↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current research on Android autonomous agents suffers from a lack of systematic evaluation across open-source and closed-source models and a lack of standardized benchmarks. Existing benchmarks often use static environments or lack comprehensive evaluation metrics. This limits the ability to analyze model behavior, conduct reinforcement learning experiments, and compare different approaches effectively.
This paper introduces ANDROIDLAB, a novel Android agent framework designed to address these limitations. ANDROIDLAB offers a reproducible benchmark with 138 tasks across nine apps, supporting both LLMs and LMMs. It uses a unified action space and introduces new evaluation metrics to measure operational efficiency. By utilizing ANDROIDLAB, the authors develop an Android Instruction dataset and fine-tune six open-source models, resulting in significant improvements in success rates. The framework and dataset are publicly available, paving the way for more systematic and comparative research in this domain.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the lack of systematic research on training and evaluating Android autonomous agents. By introducing ANDROIDLAB, it provides a standardized environment and benchmark, facilitating more robust and reproducible research in this emerging field. The open-sourcing of the framework and dataset further accelerates progress by enabling collaborative development and benchmarking of various models.
Visual Insights#

🔼 This figure provides a high-level overview of the ANDROIDLAB framework, illustrating its key components: the operation environment, which includes various modalities and action spaces for interacting with Android devices; the actions the agents can perform (Tap, Long Press, Type, Swipe, etc.); the benchmark, which comprises 9 apps and 138 tasks used to evaluate agent performance; and the metrics utilized for evaluation, including Success Rate and Reasonable Operation Rate.
read the caption
(a) Overview of the environment and benchmark of AndroidLab.
| Mode | Model | SR | Sub-SR | RRR | ROR |
|---|---|---|---|---|---|
| XML | GPT-4o | 25.36 | 30.56 | 107.45 | 86.56 |
| GPT-4-1106-Preview | 31.16 | 38.21 | 66.34 | 86.24 | |
| Gemini-1.5-Pro | 18.84 | 22.40 | 57.72 | 83.99 | |
| Gemini-1.0 | 8.70 | 10.75 | 51.80 | 71.08 | |
| GLM4-PLUS | 27.54 | 32.08 | 92.35 | 83.41 | |
| LLaMA3.1-8B-Instruct | 2.17 | 3.62 | - | 52.77 | |
| Qwen2-7B-Instruct | 4.35 | 4.95 | - | 67.26 | |
| GLM4-9B-Chat | 7.25 | 9.06 | 54.43 | 58.34 | |
| XML+SFT | LLaMA3.1-8B-ft | 23.91 | 30.31 | 75.58 | 92.46 |
| Qwen2-7B-ft | 19.57 | 24.40 | 77.31 | 92.48 | |
| GLM4-9B-ft | 21.01 | 26.45 | 74.81 | 93.25 | |
| SoM | GPT-4o | 31.16 | 35.02 | 87.32 | 85.36 |
| GPT-4-Vision-Preview | 26.09 | 29.53 | 99.22 | 78.79 | |
| Gemini-1.5-Pro | 16.67 | 18.48 | 105.95 | 91.52 | |
| Gemini-1.0 | 10.87 | 12.56 | 72.52 | 76.70 | |
| Claude-3.5-Sonnet | 28.99 | 32.66 | 113.41 | 81.16 | |
| Claude-3-Opus | 13.04 | 15.10 | 81.41 | 83.89 | |
| CogVLM2 | 0.72 | 0.72 | - | 17.97 | |
| LLaMA3.2-11B-Vision-Instruct | 1.45 | 1.45 | - | 50.76 | |
| Qwen2-VL-7B-Instruct | 3.62 | 4.59 | - | 84.81 | |
| SoM+SFT | CogVLM2-ft | 11.59 | 16.06 | 57.37 | 85.58 |
| LLaMA3.2-11B-Vision-ft | 10.14 | 12.98 | 61.67 | 87.85 | |
| Qwen2-VL-7B-Instruct-ft | 18.12 | 22.64 | 65.23 | 88.29 |
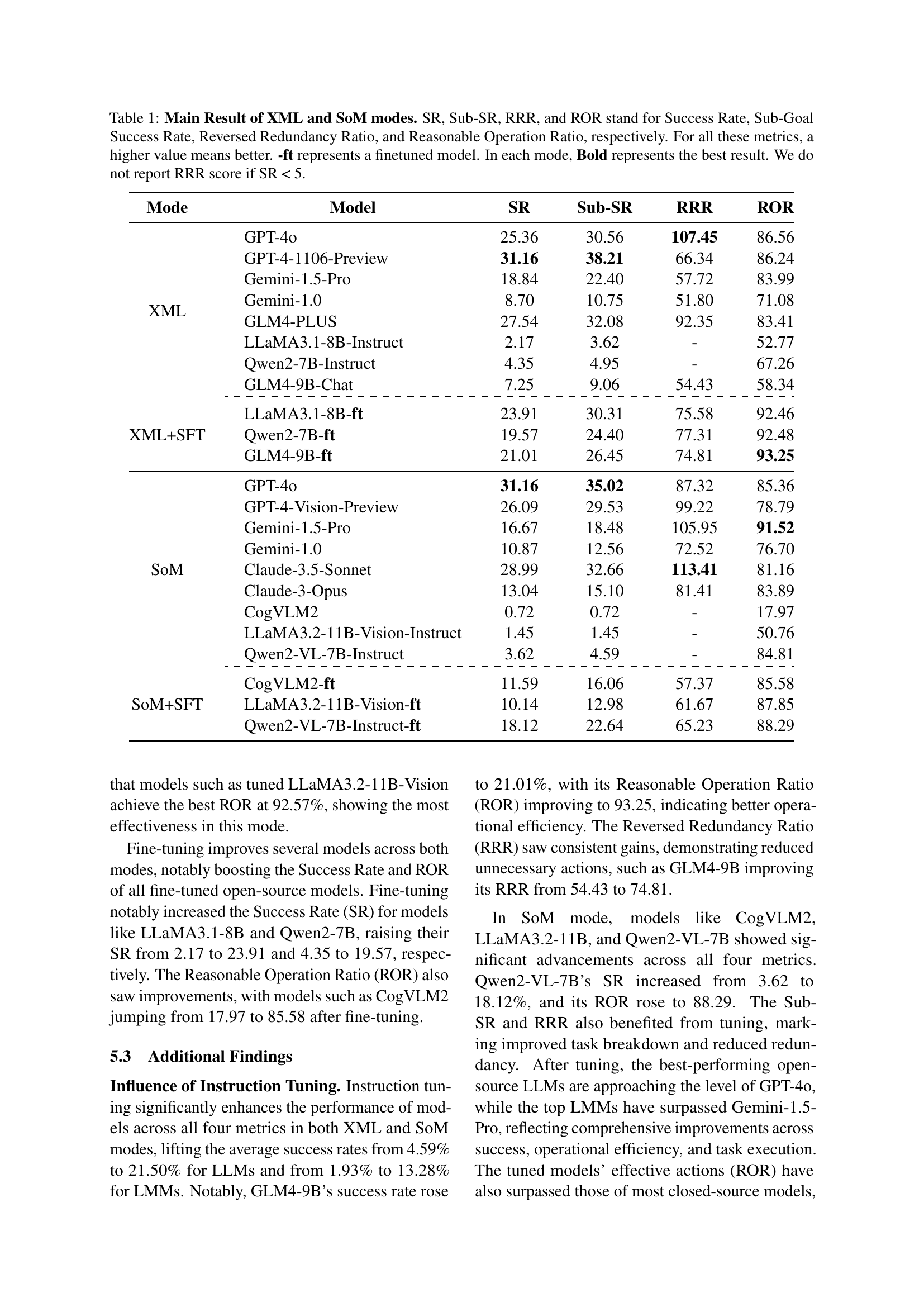
🔼 This table presents the main results obtained from evaluating various large language models (LLMs) and large multimodal models (LMMs) using two different operation modes: XML mode (text-only) and SoM mode (multimodal). The models’ performance is assessed across four key metrics: Success Rate (SR), Sub-Goal Success Rate (Sub-SR), Reversed Redundancy Ratio (RRR), and Reasonable Operation Ratio (ROR). A higher value for each metric indicates better performance. The table also includes results for fine-tuned (ft) versions of some models, highlighting the impact of fine-tuning. The best performing model in each mode is indicated in bold. Note that the RRR is not reported for models with a Success Rate (SR) below 5%.
read the caption
Table 1: Main Result of XML and SoM modes. SR, Sub-SR, RRR, and ROR stand for Success Rate, Sub-Goal Success Rate, Reversed Redundancy Ratio, and Reasonable Operation Ratio, respectively. For all these metrics, a higher value means better. -ft represents a finetuned model. In each mode, Bold represents the best result. We do not report RRR score if SR < 5.
In-depth insights#
Android Agent Benchmarks#
