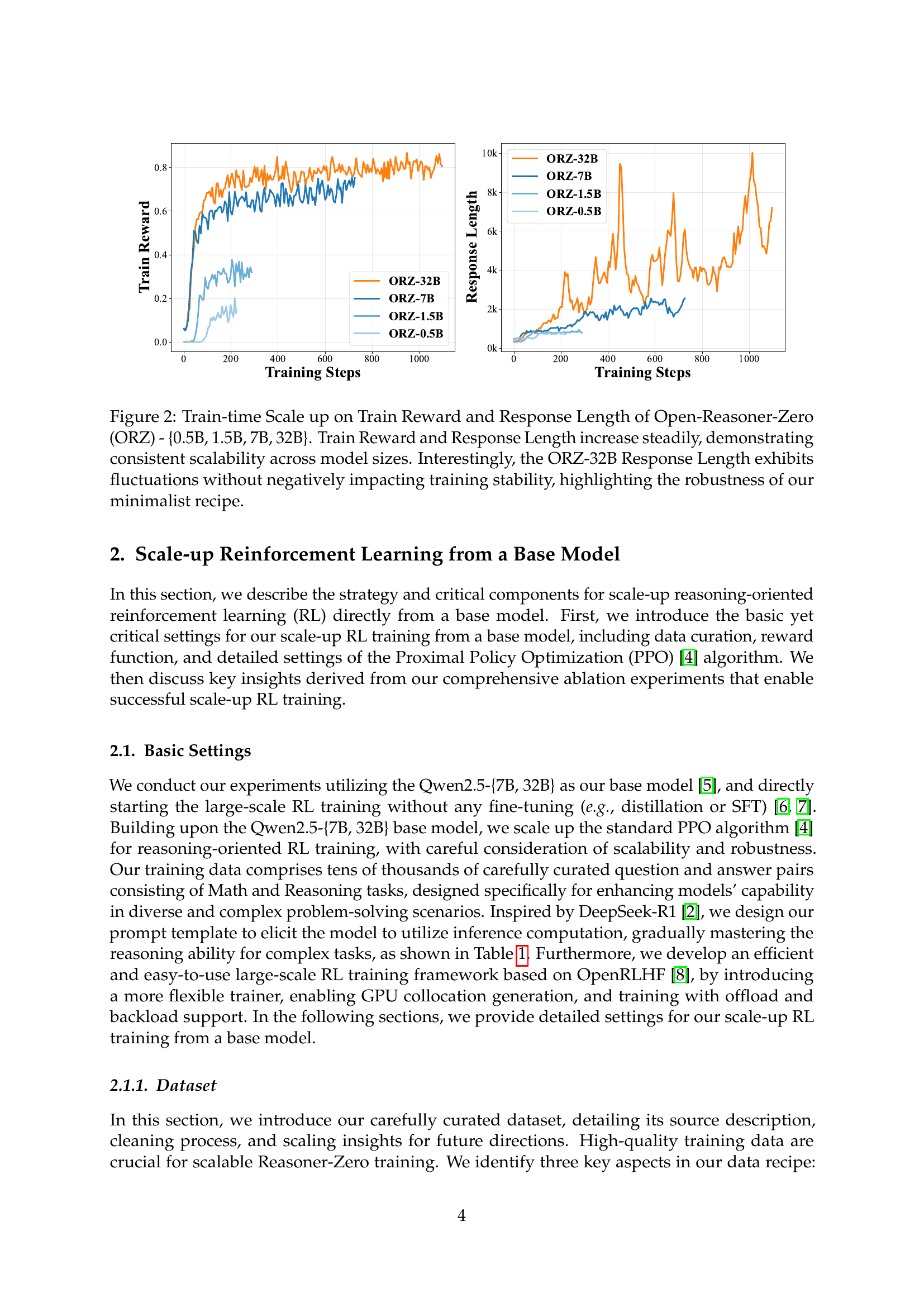
🔼 Figure 2 presents the results of scaling up the training of the Open-Reasoner-Zero model across different sizes (0.5B, 1.5B, 7B, and 32B parameters). The graphs show both the training reward and the response length over the course of training. Both metrics exhibit a steady increase across all model sizes, demonstrating that the model’s performance and response length scale consistently with increased training compute and model size. A notable observation is that even with fluctuations in response length for the largest 32B parameter model, the training remains stable, indicating the robustness of the minimalist training approach (vanilla PPO with GAE and a simple rule-based reward) employed.
read the caption
Figure 2: Train-time Scale up on Train Reward and Response Length of Open-Reasoner-Zero (ORZ) - {0.5B, 1.5B, 7B, 32B}. Train Reward and Response Length increase steadily, demonstrating consistent scalability across model sizes. Interestingly, the ORZ-32B Response Length exhibits fluctuations without negatively impacting training stability, highlighting the robustness of our minimalist recipe.
🔼 This figure shows a Python code snippet that uses the Math-Verify library to check if the generated answer from the language model is mathematically correct. The code takes two inputs: the ground truth and the model’s output, both in a parsed format. It then uses the
verifyfunction from the Math-Verify library to compare the two and returns a boolean value indicating whether the model’s answer is correct.read the caption
Figure 3: The code snippet for verifying the mathematical correctness of generated answers using the Math-Verify library.

