↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Generating high-quality meme videos presents challenges. Existing methods either struggle with exaggerated facial expressions or compromise model generalization. Furthermore, many methods require optimizing all model parameters, hindering compatibility with existing models.
HelloMeme tackles these issues by introducing adapters into text-to-image models, specifically optimizing the attention mechanism related to 2D feature maps. This method uses spatial knitting attentions to effectively integrate high-level conditions (head poses, facial expressions) with fidelity-rich details from a reference image. The approach preserves the base model’s generalization capability and is compatible with SD1.5 and its derivatives. Experiments show significant performance improvements on meme video generation, showcasing the effectiveness of this novel technique.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel method for improving the performance of text-to-image diffusion models on complex downstream tasks, such as meme video generation. The method is efficient, compatible with existing open-source models, and achieves state-of-the-art results. This work opens new avenues for post-training large text-to-image models and improves the overall capabilities of diffusion models for various applications. The released codebase will also benefit the open-source community.
Visual Insights#

🔼 The figure illustrates the architecture of the proposed HelloMeme model, which consists of three main modules: HMReferenceNet, HMControlNet, and HMDenoisingNet. HMReferenceNet extracts detailed features from a reference image, capturing high-fidelity information. HMControlNet extracts high-level features, such as head pose and facial expression, from driving images. These two feature sets are then fed into HMDenoisingNet, which performs the core denoising process to generate a new image or video frame. Optionally, a fine-tuned Animatediff module can be integrated into HMDenoisingNet for generating continuous video frames.
read the caption
Figure 1: Our solution consists of three modules. HMReferenceNet is used to extract Fidelity-Rich features from the reference image, while HMControlNet extracts high-level features such as head pose and facial expression information. HMDenoisingNet receives both sets of features and performs the core denoising function. It can also integrate a fine-tuned Animatediff module to generate continuous video frames.
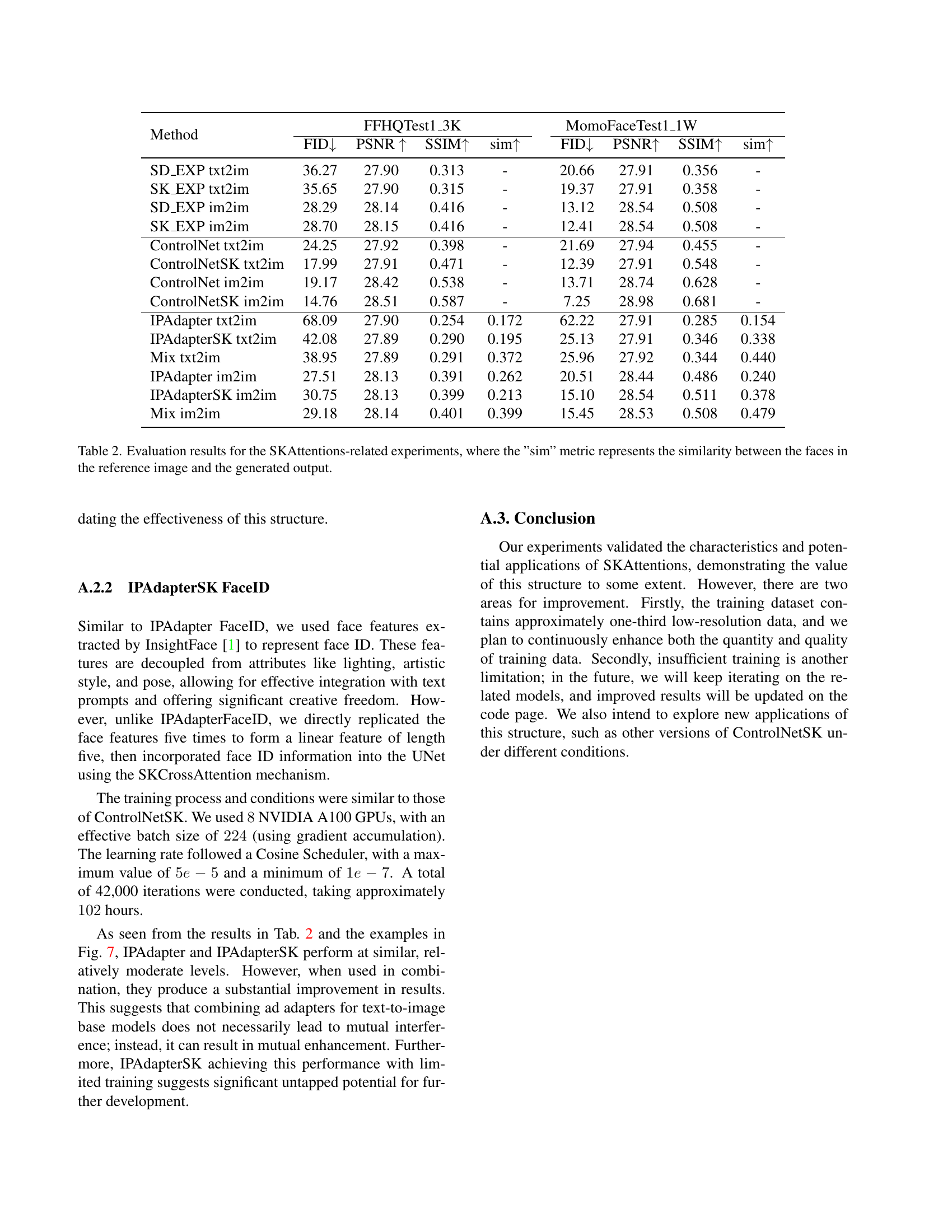
| Method | FID ↓ | FVD ↓ | PSNR ↑ | SSIM ↑ | LPIPS ↑ | FID ↓ | AED ↓ | APD ↓ | |
|---|---|---|---|---|---|---|---|---|---|
| Liveportrait[5] | 43.84 | 262.19 | 30.66 | 0.649 | 0.228 | 313.09 | 1.02 | 0.204 | |
| Aniportrait[19] | 38.34 | 384.98 | 30.78 | 0.695 | 0.147 | 309.52 | 0.96 | 0.068 | |
| FollowyourEmoji[11] | 39.11 | 301.71 | 30.91 | 0.695 | 0.152 | 312.46 | 0.97 | 0.071 | |
| Ours | 37.69 | 231.55 | 31.08 | 0.704 | 0.143 | 304.35 | 0.81 | 0.051 |
🔼 This table compares the performance of the proposed method with state-of-the-art (SOTA) open-source methods for both self-reenactment and cross-reenactment tasks. Self-reenactment uses a video of a subject as both reference and driving input, while cross-reenactment uses a separate reference image and a driving video. The metrics used include Fréchet Inception Distance (FID), Fréchet Video Distance (FVD), Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), Learned Perceptual Image Patch Similarity (LPIPS), Average Expression Distance (AED), and Average Pose Distance (APD). Note that FVD calculations are based on randomly selecting 25 continuous frames from each video, leading to some variation in the absolute values but consistent relative rankings across multiple evaluations.
read the caption
Table 1: In comparing our method with the open-source SOTA, it’s important to note that during FVD evaluation, 25 continuous frames are randomly selected from each sample video to calculate the metrics. This leads to variations in the absolute values of test results each time; however, after multiple validations, we found that their relative rankings remain consistent with the values presented in the table.
