↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Existing code completion benchmarks usually focus on a limited number of languages and lack fine-grained analysis, hindering the evaluation of code LLMs’ abilities across different languages and scenarios. This significantly limits the advancement of multilingual code intelligence.
To address these issues, this paper introduces M2RC-EVAL, a massively multilingual repository-level code completion benchmark covering 18 programming languages. It offers fine-grained annotations (bucket-level and semantic-level) for various completion scenarios, allowing for a more detailed performance analysis. Furthermore, it introduces M2RC-INSTRUCT, a large-scale multilingual instruction dataset, to improve the performance of code LLMs.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in code intelligence and software engineering because it introduces a massively multilingual benchmark for evaluating code completion models, addressing the limitations of existing benchmarks. It also provides a large-scale instruction dataset to further improve the models. This work will significantly advance the field by facilitating more comprehensive and robust evaluations of code LLMs across multiple languages and settings.
Visual Insights#

🔼 Figure 1 illustrates the M2RC-Eval benchmark, a multilingual repository-level code completion evaluation dataset. It showcases examples in three languages (Python, Java, and TypeScript) to highlight the data structure. Each example shows the code snippet, the ‘in-file’ context (from the same file), and the ‘cross-file’ context (from other files in the same repository). The task for large language models (LLMs) is to predict the missing code indicated by the
<INFILLING>placeholder. Annotations for bucket-level (complexity) and semantic-level (code type) are also provided at the code completion point to aid in fine-grained analysis.read the caption
Figure 1: Overview of our proposed M2rc-Eval with 18 languages. Specifically, first, we provide three samples from different languages (i.e., Python, Java, TypeScript) for illustration, where the bucket label and semantic label for the corresponding cursor position are provided. Second, the code LLMs need to predict the completion results given the in-file context from the current code file and the cross file context retrieved from other code files in the current repository. Note that “expectationINFILLING<\mathrm{INFILLING}>< roman_INFILLING >” denotes that the current position will be triggered for code completion.
| Benchmark | # Languages | Fine-grained | Training Set | # Test Repos |
|---|---|---|---|---|
| RepoBench (Liu et al., 2023a) | 2 | ✗ | ✓ | 1669 |
| CrossCodeEval (Ding et al., 2024) | 4 | ✗ | ✗ | 1002 |
| R2C2-Bench (Deng et al., 2024) | 4 | ✗ | ✓ | 1353 |
| M2rc-Eval & M2rc-Instruct | 18 | ✓ | ✓ | 5993 |
🔼 This table compares the M²RC-EVAL benchmark dataset with other existing notable repository-level code completion datasets. It shows the number of programming languages supported, whether fine-grained annotations are included, the presence of a training set, and the number of test repositories used in each dataset. This allows for a quantitative comparison of dataset scale and annotation detail, highlighting the unique features and improvements of M²RC-EVAL.
read the caption
Table 1: A comparison with existing notable repository-level code completion datasets.
In-depth insights#
Multilingual Code Eval#
The Multilingual Code Eval section delves into a novel benchmark dataset called M2RC-EVAL, designed to assess the multilingual code intelligence capabilities of Large Language Models (LLMs). Unlike previous benchmarks limited to a few programming languages, M2RC-EVAL supports 18 languages, enabling a comprehensive evaluation of LLMs across diverse linguistic contexts. The dataset incorporates two types of fine-grained annotations: bucket-level (based on abstract syntax tree depth) and semantic-level (categorizing code semantics), providing a nuanced understanding of LLM performance across various code completion scenarios. Furthermore, the authors introduce a companion dataset, M2RC-INSTRUCT, a multilingual instruction corpus aimed at enhancing the performance of LLMs in repository-level code completion tasks. The combined M2RC-EVAL and M2RC-INSTRUCT datasets offer a significant advancement for evaluating and improving multilingual code intelligence in LLMs.
Fine-Grained Annotation#
The heading ‘Fine-grained Annotation’ details the two levels of annotations used to enrich the M2RC-EVAL benchmark: bucket-level and semantic-level. Bucket-level annotation divides the Abstract Syntax Tree (AST) into fixed-size buckets, assigning labels based on the node’s layer. This provides a nuanced view of completion difficulty across different code structures. Semantic-level annotation focuses on the meaning of the code by assigning pre-defined semantic labels (e.g., Program Structure, Expression) to the code snippets. This granular approach reveals code LLM performance across various coding scenarios. The combined annotation strategy, based on parsed ASTs, significantly enhances the evaluation by moving beyond simple average scores to a more detailed analysis of strengths and weaknesses across various programming languages and code complexities.
Instruction Corpora#
The research paper introduces M²RC-INSTRUCT, a new massively multilingual instruction corpora designed to significantly boost the performance of repository-level code completion models. This dataset, comprising code snippets from 18 programming languages, serves as a valuable training resource for these models. Its creation involved a rigorous process of data collection, filtering, and annotation, aiming for high-quality and diverse examples. The emphasis on multilingualism and detailed annotations (including bucket-level and semantic-level labels generated from the abstract syntax tree) allows for granular evaluation of model performance across languages and specific code contexts. M²RC-INSTRUCT’s effectiveness is empirically validated in the paper’s experimental results, showcasing the positive impact on various code completion models. The inclusion of M²RC-INSTRUCT highlights a significant advancement in creating more comprehensive and effective training resources for advanced code generation tasks, which may contribute to future improvements in the field of code intelligence and automated software development.
Model Size Analysis#
The Model Size Analysis section investigates the performance of different sized models, specifically comparing StarCoder-7B and StarCoder-3B. StarCoder-7B consistently outperforms StarCoder-3B under standard conditions, highlighting the general advantage of larger models. However, a significant finding emerges after fine-tuning both models with the M2RC-INSTRUCT dataset. Post fine-tuning, StarCoder-3B surpasses the performance of the non-finetuned StarCoder-7B. This suggests that M2RC-INSTRUCT’s effectiveness lies in boosting the capabilities of smaller models, potentially making them more resource-efficient alternatives for repository-level code completion tasks. The results underscore the value of high-quality instruction datasets in enhancing the performance of code LLMs, particularly for smaller models which may be more practical for deployment scenarios with limited computational resources.
Cross-lingual Transfer#
The section on “Cross-lingual Transfer” investigates the model’s ability to generalize knowledge acquired from one language to others. A key experiment fine-tunes the StarCoder-7B model using only Python data, then evaluates its performance across 18 languages within the M²RC-EVAL benchmark. The results reveal a surprising level of cross-lingual transfer, achieving performance close to that obtained when training with data from all 18 languages. This suggests a strong inherent proficiency in coding within the base model, despite limitations in explicit instruction-following. The findings highlight the potential for efficient multilingual code generation, indicating that pre-training on a single, well-represented language can provide significant transfer learning benefits for other languages, reducing the need for extensive multilingual training data. This is particularly important given the scarcity of large, high-quality multilingual code datasets.
More visual insights#
More on figures

🔼 This figure illustrates the process of generating code completion cursor positions and their corresponding fine-grained annotations within the M2RC-EVAL benchmark. First, the source code is parsed into an Abstract Syntax Tree (AST). Then, a node within the AST is randomly selected to represent the code completion cursor position. The bucket label is determined by the node’s level or depth within the AST’s tree structure. Finally, the semantic label is assigned based on the node type identified by the Tree-sitter parser, categorizing the code snippet’s function (e.g., declaration, expression, statement, etc.).
read the caption
Figure 2: Illustration on generating completion cursor position and fine-grained annotations. Specifically, we first parse the source code into an abstract syntax tree (AST). Then, we choose one node as the completion cursor position and generate the bucket label based on the belonged layer number in AST, and obtain the semantic label based on the node type parsed by the Tree-sitter.

