↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current research on Human-AI interaction lacks specificity on the UI design patterns used in generative AI applications. This paper addresses this gap by providing a comprehensive taxonomy of user interface designs and interaction techniques. The authors surveyed numerous generative AI systems and articles, identifying common design patterns and user interaction modalities such as text, visual, and audio inputs, which are categorized into prompting, selection, parameter manipulation, and object manipulation techniques.
The study further categorizes UI layouts into conversational, canvas, contextual, modular, and simulated environments. They also introduce a taxonomy of human-AI engagement levels, ranging from passive to fully collaborative, along with a survey of applications and use cases. Finally, the authors pinpoint key open problems and research challenges, including accessibility for users with disabilities, design for diverse technical literacy levels, ethical considerations (bias mitigation), data privacy, and scalability issues. Their work serves as a valuable foundation for researchers and designers to improve the user experience and effectiveness of generative AI applications.
Key Takeaways#
Why does it matter?#
This paper is crucial for HCI and AI researchers because it systematically surveys and categorizes user interface design patterns in generative AI applications. It provides a valuable resource for informing design choices and inspiring new research directions in human-AI interaction, ultimately driving improvements in user experience and system effectiveness. The work directly addresses the lack of specificity regarding UI design in generative AI literature and is thus essential reading for the community.
Visual Insights#

🔼 This figure illustrates the difference between a prompt and an input within the context of generative AI. A prompt is a user instruction requesting the AI to perform a specific task. The input, on the other hand, is the data or resource that the AI uses to fulfill the request made in the prompt. The example shown depicts an audio editing task. The prompt is the user’s textual instructions, while the input is the actual audio file the instructions are applied to.
read the caption
Figure 1: Prompt vs Inputs (Sec. 2.3): A visual summary of the distinction between prompts and inputs. A prompt is a user-guided interaction where the user asks the system to complete a task. Whereas the input is the piece of data, information, or content that the prompt is acting upon.
| Engagement | Definition | Examples |
|---|---|---|
| Passive Engagement (§5.1) | No direct user interaction during the generation process leverages only user profile and preferences | - immersive news writing (Oh et al., 2020) - personalized curated sports articles (Kim & Lee, 2019) - AI-generated user engagement metrics (Gatti et al., 2014) |
| Deterministic Engagement (§5.2) | Similar to passive, though user provides basic instructions to the genAI model to start or stop the generative process. | - AI generated hierarchical tutorials (Truong et al., 2021) - automated newsgathering (Nishal & Diakopoulos, 2024) - chemical synthesis (Truong et al., 2021) |
| Assistive Engagement (§5.3) | Offers indirect assistance to users such as making suggestions. Systems using assistive engagement must understand the user intentions and high-level goals. | - follow-up question generation (Valencia et al., 2023b) - autocompletion (Jakesch et al., 2023) - writing suggestions (Fitria, 2021) |
| Turn-based Collaborative Engagement (§5.4) | The generative process between the user and generative model occurs in a sequential fashion (i.e., turn-based) | Turn-based conversational interfaces where the user makes a request, then AI generates content, and the process repeats in a turn-based fashion. |
| Simultaneous Collaborative Engagement (§5.5) | User and GenAI work together in parallel to generate the final content | A drawing system where user and generative AI draw concurrently in real-time (Lawton et al., 2023) |
🔼 This table categorizes different levels of interaction between humans and generative AI systems. It defines five key engagement levels: Passive, Deterministic, Assistive, Turn-based Collaborative, and Simultaneous Collaborative. Each level is described with a definition that explains the nature of the human-AI interaction and provides specific examples of AI applications that fall under that category. This provides a comprehensive overview of the spectrum of human-AI collaboration possibilities in the context of generative AI.
