TL;DR#
DUSt3R, a network for 3D scene reconstruction, requires large datasets which is a bottleneck for 4D dynamic scenes. Existing 4D methods fine-tune 3D models using data with geometric priors, like optical flow. However, accuracy declines with dynamic objects that violate geometric rules. To address this, researchers need a generalizable 4D model without extensive training. This paper asks if there are human perception methods for 4D reconstruction.
The paper introduces Easi3R, a simple, training-free method for 4D reconstruction via attention adaptation during inference. It uses DUSt3R attention layers to encode camera & object motion. By disentangling these maps, it segments dynamic regions, estimates camera pose, & reconstructs 4D point maps. Experiments show Easi3R outperforms trained methods, offering a scalable solution.
Key Takeaways#
Why does it matter?#
This paper introduces Easi3R, a novel training-free method for dynamic scene reconstruction, potentially reducing the reliance on extensive training data and offering a scalable solution for real-world applications. It opens new avenues for research in unsupervised 4D reconstruction.
Visual Insights#

🔼 Easi3R is a novel method for 4D reconstruction that works without any training. It takes advantage of the attention mechanisms within the pre-trained DUSt3R model to separate camera motion from object motion. This disentanglement allows Easi3R to adapt DUSt3R to dynamic scenes, generating accurate 4D point clouds despite the presence of moving objects. The figure shows a visual representation of this process, illustrating how Easi3R processes video frames to produce a 4D reconstruction by distinguishing between camera and object movements.
read the caption
Figure 1: We present Easi3R, a training-free, plug-and-play approach that efficiently disentangles object and camera motion, enabling the adaptation of DUSt3R for 4D reconstruction.
🔼 Table 1 presents a comprehensive comparison of different methods for dynamic object segmentation on the DAVIS dataset. The table evaluates the performance of several approaches, including the baseline methods DUSt3R and MonST3R, along with their enhanced versions using the proposed Easi3R adaptation. The results are presented in terms of Jaccard Index (JM) and Recall (JR), which are common metrics for evaluating the quality of object segmentation. The best and second-best results for each metric are highlighted, allowing for an easy comparison and clear identification of the top-performing methods. The Easi3R method is evaluated using both DUSt3R and MonST3R as the base networks (backbones).
read the caption
Table 1: Dynamic Object Segmentation on the DAVIS dataset. The best and second best results are bold and underlined, respectively. Easi3R dust3r/monst3rdust3r/monst3r{}_{\text{dust3r/monst3r}}start_FLOATSUBSCRIPT dust3r/monst3r end_FLOATSUBSCRIPT denotes the Easi3R experiment with the backbones of MonST3R/DUSt3R.
In-depth insights#
DUSt3R Adaptation#
Easi3R leverages the pre-trained DUSt3R model for dynamic scene reconstruction without fine-tuning. It cleverly exploits the attention mechanisms within DUSt3R, which implicitly encode information about camera and object motion. The core idea involves a training-free adaptation strategy during inference. By analyzing and carefully disentangling the cross-attention maps, Easi3R can segment dynamic regions, estimate camera pose, and reconstruct 4D point clouds. This approach avoids the need for extensive training on dynamic datasets, which are often limited in scale and diversity. The method’s effectiveness stems from the observation that DUSt3R’s attention layers assign low values to regions violating epipolar geometry constraints (e.g., texture-less, under-observed, and dynamic areas). Easi3R effectively isolates these components, enabling accurate long-horizon dynamic object detection and segmentation.
Training-Free 4D#
The concept of “Training-Free 4D” reconstruction is intriguing, as it aims to circumvent the limitations posed by scarce and diverse 4D datasets. The core idea likely involves leveraging pre-trained models, perhaps trained on large static scene datasets, and adapting them to dynamic scenarios without requiring further training. This could involve clever techniques like attention mechanisms or geometric priors to disentangle object and camera motion. The advantage is significant: it unlocks the potential to reconstruct dynamic scenes from readily available video data without the costly and time-consuming process of creating or fine-tuning on specialized 4D datasets. This approach would need to be highly adaptable and robust to handle the complexities of real-world dynamic videos, including varying lighting conditions, occlusions, and object motion patterns. Success in this area would represent a major step forward in making 4D reconstruction more accessible and practical.
