↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Many existing systems for understanding user intent in dialogue systems struggle with complex queries containing multiple intents. These systems typically handle simple queries with single intents, lacking the ability to effectively extract multiple intents and their corresponding spans within the query. Furthermore, there’s a shortage of multilingual datasets for training and evaluating these systems.
This paper introduces a novel multi-label multi-class intent detection dataset (MLMCID) created from existing benchmark datasets, along with a new pointer network-based architecture, also called MLMCID. The MLMCID architecture jointly extracts intent spans and detects intents with both coarse and fine-grained labels. Extensive experiments on multiple datasets showcase MLMCID’s superiority over other approaches, including LLMs, in terms of accuracy and F1-score, demonstrating its effectiveness in handling complex, multilingual queries.
Key Takeaways#
Why does it matter?#
This paper is important because it tackles the challenge of handling complex user queries with multiple intents in task-oriented dialogue systems, a crucial aspect of improving NLU capabilities. The introduction of a novel multilingual dataset and the proposed pointer network-based architecture offer significant advancements for researchers working on intent detection and span extraction, particularly in multilingual settings. The superior performance of their model over existing baselines and LLMs highlights the potential impact of this research on various NLU applications.
Visual Insights#

🔼 This figure showcases examples of multi-label, multi-class intent datasets. It illustrates how a single user query can express multiple distinct intents. The examples highlight scenarios found in three different datasets: SNIPS, Facebook, and BANKING. Each example sentence is annotated with its corresponding intents (fine and coarse-grained) and the spans of text representing those intents.
read the caption
Figure 1: Examples of multi-label multi intent datasets (SNIPS, Facebook and BANKING)
| Fine Intents Combined | Coarse Intent |
|---|---|
| cancel reminder, set reminder, show reminders | reminder_service |
| GetTrafficInformation, ShareETA | Traffic_update |
🔼 This table shows how multiple fine-grained intent labels from the Facebook English and SNIPS datasets are combined to create a single, more general coarse-grained intent label. For example, several similar fine intents related to setting reminders are grouped together under a single ‘reminder_service’ coarse intent. This process simplifies the intent classification task while retaining key semantic information.
read the caption
Table 1: Fine-Course Intent for Fb-en and SNIPS
In-depth insights#
Multi-Intent Datasets#
The research paper explores the crucial need for multi-intent datasets in advancing natural language understanding (NLU) for task-oriented dialogue systems. Existing datasets predominantly focus on single-intent queries, limiting progress in handling real-world scenarios with complex, multi-intent utterances. The paper highlights the lack of multilingual, multi-intent resources, a significant obstacle in building robust and versatile NLU systems. To address this, the study introduces a novel dataset (MLMCID) curated from existing benchmarks, carefully incorporating both coarse and fine-grained intent labels, along with primary and non-primary intent distinctions. This enriched dataset allows for more nuanced model training and evaluation, enabling the development of more accurate and comprehensive multi-intent detection and span extraction systems.
