↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Many existing language corpora are skewed towards high-resource languages, leaving many under-resourced languages underserved. This imbalance hinders the development of language technologies that can benefit diverse communities. Furthermore, existing methods for collecting and cleaning web data often struggle with minority languages. This results in noisy, unreliable data unsuitable for machine learning tasks.
To address these problems, this paper introduces GlotCC, a massive multilingual corpus covering more than 1000 languages. GlotCC is generated using a novel, open-source pipeline that incorporates a sophisticated language identification model (GlotLID v3.0) designed for high accuracy and broad language coverage. This pipeline also employs several robust filtering methods to remove noisy data, producing a high-quality and reliable corpus suitable for many natural language processing tasks. The researchers also share their pipeline and improved language identification model, enhancing the reproducibility of their work and encouraging future research and development in this field.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in NLP and computational linguistics because it addresses the critical need for large, high-quality multilingual corpora, especially for minority languages. GlotCC offers a valuable resource for developing and evaluating language technologies, and the open-source pipeline allows researchers to build upon this work and adapt it to other languages or domains. This work significantly contributes to bridging the digital divide in language technologies and fostering linguistic diversity in research.
Visual Insights#


🔼 This table lists the hyperparameters used during the training of the GlotLID v3.0 language identification model. It details the settings for various parameters that influence the model’s training process, including the minimum number of word and label occurrences required, the range of character n-grams considered, the loss function employed, the dimensionality of word embeddings, and the learning rate used. Understanding these hyperparameters is crucial for reproducibility and for comprehending the model’s behavior and performance.
read the caption
Table 1: GlotLID v3.0 training hyperparameters
In-depth insights#
Minority Lang. Data#
The research paper section on ‘Minority Lang. Data’ highlights the critical shortage of high-quality linguistic resources for low-resource languages. It emphasizes the need for large, broad-coverage corpora to train effective language models, contrasting the abundance of data for high-resource languages with the scarcity for minority languages. The paper advocates for open-source and reproducible pipelines to generate these resources, addressing the current limitations in language identification (LID) models, specifically their inability to cover a wide range of languages and their susceptibility to noise in web-crawled data. A new LID model, GlotLID, is introduced to overcome these challenges, boasting improved accuracy and coverage of over 2000 languages. The paper emphasizes that these improved resources and methods are crucial for advancing natural language processing (NLP) technologies for underserved languages, promoting linguistic diversity and inclusion in AI.
GlotLID: LID Model#
The research paper introduces GlotLID, a novel language identification (LID) model designed to address limitations of existing LID systems, particularly concerning minority languages. GlotLID’s core advancement lies in its significantly expanded language coverage, exceeding 2000 labels, encompassing a broad range of minority languages often neglected by other models. This enhanced coverage is achieved by incorporating new language resources, refining existing labels, and incorporating a robust rejection model that mitigates errors arising from unseen languages. The model’s performance is rigorously evaluated across multiple benchmark datasets, showing marked improvements in F1-score and false positive rates compared to previous versions and state-of-the-art models. Furthermore, GlotLID’s architecture enhances accuracy by incorporating script information and implementing novel techniques to remove noise and improve data quality. The model’s open-source nature and detailed documentation contribute to its broader usability and transparency within the research community. The expanded scope and improved accuracy of GlotLID represent a considerable contribution to the field, making it a powerful tool for language technology research involving minority languages and low-resource scenarios.
GlotCC Pipeline#
The GlotCC pipeline, a reproducible and open-source system, leverages the Ungoliant pipeline for text extraction from Common Crawl. A key innovation is the development of GlotLID v3.0, a significantly improved language identification model covering over 2000 languages, which addresses limitations of previous models by mitigating hash collisions and expanding language coverage. The pipeline incorporates several noise reduction techniques to enhance data quality, removing elements like list-like content and documents with inconsistent language identification. This results in a clean, document-level corpus, GlotCC v1.0, suitable for various NLP tasks. The pipeline’s architecture is modular and extensible, allowing researchers to adapt and enhance it. Further, the authors make the pipeline, GlotLID model, and filters openly accessible to promote reproducibility and foster collaboration within the research community.
