↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Large Language Models (LLMs) struggle with complex instructions, and current instruction-tuning methods using advanced LLMs to generate training data have limitations due to the models’ own imperfections. This results in noisy and suboptimal training data.
This paper proposes a novel method called “constraint back-translation.” Instead of directly generating complex instruction-response pairs, this method identifies and extracts the implicit constraints already satisfied within high-quality existing datasets and uses them to augment instructions. This results in a high-quality, cost-effective complex instruction-response dataset called CRAB which is used to post-train various LLMs. The results show significant improvements in complex instruction following ability.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on improving instruction-following capabilities of LLMs. It introduces a novel data generation method that is cost-effective and yields high-quality data, addressing the limitations of existing approaches. The findings offer valuable insights into effective training strategies and open new avenues for research in complex instruction following.
Visual Insights#

🔼 The figure illustrates that existing datasets used for training large language models (LLMs) contain implicit complex constraints that are satisfied by the model’s responses. These constraints, although not explicitly stated in the original instructions, are often related to factors like writing style, format, length, and structure of the response. The example shows how an instruction to ‘write a blog on French cuisine’ implicitly leads to constraints regarding tone (formal, informative, engaging), hierarchical structure (introduction, four main sections, conclusion), and word count (550-580 words). This observation is crucial because it highlights that high-quality responses already inherently satisfy complex requirements, a fact that can be leveraged for more efficient data generation.
read the caption
Figure 1: Existing datasets inherently include implicit satisfied complex constraints in the responses.
🔼 Table 1 presents a comprehensive comparison of various Large Language Models (LLMs) on two complex instruction following benchmarks: IFEval and FollowBench. IFEval results are broken down by strict and loose accuracy, distinguishing between prompt-level and instruction-level evaluations. FollowBench results show performance across five difficulty levels (L1-L5), representing increasing complexity. The table highlights the top two performing open-source LLMs using bold font and underlines. Results marked with † and * indicate data sourced from external studies by Sun et al. (2024) and He et al. (2024), respectively.
read the caption
Table 1: Experimental results (%) of the LLMs on IFEval and FollowBench. In IFEval, “[S]” and “[L]’ denote strict and loose accuracy, “P” and “I” indicate the prompt and instruction level. In FollowBench, L1 (simplest) to L5 (hardest) denote different difficulty levels. We highlight the highest and second-highest scores of open-source LLMs using bold font and underline. ††\dagger† and * means the results are from Sun et al. (2024) and He et al. (2024).
In-depth insights#
Constraint Back-Translation#
The core of this research paper centers around a novel data generation technique termed Constraint Back-Translation. Instead of generating complex instruction-response pairs from scratch, which is costly and prone to errors from even advanced LLMs, this method leverages existing high-quality datasets. It identifies implicit constraints already satisfied within existing responses and uses an advanced LLM (Llama3-70B-Instruct) to explicitly articulate those constraints. This approach is cost-effective and reduces data noise by utilizing existing high-quality data and simply adding already-met constraints. The resulting dataset, CRAB, demonstrates that post-training on this data improves LLMs’ complex instruction-following abilities. Furthermore, the paper finds that this technique acts as a beneficial auxiliary training objective, enhancing model understanding of constraints through a ‘reverse training’ method. This is a significant departure from previous methods, offering a more efficient and reliable way to generate training data for improving complex instruction-following abilities in LLMs.
CRAB Dataset#
The CRAB dataset is a high-quality complex instruction-following dataset created using a novel technique called constraint back-translation. Instead of relying on advanced LLMs to generate complex instruction-response pairs directly, which often results in noisy data, CRAB leverages existing high-quality datasets. It identifies implicit constraints already satisfied within the existing responses and uses an advanced LLM (Llama3-70B-Instruct) to explicitly state these constraints. This method is cost-effective and produces data with limited noise. The resulting dataset, comprising 13,500 instruction-response-constraint triples, serves as a valuable resource for training and evaluating LLMs’ complex instruction-following abilities, improving performance on benchmark datasets. The process also incorporates a reverse training objective, further enhancing model understanding of constraints. This innovative approach effectively addresses limitations of previous methods that heavily rely on LLMs’ imperfect complex instruction-following capabilities.