Pointer Networks#
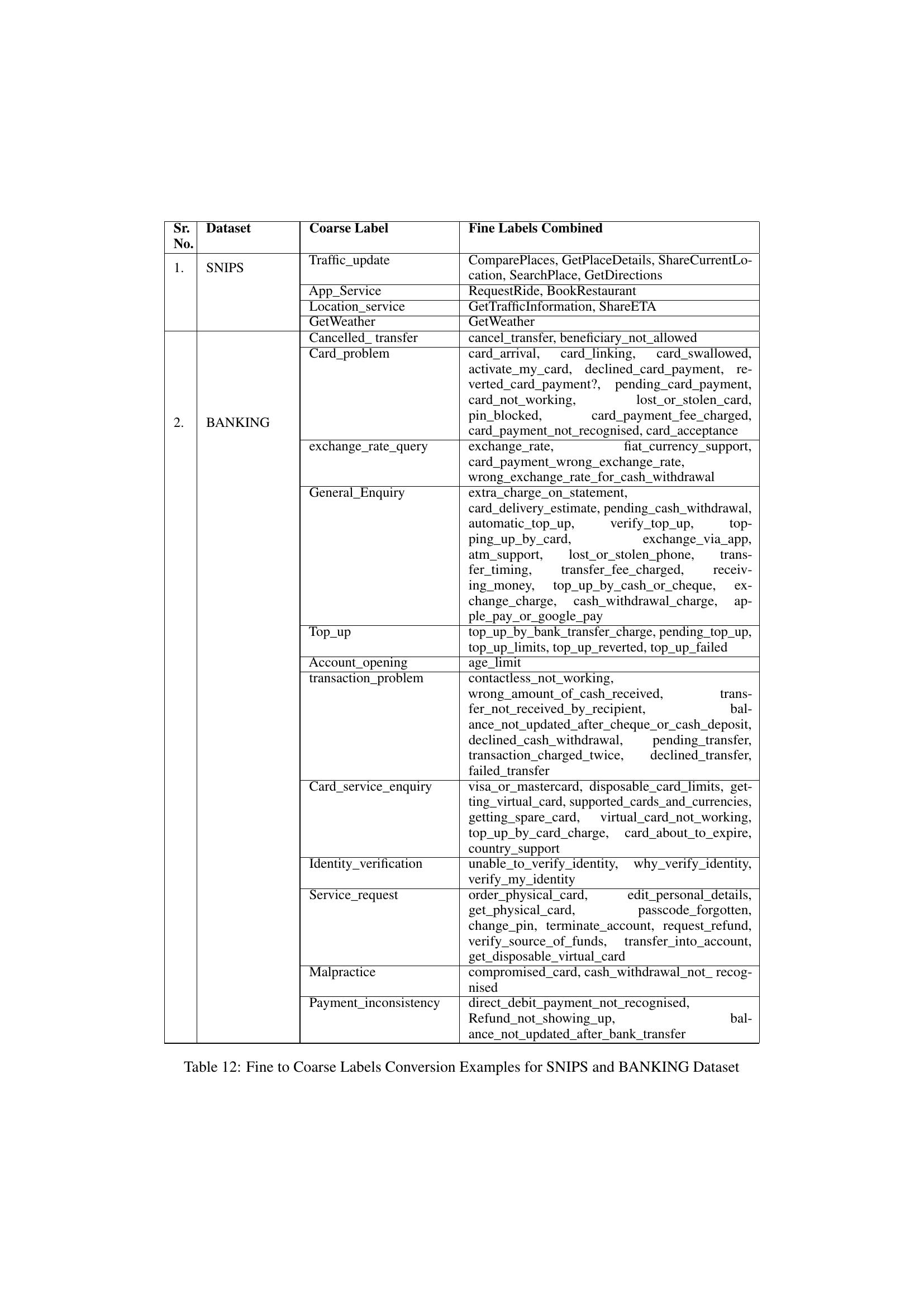
The research paper section on ‘Pointer Networks’ highlights their application in jointly extracting multiple intent spans and detecting multi-label multi-class intents. Pointer Networks offer a unique advantage by directly predicting the start and end positions of intent spans within a sentence, bypassing the need for intermediate steps and enabling the model to handle variable-length spans. This approach is particularly effective in handling overlapping intents, a common challenge in real-world conversational data. The integration of pointer networks into the proposed MLMCID architecture demonstrates superior performance over traditional methods due to this capacity for precise and efficient span extraction, leading to more accurate intent classification and a notable improvement in macro-F1 scores. The authors showcase the method’s efficacy by comparing its performance against various baselines, including other neural network models and large language models (LLMs).
MLMCID Model#
The MLMCID model, a pointer network-based architecture, tackles the complex task of jointly extracting multiple intent spans and detecting multi-label, multi-class intents from a given query. It leverages a robust encoder-decoder framework; the encoder uses contextual embeddings (like RoBERTa or XLM-R) to capture semantic information, while the decoder employs pointer networks to precisely identify intent spans. A feed-forward network then classifies these spans with both coarse-grained and fine-grained labels, further differentiating primary and non-primary intents. This novel approach surpasses traditional methods, demonstrating improved accuracy and F1-score across various datasets. Its effectiveness stems from its ability to handle overlapping intents, a critical aspect of real-world conversational scenarios, and its joint extraction-classification paradigm, providing a more holistic and accurate understanding of user intent.
LLM Comparisons#
The research compares the performance of various Large Language Models (LLMs) against a proposed Pointer Network-based model for multi-label, multi-class intent detection. LLMs, despite their size and power, underperformed the specialized Pointer Network model. This suggests that while LLMs are powerful general-purpose tools, task-specific architectures, optimized for intent extraction and classification, offer a superior performance. The study highlights the importance of architecture design for specific NLU tasks, and emphasizes that larger model size doesn’t automatically translate to better results in this domain. The findings underscore the need for targeted approaches to improve accuracy in multi-intent detection, particularly in scenarios with complex sentence structures and multiple overlapping intents. Further research should focus on improving LLM fine-tuning techniques or exploring hybrid architectures combining the strengths of both LLM and specialized models.
Future Research#
The authors suggest several avenues for future research. Extending the model to handle more than two intents per sentence is a primary focus, acknowledging that real-world conversations frequently involve more complex combinations of user requests. Improving the model’s ability to distinguish between primary and non-primary intents is another crucial area for improvement, especially when the model’s predictions incorrectly swap these labels. Finally, they mention the need for more comprehensive and diverse multilingual datasets to enable broader and more robust cross-lingual intent detection, improving the model’s generalizability and performance across various languages.