Future Work#
The authors plan to expand the GlotCC corpus by incorporating additional Common Crawl snapshots, thereby significantly increasing language coverage and data volume. This expansion will enhance the corpus’s utility for training multilingual language models and other language technologies, particularly those focused on low-resource and minority languages. Future efforts will also involve developing additional filters to further refine data quality and mitigate the challenges of noise and errors inherent in web-crawled data. Addressing the limitations of current LID models is another key focus; the researchers aim to develop improved methods to handle the challenges of hash collisions and limited language coverage, ultimately aiming to create a more robust and comprehensive language identification model. The ultimate goal is to improve the representation of minority languages in natural language processing, contributing to a more inclusive and equitable field.
Dataset Limitations#
The research paper highlights several limitations of the GlotCC dataset. Use cases are limited, as certain filtering steps exclude math and code content, impacting the applicability to specific tasks. Noise and errors remain despite cleaning efforts, including misclassifications and issues arising from language ambiguity on the web. The dataset contains more monolingual rather than multilingual content, likely due to the filtering process. The dataset is not fully comprehensive, missing data due to constraints imposed by data licensing and technical limitations in handling low-resource languages. Finally, evaluation challenges exist, as the absence of evaluation data makes it difficult to fully assess the quality of the dataset for various tasks and modeling needs. These issues necessitate careful consideration when using GlotCC, especially for tasks sensitive to noise or requiring balanced multilingual data.
More visual insights#
More on tables
| Argument | Description | Value |
|---|---|---|
| -minCount | Minimal number of word occurrences | 1000 |
| -minCountLabel | Minimal number of label occurrences | 0 |
| -wordNgrams | Max length of word ngram | 1 |
| -bucket | Number of buckets | 106 |
| -minn | Min length of char ngram | 2 |
| -maxn | Max length of char ngram | 5 |
| -loss | Loss function | softmax |
| -dim | Size of word vectors | 256 |
| -epoch | Number of epochs | 1 |
| -lr | Learning rate | .8 |
🔼 This table presents the performance of the GlotLID v3.0 language identification model on three benchmark datasets: GlotTest, UDHR, and FLORES-200. For each dataset, it shows the number of labels used, the F1 score (a measure of accuracy), and the false positive rate (FPR, the rate of incorrectly identifying a language). The F1 score and FPR are important metrics for evaluating the performance of language identification models, indicating the balance between correctly identifying languages and avoiding false positives. A high F1 score and a low FPR are desirable.
read the caption
Table 2: Performance of GlotLID v3.0
| Benchmark | # Labels | F1 ↑ | FPR ↓ |
|---|---|---|---|
| GlotTest | 2102 | 0.991 | 0.000003 |
| UDHR | 371 | 0.882 | 0.000298 |
| FLORES-200 | 199 | 0.967 | 0.000161 |
🔼 This table shows the geographic distribution of the 1275 languages included in the GlotCC corpus. It breaks down the number of languages represented by Glottolog macroarea (e.g., Eurasia, Papunesia, Africa, etc.). This provides a geographical overview of the linguistic diversity covered within the corpus.
read the caption
Table 3: Geographic distribution of languages in GlotCC.