Attention Secrets#
The title “Attention Secrets” hints at a deeper exploration into how attention mechanisms, particularly in models like DUSt3R, contribute to scene understanding. It suggests an attempt to unravel the implicit knowledge encoded within attention layers, possibly related to identifying key features, relationships between objects, and even discerning motion. The core idea is to extract useful information from the model’s internal workings without explicit training for a specific task. This involves analyzing attention weights to identify areas the network deems important, offering insights into segmentation and motion, potentially leading to novel ways to improve performance or adapt models for new scenarios. It is also expected that the study reveals the method the model use to differentiate objects, their characteristics and their movements.
Dynamic Disentangle#
While the paper doesn’t explicitly use the term “Dynamic Disentangle” as a heading, this concept is at the core of the research. It alludes to the algorithm’s ability to separate and handle independently dynamic (moving) objects and the static background within a video sequence. This disentanglement is crucial for accurate 4D reconstruction, as it prevents the motion of objects from interfering with camera pose estimation and the reconstruction of the static scene. Easi3R achieves this by analyzing attention maps within the DUSt3R framework to identify regions corresponding to moving objects. By isolating these regions, the algorithm can then re-weight the attention and improve the accuracy of both dynamic object segmentation and the overall reconstruction. The disentanglement directly affects the temporal consistency of the reconstruction.
Limited Accuracy#