🔼 Figure 3 presents a bar chart visualizing the average lengths of prompts and code completions, along with the number of cross-file dependencies, observed in the M2RC-Eval testing dataset. The ‘prompt length’ represents the average number of tokens used to solicit a code completion. ‘Completion span length’ refers to the average length of the code segment that needs to be predicted, also measured in tokens. Finally, ‘cross-file dependencies’ reflects the average number of external files, explicitly or implicitly linked to the current file, within the repository. This data offers insight into the complexity of code completion tasks within the M2RC-Eval benchmark.
read the caption
Figure 3: The average prompt length (100x tokens), completion span length (50x tokens), and cross-file dependencies (1x) in the testing set of M2rc-Eval. We define the number of other files, which are explicitly imported and implicitly referenced by the current file, as cross-file dependencies.

🔼 This figure shows the semantic-level annotations on Java code. The figure is a pie chart that visually represents the distribution of different semantic labels in Java code samples within the M2RC-EVAL benchmark. Each slice of the pie chart corresponds to one of eleven major semantic labels (Program Structure, Declaration and Definition, etc.), and the size of each slice reflects the proportion of code instances that fall into that semantic category. This provides a fine-grained analysis of the code completion scenarios in Java within the benchmark.
read the caption
(a) Java

🔼 The figure shows a pie chart visualizing the distribution of semantic-level annotations for the Go programming language in the M2RC-EVAL benchmark. Each slice of the pie chart represents a specific semantic label (e.g., Program Structure, Statement, Expression, etc.), and the size of each slice corresponds to the proportion of code completion instances in the dataset that were assigned that particular semantic label. This provides insights into the relative frequency of different semantic categories within Go code, allowing for analysis of the distribution of code completion scenarios across the programming language.
read the caption
(b) Go

🔼 This figure shows the semantic-level annotations on Scala code. Specifically, it’s a pie chart illustrating the distribution of different semantic labels (e.g., Program Structure, Declaration and Definition, Control Flow Structure, etc.) assigned to various code completion cursor positions within Scala code samples in the M2RC-EVAL benchmark. The chart visually represents the proportion of each semantic label found in the dataset, offering insights into the frequency and diversity of code completion scenarios within Scala.
read the caption
(c) Scala

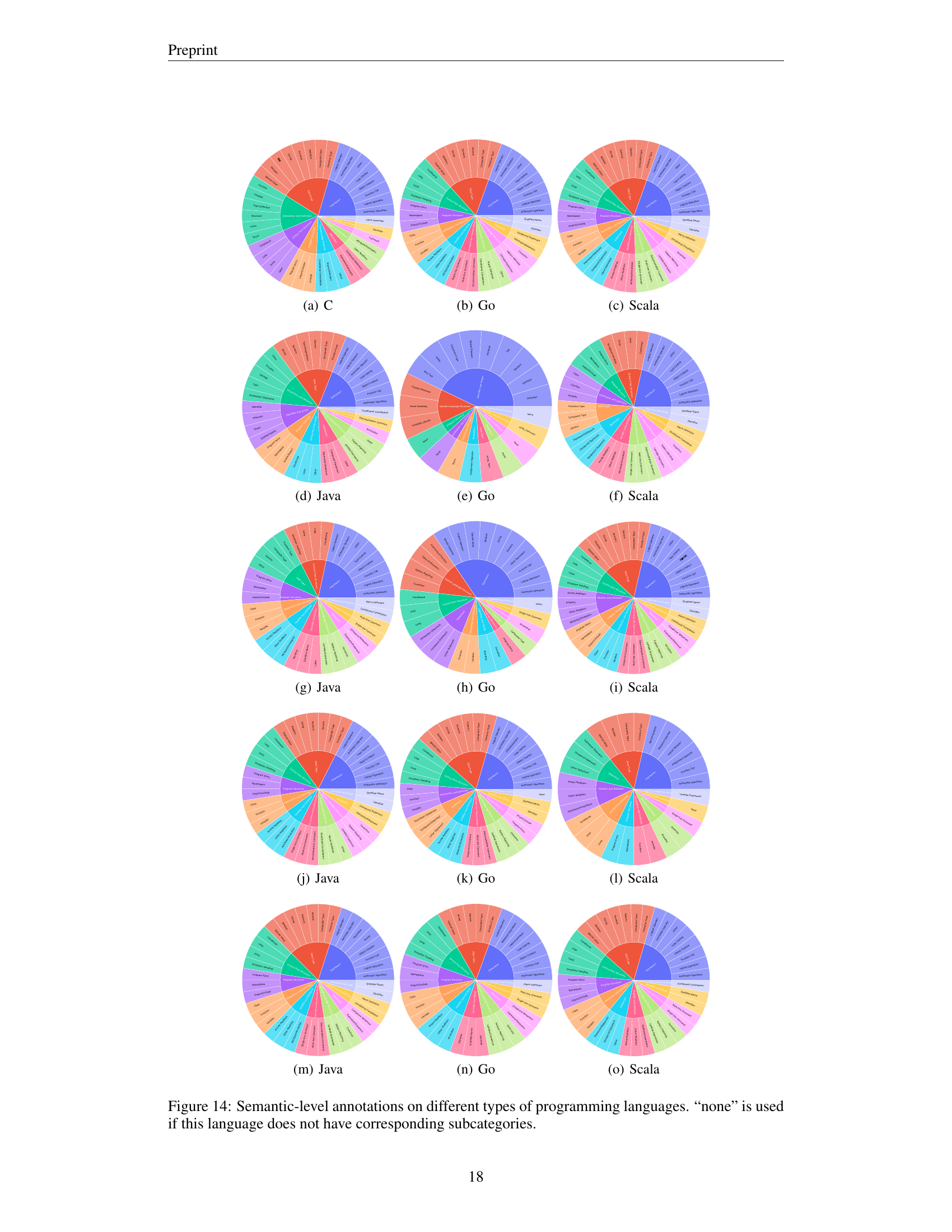
🔼 This figure shows a comparison of the semantic-level annotations for three different programming languages: Java, Go, and Scala. Each pie chart represents a language and shows the distribution of different semantic labels used to annotate code completion scenarios. The semantic labels represent different code elements and structures such as program structure, declarations, control flow, expressions, data types, statements, and identifiers. The detailed breakdown of semantic label proportions allows for a granular analysis of how different languages are annotated and how this might impact the performance of different code LLMs on those respective languages.
read the caption
Figure 4: Semantic-level annotations on different types of programming languages.