In-depth insights#
Spatial Knitting Attention#
The research introduces Spatial Knitting Attention (SKA) as a novel mechanism to enhance attention mechanisms in diffusion models for image generation. Unlike traditional methods that flatten 2D feature maps before applying attention, SKA processes attention row-wise and then column-wise, mimicking the weaving process. This preserves the spatial structure information inherent in the 2D feature maps, improving model convergence and performance. The authors demonstrate SKA’s effectiveness through various experiments, showcasing its ability to fuse 2D feature maps with linear features efficiently and achieve superior results compared to standard Cross-Attention in tasks involving facial reenactment and meme video generation. The integration of SKA into the model is also lightweight and compatible with existing models, making it a valuable addition to the diffusion model architecture.
Meme Video Generation#
The research paper explores meme video generation using diffusion models, focusing on integrating spatial knitting attentions to embed high-level and fidelity-rich conditions. A key challenge addressed is the generation of exaggerated facial expressions and poses often found in memes. The proposed method utilizes three modules: HMReferenceNet extracts fidelity-rich features; HMControlNet extracts high-level features (head pose and facial expressions); and HMDenoisingNet combines these features for denoising and video generation. Spatial Knitting Attentions are crucial, efficiently fusing 2D feature maps with linear features while preserving spatial information. This approach improves performance under exaggerated expressions and poses and offers good compatibility with SD1.5 derivative models. The method also incorporates Animatediff to generate continuous video frames, improving inter-frame continuity. The integration of spatial knitting attention and the two-stage approach for video generation are highlighted as key innovations, contributing to improved video quality and fidelity. Results show significant improvements over other methods in both self-reenactment and cross-reenactment scenarios.
Adapter Optimization#
The research paper introduces a novel adapter optimization method for enhancing text-to-image diffusion models. The core innovation lies in the use of Spatial Knitting Attentions (SKA), a mechanism that preserves the spatial structure of 2D feature maps during attention operations, unlike traditional methods which flatten these maps. This approach significantly improves the performance of adapters, particularly in tasks involving exaggerated facial expressions and poses found in meme video generation. The method is designed to be compatible with SD1.5 derived models, requiring the optimization of only the adapter’s parameters, thus preserving the generalization ability of the base model. Experimental results demonstrate that SKA outperforms traditional attention mechanisms, achieving significant improvements in both objective metrics and subjective visual quality of generated videos. The approach also integrates a fine-tuned Animatediff module for smoother and more realistic video generation. The resulting method shows promise for extending diffusion models to complex downstream tasks while maintaining ease of implementation and compatibility with the open-source community.
Diffusion Model Training#
The provided text does not contain a section explicitly titled ‘Diffusion Model Training’. Therefore, a summary cannot be generated. To provide a relevant summary, please provide the text from the section of the research paper that is titled ‘Diffusion Model Training’.
Future Research#
The provided text does not contain a section specifically titled “Future Research.” Therefore, I cannot provide a summary of such a section. To generate a response, please provide the text from the “Future Research” section of your PDF.
More visual insights#
More on figures