| Macroarea | # Labels |
|---|---|
| Eurasia | 395 |
| Papunesia | 380 |
| Africa | 252 |
| North America | 123 |
| South America | 97 |
| Australia | 16 |
| Constructed | 12 |
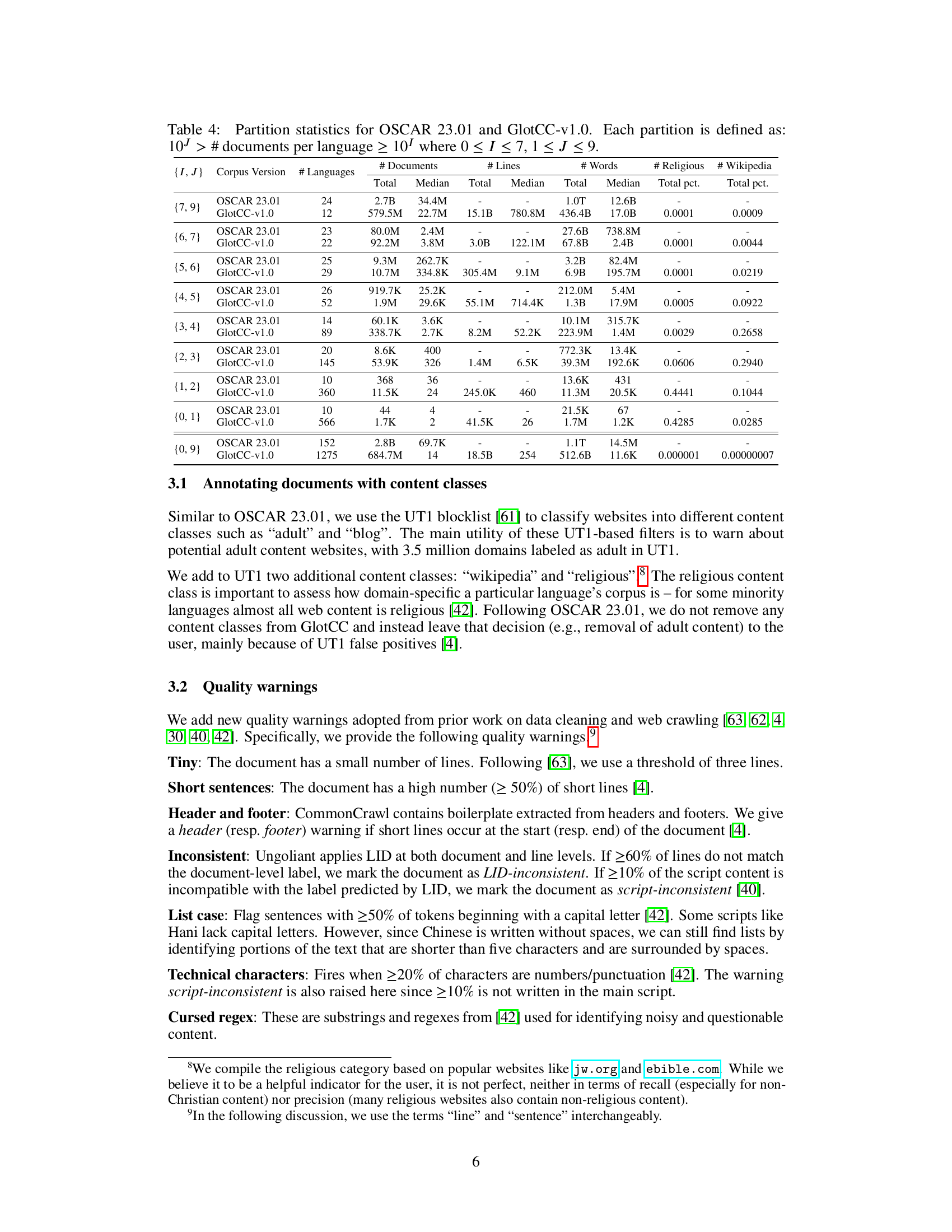
🔼 Table 4 presents a comparative analysis of the language distribution within the OSCAR 23.01 and GlotCC v1.0 corpora. It categorizes languages based on the number of documents associated with each language, grouping languages into partitions where the number of documents falls within a specific range (10I to 10J, where I and J represent integers from 0 to 7 and 1 to 9 respectively). This allows for a visualization of how many languages have a small number of documents versus a large number of documents and helps to highlight differences in corpus coverage between OSCAR and GlotCC. The table shows the total number of languages, lines, words, and religious and Wikipedia document counts for each partition across both datasets.