The research paper reveals a critical gap in systematic benchmarking for Android autonomous agents. Existing benchmarks are limited by static environments and lack of open-source model evaluation, hindering progress in the field. ANDROIDLAB is introduced as a novel framework addressing these limitations. It provides a standardized operational environment encompassing diverse modalities, a challenging benchmark with 138 tasks across nine apps, and an instruction dataset to facilitate training. Notably, ANDROIDLAB enables fair comparison of both open-source and closed-source models, offering valuable insights into their performance and highlighting the potential for improving open-source solutions through systematic evaluation. The results demonstrate that fine-tuning open-source models significantly boosts performance, narrowing the gap against their closed-source counterparts, though the latter still hold an edge in overall efficiency and success rates. The study’s impact lies in establishing a reproducible and challenging benchmark that accelerates Android autonomous agent research.
Multimodal Android Actions#
The research paper section on ‘Multimodal Android Actions’ delves into the methods for enabling autonomous agents to interact with Android devices using multiple modalities. It highlights the design of a unified action space that seamlessly supports both large language models (LLMs) and large multimodal models (LMMs). This design is crucial for enabling fair comparisons between different model types. The core of this approach lies in defining basic operation modes, including XML mode for text-only LLMs and SoM mode for LMMs which processes visual information. These modes, along with ReAct and SeeAct frameworks, provide flexibility in agent interaction strategies. The paper emphasizes the importance of a standardized action space to ensure fair comparisons and the creation of a benchmark dataset containing predefined tasks across various apps to systematically evaluate the effectiveness of different models. The framework presented enables a comprehensive evaluation of various model architectures’ success rates in executing complex tasks on the Android system. The approach facilitates systematic analysis of model behavior and promotes the development of enhanced Android-compatible autonomous agents.
Instruction Dataset#
The research paper introduces the Android Instruction dataset, a crucial component for training and evaluating Android agents. This dataset was meticulously constructed using a three-step process: task derivation and expansion, self-exploration, and manual annotation. Self-exploration leveraged LLMs and LMMs to automatically generate task traces, while manual annotation ensured accuracy and addressed challenges in data collection, particularly concerning dynamic UI elements. The dataset comprises 10.5k traces and 94.3k steps, with a focus on real-world scenarios and reproducibility. It includes tasks, phone screen states, and XML information, offering a comprehensive and detailed record of Android agent interactions. This dataset’s use in fine-tuning open-source LLMs and LMMs resulted in significant performance improvements, showcasing its value in bridging the gap between open-source and closed-source models for Android agent development.
Open-Source Model Gains#
The research reveals significant progress in open-source Android agent models. Fine-tuning with the AndroidInstruct dataset substantially improved performance, increasing success rates for LLMs from 4.59% to 21.50% and for LMMs from 1.93% to 13.28%. This demonstrates the effectiveness of the dataset and highlights the potential of open-source models to reach levels comparable to their closed-source counterparts. While closed-source models like GPT-4 maintained higher success rates, the substantial gains in open-source models emphasize the achievable improvements through effective training data and methods. This finding suggests a promising path for bridging the performance gap between open and closed-source models and fostering further development in this area.
Future Research#
The paper does not include a section specifically titled “Future Research.” Therefore, I cannot provide a summary of such a section. To obtain a relevant response, please either provide the text of any section discussing future work from the research paper or specify a different heading for analysis.
More visual insights#
More on figures
🔼 This figure presents the success rates achieved by various closed-source large language models (LLMs) and large multimodal models (LMMs) on the AndroidLab benchmark. It compares the performance of different models in terms of success rate across different operating modes (XML and SoM) and agent frameworks (ReAct and SeeAct). The chart visually represents the effectiveness of these closed-source models in completing tasks within the Android environment.
read the caption
(b) Results of Closed Models.

