TL;DR#
Operating in complex, open-world environments requires embodied agents to possess reasoning and imagination. Previous methods either incorporate one of these abilities or combine specialized models, which limits learning efficiency and generalization. To address this, this paper introduces RIG, an end-to-end generalist policy that synergizes reasoning and imagination.
To enable end-to-end training, the authors developed a data pipeline that integrates imagination and reasoning into trajectories collected from existing agents. RIG learns the correlation between reasoning, action, and environment dynamics, generating actions, simulating outcomes, and reviewing them before execution. This approach achieved significantly improved sample efficiency and generalization compared to previous works.
Key Takeaways#
Why does it matter?#
This paper introduces a novel end-to-end generalist policy, RIG, synergizing reasoning and imagination, offering a scalable approach to enhance embodied agent performance and reduce reliance on extensive training data. RIG opens new research directions for integrating cognitive abilities in AI.
Visual Insights#

🔼 Figure 1 illustrates the architectural differences between conventional embodied agents and the proposed RIG (Reasoning and Imagination Generalist) agent. Panel (a) shows a Vision-Language Model (VLM)-based agent that uses visual input to generate textual actions, lacking an explicit world model or future prediction capability. Panel (b) depicts an agent that uses a world model (VLM) to predict future states, but is separated from the reasoning/action generation process. Panel (c) presents a hybrid system that combines a VLM for reasoning and a Visual Generative Model (VGM) for imagining outcomes, but still as separate modules. In contrast, panel (d) showcases the RIG architecture. This integrates reasoning, action selection, and image generation within a unified Transformer network, synergistically combining reasoning and imagination for more robust and efficient decision-making. RIG directly outputs a low-level action.
read the caption
Figure 1: Comparison between conventional agents and RIG. RIG produces reasoning, actions, and imagination within a single Transformer.
| ID | Capabilities | Number of Samples | Accuracy (%) | |||||||||||
| Action | Gen. | Reason | Lookahead | wood | grass | dirt | avg. | Dig | Explore | Tower | avg. | |||
| Manual (ID 0–4) | ||||||||||||||
| 0 | ✓ | 7.9 | 6.2 | 8.9 | 7.7 | +0.0 | 9.1 | 11.7 | 4.4 | 8.4 | +0.0 | |||
| 1 | ✓ | ✓ | 11.0 | 16.5 | 12.1 | 13.2 | +5.5 | 12.2 | 36.8 | 41.8 | 30.3 | +21.9 | ||
| 2 | ✓ | ✓ | 17.3 | 24.5 | 22.5 | 21.4 | +13.8 | 34.2 | 31.8 | 37.8 | 34.6 | +26.2 | ||
| 3 | ✓ | ✓ | ✓ | 22.2 | 45.9 | 38.7 | 35.6 | +27.9 | 29.2 | 65.2 | 37.9 | 44.1 | +35.7 | |
| 4 | ✓ | ✓ | ✓ | ✓ | 28.3 | 137.5 | 74.8 | 80.2 | +72.5 | 65.8 | 84.2 | 88.7 | 79.6 | +71.2 |
| Tool (ID 0–4) | ||||||||||||||
| 0 | ✓ | 24.6 | 33.1 | 42.4 | 33.4 | +0.0 | 17.9 | 11.7 | 8.2 | 12.6 | +0.0 | |||
| 1 | ✓ | ✓ | 25.8 | 29.9 | 48.4 | 34.7 | +1.3 | 27.2 | 36.8 | 41.8 | 35.3 | +22.7 | ||
| 2 | ✓ | ✓ | 26.9 | 49.9 | 51.0 | 42.6 | +9.2 | 24.2 | 31.8 | 29.8 | 28.6 | +16.0 | ||
| 3 | ✓ | ✓ | ✓ | 79.4 | 115.3 | 108.6 | 101.1 | +67.7 | 85.1 | 100.4 | 94.7 | 93.4 | +80.8 | |
| 4 | ✓ | ✓ | ✓ | ✓ | 128.7 | 295.6 | 315.5 | 246.6 | +213.2 | 95.4 | 84.2 | 102.8 | 94.1 | +81.5 |
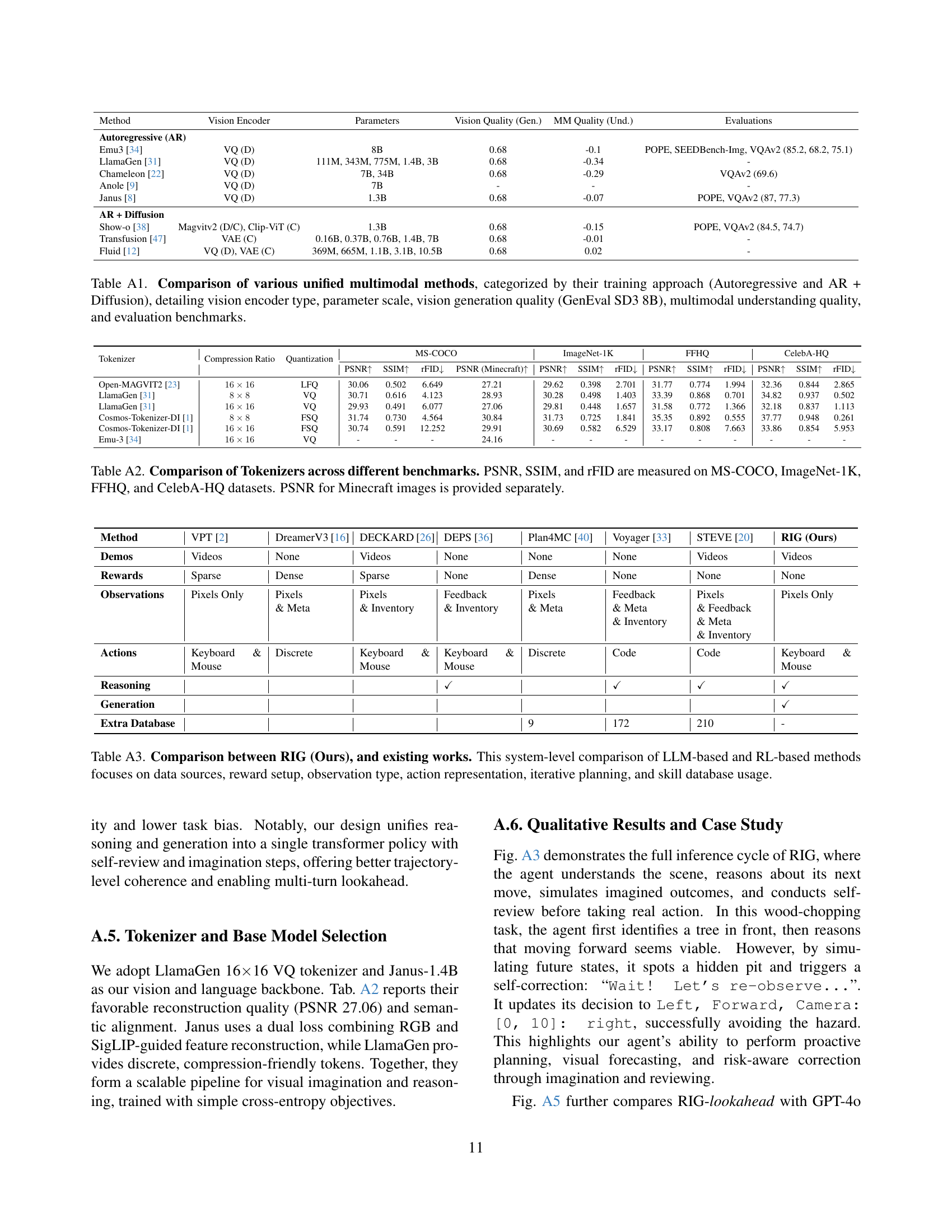