Limited accuracy is a crucial concern in many research areas. Several factors can contribute to this such as low-quality data, inadequate model complexity, or the presence of confounding variables. It’s important to acknowledge situations where the model or method struggles to achieve high precision or recall. This limitation could stem from the inherent difficulty of the task or the specific dataset used. Furthermore, accuracy may be limited by the assumptions made during model development or the availability of computational resources. Acknowledging this prompts further investigation, potentially leading to refined methods, more comprehensive datasets, or alternative approaches to mitigate the shortcomings and improve overall performance and reliability.
More visual insights#
More on figures

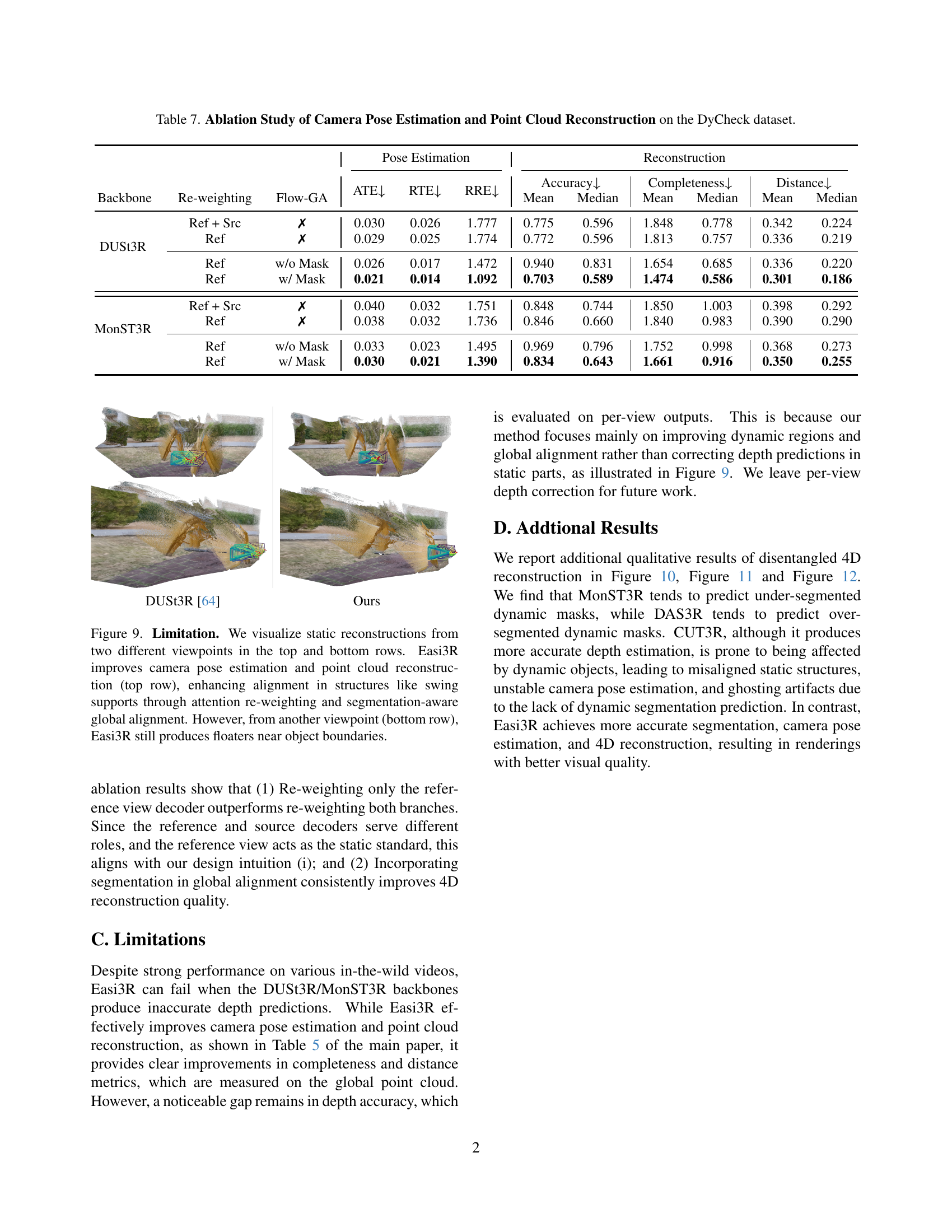
🔼 The figure illustrates how DUSt3R, a method for 3D reconstruction, handles video data. DUSt3R processes image pairs through a sliding window approach. However, when moving objects are present, the accuracy of the reconstruction decreases because the relative motion between objects and the camera violates assumptions inherent to the method. The resulting reconstruction becomes misaligned and inaccurate in areas where substantial portions of the frame are occupied by moving objects.
read the caption
Figure 2: DUSt3R with Dynamic Video. We process videos using a sliding window and infer the DUSt3R network pairwise. Reconstruction degrades with misalignment when dynamic objects occupy a considerable portion of the frames.

🔼 This figure illustrates the architecture of DUSt3R and how the authors’ method, Easi3R, adapts it for dynamic scenes. DUSt3R processes two images, creating feature tokens that are decoded into point maps. Easi3R enhances this by aggregating cross-attention maps from DUSt3R’s decoders, generating four maps representing different motion aspects (mean and variance of attention from source and reference views). These new maps are then used in a second inference pass, improving reconstruction quality in dynamic scenes.