🔼 Figure 1 illustrates the architecture of AndroidLab and its benchmark results. (a) shows the design of AndroidLab’s environment, which includes two operation modes: SoM (for multimodal models) and XML (for text-only models). Both modes share an identical action space, and incorporate ReAct and SeeAct frameworks. The benchmark is based on this environment. (b) presents the success rates achieved by various closed-source models on the AndroidLab benchmark. GPT-4-1106-Preview achieves the highest success rate (31.16%) in the XML mode, matching the performance of GPT-4o in the SoM mode.
read the caption
Figure 1: (a) We design the SoM mode for the multimodal models (LMMs) and the XML mode for the text-only models (LLMs), ensuring an identical action space. We also implement ReAct and SeeAct frameworks in both modes. Based on the environment, we propose the AndroidLab benchmark. (b) AndroidLab benchmark success rates of closed-source models. In the XML mode, GPT-4-1106-Preview has the highest success rate at 31.16%, the same as GPT-4o in the SoM mode.

🔼 The figure illustrates the process of collecting the AndroidInstruct dataset, which involves three main steps: task derivation and expansion, self-exploration, and manual annotation. Task derivation and expansion uses existing academic datasets and manual instruction writing to seed the generation of tasks. Self-exploration employs LLMs and LMMs to automatically explore the Android apps, collecting traces of operations. Finally, manual annotation involves instruction checking by annotators to assess task feasibility, preliminary familiarization with the app interface, the execution of tasks and recording their traces, and cross-verification by a second annotator to ensure data accuracy. The collected data includes tasks, phone screen states, XML information, and operations.
read the caption
(a) Overview of Android Instruct data collection.

🔼 This figure shows bar charts illustrating the success rates achieved by six open-source language models (LLMs) and multi-modal models (LMMs) before and after fine-tuning using the AndroidInstruct dataset. The chart visually compares the model performance improvement after the fine-tuning process on the Android agent tasks, showing the effectiveness of the dataset in improving agent capabilities.
read the caption
(b) Success Rates of before and after fine-tuning by Android Instruct.

🔼 Figure 2 presents data on the Android Instruction dataset and its impact on model training. (a) Details the dataset’s composition: 726 traces and over 6208 aligned steps collected in XML and SoM modes. (b) Shows the performance improvement in six open-source LLMs and LMMs after fine-tuning using this dataset. The average success rate increased significantly—from 4.59% to 21.50% for LLMs and 1.93% to 13.28% for LMMs, reaching a level comparable to closed-source models.
read the caption
Figure 2: (a) We have collected over 726 traces containing more than 6208 fully aligned steps of XML and SoM mode training data. (b) By using the Android Instruct dataset, we trained six open-source text-only and multimodal models, achieving an average success rate from 4.59% to 21.50% for LLMs and from 1.93% to 13.28% for LMMs. respectively, reaching a performance level comparable to proprietary models.

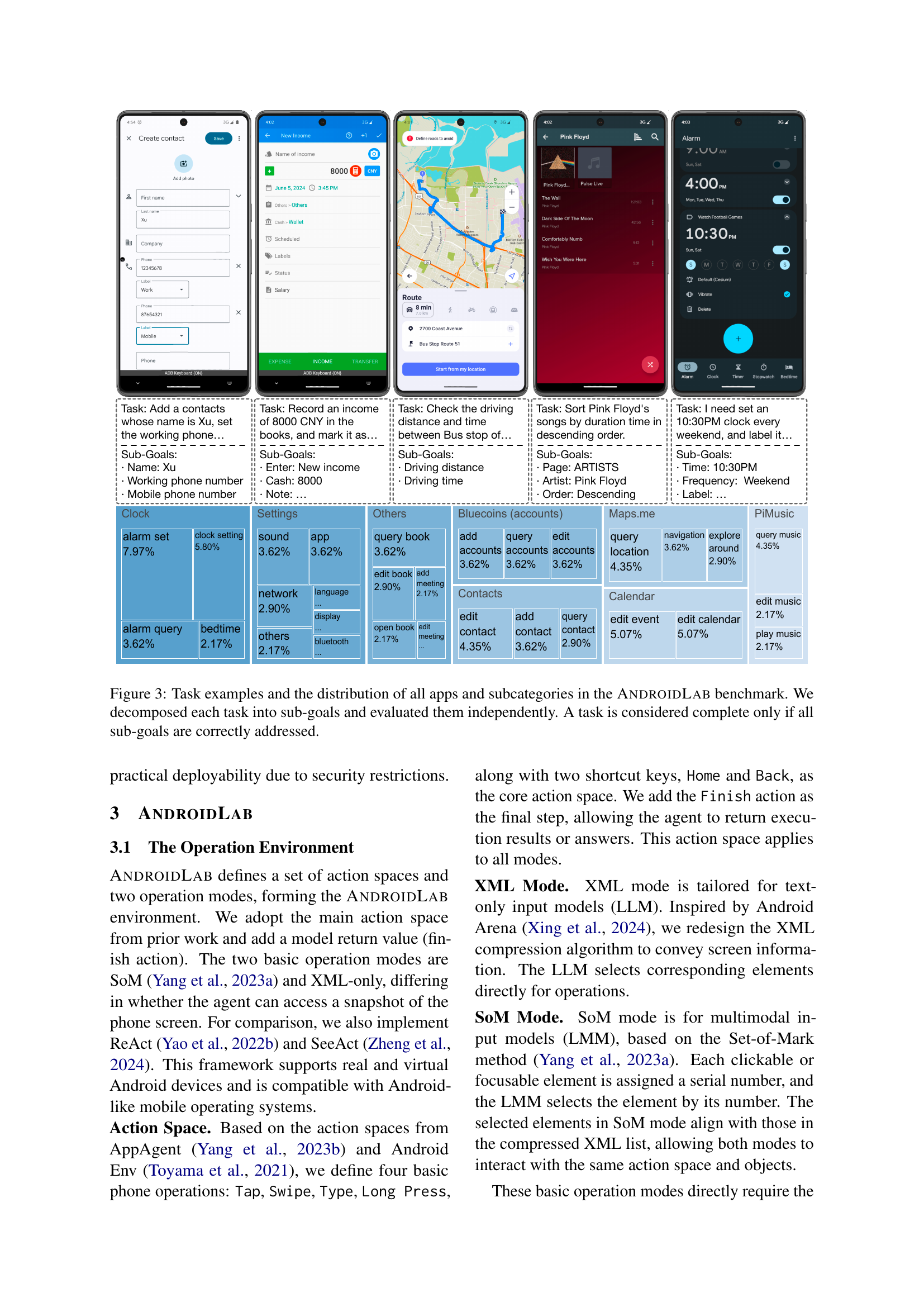
🔼 Figure 3 illustrates example tasks from the AndroidLab benchmark and shows the distribution of tasks across different apps and subcategories. Each task is broken down into smaller, independent sub-goals. A task is only marked as successfully completed if all of its sub-goals are correctly addressed. This decomposition allows for a more granular evaluation of the agent’s abilities, providing insights into which aspects of a task might be more challenging for the agent.
read the caption
Figure 3: Task examples and the distribution of all apps and subcategories in the AndroidLab benchmark. We decomposed each task into sub-goals and evaluated them independently. A task is considered complete only if all sub-goals are correctly addressed.