🔼 This ablation study analyzes the impact of different model components (Action, Generation, Reasoning, Lookahead) on embodied task performance in a Minecraft environment. The study is divided into two sections: Manual (where the agent only uses hands for actions) and Tool (where the agent can use tools). For each capability setting (combinations of the components), the table presents the number of successful resource collection tasks (‘Num.’) and the accuracy of exploration tasks (‘Acc.’). ‘Num.’ measures the number of successful tasks in collecting wood, grass, and dirt, reflecting task completion efficiency, while ‘Acc.’ reflects the success rate of exploration tasks, measuring the agent’s ability to navigate and explore the environment effectively. The average performance (‘avg.’) for both metrics is shown, along with the improvement over the baseline (no additional capabilities, ID 0 for both Manual and Tool sections).
read the caption
Table 1: Ablation study on embodied tasks under different capability settings. We compare different combinations of Action, Generation (Gen.), Reasoning (Reason), and Reviewing (Review). The table is divided into two groups: Manual (ID 0–4) and Tool (ID 0-4). The “Num.” column represents the number of completed collecting tasks (wood, grass, dirt), while “Acc.” denotes the success rate of exploration tasks. The columns “avg.” is the average performance. For both metrics, we report the absolute values, along with the improvement (+x𝑥xitalic_x) over the baseline (ID 0 for Manual and Tool).
In-depth insights#
RIG: Synergy#
RIG (Reasoning and Imagination Generalist policy) synergizes reasoning and imagination in embodied agents for enhanced policy learning and generalization. Traditional approaches often isolate these abilities, hindering efficiency. RIG integrates them end-to-end, progressively enriching trajectories with imagination and reasoning. This joint learning explicitly correlates reasoning, action, and environment dynamics, leading to sample efficiency gains and improved generalization. RIG first reasons about actions, imagines outcomes, enabling review and self-correction before execution. Experiments demonstrate robustness, generalization, interoperability, and test-time scaling, highlighting the potential of synergizing reasoning and imagination in embodied agents for complex open-world environments. RIG advances beyond prior methods by unifying reasoning, imagination, and action within a single Transformer model, trained through a progressive data collection strategy. The framework supports dynamic lookahead reasoning at test time, boosting action robustness and reducing trial-and-error.
Data Efficiency#
The research paper emphasizes RIG’s superior data efficiency. The results show that RIG achieves superior performance with only 111 hours of training data, significantly less than previous approaches (VPT: 1962h, MineDreamer: 2101h, STEVE-1/Jarvis-1: ~2000h). RIG attains SOTA results across several benchmarks using only a small dataset. This demonstrates that explicitly modelling the logic and reasoning behind actions significantly improves learning efficiency, enabling the model to generalize effectively from limited data, which may also implies better design choices and model architecture.
Lookahead Review#
The concept of ‘Lookahead Review’ presents a compelling strategy for enhancing agent decision-making. By enabling agents to simulate future states and reason about potential outcomes, this approach allows for more informed and robust action selection. This approach allows the agent to internally review and correct errors before interacting with the environment. The ‘review’ mechanism facilitates a deeper understanding of action consequences, reducing trial-and-error. This concept of self-correction based on imagined scenarios is crucial for agents operating in complex and uncertain environments, where immediate rewards may not accurately reflect long-term success or safety. By integrating this mechanism agents can learn more effective and adaptable policies.
