TL;DR#
Large language models often struggle with one-shot accuracy in text-to-SQL tasks. Existing methods, like self-consistency, fall short when dealing with structurally diverse yet semantically equivalent queries. This limitation motivates exploring methods that measure equivalence at the execution level rather than relying on structural comparison, substantially narrowing the gap between pass@1 and pass@k accuracy.
To address this, the paper proposes a novel self-consistency approach tailored to SQL generation. By leveraging exact and approximate execution-based similarity metrics, the method assesses semantic equivalence directly from query outputs. This approach enables smaller models to match the performance of larger models at a fraction of the computational cost. The method integrates with existing models, offering a pathway to state-of-the-art SQL generation, improving the accuracy and efficiency of text-to-SQL tasks.
Key Takeaways#
Why does it matter?#
This paper is important for researchers because it introduces a cost-effective method for improving SQL generation accuracy. By leveraging execution results, the approach allows smaller models to achieve performance comparable to larger models at a fraction of the computational cost. This opens new avenues for developing more efficient and scalable SQL generation systems, particularly relevant in resource-constrained environments.
Visual Insights#
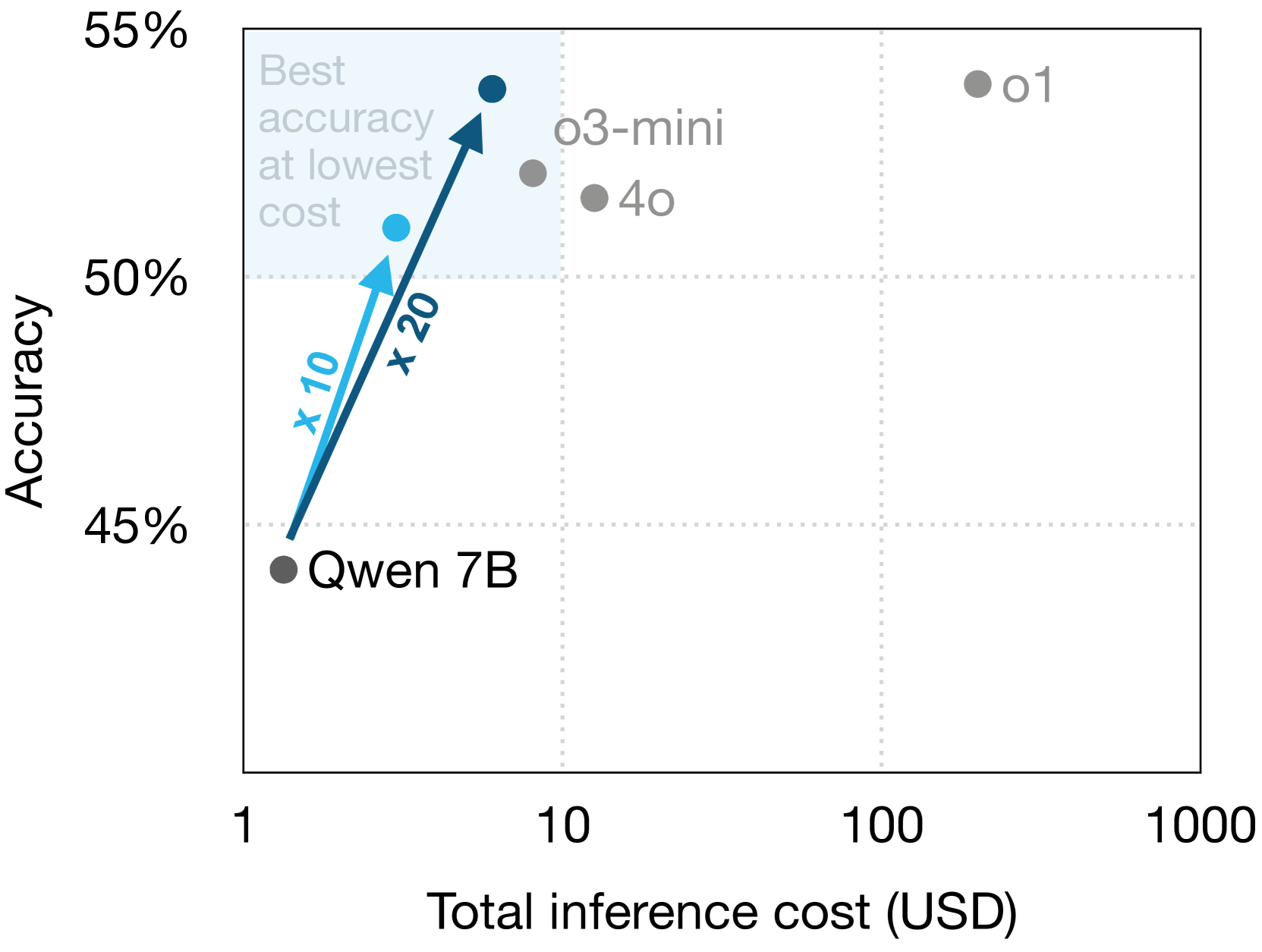
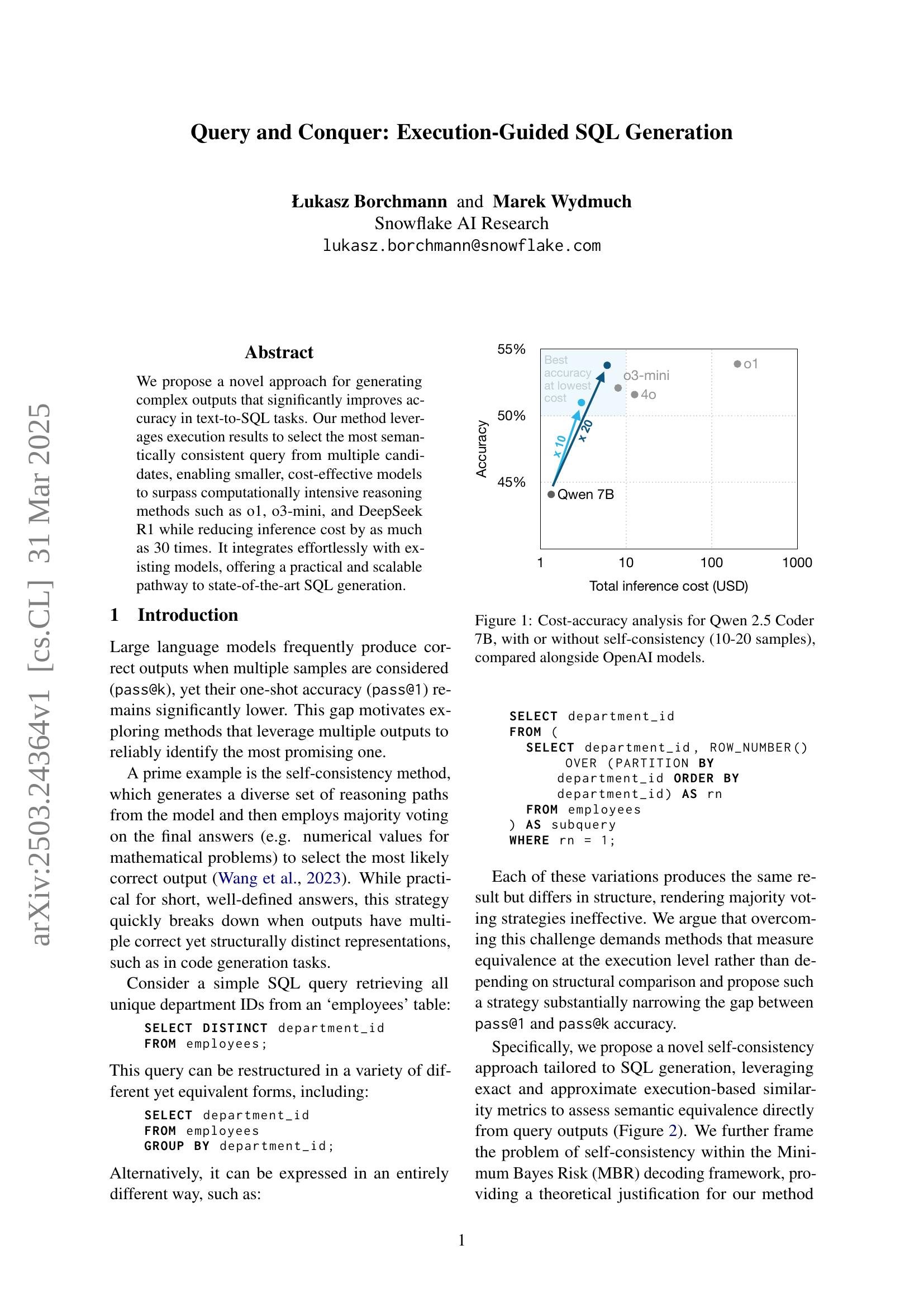
🔼 This figure presents a cost-benefit analysis of using the Qwen 2.5 Coder 7B model for text-to-SQL tasks. It compares the accuracy achieved at various inference costs, contrasting the model’s performance with and without the application of a self-consistency technique. The self-consistency method involves generating multiple query candidates (10-20 samples) and selecting the most semantically consistent one based on their execution results. The figure also includes the performance of several OpenAI models as a benchmark, illustrating the cost-effectiveness of the Qwen model when combined with the self-consistency approach.
read the caption
Figure 1: Cost-accuracy analysis for Qwen 2.5 Coder 7B, with or without self-consistency (10-20 samples), compared alongside OpenAI models.
| X | Y |
|---|---|
| 1 | |
| 2 |
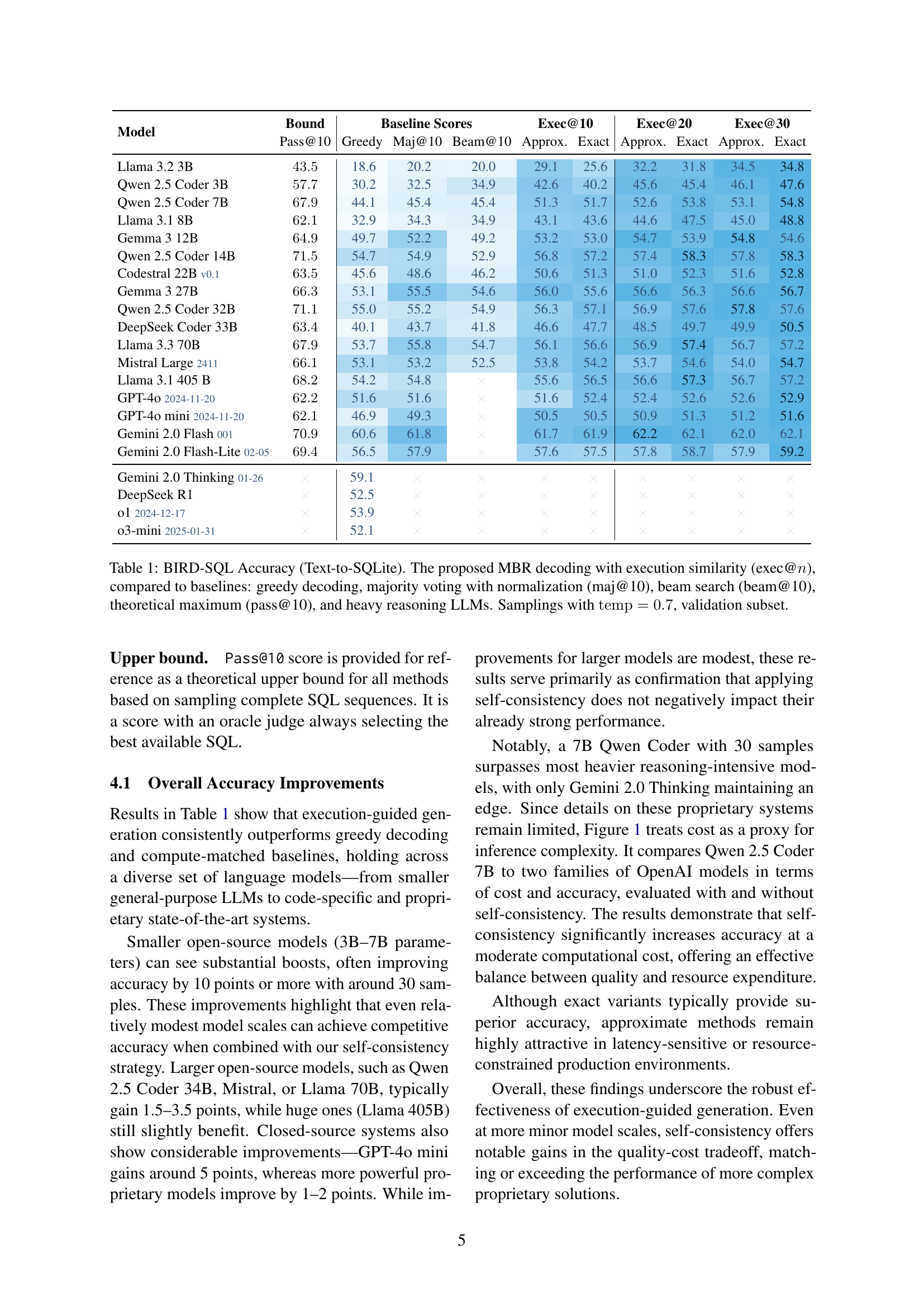