read the caption
Figure 3: DUSt3R and our Easi3R adaptation. DUSt3R encodes two images Ia,Ibsuperscript𝐼𝑎superscript𝐼𝑏I^{a},I^{b}italic_I start_POSTSUPERSCRIPT italic_a end_POSTSUPERSCRIPT , italic_I start_POSTSUPERSCRIPT italic_b end_POSTSUPERSCRIPT into feature tokens 𝐅0a,𝐅0bsuperscriptsubscript𝐅0𝑎superscriptsubscript𝐅0𝑏\mathbf{F}_{0}^{a},\mathbf{F}_{0}^{b}bold_F start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_a end_POSTSUPERSCRIPT , bold_F start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_b end_POSTSUPERSCRIPT, which are then decoded into point maps in the reference view coordinate space using two decoders. Our Easi3R aggregates the cross-attention maps from the decoders, producing four semantically meaningful maps: 𝐀μb=src,𝐀σb=src,𝐀μa=ref,𝐀σb=refsubscriptsuperscript𝐀𝑏src𝜇subscriptsuperscript𝐀𝑏src𝜎subscriptsuperscript𝐀𝑎ref𝜇subscriptsuperscript𝐀𝑏ref𝜎\mathbf{A}^{b=\text{src}}_{\mu},\mathbf{A}^{b=\text{src}}_{\sigma},\mathbf{A}^% {a=\text{ref}}_{\mu},\mathbf{A}^{b=\text{ref}}_{\sigma}bold_A start_POSTSUPERSCRIPT italic_b = src end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_μ end_POSTSUBSCRIPT , bold_A start_POSTSUPERSCRIPT italic_b = src end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_σ end_POSTSUBSCRIPT , bold_A start_POSTSUPERSCRIPT italic_a = ref end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_μ end_POSTSUBSCRIPT , bold_A start_POSTSUPERSCRIPT italic_b = ref end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_σ end_POSTSUBSCRIPT. These maps are then used for a second inference pass to enhance reconstruction quality.

🔼 Figure 4 visualizes cross-attention maps from a deep learning model used for 4D reconstruction. The maps are color-coded, with brighter colors representing higher attention values, and darker values representing lower attention. The figure showcases different patterns within these attention maps, highlighting how the model attends to various aspects of the scene, including dynamic objects, textured areas, areas with little texture, and under-observed parts. Each column shows a different type of attention pattern. The caption invites readers to visit a website for more details because the visualization is more effectively shown with interactive elements.
read the caption
Figure 4: Visualization for Cross-Attention Maps. We color the normalized values of attention maps, ranging from one to zero. We highlight the patterns captured by each type of attention map using relatively high values. For a more detailed demonstration, we invite reviewers to visit our webpage under easi3r.github.io.

🔼 Figure 5 presents a qualitative comparison of dynamic object segmentation results from several methods, including the proposed Easi3R method using the MonST3R backbone. The ’enhanced’ setting shown uses the output of each method as a prompt for the SAM2 model, which performs mask refinement. The figure demonstrates the improvement in segmentation accuracy achieved by Easi3R compared to other state-of-the-art methods.
read the caption
Figure 5: Qualitative Results of Dynamic Object Segmentation. “Ours” refers to the Easi3Rmonst3rsubscriptEasi3Rmonst3r\mbox{{Easi3R}}_{\text{monst3r}}Easi3R start_POSTSUBSCRIPT monst3r end_POSTSUBSCRIPT setting. Here, we present the enhanced setting, where outputs from different methods serve as prompts and are used with SAM2 [46] for mask inference.

🔼 Figure 6 presents a qualitative comparison of 4D reconstruction results across different methods. The top row shows the input video frames. The subsequent rows display the reconstruction results from CUTR3, MonST3R, DAS3R, and the proposed Easi3R method (with DUSt3R and MonST3R backbones). Easi3R uses estimated per-frame dynamic masks to filter out dynamic points when comparing across different timestamps, unlike previous methods which used ground truth masks. The visualization demonstrates that Easi3R achieves temporally consistent reconstruction of both static and dynamic elements, while the baseline methods suffer from issues like misaligned static structures, unstable camera pose estimation, and ghosting artifacts caused by inaccurate dynamic segmentation.
read the caption
Figure 6: Qualitative Comparison. We visualize cross-frame globally aligned static scenes with dynamic point clouds at a selected timestamp. Notably, instead of using ground truth dynamic masks in previous work, we apply the estimated per-frame dynamic masks to filter out dynamic points at other timestamps for comparison. Our method (top two and bottom two rows as Easi3R dust3r/monst3rdust3r/monst3r{}_{\text{dust3r/monst3r}}start_FLOATSUBSCRIPT dust3r/monst3r end_FLOATSUBSCRIPT, respectively) achieves temporally consistent reconstruction of both static scenes and moving objects, whereas baselines suffer from static structure misalignment and unstable camera pose estimation, and ghosting artifacts due to inaccuracy estimation of dynamic segmentation.