Ablation Synergies#
In essence, ablation studies meticulously dissect the contributions of individual components within a larger system, enabling a nuanced understanding of their respective impacts and interdependencies. Through systematic removal or modification of specific elements, researchers can discern the extent to which each contributes to overall performance, thereby illuminating potential redundancies, bottlenecks, and synergistic relationships. The synergizing effects of different components (Action, Generation, Basic Reasoning and Lookahead Reasoning) is leading to a robust performance (helps structured learning and improves short-term decisions and long-horizon task completion). Such comprehensive analyses are indispensable for refining designs, optimizing resource allocation, and gaining fundamental insights into underlying mechanisms. This is crucial for enhancing performance in research.
Multi-Modal RIG#
RIG (Reasoning and Imagination Generalist) is explored in the paper with a strong emphasis on its multi-modal capabilities. RIG is an end-to-end policy that integrates understanding and generation of visual, actions, and language in a single autoregressive Transformer. The model leverages explicit reasoning and visual imagination to enable robust performance. It uses a combination of diverse modalities that are not separated but explicitly correlated, which yields performance gains across tasks and generalization capabilities. The paper stresses that synergistic, multi-modal approach offers an effective design pattern for tackling complexity in embodied environments.
More visual insights#
More on figures

🔼 Figure 2 illustrates the process of creating the training dataset for the RIG model. It begins with existing datasets: S0 uses refined data from MineRL-V0, while S1 collects vision-action pairs from STEVE-1. In S2, reasoning is added to the data using GPT-40. Crucially, S3 involves a comparative analysis. The trained RIG-basic and STEVE-1 are run in parallel, and only instances where RIG-basic underperforms STEVE-1 are retained for the dataset. This ensures that the model learns from its mistakes and improves its performance. Finally, S4 aligns the trajectories temporally, ensuring consistency.
read the caption
Figure 2: Illustration of the data collection pipeline (S0–S4). Note that at S3 (Vision-Reviewing), we run the trained RIG-basic and policy model (STEVE-1 [20]) in parallel, keeping instances where RIG-basic performs poorly compared to STEVE-1.