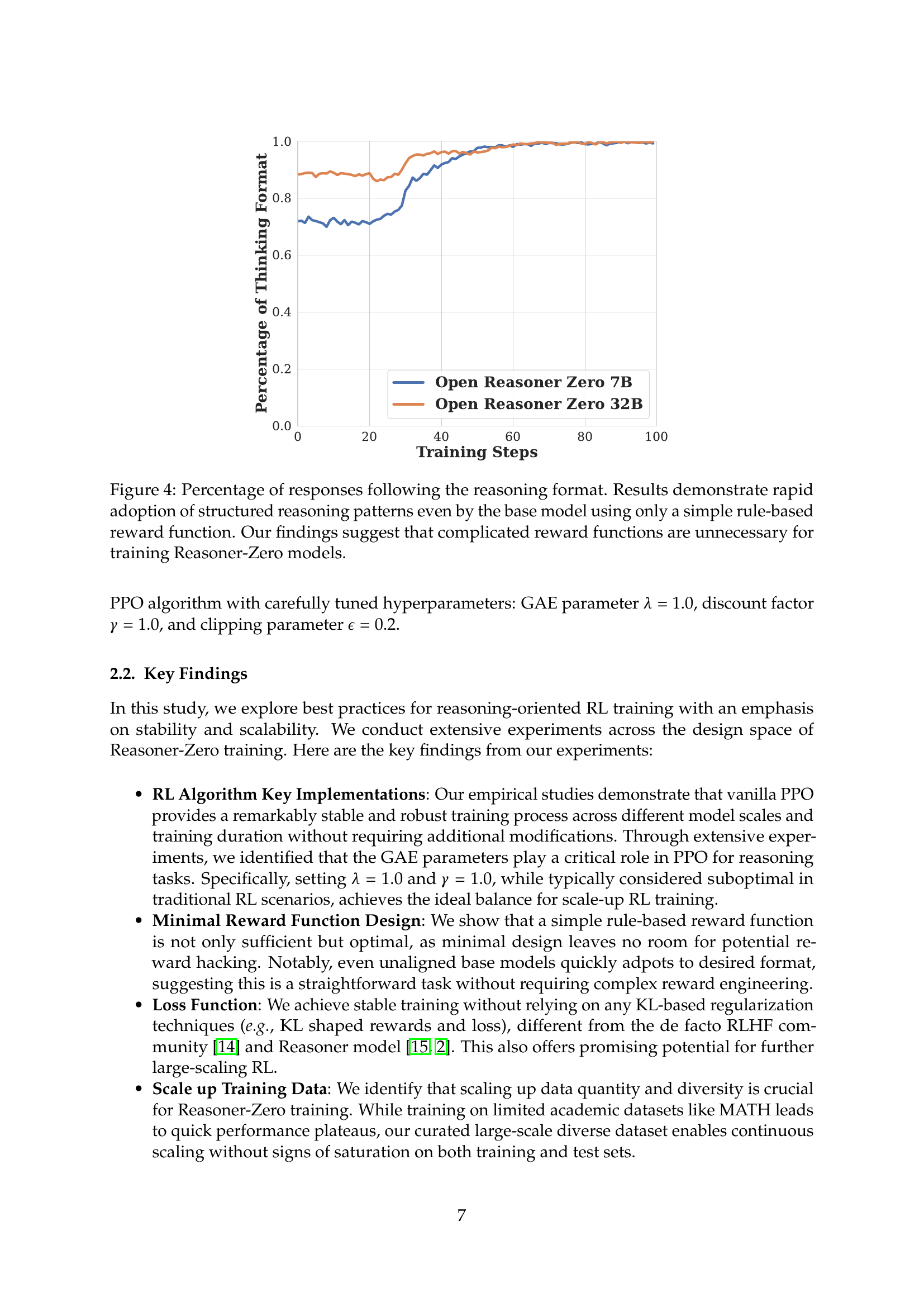
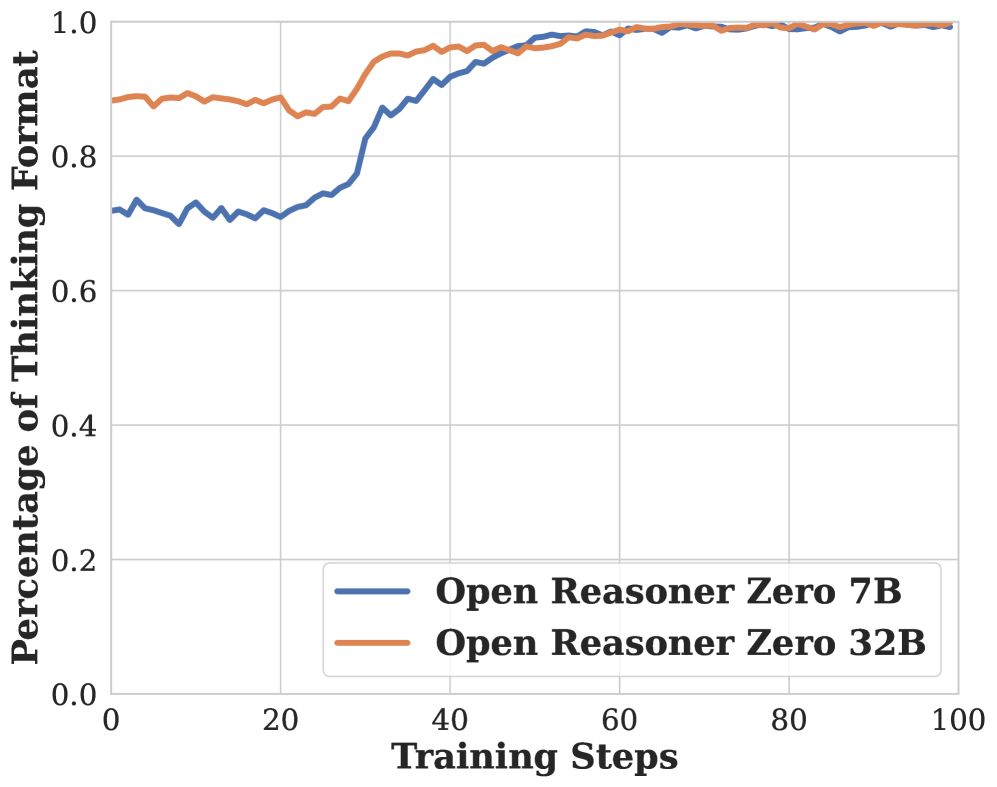
🔼 This figure shows the percentage of responses that followed the expected reasoning format during training. The results indicate that even a simple, rule-based reward function, without complex design, quickly trained the base language model to adopt a structured reasoning format. This finding suggests that complicated reward functions aren’t necessary for effective Reasoner-Zero model training, simplifying the training process and improving scalability.
read the caption
Figure 4: Percentage of responses following the reasoning format. Results demonstrate rapid adoption of structured reasoning patterns even by the base model using only a simple rule-based reward function. Our findings suggest that complicated reward functions are unnecessary for training Reasoner-Zero models.