🔼 Figure 7 presents a comparison of estimated camera trajectories. The ground truth trajectory is shown in gray. The trajectories estimated using the original DUSt3R and MonST3R models are shown in blue. The trajectory generated by the proposed Easi3R method is shown in orange. The figure visually demonstrates that Easi3R produces a more accurate camera trajectory, exhibiting less deviation from the ground truth compared to the original models.
read the caption
Figure 7: Visualization of estimated camera trajectories. Our robust estimated camera trajectory (orange) deviates less from the ground truth (gray) compared to the original backbones (blue).
More on tables
| DAVIS-16 | DAVIS-17 | DAVIS-all | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| w/o SAM2 | w/ SAM2 | w/o SAM2 | w/ SAM2 | w/o SAM2 | w/ SAM2 | ||||||||
| Method | Flow | JM | JR | JM | JR | JM | JR | JM | JR | JM | JR | JM | JR |
| DUSt3R [64] | ✓ | 42.1 | 45.7 | 58.5 | 63.4 | 35.2 | 35.3 | 48.7 | 50.2 | 35.9 | 34.0 | 47.6 | 48.7 |
| MonST3R [73] | ✓ | 40.9 | 42.2 | 64.3 | 73.3 | 38.6 | 38.2 | 56.4 | 59.6 | 36.7 | 34.3 | 51.9 | 54.1 |
| DAS3R [68] | ✗ | 41.6 | 39.0 | 54.2 | 55.8 | 43.5 | 42.1 | 57.4 | 61.3 | 43.4 | 38.7 | 53.9 | 54.8 |