More visual insights#
More on figures

🔼 This figure illustrates the architecture of the MLMCID model, a pointer network-based approach for multi-label, multi-class intent detection. The encoder processes input words using embeddings (BERT, RoBERTa, DistilBERT, or Electra) to generate contextualized word representations. A Bi-LSTM layer further refines these representations. The decoder employs two pointer networks and an LSTM-based sequence generator to extract multiple intent spans from the sentence. These span locations are then passed, along with Bi-LSTM output, through feed-forward networks (FFNs) for coarse and fine intent detection. The outputs of these networks provide sextuplets: (span1, coarse label1, fine label1, span2, coarse label2, fine label2).
read the caption
Figure 2: Pointer Network Based multi-label, multi-class intent detection (MLMCID) architecture

🔼 The figure shows the combined loss for coarse-grained intent labels across different datasets during the training process of the RoBERTa-based pointer network model. The x-axis represents the number of epochs (iterations of training), while the y-axis shows the loss value. The plot illustrates how the combined loss changes over epochs for several datasets, providing insights into the model’s training progress and convergence behavior for coarse intent detection.
read the caption
(a) Combined loss - Coarse

🔼 The plot shows the variation of the fine-grained loss for the RoBERTa-based pointer network model in MLMCID across different datasets. The y-axis represents the loss value, and the x-axis indicates the number of training epochs. The plot displays how the loss changes over the course of training for several datasets, illustrating the model’s learning progress in terms of minimizing the fine-grained loss function for intent detection.