🔼 Table 1 presents a comprehensive comparison of various text-to-SQL models’ performance on the BIRD-SQL dataset. The primary metric is accuracy (Pass@10), representing the percentage of correctly generated SQL queries within the top 10 predictions. The table contrasts the proposed Minimum Bayes Risk (MBR) decoding method, incorporating execution-based similarity, against established baselines: greedy decoding, majority voting with normalization (Maj@10), and beam search (Beam@10). Additionally, it includes results for computationally intensive, state-of-the-art models (‘Heavy Reasoners’) and provides the theoretical upper bound (Pass@10). The models’ performance is assessed at different sampling budgets (Exec@10, Exec@20, Exec@30), reflecting the impact of increased query samples on accuracy. A temperature of 0.7 was used during sampling, and the evaluation was conducted on the validation subset of the BIRD-SQL dataset.
read the caption
Table 1: BIRD-SQL Accuracy (Text-to-SQLite). The proposed MBR decoding with execution similarity (exec@n𝑛nitalic_n), compared to baselines: greedy decoding, majority voting with normalization (maj@10), beam search (beam@10), theoretical maximum (pass@10), and heavy reasoning LLMs. Samplings with temp=0.7temp0.7\mathrm{temp}=0.7roman_temp = 0.7, validation subset.
In-depth insights#
Exec-Guided SQL#
Execution-Guided SQL generation is a novel approach to enhance text-to-SQL accuracy. It leverages execution results to select semantically consistent queries from multiple candidates, surpassing computationally intensive reasoning methods with smaller models. This method uses exact and approximate execution-based similarity metrics to assess query output equivalence. Integrating seamlessly with existing models, it refines complex queries through execution-based self-consistency, narrowing the gap between pass@1 and pass@k accuracy, thus offering a practical, scalable route to state-of-the-art SQL generation and significantly reducing inference costs.
MBR for Text2SQL#
While the paper doesn’t explicitly contain a heading titled ‘MBR for Text2SQL’, its discussion of Minimum Bayes Risk (MBR) decoding is highly relevant to Text2SQL. The core idea is to optimize for expected utility rather than directly maximizing probability. In Text2SQL, this means selecting a SQL query that’s most ‘average’ or consistent with other plausible queries, given some metric of similarity. Execution similarity is introduced to address this, with a method of utilizing semantic correctness based on behavior. This differs from textual similarity, which fails to see equivalence where queries vary structurally. This MBR approach aims to improve the ‘pass@k’ accuracy by focusing on real semantic equivalence through an actual behavior of generated SQL statements. By moving away from superficial query structure to semantic validation at the execution level, a much more substantial narrowing of the gap between pass@1 and pass@k accuracy is possible and attainable.