Reverse Training#
The research introduces reverse training as an auxiliary training objective to enhance LLMs’ understanding of constraints in complex instruction following. Instead of the standard approach of using instructions and constraints to generate responses, reverse training leverages instructions and responses as inputs to train the model to generate the inherent constraints satisfied by the response. The intuition is that this reverse process forces the model to deeply understand constraints embedded within the instruction-response pairs, thereby improving its ability to generate appropriate responses to future complex instructions. This technique is used in conjunction with standard supervised fine-tuning to create a more robust training paradigm, achieving improved performance on complex instruction following benchmarks.
Ablation Study#
The ablation study systematically investigated the contribution of three key components: reverse training, forward training, and in-context demonstrations, to the model’s performance. Removing any single component resulted in a notable decline in performance, highlighting their synergistic effects. Reverse training, particularly, proved crucial, demonstrating that teaching the model to generate constraints enhances its overall understanding and application of complex instructions. The inclusion of in-context demonstrations was especially beneficial for tackling more challenging, multi-constraint instructions. These findings underscore the importance of a holistic training approach, emphasizing the value of both reverse and forward training in conjunction with effective demonstration strategies for optimal performance in complex instruction following.
Future Directions#
The paper’s “Future Directions” section points towards several promising avenues. Improving the diversity and quality of constraint types is crucial, particularly for nuanced aspects like style, where current methods struggle. The authors also suggest exploring the integration of constraint back-translation with other data augmentation techniques to further refine data generation and potentially address limitations observed