read the caption
Table 1: Taxonomy of Human-GenAI Engagement. We summarize the main categories of human-GenAI engagement and provide intuitive definitions and examples of each.
In-depth insights#
GenAI Interaction#
The research paper section on ‘GenAI Interaction’ provides a comprehensive taxonomy of human-AI interaction patterns in generative AI applications. It distinguishes between explicit user-guided interactions (e.g., prompting, selection, parameter manipulation) and implicit interactions, focusing primarily on the former. The taxonomy highlights various modalities of interaction, including text, image, audio, and combinations thereof, offering a structured view of current design practices. The analysis also incorporates a taxonomy of user interface layouts, categorizing them into conversational, canvas, contextual, modular, and simulated environments, showing how UI structure impacts interaction. A key contribution is the formalization of human-AI engagement levels, ranging from passive to fully collaborative, which helps contextualize the types of interactions and their appropriateness for different applications. This thoughtful approach offers valuable insights for designers and developers seeking to improve the usability and effectiveness of generative AI systems.
UI Taxonomy#
The research paper presents a UI taxonomy that categorizes user interactions with generative AI. It focuses on user-guided interactions, excluding implicit ones. The taxonomy is thoughtfully structured into four key categories: Prompting, covering various input methods; Selection Techniques, detailing how users choose specific UI elements; System and Parameter Manipulation, encompassing methods to adjust system settings; and Object Manipulation and Transformation, where users directly modify elements. This framework offers a comprehensive overview of how users interact with generative AI, moving beyond simple prompting and encompassing more nuanced interactions, thereby providing a valuable reference for designers and researchers in the field.
Human-AI Levels#
The research paper categorizes Human-AI interaction levels into five distinct stages: Passive, where AI acts solely on implicit user data; Deterministic, where user input is minimal (start/stop); Assistive, offering indirect guidance; Turn-based Collaborative, with sequential user-AI interaction; and Simultaneous Collaborative, involving parallel interaction. The taxonomy highlights the evolution of engagement, from AI operating independently to fully collaborative efforts. Understanding these levels is crucial for designing effective user interfaces and experiences, tailoring interaction methods to the level of human involvement desired.
GenAI Use Cases#
The research paper explores various GenAI use cases, categorized into content creation, data analysis and forecasting, research and development, task automation, and personal assistance. Content creation leverages GenAI for generating or editing text, images, or audio. Data analysis uses GenAI for data digestion, visualization, and decision-making. Research and development utilizes GenAI for complex problem-solving and tool development. Task automation employs GenAI to streamline repetitive tasks, while personal assistance uses GenAI to provide tailored support. The paper highlights the unique UI interactions and design considerations needed for each GenAI application type. UI interaction types such as conversational, canvas, and modular interfaces are discussed as effective tools within these use cases, showcasing the diverse and impactful applications of GenAI across various sectors. The key takeaway is the successful integration of GenAI requires thoughtful UI design tailored to its specific application and intended use.
Future Challenges#
The research paper identifies several crucial future challenges. Accessibility for users with disabilities is paramount, demanding interface designs that ensure independent usage without needing assistance. The need to cater to users with limited technical literacy is equally vital, requiring interfaces that are intuitive and straightforward. Ethical considerations are also critical, focusing on mitigating biases embedded in training data and designing to prevent misuse. Growth and scalability require interfaces that remain user-friendly despite increased complexity, maintaining consistency in interaction patterns as the AI evolves. Finally, adapting interfaces for the evolving landscape of future user interfaces (including virtual and augmented reality) demands further research and development.
More visual insights#
More on figures