Partial Queries#
It seems like the authors are exploring the concept of partially executable queries, specifically in the context of SQL generation. This likely involves breaking down complex queries into smaller, self-contained units that can be executed independently. Prefix executability, as mentioned with PipeSQL, would be a key property here. This approach potentially allows for incremental validation and refinement during query generation. Instead of generating a full, complex query at once and only then checking its correctness, the system could execute parts of it along the way, ensuring that each step produces valid and meaningful results. This is likely intended to improve the overall accuracy and robustness of the generated queries, especially when dealing with complex data structures or ambiguous natural language input. By leveraging the results of these partial executions to guide the subsequent steps in the generation process. This aligns with the overall theme of the paper, which emphasizes execution-guided methods for SQL generation.
Error Analysis#
Based on the paper’s exploration of SQL generation, a thorough error analysis is crucial. The study likely categorizes errors into dialectical mismatches, where generated queries, though logically sound, fail due to database-specific syntax. Schema linking errors are also prominent, stemming from incorrect associations between natural language and database elements, leading to hallucinated or misidentified columns/tables. Data type errors, aggregation errors, logical form errors further complicate accurate SQL generation. A detailed error analysis would reveal the specific weaknesses of the models, indicating areas for improvement in training data or model architecture. Analyzing the frequency of each error provides valuable insight for targeted improvements, and comparing error distributions across different model sizes sheds light on scalability and generalization challenges.
Scaling Limits#
While the paper doesn’t explicitly address ‘Scaling Limits,’ we can infer potential bottlenecks in execution-guided SQL generation. Computational cost increases with model size and the number of samples. Data transfer between the model and execution environment presents latency challenges. Memory constraints limit batch sizes for execution, requiring clever optimization. Furthermore, execution-guided methods will eventually be bottlenecked by the quality of the underlying LLM, and reach a point where the diversity of the outputs is not enough. More work should be focused on increasing the range of SQL variants generated.