in certain constraint categories. Furthermore, they highlight the potential benefits of experimenting with larger language models as baselines, acknowledging computational constraints as a current limitation. Finally, developing more sophisticated evaluation metrics that go beyond simple accuracy and delve into aspects of response quality is considered essential to fully gauge the impact of these methods. These future directions aim to create more robust and versatile complex instruction-following models.
More visual insights#
More on figures

🔼 This figure illustrates the three-stage process for creating the CRAB dataset. The first stage, Data Collection, involves gathering high-quality instruction-response pairs from existing datasets. These pairs are then processed in the Constraint Back-translation stage, where a large language model (LLM) is used to extract implicit constraints satisfied by the existing responses. Finally, the Constraint Combination stage combines these extracted constraints with the original instructions and responses to create the final training dataset. The figure shows the data flow and transformations at each stage.
read the caption
Figure 2: The framework of constructing the proposed alignment training dataset.

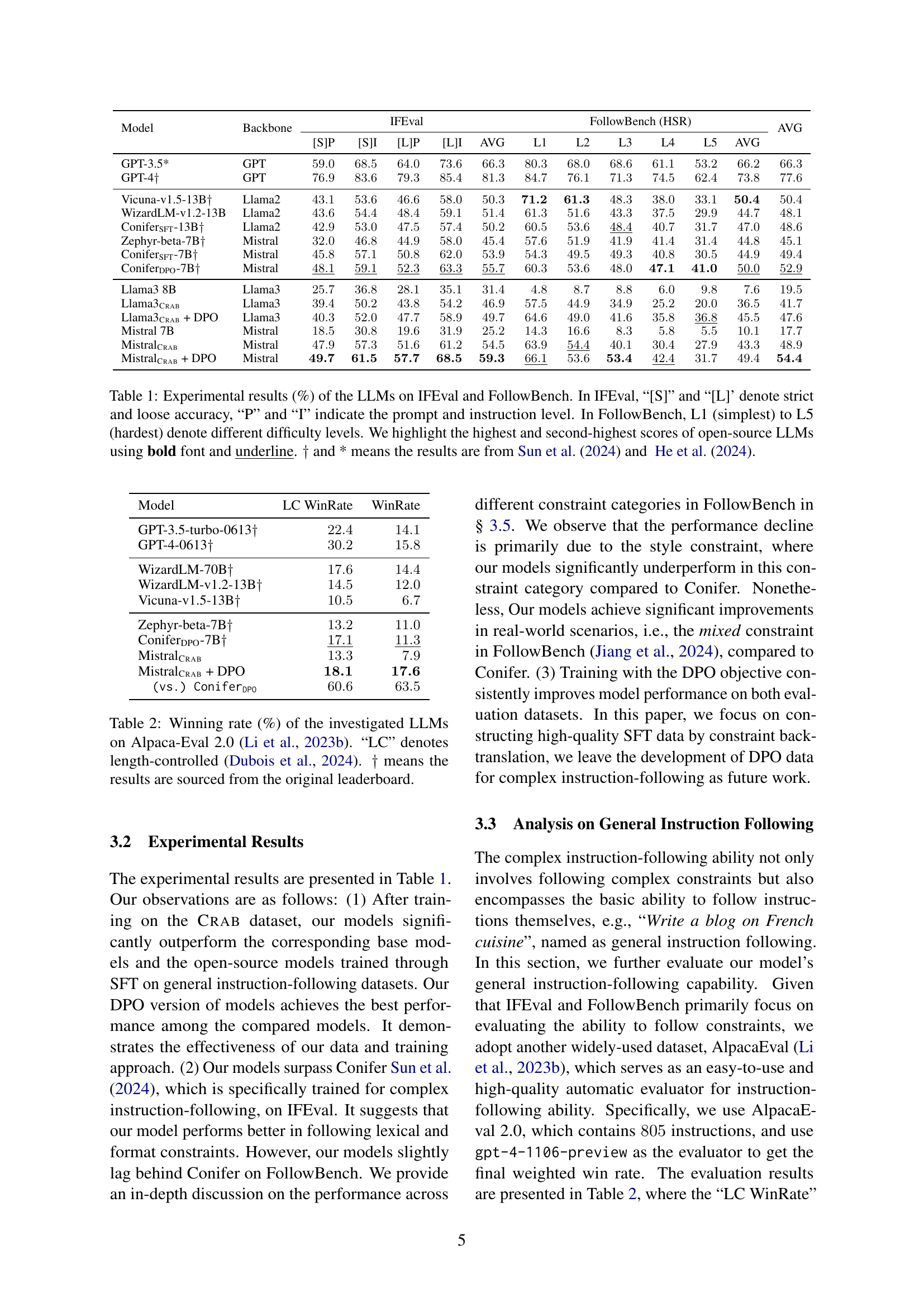
🔼 Figure 3 showcases the impact of constraints on the quality of responses generated by Llama-3-70B-Instruct. It presents an example where the same instruction is given to the model, once with specified constraints and once without. The resulting responses are then evaluated by GPT-4-0806, highlighting the differences in quality metrics. The figure emphasizes that using constraints significantly improves the quality and structure of responses.
read the caption
Figure 3: An example of responses generated with and without constraints by Llama3-70B-Instruct. The evaluator is gpt-4o-0806. For better visualization, we present only a subset of the responses generated without constraints.

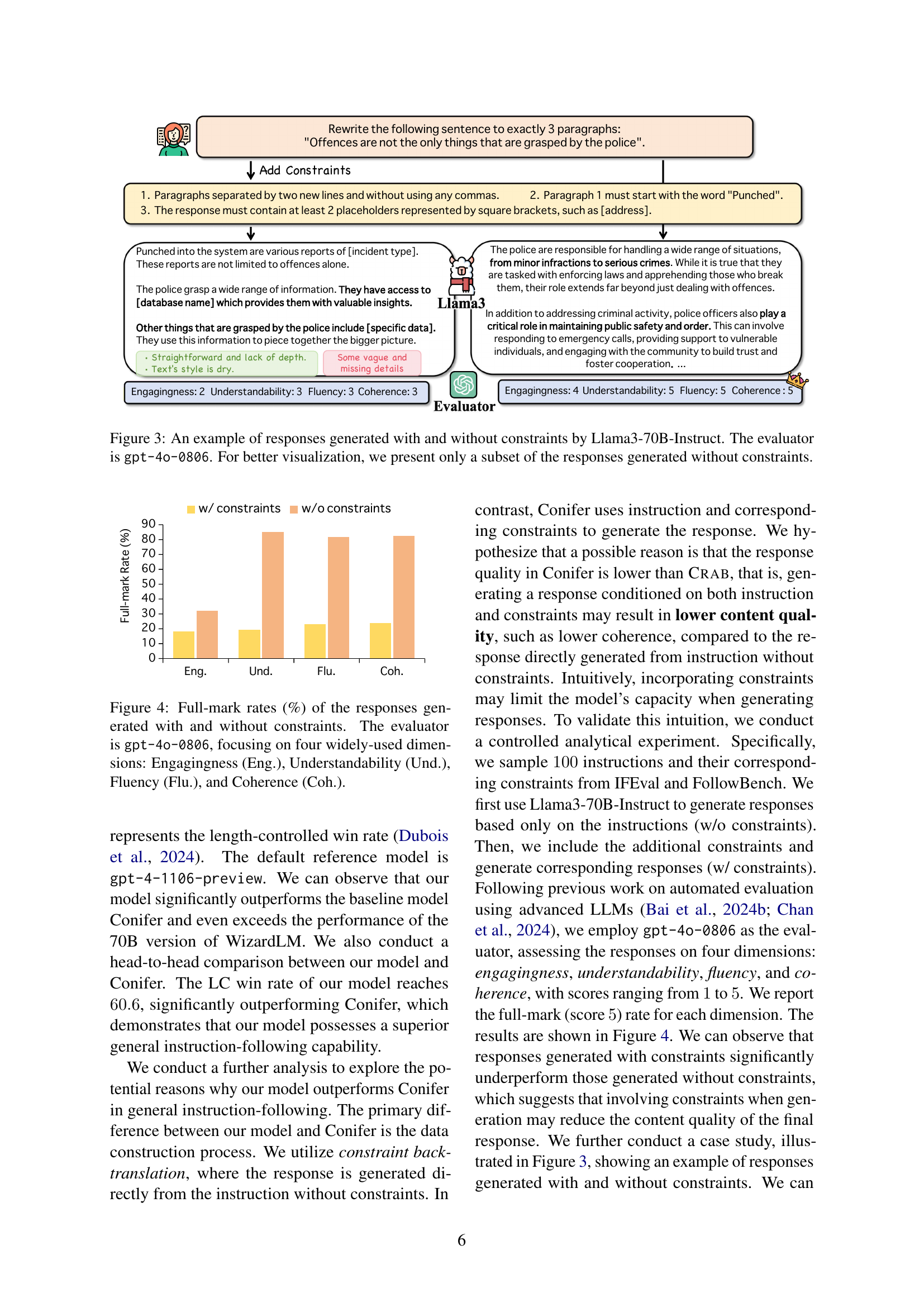