read the caption
(b) Combined Loss - Fine

🔼 This figure shows the training loss curves for a RoBERTa-based pointer network model used in the MLMCID framework. Separate curves are displayed for the combined coarse and fine intent loss functions across different datasets: SNIPS, FB_en, HWU64, BANKING, and CLINC. The x-axis represents the number of training epochs, while the y-axis shows the loss value. The plot illustrates how the loss decreases during training, indicating the model’s learning progress.
read the caption
Figure 3: By RoBERTa based pointer network (PNM) model in MLMCID
More on tables
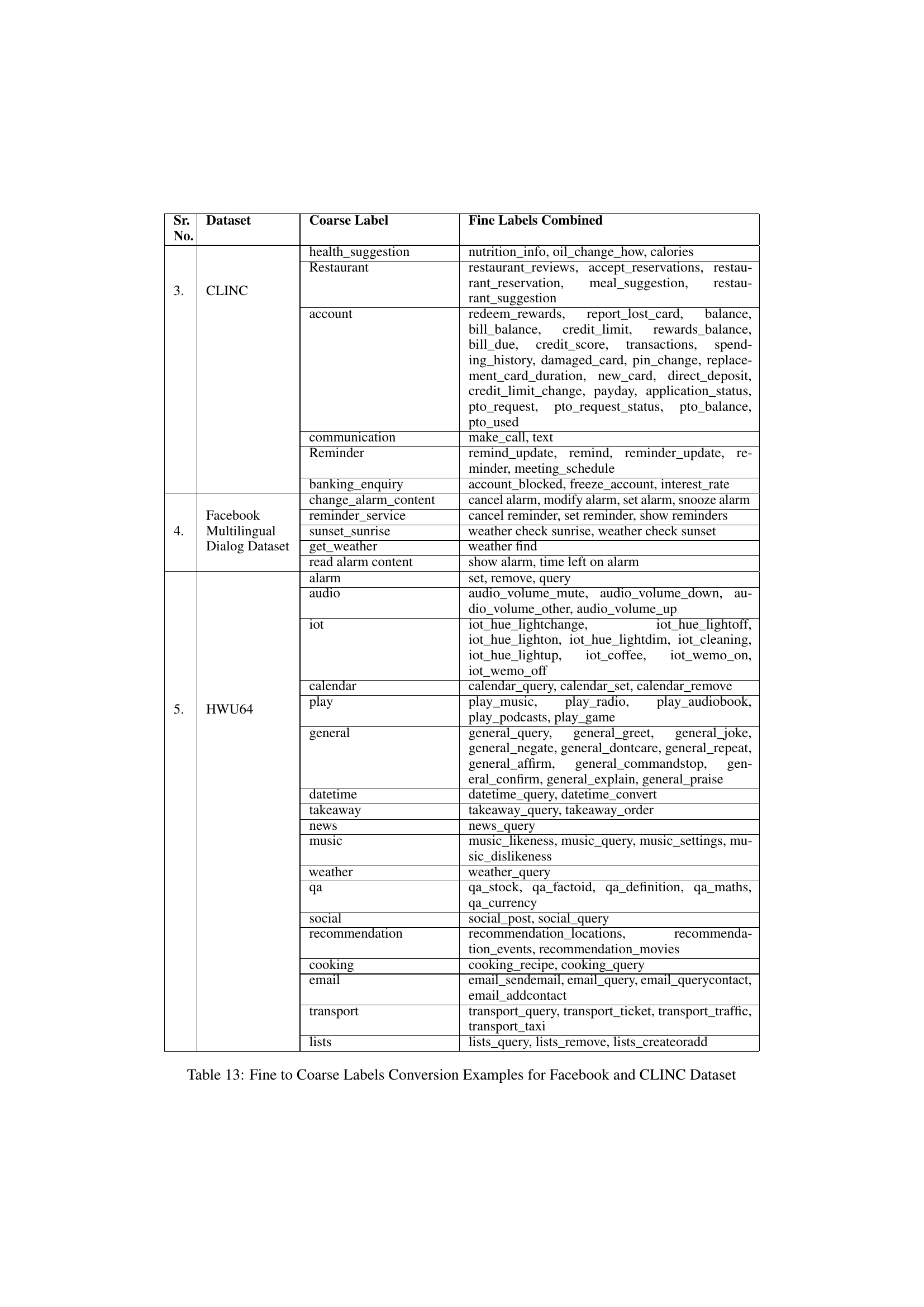
| Sr. No. | Dataset | Coarse Label | Fine Labels Combined |
|---|---|---|---|
| 1. | SNIPS | Traffic_update | ComparePlaces, GetPlaceDetails, ShareCurrentLocation, SearchPlace, GetDirections |
| App_Service | RequestRide, BookRestaurant | ||
| Location_service | GetTrafficInformation, ShareETA | ||
| GetWeather | GetWeather | ||
| 2. | BANKING | Cancelled_ transfer | cancel_transfer, beneficiary_not_allowed |
| Card_problem | card_arrival, card_linking, card_swallowed, activate_my_card, declined_card_payment, reverted_card_payment?, pending_card_payment, card_not_working, lost_or_stolen_card, pin_blocked, card_payment_fee_charged, card_payment_not_recognised, card_acceptance | ||
| exchange_rate_query | exchange_rate, fiat_currency_support, card_payment_wrong_exchange_rate, wrong_exchange_rate_for_cash_withdrawal | ||
| General_Enquiry | extra_charge_on_statement, card_delivery_estimate, pending_cash_withdrawal, automatic_top_up, verify_top_up, topping_up_by_card, exchange_via_app, atm_support, lost_or_stolen_phone, transfer_timing, transfer_fee_charged, receiving_money, top_up_by_cash_or_cheque, exchange_charge, cash_withdrawal_charge, apple_pay_or_google_pay | ||