More visual insights#
More on figures

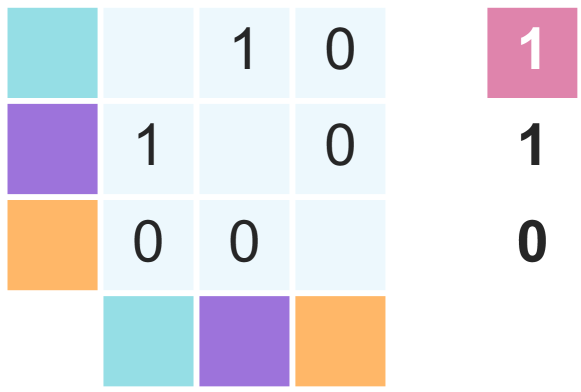
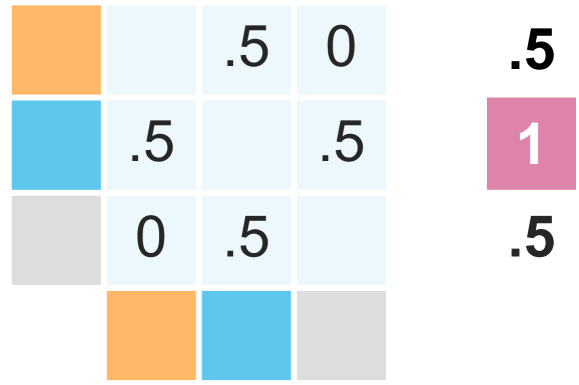
🔼 This figure illustrates the execution-guided SQL generation process. It begins by sampling several different SQL queries (1). Each query is then executed, and the resulting dataframes are compared pairwise to assess their similarity (2). Finally, the query with the highest average similarity across all comparisons is selected as the best-performing query (3). This method leverages the execution results to measure semantic equivalence directly, rather than relying on superficial structural similarities, improving the accuracy of SQL generation, especially for queries with multiple correct but structurally different representations.
read the caption
Figure 2: Execution-Guided SQL Generation.
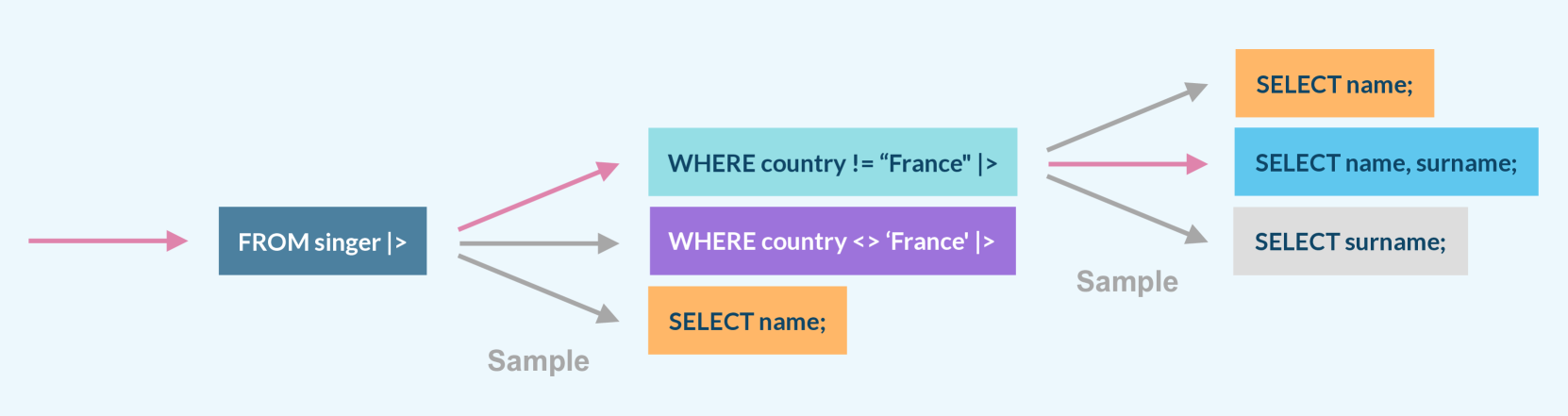
🔼 The figure illustrates the advantage of using PipeSQL for execution-guided self-consistency. PipeSQL allows for evaluating the validity of query prefixes, which enables applying self-consistency at intermediate steps during query generation. Instead of generating and evaluating complete SQL queries, the method samples multiple query prefixes (pipes) and selects the most consistent one based on execution results. This approach is then iteratively continued by sampling variants of the next pipe, enhancing accuracy and efficiency.
read the caption
Figure 3: PipeSQL dialect has a property that each query prefix (up to the pipe sequence |>) is also a valid query, making it possible to apply execution-based self-consistency in the middle of the generation process. Instead of sampling n𝑛nitalic_n complete SQL sequences, we sample n𝑛nitalic_n pipes and stop the generation process. Then, we pick the most consistent pipe and continue the generation sampling n𝑛nitalic_n variants of the next pipe.