🔼 Figure 3 illustrates the multi-step reasoning process within RIG, the proposed model. RIG doesn’t just react to immediate observations; instead, it engages in a structured conversation with itself. This is represented by a series of interconnected steps. The key element is the use of the token ‘Imagine:’ to explicitly distinguish between real-world observations and internally generated scenarios. By employing this distinction, RIG maintains coherence in its reasoning, action prediction, and visual imagination processes. This methodology allows for a more thorough evaluation of prospective actions before taking real-world action.
read the caption
Figure 3: Inference process in RIG. RIG follows a structured conversation flow through multi-turn interactions. It consistently uses the fixed word Imagine: to clearly separate internally imagined scenarios from real observations, thereby guiding coherent reasoning, action prediction, and visual imagination.
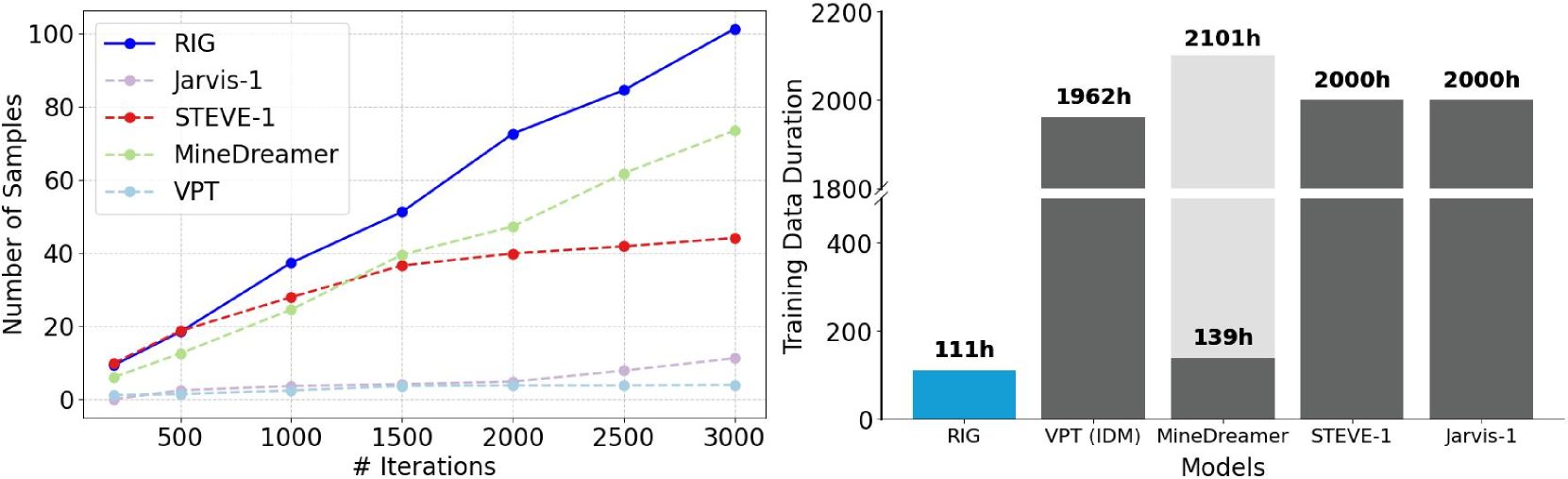
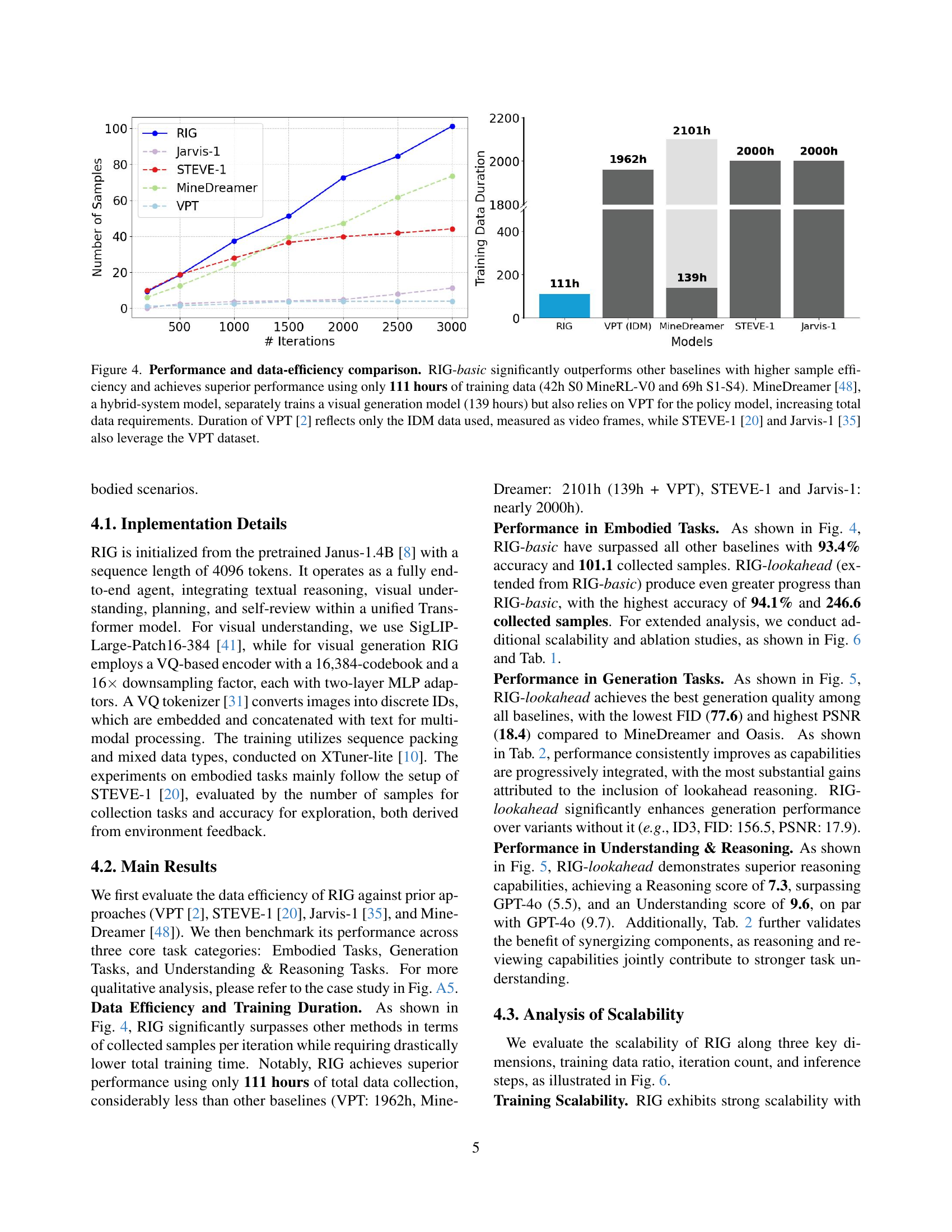
🔼 Figure 4 presents a comparison of RIG-basic’s performance against other state-of-the-art methods in terms of both sample efficiency and overall performance on embodied tasks. RIG-basic demonstrates significantly better performance using only 111 hours of training data, significantly less than the others. The figure shows that RIG-basic requires far fewer training iterations to achieve comparable or superior performance compared to models like VPT, STEVE-1, Jarvis-1, and MineDreamer. The reduced training time is particularly noteworthy considering the superior performance obtained by RIG-basic. Note that MineDreamer is a hybrid system, requiring separate training for a visual generation model in addition to utilizing the VPT policy model, thereby increasing its total training data requirements.
read the caption
Figure 4: Performance and data-efficiency comparison. RIG-basic significantly outperforms other baselines with higher sample efficiency and achieves superior performance using only 111 hours of training data (42h S0 MineRL-V0 and 69h S1-S4). MineDreamer [48], a hybrid-system model, separately trains a visual generation model (139 hours) but also relies on VPT for the policy model, increasing total data requirements. Duration of VPT [2] reflects only the IDM data used, measured as video frames, while STEVE-1 [20] and Jarvis-1 [35] also leverage the VPT dataset.