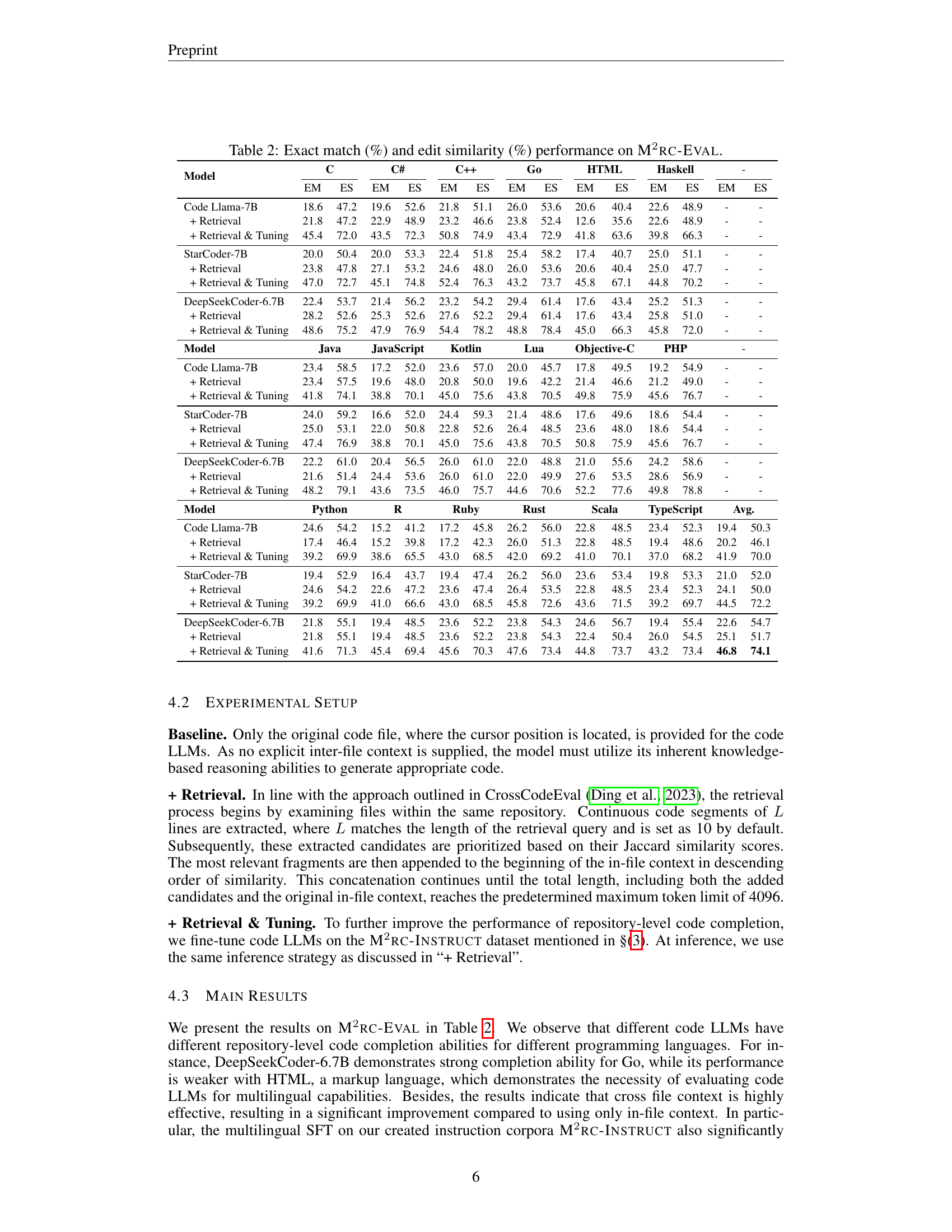
🔼 This figure shows the impact of varying training data sizes on the performance of different code LLMs on the M²RC-EVAL benchmark. The x-axis represents the size of the training dataset, and the y-axis represents the evaluation scores (Exact Match and Edit Similarity). The different lines in the graph represent various code LLMs (StarCoder-7B, DeepSeekCoder-6.7B, and Code Llama-7B), both with and without the retrieval and fine-tuning steps. The figure illustrates how increasing the training data size generally improves performance across all models, highlighting the relationship between data size and model performance in multilingual repository-level code completion.
read the caption
Figure 5: Effectiveness of using different training data sizes.

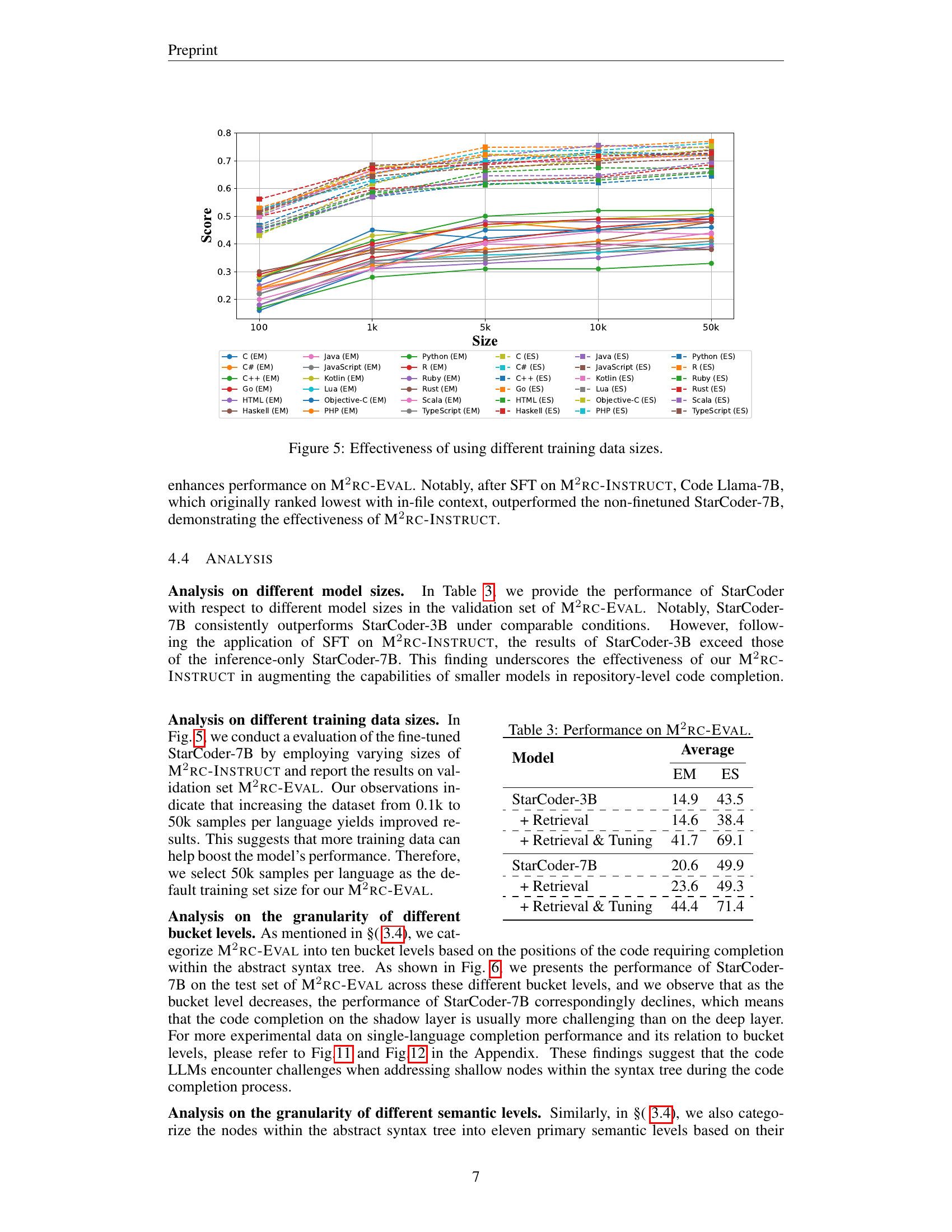
🔼 This figure analyzes the performance of the StarCoder-7B model on code completion tasks across various bucket levels. The bucket level represents the depth of a node within an abstract syntax tree (AST), indicating the complexity of the code completion scenario. Each level shows the EM and ES scores for both Retrieval and Retrieval & Tuning methods. The graph helps understand how model performance correlates with code complexity; lower bucket levels (representing more complex code) generally exhibit lower performance scores. The graph demonstrates that StarCoder-7B’s accuracy decreases as the code’s structural complexity increases.
read the caption
Figure 6: Effectiveness of different bucket levels based on StarCoder-7B.