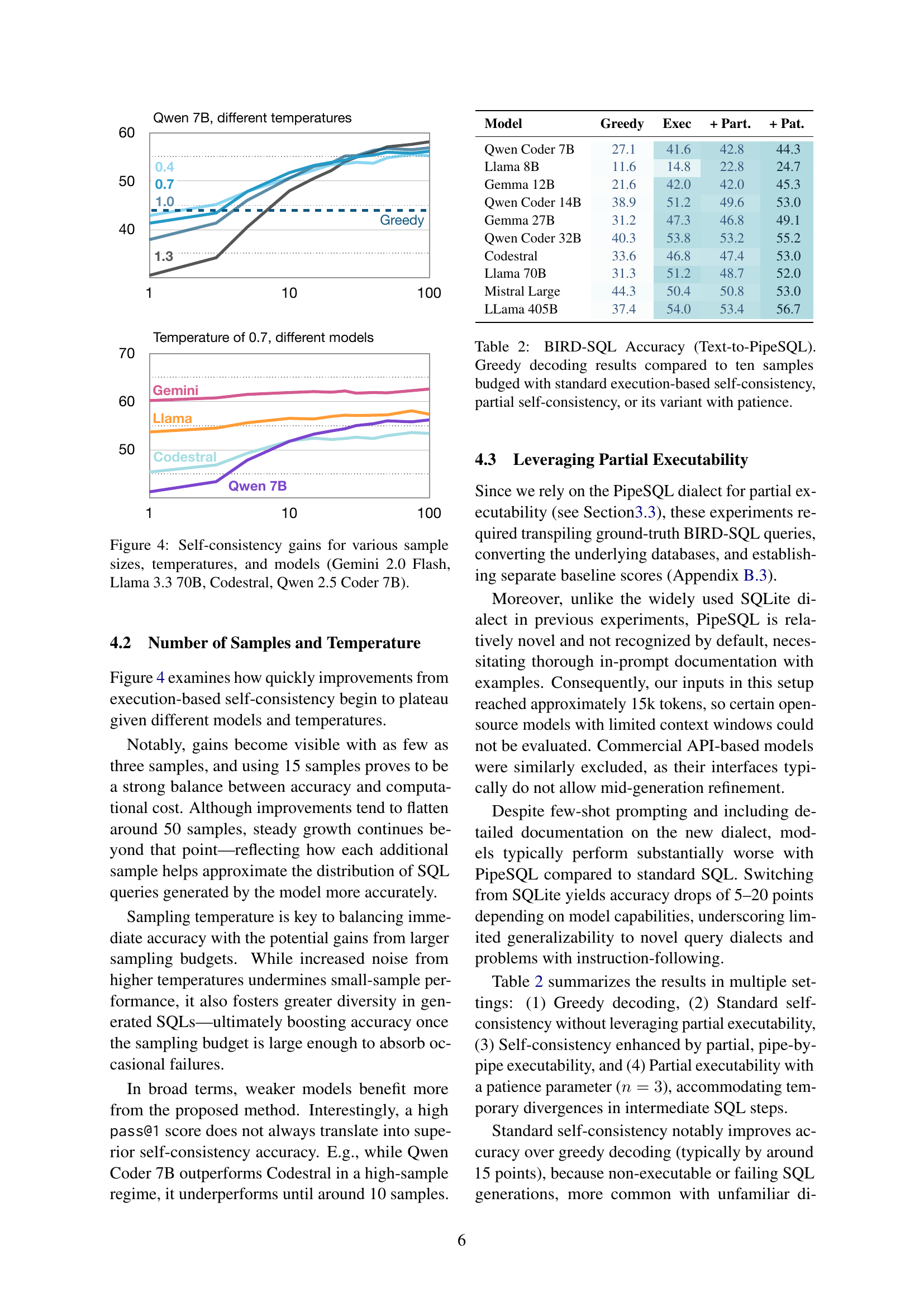
🔼 This figure displays the impact of different numbers of samples and temperatures on the effectiveness of self-consistency in improving the accuracy of various large language models (LLMs) in SQL generation tasks. The models compared include Gemini 2.0 Flash, Llama 3.3 70B, Codestral, and Qwen 2.5 Coder 7B. The x-axis represents the number of samples used in the self-consistency method, while the y-axis shows the resulting accuracy. Different lines correspond to different temperatures. The figure illustrates how self-consistency gains generally increase with the number of samples, and how this relationship varies depending on the model and the temperature setting.
read the caption
Figure 4: Self-consistency gains for various sample sizes, temperatures, and models (Gemini 2.0 Flash, Llama 3.3 70B, Codestral, Qwen 2.5 Coder 7B).
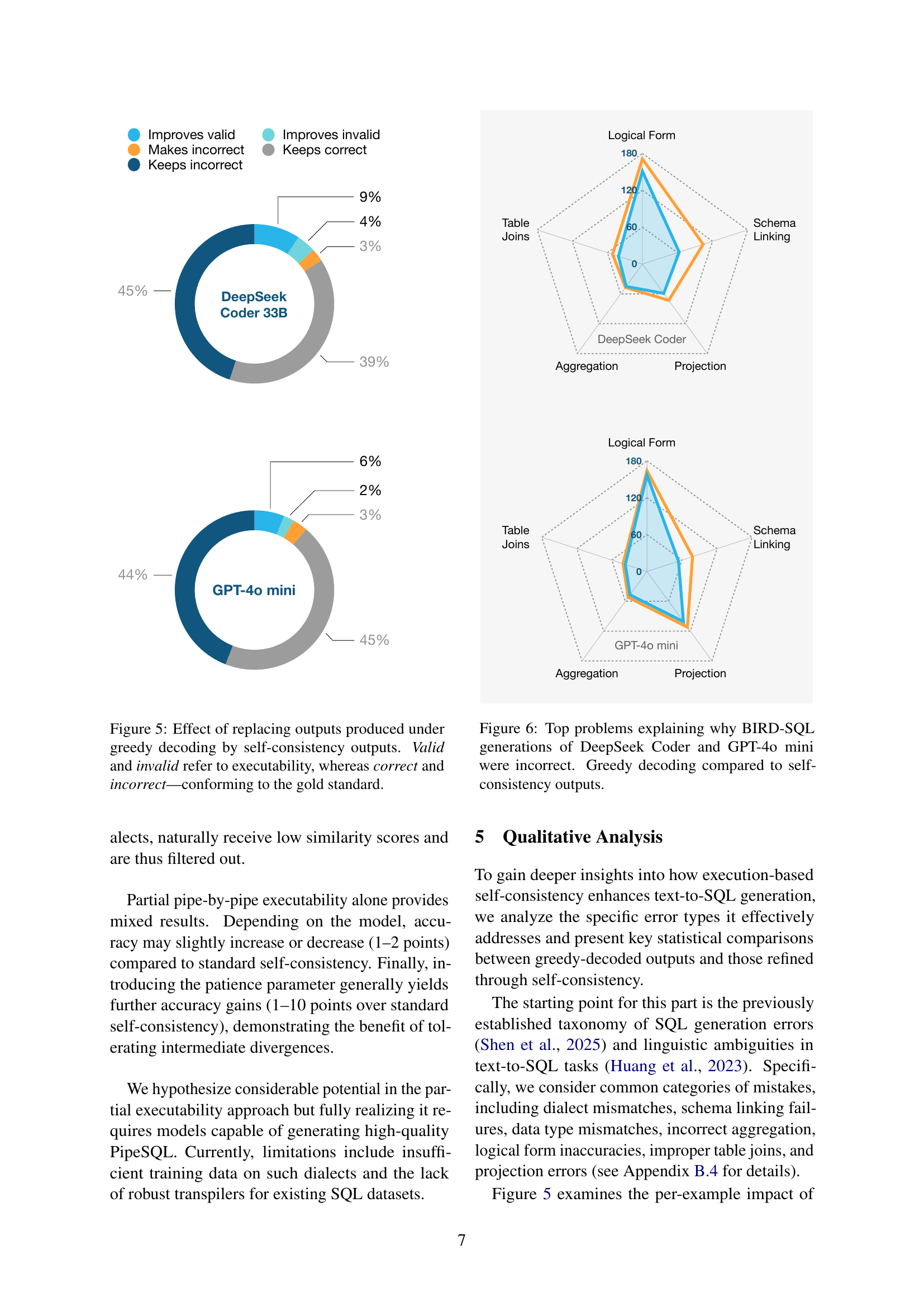
🔼 This figure displays the impact of using self-consistency instead of greedy decoding. It shows how many outputs are improved, remain incorrect, or become incorrect when using self-consistency. The terms ‘valid’ and ‘invalid’ refer