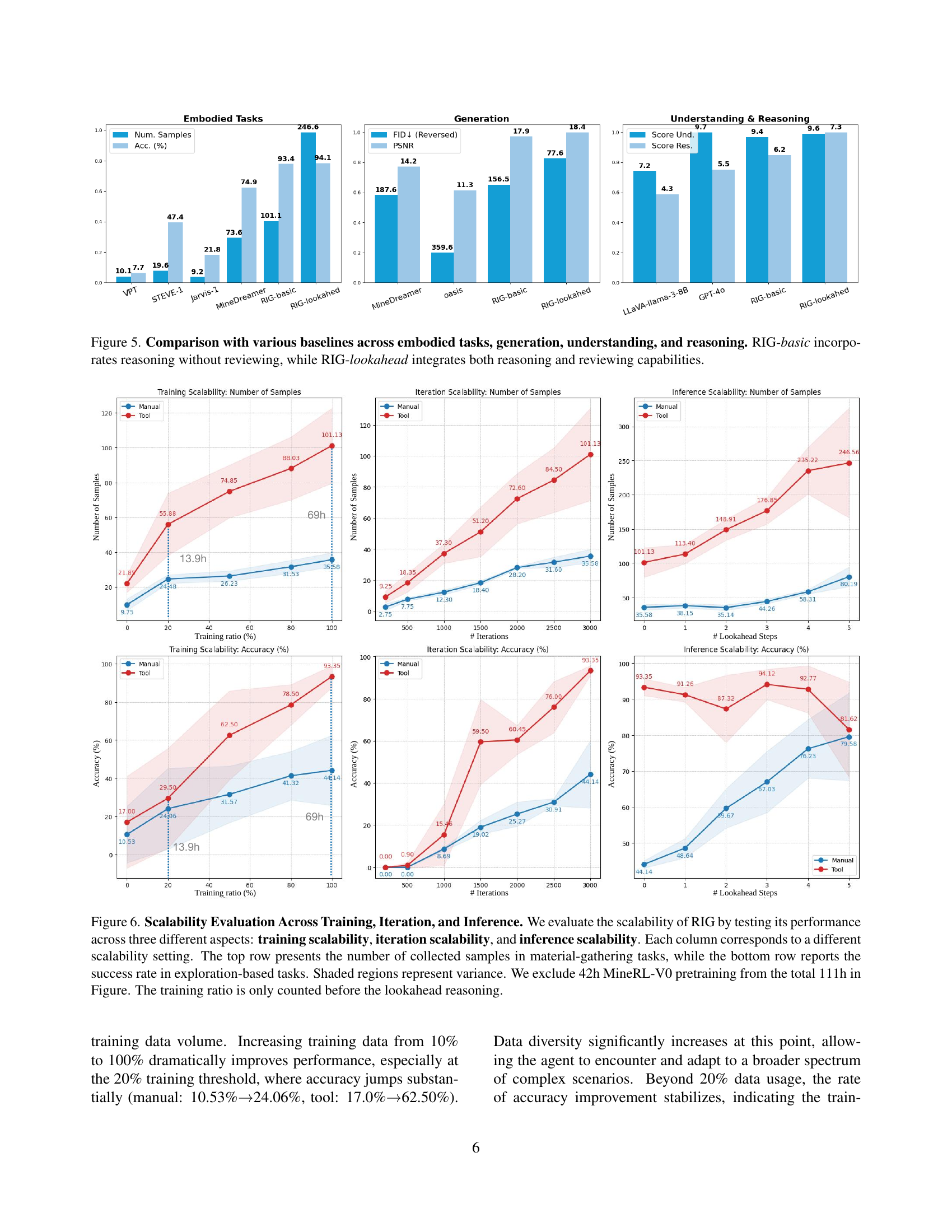
🔼 Figure 5 presents a comparative analysis of RIG (Reasoning and Imagination Generalist) against several baseline models across four key aspects: embodied tasks, image generation, understanding, and reasoning. The results showcase RIG’s superior performance. RIG-basic, the simpler model using reasoning alone, already demonstrates improvements over the baselines. However, RIG-lookahead, incorporating both reasoning and a review mechanism, achieves the best results across all four evaluation categories. This visualization highlights the substantial improvements in performance achieved by synergizing reasoning and imagination.
read the caption
Figure 5: Comparison with various baselines across embodied tasks, generation, understanding, and reasoning. RIG-basic incorporates reasoning without reviewing, while RIG-lookahead integrates both reasoning and reviewing capabilities.

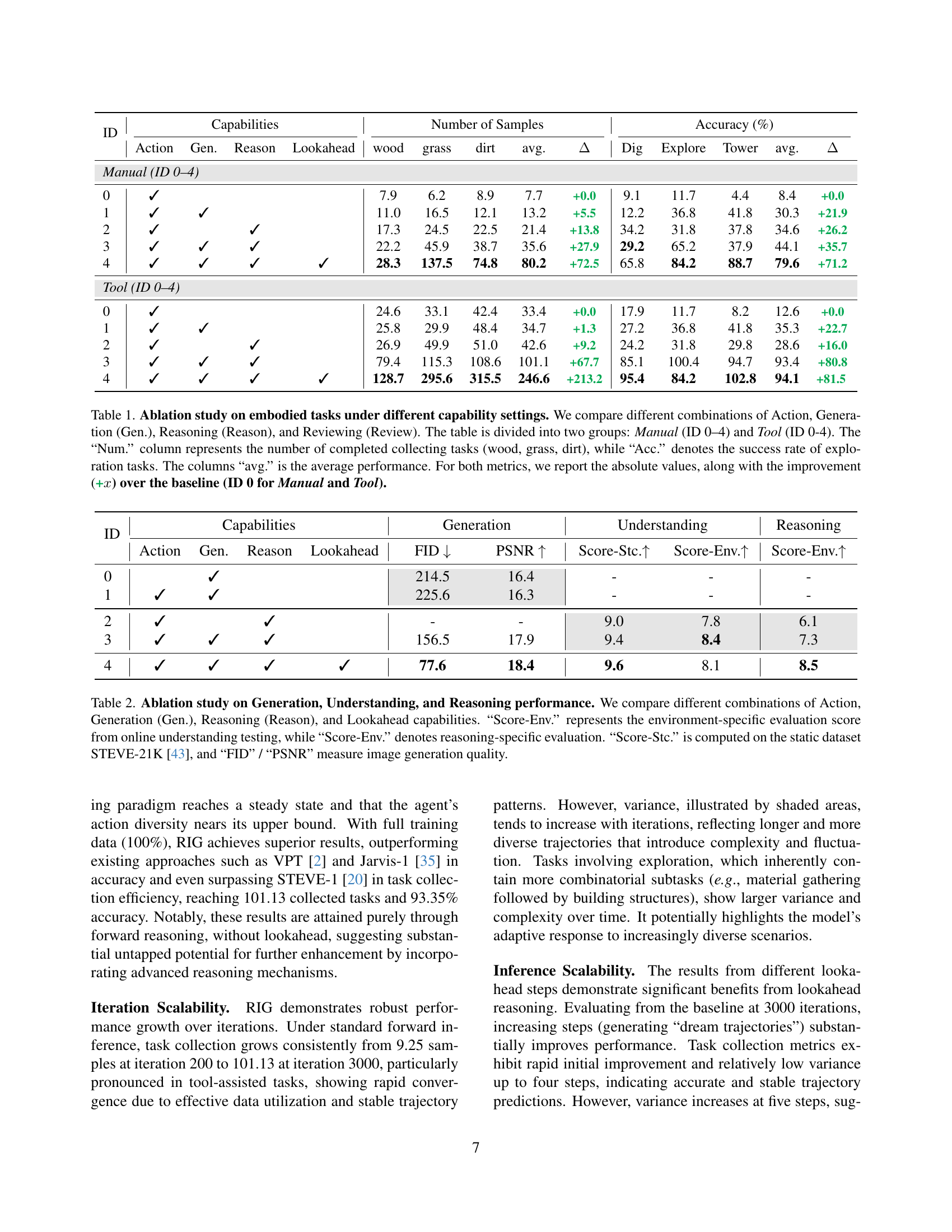
🔼 Figure 6 shows the scalability of the RIG model across training data, iterations, and inference steps. The top row displays the number of samples collected during material-gathering tasks for different scalability settings (e.g., varying training data, iterations, or lookahead steps), while the bottom row shows the success rate in exploration-based tasks under the same settings. Shaded areas indicate variance. The figure excludes the initial 42 hours of MineRL-V0 pretraining from the total 111 training hours. The training ratio only considers data before lookahead reasoning is applied.
