↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current GUI agent development heavily relies on closed-source, high-performing models, hindering open-source research progress due to their performance limitations, particularly in GUI grounding and out-of-distribution scenarios. Existing open-source GUI action models often struggle with generalization and real-world applicability because of limited training data and issues with action naming inconsistencies across platforms. This research addresses this critical gap by introducing OS-Atlas.
OS-Atlas tackles these challenges through two key innovations: First, a new open-source toolkit and the largest open-source cross-platform GUI grounding corpus were created, generating a massive dataset that encompasses various platforms and applications. Second, OS-Atlas utilizes innovative model training techniques, including a unified action space to address action naming conflicts across platforms, leading to significantly improved generalization capabilities. Extensive evaluation across six benchmarks demonstrates significant performance improvements over previous state-of-the-art models. The findings highlight the potential for open-source VLMs to achieve comparable performance with commercial counterparts. This work paves the way for broader adoption of open-source solutions in the field.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in GUI agent development due to its release of the largest open-source cross-platform GUI grounding corpus and the introduction of OS-Atlas, a foundational action model that significantly outperforms existing models. It opens new avenues for research by providing a robust and accessible toolkit, dataset, and model for developing generalist GUI agents, addressing limitations of existing open-source solutions and paving the way for more advanced and practical applications.
Visual Insights#

🔼 This figure illustrates the OS-Atlas model’s functionality and performance. The left panel shows the three operational modes of OS-Atlas: Grounding Mode (predicting coordinates from instructions, potentially using a planner), Action Mode (independently solving step-level tasks across platforms, including zero-shot out-of-distribution scenarios), and Agent Mode (fine-tuned for specific tasks). The right panel provides a visual comparison of OS-Atlas’s performance against other state-of-the-art models, highlighting its superior capabilities.
read the caption
Figure 1: (Left) The OS-Atlas model operates in three distinct modes to cater to various research needs. In Grounding mode, OS-Atlas predicts element coordinates based on user instructions and can be integrated with a planner module to create a complete agent. In Action mode, OS-Atlas functions independently to solve step-level agent tasks universally across different platforms and applications, even in zero-shot OOD scenarios. In Agent mode, OS-Atlas undergoes further supervised fine-tuning to address specific agent tasks. (Right) Overall performance comparisons between OS-Atlas and other state-of-the-art models.
| Dataset | #Screenshots | #Screenshots | #Screenshots | Open | #Elements |
|---|---|---|---|---|---|
| Web | Mobile | Desktop | Source | ||
| SeeClick | 270K | 94K | - | ✓ | 3.3M |
| Ferret-UI | - | 124K | - | ✗ | <1M |
| GUICourse | 73K | 9K | - | ✓ | 10.7M |
| CogAgent | 400K | - | - | ✗ | 70M |
| OS-Atlas | 1.9M | 285K | 54K | ✓ | 13.58M |
🔼 This table provides a quantitative comparison of the GUI grounding datasets used in the paper against existing efforts. It shows the number of screenshots and GUI elements available in each dataset, highlighting the scale of the OS-Atlas dataset relative to others. The table distinguishes between open-source and closed-source datasets, and for open-source datasets, only the publicly available data is included in the count. This allows for a clear understanding of the relative size and scope of the GUI grounding data used in the OS-Atlas project.
read the caption
Table 1: Statistics of the grounding data we collected compared to existing efforts. (For open-source datasets, we only count the amount of data made publicly available.)
In-depth insights#
GUI Agent Foundation#
The research paper section ‘GUI Agent Foundation’ introduces OS-Atlas, a novel action model designed to overcome limitations of existing GUI agents. It addresses the challenges of limited open-source VLM performance in GUI grounding and out-of-distribution (OOD) scenarios by introducing innovations in both data and modeling. A key contribution is the creation of a large, open-source, cross-platform GUI grounding corpus synthesized using a newly developed toolkit. This dataset enables more robust training and improved generalization, particularly in handling unseen interfaces. The model’s effectiveness is demonstrated through comprehensive evaluation on multiple benchmarks, showcasing substantial performance gains compared to prior state-of-the-art methods. This work significantly advances the development of generalist GUI agents, offering a powerful, open-source alternative to commercial solutions and highlighting the importance of large-scale, diverse datasets for enhanced model capabilities.
Cross-Platform Data#
The research emphasizes the creation of a large-scale, open-source, cross-platform GUI grounding corpus exceeding 13 million GUI elements. This dataset is a significant advancement, addressing the limitations of previous datasets, which were often limited in scale or platform coverage. The data synthesis toolkit developed for this project enables automatic data generation across various platforms (Windows, macOS, Linux, Android, and Web), reducing engineering efforts for future research. This multi-platform approach allows for more robust model training and better generalization to unseen interfaces. The inclusion of desktop GUI data, previously lacking in other datasets, makes this corpus particularly valuable. Moreover, the corpus addresses the issue of action naming inconsistencies across different platforms, thereby facilitating more effective model training. Overall, this extensive and diverse dataset is a key contributor to the improved performance of the OS-ATLAS model, particularly in out-of-distribution scenarios.
Action Model Design#
The research paper’s ‘Action Model Design’ section delves into the architecture and functionality of the OS-Atlas model, a foundational action model for generalist GUI agents. Key design elements include its operation in three distinct modes: Grounding, Action, and Agent. The Grounding Mode focuses on locating GUI elements based on user instructions. Action Mode enables the model to execute step-level tasks across platforms independently. Agent Mode involves further supervised fine-tuning for specific agent tasks. A unified action space is implemented to resolve conflicts in action naming across diverse platforms. This approach standardizes actions (like ‘click,’ ’type,’ ‘scroll’), enhancing model generalizability and performance. The model also utilizes basic and custom actions, the latter being platform-specific and allowing for flexibility and adaptability. The design emphasizes the need for a large, high-quality, multi-platform GUI grounding dataset, which OS-Atlas addresses through a novel data synthesis toolkit.