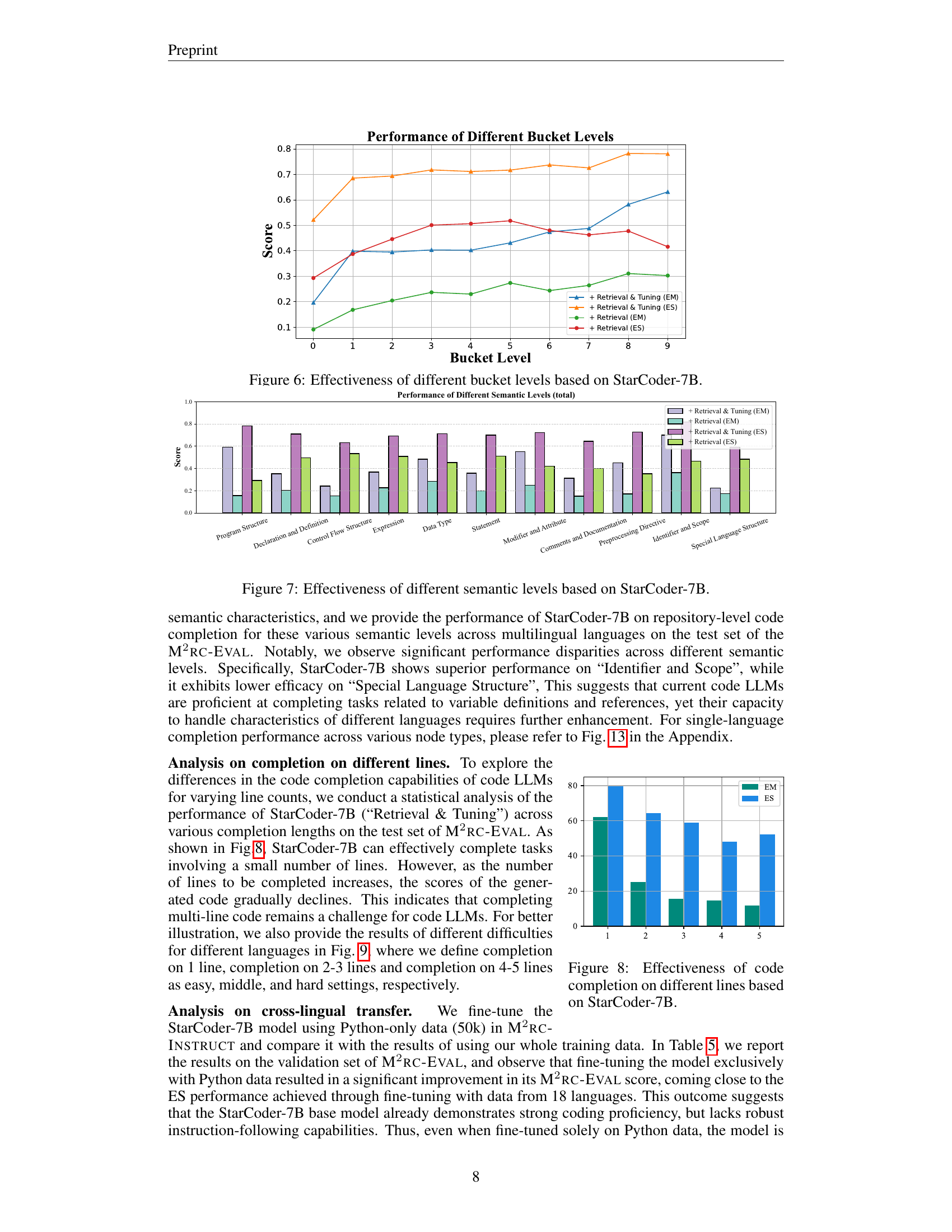
🔼 This figure analyzes the performance of StarCoder-7B, a code generation model, across different semantic levels in code completion tasks. It displays the model’s accuracy (EM and ES) for various semantic labels, such as Program Structure, Declaration and Definition, Control Flow Structure, etc. The graph allows for a granular understanding of the model’s strengths and weaknesses in different aspects of code comprehension and generation, highlighting semantic areas where the model excels and areas needing improvement.
read the caption
Figure 7: Effectiveness of different semantic levels based on StarCoder-7B.

🔼 This figure shows the performance of the StarCoder-7B model on code completion tasks with varying numbers of lines. It demonstrates how the model’s accuracy changes as the length of the code to be completed increases. The x-axis represents the number of lines, and the y-axis represents the evaluation score (likely a metric like exact match or edit similarity). The results illustrate the challenges faced by the model as the completion task becomes more complex, involving multiple lines of code.
read the caption
Figure 8: Effectiveness of code completion on different lines based on StarCoder-7B.

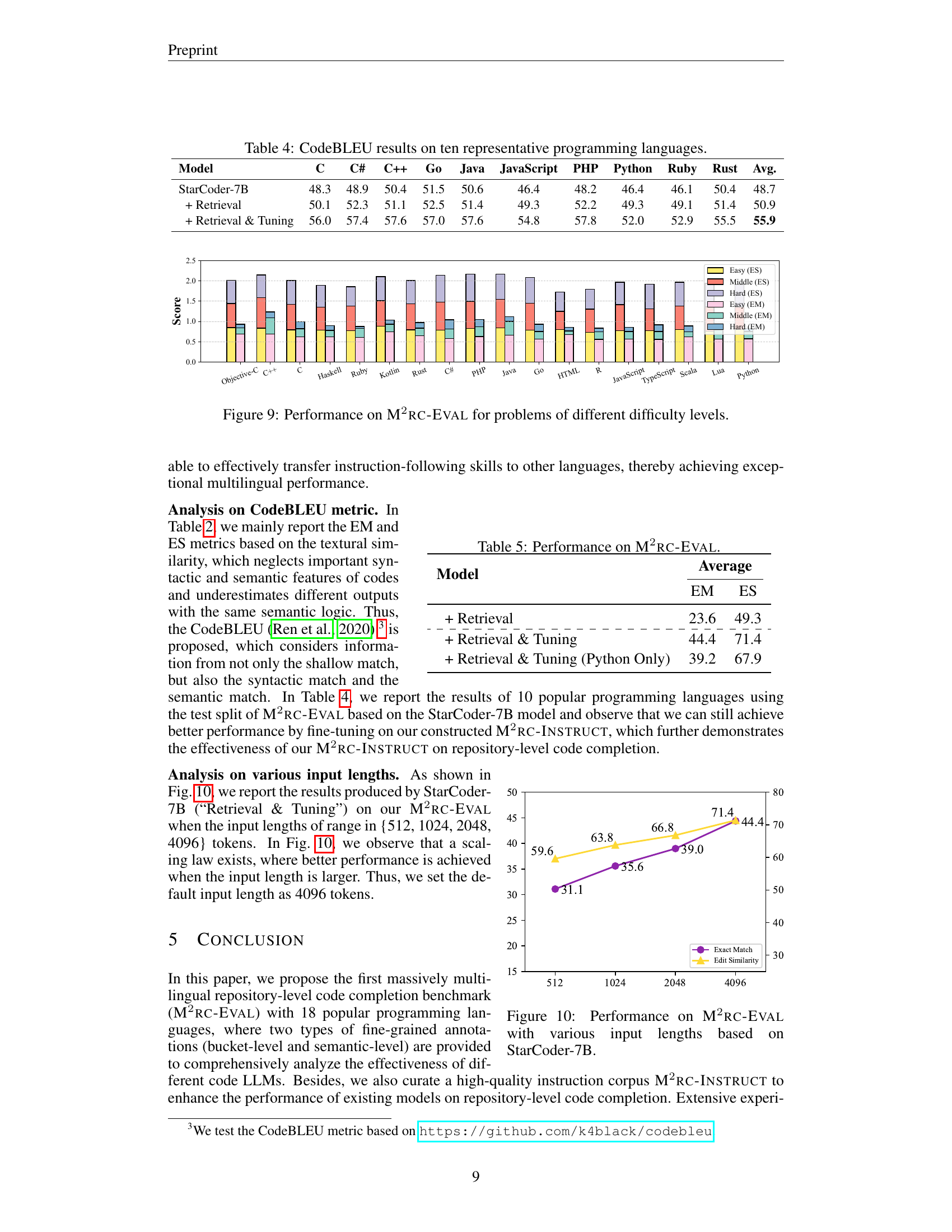
🔼 This figure presents a bar chart illustrating the performance of different code LLMs on the M2RC-Eval benchmark, categorized by the difficulty level of the problems. The x-axis displays various programming languages, while the y-axis represents the evaluation scores. Three difficulty levels are considered: easy, medium, and hard. Each bar represents the performance of a specific model on a particular programming language and difficulty level, enabling a comprehensive comparison of model capabilities across different languages and problem complexities.
read the caption
Figure 9: Performance on M2rc-Eval for problems of different difficulty levels.