read the caption
Figure 6: Scalability Evaluation Across Training, Iteration, and Inference. We evaluate the scalability of RIG by testing its performance across three different aspects: training scalability, iteration scalability, and inference scalability. Each column corresponds to a different scalability setting. The top row presents the number of collected samples in material-gathering tasks, while the bottom row reports the success rate in exploration-based tasks. Shaded regions represent variance. We exclude 42h MineRL-V0 pretraining from the total 111h in Figure. The training ratio is only counted before the lookahead reasoning.
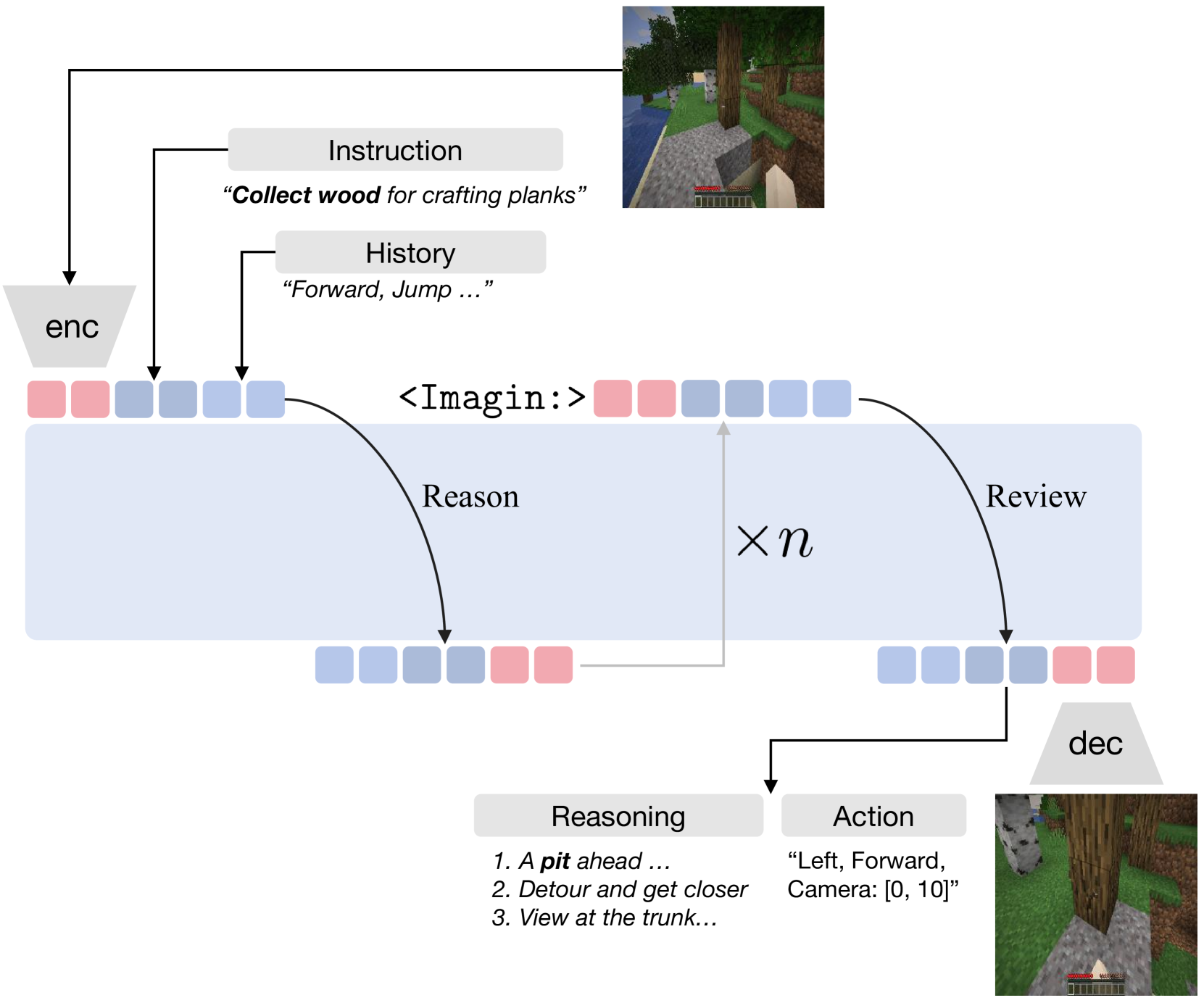
🔼 The figure illustrates RIG’s inference process, which involves generating imagined visual states and corresponding reasoning to simulate multiple action trajectories. This allows the agent to conduct self-review and make corrective predictions before executing real-world actions. The process begins with an instruction, current visual observation, and the history of previous actions. RIG uses this to produce textual reasoning steps. Importantly, to separate imagined scenarios from real observations, RIG uses the token
<Imagine:>before generating predicted future visual states (frames) and associated reasoning. These imagined scenarios are then used to refine the decision-making process. Finally, the next action and a prediction of the resulting frame are output.read the caption
Figure A1: Detailed inference pipeline. RIG generates imagined visual states and corresponding reasoning to simulate multiple action trajectories, enabling self-review and corrective prediction.