🔼 Figure 4 presents a bar chart comparing the quality of responses generated by a language model with and without constraints. The responses were evaluated by the GPT-4 model (gpt-4o-0806) across four key dimensions: Engagingness, Understandability, Fluency, and Coherence. Each dimension’s score is represented as a percentage of responses receiving a full mark (indicating the highest quality). The chart allows for a direct comparison of the impact of adding constraints to the prompts on the overall quality of the model’s output, as measured by these four dimensions. This visualization helps to demonstrate the effectiveness of constraint back-translation in enhancing the quality of generated text.
read the caption
Figure 4: Full-mark rates (%) of the responses generated with and without constraints. The evaluator is gpt-4o-0806, focusing on four widely-used dimensions: Engagingness (Eng.), Understandability (Und.), Fluency (Flu.), and Coherence (Coh.).

🔼 Figure 5 presents a bar chart comparing the performance of MistralCrab and ConiferSFT across various constraint categories within the FollowBench benchmark. Each bar represents a constraint type (e.g., example, content, situation, style, format, mixed), and the height of the bar indicates the models’ success rate for that constraint type. This visualization allows for a direct comparison of the two models’ abilities to handle different kinds of constraints in complex instruction following tasks, highlighting strengths and weaknesses of each approach.
read the caption
Figure 5: Experimental results on different categories of constraints in FollowBench of MistralCrab and ConiferSFT.

🔼 Figure 6 shows the distribution of the 13,500 instances in the CRAB dataset. The left pie chart displays the percentage of instances containing a specific number of constraints after the combination process. The right pie chart illustrates the percentage of instances originating from each of the four source datasets used to create CRAB: Alpaca GPT4, Orca Chat, Evol Instruct, and OpenAssistant. The figure helps to visualize the diversity of constraint numbers and the source dataset contributions to the CRAB dataset.
read the caption
Figure 6: Proportion (%) of data in the Crab by the number of constraints and the source dataset.