OOD Generalization#
The research paper investigates the challenge of Out-of-Distribution (OOD) generalization in the context of Graphical User Interface (GUI) agents. Existing open-source Vision-Language Models (VLMs) struggle with OOD scenarios due to limitations in training data and model architecture. The paper highlights that commercial VLMs significantly outperform open-source counterparts, especially in GUI grounding. To address this, OS-Atlas, a foundational GUI action model, is proposed. OS-Atlas leverages a newly created open-source, cross-platform GUI grounding corpus exceeding 13 million elements, enabling more robust training. Through extensive benchmarking across multiple platforms, OS-Atlas shows significant improvements over previous state-of-the-art models, demonstrating enhanced OOD generalization capabilities. This success underscores the importance of both high-quality, diverse datasets and innovative model training techniques for advancing open-source VLM-based GUI agents.
Future of GUI Agents#
The provided text does not contain a section specifically titled ‘Future of GUI Agents’. Therefore, a summary cannot be generated. To generate a summary, please provide the relevant text from the research paper.
More visual insights#
More on figures

🔼 The figure illustrates the two-stage training process of the OS-Atlas model. The first stage involves large-scale pre-training on a dataset of 13 million GUI grounding data points to create the OS-Atlas-Base model. This pre-training equips the model with a strong understanding of GUI screenshots and their constituent elements. The second stage consists of multitask fine-tuning using agent data. This fine-tuning adapts the pre-trained model to solve various agent tasks, ultimately resulting in the final OS-Atlas model, which excels at GUI grounding and out-of-distribution agentic tasks. The diagram visually depicts the flow of data and the transformation of the model through these two stages.
read the caption
Figure 2: Overall training pipeline of OS-Atlas. We first perform large-scale pre-training using 13 million GUI grounding data collected to build OS-Atlas-Base. Next, we conduct multitask fine-tuning on agent data, resulting in OS-Atlas.

🔼 This figure shows the relationship between the amount of grounding data used to train the OS-Atlas-Base model and its performance on three different GUI domains (web, desktop, and mobile). Two performance metrics are tracked: grounding accuracy (percentage of correctly located GUI elements) and Intersection over Union (IoU, a measure of the overlap between the predicted and ground truth bounding boxes). The graph illustrates that increased training data correlates with improved performance, especially for IoU. The web domain, with nearly 10 million elements, shows the strongest correlation, highlighting the potential of larger datasets.
read the caption
Figure 3: The effect of grounding data scaling on two metrics. The performances on three different domains are reported.

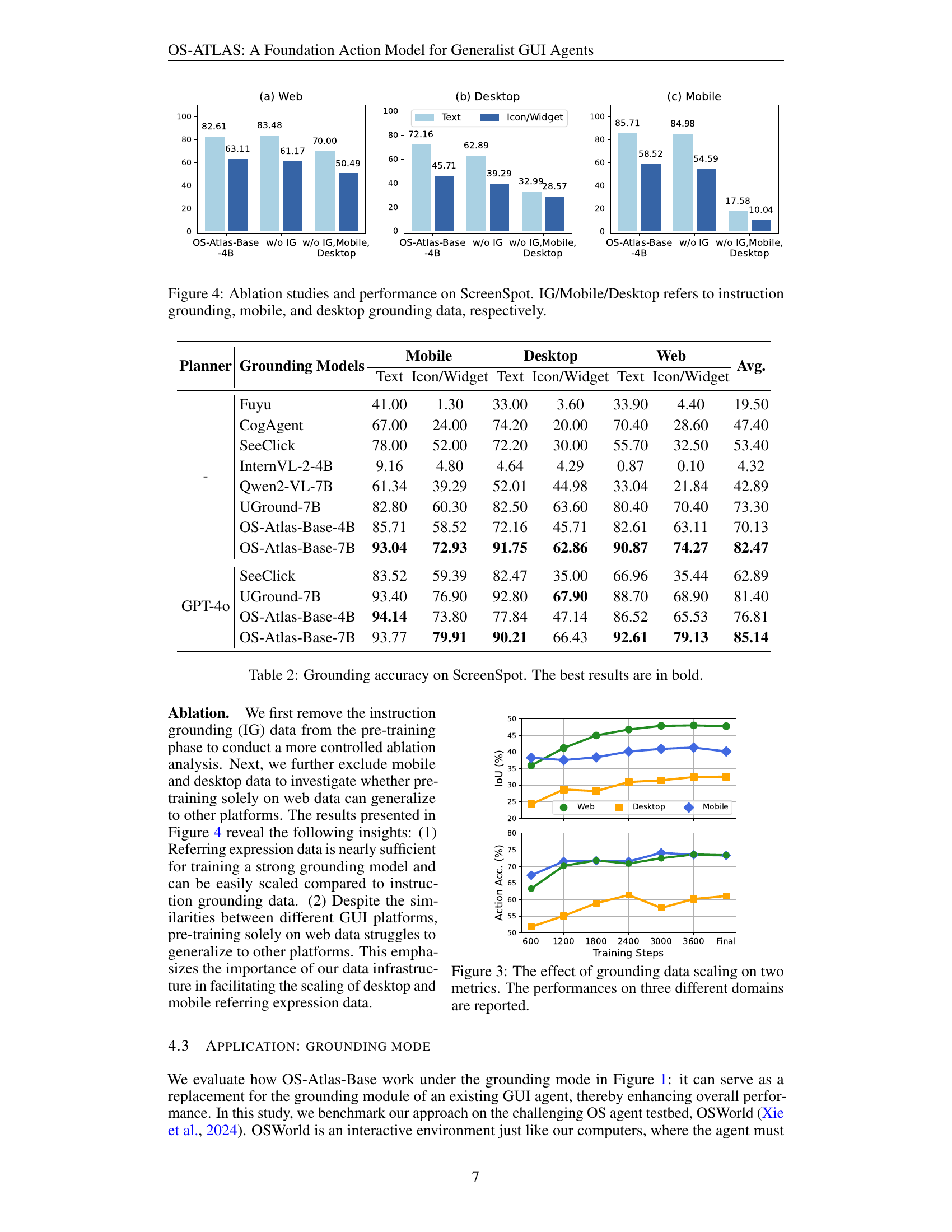
🔼 This figure presents ablation study results and performance comparisons on the ScreenSpot benchmark for GUI grounding. It shows the impact of different data sources on the model’s performance. Specifically, it compares results when instruction grounding data (IG), mobile GUI data, and desktop GUI data are included or excluded from training, showcasing the effect of various data modalities on the model’s ability to perform GUI grounding tasks accurately across different platforms (web, desktop, and mobile). The charts illustrate the impact of each data source on both text-based and icon/widget-based instructions.
read the caption
Figure 4: Ablation studies and performance on ScreenSpot. IG/Mobile/Desktop refers to instruction grounding, mobile, and desktop grounding data, respectively.