🔼 This figure details the training pipeline of the RIG model, showing how it progressively incorporates reasoning and imagination. S0 and S1 stages pretrain the model using real and imagined trajectories. S2 and S3 further improve the model by adding reasoning and reviewing capabilities via GPT-40 relabeling. Finally, S4 aligns the model’s imagined future trajectories (dream flow) with actual environmental observations (environment-grounded traces), allowing the model to refine its predictions based on reality.
read the caption
Figure A2: Training pipeline of RIG. S0/S1 pretrain the model by aligning real and imagined flows. S2/S3 enhance reasoning and reviewing via GPT-4o relabeling. S4 aligns temporally predicted trajectories (dream flow) with environment-grounded traces.

🔼 Figure A3 illustrates the decision-making process of RIG, highlighting the benefits of lookahead reasoning and internal review. The agent first perceives and interprets the environment (steps 1 and 2). Then, it simulates potential future states (step 3) by using its imagination of how actions may affect the world. By leveraging its internal predictive model, it can anticipate a hidden hazard or undesirable outcome. After reviewing the simulated future (step 3), the agent refines its planned action and modifies the decision to avoid the anticipated hazard before acting (step 4). This mechanism enhances the robustness and reliability of the agent’s actions.
read the caption
Figure A3: Qualitative example of lookahead and review. The agent understands the environment (1–2), simulates future states (3), and refines its decision through internal review before acting (4), successfully avoiding a hidden hazard.

🔼 Figure A4 is a visualization showing the distribution of different types of embodied tasks present in the datasets used to train the RIG model. The tasks are categorized by complexity, ranging from simpler tasks like collecting resources to more complex tasks requiring strategic planning and higher-level reasoning. The diversity in task complexity is highlighted to emphasize the model’s ability to generalize well across a wide range of challenging scenarios in the Minecraft environment.
read the caption
Figure A4: Task distribution. Our datasets include various embodied tasks with varying complexity, ensuring strong generalization across downstream goals.

🔼 This figure compares the performance of RIG and GPT-4 in a Minecraft tree-chopping task. Both models receive the same visual input (the game screen) and the same instruction: ‘chop a tree.’ RIG demonstrates a more robust approach. It first reasons about the scene, identifies a suitable tree, and plans actions to reach and chop it, adjusting its camera position as needed. Then, it simulates the result of its plan (through visual imagination). GPT-4, while producing visually appealing output, makes a critical error in distance judgment, selecting an unreachable tree and attempting an invalid action. Because GPT-4 doesn’t use visual imagination, it fails to correct its plan after executing the incorrect action. The comparison highlights RIG’s ability to combine reasoning, visual imagination, and planning for reliable decision-making in dynamic environments.
read the caption
Figure A5: Case study comparison with GPT-4o. Given the same input and prompt (chop a tree), RIG reasons and imagines future states to choose a reachable tree and adjust position before acting. GPT-4o, despite high visual quality, misjudges the distance, executes an invalid action, and fails to revise its plan.
More on tables
| ID | Capabilities | Generation | Understanding | Reasoning | |||||
| Action | Gen. | Reason | Lookahead | FID | PSNR | Score-Stc. | Score-Env. | Score-Env. | |
| 0 | ✓ | 214.5 | 16.4 | - | - | - | |||
| 1 | ✓ | ✓ | 225.6 | 16.3 | - | - | - | ||
| 2 | ✓ | ✓ | - | - | 9.0 | 7.8 | 6.1 | ||
| 3 | ✓ | ✓ | ✓ | 156.5 | 17.9 | 9.4 | 8.4 | 7.3 | |
| 4 | ✓ | ✓ | ✓ | ✓ | 77.6 | 18.4 | 9.6 | 8.1 | 8.5 |
🔼 This table presents an ablation study analyzing the impact of different model components on the performance of the RIG model across various aspects. Specifically, it examines the effects of incorporating action prediction, image generation, explicit reasoning, and lookahead reasoning capabilities. Performance is evaluated using metrics such as FID and PSNR for image generation, Score-Stc. for static understanding on the STEVE-21K dataset, and Score-Env. for environment-specific and reasoning-specific understanding. The table allows for a systematic comparison of how each component contributes to the overall performance of the model.
read the caption
Table 2: Ablation study on Generation, Understanding, and Reasoning performance. We compare different combinations of Action, Generation (Gen.), Reasoning (Reason), and Lookahead capabilities. “Score-Env.” represents the environment-specific evaluation score from online understanding testing, while “Score-Env.” denotes reasoning-specific evaluation. “Score-Stc.” is computed on the static dataset STEVE-21K [43], and “FID” / “PSNR” measure image generation quality.