🔼 Generative AI models can utilize different modalities for both input and output. This figure provides a visual overview of the common modalities used in generative AI systems. It shows three main categories: Text (including natural language, data, and code), Visual (including images, videos, and visual interactions), and Sound (including audio and speech). Each category is further broken down into more specific examples. This visualization helps to understand the diverse ways that humans can interact with and receive information from generative AI systems.
read the caption
Figure 2: Modalities: A high-level visual summary of the different modalities that generative AIs use (Sec. 2.3).

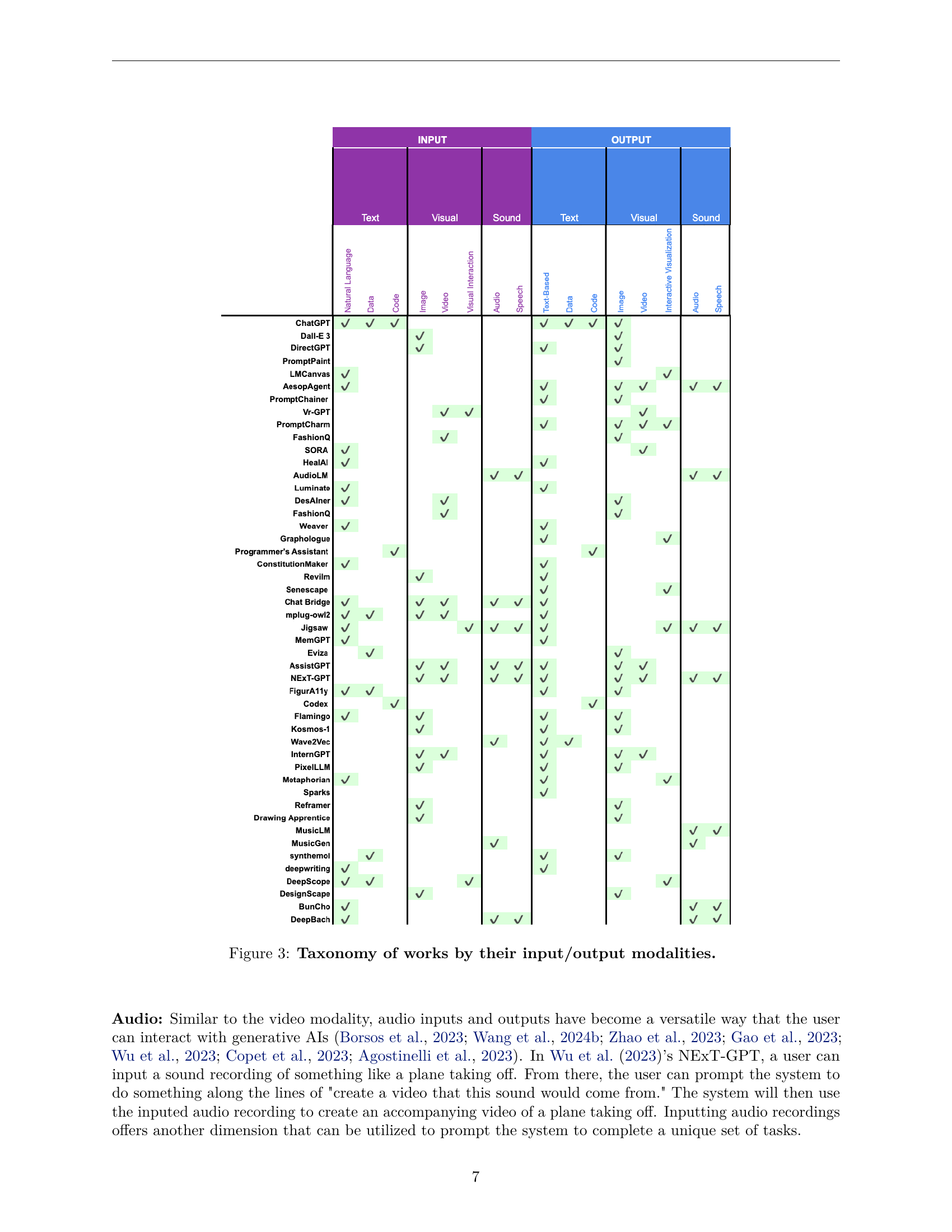
🔼 This figure provides a comprehensive overview of the different generative AI systems and their capabilities based on the modalities they support for both input and output. It presents a table where each row represents a specific generative AI system, and each column indicates the type of modality it handles (text, visual, or sound). A checkmark indicates the system’s ability to process or generate data in that specific modality. This visualization helps understand the range of functionalities offered by different generative AI systems and their suitability for various applications.
read the caption
Figure 3: Taxonomy of works by their input/output modalities.