| Top_up | top_up_by_bank_transfer_charge, pending_top_up, top_up_limits, top_up_reverted, top_up_failed | ||
| Account_opening | age_limit | ||
| transaction_problem | contactless_not_working, wrong_amount_of_cash_received, transfer_not_received_by_recipient, balance_not_updated_after_cheque_or_cash_deposit, declined_cash_withdrawal, pending_transfer, transaction_charged_twice, declined_transfer, failed_transfer | ||
| Card_service_enquiry | visa_or_mastercard, disposable_card_limits, getting_virtual_card, supported_cards_and_currencies, getting_spare_card, virtual_card_not_working, top_up_by_card_charge, card_about_to_expire, country_support | ||
| Identity_verification | unable_to_verify_identity, why_verify_identity, verify_my_identity | ||
| Service_request | order_physical_card, edit_personal_details, get_physical_card, passcode_forgotten, change_pin, terminate_account, request_refund, verify_source_of_funds, transfer_into_account, get_disposable_virtual_card | ||
| Malpractice | compromised_card, cash_withdrawal_not_ recognised | ||
| Payment_inconsistency | direct_debit_payment_not_recognised, Refund_not_showing_up, balance_not_updated_after_bank_transfer |
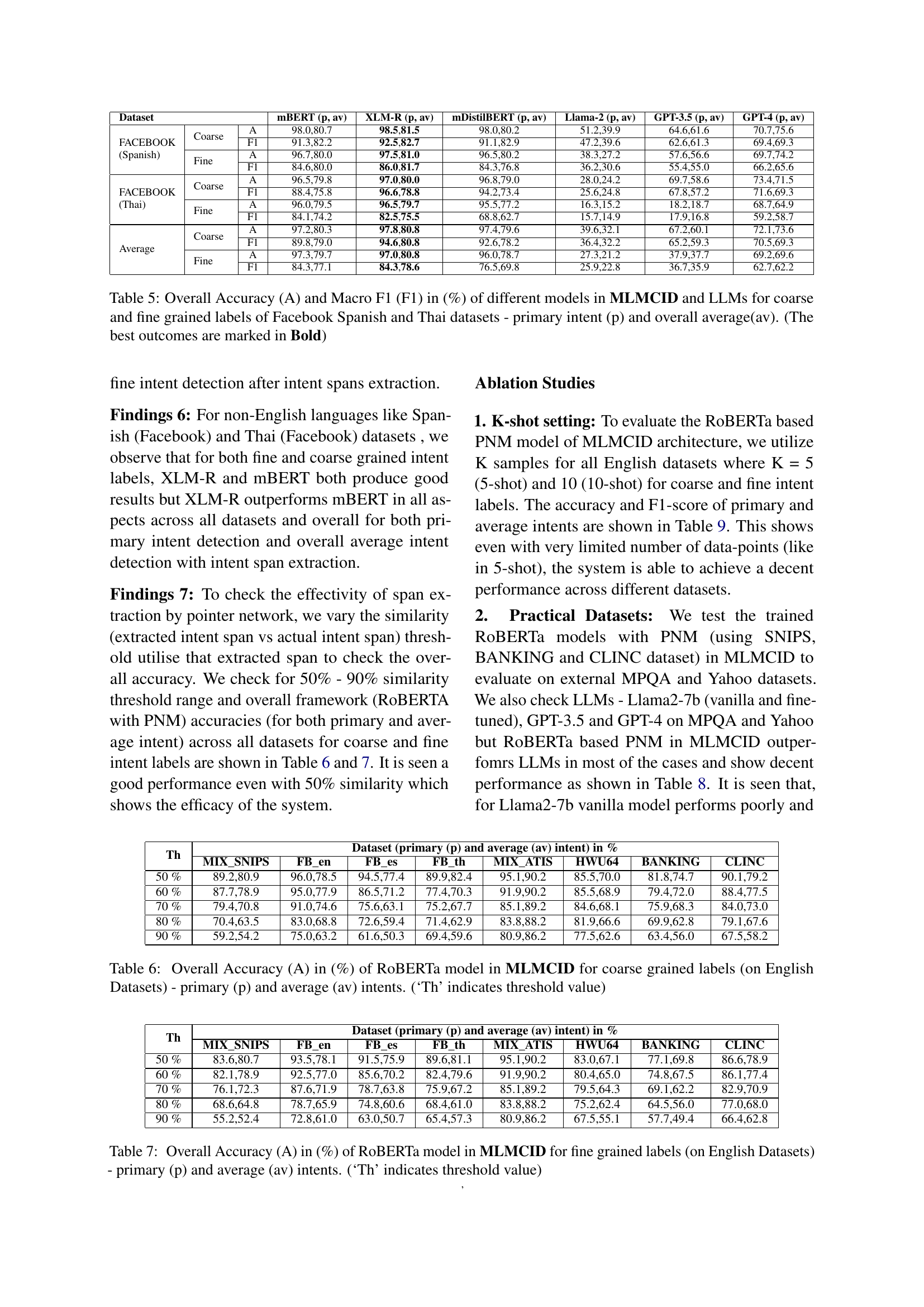
🔼 This table presents the statistical details of the MLMCID dataset, a novel multilingual, multi-label, multi-class intent detection dataset created for this research. It shows the number of training, development, and test samples for each dataset included in MLMCID (Mix-SNIPS, Mix-ATIS, Facebook English, Facebook Spanish, Facebook Thai, HWU, BANKING, CLINC, Yahoo News, MPQA). This provides a clear overview of the data split used for training, validation, and testing the proposed model.