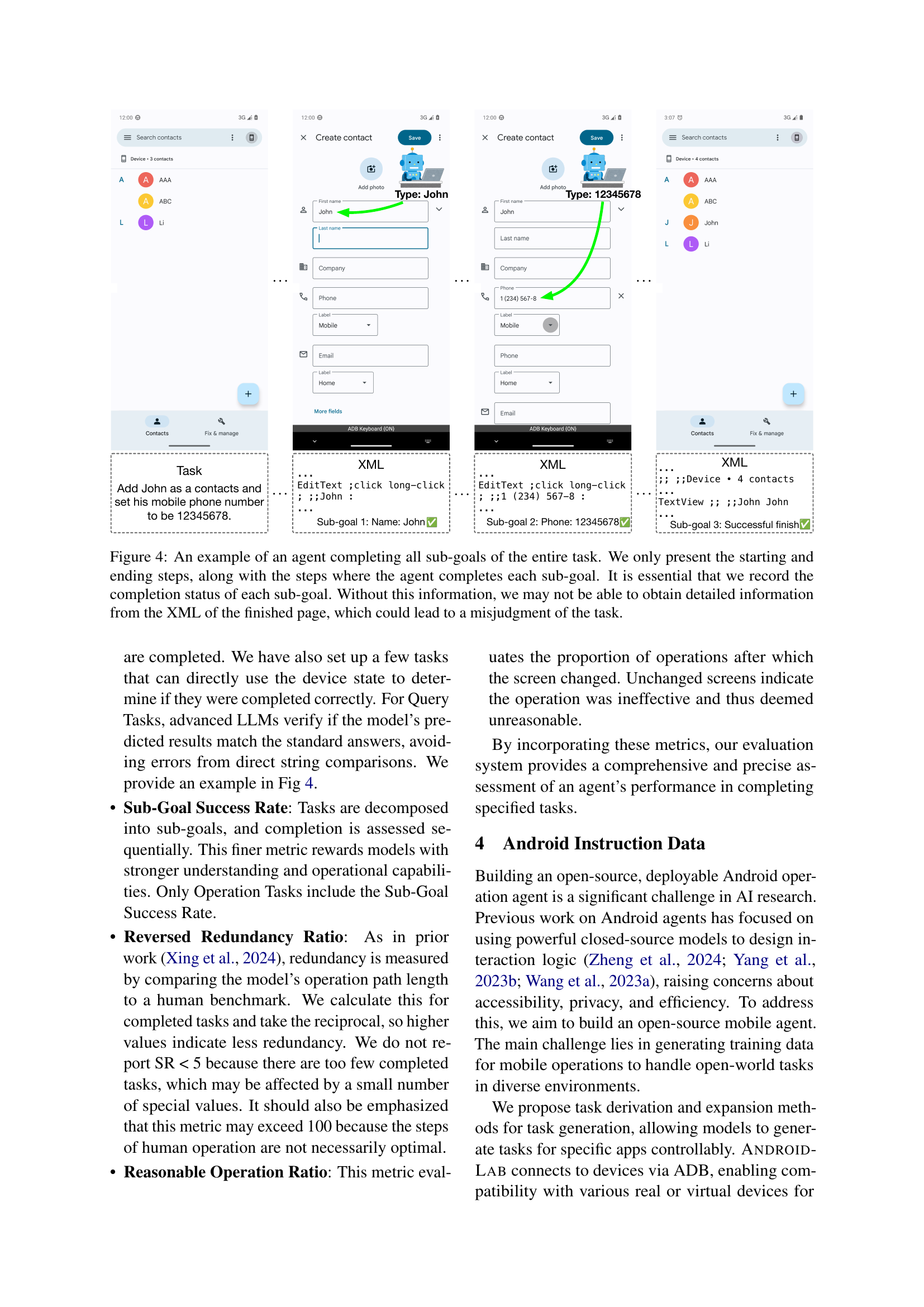
🔼 Figure 4 illustrates a successful task completion by an agent within the ANDROIDLAB environment. The figure highlights the importance of tracking sub-goal completion status. It shows only the initial, final, and intermediate steps where sub-goals are achieved. This granular level of detail is crucial because, without tracking sub-goal success, it’s difficult to accurately interpret the final XML page data and correctly assess task completion. Inaccurate interpretation of the final XML could lead to misjudgments about the agent’s success.
read the caption
Figure 4: An example of an agent completing all sub-goals of the entire task. We only present the starting and ending steps, along with the steps where the agent completes each sub-goal. It is essential that we record the completion status of each sub-goal. Without this information, we may not be able to obtain detailed information from the XML of the finished page, which could lead to a misjudgment of the task.

🔼 This histogram shows the distribution of the number of steps required to complete each of the 138 tasks in the ANDROIDLAB benchmark. The x-axis represents the number of steps, and the y-axis represents the frequency or count of tasks requiring that number of steps. This visualization helps to understand the complexity distribution of tasks within the benchmark, indicating whether most tasks are simple (requiring few steps) or complex (requiring many steps).
read the caption
(a) Step Distribution Across Tasks

🔼 This figure shows the 20 most frequent words used in the instructions given to the Android agents within the Android Instruction dataset. It provides insight into the common themes, actions, and objects that characterize the tasks the agents were trained on. This information helps to understand the nature and complexity of the tasks within the ANDROIDLAB benchmark.
read the caption
(b) Top 20 Words in Instructions.