to whether the generated SQL code is executable, while ‘correct’ and ‘incorrect’ indicate whether the code produces the correct result according to the gold standard (the ideal correct answer). The figure compares the results for two models: DeepSeek Coder 33B and GPT-40 mini, highlighting the effect of self-consistency on improving the correctness of the generated SQL code.
read the caption
Figure 5: Effect of replacing outputs produced under greedy decoding by self-consistency outputs. Valid and invalid refer to executability, whereas correct and incorrect—conforming to the gold standard.

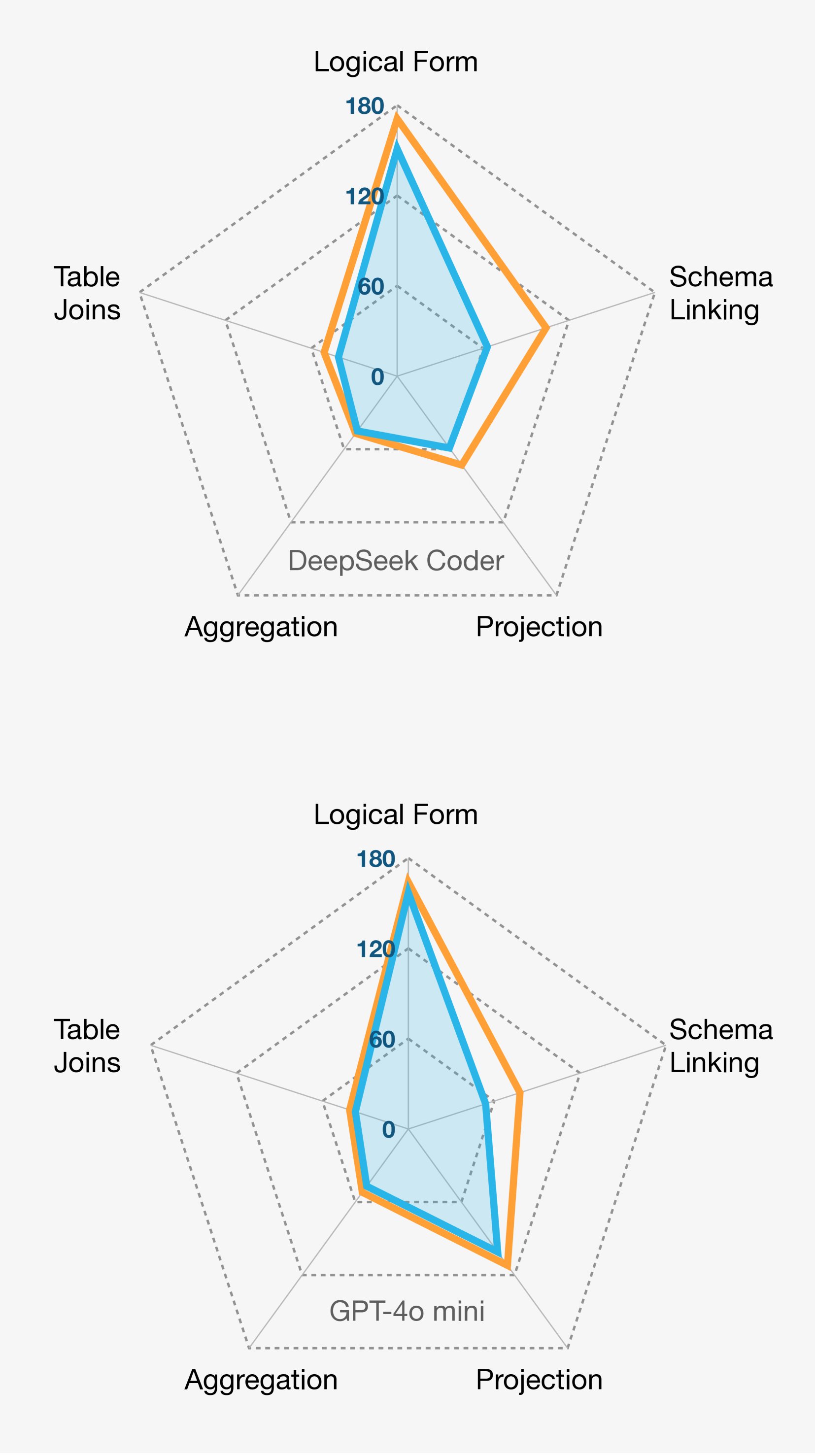
🔼 Figure 6 is a bar chart visualizing the top reasons why DeepSeek Coder and GPT-4o mini models generated incorrect SQL queries on the BIRD-SQL dataset. It contrasts the error types produced by the standard greedy decoding approach and the improved self-consistency method. The chart directly compares the frequency of errors such as schema linking issues, logical form problems, and projection mistakes, offering a quantitative insight into how self-consistency addresses typical SQL generation inaccuracies.