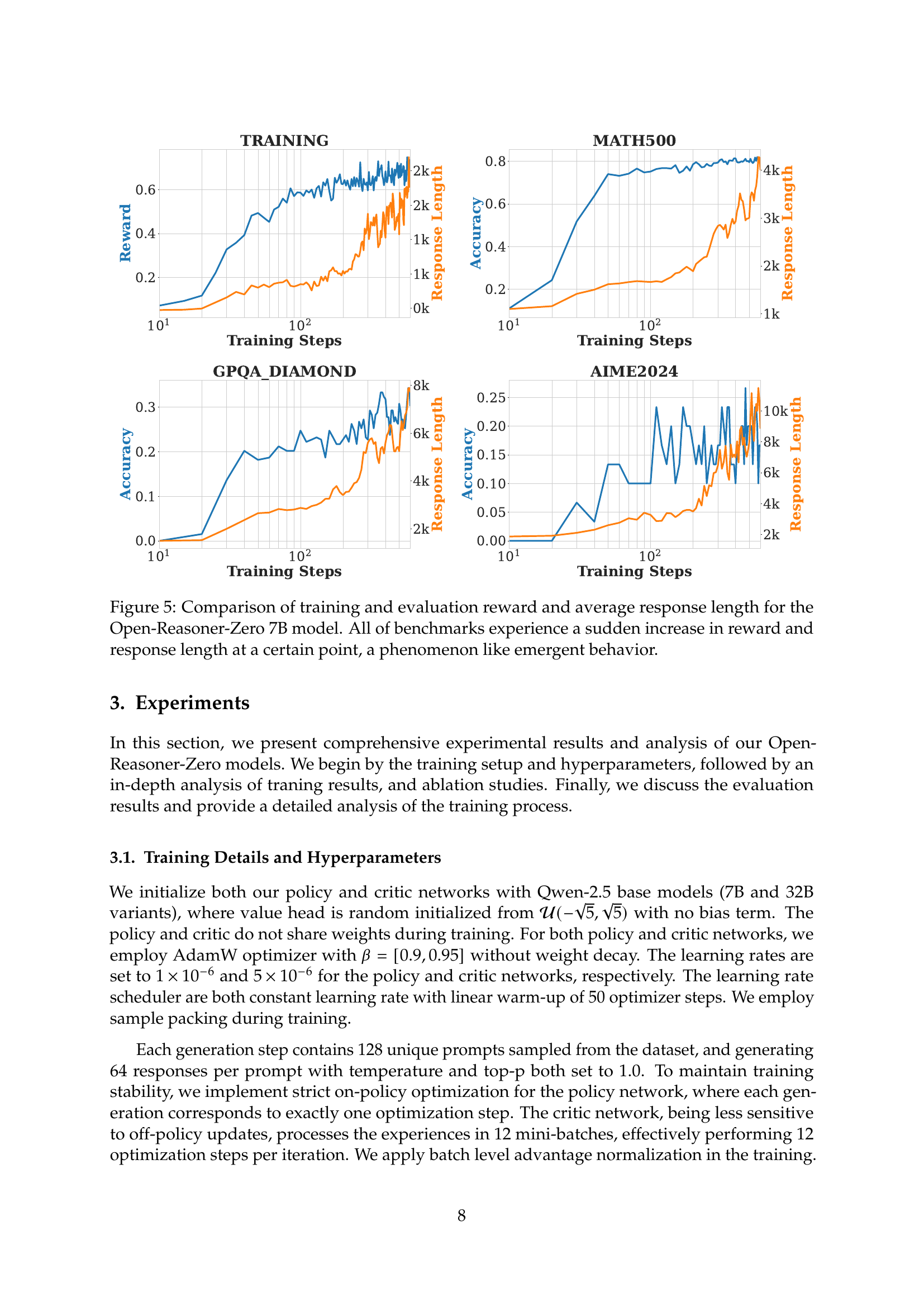
🔼 Figure 5 presents a detailed analysis of the training and evaluation results for the Open-Reasoner-Zero 7B model. It showcases four subplots, each corresponding to a specific benchmark (Training, MATH500, GPQA Diamond, and AIME2024). Each subplot displays two key metrics: reward and average response length plotted against the number of training steps. Notably, across all four benchmarks, the reward and response length exhibit a sharp increase at a certain point during training. This phenomenon suggests an emergent behavior where the model suddenly shows significantly improved performance and reasoning capabilities.
read the caption
Figure 5: Comparison of training and evaluation reward and average response length for the Open-Reasoner-Zero 7B model. All of benchmarks experience a sudden increase in reward and response length at a certain point, a phenomenon like emergent behavior.

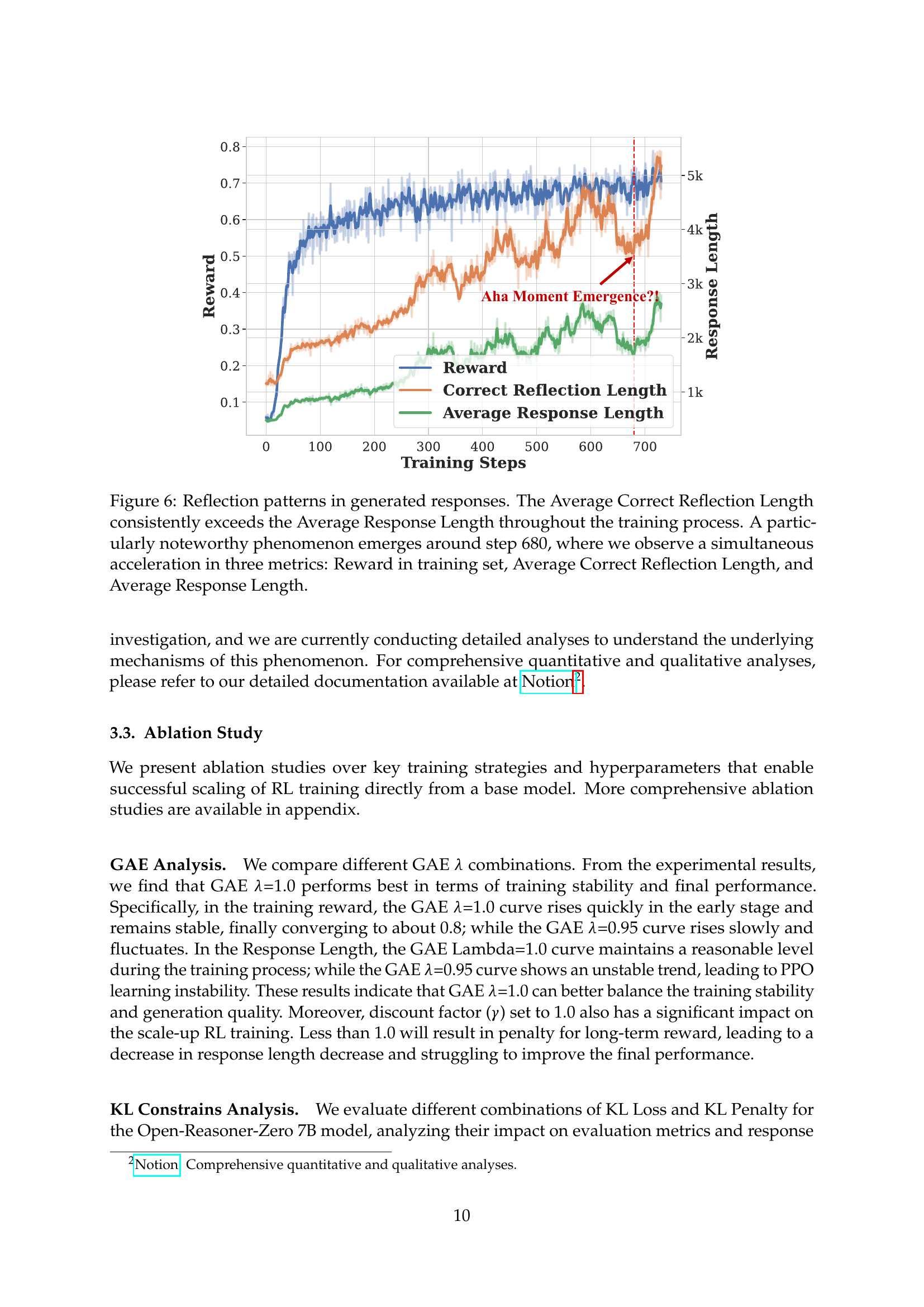
🔼 Figure 6 analyzes the relationship between reflection patterns in model-generated responses and key training metrics. The average length of correct responses containing reflection patterns consistently surpasses the average length of all generated responses, suggesting that more thoughtful responses lead to higher accuracy. A significant event occurs around training step 680, marked by a simultaneous and rapid increase in three metrics: the average training reward, the average length of correct responses with reflection patterns, and the average length of all generated responses. This sudden improvement suggests a qualitative shift in model reasoning ability, possibly indicating an emergent behavior.
read the caption
Figure 6: Reflection patterns in generated responses. The Average Correct Reflection Length consistently exceeds the Average Response Length throughout the training process. A particularly noteworthy phenomenon emerges around step 680, where we observe a simultaneous acceleration in three metrics: Reward in training set, Average Correct Reflection Length, and Average Response Length.