| Method | Vision Encoder | Parameters | Vision Quality (Gen.) | MM Quality (Und.) | Evaluations |
|---|---|---|---|---|---|
| Autoregressive (AR) | |||||
| Emu3 [34] | VQ (D) | 8B | 0.68 | -0.1 | POPE, SEEDBench-Img, VQAv2 (85.2, 68.2, 75.1) |
| LlamaGen [31] | VQ (D) | 111M, 343M, 775M, 1.4B, 3B | 0.68 | -0.34 | - |
| Chameleon [22] | VQ (D) | 7B, 34B | 0.68 | -0.29 | VQAv2 (69.6) |
| Anole [9] | VQ (D) | 7B | - | - | - |
| Janus [8] | VQ (D) | 1.3B | 0.68 | -0.07 | POPE, VQAv2 (87, 77.3) |
| AR + Diffusion | |||||
| Show-o [38] | Magvitv2 (D/C), Clip-ViT (C) | 1.3B | 0.68 | -0.15 | POPE, VQAv2 (84.5, 74.7) |
| Transfusion [47] | VAE (C) | 0.16B, 0.37B, 0.76B, 1.4B, 7B | 0.68 | -0.01 | - |
| Fluid [12] | VQ (D), VAE (C) | 369M, 665M, 1.1B, 3.1B, 10.5B | 0.68 | 0.02 | - |
🔼 Table A1 compares different unified multimodal models, categorized by whether they use an autoregressive approach or a combination of autoregressive and diffusion methods. The table details key characteristics of each model, including the type of vision encoder used (e.g., VQGAN, VAE), the model’s parameter size (in billions), vision generation quality as measured by GenEval SD3 8B, the quality of multimodal understanding, and the evaluation benchmarks used to assess the model’s performance. This provides a comprehensive overview of the capabilities and performance of various state-of-the-art multimodal models.
read the caption
Table A1: Comparison of various unified multimodal methods, categorized by their training approach (Autoregressive and AR + Diffusion), detailing vision encoder type, parameter scale, vision generation quality (GenEval SD3 8B), multimodal understanding quality, and evaluation benchmarks.
| Tokenizer | Compression Ratio | Quantization | MS-COCO | ImageNet-1K | FFHQ | CelebA-HQ | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | rFID | PSNR (Minecraft) | PSNR | SSIM | rFID | PSNR | SSIM | rFID | PSNR | SSIM | rFID | |||
| Open-MAGVIT2 [23] | LFQ | 30.06 | 0.502 | 6.649 | 27.21 | 29.62 | 0.398 | 2.701 | 31.77 | 0.774 | 1.994 | 32.36 | 0.844 | 2.865 | |
| LlamaGen [31] | VQ | 30.71 | 0.616 | 4.123 | 28.93 | 30.28 | 0.498 | 1.403 | 33.39 | 0.868 | 0.701 | 34.82 | 0.937 | 0.502 | |
| LlamaGen [31] | VQ | 29.93 | 0.491 | 6.077 | 27.06 | 29.81 | 0.448 | 1.657 | 31.58 | 0.772 | 1.366 | 32.18 | 0.837 | 1.113 | |
| Cosmos-Tokenizer-DI [1] | FSQ | 31.74 | 0.730 | 4.564 | 30.84 | 31.73 | 0.725 | 1.841 | 35.35 | 0.892 | 0.555 | 37.77 | 0.948 | 0.261 | |
| Cosmos-Tokenizer-DI [1] | FSQ | 30.74 | 0.591 | 12.252 | 29.91 | 30.69 | 0.582 | 6.529 | 33.17 | 0.808 | 7.663 | 33.86 | 0.854 | 5.953 | |
| Emu-3 [34] | VQ | - | - | - | 24.16 | - | - | - | - | - | - | - | - | - | |
🔼 Table A2 presents a comparison of various tokenizers’ performance across multiple image benchmark datasets. It shows the Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), and Fréchet Inception Distance (FID) scores for each tokenizer on the MS-COCO, ImageNet-1K, FFHQ, and CelebA-HQ datasets. A separate PSNR score is also provided for Minecraft images. This allows for a comprehensive evaluation of the tokenizers’ ability to reconstruct and represent images effectively, highlighting their relative strengths and weaknesses for various image types and visual fidelity.
read the caption
Table A2: Comparison of Tokenizers across different benchmarks. PSNR, SSIM, and rFID are measured on MS-COCO, ImageNet-1K, FFHQ, and CelebA-HQ datasets. PSNR for Minecraft images is provided separately.
| Method | VPT [2] | DreamerV3 [16] | DECKARD [26] | DEPS [36] | Plan4MC [40] | Voyager [33] | STEVE [20] | RIG (Ours) |
| Demos | Videos | None | Videos | None | None | None | Videos | Videos |
| Rewards | Sparse | Dense | Sparse | None | Dense | None | None | None |
| Observations | Pixels Only | Pixels & Meta | Pixels & Inventory | Feedback & Inventory | Pixels & Meta | Feedback & Meta & Inventory | Pixels & Feedback & Meta & Inventory | Pixels Only |
| Actions | Keyboard & Mouse | Discrete | Keyboard & Mouse | Keyboard & Mouse | Discrete | Code | Code | Keyboard & Mouse |
| Reasoning | ✓ | ✓ | ✓ | ✓ | ||||
| Generation | ✓ | |||||||
| Extra Database | 9 | 172 | 210 | - |
🔼 Table A3 provides a detailed comparison of RIG against existing methods for embodied AI, focusing on key architectural differences. It contrasts data sources used for training (e.g., videos, simulated experience), reward structures (sparse vs. dense), the type of observations provided to the agent (raw pixels, additional metadata), how actions are represented (discrete actions, keyboard inputs), the presence of planning mechanisms (iterative vs. non-iterative), and whether the agent uses a skill database for pre-trained actions. This comparison highlights RIG’s unique features and relative strengths among similar approaches.
read the caption
Table A3: Comparison between RIG (Ours), and existing works. This system-level comparison of LLM-based and RL-based methods focuses on data sources, reward setup, observation type, action representation, iterative planning, and skill database usage.
Full paper#