read the caption
Figure 6: Top problems explaining why BIRD-SQL generations of DeepSeek Coder and GPT-4o mini were incorrect. Greedy decoding compared to self-consistency outputs.
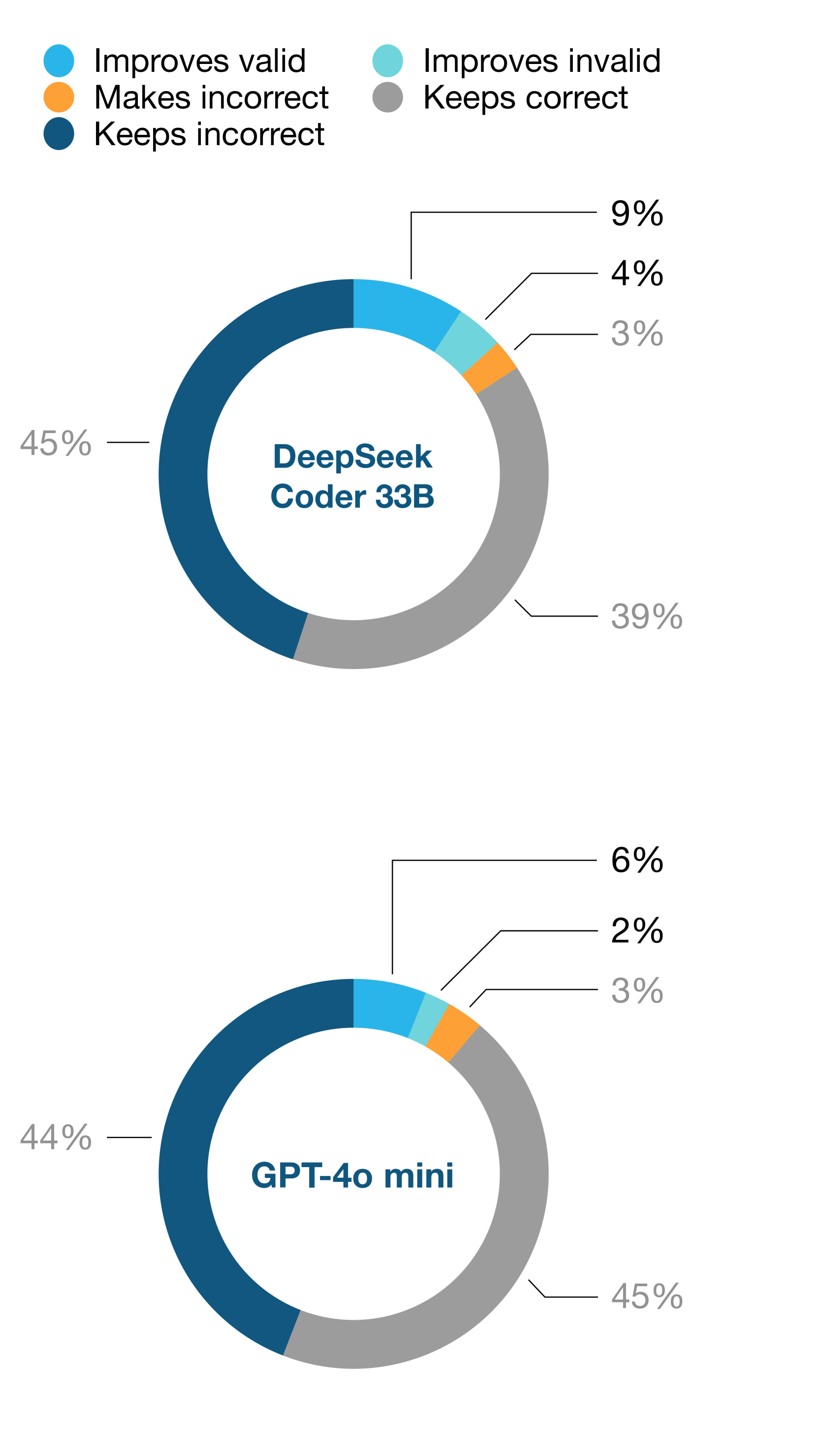
🔼 This figure displays the impact of replacing outputs generated using greedy decoding with those obtained via self-consistency. It shows the percentage of outputs that fall into four categories: valid outputs improved by self-consistency, invalid outputs corrected by self-consistency, invalid outputs that remained incorrect, and valid outputs that became incorrect. The figure presents this breakdown separately for two models: DeepSeek Coder 33B and GPT-40 mini, highlighting the effectiveness of the self-consistency method in improving the quality of the generated outputs.
read the caption
(a)
🔼 This figure displays the results of applying execution-based self-consistency to various models. Specifically, it shows the impact on accuracy (y-axis) at different inference cost levels (x-axis), comparing different models’ performance with and without this technique. The goal is to demonstrate the cost-effectiveness of using execution-based self-consistency to improve SQL query generation accuracy. Note that the specific models and their performance metrics are shown in the figure itself.