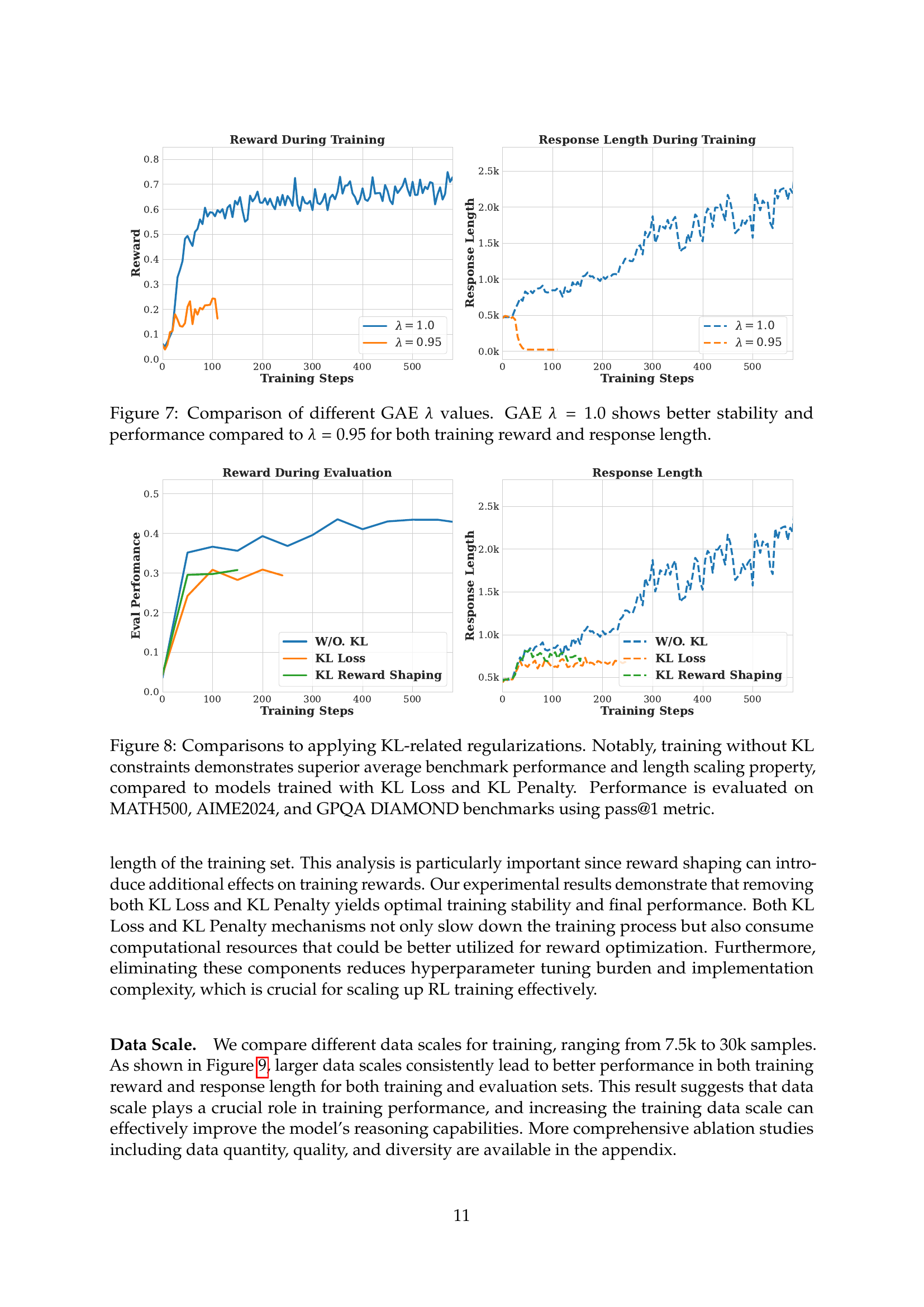
🔼 Figure 7 presents a comparison of the training reward and response length for two different values of the GAE (Generalized Advantage Estimation) lambda (λ) hyperparameter within the Proximal Policy Optimization (PPO) algorithm. The graph shows the training progress over a series of steps, plotting both reward and response length. The results show that using a GAE λ of 1.0 leads to more stable training with better performance (both reward and response length) compared to using a λ of 0.95. The improved stability is evident in the smoother curve of the λ=1.0 line. The superior performance translates to achieving higher rewards and longer response lengths across training.
read the caption
Figure 7: Comparison of different GAE λ𝜆\lambdaitalic_λ values. GAE λ=1.0𝜆1.0\lambda=1.0italic_λ = 1.0 shows better stability and performance compared to λ=0.95𝜆0.95\lambda=0.95italic_λ = 0.95 for both training reward and response length.

🔼 Figure 8 presents an ablation study comparing the performance of models trained with and without KL (Kullback-Leibler) regularization techniques. The x-axis represents the training steps, while the y-axis displays two key metrics: the average benchmark performance (pass@1 metric) across MATH500, AIME2024, and GPQA Diamond datasets, and the average response length. The results reveal that models trained without KL regularization (no KL loss or KL penalty) achieve superior performance on the benchmarks and exhibit better scaling properties with respect to the response length compared to models using KL-based regularization methods. This finding underscores the effectiveness and stability of a minimalist training approach that does not incorporate KL regularization.
read the caption
Figure 8: Comparisons to applying KL-related regularizations. Notably, training without KL constraints demonstrates superior average benchmark performance and length scaling property, compared to models trained with KL Loss and KL Penalty. Performance is evaluated on MATH500, AIME2024, and GPQA DIAMOND benchmarks using pass@1 metric.