More on tables
| Model | LC WinRate | WinRate |
|---|---|---|
| GPT-3.5-turbo-0613† | 22.4 | 14.1 |
| GPT-4-0613† | 30.2 | 15.8 |
| WizardLM-70B† | 17.6 | 14.4 |
| WizardLM-v1.2-13B† | 14.5 | 12.0 |
| Vicuna-v1.5-13B† | 10.5 | 6.7 |
| Zephyr-beta-7B† | 13.2 | 11.0 |
| ConiferDPO-7B† | 17.1 | 11.3 |
| MistralCrab | 13.3 | 7.9 |
| MistralCrab + DPO | 18.1 | 17.6 |
| (vs.) ConiferDPO | 60.6 | 63.5 |
🔼 This table presents the winning rates of various Large Language Models (LLMs) on the Alpaca-Eval 2.0 benchmark. Alpaca-Eval 2.0 assesses the general instruction-following abilities of LLMs. The winning rate indicates the percentage of times a given LLM’s response was judged superior to that of another LLM when both responded to the same prompt. The results are categorized by whether or not length constraints were applied to the model’s response generation. A dagger symbol (†) denotes that the results were taken from the original Alpaca-Eval leaderboard, indicating that those specific model results were not generated as part of this paper’s experimental setup.
read the caption
Table 2: Winning rate (%) of the investigated LLMs on Alpaca-Eval 2.0 (Li et al., 2023b). “LC” denotes length-controlled (Dubois et al., 2024). ††\dagger† means the results are sourced from the original leaderboard.
| Model | IFEval | FollowBench AVG | FollowBench L1-L2 | FollowBench L3-L5 | AVG |
|---|---|---|---|---|---|
| MistralCrab | 54.5 | 59.1 | 32.8 | 48.9 | |
| (-) Reverse training | 52.1 | 56.2 | 33.5 | 47.3 | |
| (-) Forward training | 53.9 | 57.1 | 32.1 | 48.0 | |
| (-) In-Context Demons | 53.6 | 55.8 | 30.0 | 47.0 | |
| InstBackTSFT | 52.7 | 55.4 | 29.3 | 46.2 |
🔼 This table presents the results of an ablation study analyzing the impact of different components on the performance of the model. The study investigates three key factors: reverse training, forward training (supervised fine-tuning), and the inclusion of in-context demonstrations. The model’s performance is evaluated on the IFEval and FollowBench datasets, with separate scores for strict and loose accuracy on IFEval, and scores broken down by difficulty level (L1-L5) for FollowBench. Each row represents a model trained with a specific combination (or absence) of the three factors, allowing for a comparison of their individual and combined effects on the overall effectiveness of the model in following complex instructions.
read the caption
Table 3: Experimental results (%) of the ablation study. In-Context Demons denotes in-context demonstrations.
| Constraint Category | Generator | Weighted |
|---|---|---|
| Define Circumstances | LLM | 0.7 |
| Desired Writing Style | LLM | 0.7 |
| Semantic Elements | LLM | 0.8 |
| Morphological Constraints | LLM | 0.8 |
| Multi-lingual Constraints | LLM | 0.8 |
| Specific Literary Devices | LLM | 0.8 |
| Specific Grammatical Structure | LLM | 0.8 |
| Hierarchical Instructions | LLM | 0.8 |
| Special Output Format | LLM | 0.8 |
| Paragraphs Constraints | LLM | 0.7 |
| Specific Sentence | LLM | 0.7 |
| Keyword Formatting | LLM | 1.0 |
| Item Listing Details | LLM | 1.0 |
| Length Constraint | Python | 0.5 |
| Words Per Sentence | Python | 0.5 |
| Sentences Per Paragraph | Python | 0.3 |
| Characters Per Word | Python | 0.3 |
| Keyword Constraint | Python | 0.5 |
| Punctuation Limitation | Python | 0.3 |
🔼 This table lists the nineteen types of constraints used in the constraint back-translation process, which are categorized by constraint type and generator (LLM or Python). The ‘Weighted’ column shows the probability of each constraint type being selected during the combination phase where multiple constraints are combined to form a final constraint for an instruction.