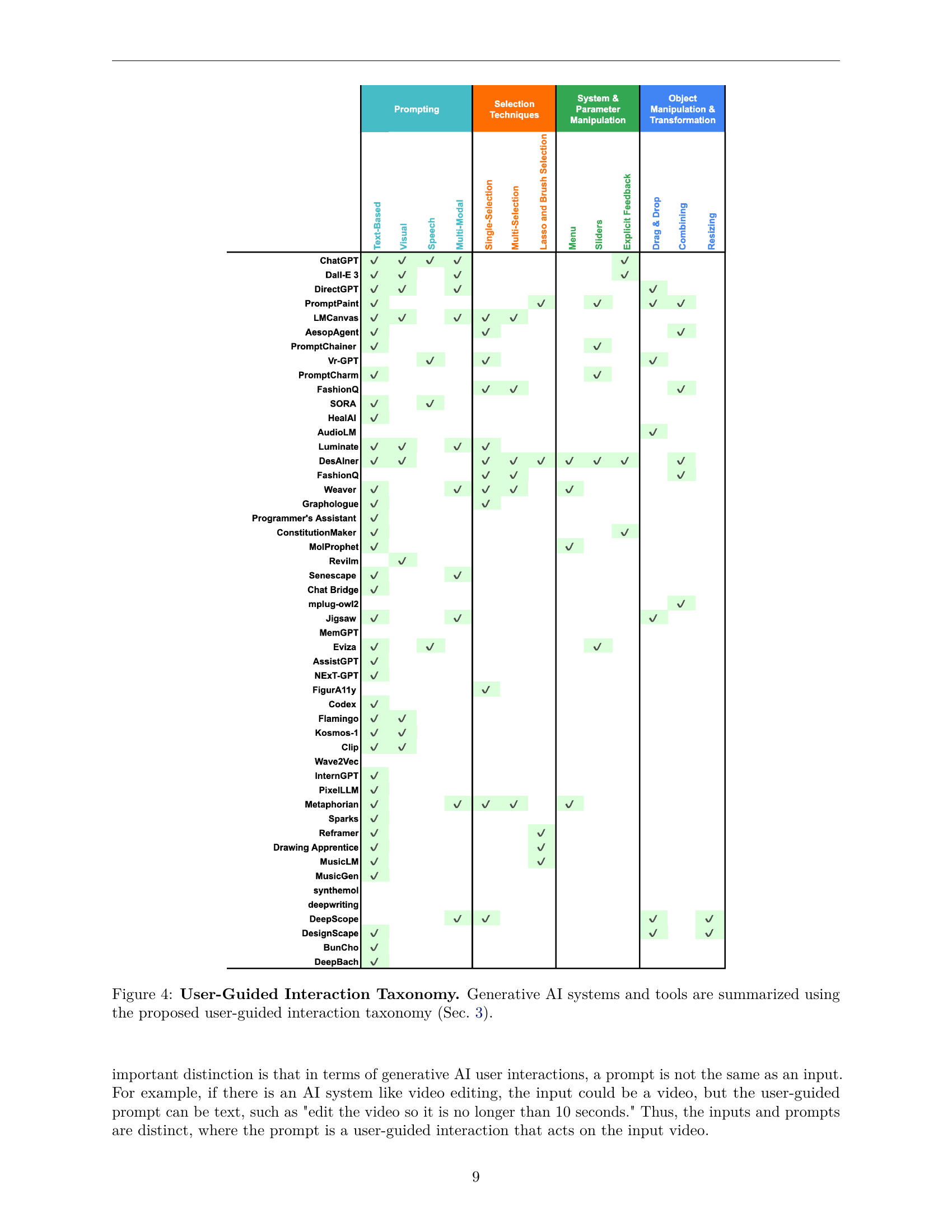
🔼 Figure 4 is a table that categorizes various generative AI systems and tools based on the user-guided interaction taxonomy introduced in Section 3 of the paper. The taxonomy breaks down user interactions into four main types: Prompting, Selection Techniques, System & Parameter Manipulation, and Object Manipulation & Transformation. Each row in the table represents a specific generative AI system or tool. Each column indicates whether that system supports a particular type of user interaction from the taxonomy. A checkmark indicates that the system supports the interaction. This visualization helps readers quickly understand the range of interaction methods used by different generative AI systems and how these methods are classified within the proposed taxonomy.
read the caption
Figure 4: User-Guided Interaction Taxonomy. Generative AI systems and tools are summarized using the proposed user-guided interaction taxonomy (Sec. 3).

🔼 This figure shows an example of a text-based prompt interaction in generative AI. The user provides a natural language instruction to the system. In the example shown, the user asks the system to generate a story about a dog in space. The system’s response is displayed below the prompt, showcasing text-based interaction as a method of prompting.
read the caption
(a) Text-based Prompt (§.3.1.1)

🔼 This figure shows an example of a visual prompt. Visual prompts are user-guided interactions where users use visual communication, like images or gestures, to prompt the system to complete a certain task. The example in the figure shows a user providing an image of two puppies to the system as a prompt. This is a way to instruct the system to generate new content related to the image, such as a similar picture, descriptions of the picture, or a story about the puppies.
read the caption
(b) Visual Prompts (§.3.1.2)