🔼 This figure shows the performance of the StarCoder-7B model on the M2RC-Eval benchmark across different input lengths. The x-axis represents the input length in tokens (512, 1024, 2048, 4096), while the y-axis represents the performance scores (Exact Match and Edit Similarity). The graph illustrates a scaling law, where longer input sequences generally lead to better performance. This suggests that providing more context to the model improves its ability to generate accurate code completions.
read the caption
Figure 10: Performance on M2rc-Eval with various input lengths based on StarCoder-7B.

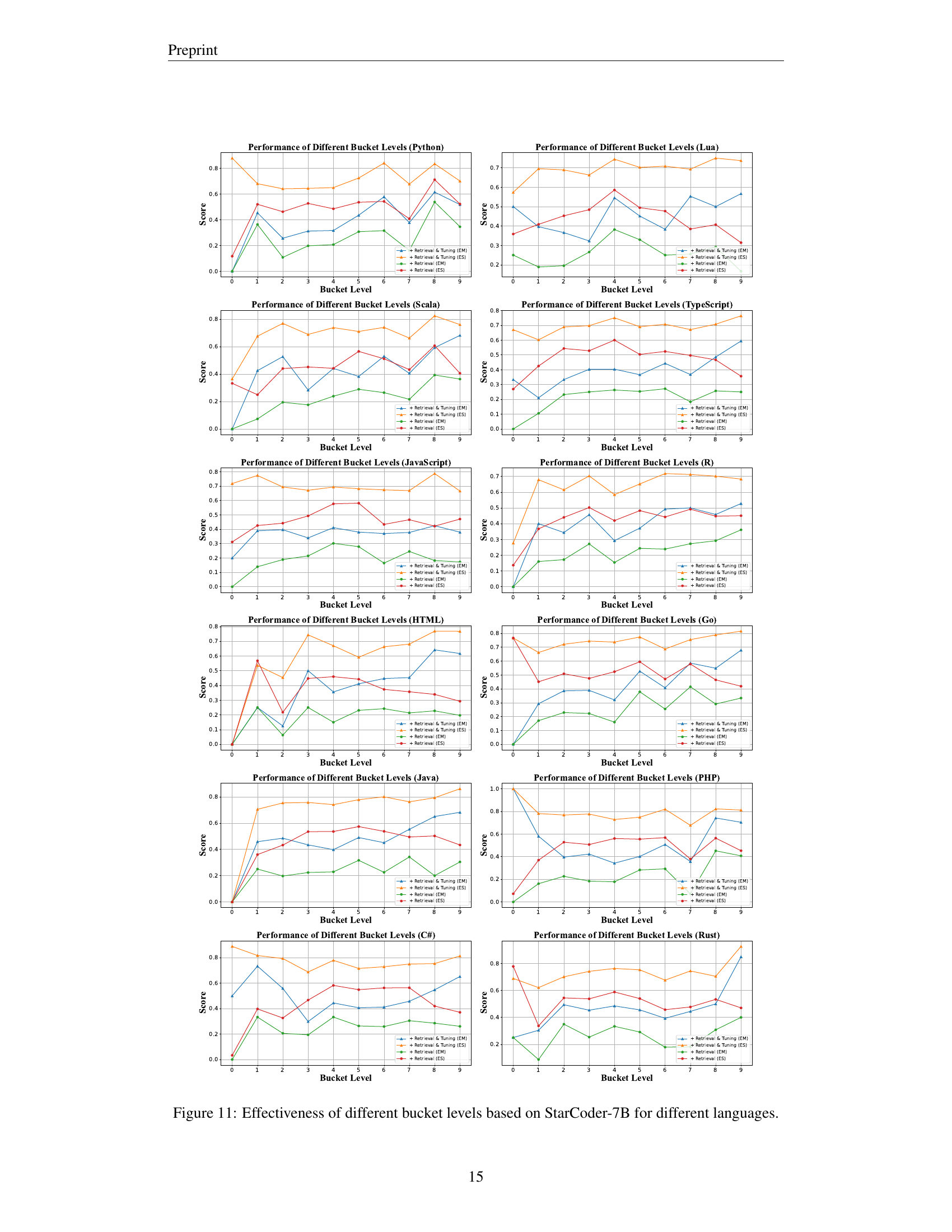
🔼 This figure presents a detailed analysis of the performance of StarCoder-7B across various bucket levels for 18 different programming languages. Bucket levels represent the depth within the abstract syntax tree, providing a measure of code complexity. The results are shown for both exact match (EM) and edit similarity (ES) metrics, demonstrating how the model’s performance varies based on the complexity of the completion context. The figure allows for a granular understanding of the model’s abilities within different code structures, enabling a deeper assessment of strengths and weaknesses.
read the caption
Figure 11: Effectiveness of different bucket levels based on StarCoder-7B for different languages.