🔼 The figure shows the architecture of SKCrossAttention, a mechanism that fuses 2D feature maps with linear features. Unlike standard cross-attention which flattens the 2D feature map before processing, SKCrossAttention performs cross-attention in two stages: first row-wise, then column-wise. This approach, inspired by the way threads are interwoven in knitting, preserves the spatial structure of the 2D feature map, leading to improved performance, especially when dealing with high-level conditions like exaggerated facial expressions.
read the caption
Figure 2: This is the structural diagram of SKCrossAttention, which utilizes the Spatial Knitting Attention mechanism to fuse 2D feature maps with linear features. It performs cross-attention first row by row, then column by column.

🔼 The figure shows the architecture of the SKReferenceAttention module. This module takes two 2D feature maps as input. First, it concatenates these maps row-wise. Then, it performs self-attention on each row, which allows the model to capture relationships between features within each row. After the self-attention, only the first half of each row is kept. This process is then repeated column-wise: the remaining feature maps are concatenated column-wise, self-attention is applied to each column, and only the first half of each column is retained. The output is a refined 2D feature map that incorporates information from both input maps.
read the caption
Figure 3: This is the structural diagram of SKReferenceAttention, which uses the Spatial Knitting Attention mechanism to fuse two 2D feature maps. Specifically, the two feature maps are first concatenated row by row, followed by performing self-attention along the rows. Afterward, only the first half of each row is retained. A similar operation is then performed column by column.