🔼 Figure 5 shows the results of ablation studies conducted on the zero-shot out-of-distribution (OOD) setting of the OS-Atlas model. The ablation studies were performed to investigate the impact of two key components of the model: grounding pre-training and the unified action space. The figure presents step-wise success rate and grounding accuracy for each ablation experiment. The results are shown separately for three different platforms: web, desktop, and mobile, demonstrating the effect of the ablations across various GUI types.
read the caption
Figure 5: Ablation studies on the zero-shot OOD setting. The results are reported respectively across three platforms.

🔼 Figure 6 shows the performance improvement achieved by OS-Atlas-Pro. OS-Atlas-Pro is a version of OS-Atlas that leverages a larger dataset for multitask fine-tuning, leading to enhanced performance across three domains: Web, Mobile, and Desktop. The chart visually compares the average performance of OS-Atlas (both 4B and 7B versions) with that of OS-Atlas-Pro across these domains. The results demonstrate the positive impact of more extensive fine-tuning on model performance.
read the caption
Figure 6: OS-Atlas-Pro evaluation results.

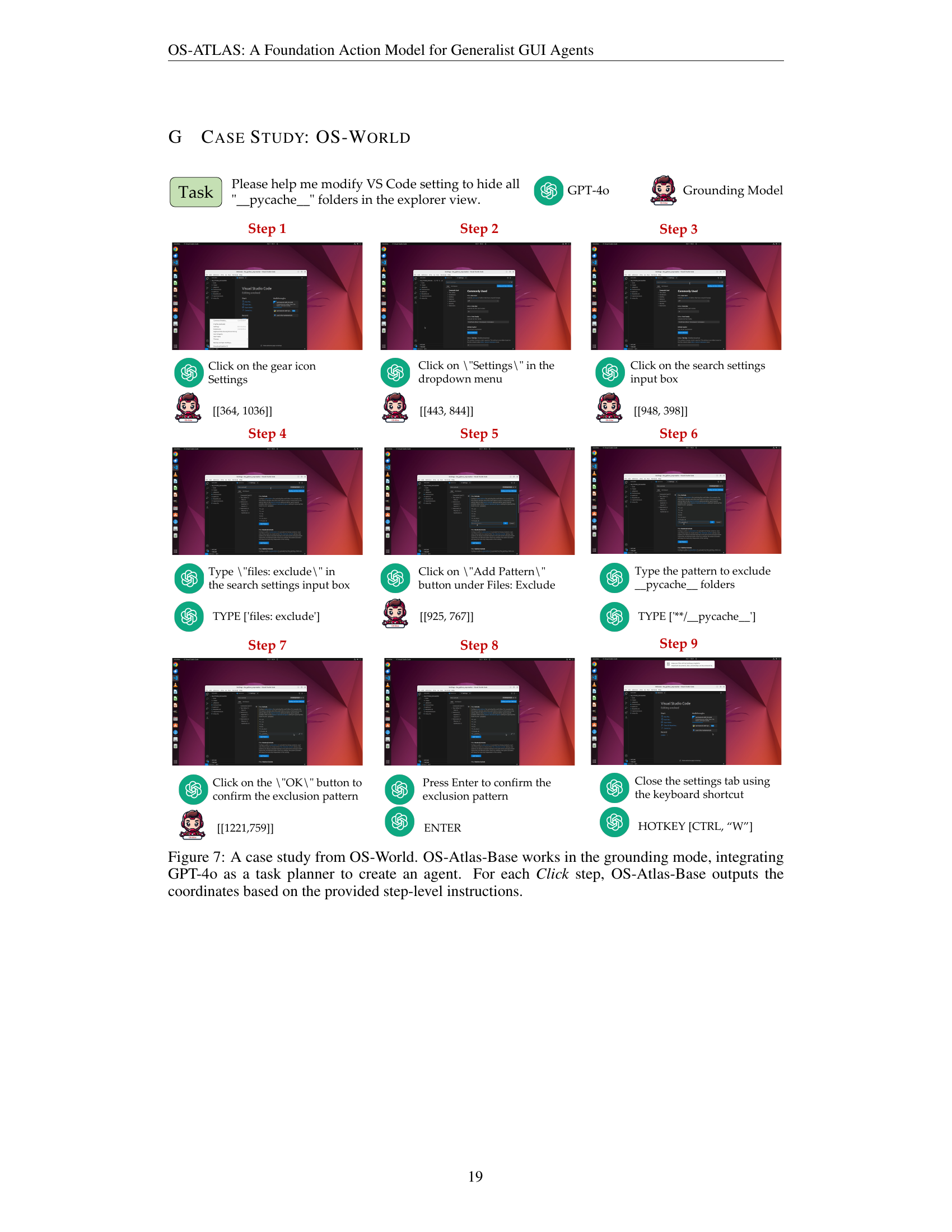
🔼 Figure 7 presents a case study demonstrating OS-Atlas-Base’s functionality within the OS-World environment. OS-Atlas-Base operates in grounding mode, collaborating with GPT-40 (acting as a task planner). The process involves GPT-40 generating a sequence of steps to accomplish a task (hiding ‘.pycache__’ folders in VS Code’s explorer). For each ‘Click’ action within these steps, OS-Atlas-Base accurately predicts the necessary coordinates, highlighting its ability to translate high-level instructions into precise, executable actions.
read the caption
Figure 7: A case study from OS-World. OS-Atlas-Base works in the grounding mode, integrating GPT-4o as a task planner to create an agent. For each Click step, OS-Atlas-Base outputs the coordinates based on the provided step-level instructions.