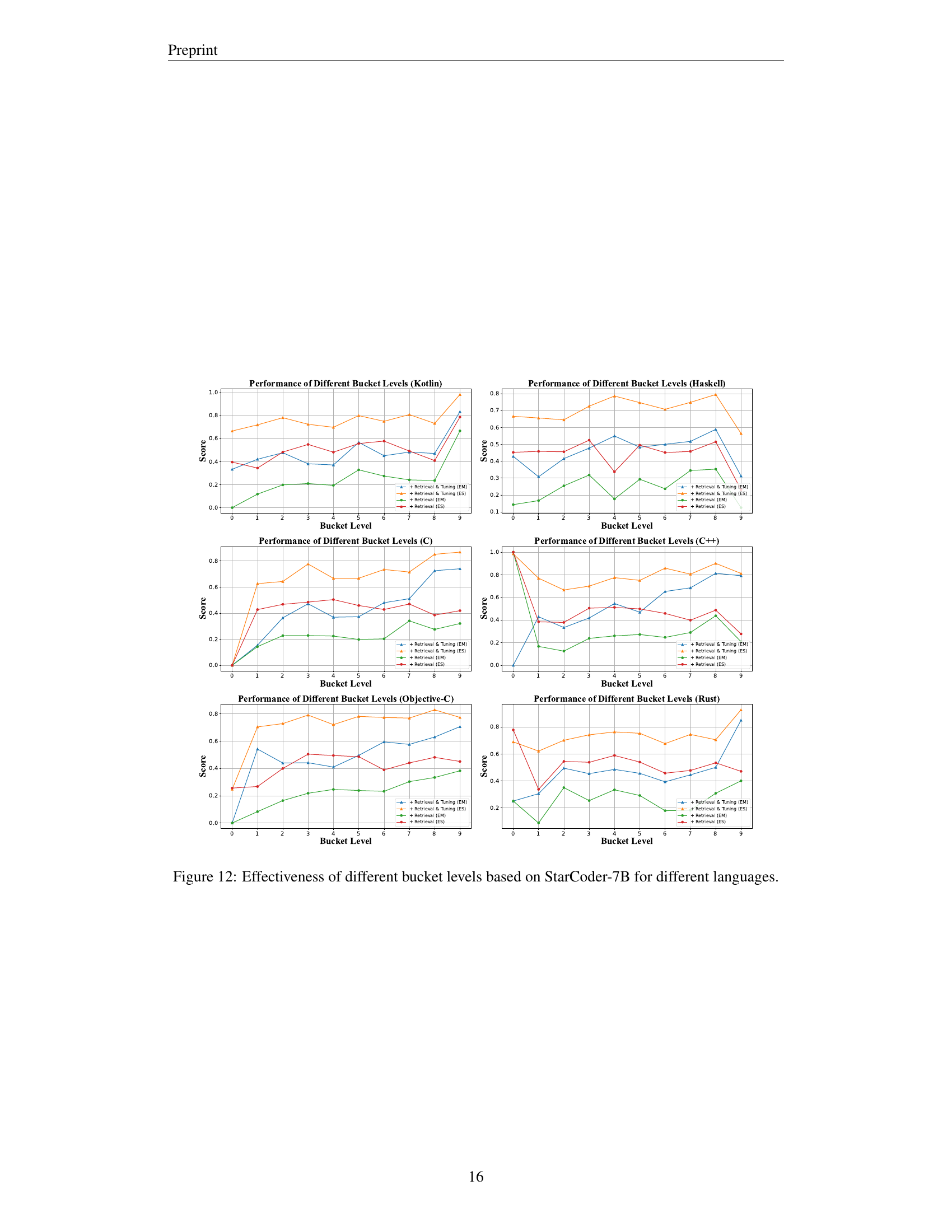
🔼 This figure presents a detailed analysis of the effectiveness of different bucket levels in the M2RC-EVAL benchmark using the StarCoder-7B model. It displays performance metrics across various programming languages (Kotlin, Haskell, C, C++, Objective-C, and Rust) for each bucket level. Each language’s performance is evaluated against the different bucket levels of the abstract syntax tree (AST), allowing for a nuanced comparison of how the model handles different levels of code complexity. The results are presented in graphs that show the exact match (EM) and edit similarity (ES) scores for each language and bucket level, revealing potential strengths and weaknesses of the model at different levels of the AST.
read the caption
Figure 12: Effectiveness of different bucket levels based on StarCoder-7B for different languages.

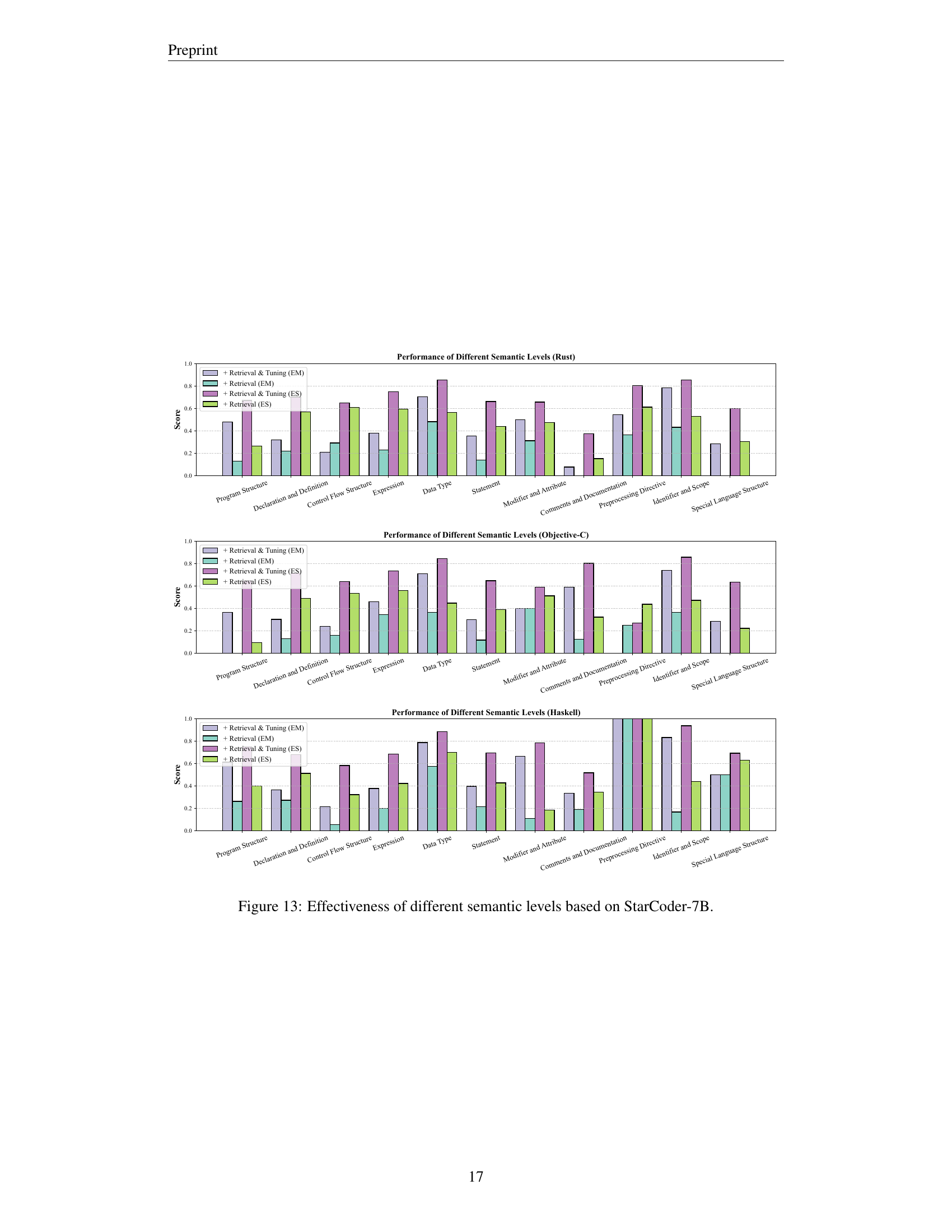
🔼 This figure presents a detailed analysis of StarCoder-7B’s performance across various semantic levels in code completion tasks. It breaks down the model’s accuracy (EM and ES) for different semantic categories, such as Program Structure, Declaration and Definition, Control Flow, Expressions, Data Types, and more. The visualization helps to understand the model’s strengths and weaknesses in handling various code constructs and complexities, showing where it excels and where it struggles. The granularity of the results provides insights into which aspects of code understanding are more or less challenging for the model, revealing subtle differences in performance across these semantic levels.
read the caption
Figure 13: Effectiveness of different semantic levels based on StarCoder-7B.