| Easi3R | ✗ | 53.1 | 60.4 | 67.9 | 71.4 | 49.0 | 56.4 | 60.1 | 65.3 | 44.5 | 49.6 | 54.7 | 60.6 |
| Easi3R | ✗ | 57.7 | 71.6 | 70.7 | 79.9 | 56.5 | 68.6 | 67.9 | 76.1 | 53.0 | 63.4 | 63.1 | 72.6 |
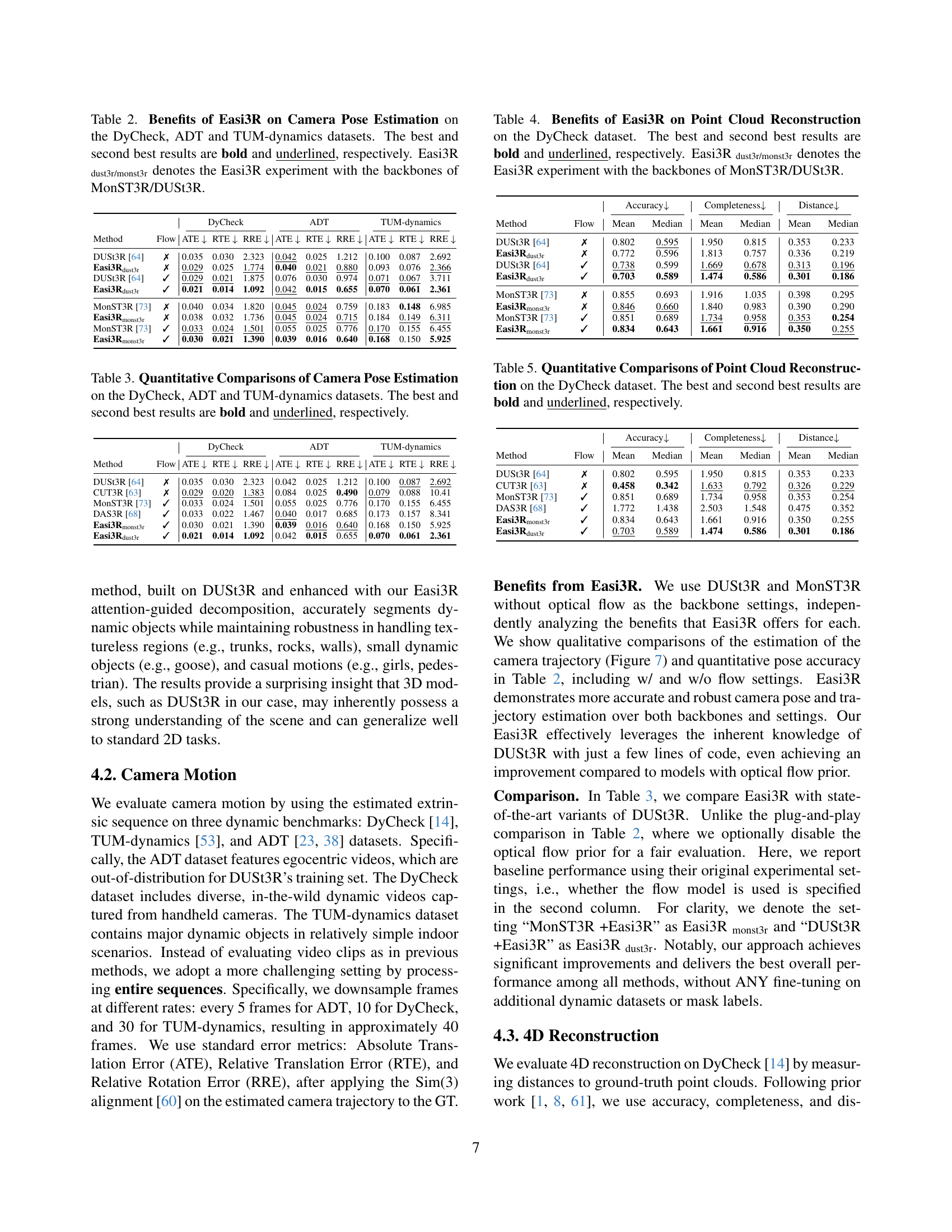
🔼 This table presents a comparison of camera pose estimation results on three datasets (DyCheck, ADT, and TUM-dynamics) using different methods. The methods compared include baseline DUSt3R and MonST3R models and the proposed Easi3R method using DUSt3R and MonST3R as backbones (denoted as Easi3R_dust3r and Easi3R_monst3r respectively). The performance is measured using three metrics: Absolute Translation Error (ATE), Relative Translation Error (RTE), and Relative Rotation Error (RRE). The best and second-best results for each metric and dataset are highlighted in bold and underlined, respectively. The table demonstrates the improvements achieved by incorporating Easi3R.
read the caption
Table 2: Benefits of Easi3R on Camera Pose Estimation on the DyCheck, ADT and TUM-dynamics datasets. The best and second best results are bold and underlined, respectively. Easi3R dust3r/monst3rdust3r/monst3r{}_{\text{dust3r/monst3r}}start_FLOATSUBSCRIPT dust3r/monst3r end_FLOATSUBSCRIPT denotes the Easi3R experiment with the backbones of MonST3R/DUSt3R.