read the caption
Table 4: Constraint types defined during the back-translation process. 'Weighted' indicates the sampling probability of each constraint type during combination.
| Instruction | Output |
|---|---|
| What is an easy J Perm PLL algorithm that wouldn’t be too complicated for a beginner at speed solving? | One easy J Perm PLL algorithm that is not too complicated for a beginner at speed solving is the following: R’ U R’ U’ J R U’ R’ U’ J’ U2 R U This algorithm only has 10 moves and does not require any complicated finger tricks. Here is a breakdown of the algorithm: 1. R’ U R’ U’ - This is a common setup move for J Perm PLL algorithms. It sets up the J shape in the corner of the cube. 2. J R U’ R’ U’ - This is the J Perm algorithm itself. It swaps the two adjacent edges and the two adjacent corners in the J shape. 3. J’ U2 R U - This is the inverse of the setup move and completes the PLL algorithm. Remember to practice this algorithm slowly at first, and then gradually increase your speed. With enough practice, you should be able to execute this algorithm quickly and efficiently. |
| Define Circumstance: What is a simple, 10-move or fewer J Perm PLL algorithm for speed solving that a beginner can learn and execute efficiently, without requiring advanced finger tricks or complex sequences? | A simple, beginner-friendly Perm PLL algorithm, involving 10 or fewer moves, and avoiding complicated finger tricks is highly desirable for efficient execution in speed solving. The algorithm should be easily learnable and executable. The focus should be on a clear, concise explanation that avoids overly technical terminology. The response must use at least 160 words and adhere to specified word and character limits. Each sentence should ideally be under 25 words, and each word should contain at least 15 characters. The explanation should use a step-by-step approach. The keywords ‘complicated finger tricks’, ‘Perm PLL’, and ‘Perm PLL algorithm’ should be included. The response should not contain question marks and should adhere to the specified grammatical structure. The goal is to provide a helpful resource for beginners in speed solving, focusing on the simplicity and ease of use of the algorithm. This means providing straightforward instructions that are easily understood without being overly verbose. |
| Length Constraint: Submit an response that contains at least 160 words. | The response will include at least 160 words, and will provide detailed instructions for executing a simple Perm PLL algorithm. The response will be carefully crafted to satisfy the specified word count requirement, while remaining clear, concise, and easy to understand for beginners. This ensures that the instructions are easy to follow, even for those new to speed cubing, making it more accessible and effective for learning and implementation. The additional word count will be used to provide further explanations and more detailed information about the algorithm, while keeping the sentences short. The focus will be on making the process simpler and easier to understand for beginners in speed solving. This way, the algorithm will be made accessible to newcomers who might have limited previous experience. |
| Word Per Sentence: Restrict each sentence to 25 words maximum. | Each sentence in the response will adhere to the 25-word limit to ensure clarity and readability. This approach makes the instructions easier to comprehend for beginners, avoiding overwhelming them with excessively long sentences. The brief sentences maintain a consistent and easily digestible flow of information throughout the entire explanation. This approach simplifies the learning process and enhances comprehension, leading to faster and more effective learning. This strategy helps to support beginners in mastering the algorithm. |
| Characters Per Word: Each word in the response must consist of at least 15 characters. | Every word used in the response will include at least fifteen characters. This constraint ensures more descriptive words, which helps to enhance the overall clarity of the explanation. The additional letters help to minimize ambiguity and add specificity to the instructions, making the process more effective. This improves the comprehension level and ensures that the algorithm’s execution is readily grasped by new users. The use of more extensive vocabulary contributes to the comprehensive nature of the response. |
| Keyword Constraint: In your reply, include the terms complicated finger tricks, Perm PLL, Perm PLL algorithm to emphasize the critical components and provide clarity. | The response includes the terms ‘complicated finger tricks’, ‘Perm PLL’, and ‘Perm PLL algorithm’ to highlight essential elements and to provide clarity. The inclusion of these keywords ensures the critical aspects are clearly emphasized. The targeted use of these keywords enhances both the understanding and accessibility of the provided information, making the response much clearer and more useful for the audience. The strategic placement of these terms further improves clarity and readability, making the text easier to follow. |