read the caption
Table 2: MLMCID-dataset statistics
| Sr. No. | Dataset | Coarse Label | Fine Labels Combined |
|---|---|---|---|
| 3. | CLINC | health_suggestion | nutrition_info, oil_change_how, calories |
| Restaurant | restaurant_reviews, accept_reservations, restaurant_reservation, meal_suggestion, restaurant_suggestion | ||
| account | redeem_rewards, report_lost_card, balance, bill_balance, credit_limit, rewards_balance, bill_due, credit_score, transactions, spending_history, damaged_card, pin_change, replacement_card_duration, new_card, direct_deposit, credit_limit_change, payday, application_status, pto_request, pto_request_status, pto_balance, pto_used | ||
| communication | make_call, text | ||
| Reminder | remind_update, remind, reminder_update, reminder, meeting_schedule | ||
| banking_enquiry | account_blocked, freeze_account, interest_rate | ||
| 4. | Facebook Multilingual Dialog Dataset | change_alarm_content | cancel alarm, modify alarm, set alarm, snooze alarm |
| reminder_service | cancel reminder, set reminder, show reminders | ||
| sunset_sunrise | weather check sunrise, weather check sunset | ||
| get_weather | weather find | ||
| read alarm content | show alarm, time left on alarm | ||
| 5. | HWU64 | alarm | set, remove, query |
| audio | audio_volume_mute, audio_volume_down, audio_volume_other, audio_volume_up | ||
| iot | iot_hue_lightchange, iot_hue_lightoff, iot_hue_lighton, iot_hue_lightdim, iot_cleaning, iot_hue_lightup, iot_coffee, iot_wemo_on, iot_wemo_off | ||
| calendar | calendar_query, calendar_set, calendar_remove | ||
| play | play_music, play_radio, play_audiobook, play_podcasts, play_game | ||
| general | general_query, general_greet, general_joke, general_negate, general_dontcare, general_repeat, general_affirm, general_commandstop, general_confirm, general_explain, general_praise | ||
| datetime | datetime_query, datetime_convert | ||
| takeaway | takeaway_query, takeaway_order | ||
| news | news_query | ||
| music | music_likeness, music_query, music_settings, music_dislikeness | ||
| weather | weather_query | ||
| qa | qa_stock, qa_factoid, qa_definition, qa_maths, qa_currency | ||
| social | social_post, social_query | ||
| recommendation | recommendation_locations, recommendation_events, recommendation_movies | ||
| cooking | cooking_recipe, cooking_query | ||