🔼 This figure shows an example of an audio prompt interaction within a generative AI system. The user provides an audio input, for example an audio clip of a piano intro, and then prompts the system to complete the audio using either text or audio prompts. The system’s response, a finished song, is shown next to the prompt.
read the caption
(c) Audio Prompts (§.3.1.3)

🔼 This figure shows an example of a multimodal prompt in a generative AI system. Multimodal prompts combine different input modalities (text, visuals, audio) to guide the AI’s generation process. In this particular example, the user might be providing a text description, a visual input (perhaps an image or sketch), and an audio clip to create a specific output. The combination of inputs allows for richer and more nuanced instructions compared to using just a single modality.
read the caption
(d) Multi-Modal Prompts (§.3.1.4)

🔼 This figure provides a visual summary of the four main prompting subcategories discussed in Section 3.1 of the paper. These subcategories are: 1) Text-based prompts, where users type text instructions; 2) Visual prompts, where users provide visual input (like images) to guide the generation; 3) Audio prompts, where users provide audio input; and 4) Multi-modal prompts, combining elements of the previous three methods. The figure visually shows example user prompts and system responses for each type of prompting interaction, illustrating the diversity of ways users can guide generative AI systems towards completing a task.
read the caption
Figure 5: Prompting Visual Summary (Sec. 3.1): An overview of the four main prompting subcategories. Prompting is a user-guided interaction where a user asks or 'prompts' the generative AI system to complete a certain task.

🔼 This figure shows an example of single selection in a generative AI system. The user is given several options for a story title, and single selection allows the user to select just one of the choices to proceed further. This contrasts with multi-selection where several options could be chosen at once. This simple interaction highlights a key way a user can provide refined control to a generative system, allowing for iterative refinement.
read the caption
(a) Single Selection

🔼 In the context of generative AI systems, multi-selection involves choosing or highlighting multiple UI elements simultaneously to further interact with them. This allows for more complex interactions, such as selecting multiple words to apply a uniform change (e.g., replace with synonyms) or selecting components from different outputs to create something new (e.g., combining elements from different dress designs to create a unique garment). It contrasts with single-selection, where only one element is selected at a time.
read the caption
(b) Multi-Selection

🔼 This figure shows an example of lasso and brush selection in a generative AI system. Lasso and brush selection techniques allow for the precise selection of parts of a larger element (e.g., an image or a document), giving the user finer control over how the generative model processes that content. The user can use a brush tool or lasso tool to select a specific area to manipulate or apply specific parameters. In this case, a brush is used to select parts of an image to add a hat to, enabling a specific editing task only to the selected section.
read the caption
(c) Lasso and Brush Selection

🔼 This figure illustrates the concept of selection techniques in generative AI user interfaces. Selecting, in the context of generative AI, involves choosing or highlighting a specific UI element (a button, an image, text, etc.) to trigger further interaction with the system. The figure showcases three examples: single selection, where a single element is chosen; multi-selection, where multiple elements are chosen; and lasso/brush selection, where a region is selected using lasso or brush tools. This highlights how users can directly manipulate UI elements to guide the generative AI’s output, providing a more precise and controlled interaction compared to simply providing textual prompts.
read the caption
Figure 6: Selection Techniques (Sec. 3.2): Selecting, in terms of generative AI systems, consists of choosing or highlighting a specific UI element in order to further interact with it.

🔼 This figure shows an example of a menu UI element in a generative AI system. Menus allow users to select from preset options or input their own parameters to modify the generative process. The menu in the figure presents different choices, presumably to change certain aspects of the generated output. The various options suggest that the AI system offers customizable features.
read the caption
(a) Menus

🔼 This figure shows how sliders can be used to adjust the parameters of a generative AI system. Sliders are visual UI elements that allow for the manipulation of parameters by adjusting their values. The example in the figure likely displays a slider that controls some aspect of a generative model, perhaps influencing a visual output, the settings for a text generation, or parameters in an audio editor. The specific parameter being adjusted by the slider is not explicitly stated in the caption.
read the caption
(b) Sliders

🔼 This figure shows an example of explicit feedback in the context of generative AI systems. Explicit feedback involves users directly communicating their satisfaction or dissatisfaction with a generated output. This is not implicit feedback where the system infers user satisfaction or dissatisfaction based on indirect cues. The example shows a user providing textual feedback to critique the AI’s response and suggest improvements for future interactions. The user’s feedback is explicitly communicated to the system.
read the caption
(c) Explicit Feedback