🔼 This figure shows the distribution of instruction lengths in the Android Instruct dataset. The x-axis represents the length of instructions (in words), and the y-axis represents the frequency of instructions with that length. The distribution provides insight into the complexity and variability of the instructions used to train the Android agents.
read the caption
(c) Instruction Length Distribution.

🔼 The bar chart displays the frequency distribution of the nine applications (Clock, Contacts, Maps.me, PiMusicPlayer, Calendar, Settings, Cantook, Bluecoins, and Others) used in the ANDROIDLAB benchmark. The height of each bar represents the number of tasks associated with each application, indicating which apps have a higher concentration of tasks in the benchmark.
read the caption
(d) APP Distribution.

🔼 This figure shows the distribution of action types in the Android Instruction dataset. It displays the frequency of different actions such as Tap, Type, Swipe, Long Press, Launch, Back, Finish, and other actions, providing insights into the types of interactions captured in the dataset.
read the caption
(e) Actions Distribution.

🔼 This figure shows the average number of steps required to complete tasks within each of the nine apps included in the ANDROIDLAB benchmark. It provides insight into the relative complexity of tasks across different applications.
read the caption
(f) Average Task Length per App

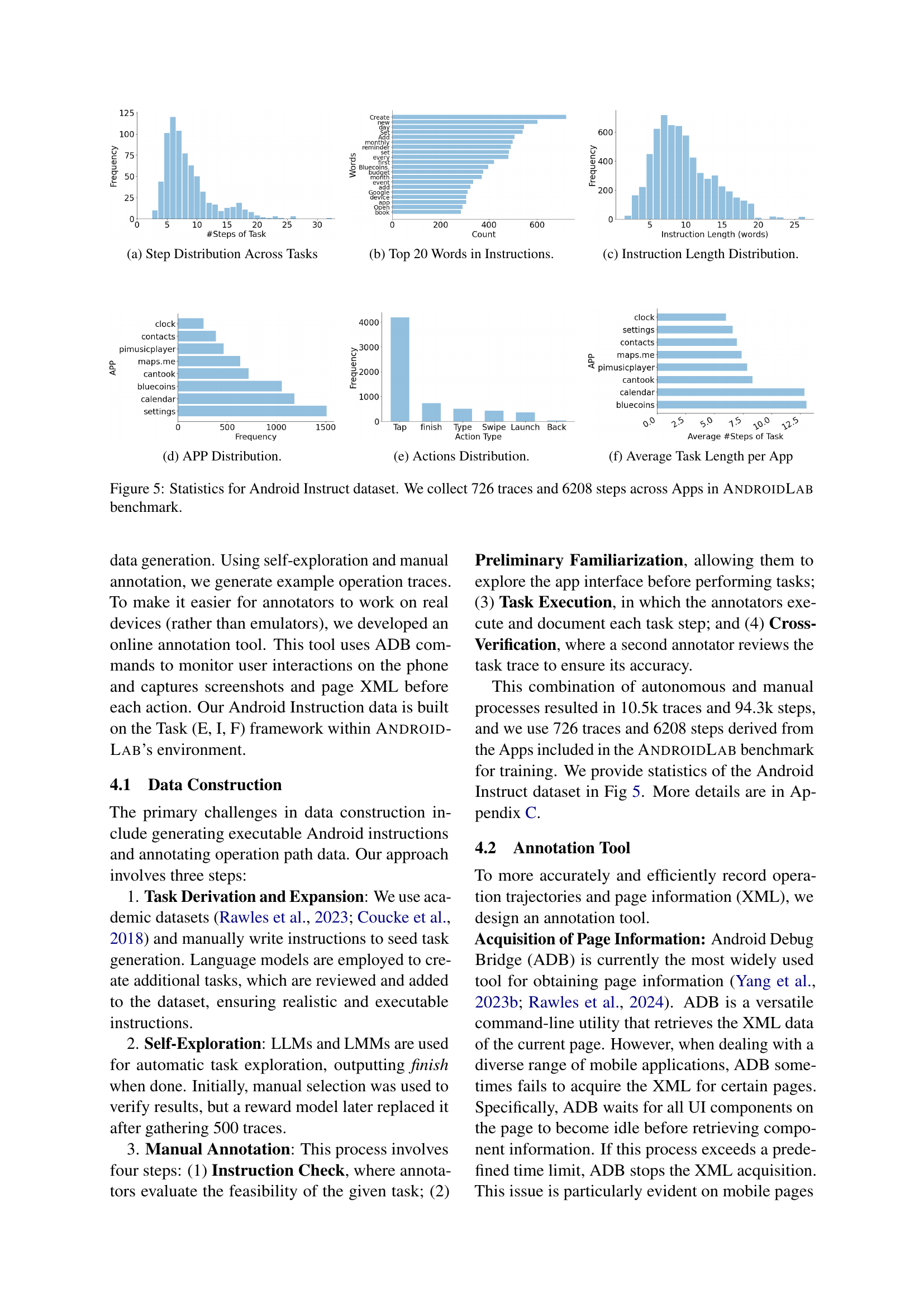