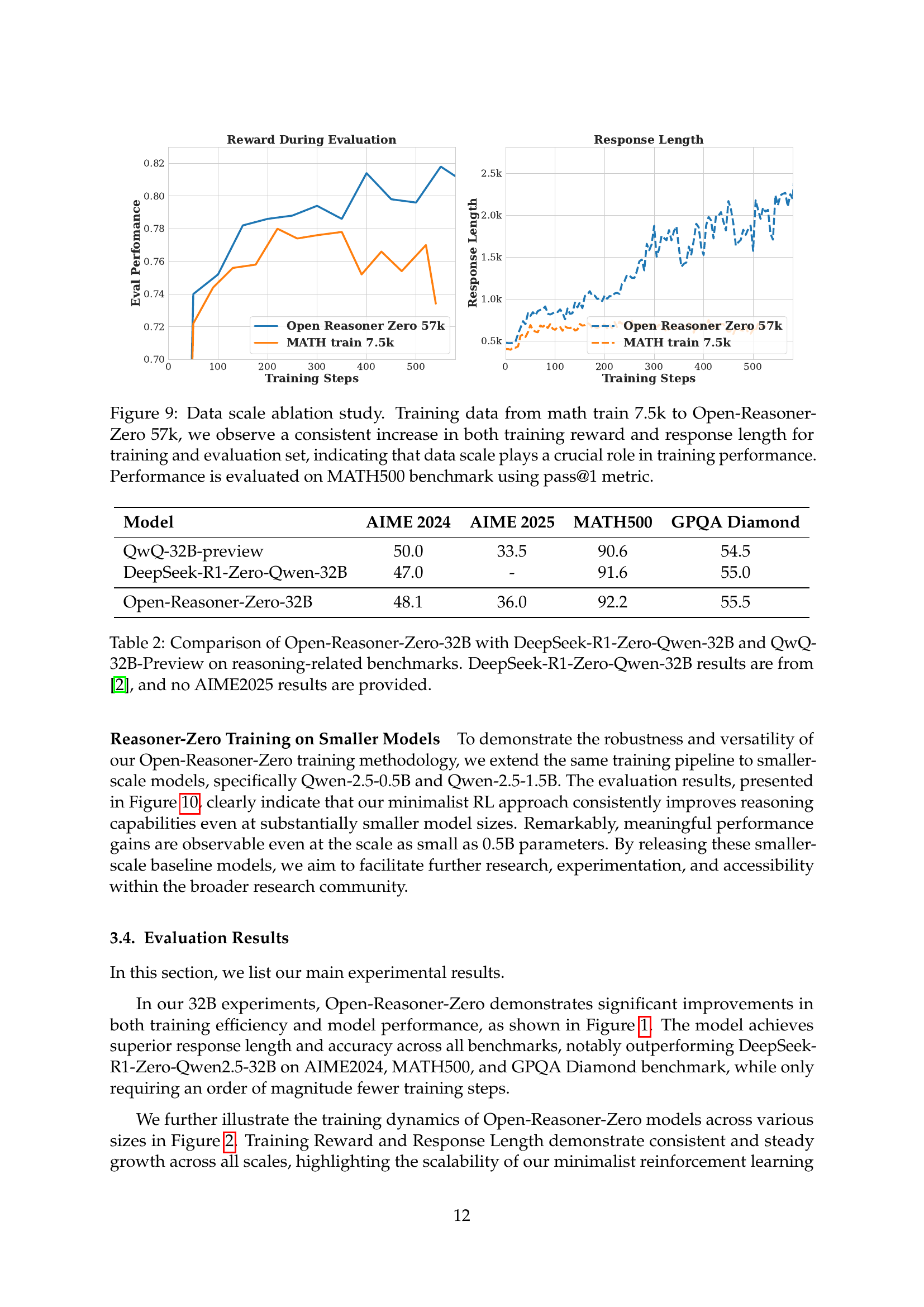
🔼 This figure presents an ablation study on the impact of training data size on the performance of the Open-Reasoner-Zero model. It shows that increasing the amount of training data, from a smaller set of 7.5k samples to a much larger set of 57k samples from the MATH500 benchmark, leads to a consistent improvement in both the training reward and the average response length. This result is observed for both the training dataset and the evaluation dataset, demonstrating the importance of data scale for achieving better performance in large-scale reinforcement learning. The evaluation metric used is pass@1, specifically on the MATH500 benchmark.
read the caption
Figure 9: Data scale ablation study. Training data from math train 7.5k to Open-Reasoner-Zero 57k, we observe a consistent increase in both training reward and response length for training and evaluation set, indicating that data scale plays a crucial role in training performance. Performance is evaluated on MATH500 benchmark using pass@1 metric.

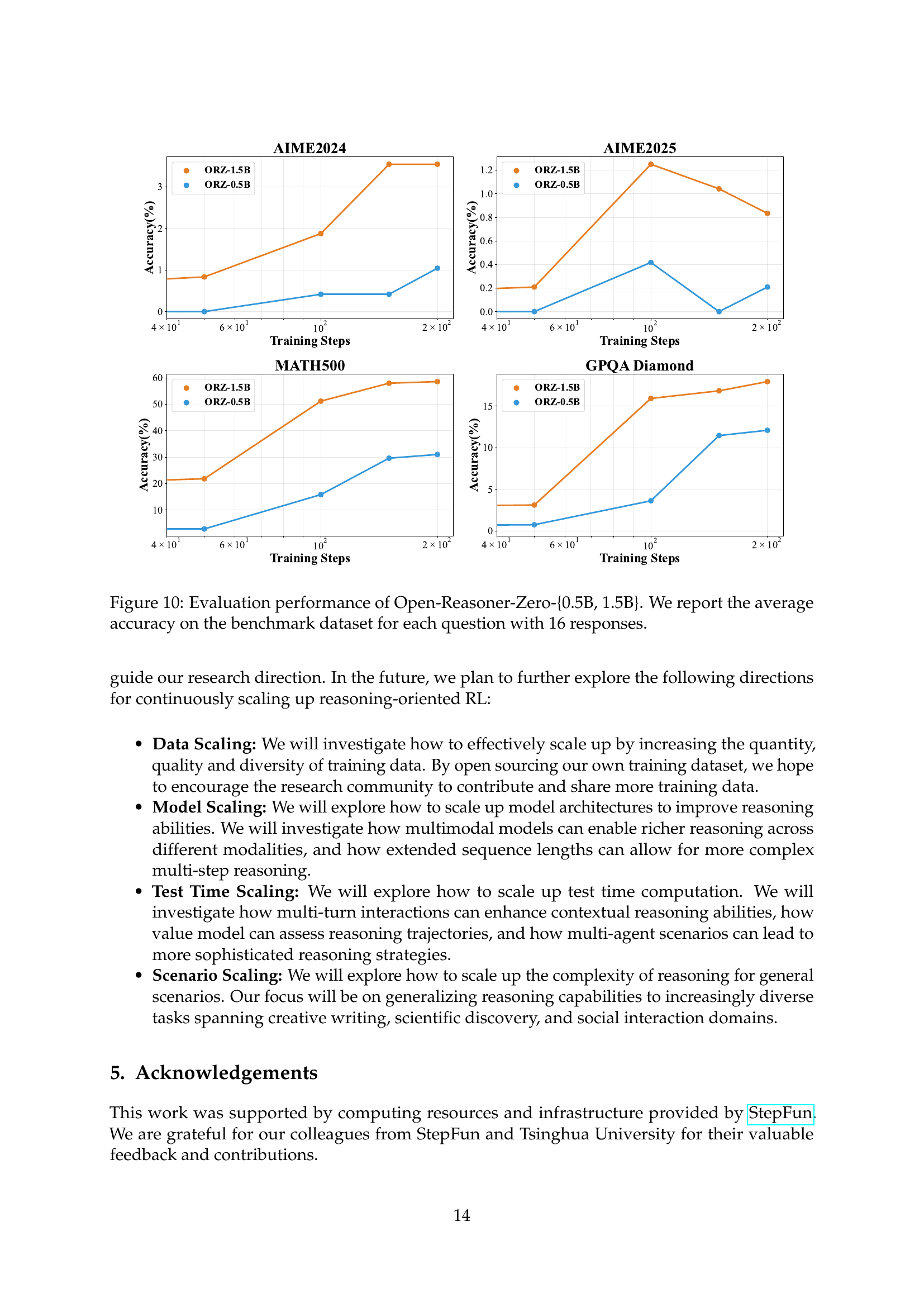
🔼 Figure 10 presents the evaluation results for the Open-Reasoner-Zero models with 0.5B and 1.5B parameters. It shows the average accuracy achieved on four benchmark datasets (AIME2024, AIME2025, MATH500, and GPQA Diamond) across different training steps. The graph visually demonstrates the performance improvement of both models on these reasoning tasks as training progresses. Each data point represents the average accuracy calculated from 16 responses to each question.