| email_sendemail, email_query, email_querycontact, email_addcontact | |||
| transport | transport_query, transport_ticket, transport_traffic, transport_taxi | ||
| lists | lists_query, lists_remove, lists_createoradd |
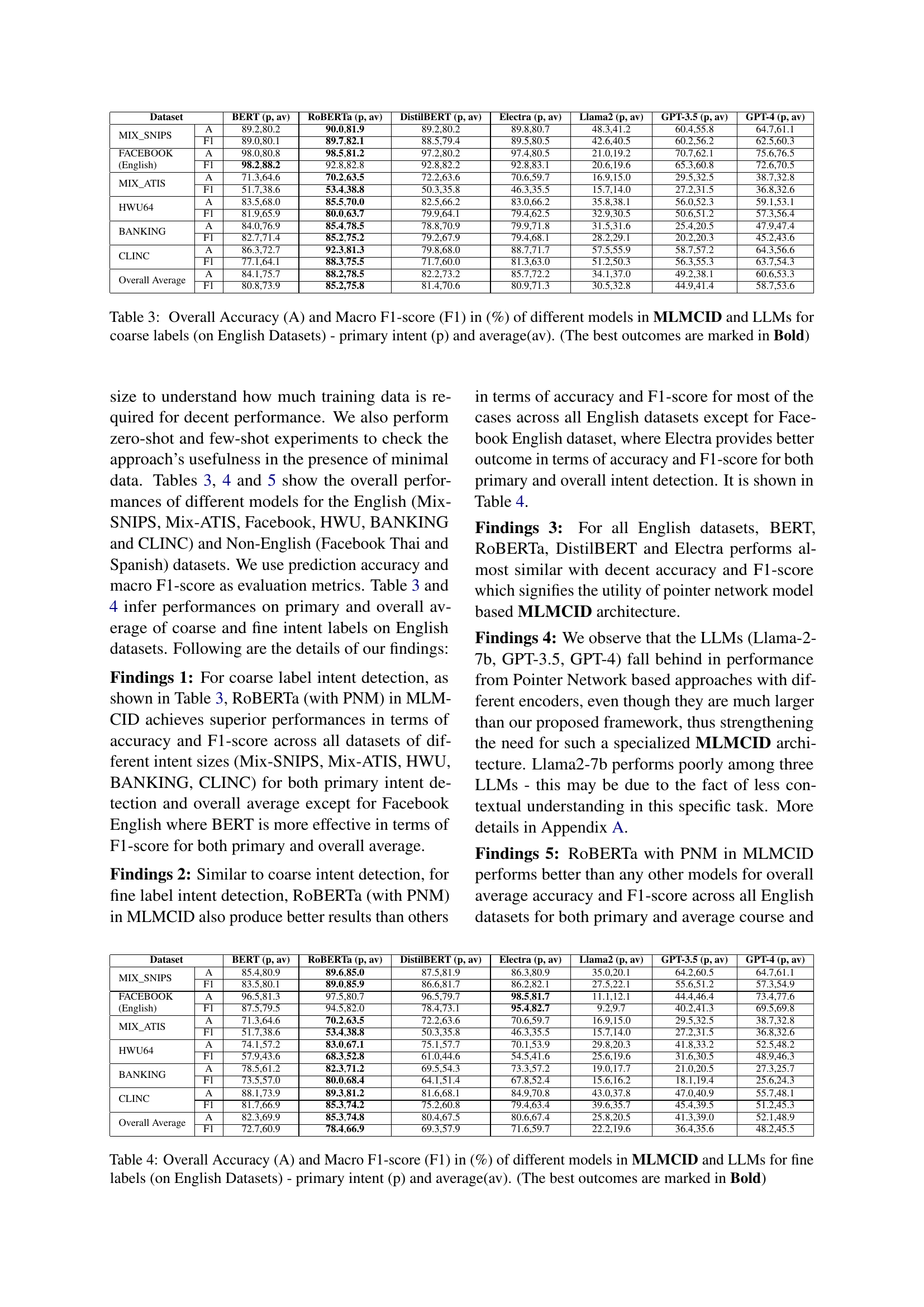
🔼 This table presents the performance of the RoBERTa model on coarse and fine intent classification tasks using a k-shot learning approach, where k represents the number of training examples used. Specifically, it shows the accuracy (A) and F1-score for both primary and average intents when using 5-shot (5 training examples) and 10-shot (10 training examples) learning scenarios. Results are broken down by dataset (SNIPS, FACEBOOK (English), HWU-64, BANKING, CLINC).
read the caption
Table 9: Accuracy (A) and F1-Score for coarse and fine intents by RoBERTa(in %) for k-shot, k = {5, 10}
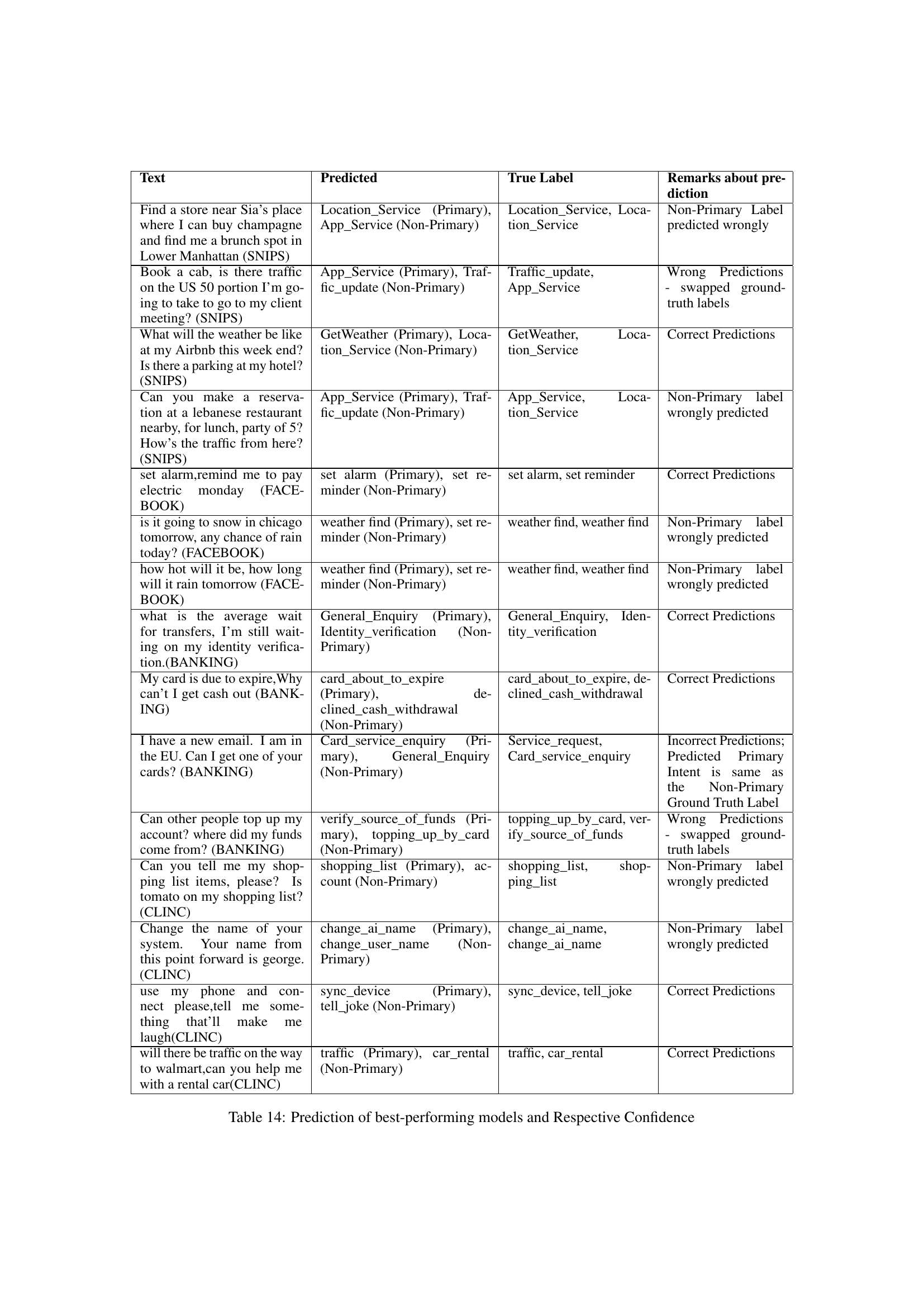
| Text | Predicted | True Label | Remarks about prediction |
|---|---|---|---|
| Find a store near Sia’s place where I can buy champagne and find me a brunch spot in Lower Manhattan (SNIPS) | Location_Service (Primary), App_Service (Non-Primary) | Location_Service, Location_Service | Non-Primary Label predicted wrongly |
| Book a cab, is there traffic on the US 50 portion I’m going to take to go to my client meeting? (SNIPS) | App_Service (Primary), Traffic_update (Non-Primary) | Traffic_update, App_Service | Wrong Predictions - swapped ground-truth labels |
| What will the weather be like at my Airbnb this week end? Is there a parking at my hotel? (SNIPS) | GetWeather (Primary), Location_Service (Non-Primary) | GetWeather, Location_Service | Correct Predictions |
| Can you make a reservation at a lebanese restaurant nearby, for lunch, party of 5? How’s the traffic from here? (SNIPS) | App_Service (Primary), Traffic_update (Non-Primary) | App_Service, Location_Service | Non-Primary label wrongly predicted |
| set alarm,remind me to pay electric monday (FACEBOOK) | set alarm (Primary), set reminder (Non-Primary) | set alarm, set reminder | Correct Predictions |
| is it going to snow in chicago tomorrow, any chance of rain today? (FACEBOOK) | weather find (Primary), set reminder (Non-Primary) | weather find, weather find | Non-Primary label wrongly predicted |
| how hot will it be, how long will it rain tomorrow (FACEBOOK) | weather find (Primary), set reminder (Non-Primary) | weather find, weather find | Non-Primary label wrongly predicted |