More on tables
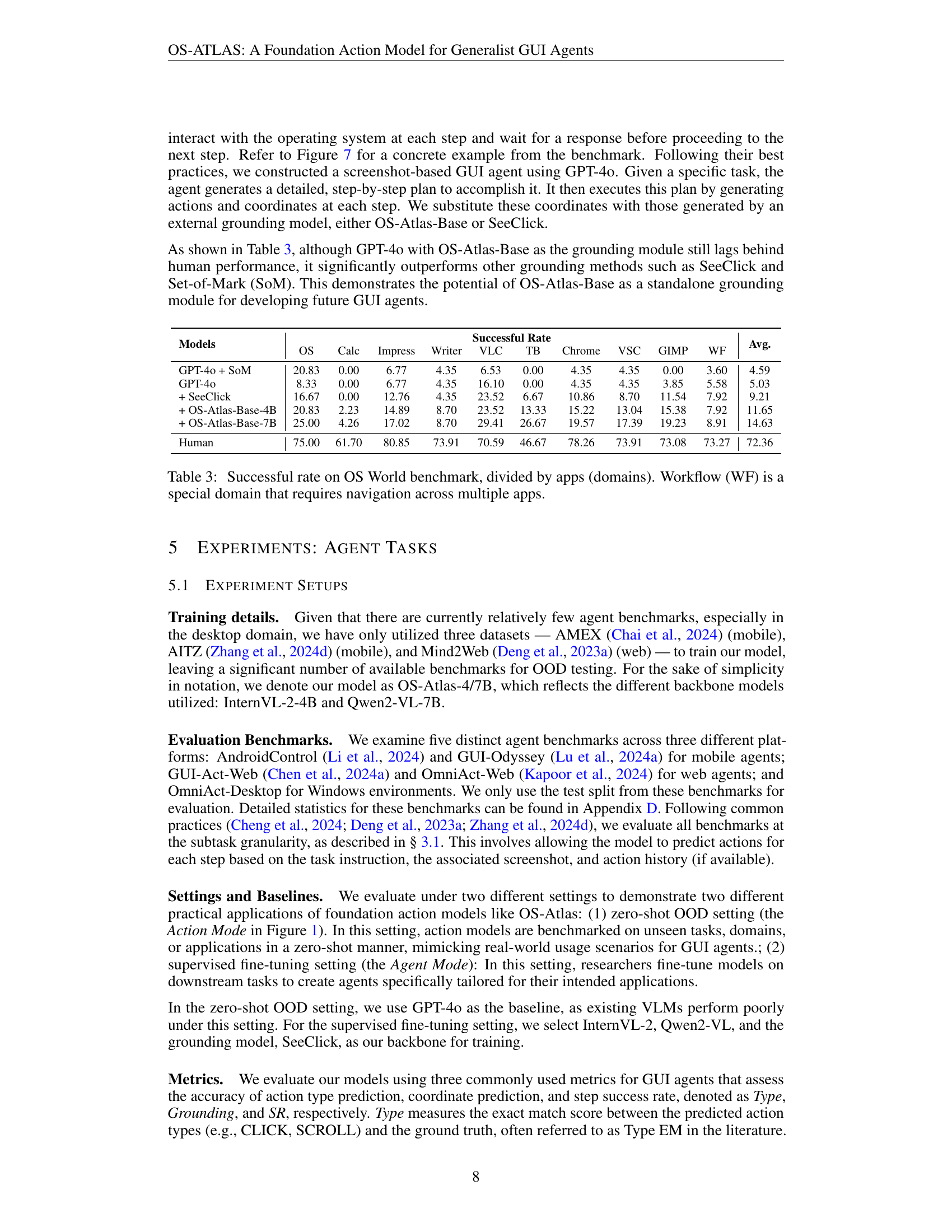
| Planner | Grounding Models | Mobile Text | Mobile Icon/Widget | Desktop Text | Desktop Icon/Widget | Web Text | Web Icon/Widget | Avg. |
|---|---|---|---|---|---|---|---|---|
| - | Fuyu | 41.00 | 1.30 | 33.00 | 3.60 | 33.90 | 4.40 | 19.50 |
| CogAgent | 67.00 | 24.00 | 74.20 | 20.00 | 70.40 | 28.60 | 47.40 | |
| SeeClick | 78.00 | 52.00 | 72.20 | 30.00 | 55.70 | 32.50 | 53.40 | |
| InternVL-2-4B | 9.16 | 4.80 | 4.64 | 4.29 | 0.87 | 0.10 | 4.32 | |
| Qwen2-VL-7B | 61.34 | 39.29 | 52.01 | 44.98 | 33.04 | 21.84 | 42.89 | |
| UGround-7B | 82.80 | 60.30 | 82.50 | 63.60 | 80.40 | 70.40 | 73.30 | |
| OS-Atlas-Base-4B | 85.71 | 58.52 | 72.16 | 45.71 | 82.61 | 63.11 | 70.13 | |
| OS-Atlas-Base-7B | 93.04 | 72.93 | 91.75 | 62.86 | 90.87 | 74.27 | 82.47 | |
| GPT-4o | SeeClick | 83.52 | 59.39 | 82.47 | 35.00 | 66.96 | 35.44 | 62.89 |
| UGround-7B | 93.40 | 76.90 | 92.80 | 67.90 | 88.70 | 68.90 | 81.40 | |
| OS-Atlas-Base-4B | 94.14 | 73.80 | 77.84 | 47.14 | 86.52 | 65.53 | 76.81 | |
| OS-Atlas-Base-7B | 93.77 | 79.91 | 90.21 | 66.43 | 92.61 | 79.13 | 85.14 |
🔼 This table presents the performance of different Vision-Language Models (VLMs) on the ScreenSpot benchmark for GUI grounding tasks. It shows the accuracy of each model in predicting the location of GUI elements based on textual descriptions. The models are evaluated under two settings: one with a planner module and another without. Results are broken down by platform (web, desktop, mobile), element type (text, icon/widget), and model. OS-Atlas-Base consistently outperforms other models, demonstrating its effectiveness in GUI grounding.
read the caption
Table 2: Grounding accuracy on ScreenSpot. The best results are in bold.