read the caption
Figure 10: Evaluation performance of Open-Reasoner-Zero-{0.5B, 1.5B}. We report the average accuracy on the benchmark dataset for each question with 16 responses.

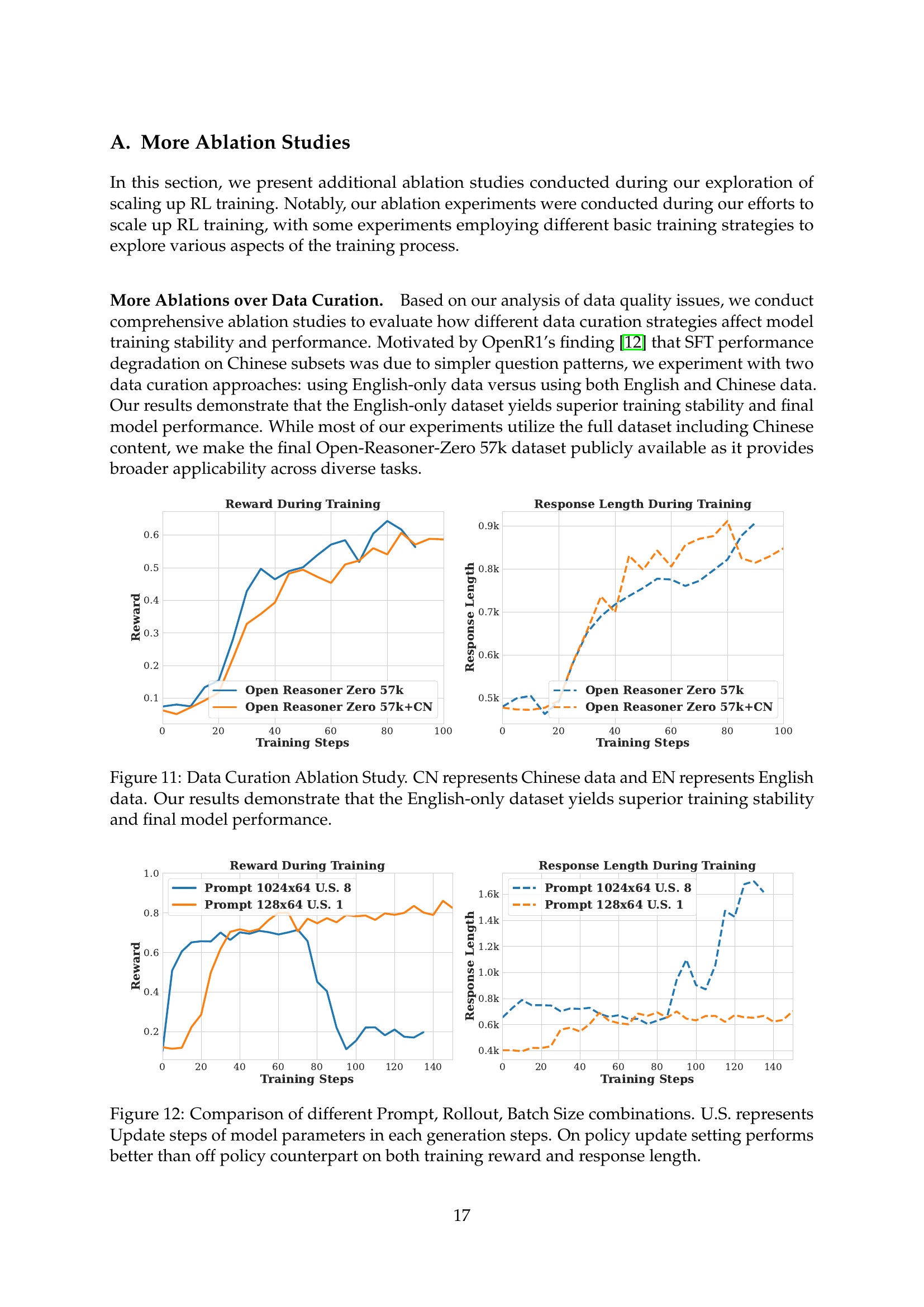
🔼 This ablation study investigates the impact of data curation on the training stability and final model performance of the Open-Reasoner-Zero model. The study compares two different data configurations: one using only English data (EN) and another including both English and Chinese data (CN). The results show that training with the English-only dataset leads to superior stability and ultimately better model performance compared to the dataset containing both languages. This suggests that the inclusion of Chinese data might introduce complexities or noise that hinder the training process, thus reducing the overall effectiveness of the model.
read the caption
Figure 11: Data Curation Ablation Study. CN represents Chinese data and EN represents English data. Our results demonstrate that the English-only dataset yields superior training stability and final model performance.

🔼 Figure 12 investigates the impact of different hyperparameters on the performance of reinforcement learning for large language models. It compares training results using various combinations of prompt numbers, rollout lengths (number of responses generated per prompt), and batch sizes during training. A key variable is ‘U.S.’, which represents the number of times model parameters are updated per generation step. The figure shows that an on-policy update strategy (where parameters are updated after each generation) outperforms an off-policy strategy (where updates are less frequent) in terms of both training reward and response length.
read the caption
Figure 12: Comparison of different Prompt, Rollout, Batch Size combinations. U.S. represents Update steps of model parameters in each generation steps. On policy update setting performs better than off policy counterpart on both training reward and response length.