🔼 This table presents a quantitative comparison of camera pose estimation results across three different datasets: DyCheck, ADT, and TUM-dynamics. For each dataset, it shows the Absolute Translation Error (ATE), Relative Translation Error (RTE), and Relative Rotation Error (RRE) achieved by several different methods. The best performing method for each error metric on each dataset is highlighted in bold, with the second best underlined. This allows for a direct comparison of the accuracy and robustness of various approaches in estimating camera poses within diverse and challenging dynamic scenes.
read the caption
Table 3: Quantitative Comparisons of Camera Pose Estimation on the DyCheck, ADT and TUM-dynamics datasets. The best and second best results are bold and underlined, respectively.
| DyCheck | ADT | TUM-dynamics | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Method | Flow | ATE | RTE | RRE | ATE | RTE | RRE | ATE | RTE | RRE |
| DUSt3R [64] | ✗ | 0.035 | 0.030 | 2.323 | 0.042 | 0.025 | 1.212 | 0.100 | 0.087 | 2.692 |
| Easi3R | ✗ | 0.029 | 0.025 | 1.774 | 0.040 | 0.021 | 0.880 | 0.093 | 0.076 | 2.366 |
| DUSt3R [64] | ✓ | 0.029 | 0.021 | 1.875 | 0.076 | 0.030 | 0.974 | 0.071 | 0.067 | 3.711 |
| Easi3R | ✓ | 0.021 | 0.014 | 1.092 | 0.042 | 0.015 | 0.655 | 0.070 | 0.061 | 2.361 |
| MonST3R [73] | ✗ | 0.040 | 0.034 | 1.820 | 0.045 | 0.024 | 0.759 | 0.183 | 0.148 | 6.985 |
| Easi3R | ✗ | 0.038 | 0.032 | 1.736 | 0.045 | 0.024 | 0.715 | 0.184 | 0.149 | 6.311 |
| MonST3R [73] | ✓ | 0.033 | 0.024 | 1.501 | 0.055 | 0.025 | 0.776 | 0.170 | 0.155 | 6.455 |
| Easi3R | ✓ | 0.030 | 0.021 | 1.390 | 0.039 | 0.016 | 0.640 | 0.168 | 0.150 | 5.925 |
🔼 This table presents a quantitative comparison of point cloud reconstruction results on the DyCheck dataset. It shows the performance of different methods, including the baseline DUSt3R and MonST3R, as well as the proposed Easi3R method using both DUSt3R and MonST3R as backbones. The metrics used are Accuracy, Completeness, and Distance, reflecting the quality of the reconstructed point cloud. The best and second-best results for each metric are highlighted. This allows for an evaluation of how effectively each method reconstructs the 3D point cloud from the input data, especially in the context of handling dynamic scenes.
read the caption
Table 4: Benefits of Easi3R on Point Cloud Reconstruction on the DyCheck dataset. The best and second best results are bold and underlined, respectively. Easi3R dust3r/monst3rdust3r/monst3r{}_{\text{dust3r/monst3r}}start_FLOATSUBSCRIPT dust3r/monst3r end_FLOATSUBSCRIPT denotes the Easi3R experiment with the backbones of MonST3R/DUSt3R.
| DyCheck | ADT | TUM-dynamics | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Method | Flow | ATE | RTE | RRE | ATE | RTE | RRE | ATE | RTE | RRE |
| DUSt3R [64] | ✗ | 0.035 | 0.030 | 2.323 | 0.042 | 0.025 | 1.212 | 0.100 | 0.087 | 2.692 |
| CUT3R [63] | ✗ | 0.029 | 0.020 | 1.383 | 0.084 | 0.025 | 0.490 | 0.079 | 0.088 | 10.41 |
| MonST3R [73] | ✓ | 0.033 | 0.024 | 1.501 | 0.055 | 0.025 | 0.776 | 0.170 | 0.155 | 6.455 |
| DAS3R [68] | ✓ | 0.033 | 0.022 | 1.467 | 0.040 | 0.017 | 0.685 | 0.173 | 0.157 | 8.341 |
| Easi3R | ✓ | 0.030 | 0.021 | 1.390 | 0.039 | 0.016 | 0.640 | 0.168 | 0.150 | 5.925 |
| Easi3R | ✓ | 0.021 | 0.014 | 1.092 | 0.042 | 0.015 | 0.655 | 0.070 | 0.061 | 2.361 |
🔼 This table presents a quantitative comparison of point cloud reconstruction results on the DyCheck dataset. Several methods are compared, including DUSt3R, MonST3R, DAS3R, and the proposed Easi3R method, with and without the use of optical flow. The metrics used to evaluate performance are Accuracy, Completeness, and Distance. For each method, the mean and median values of these metrics are reported. The best and second-best results for each metric are highlighted in bold and underlined, respectively, allowing for easy identification of top-performing methods.