🔼 This figure illustrates three types of user interaction techniques that allow users to modify the parameters, settings, or functions of a generative AI system. These techniques are: 1. Menus: Users select options from menus (dropdowns, etc.) to alter settings or parameters. The example shows a revenue graph with menus for selecting different metrics (total revenue, tone, mood, language, time period) to be displayed. 2. Sliders: Users adjust sliders to control parameters and settings. The example showcases how sliders can be used to control values like range and increments of a revenue graph. 3. Explicit Feedback: Users provide direct feedback (thumbs up/down, written critiques, etc.) to fine-tune the system’s behavior. The example shows a user providing feedback about the information shown in the system’s response to a query.
read the caption
Figure 7: System and Parameter Manipulation (Sec. 3.3): User interaction techniques that allow the user to adjust the parameters, settings, or functions of an overall generative AI system.

🔼 This figure shows an example of a drag-and-drop interaction within a generative AI system. Drag-and-drop interactions allow users to directly manipulate UI elements by dragging them to a specific location or another element. This manipulation can trigger actions within the system, such as creating or connecting elements, altering parameters, or prompting the system to perform a task. The example illustrates how the user might combine prompts by dragging and dropping them onto each other. This specific example is from the Object Manipulation and Transformation section of the paper.
read the caption
(a) Drag and Drop

🔼 This figure shows an example of connecting UI elements within a generative AI system. Users can combine UI elements that represent different system instructions (or parts of prompts) by connecting them visually. This process creates a combined prompt or instruction by combining the individual components. In the example shown, UI elements containing parts of a prompt are connected. The system understands the combined meaning of these connected elements, resulting in a combined prompt such as, “Create a poem about a spaceship set in the modern age”. This technique facilitates prompt creation by enabling users to combine modular units of instructions rather than writing a complete prompt from scratch.
read the caption
(b) Connecting

🔼 This figure shows an example of the object manipulation and transformation interaction technique, specifically resizing. The user is shown to be able to resize an object in the system. Resizing an object changes the size of that object, and depending on the generative AI system that is used, can change the object’s function.
read the caption
(c) Resizing

🔼 Figure 8 shows three types of user interaction techniques in Generative AI systems that involve directly manipulating visual UI elements. These techniques allow users to modify, adjust, or transform a specific element. The examples shown illustrate: (a) Drag and Drop: moving an element to a new position or using it to modify the system’s generative process. (b) Connecting: linking UI elements together to create a composite input or prompt. (c) Resizing: changing the size of an element to alter its effects on the system. These interactions are useful for giving users a more nuanced control over the generative process.
read the caption
Figure 8: Object Manipulation and Transformation (Sec. 3.4): User interaction techniques that modify, adjust, and/or transform a specific UI element, like a building block, puzzle piece, or similar entity.

🔼 This figure illustrates the structure of a conversational user interface (UI) in generative AI applications. It shows how the UI is designed to mimic a human conversation. The user interacts with a designated prompt/input box, where they enter their queries or instructions. The system’s responses and the history of the entire conversation are then displayed in a larger area within the UI, making it easy for the user to follow the interaction flow and refer to previous exchanges. This structure facilitates a turn-based conversation between the user and the AI.
read the caption
Figure 9: Conversational UI: A conversational UI is structured so that a user interacts with the user prompt/input box. From there, their output(s) and output history exist in a larger space within the UI (Sec. 4.1).

🔼 This figure illustrates the layout of a Canvas User Interface, a common design pattern for generative AI applications. The core element is a large central canvas area where the primary generated content (e.g., an image, a text, a video) is displayed. Surrounding this canvas, in the periphery, are various tools and controls related to the generative process. These peripheral elements might include options for adjusting parameters, selecting from different styles, adding new elements, modifying the generated content, and so on. This arrangement keeps the focus on the main generated content, making it easy for users to view and interact with the generated output while providing convenient access to tools that enable adjustments and modifications.
read the caption
Figure 10: Canvas User Interface: A UI structure with a central canvas area that houses the primary content. The generative and other tools are often in the periphery or off to the side. (Sec. 4.2).
Full paper#