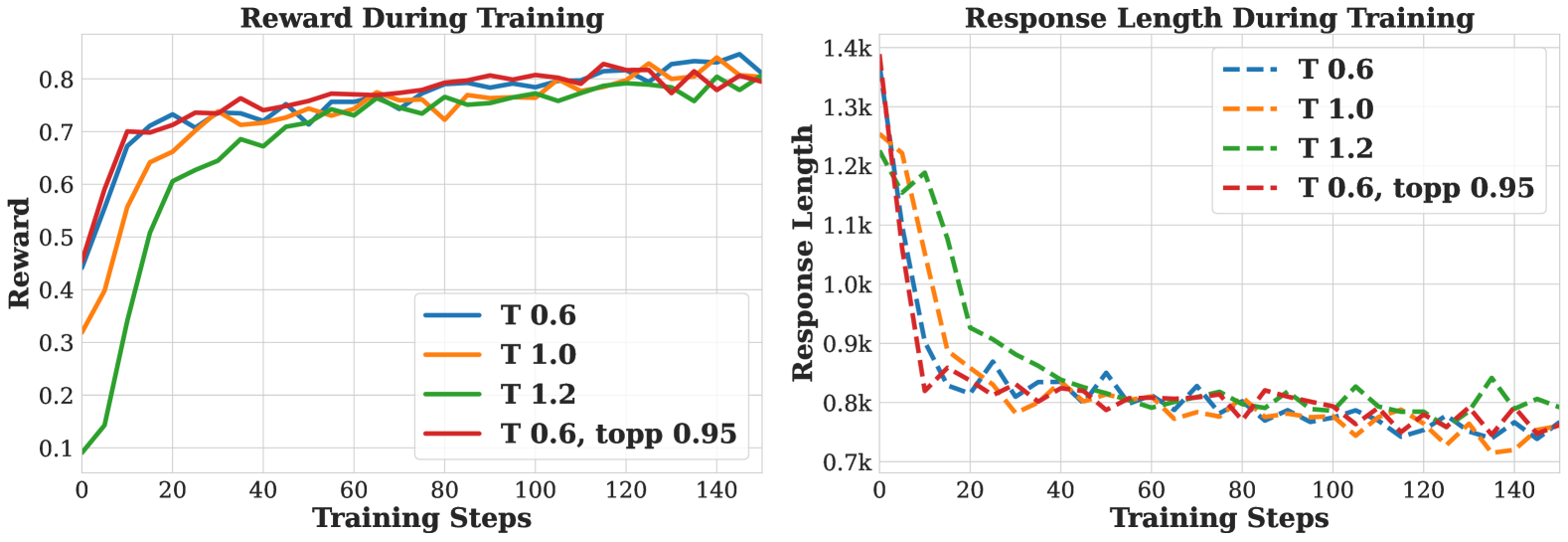
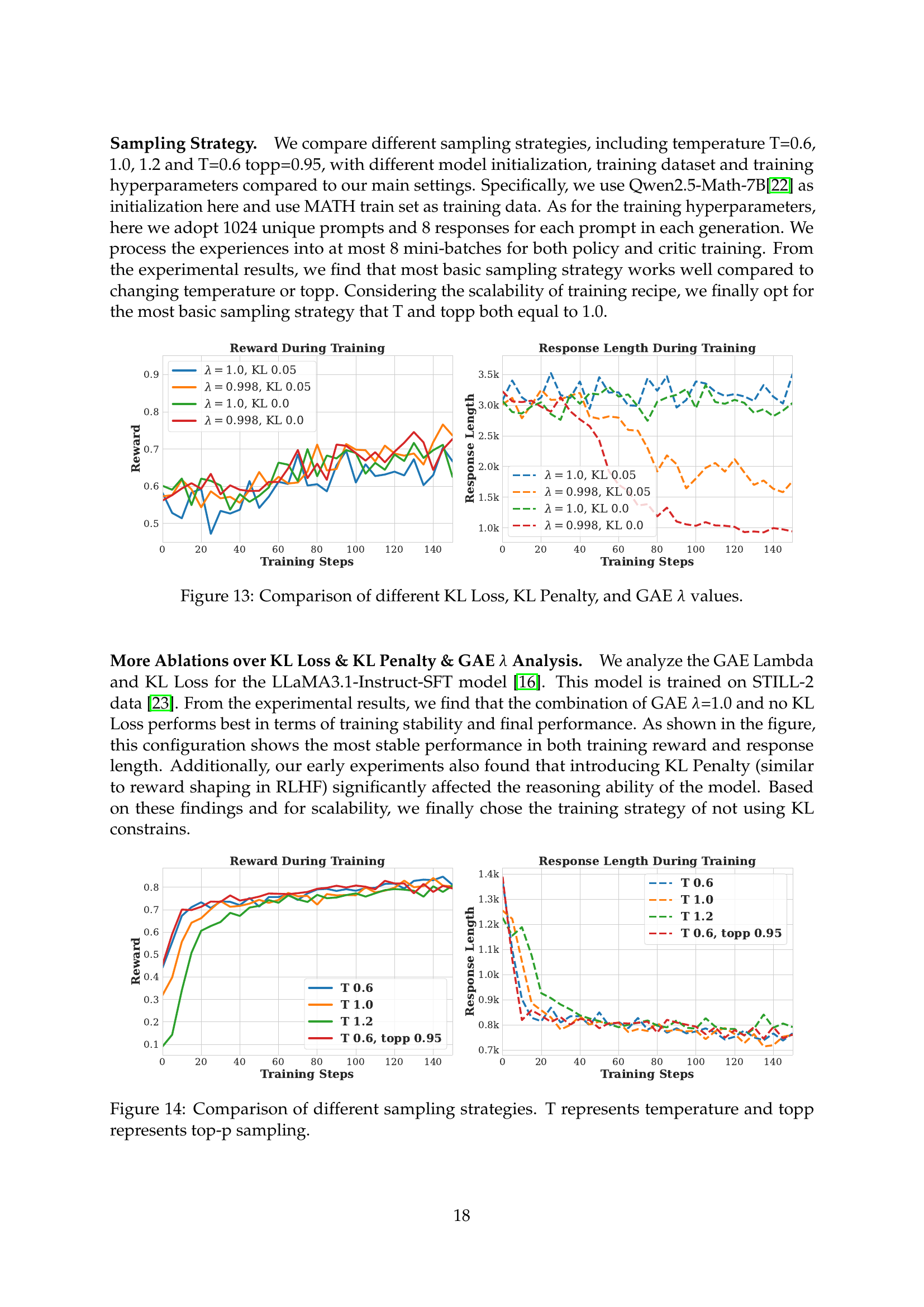
🔼 This figure presents an ablation study comparing the effects of different KL loss, KL penalty, and GAE lambda values on reinforcement learning performance. It likely shows training curves (reward and response length) for various combinations of these hyperparameters, illustrating how each setting affects the stability and final performance of the model. The goal is to determine the optimal combination for stable and high-performing training.
read the caption
Figure 13: Comparison of different KL Loss, KL Penalty, and GAE λ𝜆\lambdaitalic_λ values.