🔼 This figure presents a statistical overview of the Android Instruct dataset, a key component of the AndroidLab benchmark. The dataset comprises 726 distinct interaction traces, which represent sequences of user actions within various Android apps. A total of 6208 individual action steps were recorded across these traces. This data provides valuable insights into the scale and diversity of user interactions captured for training and evaluating Android agents within the AndroidLab framework.
read the caption
Figure 5: Statistics for Android Instruct dataset. We collect 726 traces and 6208 steps across Apps in AndroidLab benchmark.
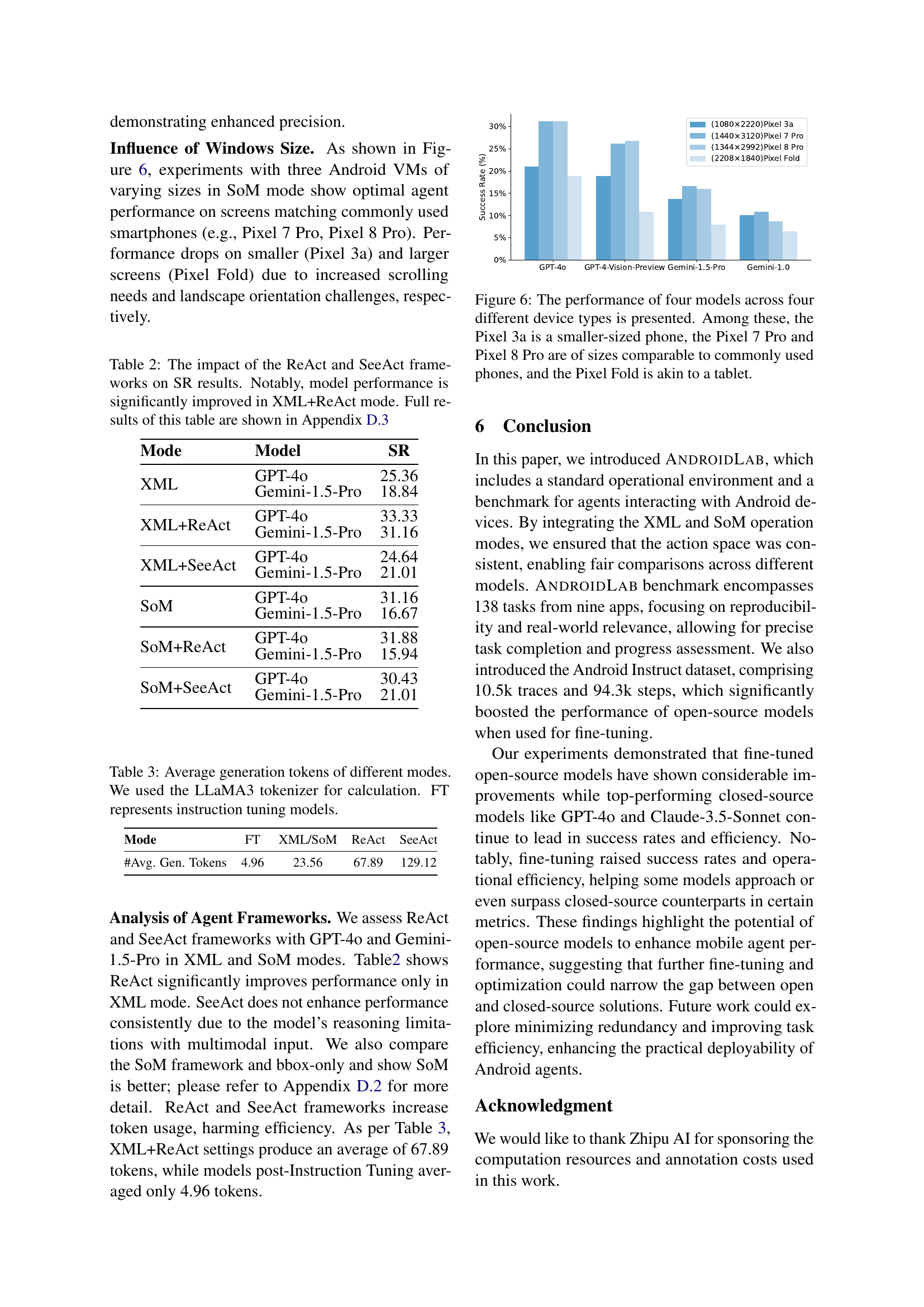
🔼 This figure displays the performance of four different large language models (LLMs) on Android devices with varying screen sizes. The models’ success rates are compared across four different phone models: Pixel 3a (smaller screen), Pixel 7 Pro, and Pixel 8 Pro (common screen sizes), and Pixel Fold (tablet-like larger screen). The results illustrate how screen size affects the performance of the models, suggesting that models perform best on screens similar in size to commonly used smartphones.
read the caption
Figure 6: The performance of four models across four different device types is presented. Among these, the Pixel 3a is a smaller-sized phone, the Pixel 7 Pro and Pixel 8 Pro are of sizes comparable to commonly used phones, and the Pixel Fold is akin to a tablet.