🔼 This figure shows a pie chart visualizing the distribution of semantic labels in the C programming language within the M²RC-EVAL benchmark. Each slice of the pie chart represents a different semantic label, with its size corresponding to the proportion of code snippets in the dataset that are annotated with that specific label. The semantic labels provide a fine-grained annotation for the various types of code completion scenarios present in the dataset. The visualization helps in understanding the relative frequencies of different code semantic patterns in the benchmark, which can be useful for evaluating the performance of code language models on different aspects of code completion tasks.
read the caption
(a) C

🔼 This figure shows a pie chart visualizing the distribution of semantic-level annotations for the Go programming language in the M2RC-EVAL benchmark. Each slice of the pie represents a different semantic label (e.g., Program Structure, Declaration and Definition, Control Flow Structure, etc.), and the size of the slice corresponds to the proportion of code completion samples in the dataset that belong to that particular semantic label. This provides a fine-grained view of the types of code completion scenarios covered by the benchmark for Go.
read the caption
(b) Go

🔼 This figure shows the semantic-level annotations on the Scala programming language. The pie chart visually represents the distribution of different semantic labels within the Scala codebase. Each slice of the pie chart corresponds to a specific semantic label, such as Program Structure, Declaration and Definition, Control Flow Structure, etc., reflecting the relative frequency of each semantic category in the code examples. This granular level of detail provides insight into the types of code completion scenarios present in the dataset and helps in evaluating the performance of different models in various code completion contexts.
read the caption
(c) Scala

🔼 This figure shows one of the example code snippets used in the M2RC-EVAL benchmark. Specifically, it demonstrates a code completion scenario in Java. The image highlights the ‘in-file context’ (the surrounding code within the current file), ‘cross-file context’ (code snippets from other files in the project), the location of the ‘cursor position’ where code completion is needed, and the associated ‘bucket label’ and ‘semantic label’ indicating the type of code completion task and its complexity level.
read the caption
(d) Java

🔼 The figure shows the distribution of semantic-level annotations for the Go programming language in the M2RC-EVAL benchmark. It’s a pie chart that visually represents the proportion of different semantic labels assigned to code completion points within Go code samples. Each slice of the pie corresponds to a specific semantic label (e.g., Program Structure, Declaration and Definition, Control Flow Structure, etc.), and the size of each slice indicates the relative frequency of that label in the dataset. This helps illustrate the variety of code completion scenarios present in the benchmark for Go and provides a nuanced understanding of the dataset’s composition.
read the caption
(e) Go

🔼 This figure shows a pie chart that visually represents the distribution of semantic-level annotations for Scala code in the M²RC-EVAL benchmark. Each slice of the pie chart corresponds to one of the 11 pre-defined semantic labels (e.g., Program Structure, Declaration and Definition, etc.). The size of each slice is proportional to the frequency of that specific semantic label in the Scala code samples. This visualization helps illustrate the relative prevalence of different code semantic categories within the Scala portion of the benchmark dataset. The figure provides valuable insights into the types of code completion tasks that are prevalent in the Scala subset of M²RC-EVAL.
read the caption
(f) Scala

🔼 This figure shows the semantic-level annotations on Java code in the M²RC-EVAL benchmark. The pie chart visually represents the distribution of different semantic labels assigned to code completion points within Java code samples. Each slice corresponds to a specific semantic category (e.g., Program Structure, Statement, Expression, etc.), and its size reflects the proportion of that category within the dataset. This provides a fine-grained view of code completion scenarios in Java, highlighting the diversity of semantic contexts the model needs to handle.
read the caption
(g) Java

🔼 This figure shows the distribution of semantic labels in Go code within the M2RC-EVAL benchmark. The pie chart visually represents the proportion of various semantic labels (e.g., Program Structure, Declaration and Definition, etc.) found in the Go code snippets used for the code completion task. This provides insights into the relative frequency of different semantic patterns in the dataset.
read the caption
(h) Go

🔼 This figure shows the distribution of semantic labels in Scala code snippets within the M²RC-EVAL benchmark. It provides a detailed breakdown of the frequency of different semantic categories (e.g., Program Structure, Declaration and Definition, Control Flow Structure, etc.) found in the code samples. The pie chart visually represents the proportion of each semantic label, offering insights into the types of code constructs prevalent in the Scala portion of the dataset. This granular analysis helps to understand the characteristics of the dataset and its suitability for evaluating different aspects of code language models.
read the caption
(i) Scala

🔼 This figure shows a pie chart visualizing the distribution of semantic labels in Java code snippets within the M2RC-EVAL benchmark. Each slice represents a different semantic category (e.g., Program Structure, Declaration and Definition, etc.) and its size is proportional to the frequency of that category in the dataset. This provides a granular view of the code completion scenarios captured in the benchmark for Java.
read the caption
(j) Java

🔼 This figure shows a pie chart visualizing the distribution of semantic-level annotations for the Go programming language in the M²RC-EVAL benchmark. Each slice of the pie chart represents a different semantic label, such as Program Structure, Declaration and Definition, Control Flow, etc., showing the proportion of code completion instances categorized under each label. This provides insights into the distribution of different code completion scenarios within the Go language samples of the dataset.
read the caption
(k) Go

🔼 This figure shows a pie chart visualizing the distribution of semantic-level annotations for Scala code in the M2RC-EVAL benchmark. Each slice represents a different semantic label assigned to code completion points, indicating the frequency of each code semantic type within the dataset. The semantic labels categorize the type of code element being completed, offering insights into the various code contexts within the Scala programming language included in the dataset.
read the caption
(l) Scala