read the caption
Table 4: Partition statistics for OSCAR 23.01 and GlotCC-v1.0. Each partition is defined as: 10J># documents per language≥10Isuperscript10𝐽# documents per languagesuperscript10𝐼10^{J}>\text{\# documents per language}\geq 10^{I}10 start_POSTSUPERSCRIPT italic_J end_POSTSUPERSCRIPT > # documents per language ≥ 10 start_POSTSUPERSCRIPT italic_I end_POSTSUPERSCRIPT where 0≤I≤70𝐼70\leq I\leq 70 ≤ italic_I ≤ 7, 1≤J≤91𝐽91\leq J\leq 91 ≤ italic_J ≤ 9.
| {I, J} | Corpus Version | # Languages | # Documents (Total) | # Documents (Median) | # Lines (Total) | # Lines (Median) | # Words (Total) | # Words (Median) | # Religious (Total pct.) | # Wikipedia (Total pct.) | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| {7, 9} | OSCAR 23.01 | 24 | 2.7B | 34.4M | - | - | 1.0T | 12.6B | - | - | |
| {7, 9} | GlotCC-v1.0 | 12 | 579.5M | 22.7M | 15.1B | 780.8M | 436.4B | 17.0B | 0.0001 | 0.0009 | |
| {6, 7} | OSCAR 23.01 | 23 | 80.0M | 2.4M | - | - | 27.6B | 738.8M | - | - | |
| {6, 7} | GlotCC-v1.0 | 22 | 92.2M | 3.8M | 3.0B | 122.1M | 67.8B | 2.4B | 0.0001 | 0.0044 | |
| {5, 6} | OSCAR 23.01 | 25 | 9.3M | 262.7K | - | - | 3.2B | 82.4M | - | - | |
| {5, 6} | GlotCC-v1.0 | 29 | 10.7M | 334.8K | 305.4M | 9.1M | 6.9B | 195.7M | 0.0001 | 0.0219 | |
| {4, 5} | OSCAR 23.01 | 26 | 919.7K | 25.2K | - | - | 212.0M | 5.4M | - | - | |
| {4, 5} | GlotCC-v1.0 | 52 | 1.9M | 29.6K | 55.1M | 714.4K | 1.3B | 17.9M | 0.0005 | 0.0922 | |
| {3, 4} | OSCAR 23.01 | 14 | 60.1K | 3.6K | - | - | 10.1M | 315.7K | - | - | |
| {3, 4} | GlotCC-v1.0 | 89 | 338.7K | 2.7K | 8.2M | 52.2K | 223.9M | 1.4M | 0.0029 | 0.2658 | |
| {2, 3} | OSCAR 23.01 | 20 | 8.6K | 400 | - | - | 772.3K | 13.4K | - | - | |
| {2, 3} | GlotCC-v1.0 | 145 | 53.9K | 326 | 1.4M | 6.5K | 39.3M | 192.6K | 0.0606 | 0.2940 | |
| {1, 2} | OSCAR 23.01 | 10 | 368 | 36 | - | - | 13.6K | 431 | - | - | |
| {1, 2} | GlotCC-v1.0 | 360 | 11.5K | 24 | 245.0K | 460 | 11.3M | 20.5K | 0.4441 | 0.1044 | |
| {0, 1} | OSCAR 23.01 | 10 | 44 | 4 | - | - | 21.5K | 67 | - | - | |
| {0, 1} | GlotCC-v1.0 | 566 | 1.7K | 2 | 41.5K | 26 | 1.7M | 1.2K | 0.4285 | 0.0285 | |
| {0, 9} | OSCAR 23.01 | 152 | 2.8B | 69.7K | - | - | 1.1T | 14.5M | - | - | |
| {0, 9} | GlotCC-v1.0 | 1275 | 684.7M | 14 | 18.5B | 254 | 512.6B | 11.6K | 0.000001 | 0.00000007 |
🔼 This table compares the performance of the GlotLID and NLLB language identification models on a random sample of 20 pages containing minority languages. It shows the number of times each model correctly identified the language, made an incorrect classification, or failed to make a prediction (labeled as ‘miss’). This comparison highlights the relative strengths and weaknesses of each model in handling minority languages, providing insights into their accuracy and the frequency of prediction failures.
read the caption
Table 5: Comparison of GlotLID and NLLB on a random subset of 20 pages from minority languages
Full paper#