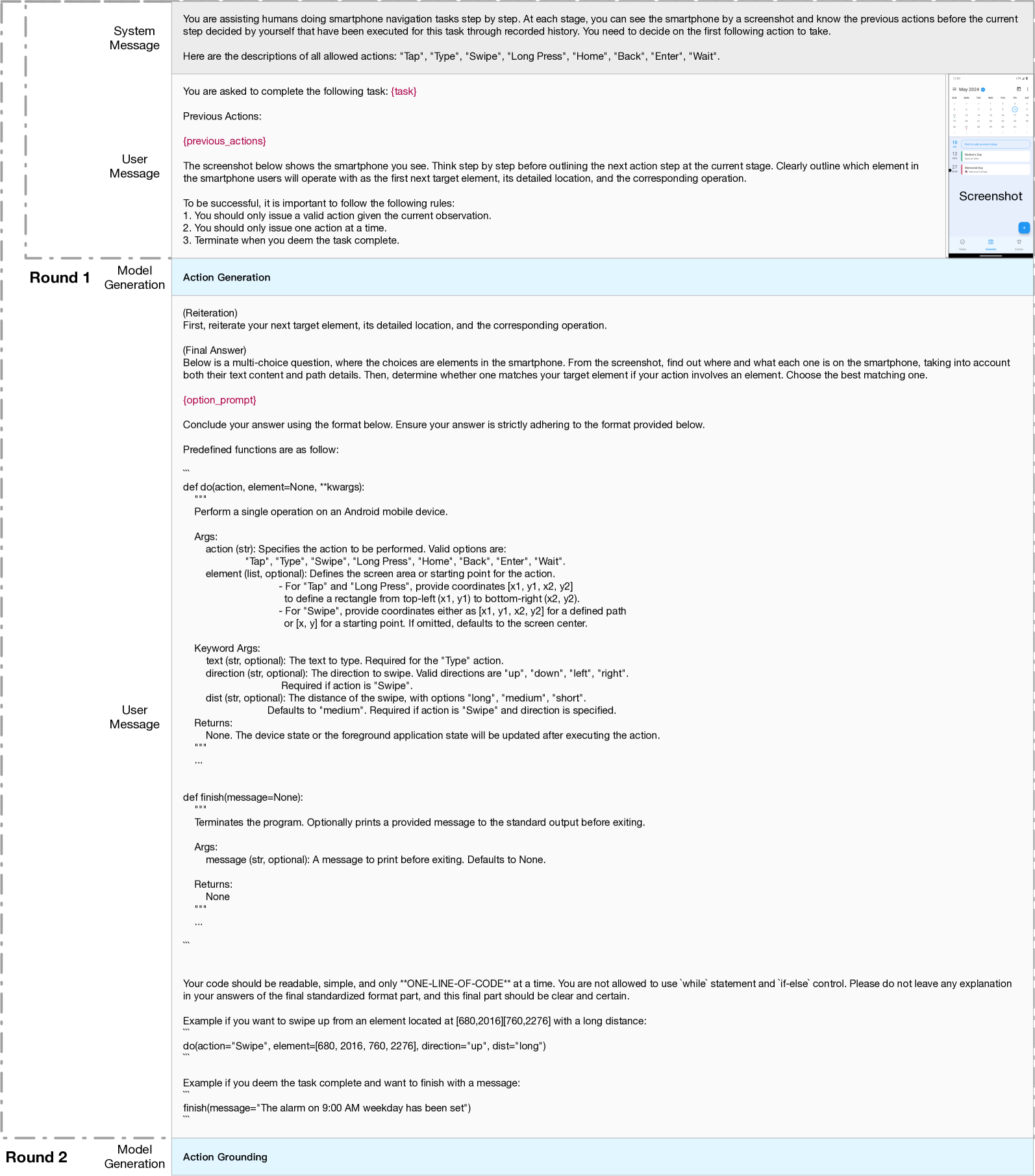
🔼 This figure displays the prompts used in the XML mode for text-only models during testing. It shows the interaction between the user and the model, with examples of how the system provides XML data about the application interface and prompts the model for the next action. The prompts guide the model to perform actions (such as Tap, Type, Swipe) on specified elements of the app’s UI using their XML coordinates.
read the caption
Figure 7: Prompts of XML Mode for Text-only Testing
More on tables
| Mode | Model | SR |
|---|---|---|
| XML | GPT-4o | 25.36 |
| XML | Gemini-1.5-Pro | 18.84 |
| XML+ReAct | GPT-4o | 33.33 |
| XML+ReAct | Gemini-1.5-Pro | 31.16 |
| XML+SeeAct | GPT-4o | 24.64 |
| XML+SeeAct | Gemini-1.5-Pro | 21.01 |
| SoM | GPT-4o | 31.16 |
| SoM | Gemini-1.5-Pro | 16.67 |
| SoM+ReAct | GPT-4o | 31.88 |
| SoM+ReAct | Gemini-1.5-Pro | 15.94 |
| SoM+SeeAct | GPT-4o | 30.43 |
| SoM+SeeAct | Gemini-1.5-Pro | 21.01 |
🔼 This table presents the success rates (SR) achieved by different language models (GPT-40 and Gemini-1.5-Pro) when employing various agent frameworks (ReAct and SeeAct). The results are categorized by the mode of interaction (XML and SoM) and the agent framework used. A key finding highlighted in the caption is the significant improvement in model performance observed specifically when the XML mode is combined with the ReAct framework. The full dataset of results from this table is available in Appendix D.3.
read the caption
Table 2: The impact of the ReAct and SeeAct frameworks on SR results. Notably, model performance is significantly improved in XML+ReAct mode. Full results of this table are shown in Appendix D.3
| Mode | FT | XML/SoM | ReAct | SeeAct |
|---|---|---|---|---|
| #Avg. Gen. Tokens | 4.96 | 23.56 | 67.89 | 129.12 |
🔼 This table presents the average number of tokens generated by different agent frameworks (XML, SoM, XML+ReAct, XML+SeeAct, SoM+ReAct, SoM+SeeAct) across various models. The LLaMA3 tokenizer was used for calculating token counts. The ‘FT’ designation indicates models that have undergone instruction tuning, highlighting the impact of this training method on the verbosity of the agents’ responses.
read the caption
Table 3: Average generation tokens of different modes. We used the LLaMA3 tokenizer for calculation. FT represents instruction tuning models.
| APP | Example Task | Sub-Goals | # tasks |
|---|---|---|---|
| Bluecoins | Record an income of 8000 CNY in the books, and mark it as “salary”. | · type: income | |
| · cash: 8000 CNY | |||
| · note: salary | 15 | ||
| Calendar | Edit the event with title “work”, change the time to be 7:00 PM. | · title: work | |
| · state: editing | |||
| · date: today | |||
| · time: 7 PM | 14 | ||
| Cantook | Mark Hamlet as read. | · book: Hamlet | |
| · state: 100% read | 12 | ||
| Clock | I need set an 10:30PM clock every weekend, and label it as “Watch Football Games”. | · time: 10:30PM | |
| · frequency: every weekend | |||
| · label: Watch Football Games | 27 | ||
| Contacts | Add a contacts whose name is Xu, set the working phone number to be 12345678, and mobile phone number to be 87654321. | · name: Xu | |
| · working phone number: 12345678 | |||
| · mobile phone number: 87654321 | 15 | ||
| Maps.me | Check the driving distance and time between Bus stop of 2700 Coast Avenue and Bus Stop Route 51. | · driving distance: 7.0km | |
| · driving time: 8 min | 15 | ||
| PiMusic | Sort Pink Floyd’s songs by duration time in descending order. | · page: ARTISTS | |
| · artist: Pink Floyd | |||
| · order: descending by duration | 12 | ||
| Setting | Show battery percentage in status bar. | · battery percentage: displayed | 23 |