🔼 This figure shows a pie chart visualizing the distribution of semantic-level annotations for the Java programming language in the M²RC-EVAL benchmark. Each slice represents a different semantic label (e.g., Program Structure, Declaration and Definition, Control Flow Structure, Expression, etc.), with the size of each slice proportional to the frequency of that label in the Java code samples.
read the caption
(m) Java
More on tables
| Model | C EM | C ES | C# EM | C# ES | C++ EM | C++ ES | Go EM | Go ES | HTML EM | HTML ES | Haskell EM | Haskell ES | Java EM | Java ES | JavaScript EM | JavaScript ES | Kotlin EM | Kotlin ES | Lua EM | Lua ES | Objective-C EM | Objective-C ES | PHP EM | PHP ES | Python EM | Python ES | R EM | R ES | Ruby EM | Ruby ES | Rust EM | Rust ES | Scala EM | Scala ES | TypeScript EM | TypeScript ES | Avg. EM | Avg. ES | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Code Llama-7B | 18.6 | 47.2 | 19.6 | 52.6 | 21.8 | 51.1 | 26.0 | 53.6 | 20.6 | 40.4 | 22.6 | 48.9 | - | - | 23.4 | 58.5 | 17.2 | 52.0 | 23.6 | 57.0 | 20.0 | 45.7 | 17.8 | 49.5 | 19.2 | 54.9 | 24.6 | 54.2 | 15.2 | 41.2 | 17.2 | 45.8 | 26.2 | 56.0 | 22.8 | 48.5 | 23.4 | 52.3 | 19.4 | 50.3 | ||||
| + Retrieval | 21.8 | 47.2 | 22.9 | 48.9 | 23.2 | 46.6 | 23.8 | 52.4 | 12.6 | 35.6 | 22.6 | 48.9 | - | - | 23.4 | 57.5 | 19.6 | 48.0 | 20.8 | 50.0 | 19.6 | 42.2 | 21.4 | 46.6 | 21.2 | 49.0 | 17.4 | 46.4 | 15.2 | 39.8 | 17.2 | 42.3 | 26.0 | 51.3 | 22.8 | 48.5 | 19.4 | 48.6 | 20.2 | 46.1 | ||||
| + Retrieval & Tuning | 45.4 | 72.0 | 43.5 | 72.3 | 50.8 | 74.9 | 43.4 | 72.9 | 41.8 | 63.6 | 39.8 | 66.3 | - | - | 41.8 | 74.1 | 38.8 | 70.1 | 45.0 | 75.6 | 43.8 | 70.5 | 49.8 | 75.9 | 45.6 | 76.7 | 39.2 | 69.9 | 38.6 | 65.5 | 43.0 | 68.5 | 42.0 | 69.2 | 41.0 | 70.1 | 37.0 | 68.2 | 41.9 | 70.0 | ||||
| StarCoder-7B | 20.0 | 50.4 | 20.0 | 53.3 | 22.4 | 51.8 | 25.4 | 58.2 | 17.4 | 40.7 | 25.0 | 51.1 | - | - | 24.0 | 59.2 | 16.6 | 52.0 | 24.4 | 59.3 | 21.4 | 48.6 | 17.6 | 49.6 | 18.6 | 54.4 | 19.4 | 52.9 | 16.4 | 43.7 | 19.4 | 47.4 | 26.2 | 56.0 | 23.6 | 53.4 | 19.8 | 53.3 | 21.0 | 52.0 | ||||
| + Retrieval | 23.8 | 47.8 | 27.1 | 53.2 | 24.6 | 48.0 | 26.0 | 53.6 | 20.6 | 40.4 | 25.0 | 47.7 | - | - | 24.6 | 54.2 | 22.6 | 47.2 | 23.6 | 47.4 | 26.4 | 53.5 | 22.8 | 48.5 | 23.4 | 52.3 | 24.1 | 50.0 | ||||||||||||||||
| + Retrieval & Tuning | 47.0 | 72.7 | 45.1 | 74.8 | 52.4 | 76.3 | 43.2 | 73.7 | 45.8 | 67.1 | 44.8 | 70.2 | - | - | 39.2 | 69.9 | 38.6 | 65.5 | 43.0 | 68.5 | 42.0 | 69.2 | 41.0 | 70.1 | 37.0 | 68.2 | 44.5 | 72.2 | ||||||||||||||||
| DeepSeekCoder-6.7B | 22.4 | 53.7 | 21.4 | 56.2 | 23.2 | 54.2 | 29.4 | 61.4 | 17.6 | 43.4 | 25.2 | 51.3 | - | - | 22.2 | 61.0 | 20.4 | 56.5 | 26.0 | 61.0 | 22.0 | 48.8 | 21.0 | 55.6 | 24.2 | 58.6 | 21.8 | 55.1 | 19.4 | 48.5 | 23.6 | 52.2 | 23.8 | 54.3 | 24.6 | 56.7 | 19.4 | 55.4 | 22.6 | 54.7 | ||||
| + Retrieval | 28.2 | 52.6 | 25.3 | 52.6 | 27.6 | 52.2 | 29.4 | 61.4 | 17.6 | 43.4 | 25.8 | 51.0 | - | - | 21.6 | 51.4 | 24.4 | 53.6 | 26.0 | 61.0 | 22.0 | 49.9 | 27.6 | 53.5 | 28.6 | 56.9 | 21.8 | 55.1 | 19.4 | 48.5 | 23.6 | 52.2 | 23.8 | 54.3 | 22.4 | 50.4 | 26.0 | 54.5 | 25.1 | 51.7 | ||||
| + Retrieval & Tuning | 48.6 | 75.2 | 47.9 | 76.9 | 54.4 | 78.2 | 48.8 | 78.4 | 45.0 | 66.3 | 45.8 | 72.0 | - | - | 48.2 | 79.1 | 43.6 | 73.5 | 46.0 | 75.7 | 44.6 | 70.6 | 52.2 | 77.6 | 49.8 | 78.8 | 41.6 | 71.3 | 45.4 | 69.4 | 45.6 | 70.3 | 47.6 | 73.4 | 44.8 | 73.7 | 43.2 | 73.4 | 46.8 | 74.1 |
🔼 This table presents the performance of three different code large language models (Code Llama-7B, StarCoder-7B, and DeepSeekCoder-6.7B) on the M2RC-Eval benchmark. The performance is measured using two metrics: Exact Match (EM) and Edit Similarity (ES), both expressed as percentages. Results are shown for each of the 18 programming languages included in the benchmark, with and without retrieval and retrieval with fine-tuning.
read the caption
Table 2: Exact match (%) and edit similarity (%) performance on M2rc-Eval.
| Model | Average | ||
|---|---|---|---|
| Model | Average | EM | ES |
| StarCoder-3B | 14.9 | 43.5 | |
Retrieval | 14.6 | 38.4 | | |
Retrieval & Tuning | 41.7 | 69.1 | | | StarCoder-7B | 20.6 | 49.9 | | |
Retrieval | 23.6 | 49.3 | | |
Retrieval & Tuning | 44.4 | 71.4 | |
🔼 This table presents the average performance of three different code large language models (StarCoder-3B, StarCoder-7B, and DeepSeekCoder-6.7B) on the M2RC-Eval benchmark. It shows the exact match (EM) and edit similarity (ES) scores for each model under different conditions: baseline (using only the in-file code), with retrieval (incorporating cross-file contexts), and with retrieval and tuning (fine-tuned on the M2RC-INSTRUCT dataset). This allows for comparison of model performance with and without cross-file context retrieval and the impact of fine-tuning on a large multilingual instruction dataset.
read the caption
Table 3: Performance on M2rc-Eval.
| Model | C | C# | C++ | Go | Java | JavaScript | PHP | Python | Ruby | Rust | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|---|
| StarCoder-7B | 48.3 | 48.9 | 50.4 | 51.5 | 50.6 | 46.4 | 48.2 | 46.4 | 46.1 | 50.4 | 48.7 |
| + Retrieval | 50.1 | 52.3 | 51.1 | 52.5 | 51.4 | 49.3 | 52.2 | 49.3 | 49.1 | 51.4 | 50.9 |
| + Retrieval & Tuning | 56.0 | 57.4 | 57.6 | 57.0 | 57.6 | 54.8 | 57.8 | 52.0 | 52.9 | 55.5 | 55.9 |
🔼 This table presents a quantitative evaluation of the performance of different code generation models across ten programming languages using the CodeBLEU metric. CodeBLEU offers a more nuanced evaluation than simpler metrics by considering textual, syntactic, and semantic similarities between generated and reference code. The results help illustrate the models’ strengths and weaknesses in generating code in different programming languages.
read the caption
Table 4: CodeBLEU results on ten representative programming languages.
| Model | Average | ||||
|---|---|---|---|---|---|
| EM | ES | ||||
| + Retrieval | 23.6 | 49.3 | |||
| + Retrieval & Tuning | 44.4 | 71.4 | |||
| + Retrieval & Tuning (Python Only) | 39.2 | 67.9 |
🔼 This table presents the performance of different code generation models on the M2RC-Eval benchmark. It shows the average exact match (EM) and edit similarity (ES) scores for each model, across all languages in the benchmark. Different configurations are shown, such as using only the in-file context or adding retrieved cross-file context, and with or without further fine-tuning on the M2RC-Instruct dataset. The table allows for comparison of the performance improvement due to retrieval and fine-tuning, and provides insights into the effectiveness of these techniques for different code models.
read the caption
Table 5: Performance on M2rc-Eval.
Full paper#