read the caption
(b)
More on tables
| X |
|---|
| 1 |
| 2 |
| 3 |
🔼 This table presents the results of experiments evaluating different approaches to improving SQL generation accuracy on the BIRD-SQL dataset using the PipeSQL dialect. It compares the performance of greedy decoding (a baseline) against three self-consistency methods: standard execution-based self-consistency, partial self-consistency, and a variant of partial self-consistency that incorporates a ‘patience’ parameter. The table shows the accuracy achieved by each method, highlighting the impact of different self-consistency strategies on the overall performance of SQL generation in the context of partial query executability.
read the caption
Table 2: BIRD-SQL Accuracy (Text-to-PipeSQL). Greedy decoding results compared to ten samples budged with standard execution-based self-consistency, partial self-consistency, or its variant with patience.
| Model | Bound | Baseline Scores | Exec@10 | Exec@20 | Exec@30 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Pass@10 | Greedy | Maj@10 | Beam@10 | Approx. | Exact | Approx. | Exact | Approx. | Exact | |
| Llama 3.2 3B | 18.6 | 20.2 | 20.0 | 29.1 | 25.6 | 32.2 | 31.8 | 34.5 | 34.8 | |
| Qwen 2.5 Coder 3B | 30.2 | 32.5 | 34.9 | 42.6 | 40.2 | 45.6 | 45.4 | 46.1 | 47.6 | |
| Qwen 2.5 Coder 7B | 44.1 | 45.4 | 45.4 | 51.3 | 51.7 | 52.6 | 53.8 | 53.1 | 54.8 | |
| Llama 3.1 8B | 32.9 | 34.3 | 34.9 | 43.1 | 43.6 | 44.6 | 47.5 | 45.0 | 48.8 | |
| Gemma 3 12B | 49.7 | 52.2 | 49.2 | 53.2 | 53.0 | 54.7 | 53.9 | 54.8 | 54.6 | |
| Qwen 2.5 Coder 14B | 54.7 | 54.9 | 52.9 | 56.8 | 57.2 | 57.4 | 58.3 | 57.8 | 58.3 | |
| Codestral 22B v0.1 | 45.6 | 48.6 | 46.2 | 50.6 | 51.3 | 51.0 | 52.3 | 51.6 | 52.8 | |
| Gemma 3 27B | 53.1 | 55.5 | 54.6 | 56.0 | 55.6 | 56.6 | 56.3 | 56.6 | 56.7 | |
| Qwen 2.5 Coder 32B | 55.0 | 55.2 | 54.9 | 56.3 | 57.1 | 56.9 | 57.6 | 57.8 | 57.6 | |
| DeepSeek Coder 33B | 40.1 | 43.7 | 41.8 | 46.6 | 47.7 | 48.5 | 49.7 | 49.9 | 50.5 | |
| Llama 3.3 70B | 53.7 | 55.8 | 54.7 | 56.1 | 56.6 | 56.9 | 57.4 | 56.7 | 57.2 | |
| Mistral Large 2411 | 53.1 | 53.2 | 52.5 | 53.8 | 54.2 | 53.7 | 54.6 | 54.0 | 54.7 | |
| Llama 3.1 405 B | 54.2 | 54.8 | 55.6 | 56.5 | 56.6 | 57.3 | 56.7 | 57.2 | ||
| GPT-4o 2024-11-20 | 51.6 | 51.6 | 51.6 | 52.4 | 52.4 | 52.6 | 52.6 | 52.9 | ||
| GPT-4o mini 2024-11-20 | 46.9 | 49.3 | 50.5 | 50.5 | 50.9 | 51.3 | 51.2 | 51.6 | ||
| Gemini 2.0 Flash 001 | 60.6 | 61.8 | 61.7 | 61.9 | 62.2 | 62.1 | 62.0 | 62.1 | ||
| Gemini 2.0 Flash-Lite 02-05 | 56.5 | 57.9 | 57.6 | 57.5 | 57.8 | 58.7 | 57.9 | 59.2 | ||
| Gemini 2.0 Thinking 01-26 | 59.1 | |||||||||
| DeepSeek R1 | 52.5 | |||||||||
| o1 2024-12-17 | 53.9 | |||||||||
| o3-mini 2025-01-31 | 52.1 | |||||||||
🔼 This table presents the accuracy of Python code generation using two different methods: greedy decoding and execution-based self-consistency. It compares the performance of several large language models on two benchmark datasets: HumanEval+ and MBPP+. The results show the accuracy achieved by each method on each dataset, highlighting the improvement in accuracy provided by using execution-based self-consistency.
read the caption
Table 3: Python generation accuracy. Greedy decoding compared to execution-based self-consistency.
| Model | Greedy | Exec | + Part. | + Pat. |
|---|---|---|---|---|
| Qwen Coder 7B | 27.1 | 41.6 | 42.8 | 44.3 |
| Llama 8B | 11.6 | 14.8 | 22.8 | 24.7 |
| Gemma 12B | 21.6 | 42.0 | 42.0 | 45.3 |
| Qwen Coder 14B | 38.9 | 51.2 | 49.6 | 53.0 |
| Gemma 27B | 31.2 | 47.3 | 46.8 | 49.1 |
| Qwen Coder 32B | 40.3 | 53.8 | 53.2 | 55.2 |
| Codestral | 33.6 | 46.8 | 47.4 | 53.0 |
| Llama 70B | 31.3 | 51.2 | 48.7 | 52.0 |
| Mistral Large | 44.3 | 50.4 | 50.8 | 53.0 |
| LLama 405B | 37.4 | 54.0 | 53.4 | 56.7 |
🔼 This table presents the results of an experiment evaluating the impact of combining predictions from multiple large language models (LLMs) on the accuracy of SQL query generation. It shows how using a diverse set of LLM predictions, rather than relying solely on a single model, improves the overall accuracy of generated SQL queries. The table compares accuracy metrics (Pass@10, @20, @30) achieved using different combinations of LLMs and demonstrates the extent to which leveraging cross-model consistency enhances performance.
read the caption
Table 4: Impact of cross-model consistency on BIRD-SQL Accuracy (Text-to-SQLite).
Full paper#