| Zoom | I need to join meeting 1234567890 without audio and video. | · meeting ID: 1234567890 | |
| · audio: off | |||
| · video: off | 5 |
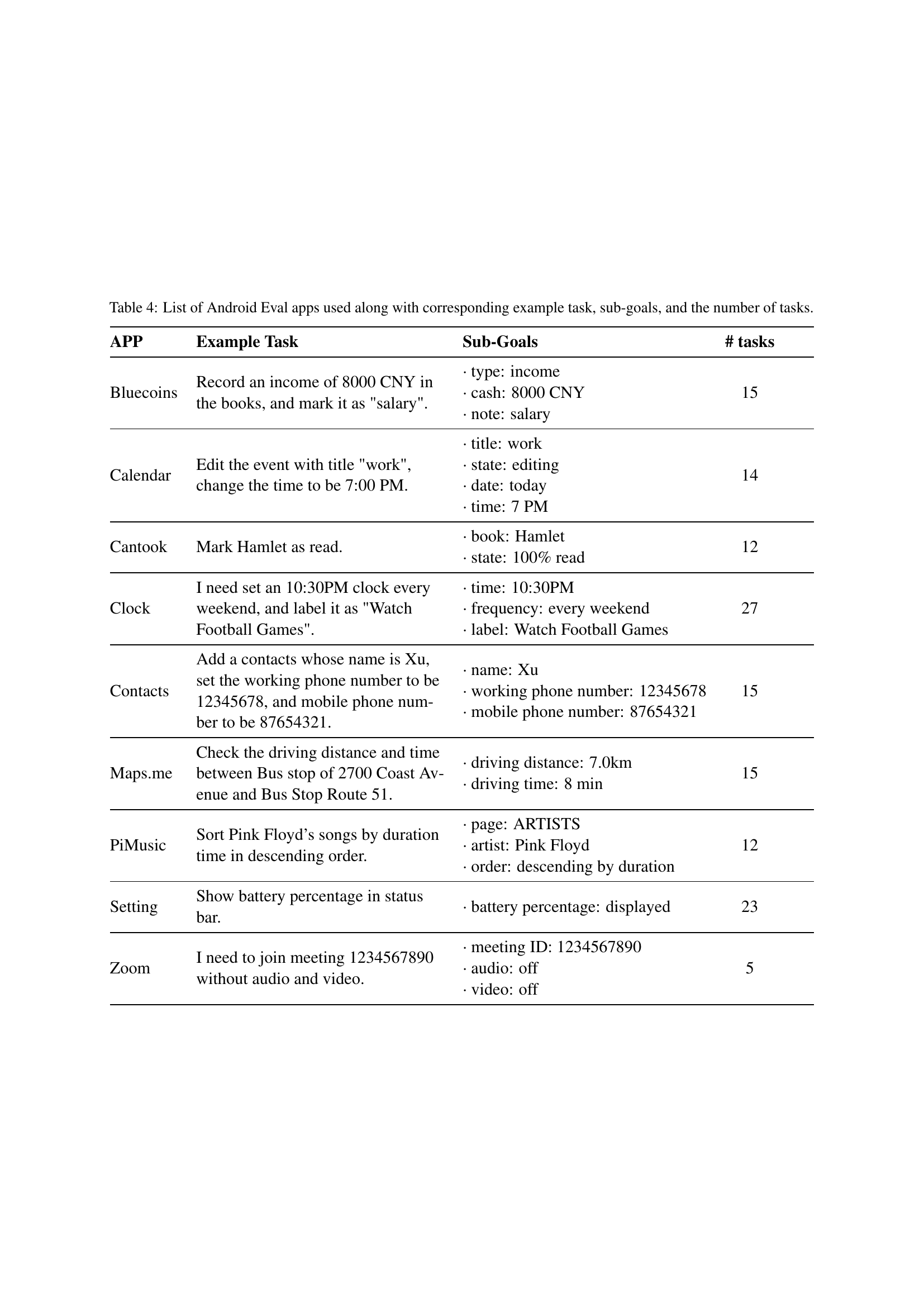
🔼 This table lists nine Android applications used in the ANDROIDLAB benchmark, along with example tasks, their sub-goals (smaller, more specific tasks that comprise each larger task), and the total number of tasks for each app. It showcases the variety and complexity of tasks within ANDROIDLAB.
read the caption
Table 4: List of Android Eval apps used along with corresponding example task, sub-goals, and the number of tasks.
| Record an income of 8000 CNY in | the books, and mark it as “salary”. |
|---|
🔼 This table presents a comprehensive overview of the performance of various language models (LLMs and LMMs) across a diverse set of 138 tasks within the AndroidLab benchmark. It breaks down the number of successfully completed tasks for each model across nine different Android apps, providing detailed insights into model performance in different operational modes (XML and SoM) and across different app categories. This allows for granular comparison of model capabilities and reveals strengths and weaknesses in handling various task types and application contexts.
read the caption
Table 5: The number of tasks completed by all models across all apps in different modes.
| Feature | Value |
|---|---|
| type | income |
| cash | 8000 CNY |
| note | salary |
🔼 This table presents a detailed breakdown of how the ReAct and SeeAct agent frameworks impact the number of successfully completed tasks across different apps. It demonstrates the improvement in model performance achieved by incorporating these frameworks, providing granular results for each app and model.
read the caption
Table 6: The improvement in model performance after employing the ReAct and SeeAct frameworks, is reflected in the increased number of successfully completed tasks across various apps.
🔼 This table compares the performance of different multi-modal instruction tuning methods. The experiment uses the same training data across all methods, but only the ‘Set of Mask’ index is added to the SoM (Set of Mask) mode. Importantly, the caption notes a limitation of the AITW (Android In The Wild) dataset, which only provides point coordinates instead of accurate bounding boxes (bbox), making it a more challenging dataset. CogVLM2 serves as the base model for all experiments. The results are presented in terms of SR (Success Rate), Sub-SR (Sub-Goal Success Rate), RRR (Reversed Redundancy Ratio), and ROR (Reasonable Operation Ratio) for both BBOX (Bounding Box) and SoM modes.
read the caption
Table 7: Different multi-modal modes of instruction tuning. We use the same set of training data but only add a set-of-mask index on SoM mode. Note that AITW dataset even could not provide accurate bbox, but only point. We use CogVLM2 as base model.
| Feature | Description |
|---|---|
| title | work |
| state | editing |
| date | today |
| time | 7 PM |
🔼 This table presents the results of experiments evaluating the impact of the ReAct and SeeAct frameworks on model performance. It shows the success rate (SR), sub-goal success rate (Sub-SR), reversed redundancy ratio (RRR), and reasonable operation ratio (ROR) for GPT-40 and Gemini-1.5-Pro models across different modes (XML, XML+ReAct, XML+SeeAct, SoM, SoM+ReAct, SoM+SeeAct). The results highlight a significant improvement in model performance, particularly in the XML+ReAct mode, demonstrating the effectiveness of the ReAct framework in enhancing agent capabilities.
read the caption
Table 8: The impact of the ReAct and SeeAct frameworks. Notably, model performance is significantly improved in XML+ReAct mode.
Full paper#