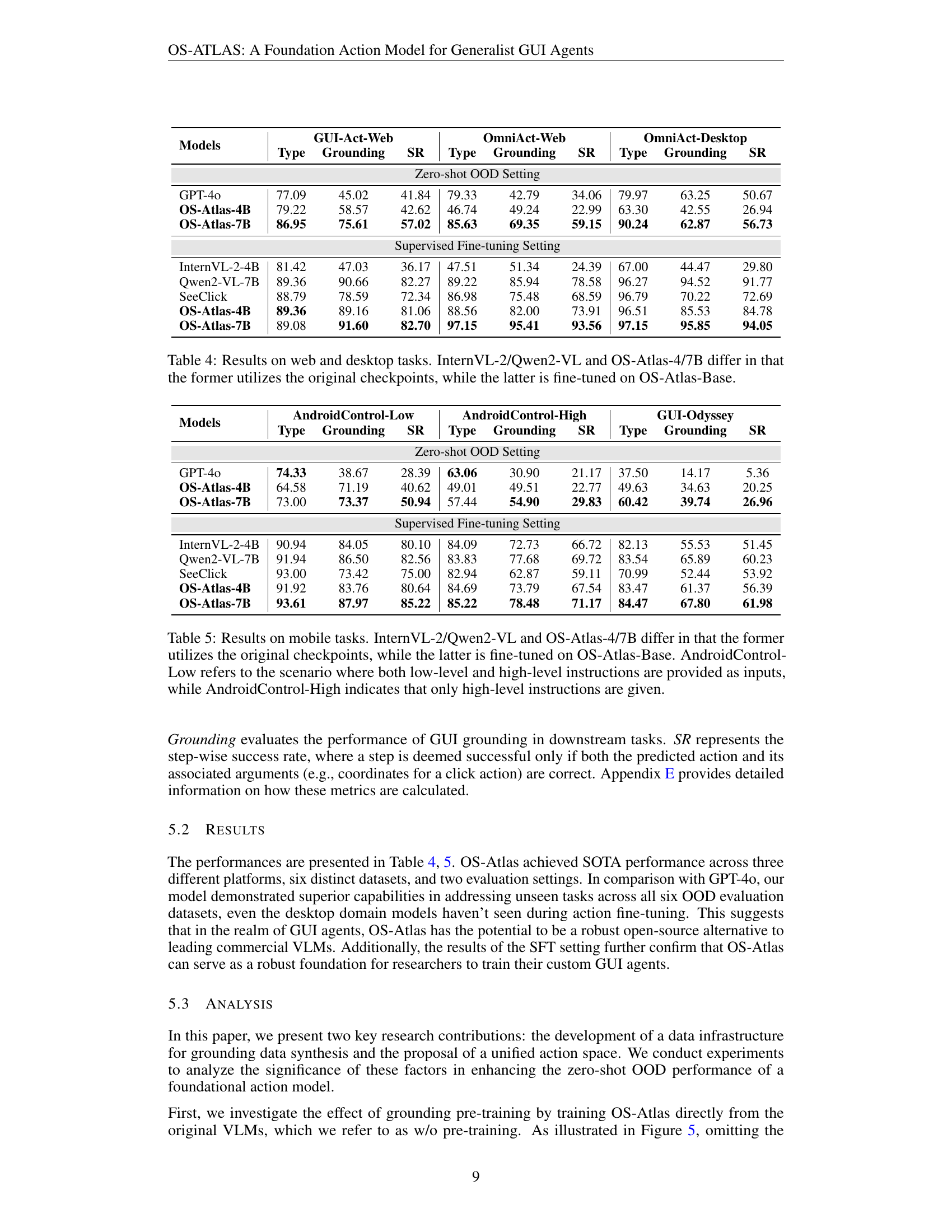
| Models | OS | Calc | Impress | Writer | VLC | TB | Chrome | VSC | GIMP | WF | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|---|
| GPT-4o + SoM | 20.83 | 0.00 | 6.77 | 4.35 | 6.53 | 0.00 | 4.35 | 4.35 | 0.00 | 3.60 | 4.59 |
| GPT-4o | 8.33 | 0.00 | 6.77 | 4.35 | 16.10 | 0.00 | 4.35 | 4.35 | 3.85 | 5.58 | 5.03 |
| + SeeClick | 16.67 | 0.00 | 12.76 | 4.35 | 23.52 | 6.67 | 10.86 | 8.70 | 11.54 | 7.92 | 9.21 |
| + OS-Atlas-Base-4B | 20.83 | 2.23 | 14.89 | 8.70 | 23.52 | 13.33 | 15.22 | 13.04 | 15.38 | 7.92 | 11.65 |
| + OS-Atlas-Base-7B | 25.00 | 4.26 | 17.02 | 8.70 | 29.41 | 26.67 | 19.57 | 17.39 | 19.23 | 8.91 | 14.63 |
| Human | 75.00 | 61.70 | 80.85 | 73.91 | 70.59 | 46.67 | 78.26 | 73.91 | 73.08 | 73.27 | 72.36 |
🔼 This table presents the success rate of different models on the OS World benchmark, categorized by application domains. The OS World benchmark involves tasks that require interactions with multiple applications. The models are evaluated on their ability to successfully complete each task, and the success rates are broken down by application (e.g., Calculator, Impress, VLC, etc.) to show performance variations across different types of software. The ‘Workflow’ (WF) category represents a unique set of tasks that demand navigation and interaction across various applications, indicating a higher level of complexity.
read the caption
Table 3: Successful rate on OS World benchmark, divided by apps (domains). Workflow (WF) is a special domain that requires navigation across multiple apps.