| Punctuation Limitation: Avoid using question marks in your response. | The response will not include any question marks. This adherence to the punctuation limitation enhances the tone and style of the response, enhancing its overall structure and appeal. The absence of question marks contributes to the overall clarity and professionalism of the provided information, making it easier for beginners to understand the algorithm. The absence of question marks simplifies the process, improving readability. |
| Desired Writing Style: The response should be written in a clear and concise manner, with a tone that is informative and helpful, suitable for a beginner in speed solving. | The response maintains a clear, concise, and informative style, appropriate for beginners. The tone is helpful and supportive. The writing is intended to be easily understood, and the information is presented in a manner that is accessible to new learners of speed solving. The simple writing ensures the algorithm is straightforward for beginners to learn, helping them improve and progress quickly. The use of clear, concise language avoids confusion. |
| Semantic Elements: The main theme of the response should focus on providing a simple J Perm PLL algorithm for beginners, highlighting its ease of use and simplicity. | The response focuses on providing a simple J Perm PLL algorithm for beginners. It emphasizes the algorithm’s ease of use and simplicity. The core message highlights the beginner-friendliness and ease of execution. The simplicity and clarity of the presented algorithm are essential to assist new speed cubers in their learning journey. The main emphasis is making learning as simple as possible. |
| Morphological Constraints: Avoid using overly technical jargon or complex mathematical notation, and refrain from using formatting styles that may confuse the reader. | The response avoids using overly complex mathematical notation or technical jargon. It also avoids formatting that may confuse the reader. This makes the response more accessible to a wider range of beginners. This style ensures the information remains clear, concise, and uncomplicated. The simple style ensures understanding is prioritized. The uncomplicated language improves accessibility and understanding for a broader audience. |
| Multi-lingual Constraints: The response should be written in English. | The response is written in English. This is to ensure the greatest accessibility for the largest possible number of English-speaking users. This ensures the response is easily accessible to a global audience. This focus on English language improves inclusivity for a large segment of the global audience. English is used for accessibility. |
| Specific Literary Devices: Use a step-by-step breakdown of the algorithm to enhance clarity and facilitate understanding. | The response uses a step-by-step approach to break down the algorithm. This helps ensure clarity and understanding for the reader. The breakdown uses numbered steps for better organization and ease of understanding. This organization improves understanding and ease of implementation. The step-by-step explanation makes the learning process easier. |
| Specific Grammatical Structure: The response should be written primarily in simple sentences, with occasional use of compound sentences to provide additional explanations. | The response primarily uses simple sentences. Compound sentences are occasionally used for providing further context. This grammatical structure ensures the information is easily accessible for beginners. Simple sentence structures support clarity for new learners. This grammatical choice improves readability. |
| Hierarchical Instructions: The response should prioritize explaining the algorithm, followed by a breakdown of the algorithm, and finally providing practice tips. | The response prioritizes the algorithm’s explanation, then the breakdown, and finally practice tips. This structure helps to build understanding in stages. This hierarchy improves comprehension. This organizational strategy focuses on building understanding in steps. |
| Paragraphs Constraints: The response should consist of three paragraphs, with a blank line separating each paragraph. | The response has three paragraphs separated by blank lines. This structure aids readability. This structure improves readability and organization. The use of paragraphs enhances the organization and readability of the response. |
| Specific Sentence: The response should start with a sentence that introduces the algorithm, and end with a sentence that encourages practice. | The response begins by introducing the algorithm and ends by encouraging practice. This structure helps to provide a solid start and finish to the response. This structure improves the response’s overall flow and presentation. A strong introduction and conclusion create a clear framework for the explanation. |
🔼 This table shows an example of data from the OpenAssistant dataset after the constraint back-translation process has been applied but before the final constraints have been combined. It illustrates the intermediate step in the CRAB dataset creation process, highlighting the different constraints identified and added to the original instruction and response pair.
read the caption
Table 5: An example from OpenAssistant of Crab after constraint back-translation and before combination.
Full paper#