More on tables
| Model | AIME 2024 | AIME 2025 | MATH500 | GPQA Diamond |
|---|---|---|---|---|
| QwQ-32B-preview | 50.0 | 33.5 | 90.6 | 54.5 |
| DeepSeek-R1-Zero-Qwen-32B | 47.0 | - | 91.6 | 55.0 |
| Open-Reasoner-Zero-32B | 48.1 | 36.0 | 92.2 | 55.5 |
🔼 This table compares the performance of three different large language models (LLMs) on several reasoning benchmarks. The models compared are Open-Reasoner-Zero-32B (the model introduced in this paper), DeepSeek-R1-Zero-Qwen-32B (a prior model from another research paper), and QwQ-32B-Preview (another baseline model). The benchmarks used assess the models’ reasoning abilities across various tasks, and the results are presented as accuracy scores. Note that DeepSeek-R1-Zero-Qwen-32B’s results are taken from a separate publication, and that model did not report results for the AIME2025 benchmark.
read the caption
Table 2: Comparison of Open-Reasoner-Zero-32B with DeepSeek-R1-Zero-Qwen-32B and QwQ-32B-Preview on reasoning-related benchmarks. DeepSeek-R1-Zero-Qwen-32B results are from [2], and no AIME2025 results are provided.
| Model | MMLU | MMLU_PRO |
|---|---|---|
| Qwen2.5-32B-Base | 83.3 | 55.1 |
| Qwen2.5-32B-Instruct | 83.2 | 69.2 |
| Open-Reasoner-Zero-32B | 84.9 | 74.4 |
🔼 Table 3 presents the generalization performance of the Open-Reasoner-Zero models on the MMLU and MMLU_PRO benchmarks. It demonstrates that by solely scaling up reinforcement learning (RL) on reasoning-oriented tasks, Open-Reasoner-Zero surpasses the Qwen2.5-Instruct model’s performance without any extra instruction tuning. This highlights the significant improvement in model generalization capabilities achieved through the training pipeline used in Open-Reasoner-Zero.
read the caption
Table 3: Generalization performance of Open-Reasoner-Zero models on MMLU and MMLU_PRO benchmarks. Through solely scaling up RL training on reasoning-oriented tasks, Open-Reasoner-Zero achieves superior performance on both benchmarks, surpassing Qwen2.5-Instruct without any additional instruction tuning. This demonstrates the remarkable effectiveness of our training pipeline in enhancing model generalization capabilities.
| Model | AIME 2024 | AIME 2025 | MATH500 | GPQA Diamond |
|---|---|---|---|---|
| Open-Reasoner-Zero-0.5B | 1.0 | 0.2 | 31.0 | 12.1 |
| Open-Reasoner-Zero-1.5B | 3.5 | 1.0 | 58.0 | 16.8 |
| Open-Reasoner-Zero-7B | 17.9 | 15.6 | 81.4 | 36.6 |
| Open-Reasoner-Zero-32B | 48.1 | 36.0 | 92.2 | 55.5 |
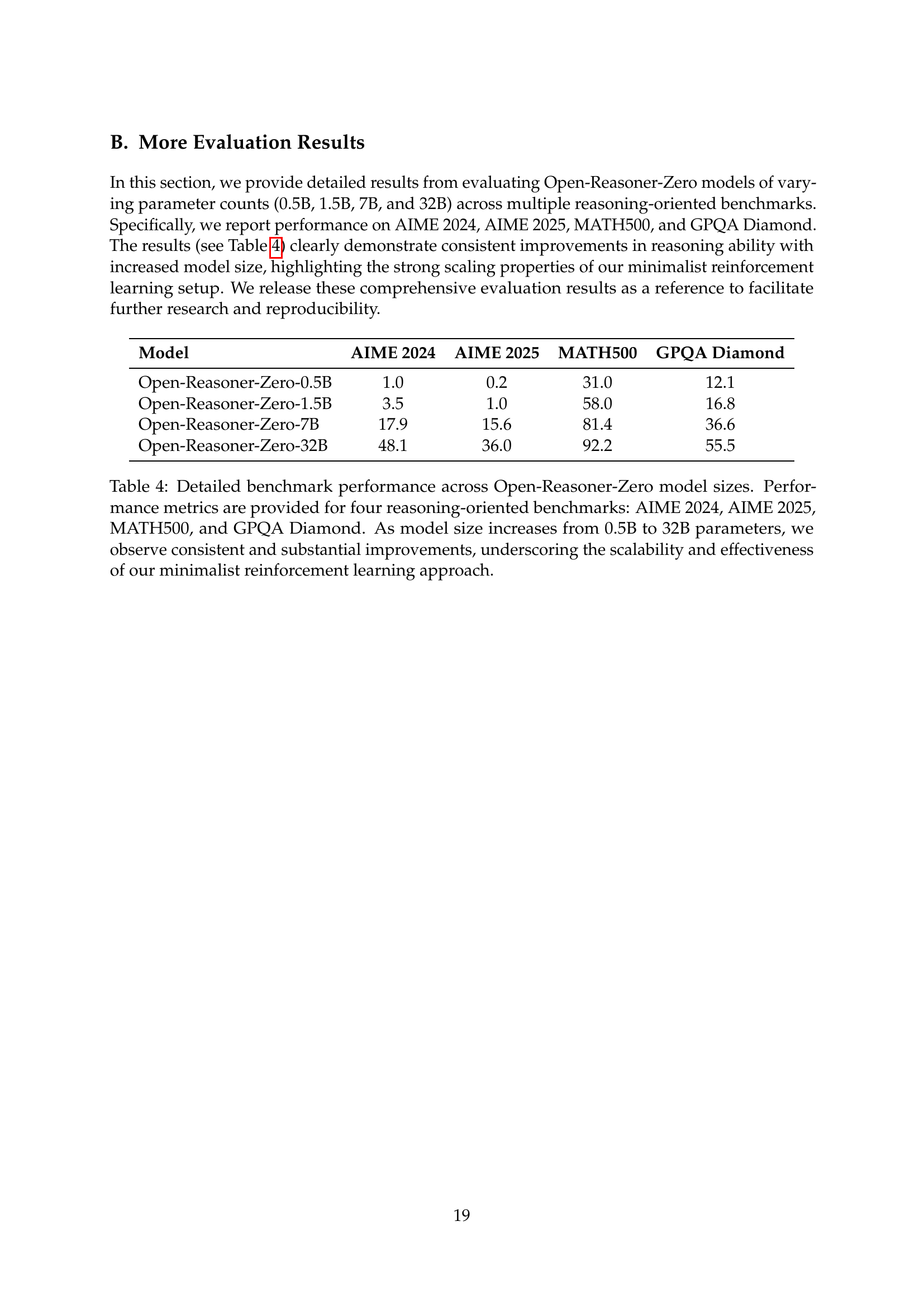
🔼 This table presents a detailed breakdown of the performance achieved by the Open-Reasoner-Zero models across four different reasoning benchmarks (AIME 2024, AIME 2025, MATH500, and GPQA Diamond). It shows the accuracy of models with varying parameter sizes (0.5B, 1.5B, 7B, and 32B). The results demonstrate a clear improvement in performance as the model size scales up, highlighting the effectiveness and scalability of the minimalist reinforcement learning approach used.
read the caption
Table 4: Detailed benchmark performance across Open-Reasoner-Zero model sizes. Performance metrics are provided for four reasoning-oriented benchmarks: AIME 2024, AIME 2025, MATH500, and GPQA Diamond. As model size increases from 0.5B to 32B parameters, we observe consistent and substantial improvements, underscoring the scalability and effectiveness of our minimalist reinforcement learning approach.
Full paper#