read the caption
Table 5: Quantitative Comparisons of Point Cloud Reconstruction on the DyCheck dataset. The best and second best results are bold and underlined, respectively.
| Accuracy | Completeness | Distance | |||||
|---|---|---|---|---|---|---|---|
| Method | Flow | Mean | Median | Mean | Median | Mean | Median |
| DUSt3R [64] | ✗ | 0.802 | 0.595 | 1.950 | 0.815 | 0.353 | 0.233 |
| Easi3R | ✗ | 0.772 | 0.596 | 1.813 | 0.757 | 0.336 | 0.219 |
| DUSt3R [64] | ✓ | 0.738 | 0.599 | 1.669 | 0.678 | 0.313 | 0.196 |
| Easi3R | ✓ | 0.703 | 0.589 | 1.474 | 0.586 | 0.301 | 0.186 |
| MonST3R [73] | ✗ | 0.855 | 0.693 | 1.916 | 1.035 | 0.398 | 0.295 |
| Easi3R | ✗ | 0.846 | 0.660 | 1.840 | 0.983 | 0.390 | 0.290 |
| MonST3R [73] | ✓ | 0.851 | 0.689 | 1.734 | 0.958 | 0.353 | 0.254 |
| Easi3R | ✓ | 0.834 | 0.643 | 1.661 | 0.916 | 0.350 | 0.255 |
🔼 This table presents the results of an ablation study on the dynamic object segmentation task using the DAVIS dataset. It shows the impact of removing different components of the proposed Easi3R method on the final performance, measured by the Jaccard Index (JM) and Recall (JR). The components investigated include individual attention maps (Aa=src, A=src, Aa=ref, A=ref), the feature clustering process, and all features combined. The ablation is conducted on the DUSt3R and MonST3R backbones separately to assess their individual contribution and robustness.
read the caption
Table 6: Ablation of Dynamic Object Segmentation on DAVIS.
| Accuracy | Completeness | Distance | |||||
|---|---|---|---|---|---|---|---|
| Method | Flow | Mean | Median | Mean | Median | Mean | Median |
| DUSt3R [64] | ✗ | 0.802 | 0.595 | 1.950 | 0.815 | 0.353 | 0.233 |
| CUT3R [63] | ✗ | 0.458 | 0.342 | 1.633 | 0.792 | 0.326 | 0.229 |
| MonST3R [73] | ✓ | 0.851 | 0.689 | 1.734 | 0.958 | 0.353 | 0.254 |
| DAS3R [68] | ✓ | 1.772 | 1.438 | 2.503 | 1.548 | 0.475 | 0.352 |
| Easi3R | ✓ | 0.834 | 0.643 | 1.661 | 0.916 | 0.350 | 0.255 |
| Easi3R | ✓ | 0.703 | 0.589 | 1.474 | 0.586 | 0.301 | 0.186 |
🔼 This table presents the results of ablation studies conducted on the DyCheck dataset to analyze the impact of different design choices on camera pose estimation and point cloud reconstruction. It examines the effects of applying attention re-weighting to either only the reference view decoder or both the reference and source decoders, and the influence of incorporating global alignment using optical flow with and without dynamic object segmentation. The metrics used for evaluation include Absolute Translation Error (ATE), Relative Translation Error (RTE), Relative Rotation Error (RRE), Accuracy, Completeness, and Distance.
read the caption
Table 7: Ablation Study of Camera Pose Estimation and Point Cloud Reconstruction on the DyCheck dataset.
Full paper#