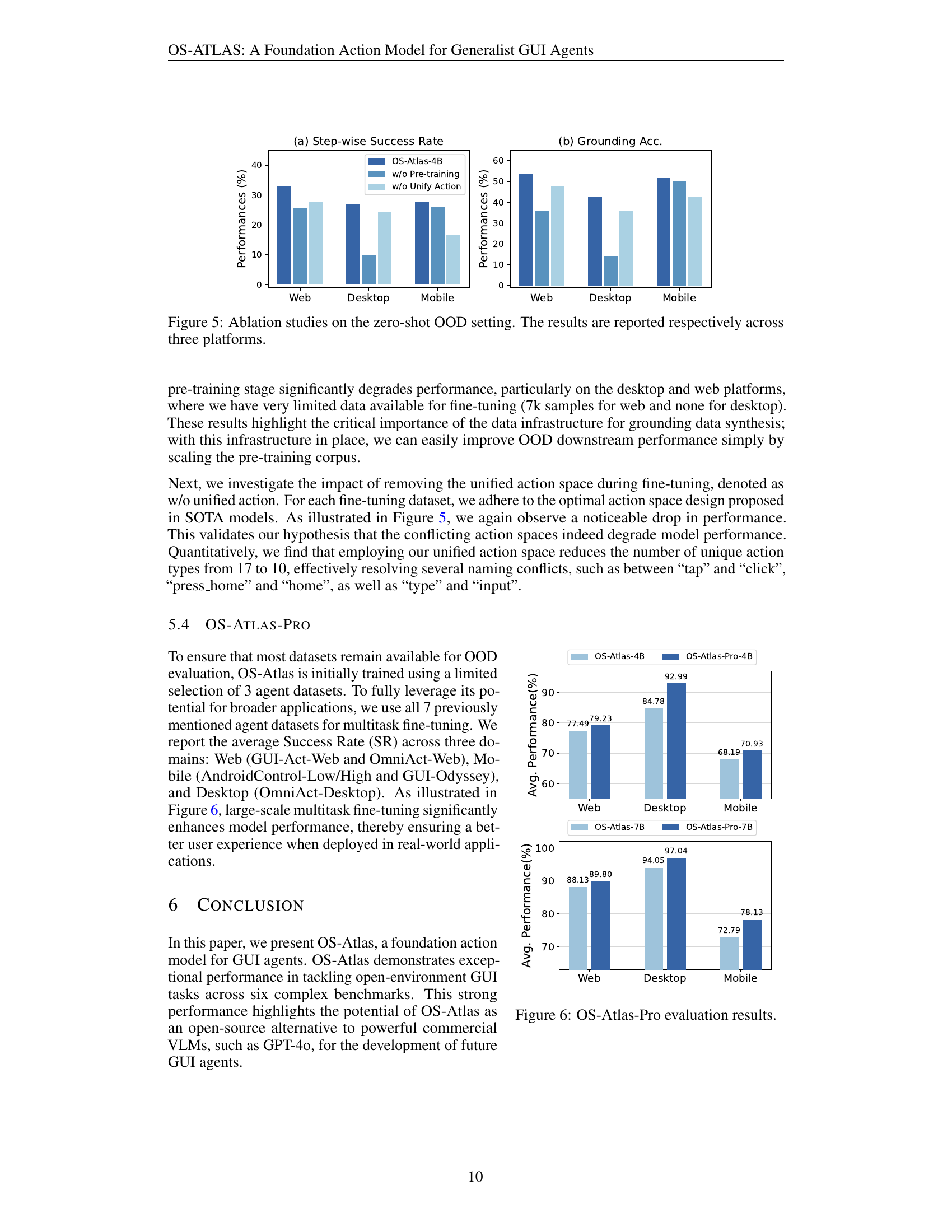
| Models | GUI-Act-Web Type | GUI-Act-Web Grounding | GUI-Act-Web SR | OmniAct-Web Type | OmniAct-Web Grounding | OmniAct-Web SR | OmniAct-Desktop Type | OmniAct-Desktop Grounding | OmniAct-Desktop SR |
|---|---|---|---|---|---|---|---|---|---|
| Zero-shot OOD Setting | |||||||||
| GPT-4o | 77.09 | 45.02 | 41.84 | 79.33 | 42.79 | 34.06 | 79.97 | 63.25 | 50.67 |
| OS-Atlas-4B | 79.22 | 58.57 | 42.62 | 46.74 | 49.24 | 22.99 | 63.30 | 42.55 | 26.94 |
| OS-Atlas-7B | 86.95 | 75.61 | 57.02 | 85.63 | 69.35 | 59.15 | 90.24 | 62.87 | 56.73 |
| Supervised Fine-tuning Setting | |||||||||
| InternVL-2-4B | 81.42 | 47.03 | 36.17 | 47.51 | 51.34 | 24.39 | 67.00 | 44.47 | 29.80 |
| Qwen2-VL-7B | 89.36 | 90.66 | 82.27 | 89.22 | 85.94 | 78.58 | 96.27 | 94.52 | 91.77 |
| SeeClick | 88.79 | 78.59 | 72.34 | 86.98 | 75.48 | 68.59 | 96.79 | 70.22 | 72.69 |
| OS-Atlas-4B | 89.36 | 89.16 | 81.06 | 88.56 | 82.00 | 73.91 | 96.51 | 85.53 | 84.78 |
| OS-Atlas-7B | 89.08 | 91.60 | 82.70 | 97.15 | 95.41 | 93.56 | 97.15 | 95.85 | 94.05 |
🔼 Table 4 presents the results of experiments conducted on web and desktop tasks using different models. A key distinction highlighted is the training approach: InternVL-2 and Qwen2-VL utilize their original checkpoints, while OS-Atlas-4/7B is fine-tuned using OS-Atlas-Base as a foundation. This comparison allows for an analysis of performance gains achieved through fine-tuning.
read the caption
Table 4: Results on web and desktop tasks. InternVL-2/Qwen2-VL and OS-Atlas-4/7B differ in that the former utilizes the original checkpoints, while the latter is fine-tuned on OS-Atlas-Base.
| Models | AndroidControl-Low | AndroidControl-High | GUI-Odyssey | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Type | Grounding | SR | Type | Grounding | SR | Type | Grounding | SR | |
| — | — | — | — | — | — | — | — | — | — |
| Zero-shot OOD Setting | |||||||||
| GPT-4o | 74.33 | 38.67 | 28.39 | 63.06 | 30.90 | 21.17 | 37.50 | 14.17 | 5.36 |
| OS-Atlas-4B | 64.58 | 71.19 | 40.62 | 49.01 | 49.51 | 22.77 | 49.63 | 34.63 | 20.25 |
| OS-Atlas-7B | 73.00 | 73.37 | 50.94 | 57.44 | 54.90 | 29.83 | 60.42 | 39.74 | 26.96 |
| Supervised Fine-tuning Setting | |||||||||
| InternVL-2-4B | 90.94 | 84.05 | 80.10 | 84.09 | 72.73 | 66.72 | 82.13 | 55.53 | 51.45 |
| Qwen2-VL-7B | 91.94 | 86.50 | 82.56 | 83.83 | 77.68 | 69.72 | 83.54 | 65.89 | 60.23 |
| SeeClick | 93.00 | 73.42 | 75.00 | 82.94 | 62.87 | 59.11 | 70.99 | 52.44 | 53.92 |
| OS-Atlas-4B | 91.92 | 83.76 | 80.64 | 84.69 | 73.79 | 67.54 | 83.47 | 61.37 | 56.39 |
| OS-Atlas-7B | 93.61 | 87.97 | 85.22 | 85.22 | 78.48 | 71.17 | 84.47 | 67.80 | 61.98 |
🔼 Table 5 presents the performance comparison of different models on mobile agent tasks. It shows the accuracy of action type prediction (Type), coordinate prediction (Grounding), and step success rate (SR) for several benchmarks. The key difference highlighted is between models using original checkpoints (InternVL-2/Qwen2-VL) and those fine-tuned on OS-Atlas-Base (OS-Atlas-4/7B). The table also distinguishes between two scenarios within the AndroidControl benchmark: one where both low-level and high-level instructions are provided, and another where only high-level instructions are given.