🔼 This figure displays a comparison of self-reenactment performance across five different methods: ground truth, Liveportrait, Aniportrait, FollowYourEmoji, and the proposed method. Each method is represented by five frames sampled from a generated video to illustrate the visual results. The first row shows the ground truth video, with the initial frame outlined in red dashed lines to highlight its use as the reference image.
read the caption
(a) Ground Truth

🔼 This figure shows a visual comparison of meme video generation results from the Liveportrait method. The image displays five frames from a video sequence, showcasing the method’s ability to generate talking head videos. This allows for a direct visual assessment of the video quality and the method’s performance on the task. The specific frames shown likely highlight key aspects of the video generation process, such as facial expressions, head movements and overall visual fidelity.
read the caption
(b) Liveportrait

🔼 The figure shows a comparison of self-reenactment performance between different methods. Specifically, it displays five frames sampled from a video generated by the Aniportrait method, where the first frame of the video serves as the reference image. This visual comparison helps to illustrate the quality of video generation, particularly in terms of fidelity and consistency of facial expressions.
read the caption
(c) Aniportrait

🔼 This figure shows results from the FollowYourEmoji method. It is part of a qualitative comparison of several methods for self-reenactment performance. The image displays five frames sampled from a video generated by FollowYourEmoji, showcasing its ability to generate talking video. The first frame serves as a reference image and is outlined in red dashed lines. The comparison allows assessment of the visual quality and accuracy of facial expressions and head poses compared to the ground truth.
read the caption
(d) FollowyourEmoji

🔼 This figure shows a video frame generated by the proposed ‘HelloMeme’ method, demonstrating the quality of facial reenactment and the ability to generate realistic meme videos. It is part of a comparison with other state-of-the-art methods (a-d) to illustrate the superior performance of the proposed method in handling exaggerated facial expressions and generating smooth, continuous video frames.
read the caption
(e) Ours

🔼 Figure 4 presents a qualitative comparison of self-reenactment performance across five different methods. Each method is shown with five frames from a generated video sequence. The first row displays the ground truth video frames, clearly indicating the initial frame used as a reference image via a red dashed outline. This visualization directly allows for comparison between the ground truth and the outputs of each method, highlighting differences in facial expression and head pose accuracy. The figure directly supports the claims made in the paper regarding performance.
read the caption
Figure 4: Examples of self-reenactment performance comparisons, with five frames sampled from each video for illustration. The first row represents the ground truth, with the initial frame serving as the reference image (outlined in red dashed lines).

🔼 This figure compares the results of two experiments: SD_EXP and SK_EXP. SD_EXP uses the standard cross-attention mechanism in the Stable Diffusion 1.5 model, while SK_EXP replaces it with the Spatial Knitting Attention (SKA) mechanism. The comparison demonstrates the impact of SKA on image generation, particularly in terms of visual quality and adherence to various conditions or prompts. The results show image samples generated under different conditions (text-to-image and image-to-image) for each method, highlighting the effectiveness of SKA in enhancing image generation.
read the caption
Figure 5: SD_EXP vs. SK_EXP

🔼 This figure compares the results of using ControlNet and ControlNetSK for image generation. ControlNet is a pre-existing method, while ControlNetSK incorporates Spatial Knitting Attention. Both methods were tested under the same conditions. The figure visually demonstrates the outputs for different tasks (text-to-image and image-to-image) using both methods. The Ground Truth images are also provided for reference. This allows for a direct visual comparison of the image quality and fidelity generated by each method.
read the caption
Figure 6: ControlNet vs. ControlNetSK

🔼 This figure compares the performance of IPAdapter and IPAdapterSK, two methods for integrating face features into diffusion models. The top row shows examples where only text was used as input to the model, and the second row shows examples where both text and images were used as input. IPAdapterSK uses Spatial Knitting Attention, which improved the model’s ability to generate high-quality images, even when given limited information. The ‘Mix’ column shows a combination of both approaches.
read the caption
Figure 7: IPAdapter vs. IPAdapterSK
Full paper#