| what is the average wait for transfers, I’m still waiting on my identity verification.(BANKING) | General_Enquiry (Primary), Identity_verification (Non-Primary) | General_Enquiry, Identity_verification | Correct Predictions |
| My card is due to expire,Why can’t I get cash out (BANKING) | card_about_to_expire (Primary), declined_cash_withdrawal (Non-Primary) | card_about_to_expire, declined_cash_withdrawal | Correct Predictions |
| I have a new email. I am in the EU. Can I get one of your cards? (BANKING) | Card_service_enquiry (Primary), General_Enquiry (Non-Primary) | Service_request, Card_service_enquiry | Incorrect Predictions; Predicted Primary Intent is same as the Non-Primary Ground Truth Label |
| Can other people top up my account? where did my funds come from? (BANKING) | verify_source_of_funds (Primary), topping_up_by_card (Non-Primary) | topping_up_by_card, verify_source_of_funds | Wrong Predictions - swapped ground-truth labels |
| Can you tell me my shopping list items, please? Is tomato on my shopping list? (CLINC) | shopping_list (Primary), account (Non-Primary) | shopping_list, shopping_list | Non-Primary label wrongly predicted |
| Change the name of your system. Your name from this point forward is george. (CLINC) | change_ai_name (Primary), change_user_name (Non-Primary) | change_ai_name, change_ai_name | Non-Primary label wrongly predicted |
| use my phone and connect please,tell me something that’ll make me laugh(CLINC) | sync_device (Primary), tell_joke (Non-Primary) | sync_device, tell_joke | Correct Predictions |
| will there be traffic on the way to walmart,can you help me with a rental car(CLINC) | traffic (Primary), car_rental (Non-Primary) | traffic, car_rental | Correct Predictions |
🔼 This table presents the performance of the RoBERTa-based Pointer Network Model (PNM) in detecting three intents simultaneously. It shows the accuracy of the model in identifying each of the three intents individually and then provides an average accuracy across all three. The results are broken down for fine-grained and coarse-grained intent labels and are presented for several datasets to demonstrate the generalizability of the method.
read the caption
Table 10: 3-Intent Detection by Roberta based PNM
Full paper#