read the caption
Table 5: Results on mobile tasks. InternVL-2/Qwen2-VL and OS-Atlas-4/7B differ in that the former utilizes the original checkpoints, while the latter is fine-tuned on OS-Atlas-Base. AndroidControl-Low refers to the scenario where both low-level and high-level instructions are provided as inputs, while AndroidControl-High indicates that only high-level instructions are given.
| Unified Action Space Prompt | |
|---|---|
| You are a foundational action model capable of automating tasks across various digital environments, including desktop systems like Windows, macOS, and Linux, as well as mobile platforms such as Android and iOS. You also excel in web browser environments. You will interact with digital devices in a human-like manner: by reading screenshots, analyzing them, and taking appropriate actions. | |
| Your expertise covers two types of digital tasks: - Grounding: Given a screenshot and a description, you assist users in locating elements mentioned. Sometimes, you must infer which elements best fit the description when they aren’t explicitly stated. - Executable Language Grounding: With a screenshot and task instruction, your goal is to determine the executable actions needed to complete the task. You should only respond with the Python code in the format as described below: You are now operating in Executable Language Grounding mode. Your goal is to help users accomplish tasks by suggesting executable actions that best fit their needs. Your skill set includes both basic and custom actions: | |
| 1. Basic Actions Basic actions are standardized and available across all platforms. They provide essential functionality and are defined with a specific format, ensuring consistency and reliability. | |
| Basic Action 1: CLICK | |
| - purpose: Click at the specified position. | |
| - format: CLICK <point>[[x-axis, y-axis]]</point> | |
| - example usage: CLICK <point>[[101, 872]]</point> | |
| Basic Action 2: TYPE | |
| - purpose: Enter specified text at the designated location. | |
| - format: TYPE [input text] | |
| - example usage: TYPE [Shanghai shopping mall] | |
| Basic Action 3: SCROLL | |
| - purpose: SCROLL in the specified direction. | |
| - format: SCROLL [direction (UP/DOWN/LEFT/RIGHT)] | |
| - example usage: SCROLL [UP] | |
| 2.Custom Actions Custom actions are unique to each user’s platform and environment. They allow for flexibility and adaptability, enabling the model to support new and unseen actions defined by users. These actions extend the functionality of the basic set, making the model more versatile and capable of handling specific tasks. Your customized actions varied by datasets. |
🔼 This table presents the prompt used during the action fine-tuning phase of the OS-ATLAS model training. The prompt instructs the model to act as a foundational action model capable of handling tasks across various digital environments (desktop, mobile, web). It emphasizes the need for human-like interaction, using screenshots and descriptions to guide actions. The prompt specifies two main task types: grounding (locating elements) and executable language grounding (converting instructions to executable actions). It defines a unified action space that includes standardized basic actions (CLICK, TYPE, SCROLL) and custom actions (allowing for flexibility and adaptability across platforms). The provided example usages clarify how each action should be formatted in the Python code output. The custom actions are dataset-specific, providing flexibility for handling various tasks and environments.
read the caption
Table 6: The prompt for the action fine-tuning with a unified action space.
| Training dataset | Type | Platform | Source | #Elements | #Screenshots |
|---|---|---|---|---|---|
| FineWeb-filtered | REG | Web | synthetic | 7,779,922 | 1,617,179 |
| Windows-desktop | REG | Windows | synthetic | 1,079,707 | 51,726 |
| Linux-desktop | REG | Linux | synthetic | 41,540 | 1,186 |
| MacOS-desktop | REG | MacOS | synthetic | 13,326 | 1,339 |
| Pixel6-mobile | REG | Mobile | synthetic | 104,598 | 21,745 |
| SeeClick | REG | Web & Mobile | public | 3,303,479 | 364,760 |
| AMEX | REG | Mobile | public | 1,097,691 | 99,939 |
| UIbert | REG | Mobile | public | 16660 | 5682 |
| Mind2Web-annotated | IG | Web | GPT-4o | 5,943 | 5,943 |
| AITZ-annotated | IG | Mobile | GPT-4o | 10,463 | 10,463 |
| AMEX-annotated | IG | Mobile | GPT-4o | 5,745 | 5,745 |
| AndroidControl | IG | Mobile | public | 47,658 | 47,658 |
| Wave-UI | IG | All platforms | public | 65,478 | 7,357 |
| Total | 13,582,210 | 2,240,717 |
🔼 This table presents a detailed overview of the datasets used for pre-training the grounding model. It breaks down the data by type (REG: Referring Expression Grounding, IG: Instruction Grounding), platform (Web, Windows, MacOS, Mobile), source (whether it’s synthetically generated or from a public dataset), the number of elements (GUI elements) in the dataset, and the number of screenshots.
read the caption
Table 7: Grounding training datasets statistics overview.
| Planner | Models | Mobile Text | Mobile Icon/Widget | Desktop Text | Desktop Icon/Widget | Web Text | Web Icon/Widget | Avg. |
|---|---|---|---|---|---|---|---|---|
| - | SeeClick | 78.39 | 50.66 | 70.10 | 29.29 | 55.22 | 32.52 | 55.09 |
| OS-Atlas-Base-4B | 87.24 | 59.72 | 72.68 | 46.43 | 85.90 | 63.05 | 71.86 | |
| OS-Atlas-Base-7B | 95.17 | 75.83 | 90.72 | 63.57 | 90.60 | 77.34 | 84.12 | |
| GPT-4o | SeeClick | 85.17 | 58.77 | 79.90 | 37.14 | 72.65 | 30.05 | 63.60 |
| OS-Atlas-Base-4B | 95.52 | 75.83 | 79.38 | 49.29 | 90.17 | 66.50 | 79.09 | |
| OS-Atlas-Base-7B | 96.21 | 83.41 | 89.69 | 69.29 | 94.02 | 79.80 | 87.11 |
🔼 This table presents the results of a GUI grounding accuracy evaluation on the ScreenSpot-V2 benchmark dataset. It compares the performance of several models, including OS-Atlas-Base, across different settings (with and without a planner). The results show the accuracy of each model in predicting the location of GUI elements based on textual instructions. The best-performing model in each category is highlighted in bold, indicating its superior accuracy in GUI grounding tasks. This benchmark assesses single-step GUI grounding capability across mobile, desktop, and web platforms. The results are further broken down by the type of GUI element (Text, Icon/Widget) and the platform.
read the caption
Table 8: Grounding accuracy on ScreenSpot-v2. The best results are in bold.
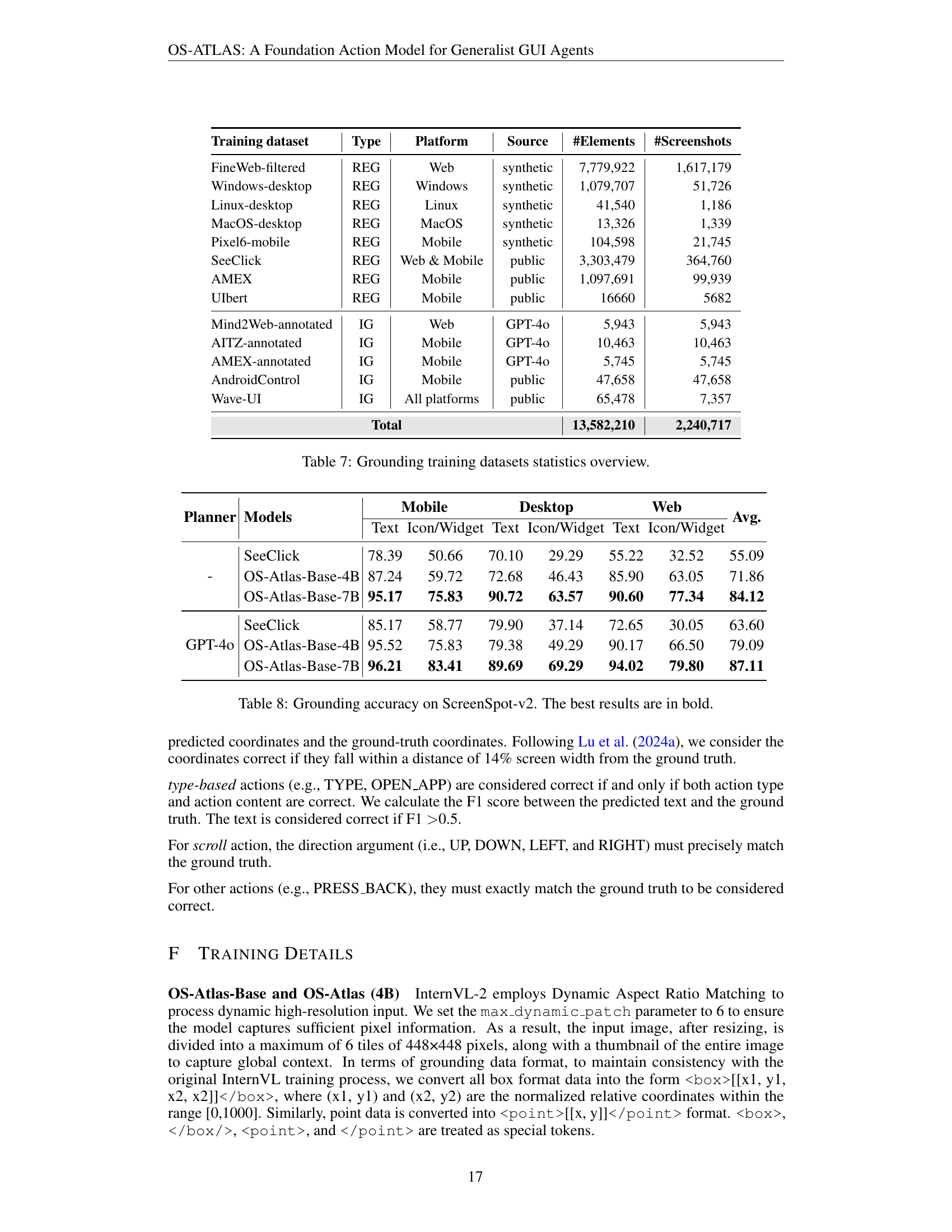
| Benchmarks | Platforms | #Test Samples | History? | # Unified Actions |
|---|---|---|---|---|
| GUI-Act-Web | Web | 1,410 | 3+2 | |
| Omniact | Web | 1,427 | 3+11 | |
| Desktop | 594 | 3+11 | ||
| AndroidControl-Low | Mobile | 7,708 | ✓ | 3+5 |
| AndroidControl-High | Mobile | 7,708 | ✓ | 3+5 |
| GUI-Odyssey-Random | Mobile | 29,414 | 3+6 | |
| GUI-Odyssey-Task | Mobile | 17,920 | 3+6 | |
| GUI-Odyssey-Device | Mobile | 18,969 | 3+6 | |
| GUI-Odyssey-App | Mobile | 17,455 | 3+6 |
🔼 This table presents details of the benchmarks used to evaluate the performance of agent tasks. For each benchmark, it indicates the platform (Web, Desktop, or Mobile), the number of test samples, whether the history of previous actions is included as input, and the number of unified actions (a combination of basic and custom actions) available for each task.
read the caption
Table 9: Details of the agentic benchmarks. History represents whether the history information of the previous actions is provided in the input. #Unified Actions denotes the number of actions (basic actions + custom actions) for each task.
Full paper#